
Best Open-Source Re-Ranker Tools for Improved RAG Accuracy
Re-rankers enhance RAG by improving the relevance of retrieved results. This guide reviews the best open-source re-ranker tools, comparing features and performance to help you choose the right solution for more accurate and effective AI retrieval.


When a Retrieval-Augmented Generation (RAG) system misses the mark, it’s rarely the fault of the language model.
The real gap often lies in how the system ranks its retrieved documents.
A weak re-ranker can surface results that are technically related but contextually useless — and that’s a problem when you’re working with legal evidence, clinical trials, or customer-facing answers.
That’s where the best open-source re-ranker tools for improved RAG accuracy come in. These tools don’t just score documents — they understand context, disambiguate meaning, and adapt to domain-specific language.
Whether you’re building for healthcare, finance, or e-commerce, getting the re-ranking layer right is what turns a decent RAG system into a dependable one.
In this guide, we’ll explore the top open-source re-rankers, how they work, and how they can boost RAG accuracy without slowing you down.
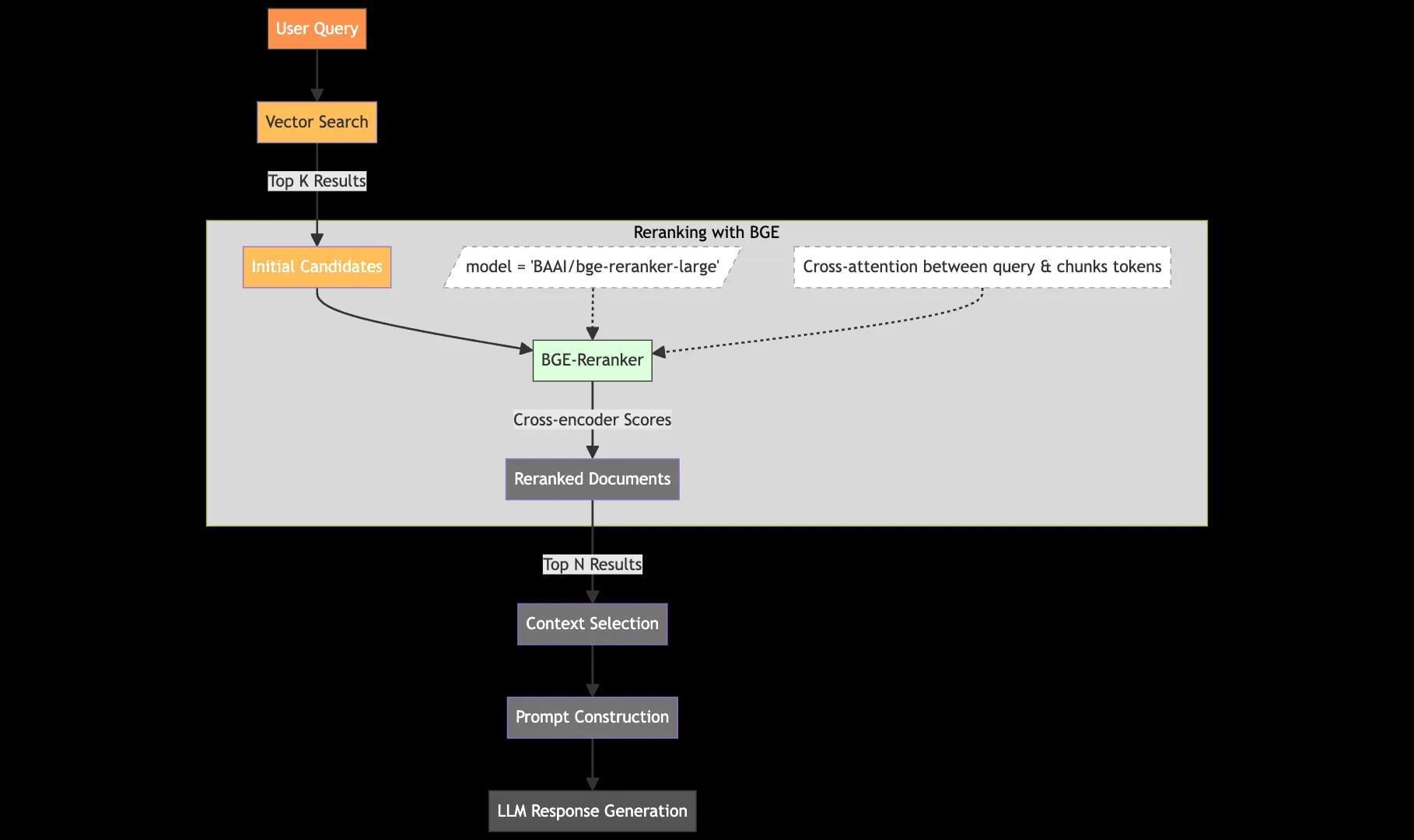
Role of Re-Rankers in Information Retrieval
Re-rankers excel in bridging the gap between initial retrieval and user intent by leveraging semantic precision.
