
Adaptive RAG Systems: Improving Accuracy Through LangChain & LangGraph
Adaptive RAG systems leverage LangChain & LangGraph to improve accuracy and efficiency. This guide explores key techniques, implementation strategies, and best practices for optimizing retrieval, refining responses, and enhancing AI-driven workflows.


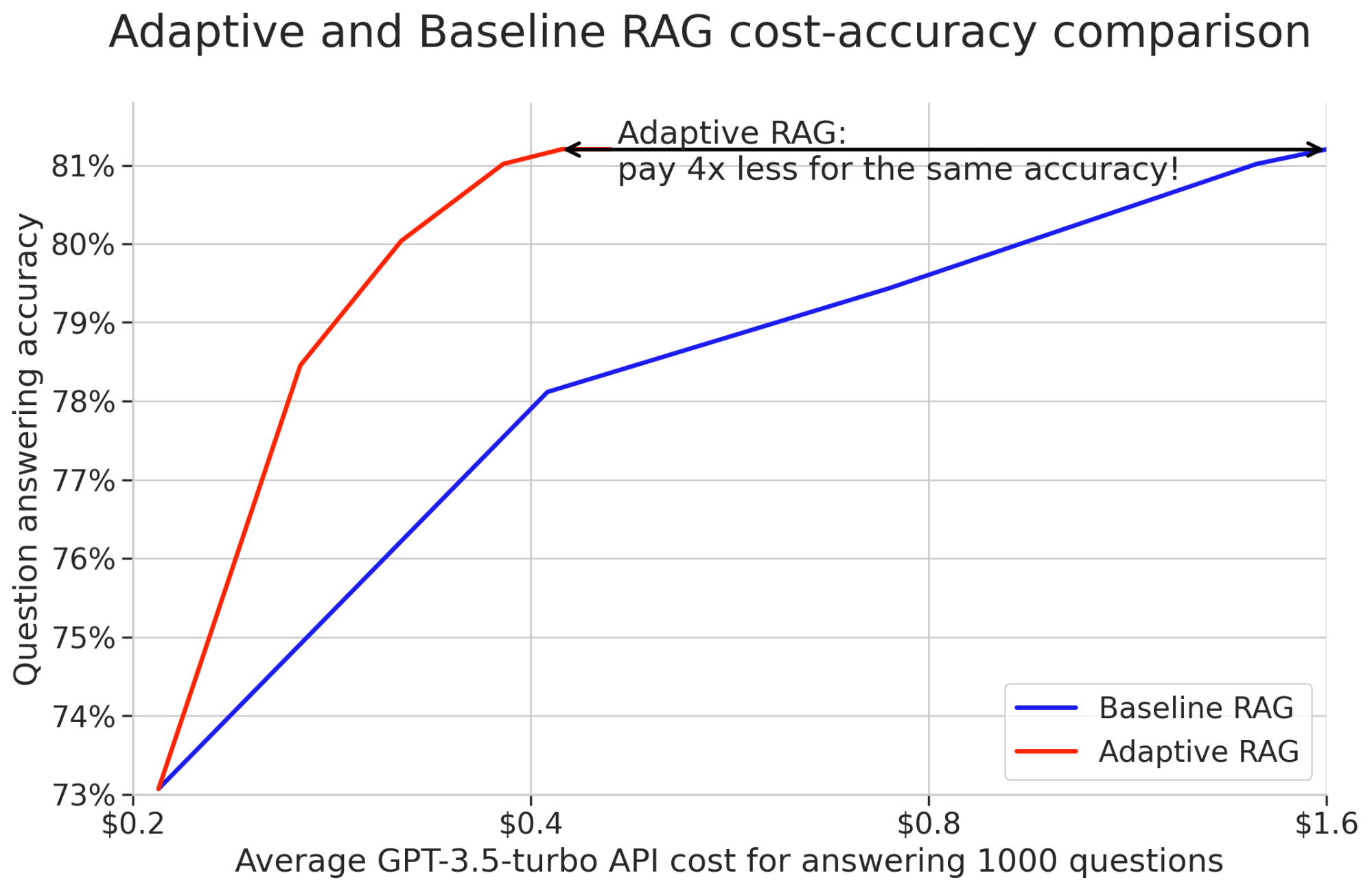
AI systems often retrieve too much or too little information, leading to irrelevant or incomplete answers.
