
Advanced RAG Techniques You Should Know About
Explore key advanced RAG techniques that enhance AI efficiency, improve retrieval accuracy, and reduce costs. Learn how adaptive reasoning, real-time data retrieval, and scalable AI infrastructure are shaping the future, making intelligent systems more accessible and effective



In a world where AI systems are expected to deliver instant, accurate, and context-rich responses, the traditional methods of information retrieval are quietly falling short.
Did you know that even the most advanced generative models can produce irrelevant or outdated answers if the retrieval process feeding them isn’t optimized? This gap between retrieval and generation is where Advanced RAG (Retrieval-Augmented Generation) techniques come into play, offering a game-changing solution.
As businesses grapple with ever-growing data volumes and increasingly complex queries, the stakes couldn’t be higher. Whether it’s powering real-time customer support, navigating compliance in regulated industries, or enabling smarter decision-making, the ability to retrieve and generate precise information is no longer optional—it’s essential.
But how do you ensure your RAG system doesn’t just work but excels? This article dives into the cutting-edge strategies that are redefining what’s possible in AI-driven retrieval and generation.
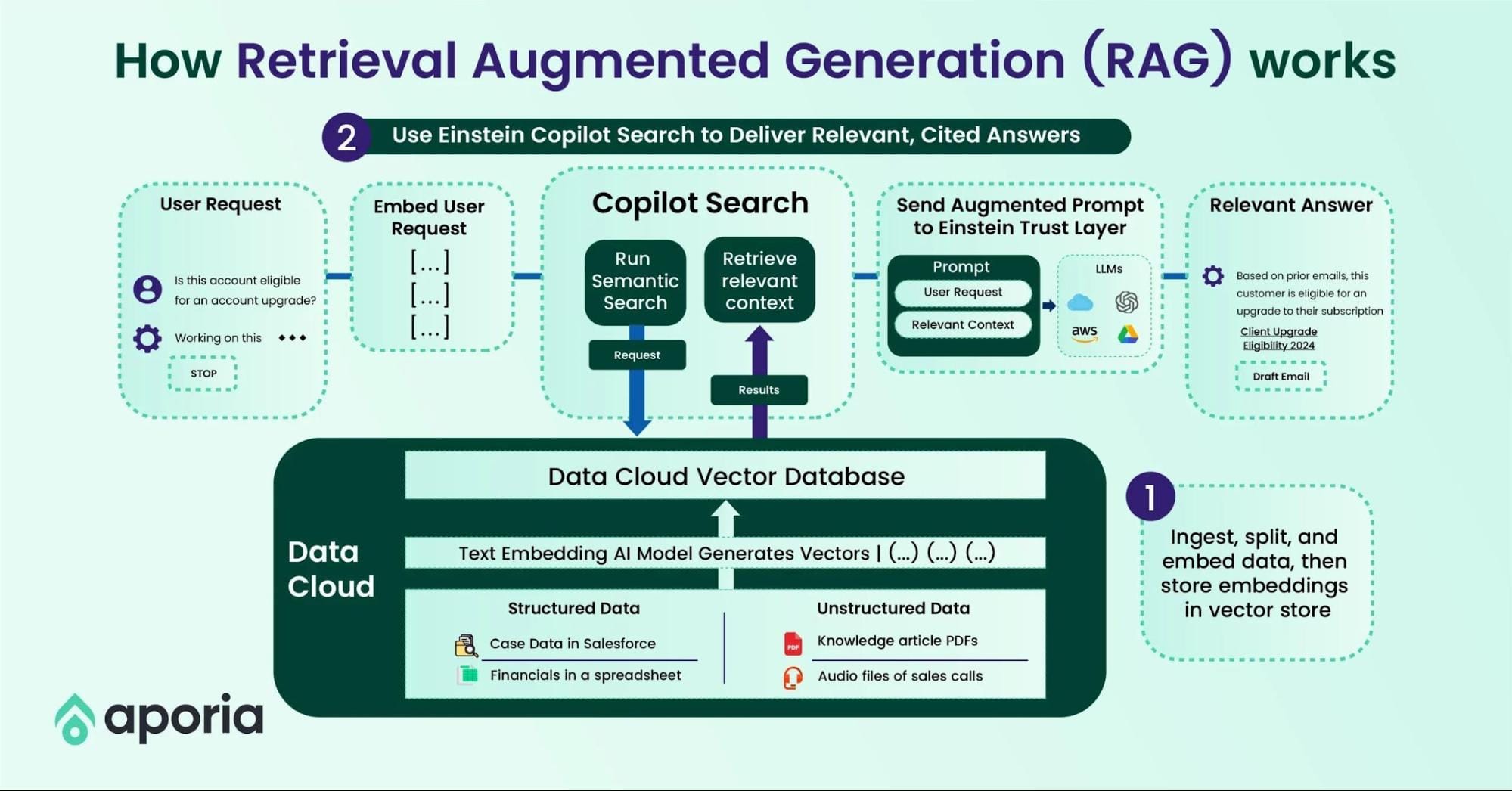
Understanding Retrieval-Augmented Generation
One of the most fascinating aspects of Retrieval-Augmented Generation (RAG) is its ability to dynamically integrate external knowledge into generative processes, effectively bridging the gap between static training data and real-time information needs.
Unlike traditional generative models that rely solely on pre-trained knowledge, RAG systems leverage dense retrieval techniques to map queries directly to relevant data sources, such as vector stores or knowledge graphs. This ensures that the generated output is not only contextually rich but also factually grounded.
For instance, in customer support, a RAG-powered chatbot can pull up-to-date product details from a database, providing accurate answers even as inventory or policies change. However, the success of this approach hinges on the quality of the retrieval mechanism.
Factors like dataset curation, indexing strategies, and retrieval latency can significantly influence outcomes.
The Evolution of RAG in Natural Language Processing
A pivotal shift in RAG’s evolution has been the integration of multimodal capabilities, enabling systems to process and generate responses across text, images, and even audio.
This advancement addresses the growing demand for AI systems that can handle diverse data types, such as combining textual instructions with visual data for tasks like medical imaging analysis or e-commerce recommendations.
The key to this evolution lies in cross-modal retrieval mechanisms, where models retrieve relevant information from multiple modalities and synthesize it into coherent outputs. For example, in healthcare, a RAG system can retrieve patient records (text) and diagnostic images to assist doctors in making informed decisions.
