
Agent RAG: Achieving Extreme Accuracy with Parallel Quotations
Agent RAG leverages parallel quotations to achieve extreme accuracy in retrieval. This guide explores how this technique enhances contextual understanding, improves precision, and optimizes AI-driven knowledge retrieval for better results.


In 2024, a team of engineers at LangChain faced a challenge that had long plagued AI systems: ensuring absolute accuracy when combining information from different sources.
The stakes were high.
Even minor inaccuracies could have significant consequences in fields like legal research and medical diagnostics.
Their solution, a novel approach called “Agent RAG with Parallel Quotations,” redefined how retrieval-augmented generation systems.
This method does not rely on a single data retrieval stream but uses multiple agents to extract and cross-verify information simultaneously.
This breakthrough revealed a deeper truth: the power of AI lies not in its speed or scale but in its ability to mirror the meticulousness of human expertise.
Understanding Retrieval-Augmented Generation
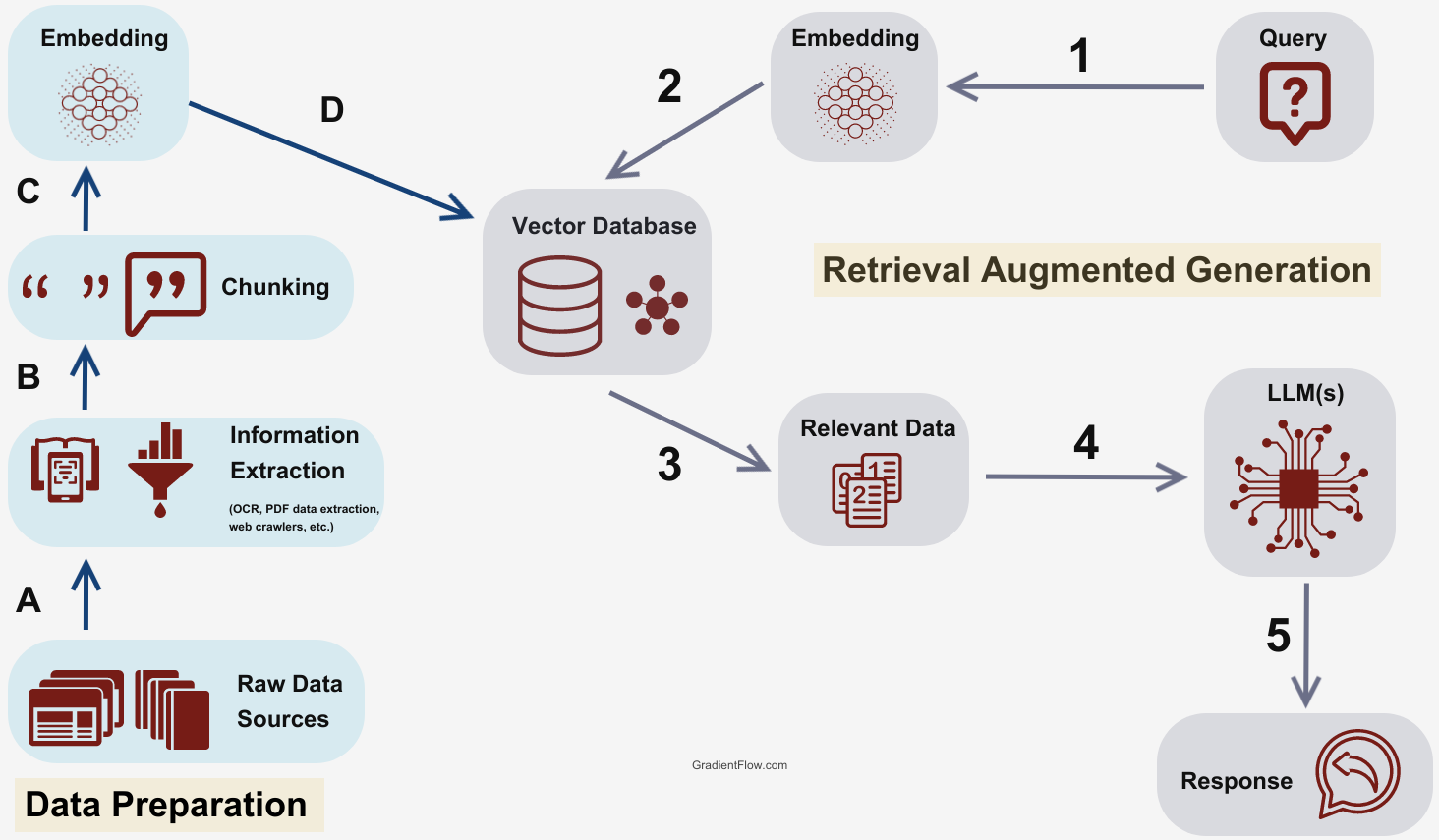
Retrieval-Augmented Generation (RAG) operates at the intersection of data retrieval and generative AI, transforming how systems access and synthesize information.