Traditional RAG models apply the same retrieval process to every query, regardless of complexity. This results in unnecessary computation for simple questions and insufficient depth for complex ones.
Adaptive Retrieval-Augmented Generation (RAG) systems address this by dynamically adjusting retrieval depth based on query complexity.
By integrating LangChain’s modular tools with LangGraph’s state machine architecture, AI systems can determine when to skip retrieval, retrieve a single document, or iterate through multiple sources.
Companies using Adaptive RAG have reported efficiency gains. In customer support, response times dropped when queries were routed intelligently.
In research, domain-specific embeddings improved retrieval accuracy by 20%. This guide explains how Adaptive RAG systems refine retrieval, reduce latency, and improve AI-generated responses.
Understanding Retrieval-Augmented Generation
Adaptive Retrieval-Augmented Generation (RAG) systems thrive on their ability to adjust retrieval processes dynamically based on query complexity.
One standout feature is the integration of LangChain’s modular tools with LangGraph’s state machine architecture. This pairing enables systems to route queries intelligently, reducing latency and improving accuracy.
But why does this work so well?
The secret lies in the adaptability of the retrieval mechanism.
For instance, Athina AI, a pioneer in customer support automation, reported reduced response times by leveraging Adaptive RAG.
Their system skipped retrieval for straightforward FAQs, retrieved single documents for mid-level queries, and executed multi-step retrieval for complex cases.
This tiered approach saved computational resources and enhanced user satisfaction by delivering precise answers faster.