One critical aspect often overlooked is their ability to resolve query ambiguity through contextual coherence.
Unlike basic retrieval systems that treat documents as isolated entities, advanced re-rankers evaluate how well documents complement each other, ensuring cohesive and authoritative responses.
This process hinges on neural models like BERT-based cross-encoders, which analyze query-document pairs holistically.
By scoring documents based on their semantic alignment, these models prioritize relevance while filtering out noise.
However, their computational intensity poses challenges in real-time applications. A hybrid approach, combining lightweight retrievers with selective re-ranking, mitigates this trade-off, balancing speed and precision.
Key Concepts: Embedding Models and Vector Similarity
Embedding models revolutionize information retrieval by mapping language into a shared vector space, where semantic relationships are quantified through proximity.
This transformation allows systems to interpret queries beyond literal keywords, capturing nuanced intent and contextual depth.
The cornerstone of this process is vector similarity, often calculated using metrics like cosine similarity, which determines how closely a query vector aligns with document vectors.
The real power of embedding models lies in their adaptability.
Fine-tuning these models on domain-specific data enhances their ability to discern subtle distinctions, such as differentiating between legal terminologies or medical jargon.
However, this precision comes with challenges.
For instance, embeddings can oversimplify complex documents when chunked into smaller segments, potentially losing critical context. Addressing this requires balancing granularity with coherence during preprocessing.
A practical example is the use of ColBERT in e-commerce, where fine-tuned embeddings improved product recommendation accuracy by aligning user queries with detailed product reviews.
This demonstrates how embedding models, when optimized, bridge the gap between abstract queries and actionable insights, reshaping the retrieval landscape.
Exploring Open-Source Re-Ranker Tools
Open-source re-rankers have redefined how Retrieval-Augmented Generation (RAG) systems achieve precision, offering unparalleled flexibility and transparency.
Tools like Hugging Face’s Sentence-BERT exemplify this shift, enabling developers to fine-tune models for domain-specific tasks.
For instance, Sentence-BERT has been adapted in academic research to prioritize peer-reviewed papers, reducing irrelevant retrievals in pilot studies.
What sets open-source re-rankers apart is their adaptability. Unlike closed-source counterparts, they allow direct inspection and modification of underlying algorithms.
This fosters innovation, as seen with the Cohere Re-Ranker, which integrates seamlessly into hybrid pipelines, balancing dense retrieval with semantic re-ranking.
However, misconceptions persist. Many assume open-source tools are inherently less efficient.
In reality, advancements like sparse embeddings and quantized models have significantly reduced computational overhead.
Think of these tools as modular components in a larger system—each piece optimized for a specific role, ensuring both scalability and precision.
The implications are clear: open-source re-rankers empower organizations to tailor solutions without vendor lock-in, driving both innovation and cost-efficiency.