However, challenges like aligning representations across modalities and ensuring retrieval relevance remain critical. Future innovations, such as contrastive learning techniques, could enhance cross-modal alignment, paving the way for RAG systems to redefine how industries leverage AI for complex, multimodal tasks.
Core Concepts of Retrieval-Augmented Generation
Retrieval-Augmented Generation (RAG) combines retrieval systems and large language models (LLMs) to create responses that are both accurate and contextually rich.
A standout feature is the use of vector embeddings, which numerically represent text for efficient similarity searches. For example, a customer support bot can retrieve precise troubleshooting steps from a database, even if the user’s query is phrased differently.
A common misconception is that RAG relies solely on retrieval. In reality, prompt engineering plays a critical role in guiding the LLM to synthesize retrieved data effectively.
Unexpectedly, RAG’s potential extends beyond text—multimodal applications, like pairing product descriptions with images, are transforming industries like e-commerce. As RAG evolves, its adaptability across domains will only deepen its impact.
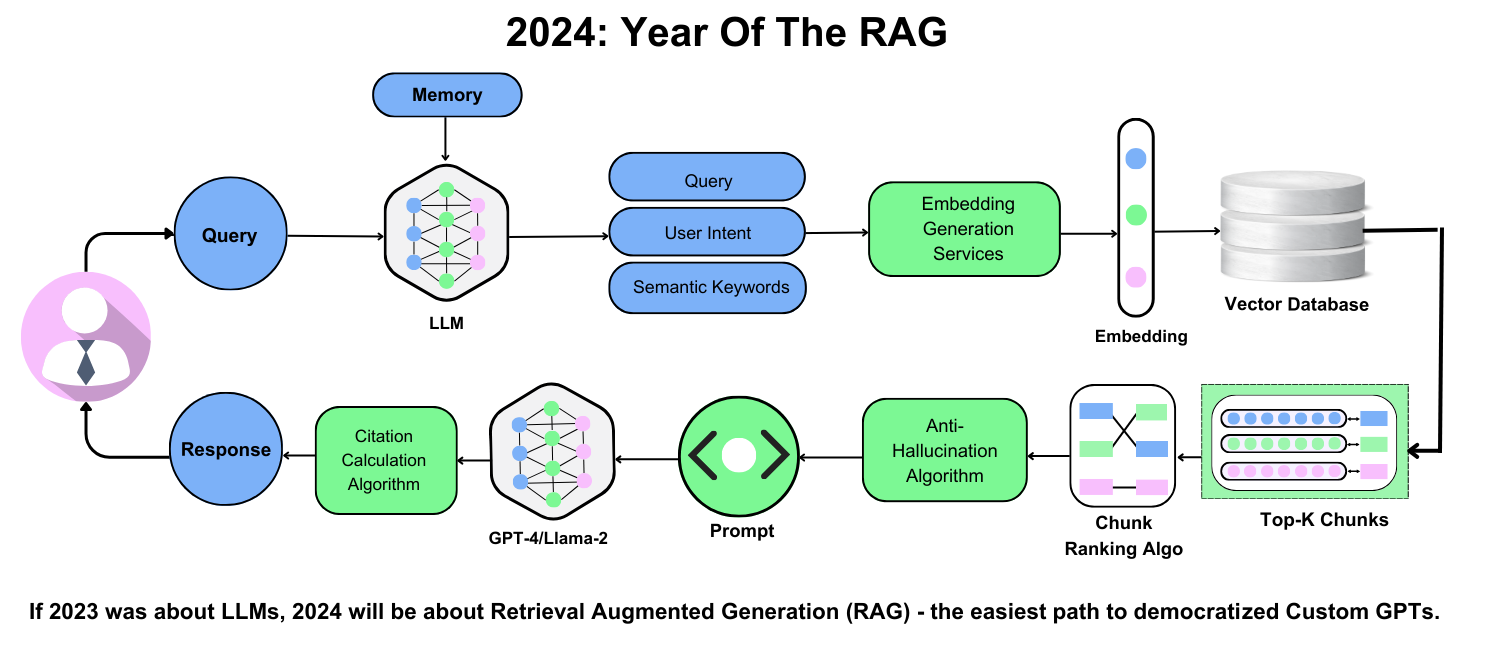
Anatomy of RAG Models
A critical yet often overlooked component of RAG models is the fusion module, which seamlessly integrates retrieved data with the language model’s generative process. This step is where the magic happens—turning raw, retrieved snippets into coherent, contextually relevant outputs.
The fusion process can vary. Some models use concatenation, simply appending retrieved data to the input prompt. Others employ attention mechanisms, allowing the model to weigh the importance of each retrieved piece dynamically. For instance, in legal tech, a RAG model might prioritize case law over general statutes when drafting legal arguments.
Interestingly, the quality of fusion directly impacts output accuracy. Poorly aligned retrieval can lead to irrelevant or contradictory responses. Emerging techniques, like reinforcement learning, are refining this process by optimizing how models select and integrate data.
Advantages Over Traditional Generation Models
One standout advantage of RAG models is their ability to dynamically incorporate real-time data, addressing the limitations of static training in traditional generative models. Unlike conventional systems that rely solely on pre-trained knowledge, RAG retrieves up-to-date information, ensuring responses remain relevant even in rapidly changing fields like finance or healthcare.
For example, in medical diagnostics, a RAG model can pull the latest research on treatment protocols, offering insights that a traditional model—trained months or years earlier—might miss. This adaptability is particularly valuable in industries where accuracy and timeliness are critical.
Retrieval diversity enhances output quality by sourcing information from multiple perspectives, reducing the risk of bias.
To maximize this advantage, organizations should focus on curating diverse, high-quality datasets for retrieval. Future innovations in retrieval algorithms could further refine this process, making RAG indispensable for knowledge-intensive applications.
Advanced Retrieval Techniques in RAG
Advanced retrieval techniques in RAG go beyond simple keyword matching, leveraging hybrid search models that combine vector-based retrieval with traditional keyword searches. This dual approach ensures both contextual understanding and precision, making it ideal for complex queries.
A surprising yet impactful technique is semantic chunking, where documents are divided into meaningful sections. This preserves context and reduces noise, ensuring the retrieval system focuses on the most relevant data. For example, in customer support, chunking FAQs into thematic sections improves response accuracy.
Another game-changer is intelligent re-ranking, which prioritizes retrieved results based on relevance scores. By integrating user feedback loops, systems can continuously refine these rankings, much like a personalized recommendation engine.