A lesser-known factor is the role of domain-specific embeddings. By tailoring retrieval models to understand industry-specific jargon, companies like MedResearch Institute achieved a 20% improvement in retrieval accuracy for medical literature.
This precision directly impacted their ability to generate actionable insights for researchers.
Role of LangChain and LangGraph
LangChain and LangGraph form the backbone of Adaptive RAG systems, enabling seamless orchestration of retrieval and generation processes.
LangChain’s modular tools simplify the integration of language models with external data sources, while LangGraph’s state machine architecture ensures precise query routing.
Together, they create a system that’s both flexible and efficient.
A lesser-known advantage lies in LangGraph’s support for iterative retrieval. This feature is critical for multi-hop reasoning, where answers depend on synthesizing information from multiple sources.
Looking forward, the challenge is scaling these systems while maintaining ethical transparency. As more organizations adopt LangChain and LangGraph, the focus must shift to mitigating biases and ensuring equitable access to these transformative technologies.
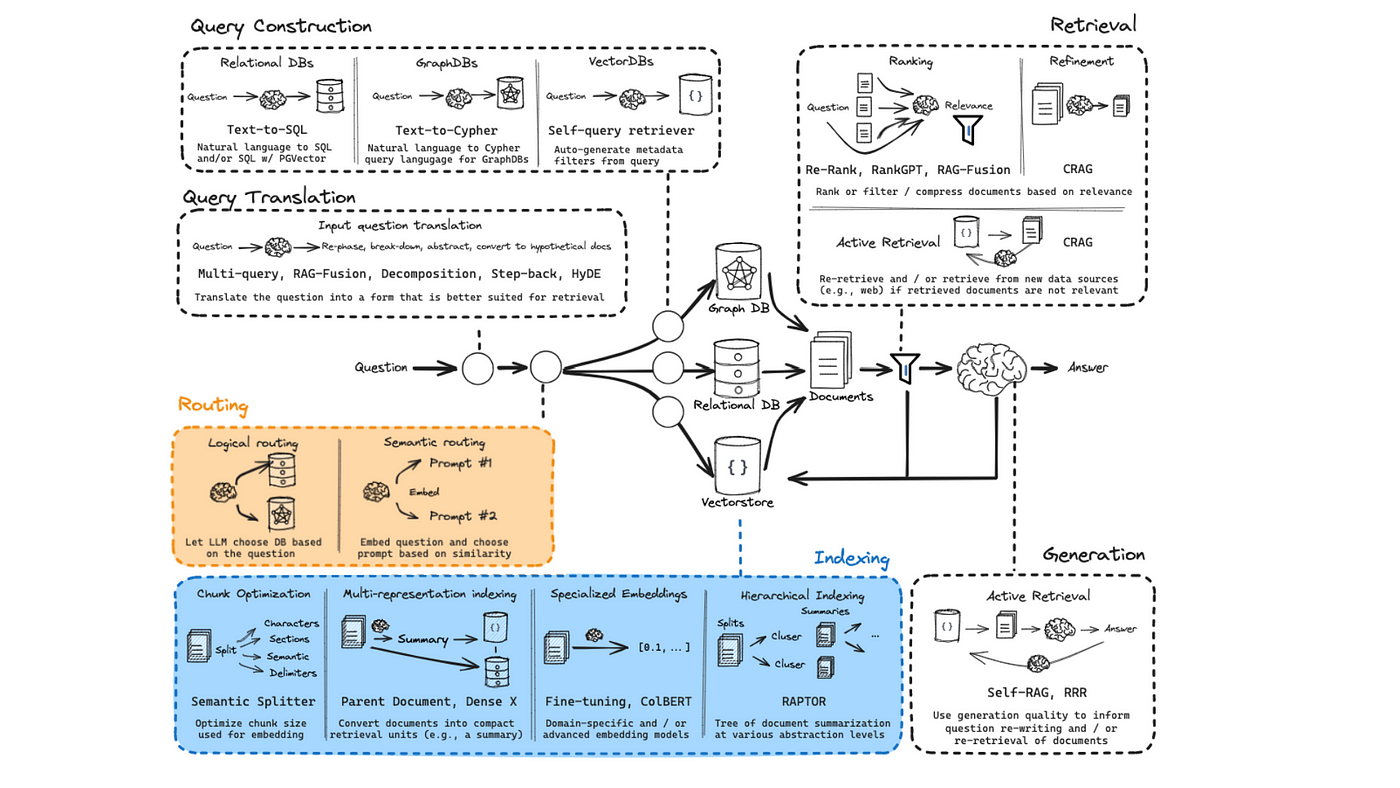
Core Components of Adaptive RAG Systems
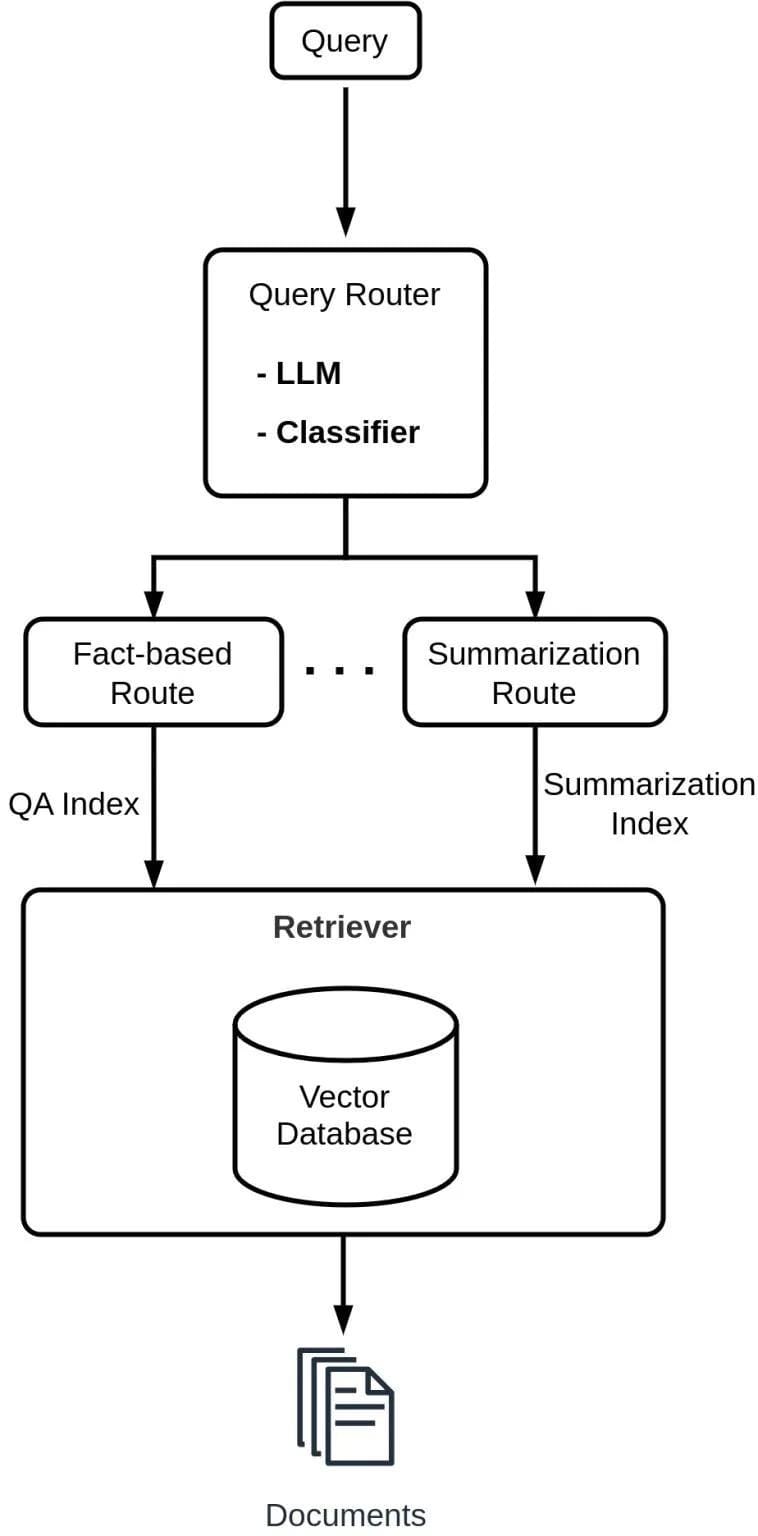
Adaptive RAG systems adjust retrieval depth based on query complexity. Their effectiveness relies on four key components: the complexity classifier, query router, retriever, and generator. These elements work together to optimize efficiency, reduce computation costs, and improve response accuracy.
The complexity classifier determines whether a query requires retrieval. Simple questions may not need retrieval at all, while complex ones may require multiple iterations. This prevents unnecessary lookups, reducing latency.
