
Balancing Relevance and Diversity in RAG Knowledge Retrieval
Striking the right balance between relevance and diversity is key to effective RAG retrieval. This guide covers techniques to avoid redundancy, enhance content variety, and maintain contextual accuracy in AI-generated outputs.


What happens when your AI system keeps giving you the same kind of answers, over and over?
You might get precision, but you miss the bigger picture.
That’s the core issue with Retrieval-Augmented Generation (RAG) today.
Many systems prioritize relevance so heavily that they shut out diversity—leaving out rare cases, new ideas, and valuable outliers.
This is more than a technical limitation. In healthcare, legal research, and finance, missing diverse sources can lead to blind spots, incomplete findings, or even costly mistakes.
Balancing relevance and diversity in RAG knowledge retrieval isn’t just a nice-to-have—it’s essential for building useful and trustworthy systems.
In this article, we explore why this balance matters, how modern systems are starting to address it, and what strategies actually work in practice.
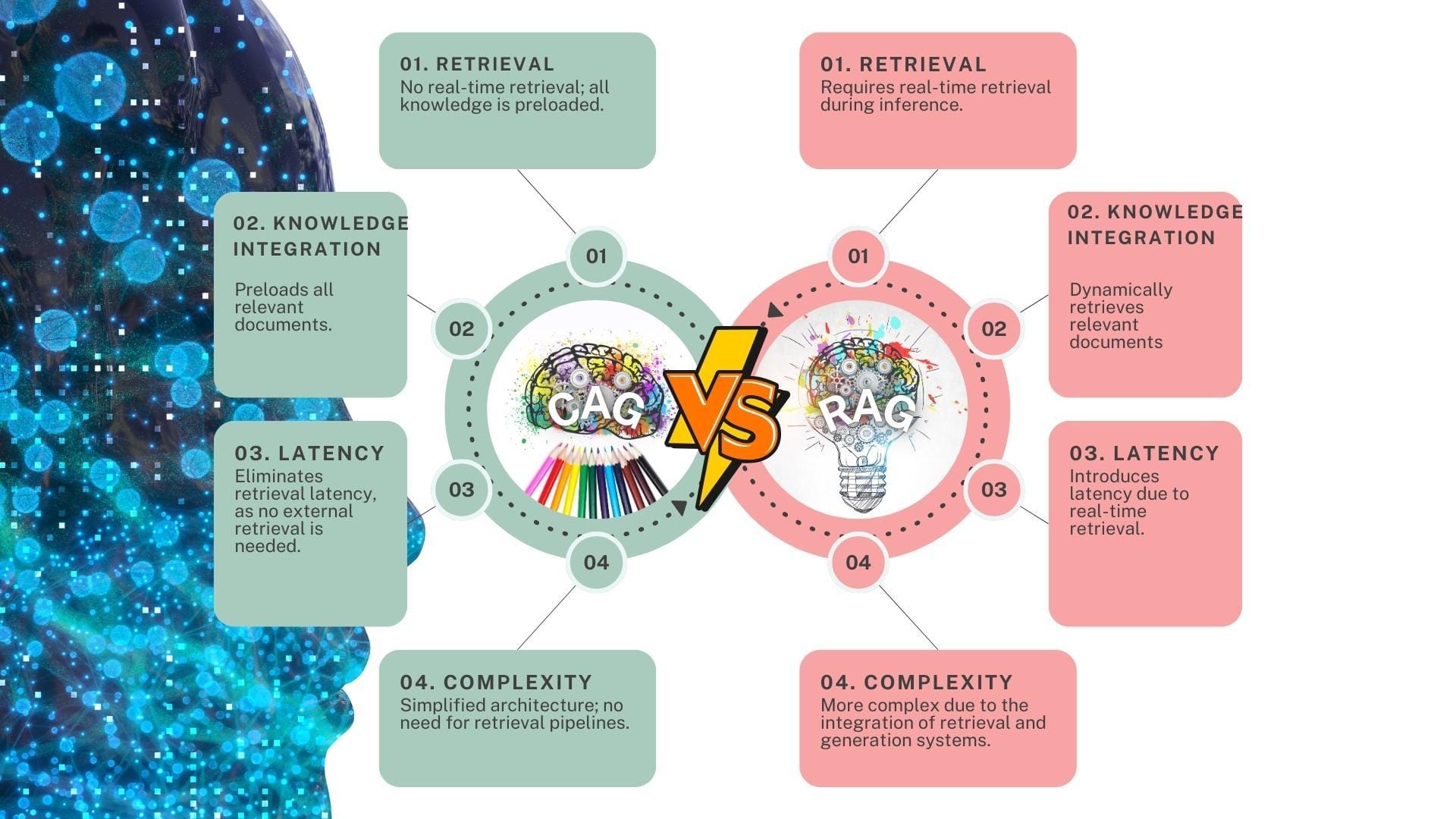
Foundational Concepts of RAG Systems
One critical yet often overlooked aspect of RAG systems is the role of adaptive retrieval mechanisms in balancing relevance and diversity.