Unlike traditional generative models relying solely on pre-trained data, RAG integrates real-time retrieval mechanisms to ground outputs in external, context-specific knowledge.
This dual-layered approach enhances accuracy and mitigates issues like hallucination—a persistent flaw in standalone large language models (LLMs).
As RAG evolves, its potential to redefine enterprise AI applications becomes evident. To fully harness its capabilities, organizations must prioritize robust data governance and real-time retrieval pipelines.
The Role of Parallel Quotations
Parallel Quotations in Agent RAG represent a new approach to ensuring accuracy by enabling simultaneous cross-verification of retrieved data.
This method uses multiple retrieval agents to extract information from diverse sources and verify outputs to minimize errors.
The innovation lies in its ability to emulate the meticulousness of human expertise, particularly in high-stakes domains.
The technical advantage stems from the orchestration of independent retrieval agents, each optimized for specific data repositories.
For instance, metadata tagging and semantic search algorithms ensure that retrieved content aligns with the query’s intent. This layered verification process enhances reliability and builds user trust in AI-generated outputs.
Looking forward, Parallel Quotations could redefine enterprise AI by setting new benchmarks for accuracy.
Organizations should explore integrating this approach into workflows, particularly in sectors like healthcare and finance, where the cost of errors is exceptionally high.
Agentic RAG Architecture and Components
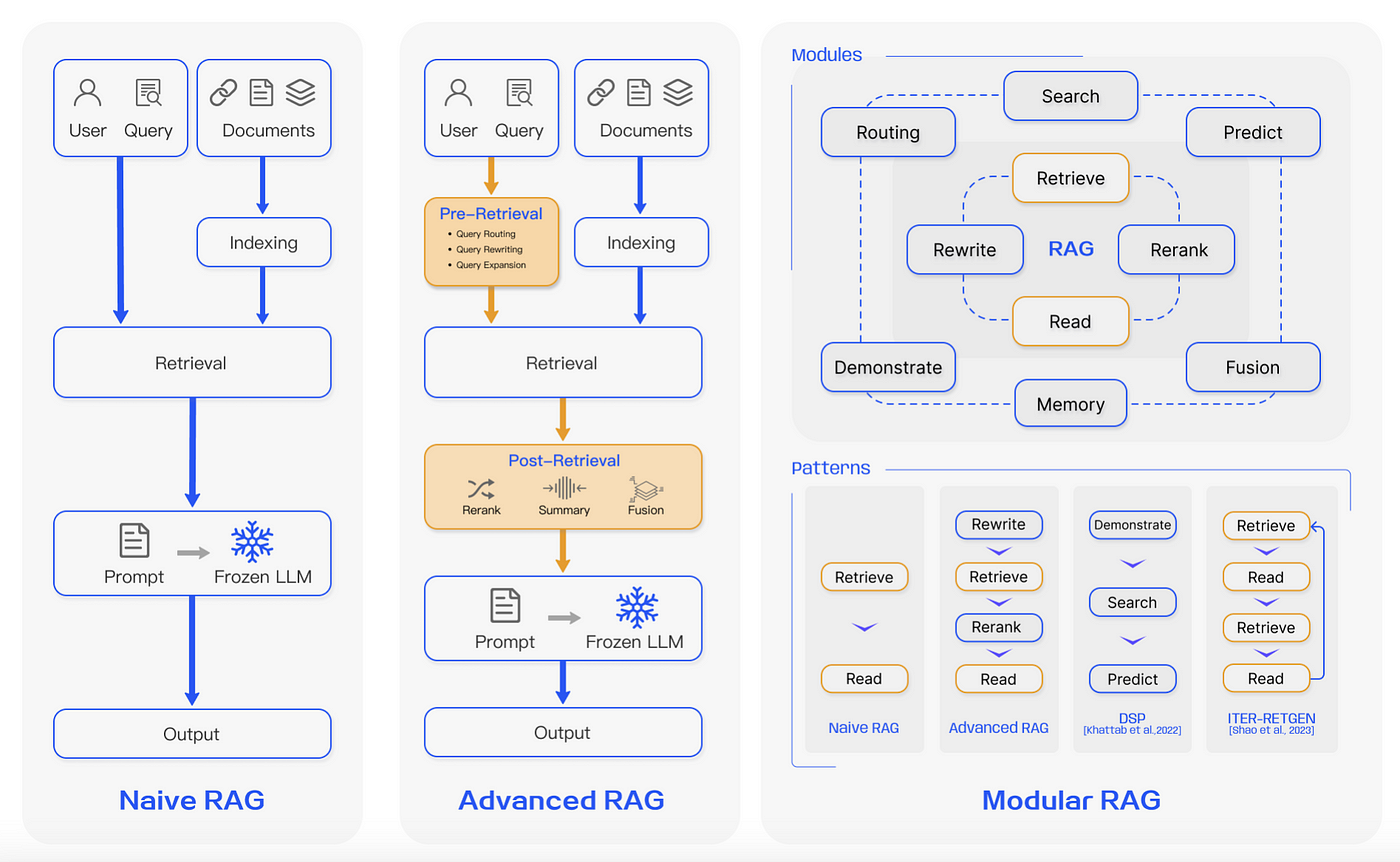
The architecture of Agentic RAG is a sophisticated interplay of modular components, each designed to optimize retrieval and generation processes.
At its core, the system integrates autonomous agents that dynamically manage data retrieval, prioritization, and synthesis. These agents operate within a multi-layered framework, ensuring adaptability and precision.
A key component is the retrieval orchestration layer, which assigns specific tasks to agents based on query complexity.