The query router directs requests to the best data source. It decides whether a query should pull from a vector database, external API, or a combination of sources. By routing queries efficiently, the system avoids redundant searches.
The retriever fetches relevant documents, refining its selections using domain-specific embeddings. This ensures the retrieved data aligns with the user’s intent rather than relying on broad keyword matches.
The generator synthesizes retrieved information into a coherent response. By integrating retrieved data with a language model, it produces structured, context-aware answers tailored to the query’s complexity.
A common misconception is that Adaptive RAG systems follow a fixed process. In reality, their strength lies in their ability to iterate and improve over time. As more organizations adopt them, the challenge will be balancing efficiency with ethical transparency, ensuring fair and accurate responses across diverse applications.
Query Analysis and Optimization
Query analysis in Adaptive RAG systems involves more than extracting keywords. It consists in understanding intent and selecting the best retrieval strategy, which ensures efficient data retrieval and precise responses.
The query complexity classifier determines the depth of retrieval needed. It evaluates whether a query requires no retrieval, a single document, or multiple sources. The system can improve efficiency while maintaining accuracy by filtering out unnecessary retrieval steps.
Query optimization refines input before retrieval begins. Query rewriters adjust ambiguous phrasing to ensure clear and relevant results. This is especially useful in specialized fields like healthcare and finance, where technical terms or vague wording can lead to incorrect outputs.
