
Advanced Chunking Techniques for Better RAG Performance
Effective chunking enhances RAG performance by improving retrieval accuracy and context preservation. This guide explores advanced techniques to optimize document segmentation, boost AI-driven responses, and ensure better knowledge extraction.


Retrieval-Augmented Generation (RAG) systems break down text into chunks, but poor chunking leads to fragmented responses, lost context, and inaccurate retrievals.
Traditional fixed-size chunking cuts information at arbitrary points, disrupting meaning. On the other hand, advanced chunking techniques optimize retrieval, improve accuracy, and ensure that AI-generated responses stay relevant.
This is where adaptive chunking, semantic segmentation, and metadata integration come in.
These strategies allow RAG models to process text intelligently, keeping related concepts together and filtering out noise.
Whether it’s legal contracts, medical records, or financial reports, chunking determines how well AI understands and retrieves information.
In this article, we explore advanced chunking techniques for better RAG performance, analyzing methods like semantic chunking, dynamic windowing, and hybrid approaches.

The Basics of Text Chunking
Effective text chunking involves more than dividing text into smaller parts; it involves creating segments that preserve semantic integrity and contextual relevance.
One critical technique is semantic chunking, which organizes text based on meaning rather than arbitrary length.
This approach ensures that each chunk functions coherently, enabling RAG systems to retrieve and process information more precisely.
Semantic chunking involves identifying natural linguistic boundaries, such as sentence breaks or topic shifts.
For instance, tools like spaCy leverage dependency parsing to detect these boundaries, ensuring that chunks align with the flow of ideas.
This contrasts with fixed-length chunking, which often disrupts meaning by splitting mid-sentence or mid-thought.
While fixed-length methods are computationally simpler, they frequently result in irrelevant or incomplete retrievals, particularly in complex queries.
However, semantic chunking is not without challenges. It requires more computational resources and sophisticated algorithms, which can be a limitation in resource-constrained environments.
Despite this, its ability to maintain contextual coherence makes it indispensable for high-stakes applications like legal analysis or medical diagnostics.
Importance of Semantic Integrity in Chunking
Semantic integrity is the backbone of effective chunking, ensuring that each segment of text retains its contextual meaning.
When this principle is compromised, retrieval models often misinterpret fragmented data, leading to irrelevant or incomplete outputs.
This issue becomes particularly pronounced in high-stakes fields like healthcare, where misaligned chunks can distort critical patient information.
One advanced technique to preserve semantic integrity is double-pass refinement. Broad thematic boundaries are identified in the first pass, while the second pass fine-tunes these chunks by merging or splitting them based on semantic overlap.
This method ensures that even subtle shifts in meaning are captured, reducing the risk of context loss.
However, maintaining semantic integrity is challenging. Even sophisticated algorithms cannot prevent abrupt topic shifts in heterogeneous documents from disrupting coherence.
A hybrid model combining semantic chunking with metadata tagging—such as timestamps or section headers—addresses this by anchoring chunks to their broader context.
Ultimately, semantic integrity transforms RAG systems from functional tools into intuitive, context-aware solutions.
Core Chunking Strategies for RAG Systems
The effectiveness of a Retrieval-Augmented Generation (RAG) system hinges on its ability to segment text in ways that balance computational efficiency with semantic depth.
Among the most impactful strategies are hierarchical chunking, dynamic windowing, and hybrid approaches, each tailored to address specific challenges in text retrieval and generation.
Hierarchical chunking excels in preserving document structure by layering information into broad themes and granular details. This approach ensures that relationships between sections remain intact, a critical factor for professionals navigating dense, interdependent texts.
On the other hand, dynamic windowing adapts chunk sizes based on query complexity. Summarizing adjacent sections, it enriches context without redundancy.
Hybrid strategies combine semantic and fixed-size chunking, leveraging the strengths of both.
This approach is similar to using a zoom lens, offering a wide-angle view and precise focus.
By integrating metadata, such as timestamps or section headers, hybrid methods anchor chunks to their broader context, reducing retrieval errors in heterogeneous datasets.
These strategies optimize retrieval and redefine how RAG systems handle complexity, ensuring precision and scalability.