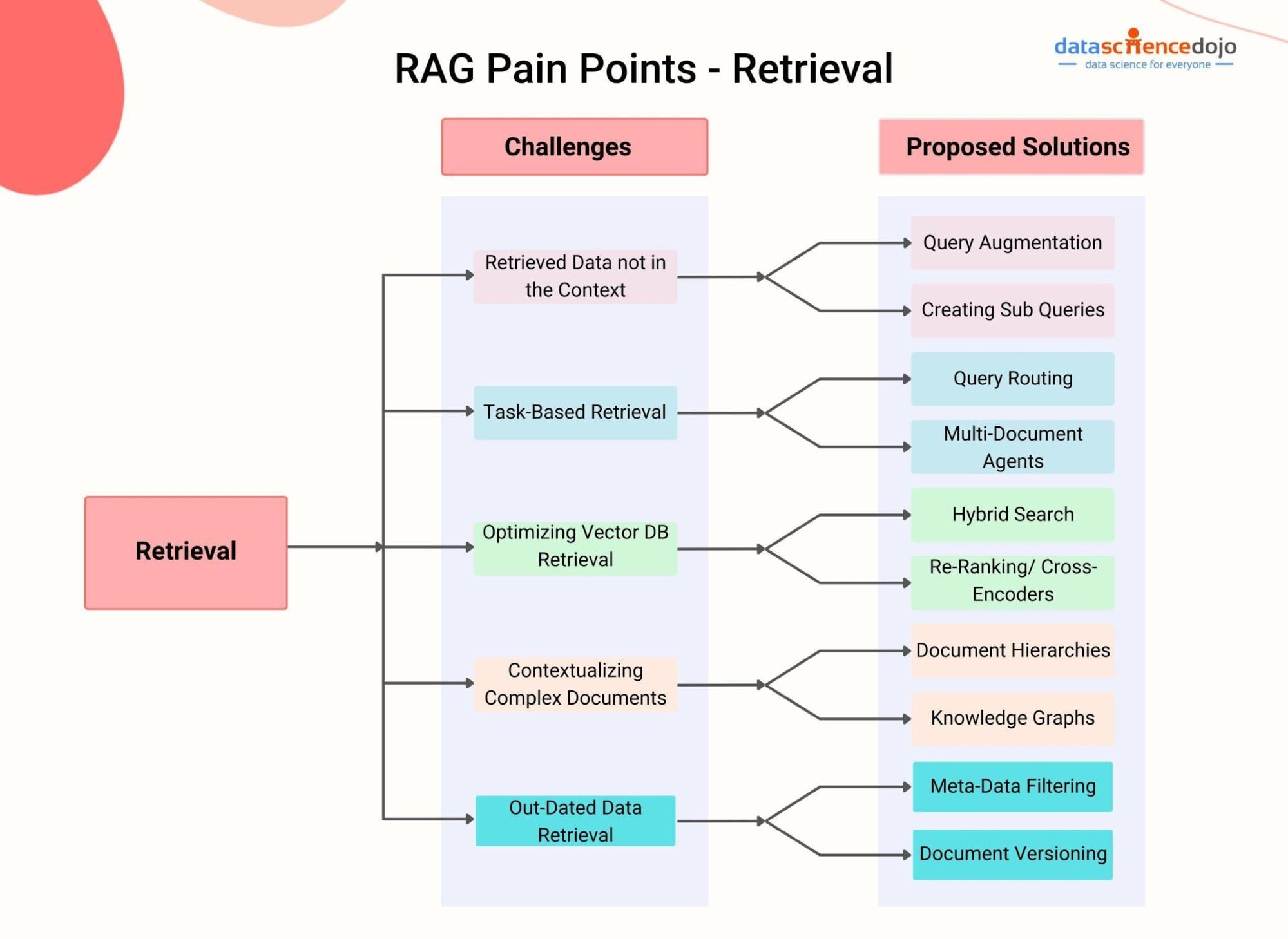
State-of-the-Art Retrieval Algorithms
Modern retrieval algorithms in RAG are redefining efficiency and accuracy by leveraging vector-based retrieval systems like FAISS and Pinecone. These systems excel at mapping queries and documents into high-dimensional spaces, enabling lightning-fast similarity searches.
A standout innovation is contextual re-ranking, where algorithms dynamically adjust rankings based on user intent. This approach, often powered by transformer models, ensures that retrieved results align with nuanced query contexts.
Interestingly, graph-based retrieval is emerging as a game-changer. By structuring data into knowledge graphs, systems can perform multi-hop reasoning, uncovering relationships across disparate datasets. This is particularly impactful in fraud detection, where uncovering hidden connections is critical.
Efficient Indexing and Search Strategies
A critical yet underexplored aspect of indexing is dimensionality reduction in vector embeddings. By reducing the number of dimensions, systems can significantly improve search speed without sacrificing much accuracy. Techniques like Principal Component Analysis (PCA) or t-SNE are particularly effective here. For instance, in real-time recommendation systems, this approach ensures faster retrieval of relevant items, enhancing user experience.
Another game-changer is dynamic indexing, where indices are updated incrementally rather than rebuilt entirely. This is invaluable in news aggregation platforms, where new articles are constantly added, and outdated ones are removed. Dynamic indexing ensures the system remains responsive without downtime.
Index clustering also plays a crucial role in optimizing searches. By grouping similar vectors into clusters, it narrows search scope, significantly reducing computational overhead while improving retrieval efficiency. This technique is especially useful in large-scale genomic research, where datasets are massive and highly complex.
Leveraging External Knowledge Bases
A standout approach in leveraging external knowledge bases is metadata-driven filtering. By tagging data with rich metadata—such as timestamps, categories, or user-specific preferences—retrieval systems can dramatically improve relevance.
Another powerful technique is query expansion, where user queries are enriched with synonyms or related terms derived from the knowledge base. This is particularly effective in healthcare applications, where medical terminology varies widely. For instance, a query for “heart attack” could also retrieve results for “myocardial infarction,” ensuring comprehensive coverage.
The quality of knowledge base curation is also critical. Poorly curated sources can introduce bias or inaccuracies, compromising the system’s reliability. Organizations should conduct regular audits and implement bias mitigation strategies to ensure data integrity.