Linguistic and cultural differences also affect query interpretation. Users from different regions phrase questions differently, which can influence retrieval results. Systems that adjust for these variations improve clarity and relevance in multilingual applications.
The next advancement in query optimization is dynamic query planning. By breaking complex questions into smaller sub-queries, systems can retrieve information step by step. This structured approach ensures accurate responses, especially for tasks that require reasoning across multiple sources.
Dynamic Retrieval Strategies
Dynamic retrieval strategies adjust retrieval depth based on query complexity. This prevents unnecessary lookups for simple questions while enabling deeper searches for multi-step queries.
One effective approach is iterative retrieval-generation loops, where generated responses refine future retrievals. Instead of relying on a single search pass, the system continuously improves its results. This is useful for tasks requiring multi-hop reasoning, such as research or legal analysis.
Contextual adjustments also play a role. Queries phrased differently due to cultural or linguistic variations may require tailored retrieval methods.
Systems that recognize these differences improve relevance and user satisfaction, particularly in multilingual applications.
An advanced method is query decomposition, where complex questions are broken into smaller parts.
A legal system, for instance, could retrieve precedents separately and synthesize them into a single response. This structured approach enhances accuracy in fields where decision-making depends on multiple data sources.
Self-Corrective Mechanisms
Self-corrective mechanisms improve the reliability of Adaptive RAG systems by evaluating responses for relevance and accuracy. These systems do more than retrieve and generate—they refine their own outputs through iterative feedback.
A key feature is generation verification, which cross-checks responses against retrieved documents. This reduces hallucinations, ensuring that generated answers align with factual sources. Systems using this method build user trust by minimizing errors in fields where precision is critical, such as healthcare or legal research.
Context-aware adjustments further enhance accuracy. Verification thresholds can be adapted based on regional language variations, improving system performance in multilingual environments. This ensures that retrieval and response generation remain relevant across different audiences.
A future development is real-time error handling, where AI flags inaccurate outputs and suggests alternative sources or reformulates unclear queries. These enhancements move beyond static AI models, making systems more adaptive and capable of learning from user interactions.
Advanced Techniques in Adaptive RAG
Let’s talk about what really sets Adaptive RAG apart: its ability to evolve with the complexity of the task.
One standout technique is iterative retrieval-generation loops, where the system refines its answers by cycling outputs back into the retrieval process.
Another game-changer? Dynamic query rewriting. This isn’t just about fixing typos; it’s about reshaping vague or ambiguous questions into something the system can actually work with.
Here’s the kicker: many assume these techniques are resource-heavy. But Athina AI proved otherwise, cutting response times through smart query routing and retrieval skipping. It’s efficiency without compromise.
The real magic happens when these techniques combine. Imagine a legal AI breaking down a case into sub-queries, iterating for precedents, and rewriting unclear prompts—all in real time. That’s not just advanced; it’s transformative.
Multi-Agent Systems with LangGraph
When it comes to tackling complex workflows, Multi-Agent Systems with LangGraph shine by orchestrating specialized agents to work in harmony.
Think of it as a symphony where each instrument plays a distinct role, yet together they create something extraordinary. LangGraph’s stateful workflows allow agents to share a global state, ensuring task consistency. This is a game-changer for industries like healthcare and legal research, where precision and coordination are non-negotiable.
What’s fascinating is how LangGraph enables adaptive workflows.
For example, Athina AI used agents to switch between retrieval strategies based on query complexity dynamically. This reduced response times, proving that efficiency doesn’t have to come at the cost of accuracy.
Here’s a thought experiment: imagine a legal AI breaking down a case into sub-queries. One agent retrieves precedents, another analyzes them, and a third drafts a summary. This layered approach could revolutionize how law firms handle intricate cases.
Adaptive Routing and Strategy Selection
Let’s talk about what makes adaptive routing a standout feature in modern RAG systems: its ability to dynamically select the best retrieval strategy for each query.