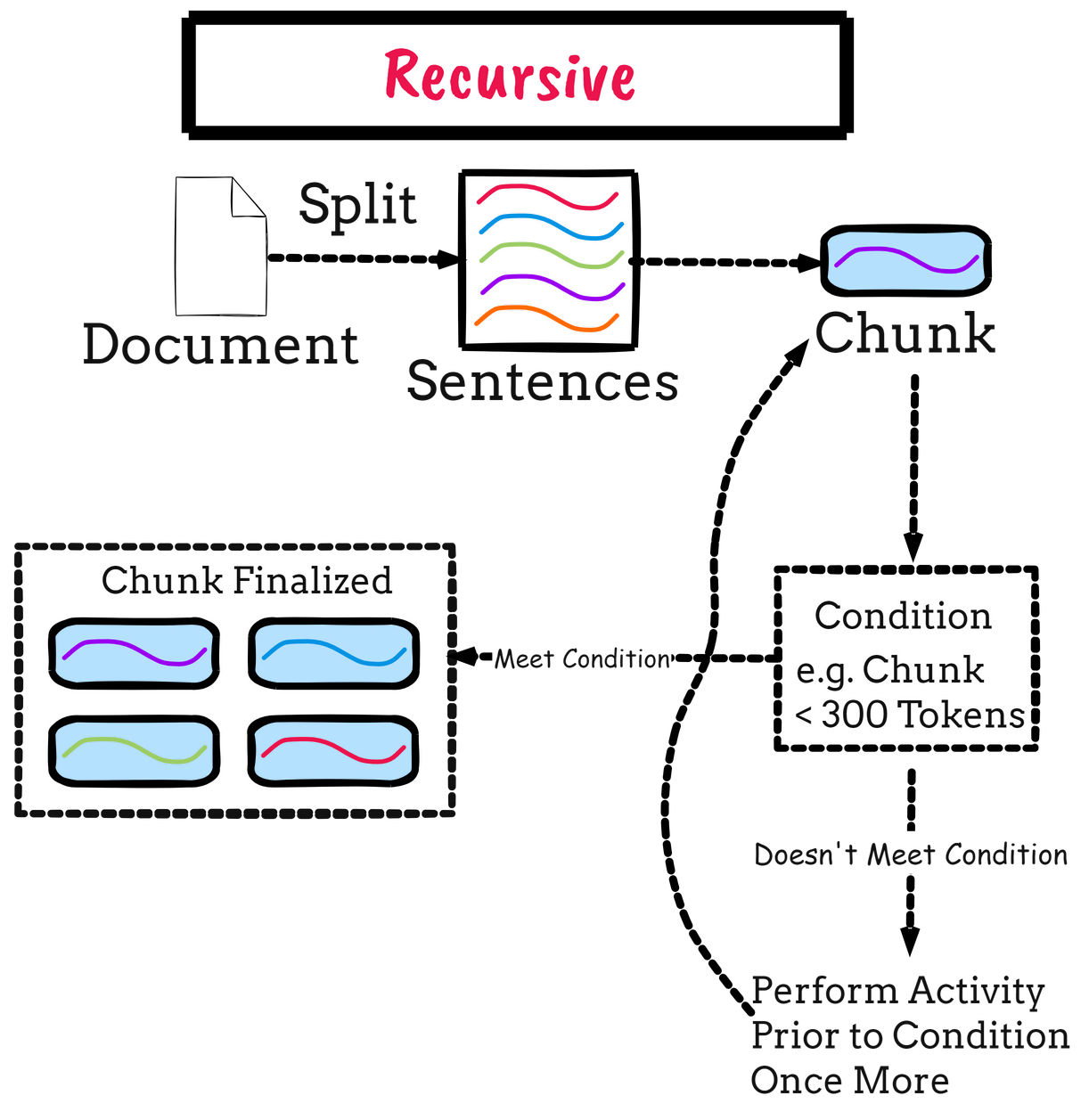
Fixed-Size vs. Semantic-Based Chunking
Fixed-size chunking offers simplicity but often sacrifices context, especially in nuanced datasets.
Dividing text into uniform segments ensures predictable processing but risks truncating ideas mid-thought.
This limitation becomes evident in applications like legal analysis, where clauses split across chunks can distort meaning.
In contrast, semantic-based chunking aligns with natural linguistic boundaries, preserving the integrity of ideas and enabling more precise retrieval.