Dynamic and Contextual Retrieval Methods
A key innovation in dynamic retrieval is contextual re-ranking, where retrieved results are dynamically adjusted based on user intent or query evolution. This approach excels in e-commerce platforms, where user preferences shift during a session. For instance, a user searching for “laptops” might prioritize gaming features after viewing specific products. Contextual re-ranking ensures the system adapts in real-time, offering more relevant results.
Another impactful method is sentence window retrieval, which embeds individual sentences for precise context matching. This technique is invaluable in academic research, where nuanced queries require pinpoint accuracy. By retrieving sentence-level data, systems avoid overwhelming users with irrelevant information.
A key challenge is query drift, where iterative refinements unintentionally shift from the original intent. To counter this, organizations should implement feedback loops that validate user satisfaction and ensure alignment with intended queries.
Enhancing Generation with Advanced Methods
Advanced generation techniques in RAG focus on contextual coherence and precision, ensuring outputs are not only accurate but also engaging. One standout method is attention-based fusion, where retrieved data is weighted dynamically based on its relevance to the query. For example, in legal document drafting, this ensures that critical precedents are emphasized while less relevant cases are deprioritized.
Another innovation is auto-merging retrieved snippets, which synthesizes overlapping information into a unified narrative. This is particularly effective in healthcare applications, where patient histories and medical guidelines must be seamlessly integrated for actionable insights.
A common misconception is that larger models inherently improve generation quality. However, evidence shows that fine-tuning on domain-specific data often yields better results. For instance, a biotech firm fine-tuning a model on clinical trial data achieved a 30% improvement in response relevance.
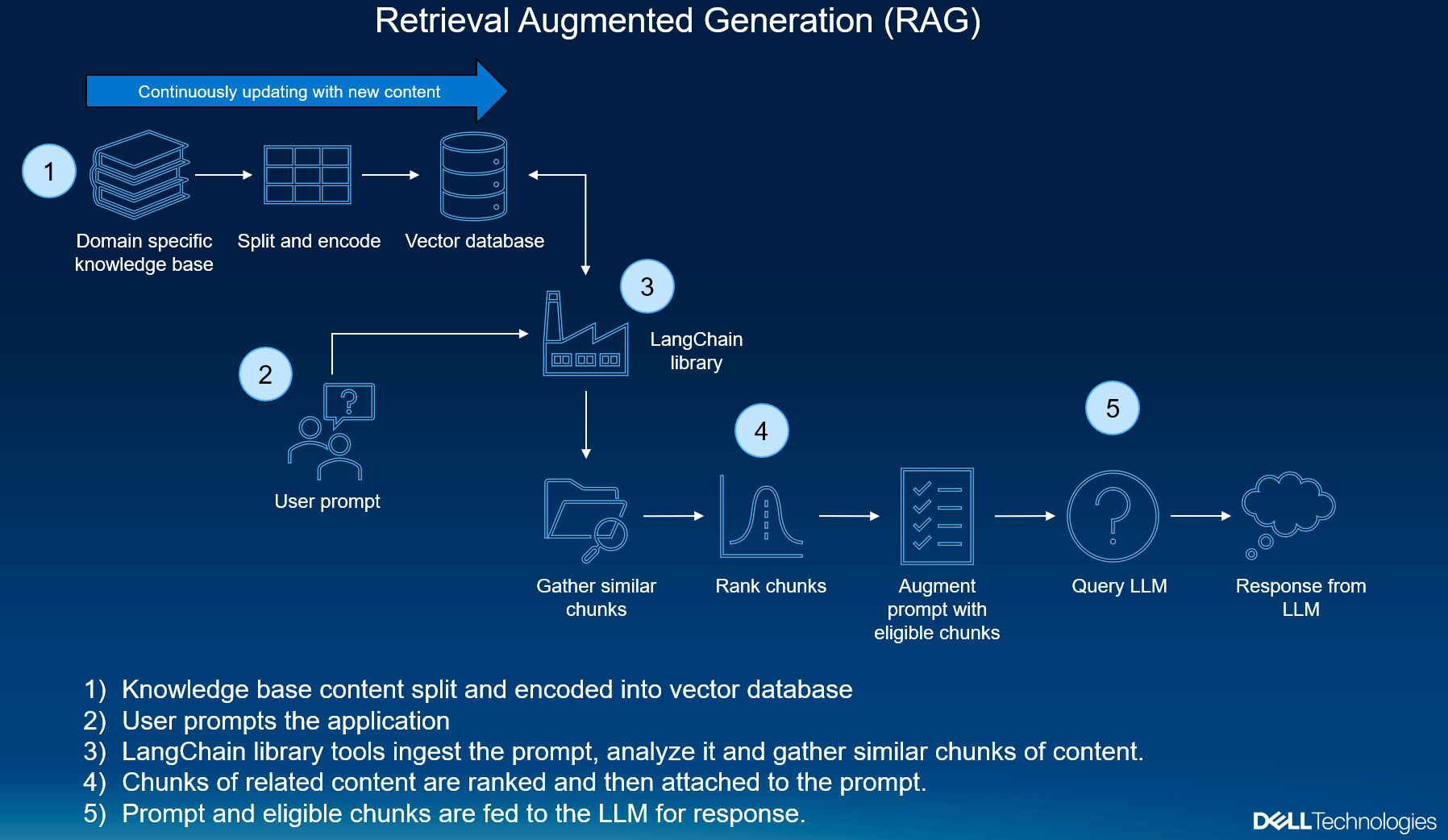
Integrating Multi-Hop Reasoning
Multi-hop reasoning transforms RAG systems by enabling them to connect disparate pieces of information across multiple sources. A critical approach is decomposing complex queries into smaller, manageable sub-questions, which are then solved iteratively. For instance, in supply chain optimization, a query like “What’s the best shipping route considering weather and costs?” can be broken into sub-queries addressing weather forecasts and cost analysis separately, before synthesizing the results.
Interestingly, graph-based retrieval plays a pivotal role here, mapping relationships between entities to uncover hidden connections. This technique has shown remarkable success in scientific research, where linking studies across disciplines often leads to groundbreaking insights.
Conventional wisdom suggests that more hops equal better reasoning, but studies reveal diminishing returns beyond three hops due to information noise. To counter this, probability maximization methods prioritize the most relevant paths, ensuring clarity.