For example, in a healthcare application, one agent might retrieve patient records while another cross-references medical literature. This division of labor reduces processing time and enhances accuracy.
The feedback loop mechanism within Agentic RAG introduces a self-correcting capability. Agents refine their retrieval strategies by continuously evaluating output quality, mirroring human-like learning. This contrasts with traditional RAG systems, which lack iterative improvement.
A common misconception is that such architectures are resource-intensive. However, frameworks like LangChain and LlamaIndex streamline deployment, making Agentic RAG scalable for enterprises.
Agentic Systems in RAG Pipelines
Agentic systems within RAG pipelines excel by leveraging multi-agent collaboration to address complex, high-stakes queries.
Unlike single-agent models, these systems distribute tasks across specialized agents, each optimized for distinct data repositories or analytical functions. This modularity enhances both scalability and precision, particularly in dynamic environments.
One critical innovation is the hierarchical agent structure, where supervisory agents oversee task-specific agents.
This approach mirrors organizational decision-making, ensuring alignment between granular data retrieval and strategic objectives.
However, a lesser-known factor influencing success is contextual adaptability. Agents equipped with semantic search capabilities dynamically adjust retrieval strategies based on query intent.
Looking ahead, integrating learning agents capable of refining retrieval algorithms through iterative feedback could redefine enterprise AI, enabling continuous improvement and deeper domain specialization.
Integration with Large Language Models
The integration of Agentic RAG systems with Large Language Models (LLMs) represents a pivotal advancement in AI-driven decision-making.
A key aspect deserving focused attention is the dynamic alignment of retrieval outputs with LLM processing pipelines, which ensures that real-time data enhances the contextual relevance of generated responses.