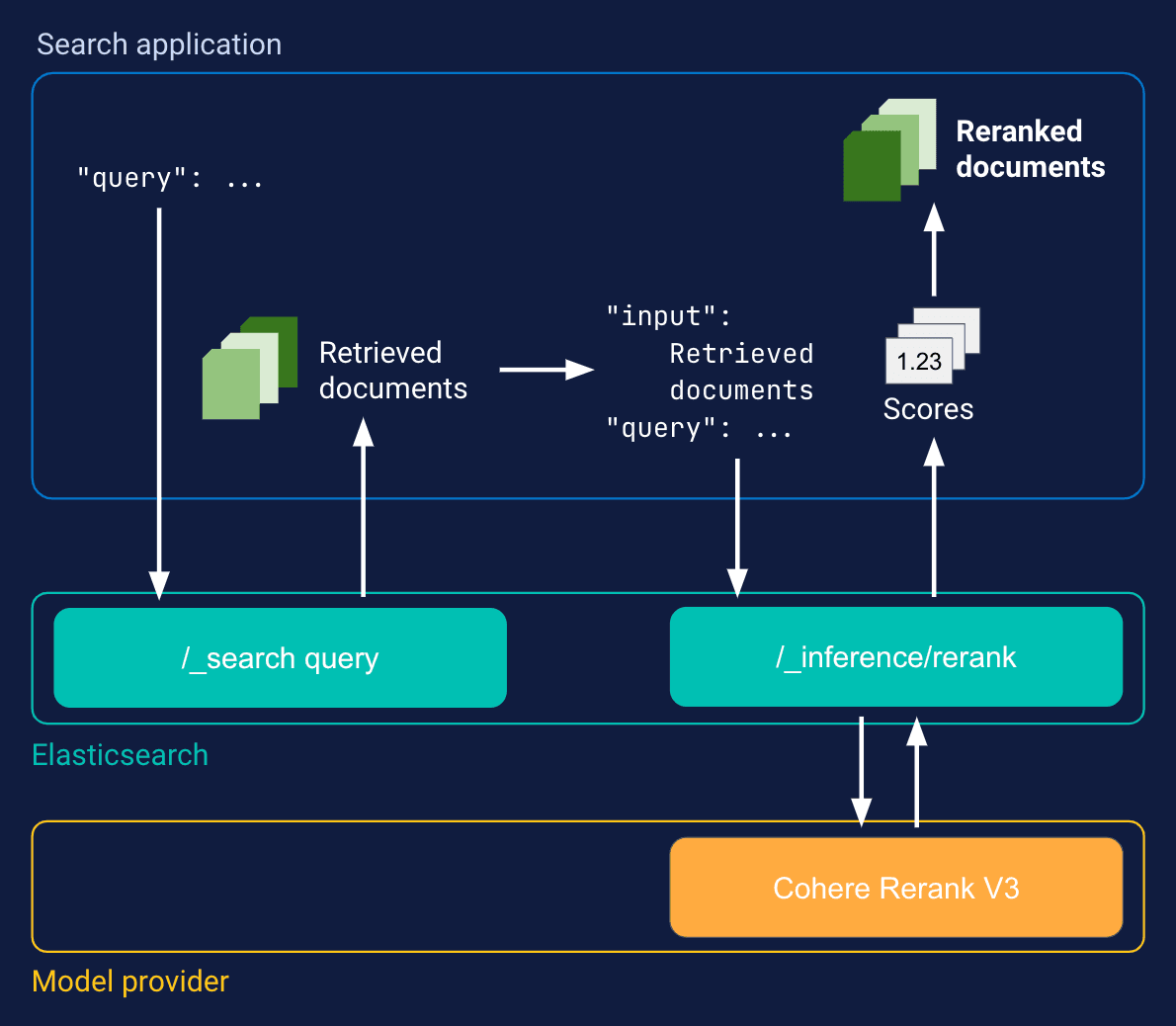
BERT-Based Re-Rankers: Deep Contextual Understanding
BERT-based re-rankers excel in capturing the intricate interplay between queries and documents, leveraging their bidirectional transformer architecture to model context with exceptional granularity.
This capability is particularly transformative in domains where subtle linguistic nuances dictate relevance, such as legal or medical information retrieval.
What sets BERT apart is its ability to process query-document pairs holistically, ensuring that semantic relationships are not lost in isolation.
For instance, when fine-tuned on domain-specific datasets, BERT can discern the intent behind ambiguous queries, aligning results with user expectations.
However, this precision comes with computational demands, making it essential to optimize deployment strategies.
A notable implementation is the Co-BERT model, which introduces groupwise scoring to incorporate cross-document interactions.
By modeling ranking contexts collectively, Co-BERT enhances relevance without significantly increasing computational overhead.
This approach has proven effective in large-scale benchmarks like TREC, outperforming traditional BERT-based re-rankers.
Despite its strengths, BERT’s reliance on extensive fine-tuning and high resource consumption highlights the need for hybrid systems.
Pairing BERT with lightweight retrievers balances precision and efficiency, ensuring scalability in real-world applications. This synergy underscores the importance of strategic integration in maximizing BERT’s contextual prowess.
Lightweight Alternatives for Efficient Re-Ranking
Lightweight re-rankers excel by balancing computational efficiency with contextual precision, making them indispensable for real-time applications.