Handling Ambiguity and Uncertainty in Responses
A powerful way to tackle ambiguity in RAG systems is through probabilistic reasoning, which assigns confidence scores to retrieved data. This ensures that responses are ranked by reliability, reducing the risk of presenting uncertain information. For example, in financial advisory tools, ambiguous queries like “What’s the best investment now?” can be clarified by surfacing options with confidence levels, guiding users toward informed decisions.
Contextual disambiguation is another game-changer. By analyzing prior interactions or related queries, RAG systems can infer user intent more accurately. This is particularly effective in customer support, where vague questions like “Why isn’t this working?” can be resolved by referencing past troubleshooting steps.
Conventional systems often ignore user feedback loops, but incorporating them can refine responses over time. Future systems could leverage adaptive learning frameworks, dynamically adjusting to user preferences and evolving contexts, ensuring more precise and user-aligned outputs.
Personalization and User Adaptation Techniques
One standout approach in personalization is dynamic user profiling, where RAG systems continuously update user models based on real-time interactions. This technique excels in e-learning platforms.
Unlike static personalization, this method allows systems to recall and apply past interactions dynamically. For instance, in healthcare applications, RAG systems can retrieve and adapt recommendations based on a patient’s evolving medical history, ensuring relevance and accuracy.
Conventional wisdom often overlooks the role of micro-preferences—subtle user behaviors like scrolling speed or time spent on specific content. Incorporating these signals into adaptive algorithms can significantly enhance personalization. Future advancements could integrate neuroadaptive interfaces, responding to cognitive states for even deeper customization.
Implementing Advanced RAG Models in Practice
To implement advanced RAG models effectively, hybrid retrieval techniques are key. Combining vector-based and keyword searches ensures nuanced query handling. For example, in legal research platforms, hybrid methods retrieve both precise case law references and broader contextual documents, improving accuracy and relevance.
A common misconception is that scaling model size guarantees better performance. Instead, domain-specific fine-tuning often yields superior results. In healthcare, fine-tuned RAG models trained on medical ontologies outperform generic models by delivering precise, actionable insights.
Unexpectedly, multi-modal RAG systems are transforming industries like e-commerce. By integrating text, images, and user reviews, these systems provide personalized product recommendations, bridging the gap between static catalogs and dynamic user needs.
Expert perspectives emphasize the importance of feedback loops. Continuous user input refines retrieval and generation, much like a chef adjusting a recipe based on diner preferences. Future advancements may focus on adaptive learning, enabling RAG systems to evolve alongside user expectations.
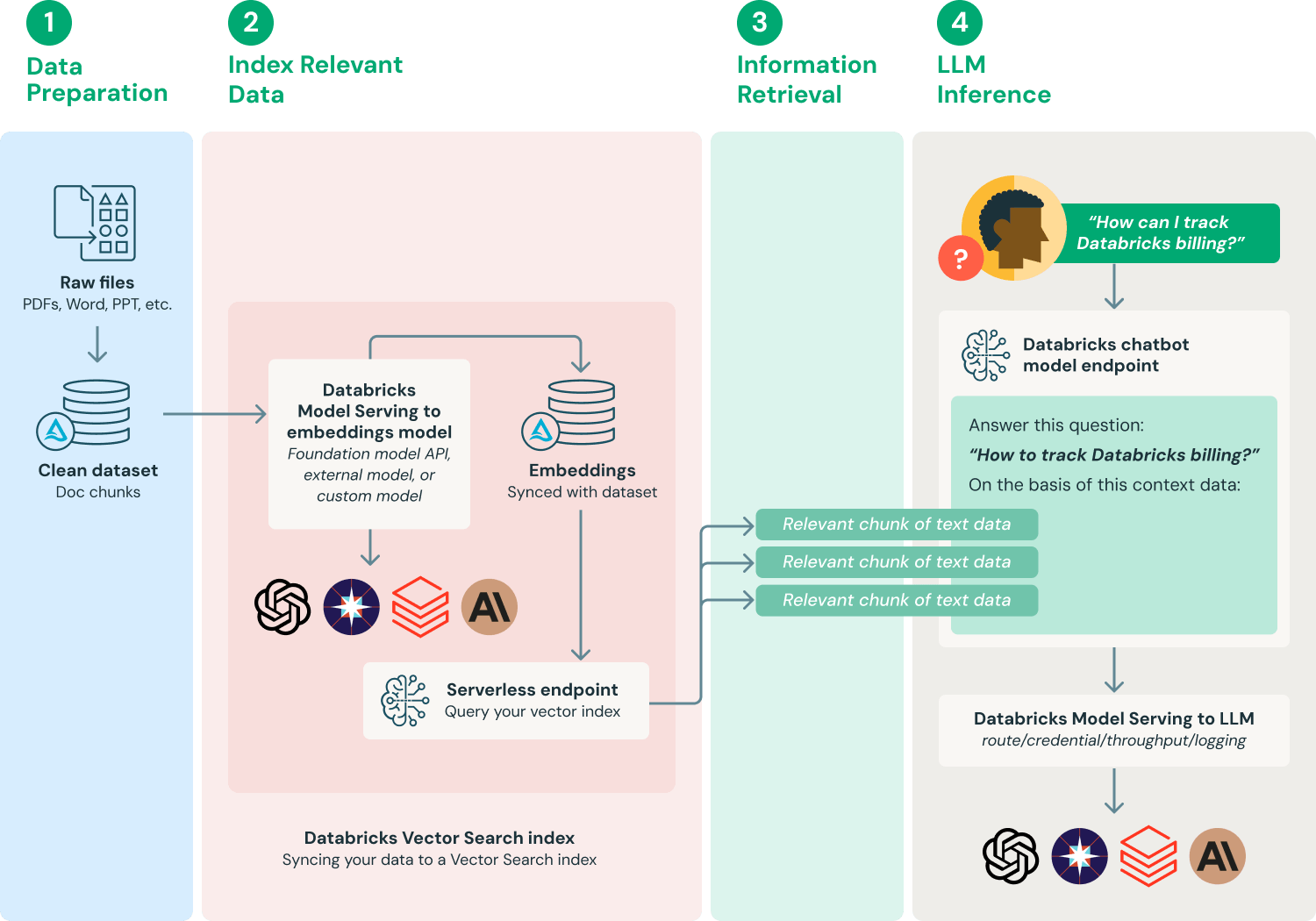
Tools and Frameworks for Advanced RAG
One standout tool for advanced RAG systems is LangChain, a framework designed to seamlessly integrate large language models (LLMs) with external data sources. Its modular design supports document indexing, query optimization, and multi-step retrieval, making it ideal for scalable, domain-specific RAG applications.