One exemplary application is GitHub Copilot, which leverages fine-tuned LLMs alongside retrieval-augmented systems to provide developers with code suggestions grounded in both historical repositories and live project contexts.
A critical technical nuance lies in the feedback loop mechanism. Agentic RAG systems minimize hallucination risks while enhancing response accuracy by iteratively refining retrieval strategies based on LLM output quality. This contrasts with traditional RAG systems, which often lack iterative adaptability.
Emerging trends suggest that contextual embeddings—where retrieval outputs are pre-processed into vectorized formats compatible with LLM architectures—are redefining integration efficiency.
Looking forward, developing adaptive orchestration layers capable of dynamically reconfiguring retrieval pipelines based on LLM feedback could further optimize integration.
This approach promises to unlock new levels of precision and scalability across industries, from healthcare diagnostics to financial compliance.
Parallel Quotation Retrieval and Processing
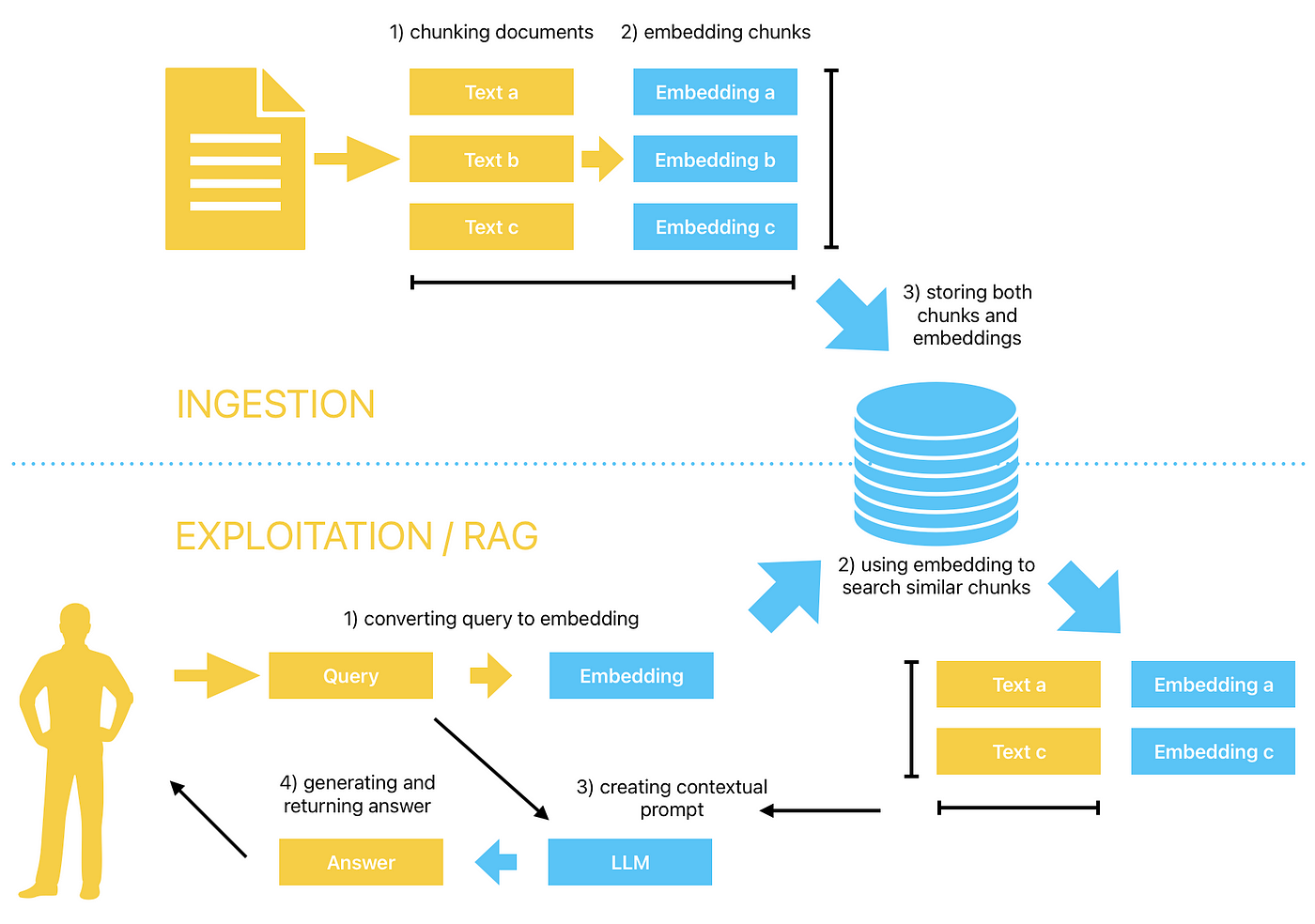
Parallel Quotation Retrieval and Processing introduces a paradigm shift in ensuring data accuracy by orchestrating multiple simultaneous retrieval agents.