Unlike static retrieval methods, adaptive systems dynamically adjust retrieval parameters based on real-time feedback, ensuring that both mainstream and peripheral data points are considered.
This approach matters because static retrieval often reinforces biases by over-prioritizing frequently accessed data.
Adaptive mechanisms, however, leverage techniques like contextual embeddings and real-time query refinement to identify underrepresented yet contextually significant information.
For instance, semantic retrieval models can prioritize diverse perspectives by weighting less common but contextually relevant documents higher in the ranking process.
A notable implementation of this is seen in Google DeepMind’s AlphaCode, which uses adaptive retrieval to refine programming solutions by incorporating edge-case scenarios. This ensures outputs are accurate and robust across diverse use cases.
However, adaptive systems face challenges, such as increased computational overhead and the risk of overfitting to specific feedback loops.
Addressing these requires careful calibration of retrieval algorithms to maintain scalability without sacrificing diversity.
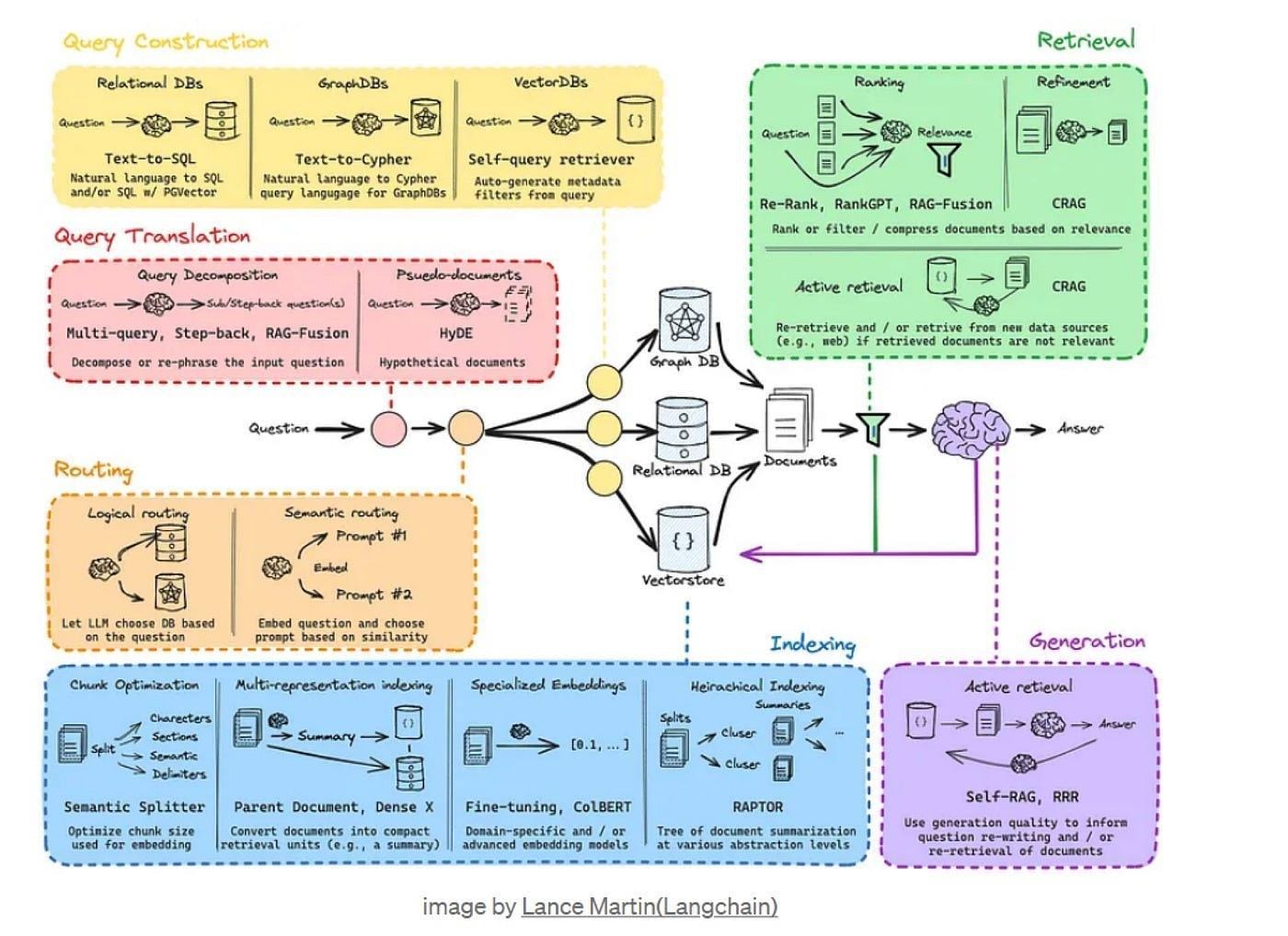
Traditional vs. Modern Retrieval Methods
Traditional retrieval methods rely on static keyword matching, which often struggles to interpret the subtleties of complex queries.
This approach assumes that relevance is tied solely to exact term overlap, leading to a rigid and sometimes myopic view of the data.
For instance, a query about “renewable energy innovations” might surface documents heavily weighted toward frequently cited technologies, ignoring emerging or niche advancements.
Modern retrieval systems, by contrast, leverage contextual embeddings and dynamic query transformations to interpret user intent adaptively.
These techniques enable the system to identify latent connections between concepts, even when explicit keywords are absent. For example, a modern system might link “solar panel efficiency” with “perovskite materials,” uncovering less obvious but highly relevant insights.
One notable implementation is OpenAI’s dense passage retrieval (DPR), which encodes queries and documents into a shared vector space.