A key feature is its vector database integration, which enhances retrieval precision using semantic embeddings. This approach surpasses traditional keyword searches, particularly in fields like healthcare, where a nuanced understanding of medical terminology is crucial.
Conventional wisdom often overlooks the importance of workflow orchestration. LangChain’s ability to chain retrieval, reasoning, and generation steps ensures coherent, contextually relevant outputs, even for complex queries.
Best Practices and Optimization Strategies
A critical yet underappreciated optimization strategy in RAG systems is iterative retrieval-generation loops. This approach refines results by feeding generated outputs back into the retrieval process, enabling the system to handle multi-hop reasoning and complex queries more effectively.
Why does this work? It aligns retrieval with the evolving context of the query, ensuring that each iteration builds on the last. This is particularly effective when combined with chain-of-thought prompting, which guides the model to break down complex problems into smaller, manageable steps.
Conventional wisdom often prioritizes static retrieval pipelines, but evidence shows that dynamic, iterative methods significantly improve accuracy. To implement this, focus on feedback mechanisms and adaptive query reformulation. Future advancements could integrate real-time user feedback, making RAG systems even more responsive and context-aware.
Cross-Domain Applications of RAG
RAG’s versatility shines in cross-domain applications, where it seamlessly integrates knowledge from diverse fields to solve complex problems. For example, in climate science, RAG systems can combine meteorological data with economic reports to model the financial impact of extreme weather events. This cross-pollination of data sources enables more holistic decision-making.
A surprising connection emerges in education technology, where RAG systems adaptively retrieve content from multiple disciplines to create personalized learning paths.
A common misconception is that RAG struggles with domain specificity in such scenarios. However, hybrid retrieval techniques—blending keyword and vector searches—ensure precision without sacrificing breadth. Expert insights suggest that future advancements in multi-modal RAG could further enhance these applications, enabling systems to process text, images, and even simulations for richer, cross-domain insights.
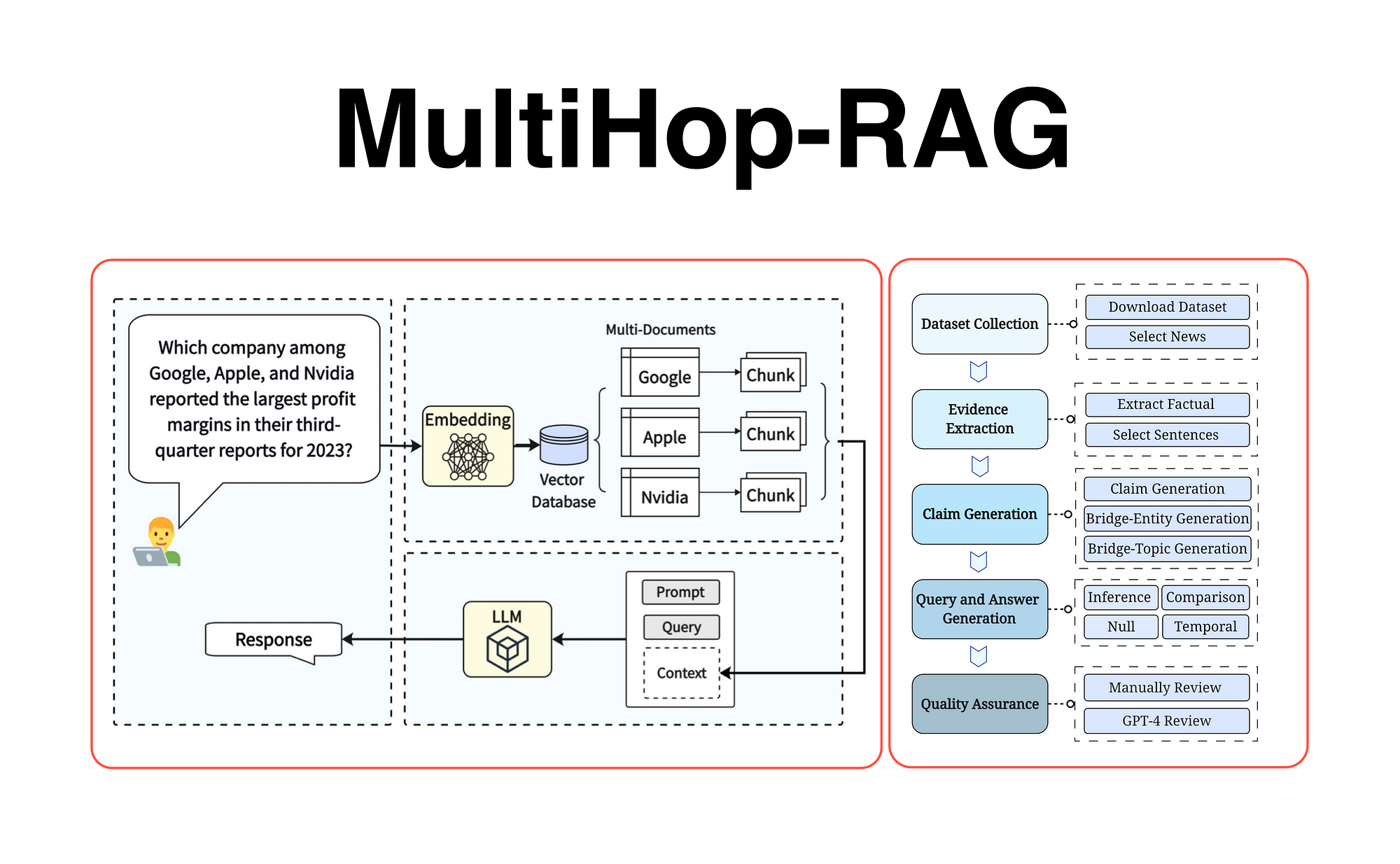
RAG in Healthcare and Clinical Decision Support
In healthcare, RAG systems revolutionize clinical decision support by integrating real-time data with domain-specific knowledge. A standout application is in oncology, where RAG retrieves the latest research, patient histories, and treatment guidelines to assist in crafting personalized care plans. This approach ensures decisions are grounded in the most current evidence, reducing reliance on outdated protocols.
A critical factor is metadata-driven filtering, which prioritizes recent, peer-reviewed studies over less reliable sources. For example, filtering by publication date and journal impact ensures only high-quality data informs decisions. Additionally, multi-modal RAG systems enhance diagnostics by combining textual data with imaging, such as linking X-rays to relevant case studies.