These models often rely on optimized architectures, such as sparse embeddings or compact transformer variants, to reduce latency without sacrificing relevance.
Their design prioritizes speed, enabling seamless integration into high-demand systems like e-commerce or customer support platforms.
One standout technique is the use of inference-time model compression, which minimizes resource consumption by distilling knowledge from larger models into smaller, faster ones.
For instance, RankZephyr employs this approach to achieve competitive performance while operating at a fraction of the computational cost.
This method accelerates processing and ensures scalability across diverse hardware environments, from cloud GPUs to edge devices.
However, lightweight models face challenges in handling complex, multi-faceted queries.
Their reduced capacity can lead to oversimplified rankings, particularly in domains requiring deep contextual understanding.
Addressing this limitation often involves hybrid systems, where lightweight re-rankers handle the bulk of queries, while more robust models are reserved for edge cases.
Organizations can achieve a pragmatic balance between performance and precision by strategically deploying lightweight alternatives, ensuring robust user experiences without overburdening infrastructure.
Domain-Specific Implementations and Their Impact
When re-rankers are tailored to domain-specific datasets, their ability to interpret nuanced queries transforms dramatically.
This customization allows them to capture the intricate language and context unique to specialized fields, such as healthcare or legal research, where precision is paramount.
A key mechanism behind this success is domain-specific fine-tuning. By training models on curated datasets, re-rankers learn to prioritize contextually relevant information while filtering out noise.
For example, in healthcare, re-rankers trained on clinical trial data can surface the most recent and evidence-based studies, directly impacting decision-making.
This contrasts with general-purpose models, which often fail to distinguish between outdated and cutting-edge research.
However, the effectiveness of domain-specific re-rankers depends heavily on the quality of the training data. Poorly curated datasets can introduce biases, leading to skewed rankings. Addressing this requires rigorous data audits and iterative feedback loops to refine model performance.
In practice, these implementations bridge the gap between user intent and actionable insights, ensuring retrieval systems deliver relevant and contextually precise results. This alignment is what makes domain-specific re-rankers indispensable in high-stakes industries.
Integration of Re-Rankers in RAG Pipelines
Integrating re-rankers into Retrieval-Augmented Generation (RAG) pipelines is akin to refining raw ore into polished metal—each step enhances precision and usability.
At its core, this process involves embedding re-rankers as a secondary layer that evaluates and reorders retrieved documents based on semantic relevance.
Unlike initial retrieval, which casts a wide net, re-rankers act as precision tools, ensuring that only the most contextually aligned documents are prioritized.
One critical insight is the role of hybrid architectures.
By combining lightweight retrievers, such as Dense Passage Retrieval (DPR), with computationally intensive cross-encoders like BERT, systems achieve a balance between speed and accuracy.
A common misconception is that re-rankers are computational bottlenecks. However, techniques like model quantization and sparse embeddings have significantly mitigated these concerns.
Ultimately, successful integration hinges on aligning re-ranker configurations with domain-specific needs, ensuring that RAG systems deliver not just relevant but actionable insights.