This allows for nuanced matching based on semantic similarity rather than surface-level terms. However, such systems are not without challenges; they require significant computational resources and can occasionally overfit to dominant patterns in the training data.
This evolution underscores the importance of balancing computational efficiency with the need for diverse, contextually rich outputs.
The Importance of Relevance and Diversity
Relevance and diversity are not opposing forces but complementary dimensions that, when balanced, unlock the full potential of Retrieval-Augmented Generation (RAG) systems.
Overemphasizing relevance often leads to a narrow focus, where only the most frequently cited or contextually dominant data is retrieved.
This approach risks creating echo chambers, particularly in fields like medical research or legal analysis, where alternative perspectives can be critical.
Diversity, on the other hand, ensures that a broader spectrum of viewpoints and data sources is considered.
Techniques like Maximum Marginal Relevance (MMR) balance novelty with relevance by re-ranking documents to include underrepresented yet contextually significant information.
This approach is particularly effective in addressing ambiguous queries, such as those involving cultural trends or emerging technologies, where a single “correct” answer may not exist.
By integrating relevance and diversity, RAG systems can provide outputs that are not only accurate but also robust, nuanced, and innovative.
Defining Relevance in Knowledge Retrieval
Relevance in knowledge retrieval transcends simple keyword matching, demanding a nuanced understanding of user intent and contextual alignment.
At its core, relevance is about identifying information that answers a query and anticipates the underlying needs driving it.
This distinction is critical in domains like legal research, where precision and contextual depth are paramount.
One advanced technique for refining relevance is contextual weighting, which dynamically adjusts the importance of retrieved data based on its semantic relationship to the query.
Unlike static scoring models, this approach incorporates temporal context, domain-specific terminology, and user behavior patterns. For instance, in a project by Microsoft Research, contextual weighting was used to enhance legal document retrieval, significantly improving the system’s ability to surface precedent cases relevant to nuanced legal arguments.