Conventional wisdom suggests RAG struggles with domain specificity, but fine-tuned embeddings tailored to medical vocabularies challenge this notion.
Applications in Legal and Regulatory Compliance
RAG systems are transforming legal and regulatory compliance by automating the retrieval of critical documents, such as case law, regulatory updates, and compliance guidelines. A key innovation is contextual re-ranking, which ensures the most relevant legal precedents or statutes are prioritized based on the query’s intent. For instance, a law firm handling mergers can use RAG to instantly retrieve and summarize past rulings, saving hours of manual research.
A lesser-known factor is the role of query expansion, which enriches user inputs by including synonyms or related terms, ensuring comprehensive retrieval even when legal terminology varies. This is particularly impactful in international compliance, where laws differ across jurisdictions.
Conventional wisdom assumes RAG outputs require heavy human oversight, but metadata tagging—such as jurisdiction or case type—has significantly reduced errors.
Enhancing Educational Platforms with RAG
A standout application of RAG in education is adaptive learning, where systems dynamically adjust content based on a student’s progress and comprehension. By analyzing interaction data, RAG-powered platforms like Duolingo and Khan Academy deliver personalized exercises and explanations, ensuring students engage with material at the right difficulty level. This approach boosts retention and motivation by reducing cognitive overload.
A lesser-known but critical factor is the integration of spaced repetition algorithms, which optimize the timing of content reviews to reinforce learning. When combined with RAG’s retrieval capabilities, these systems can identify knowledge gaps and prioritize relevant materials, creating a seamless learning experience.
Conventional wisdom suggests that personalization requires extensive manual input, but multi-modal RAG systems—incorporating text, video, and interactive content—challenge this by automating tailored content delivery. Future innovations could focus on real-time feedback loops, enabling platforms to refine recommendations instantly, further enhancing educational outcomes.
Future Trends and Emerging Developments
The future of RAG is set to be shaped by neuro-symbolic AI, blending neural networks with symbolic reasoning to enhance logical consistency in generated outputs. Another trend is real-time multi-modal integration, where RAG systems process text, images, and audio simultaneously.
A common misconception is that larger models always outperform smaller ones. However, domain-specific fine-tuning is proving more effective, as seen in financial RAG systems that outperform general-purpose models by focusing on niche datasets.
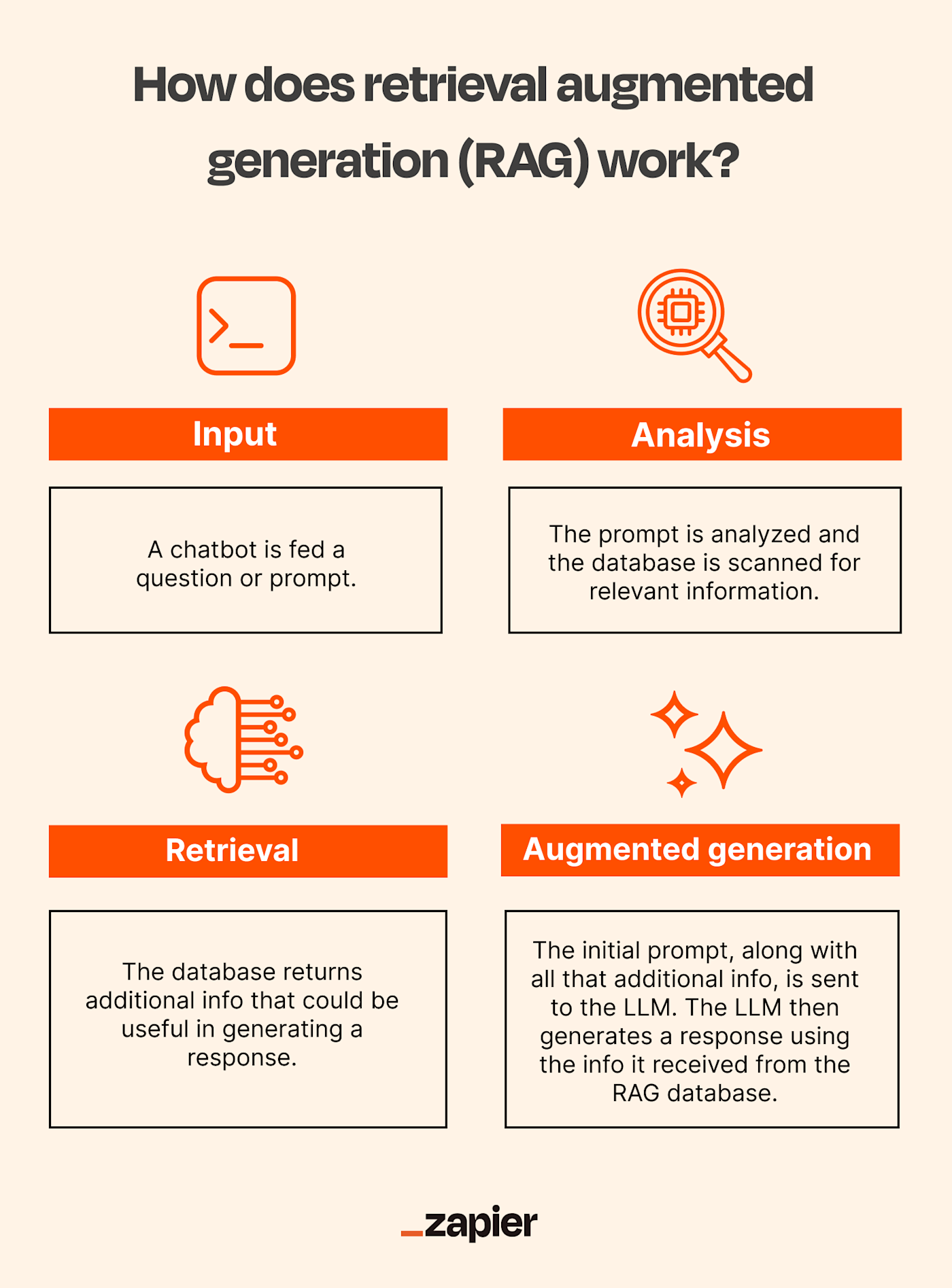
Advancements in Zero-Shot and Few-Shot Learning
A key breakthrough in zero-shot and few-shot learning is the use of prompt engineering to guide models toward better generalization. By crafting prompts that mimic natural human queries, models like GPT-4 can perform tasks they were never explicitly trained for, such as translating niche dialects or summarizing legal documents. This approach reduces dependency on large datasets, making AI more accessible for resource-constrained industries.