This approach mirrors the precision of a legal team cross-referencing case law, where each agent specializes in a distinct repository or data type, ensuring comprehensive coverage and verification.
The system’s ability to synthesize corroborated outputs from diverse sources highlights its potential in high-stakes domains like compliance and healthcare.
A common misconception is that parallel processing increases redundancy.
However, the layered verification mechanism ensures that discrepancies are flagged and resolved, enhancing reliability. For instance, metadata tagging and semantic search algorithms dynamically align retrieved data with query intent, minimizing inconsistencies.
Advanced Retrieval Mechanisms
Advanced Retrieval Mechanisms within Parallel Quotation Retrieval leverage multi-agent orchestration to achieve unparalleled precision and efficiency.
A critical innovation is using context-aware semantic embeddings, which dynamically adapt retrieval strategies based on query complexity and domain-specific nuances.
This ensures that retrieved data aligns with the query’s intent and its contextual dependencies.
Emerging trends suggest integrating predictive retrieval models that anticipate user needs based on historical queries. This could redefine workflows in dynamic sectors like emergency response, where real-time prioritization of critical data streams is vital.
Quote Selection and Relevance Ranking
Quote Selection and Relevance Ranking within Parallel Quotation Retrieval focuses on optimizing the alignment between retrieved data and user intent.
A pivotal innovation is the integration of semantic rankers that evaluate retrieved quotes based on contextual relevance, accuracy, and source credibility. This ensures that only the most pertinent and reliable information is synthesized into outputs.
A notable application is Microsoft Azure’s use of semantic ranking in its AI Search platform.
A lesser-explored factor is contextual weighting, where quotes are ranked not only by direct relevance but also by their contribution to the broader narrative. This approach minimizes the risk of overfitting to isolated data points.
Emerging trends suggest adopting adaptive ranking models that dynamically incorporate user feedback to refine quote prioritization.
Organizations should explore these models to enhance decision-making processes, particularly in domains like healthcare diagnostics, where nuanced interpretations of data are critical.
Accuracy Enhancement Techniques
Accuracy in Parallel Quotation Retrieval is achieved through multi-agent orchestration and contextual verification frameworks.
A key technique involves leveraging redundancy without duplication, where multiple agents independently retrieve overlapping data to cross-validate outputs.
This mirrors the precision of peer-reviewed research, ensuring that inconsistencies are flagged and resolved.
A common misconception is that increased agent collaboration leads to inefficiency. However, hierarchical agent structures streamline this process by assigning supervisory agents to oversee task-specific agents.
Emerging trends, such as feedback-driven refinement loops, promise to further enhance accuracy by enabling agents to learn from iterative performance evaluations, ensuring adaptability in dynamic environments.