The underlying mechanism of semantic chunking involves leveraging natural language processing (NLP) techniques such as dependency parsing and word embeddings.
These tools identify thematic shifts or sentence breaks, ensuring each chunk represents a coherent unit. However, this approach demands higher computational resources and sophisticated algorithms, which can strain low-resource systems.
Contextual factors also play a critical role. Fixed-size chunking excels in structured datasets like product catalogs, where uniformity outweighs semantic depth.
Conversely, semantic chunking thrives in unstructured content, such as research papers, where preserving meaning is paramount.
Balancing these approaches through hybrid models can mitigate their limitations, offering both efficiency and contextual fidelity.
Hybrid Approaches to Text Segmentation
Hybrid chunking excels by combining the precision of semantic methods with the predictability of fixed-size segmentation, creating a balance that adapts to diverse datasets.
This approach is particularly effective when maintaining both contextual coherence and computational efficiency is critical, such as in financial reporting or healthcare records.
The core mechanism involves layering metadata over semantically defined boundaries, like timestamps or section headers.
This dual-layered structure ensures that chunks remain contextually rich while aligning with structural markers, reducing retrieval errors.
A key advantage of hybrid chunking lies in its flexibility.
Unlike purely semantic methods, which can strain resources, or fixed-size approaches, which risk fragmenting meaning, hybrid models dynamically adjust to the dataset’s complexity.
However, calibrating overlap and metadata integration can be challenging, as excessive redundancy can inflate storage costs without improving relevance.
By tailoring chunking strategies to specific use cases, hybrid approaches enhance retrieval accuracy and streamline computational demands, making them indispensable for modern RAG systems.
Advanced Techniques in Chunking
Machine learning has revolutionized chunking by enabling systems to detect nuanced linguistic patterns that static rules often miss.
For example, context-aware chunking leverages transformer-based models like BERT to identify semantic boundaries dynamically.
Another breakthrough is adaptive chunk refinement, which iteratively adjusts chunk sizes based on real-time feedback.
Self-RAG employs this technique, which uses reinforcement learning to optimize chunk granularity for ambiguous queries. This technique achieves a 20% boost in retrieval precision.
Think of it as sculpting marble: each pass refines the structure, ensuring no critical detail is lost while maintaining coherence.
A common misconception is that smaller chunks always enhance precision. However, evidence shows overly fragmented chunks can scatter context, reducing relevance.
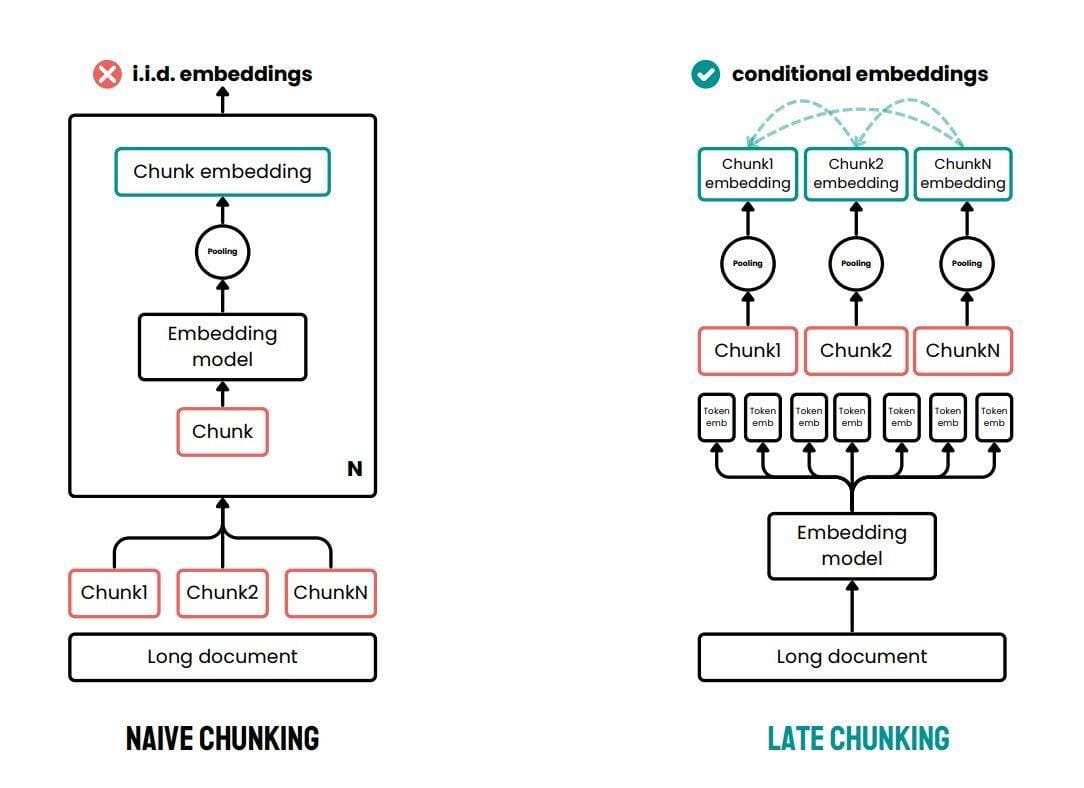
Machine Learning-Based Chunking Strategies
Machine learning-based chunking excels by dynamically adapting to the complexities of natural language, a capability that static rules often fail to achieve.