Interestingly, cross-domain transfer is emerging as a game-changer. For instance, a few-shot model trained on medical data can adapt to financial risk analysis by leveraging shared patterns in decision-making processes. This challenges the belief that domain-specific training is always necessary.
However, success hinges on data quality. Poorly curated examples can mislead models, emphasizing the need for robust validation pipelines. Moving forward, integrating reinforcement learning with few-shot techniques could enable models to self-correct, unlocking even greater adaptability across disciplines.
Integrating RAG with Multimodal Data
A standout innovation in integrating RAG with multimodal data is cross-modal embeddings, where shared representations align text, images, and audio in a unified space. This enables seamless retrieval and generation across formats.
The success of this approach lies in contrastive learning, which trains models to identify relationships between modalities. However, a major challenge is modality imbalance—text-heavy datasets often overshadow visual or audio inputs, skewing results. Addressing this requires balanced datasets and adaptive weighting mechanisms during training.
Ethical Considerations and Responsible AI
A critical yet underexplored aspect of ethical AI is dynamic bias auditing, where RAG systems are continuously monitored for emerging biases rather than relying on static, pre-deployment checks. This approach works by integrating real-time feedback loops and anomaly detection algorithms to flag and mitigate biases as they arise.
What makes this effective is its adaptability—bias patterns evolve, and so must the auditing mechanisms. However, a major challenge is feedback sparsity, where limited user input restricts self-correction. Addressing this requires incentivizing user participation and leveraging synthetic data to simulate diverse scenarios.
FAQ
What are the key differences between basic RAG and advanced RAG techniques?
Basic RAG techniques primarily focus on straightforward retrieval and generation processes, often relying on simple semantic searches and static data inputs. While effective for general queries, they struggle with complex, multi-step questions and maintaining contextual relevance in dynamic scenarios.
In contrast, advanced RAG techniques incorporate sophisticated methods like hybrid retrieval, re-ranking, and metadata-driven filtering to enhance precision and relevance. These systems also leverage dynamic indexing and multimodal capabilities, enabling them to process diverse data types such as text, images, and audio. Additionally, advanced RAG employs fine-tuned language models and attention-based fusion mechanisms to ensure coherent and contextually rich outputs.
The key distinction lies in adaptability—advanced RAG systems are designed to handle evolving data and user intents, making them more suitable for high-stakes applications like healthcare, legal compliance, and personalized recommendations. This evolution addresses the limitations of basic RAG, offering greater accuracy, efficiency, and scalability.
How do advanced retrieval methods like re-ranking and hybrid search improve RAG performance?
Advanced retrieval methods like re-ranking and hybrid search significantly enhance RAG performance by refining the quality and relevance of retrieved data.
- Re-ranking prioritizes the most pertinent documents by scoring them based on their contextual alignment with the query. This ensures that the generative model processes only the most valuable information, leading to more accurate and coherent outputs.
- Hybrid search, on the other hand, combines the strengths of sparse retrieval (keyword-based) and dense retrieval (semantic-based) techniques.
By leveraging both approaches, it captures a broader spectrum of relevant data, accommodating both explicit terms and nuanced meanings. This dual-layered strategy is particularly effective for complex queries, where precision and recall are equally critical.
Together, these methods optimize the retrieval pipeline, reducing noise and improving the overall efficiency of RAG systems. They enable the generation of responses that are not only contextually accurate but also tailored to diverse and intricate user needs.
What role does multimodal data integration play in enhancing RAG systems?
Multimodal data integration plays a transformative role in enhancing RAG systems by enabling them to process and synthesize information across diverse data formats, such as text, images, audio, and video. This capability allows RAG systems to deliver more comprehensive and contextually enriched responses, addressing complex queries that require insights from multiple modalities.
By aligning and embedding data from different sources into a unified framework, multimodal integration ensures that the system can draw connections between disparate pieces of information.
The integration of multimodal data also enhances the adaptability of RAG systems, allowing them to cater to a wider range of use cases and user preferences. This advancement not only improves the depth and relevance of generated outputs but also opens new frontiers for applications in fields like multimedia content creation, virtual assistants, and cross-domain research.
How can organizations address ethical challenges when implementing advanced RAG techniques?
Organizations can tackle ethical challenges in RAG implementation by prioritizing transparency, fairness, and accountability. Establishing governance frameworks, ethics advisory boards, and regular bias audits ensures responsible deployment.
Strong data governance is crucial for privacy and regulatory compliance, requiring strict policies on consent, anonymization, and security. Explainable AI (XAI) enhances accountability by making decision processes more transparent.
Engaging stakeholders—ethicists, domain experts, and communities—helps refine systems and address risks. Continuous monitoring and feedback loops ensure ethical standards evolve with emerging challenges, maintaining trust in RAG applications.
What are the most effective tools and frameworks for building advanced RAG systems?
Building advanced RAG systems requires powerful tools that streamline retrieval, ranking, and generation workflows. LangChain excels as a versatile framework, integrating language models with external data through document indexing, query processing, and multi-step retrieval-to-generation pipelines. It also connects seamlessly with vector databases for efficient data handling.
Haystack, an open-source framework, enables scalable RAG pipelines with advanced retrieval techniques like dense passage retrieval and hybrid search. Its modular design supports filtering, ranking, and response generation, making it ideal for domain-specific applications.
Vector databases like Pinecone and Weaviate optimize similarity searches, ensuring fast and accurate data retrieval. Additionally, Hugging Face Transformers provide pre-trained models and APIs that simplify RAG implementation.
By leveraging these tools, organizations can develop scalable, high-performance RAG systems tailored to their specific needs, enhancing AI-driven decision-making and automation.
Conclusion
Advanced RAG techniques are reshaping how organizations harness AI for dynamic, data-driven tasks, offering a level of precision and adaptability that static models simply cannot match.
A common misconception is that RAG systems are only as good as their retrieval algorithms. In reality, their true power lies in the seamless fusion of retrieved data with generative models. Experts emphasize that ethical considerations, such as bias auditing and data privacy, are as critical as technical advancements. By addressing these, RAG systems can unlock transformative potential across industries.