Grounding Responses in Verified Information
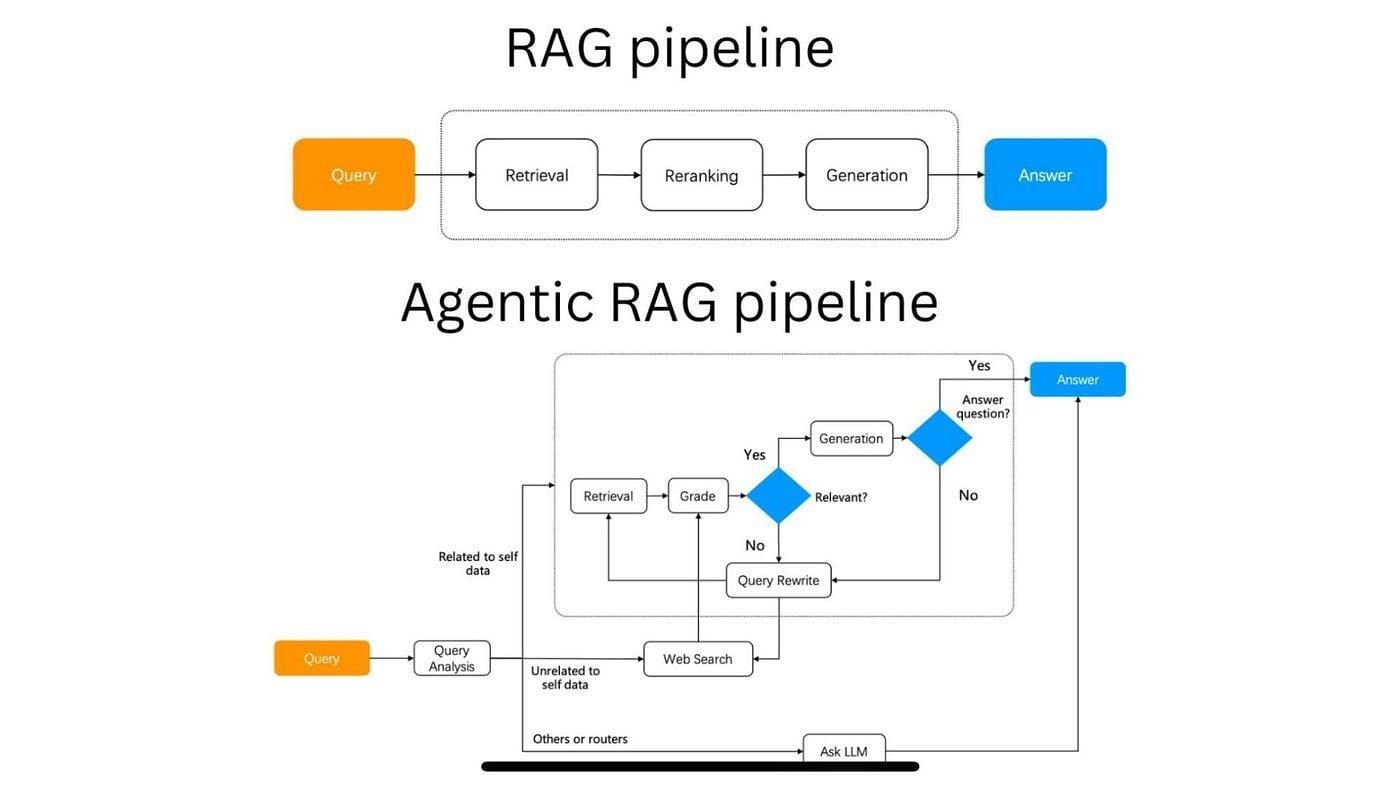
Grounding responses in verified information is pivotal for ensuring the reliability of outputs in high-stakes applications.
A critical approach involves source triangulation, where multiple agents independently retrieve data from diverse repositories and cross-reference results to eliminate inconsistencies.
This method mirrors investigative journalism, where corroboration across sources ensures factual integrity.
This success underscores the importance of source credibility scoring, where metadata tagging prioritizes high-reliability repositories, such as clinical trials or regulatory databases.
Emerging trends reveal the potential of contextual embeddings to enhance grounding.
A lesser-known factor influencing success is temporal relevance. In dynamic fields like finance, outdated data can skew results.
Looking forward, organizations should adopt adaptive verification pipelines that incorporate user feedback and evolving data landscapes. This strategy ensures sustained accuracy, fostering trust in AI-driven decision-making across industries.