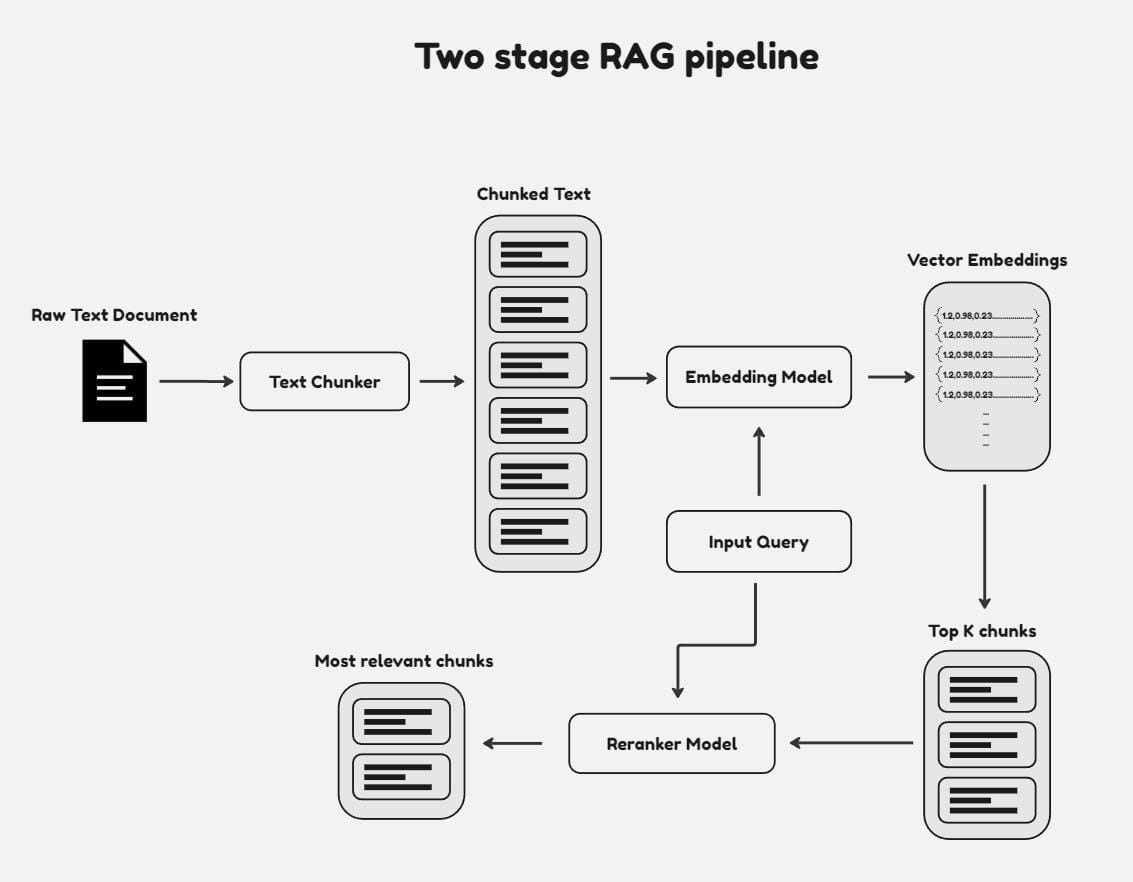
Enhancing Retrieval Quality with Re-Rankers
Re-rankers excel at addressing a critical challenge in RAG pipelines: the gap between initial retrieval and true user intent.
While retrievers cast a wide net, re-rankers act as precision instruments, refining results to ensure contextual alignment.
One particularly effective technique is multi-pass retrieval, where an initial retriever generates a broad set of candidates, and a re-ranker, such as a BERT-based cross-encoder, evaluates these candidates for semantic relevance.
The strength of this approach lies in its ability to resolve query ambiguity. For instance, a query like “Apple” could refer to the fruit or the company.
A re-ranker trained on contextual embeddings can dynamically prioritize results based on subtle cues, such as co-occurring terms or metadata.
However, this precision comes with computational trade-offs, as cross-encoders are resource-intensive.
Techniques like sparse embeddings or model quantization mitigate these challenges, enabling scalable deployment.
In practice, organizations like Zendesk have leveraged re-rankers to enhance customer support systems, ensuring that responses are relevant and contextually precise.
This demonstrates how re-rankers, when fine-tuned and strategically integrated, elevate the quality of retrieval systems, making them indispensable in high-stakes applications.
Balancing Speed and Accuracy in Re-Ranking
Achieving the right balance between speed and accuracy in re-ranking requires a nuanced approach beyond simply optimizing for one metric.
The interplay between lightweight retrievers and computationally intensive re-rankers is central to this dynamic.
Lightweight models, such as BM25 or dense retrievers, excel at quickly narrowing down a large dataset, but they often lack the semantic depth needed for nuanced queries.
This is where re-rankers, like BERT-based cross-encoders, refine the results by evaluating deeper contextual relationships.
One critical technique is the hybrid pipeline, where retrievers handle the initial filtering, and re-rankers focus on the top-k candidates.
This layered approach minimizes latency while preserving precision.
However, real-world data introduces challenges such as noisy inputs or domain-specific jargon, which can skew results. Fine-tuning re-rankers on domain-specific datasets mitigates these issues, ensuring alignment with user intent.
Practical implementations, such as in customer support systems, demonstrate how this balance enhances user satisfaction.
Organizations can maintain responsiveness without sacrificing relevance by dynamically adjusting re-ranking thresholds based on query complexity, showcasing the adaptability of well-integrated pipelines.