However, challenges persist. Contextual weighting can struggle with ambiguous queries, where user intent is unclear. Addressing this requires integrating interactive feedback loops, allowing users to refine results iteratively.
By treating relevance as a dynamic, user-centered process, organizations can transform retrieval systems into tools that inform and empower decision-making.
Measuring Diversity in Information Sources
Diversity in information sources is not merely a safeguard against bias but a mechanism for uncovering hidden insights that enrich system outputs.
Maximum Marginal Relevance (MMR) balances relevance with novelty by re-ranking retrieved documents. This ensures that less dominant but contextually significant perspectives are included, creating a more nuanced response.
The principle behind MMR lies in its iterative scoring mechanism, which penalizes redundancy while rewarding unique contributions.
For example, in a legal research system, MMR can prioritize case law from underrepresented jurisdictions, offering a broader legal context.
However, its effectiveness depends on fine-tuning parameters like similarity thresholds, which, if miscalibrated, may either dilute relevance or fail to capture sufficient diversity.
A notable implementation of this concept was observed in IBM Watson’s healthcare applications, where integrating diverse clinical studies improved diagnostic recommendations.
The system identified alternative treatment pathways by incorporating data from smaller, less-cited studies, enhancing patient outcomes.
Ultimately, measuring diversity requires a dynamic approach, adapting to users' evolving needs and the complexity of their queries. This balance is critical for fostering innovation and trust in retrieval-augmented systems.
Advanced Retrieval Strategies
Adaptive retrieval strategies have redefined how RAG systems balance precision and recall, particularly in high-stakes domains like healthcare and finance.
By dynamically adjusting retrieval parameters based on real-time feedback, these systems can prioritize contextually relevant yet underrepresented data.
One key innovation is hybrid retrieval, which combines sparse methods like BM25 with dense embeddings to capture both exact matches and semantic nuances. This dual-layered approach ensures comprehensive coverage without sacrificing specificity.
For example, BloombergGPT employs hybrid retrieval to analyze financial reports, enabling it to surface both explicit trends and latent market signals.
A common misconception is that increasing retrieval diversity dilutes relevance. However, techniques like contextual re-ranking prove otherwise.
Systems can maintain relevance while integrating diverse perspectives by re-evaluating retrieved documents based on query-specific embeddings.
This mirrors the way a skilled editor curates a balanced narrative, ensuring no critical viewpoint is overlooked.