Self-Evaluation and Reflection Mechanisms
Self-evaluation and reflection mechanisms in Agent RAG systems are transformative for enhancing accuracy through iterative improvement.
A critical focus lies in the feedback loop mechanism, where agents continuously assess the quality of their outputs against predefined metrics such as coherence, relevance, and groundedness. This iterative process enables dynamic refinement of retrieval strategies, mirroring human learning.
Emerging insights suggest that adaptive scoring models incorporate user feedback and domain-specific benchmarks and are pivotal for sustained accuracy.
A lesser-known factor is the role of contextual adaptability. Systems that dynamically adjust evaluation criteria based on query complexity outperform static models.
Looking ahead, organizations should invest in multi-layered evaluation frameworks that combine automated scoring with expert oversight. This hybrid approach ensures robust accuracy while fostering trust in AI-driven decision-making.
Implementation Strategies and Challenges
Implementing Agent RAG with Parallel Quotations requires balancing technical precision and operational scalability.
A key strategy involves modular agent design, where specialized agents handle distinct tasks, such as metadata tagging or semantic alignment.
A common misconception is that multi-agent systems inherently increase redundancy. However, hierarchical orchestration mitigates this by assigning supervisory agents to oversee task-specific agents, ensuring efficiency without compromising accuracy.
Unexpectedly, data quality governance emerges as a critical factor. Poorly curated repositories can skew outputs, underscoring the need for robust verification pipelines.
Integrating adaptive learning agents capable of refining retrieval strategies in real-time will be pivotal for addressing evolving data landscapes and ensuring sustained accuracy.
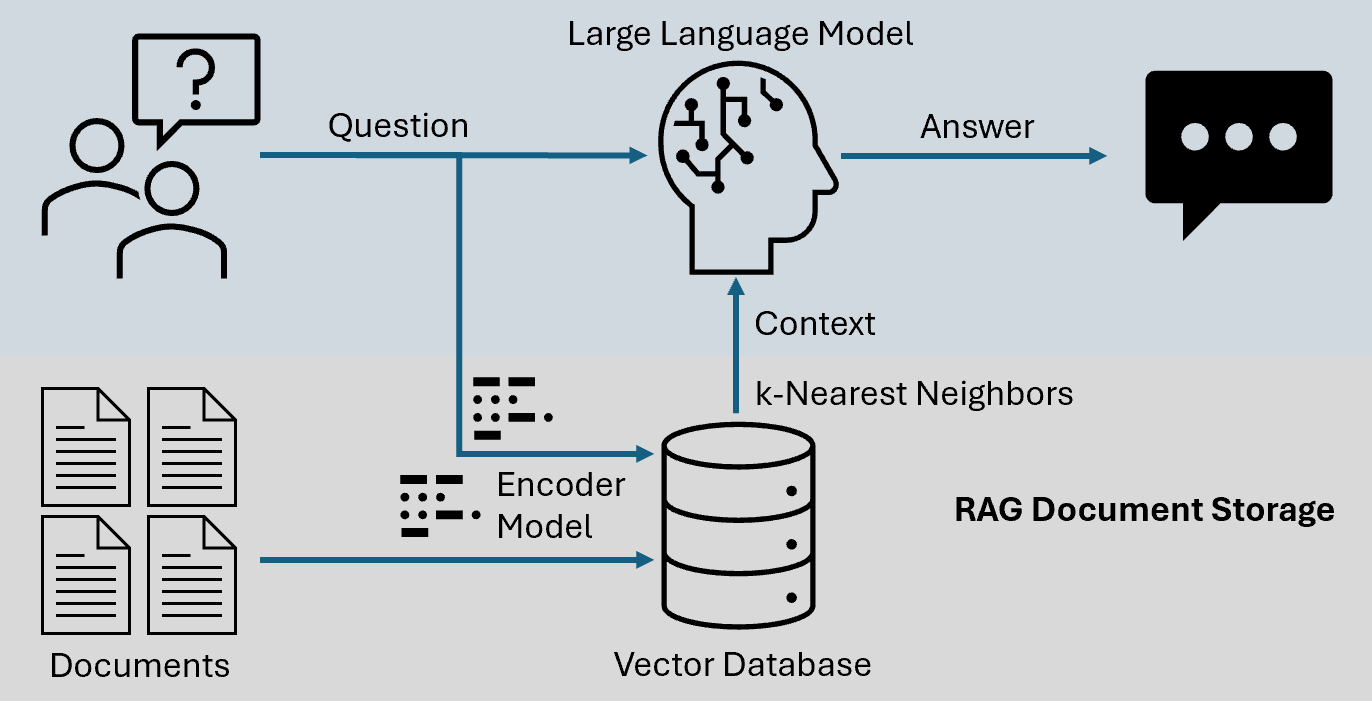
Query Planning and Decomposition
Effective query planning and decomposition in Agent RAG systems is pivotal for managing complex, multi-faceted queries.