Performance Metrics and Optimization Techniques
Evaluating re-rankers demands precision, as the metrics chosen directly influence system behavior and user satisfaction.
Metrics like Normalized Discounted Cumulative Gain (NDCG) and Mean Reciprocal Rank (MRR) are indispensable for quantifying ranking quality, but their true value emerges when paired with domain-specific insights.
For instance, in e-commerce, NDCG at higher cutoffs (e.g., NDCG@10) often reveals how well a system balances relevance with diversity, a critical factor for user engagement.
Optimization techniques, such as knowledge distillation, allow smaller models to inherit the semantic depth of larger counterparts, reducing latency without sacrificing accuracy.
A practical example is the use of quantized BERT models, which achieve near-parity with full-scale versions while operating at a fraction of the computational cost. This trade-off is particularly impactful in real-time applications like customer support, where milliseconds matter.
Ultimately, aligning metrics with optimization strategies ensures re-rankers deliver not just relevance but actionable, context-aware results.
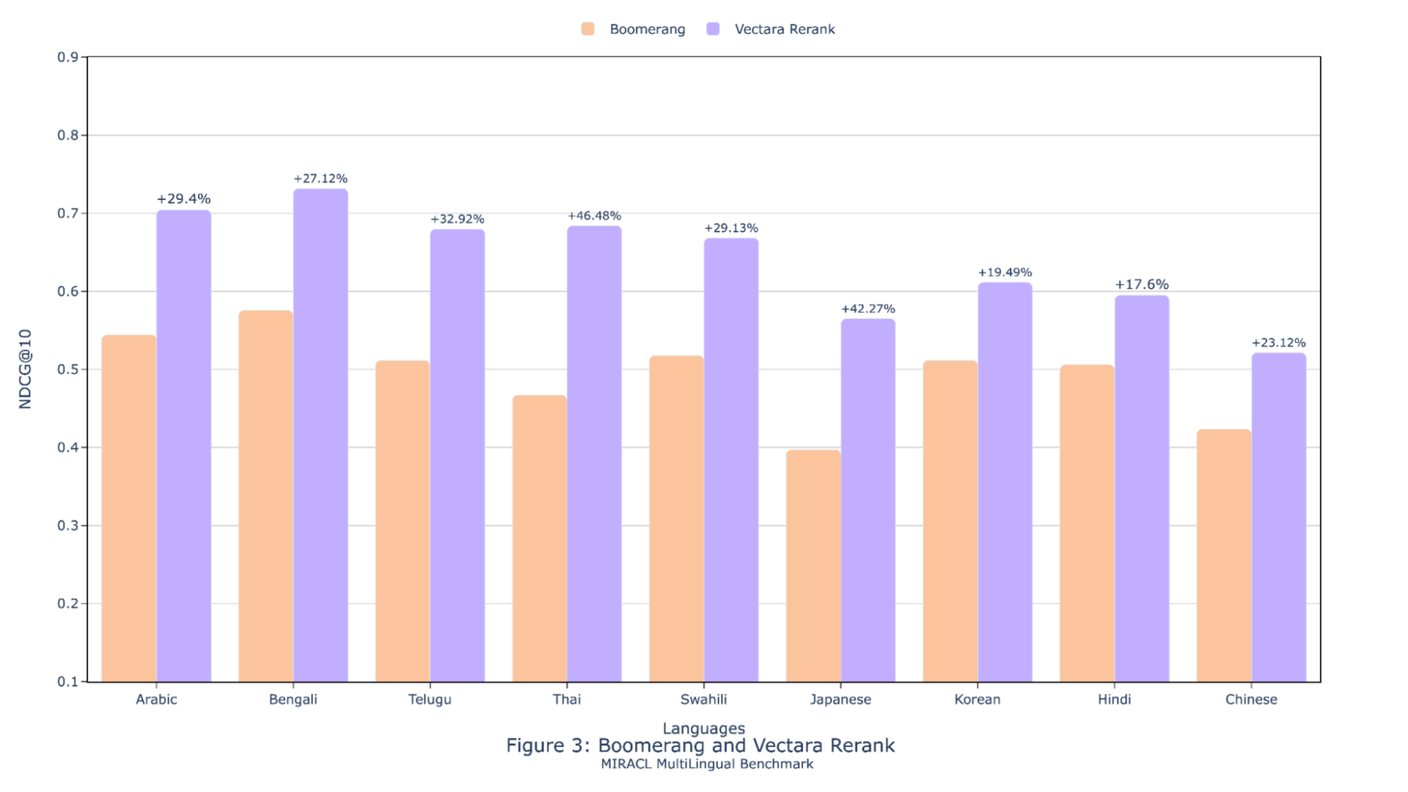
Evaluating Re-Ranker Effectiveness: Hit Rates and MRR
Hit rates and Mean Reciprocal Rank (MRR) serve distinct yet complementary roles in evaluating re-ranker performance.