The implications are clear: advanced retrieval strategies enhance system performance and foster trust by delivering nuanced, actionable insights.
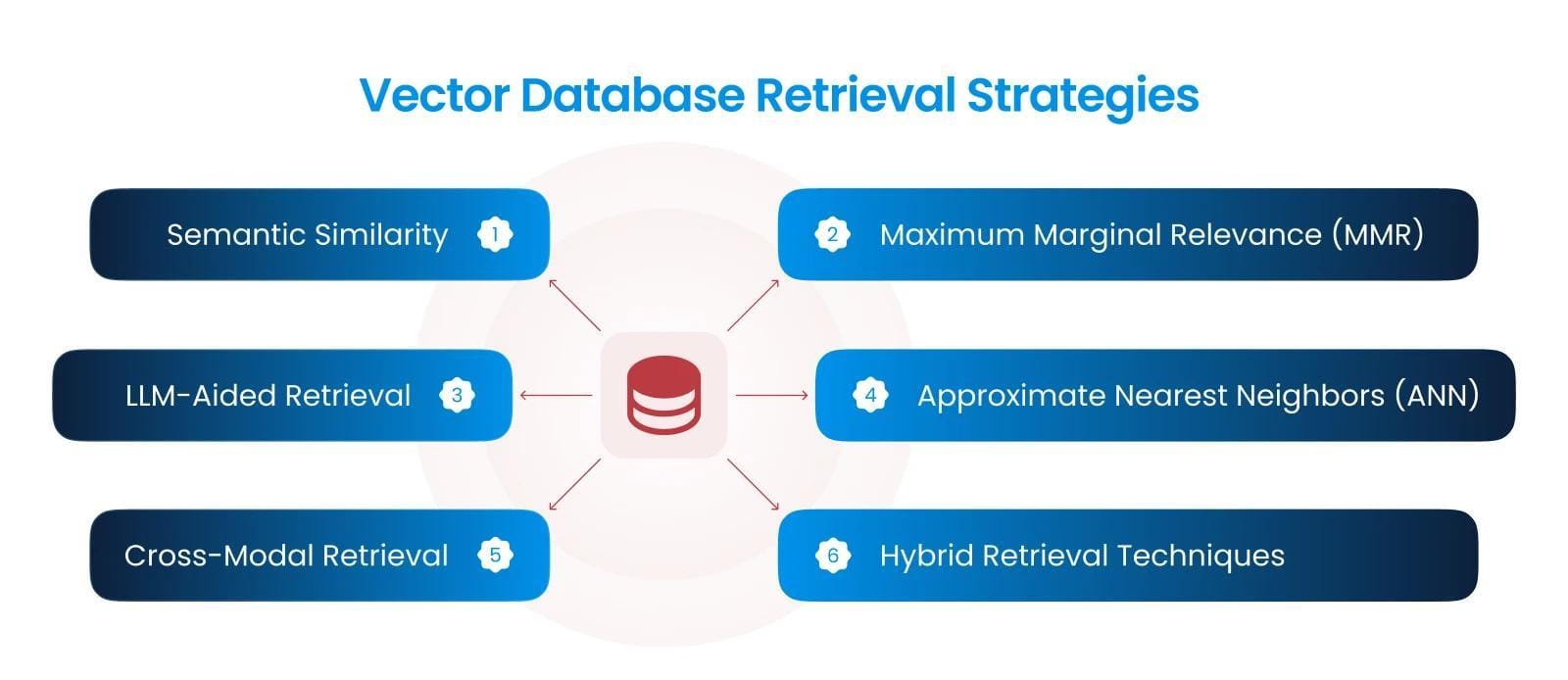
Adaptive Retrieval Techniques
Adaptive retrieval thrives on its ability to dynamically tailor query handling, a capability that transforms static systems into responsive, context-aware engines.
At its core, this technique leverages real-time query refinement, where retrieval parameters evolve based on user feedback and interaction patterns. This adaptability ensures that even nuanced or evolving queries yield relevant and diverse results.
One standout mechanism is the query classifier, which categorizes user inputs into factual, analytical, or contextual types.
By aligning retrieval strategies with query intent, systems can prioritize precision for factual queries while broadening scope for exploratory ones. For instance, IBM’s modular RAG architecture integrates adaptive retrieval to fine-tune responses in legal and medical domains, where precision and contextual depth are paramount.
However, adaptive retrieval is not without challenges. Overfitting to user feedback can skew results, creating a feedback loop that amplifies biases.
Addressing this requires balancing real-time adjustments with safeguards like contextual embeddings, which anchor retrieval in a broader semantic framework.
By integrating adaptive techniques, organizations unlock a retrieval process that not only answers queries but also anticipates the complexities of user intent, fostering richer, more actionable insights.
Semantic Search Optimization
Semantic search optimization hinges on the delicate interplay between contextual embeddings and adaptive re-ranking, transforming how systems interpret and prioritize information.
At its core, this approach ensures that search engines retrieve relevant results and surface nuanced perspectives that might otherwise be overlooked.
One critical technique involves fine-tuning vector embeddings to align with domain-specific language.
For instance, in legal research, embeddings trained on case law terminology outperform general-purpose models by capturing subtle distinctions in legal phrasing.
Adaptive re-ranking further enhances this precision, which dynamically adjusts result order based on query intent and user interaction patterns.
Together, these methods create a feedback loop that refines relevance without sacrificing diversity.
However, challenges arise when embeddings are miscalibrated, leading to overemphasising dominant patterns. Addressing this requires integrating knowledge graphs, which provide a structured framework to anchor semantic relationships.
For example, in healthcare, combining embeddings with a graph of medical terms ensures that more common conditions do not overshadow rare but critical diagnoses.
By blending these techniques, organizations can achieve a balance between precision and inclusivity, enabling systems to deliver insights that are both actionable and comprehensive.