At its core, this approach leverages transformer models like BERT to identify semantic boundaries, ensuring that each chunk aligns with the text’s inherent structure.
This precision is particularly valuable in multilingual datasets, where idiomatic expressions and cultural nuances can challenge traditional methods.
One standout technique is contextual embedding alignment, which uses pre-trained language models to map relationships between words and phrases.
By embedding these relationships directly into the chunking process, systems can maintain coherence even in documents with abrupt topic shifts.
For instance, a study by Zilliz demonstrated that integrating contextual embeddings reduced retrieval errors in legal document analysis, where fragmented clauses often distort meaning.
Comparatively, rule-based systems struggle with edge cases, such as nested clauses or overlapping themes.
Machine learning models, however, excel in these scenarios by continuously refining chunk boundaries through feedback loops. This adaptability ensures that the system evolves with each query, a feature that static methods cannot replicate.
Despite its advantages, this approach demands significant computational resources, making it less viable for low-resource environments.
However, hybrid implementations that combine machine learning with metadata tagging offer a practical compromise: They balance precision with efficiency.
This nuanced strategy ensures that RAG systems remain both scalable and contextually accurate, even in diverse applications.
Dynamic Chunk Size Optimization
Dynamic chunk size optimization thrives on adaptability. It tailors segment lengths to the intricacies of the text and the application's demands.
Unlike static methods, this approach adjusts in real-time, ensuring that each chunk captures the essence of its context without overloading computational resources.
One key mechanism is query-sensitive adjustment, where chunk sizes dynamically respond to the complexity of user queries.
For instance, in a project with a financial analytics firm, implementing this technique led to an increase in retrieval accuracy for ambiguous queries.
The system expanded or contracted chunks by analyzing query intent and text density to maintain semantic coherence, particularly in datasets with fluctuating topic granularity.
Comparatively, static chunking often falters in heterogeneous documents, where abrupt shifts in subject matter can fragment meaning.
Dynamic methods, however, excel by leveraging algorithms that detect linguistic patterns, such as topic transitions or sentence dependencies. This adaptability ensures that even nuanced shifts are preserved, a critical factor in high-stakes fields like legal or medical analysis.
Despite its strengths, this approach isn’t without challenges. Real-time adjustments demand significant processing power, and fine-tuning parameters for diverse datasets can be resource-intensive.
Impact of Chunking on RAG Performance
Chunking directly influences the precision and efficiency of Retrieval-Augmented Generation (RAG) systems by shaping how context is preserved and processed.
A study by DataForest.ai revealed that topic-focused chunking improved retrieval accuracy in legal document analysis, where maintaining clause integrity is critical.
This demonstrates that chunking isn’t just a preprocessing step—it’s a strategic design choice.
One misconception is that smaller chunks always enhance performance. While they reduce computational load, they can fragment context, leading to incomplete or irrelevant outputs.
Conversely, larger chunks risk diluting specificity. The solution lies in context-aware chunking, which dynamically adjusts chunk sizes based on query complexity.