This isn’t just about efficiency—it’s about precision. By leveraging tools like LangGraph’s state machine architecture, systems can route queries to the most relevant data source, whether it’s a local vector store or a web search interface.
Here’s the nuance: adaptive routing isn’t just technical; it’s contextual. Companies like GlobalEdTech fine-tuned their systems to account for regional idioms and cultural nuances, improving multilingual query accuracy by 15%.
This highlights how understanding user intent can transform outcomes beyond just the words they use.
Now, imagine applying this to legal research. A system could break down a case into sub-queries, dynamically route each to the best data source, and synthesize the results into actionable insights. This layered approach could redefine how industries handle complex decision-making.
Integration with External Knowledge Sources
When it comes to Adaptive RAG systems, integrating external knowledge sources is like giving your AI a library card to the world’s most specialized collections.
But here’s the catch: not all libraries are created equal. The key lies in tailoring retrieval to the context—whether it’s a vector database for technical manuals or a live web search for breaking news.
A common misconception is that more data equals better results. In reality, it’s about relevance. Systems like Athina AI prove this by skipping retrieval for simple queries, cutting response times.
The lesson? Smarter integration beats brute force every time.
Incorporating Web Search for Real-Time Data
Integrating web search into Adaptive RAG systems ensures access to up-to-date, relevant information. This is critical in fields like finance and healthcare, where outdated data can lead to poor decisions.
The challenge is prioritizing credible sources while maintaining response speed. Systems can filter web data using metadata analysis, favoring high-quality publications over less reliable content. This prevents misinformation from influencing retrieval-based outputs.
Another consideration is regional adaptation. Multilingual systems must refine search strategies based on local phrasing and terminology. This improves relevance and ensures that retrieved information aligns with the intended context.
Future advancements in dynamic query reformulation will refine search inputs iteratively, adjusting terms based on initial results. This approach enhances depth and accuracy, allowing AI to extract meaningful insights from an ever-changing information landscape.
FAQ
What are the core components of Adaptive RAG systems and how do they enhance accuracy?
Adaptive RAG systems consist of a complexity classifier, query router, retriever, and generator. The classifier determines retrieval depth, the router directs queries to the best data source, and the retriever fetches relevant information using domain-specific embeddings. The generator then synthesizes responses, improving precision and reducing redundancy.
How do LangChain and LangGraph optimize retrieval and generation in Adaptive RAG systems?
LangChain connects AI models with external data sources, while LangGraph structures query workflows. Together, they refine retrieval depth and improve multi-hop reasoning. LangGraph’s state machine architecture enables precise query routing, reducing response times and improving AI-generated accuracy in fields like healthcare, finance, and customer support.
What role do domain-specific embeddings play in improving Adaptive RAG performance?
Domain-specific embeddings refine retrieval by understanding specialized terminology. In healthcare and legal research, they improve search relevance by aligning with industry jargon. This ensures AI retrieves precise, context-aware information instead of generic results. Organizations using tailored embeddings have reported a 20% increase in retrieval accuracy.
How can Adaptive RAG systems scale while maintaining ethical transparency and minimizing bias?
Ethical scaling requires bias audits, explainable AI, and diverse training data. Real-time feedback loops detect inconsistencies, while domain-specific embeddings reduce inaccuracies in sensitive applications. Organizations using LangChain and LangGraph can build accountable, fair AI models that improve accuracy while maintaining transparency in decision-making.
What are the practical applications of Adaptive RAG in healthcare, legal research, and customer support?
Adaptive RAG improves diagnostic support in healthcare, accelerates legal case research, and refines customer support interactions. In medical research, multi-hop retrieval extracts insights from clinical trials. Legal AI synthesizes case law into summaries. Customer support systems dynamically adjust responses, cutting response times by 35%.
Conclusion
Adaptive RAG systems improve AI retrieval by adjusting to query complexity. By using LangChain for data connections and LangGraph for structured query routing, these systems refine retrieval depth, reduce computation costs, and improve response accuracy. Adaptive RAG ensures AI delivers relevant, efficient, and context-aware insights in industries requiring precision.