While hit rates measure whether relevant items appear within a predefined range, MRR focuses on the rank of the first relevant item, offering a nuanced view of ranking quality.
This distinction is critical in applications like question-answering systems, where both metrics must align to ensure user satisfaction.
The interplay between these metrics becomes evident when optimizing retrieval pipelines.
For instance, a high hit rate might indicate that relevant items are being retrieved, but without a strong MRR, these items may be buried too deep in the ranking to be useful.
This dynamic underscores the importance of balancing breadth (hit rate) with precision (MRR).
Techniques like multi-pass retrieval, where lightweight retrievers generate candidates and re-rankers refine them, exemplify this balance.
A practical example is in customer support systems, where optimizing for MRR ensures that the most relevant solutions are immediately accessible, reducing resolution times.
By integrating these metrics into iterative feedback loops, organizations can fine-tune their systems to deliver both comprehensive and contextually precise results, enhancing overall user experience.
Fine-Tuning and Performance Optimization Strategies
Fine-tuning re-rankers is less about brute force and more about precision—like calibrating a lens to bring a blurry image into sharp focus.
One often-overlooked technique is curriculum learning, where models are trained on progressively complex datasets.
This approach mirrors how humans learn, starting with foundational concepts before tackling nuanced scenarios.
By structuring training data hierarchically, re-rankers can better adapt to domain-specific subtleties, such as legal jargon or medical terminology.
The choice of hyperparameters, particularly learning rates and batch sizes, plays a pivotal role in this process.
A learning rate that’s too high risks overshooting optimal weights, while one that’s too low prolongs convergence.
Similarly, batch sizes influence the model’s ability to generalize; smaller batches capture fine-grained patterns but may introduce noise, whereas larger ones smooth out variability at the cost of detail.
Striking the right balance requires iterative experimentation and domain-specific insights.
A practical example is in financial services, where fine-tuned re-rankers prioritize regulatory compliance documents over general market analysis.
This demonstrates how tailored optimization transforms re-rankers into indispensable assets for specialized applications.
FAQ
What are the best open-source re-ranker tools to improve RAG accuracy?
Top open-source re-rankers for RAG accuracy include bge-ranker-base, ColBERT, SWIRL, and AutoRAG. These tools use entity alignment, co-occurrence optimization, and domain fine-tuning to improve retrieval relevance and reduce ranking errors.
How do entity relationships and salience analysis improve open-source re-rankers?
Entity relationships connect queries with key concepts in documents, while salience analysis highlights important content. Together, they help re-rankers filter out irrelevant data and return contextually accurate results in complex or ambiguous information retrieval tasks.
Why is co-occurrence optimization important for selecting a RAG re-ranker?
Co-occurrence optimization improves re-ranker selection by identifying term patterns between queries and documents. This boosts semantic accuracy and helps re-rankers select content aligned with user intent, especially in multi-topic or vague search queries.
Which open-source re-rankers work best for legal or healthcare RAG systems?
Sentence-BERT, Cohere Re-Ranker, and ColBERT perform well for legal and healthcare RAG tasks. Their domain-tuned models and co-occurrence handling allow them to prioritize relevant studies or legal citations with greater accuracy than general-purpose re-rankers.
What are the top metrics and practices for evaluating RAG re-ranker accuracy?
Effective metrics include nDCG, MRR, and Precision@K. Combining these with domain-specific testing, salience tracking, and co-occurrence analysis helps evaluate if a re-ranker accurately ranks documents and meets the intent of RAG retrieval tasks.
Conclusion
Open-source re-ranker tools improve RAG accuracy by refining initial retrievals into context-aware results.
With tools like ColBERT, SWIRL, and bge-ranker-base, and techniques such as salience analysis and entity mapping, teams can build retrieval pipelines that are both efficient and precise.
As RAG systems expand across industries, the right re-ranking strategy is not optional—it’s essential for delivering reliable output.