This process involves breaking down a query into smaller, manageable sub-tasks, each assigned to specialized agents.
The hierarchical task allocation model ensures that each agent focuses on a specific query aspect, optimising precision and efficiency.
A lesser-known factor is the role of temporal alignment. In dynamic fields like finance, decomposed queries must synchronise with real-time data streams to maintain relevance.
Looking forward, integrating predictive decomposition models could enable agents to anticipate user needs, further enhancing scalability and accuracy.
Balancing Retrieval Accuracy and Response Coherence
Achieving a balance between retrieval accuracy and response coherence in Agent RAG systems requires a nuanced approach that integrates contextual embeddings and dynamic weighting algorithms.
These techniques ensure that retrieved data aligns with the query’s intent while maintaining logical flow in the generated response.
A compelling case study is GitHub Copilot, which leverages retrieval-augmented systems to provide developers with code suggestions.
Narrative structuring is a lesser-known factor influencing this balance, where agents prioritize data that contributes to a cohesive response.
Emerging trends suggest adopting adaptive coherence models that dynamically adjust retrieval strategies based on user feedback.
Organizations should explore these models to enhance decision-making processes, particularly in high-stakes domains like healthcare and finance, where both precision and clarity are critical.
Looking ahead, integrating feedback-driven refinement loops will be essential for sustaining this balance in evolving data landscapes.
FAQ
What is Agent RAG, and how does it leverage Parallel Quotations to enhance accuracy?
Agent RAG uses multiple retrieval agents to cross-verify data from different sources, reducing errors and inconsistencies. Parallel Quotations ensure that retrieved information is validated across independent streams before generating a response. This approach improves accuracy in fields like legal research and healthcare, where precision is critical.
What are the key components and technical innovations behind Agent RAG’s Parallel Quotation framework?
Agent RAG relies on multi-agent orchestration, semantic embeddings, and layered verification. Each agent specializes in retrieving data from distinct repositories, ensuring comprehensive coverage. Metadata scoring prioritizes high-credibility sources, while adaptive feedback loops refine retrieval strategies, improving accuracy in fields like compliance and healthcare.
How does Agent RAG address challenges like data inconsistencies and scalability in complex retrieval tasks?
Agent RAG reduces inconsistencies through layered verification, where agents independently retrieve and validate data. Hierarchical agent structures coordinate tasks for scalability, while semantic embeddings and metadata scoring enhance data alignment. These strategies ensure precise retrieval for industries like financial compliance, healthcare, and legal analysis.
What are the future implications of Agent RAG with Parallel Quotations for enterprise AI applications?
Agent RAG is set to redefine AI-driven decision-making by improving accuracy and adaptability. Future developments may include predictive retrieval models, real-time prioritization, and ethical decision-making modules. These innovations will make AI systems more reliable for regulatory compliance, healthcare, and financial risk assessment.
Conclusion
Agent RAG with Parallel Quotations is reshaping AI-driven retrieval by ensuring higher accuracy and reducing errors in complex tasks.
Its ability to cross-verify multiple sources before generating responses makes it a valuable tool for industries where precision is non-negotiable.
Integrating multi-agent validation and real-time retrieval strategies will be key to maintaining trust and reliability as AI applications expand. Businesses that adopt these techniques will gain a competitive edge in compliance, healthcare, finance, and beyond.