Balancing Techniques in RAG Systems
Balancing relevance and diversity in Retrieval-Augmented Generation (RAG) systems requires a nuanced interplay of methodologies beyond surface-level optimization.
One critical approach is dynamic thresholding, where retrieval algorithms adjust relevance scores in real-time to include less dominant but contextually significant data.
Another innovative technique is multi-objective optimization, which simultaneously evaluates relevance and diversity as competing yet complementary goals. This method employs Pareto efficiency to ensure no improvement in one metric comes at the expense of the other.
A common misconception is that increasing diversity inherently reduces relevance. However, evidence from IBM’s modular RAG architecture shows that integrating contextual embeddings with knowledge graphs can enhance both dimensions.
This synergy ensures that rare insights are not overshadowed, fostering precise and comprehensive outputs.
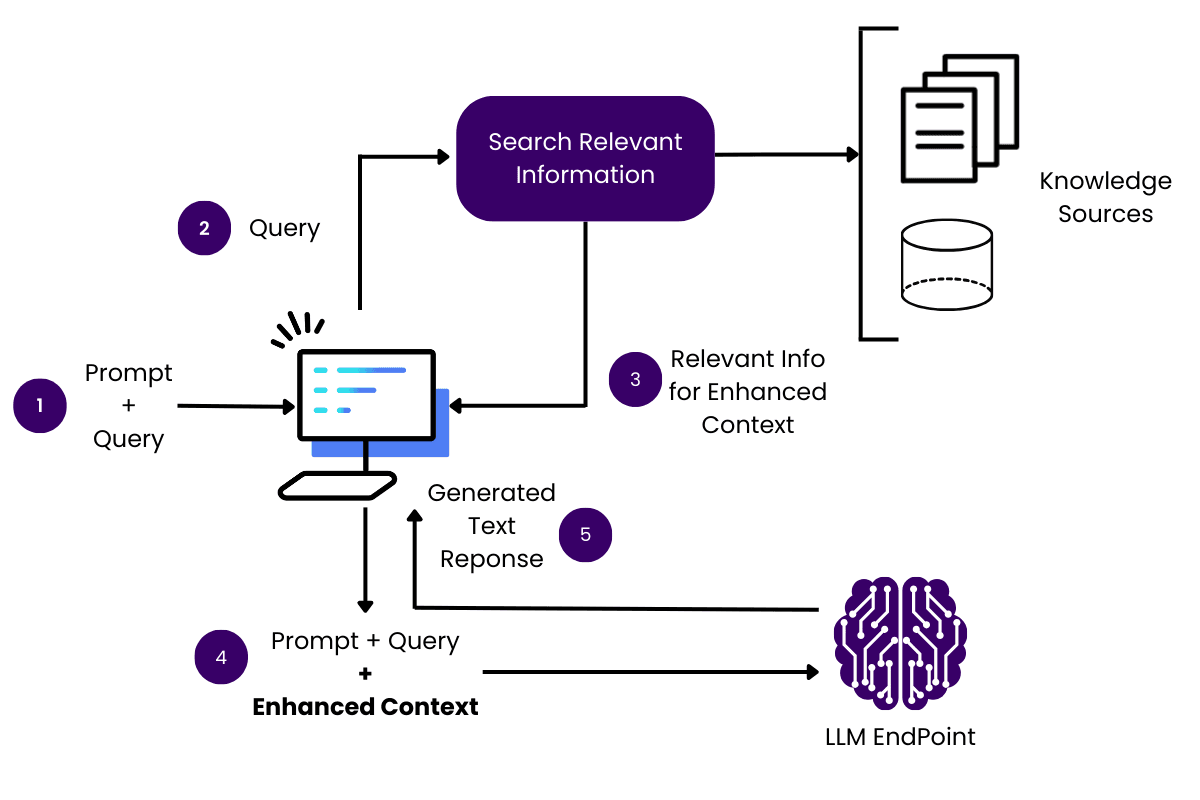
Iterative Optimization Processes
Iterative optimization in RAG systems operates as a dynamic recalibration, where each cycle refines the balance between relevance and diversity.
This process is about improving retrieval precision and uncovering latent insights that static methods often miss.