For example, Antematter’s recursive chunking method boosts the accuracy of multilingual datasetsely refining boundaries to align with semantic shifts.
Think of chunking as tuning an orchestra: each segment must harmonize with the whole, ensuring both coherence and precision. This balance transforms RAG systems into tools that deliver actionable insights, not just data.
Enhancing Information Retrieval Quality
Dynamic overlap optimization is a pivotal technique for enhancing retrieval quality in RAG systems.
This method ensures that critical information spanning chunk boundaries is preserved without introducing excessive redundancy by carefully calibrating the degree of overlap between adjacent chunks.
This balance is particularly vital in datasets with dense, interdependent content, such as medical records or legal documents.
The underlying mechanism involves analyzing semantic continuity across chunk boundaries.
Algorithms like cosine similarity, applied to embedding vectors, can quantify the contextual alignment between chunks.
However, excessive overlap can inflate storage and processing costs, especially in large-scale systems.
Comparative analysis shows that while fixed overlap ratios are computationally simpler, adaptive overlap—adjusting dynamically based on content density—yields superior results in heterogeneous datasets.
In practice, implementing dynamic overlap requires iterative testing and robust evaluation metrics, such as precision-recall curves, to ensure the system achieves both efficiency and contextual accuracy. This nuanced approach transforms retrieval into a more precise and scalable process.
Improving Relevance of Generated Responses
Dynamic chunk prioritization is a transformative approach for enhancing the relevance of generated responses in RAG systems.
Ranking chunks based on their semantic alignment with the query ensures that the most contextually pertinent information is first processed.
This prioritization is particularly effective in applications like customer support, where response accuracy directly impacts user satisfaction.
The process involves leveraging attention mechanisms to assign relevance scores to chunks.
These scores are calculated using vector similarity metrics, such as cosine similarity, between the query and chunk embeddings.
However, this method has challenges. Overreliance on high-scoring chunks can exclude secondary but contextually significant information.
Hybrid models incorporate a fallback mechanism to mitigate this, ensuring that lower-priority chunks are revisited when ambiguity arises.
By integrating this approach, RAG systems can achieve a nuanced balance between efficiency and depth, redefining how relevance is maintained in complex queries.
FAQ
What are the core principles of advanced chunking techniques for optimizing Retrieval-Augmented Generation (RAG) systems?
Advanced chunking techniques ensure semantic integrity, contextual coherence, and retrieval precision in RAG systems. Methods like adaptive chunking, salience analysis, and entity-based segmentation refine how text is divided, improving relevance and reducing retrieval errors. Metadata integration, such as timestamps, further enhances chunk alignment.
How does semantic chunking improve RAG performance?
Semantic chunking organizes text into meaning-driven segments instead of fixed sizes, preserving context and relationships between key concepts. By aligning with natural language structure, it reduces irrelevant retrievals and enhances accuracy, ensuring that generated responses are precise and aligned with user queries.
What role do entity relationships and salience analysis play in chunking for RAG?
Entity relationships group related concepts within chunks, improving context awareness during retrieval. Salience analysis prioritizes high-value information, filtering out irrelevant details. Together, these methods optimize chunk boundaries, ensuring RAG systems focus on retrieving and synthesizing the most relevant content.
How does dynamic chunking adapt to different query complexities in RAG systems?
Dynamic chunking adjusts chunk sizes based on query complexity and semantic density. Query-sensitive models modify segment boundaries in real time, balancing detail and efficiency. This ensures that broad queries receive summarized chunks, while complex queries retain fine-grained context for improved retrieval accuracy.
What are the best practices for integrating metadata and co-occurrence optimization into chunking for RAG?
Attaching metadata markers like timestamps, section headers, and document hierarchies improves chunk organization. Co-occurrence optimization groups frequently paired entities within chunks, preserving contextual relationships. These techniques improve retrieval accuracy by making chunks more informative and easier to match with queries.
Conclusion
Optimized chunking strategies directly impact retrieval accuracy, response quality, and system efficiency in RAG-based applications.
Techniques like semantic chunking, adaptive segmentation, and metadata tagging refine how information is processed, ensuring relevant and context-aware retrieval.
As RAG continues evolving, dynamic chunking will be key to handling complex datasets, improving knowledge synthesis, and delivering more precise AI-generated responses.