By iteratively adjusting retrieval parameters, such as contextual weighting or diversity thresholds, systems can adapt to the evolving complexity of user queries.
One compelling technique is feedback-driven re-ranking, where user interactions guide subsequent iterations.
For instance, a legal research platform might initially retrieve precedent-heavy cases but, through iterative refinement, surface underrepresented rulings that align with nuanced legal arguments. This approach ensures that the system evolves in real-time, responding to both explicit and implicit user needs.
However, iterative processes are not without challenges.
Overfitting to user feedback can inadvertently amplify biases, particularly in domains with skewed data distributions.
To mitigate this, integrating multi-layered embeddings—anchoring retrieval in broader semantic contexts—can prevent the system from narrowing its focus excessively.
A notable application of this methodology is seen in healthcare RAG systems, where iterative optimization has identified rare but critical diagnostic patterns.
By continuously refining retrieval outputs, these systems enhance accuracy and foster trust, as users see their queries reflected in increasingly nuanced results. This iterative dance between relevance and diversity transforms RAG systems into adaptive, context-aware tools.
Vendi-RAG Framework Analysis
The Vendi Score (VS) is the cornerstone of Vendi-RAG’s ability to balance diversity and relevance in document retrieval.
Unlike traditional metrics that prioritize frequency or surface-level similarity, the VS leverages eigenvalues from a normalized kernel similarity matrix to quantify semantic diversity.
This approach ensures retrieved documents represent a broad spectrum of perspectives, even when initial queries are narrowly defined.
This mechanism is particularly effective in multi-hop reasoning tasks, where connecting disparate pieces of information is critical.
By encoding the “effective number” of unique documents, the VS prevents redundancy and promotes the inclusion of outlier data points that might otherwise be overlooked.
For example, in a legal research context, this could mean surfacing precedent cases from less-cited jurisdictions, enriching the depth of analysis.
However, the VS is not without its challenges. Its reliance on eigenvalue computation introduces computational overhead, which can be a bottleneck in large-scale applications.
Additionally, the metric’s sensitivity to parameter tuning, such as the diversity parameters, requires careful calibration to avoid diluting relevance.
In practice, the VS has shown remarkable adaptability.
For instance, in experiments with HotpotQA, iterative adjustments to the diversity parameter allowed the system to refine its retrieval strategy dynamically, achieving nuanced outputs that static methods could not replicate.
This underscores the VS’s potential to redefine how retrieval systems approach complexity.
FAQ
What are the key strategies for balancing relevance and diversity in RAG knowledge retrieval systems?
Balancing relevance and diversity in RAG systems involves methods like Maximum Marginal Relevance, entity mapping, salience analysis, and adaptive retrieval. These techniques work together to prioritize accuracy while including diverse, contextually useful information.
How do entity relationships and salience analysis improve document selection in RAG frameworks?
Entity relationships connect related concepts across documents, while salience analysis ranks content based on importance to the query. Together, they help RAG systems select relevant and varied documents, improving the quality and depth of retrieved responses.
What role does co-occurrence optimization play in enhancing diversity without compromising relevance?
Co-occurrence optimization tracks how often terms appear together, revealing less frequent but meaningful data. It adds diversity by surfacing underused terms while salience analysis keeps results aligned with query intent, maintaining both coverage and focus.
How can adaptive retrieval techniques address the challenges of balancing precision and recall in RAG systems?
Adaptive retrieval adjusts real-time retrieval settings based on query type and user feedback. It uses entity mapping and salience scoring to balance precision with recall, helping RAG systems return exact and varied results across complex queries.
What are the best practices for integrating diverse data formats while maintaining contextual relevance in RAG pipelines?
To integrate varied data formats, RAG systems use normalization, salience scoring, and entity recognition. Co-occurrence signals help align different sources, while adaptive indexing maintains context, ensuring relevance across structured and unstructured inputs.
Conclusion
Balancing relevance and diversity in RAG knowledge retrieval is key to building systems that reflect the complexity of real-world data.
By combining adaptive retrieval, entity mapping, and salience-aware scoring, RAG systems can move beyond surface-level matches to deliver results that are both accurate and broad in scope.
This balance supports better outcomes in research, legal reasoning, and decision-making, where the cost of missing a critical detail is high.