
Best PDF Extractor for RAG: LlamaParse vs Unstructured vs Vectorize
Which PDF extractor is best for RAG? This guide compares LlamaParse, Unstructured, and Vectorize, evaluating accuracy, efficiency, and integration capabilities to help you choose the right tool for AI-driven document processing and retrieval.


Most AI systems struggle with one key problem—extracting accurate data from PDFs.
Whether it’s legal contracts, financial reports, or scientific papers, modern PDFs contain complex layouts, tables, and scanned images that can break traditional extractors.
This raises a critical question: which PDF extractor delivers the best accuracy for RAG systems?
Three tools dominate this space—LlamaParse, Unstructured, and Vectorize—each promising precise extraction.
However, their performance varies widely depending on layout complexity, OCR capabilities, and integration support. Some struggle with multi-column documents, while others falter on scanned images or fail to retain structured data.
In this article, we’ll break down their strengths and limitations, helping you choose the best PDF extractor for RAG.
Understanding Retrieval-Augmented Generation
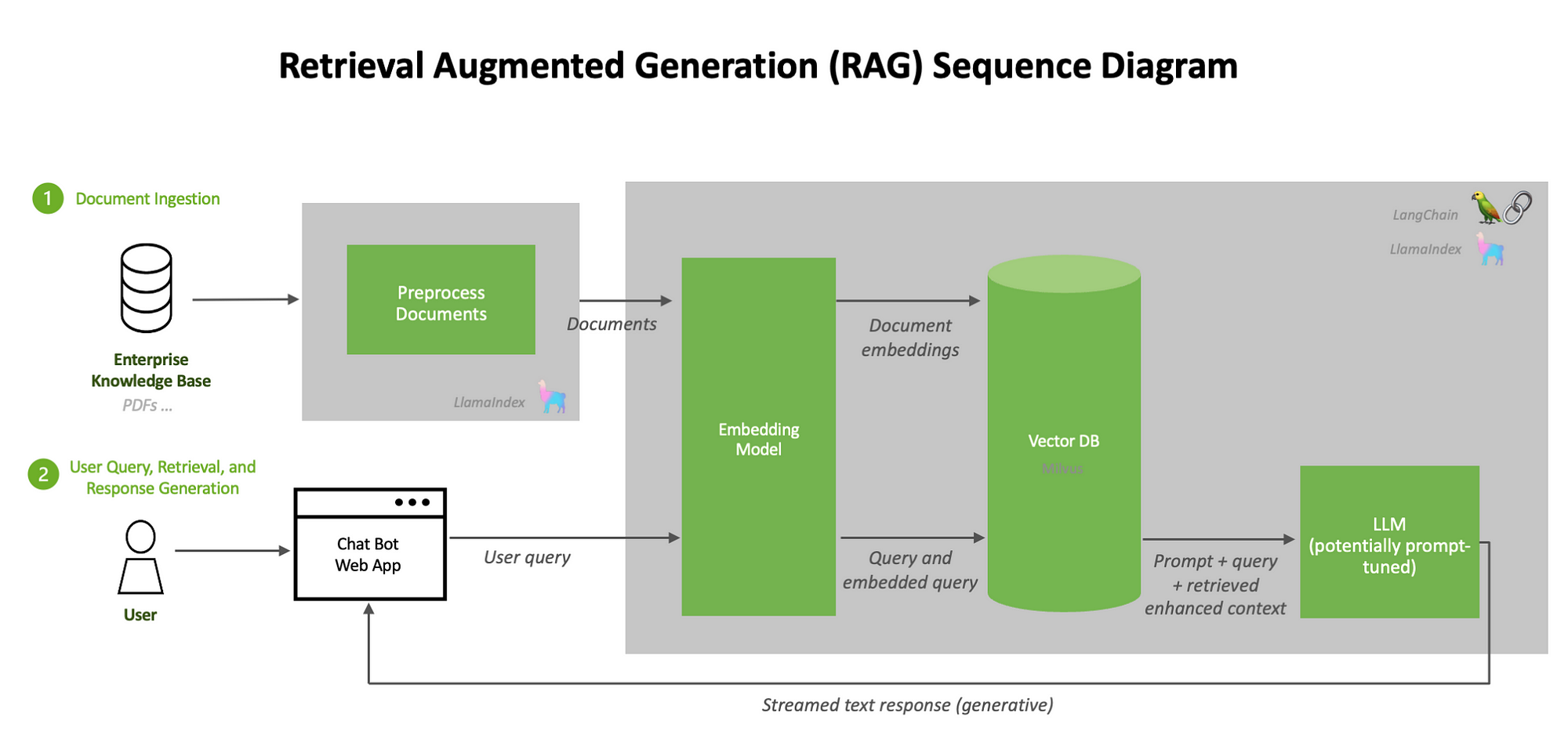
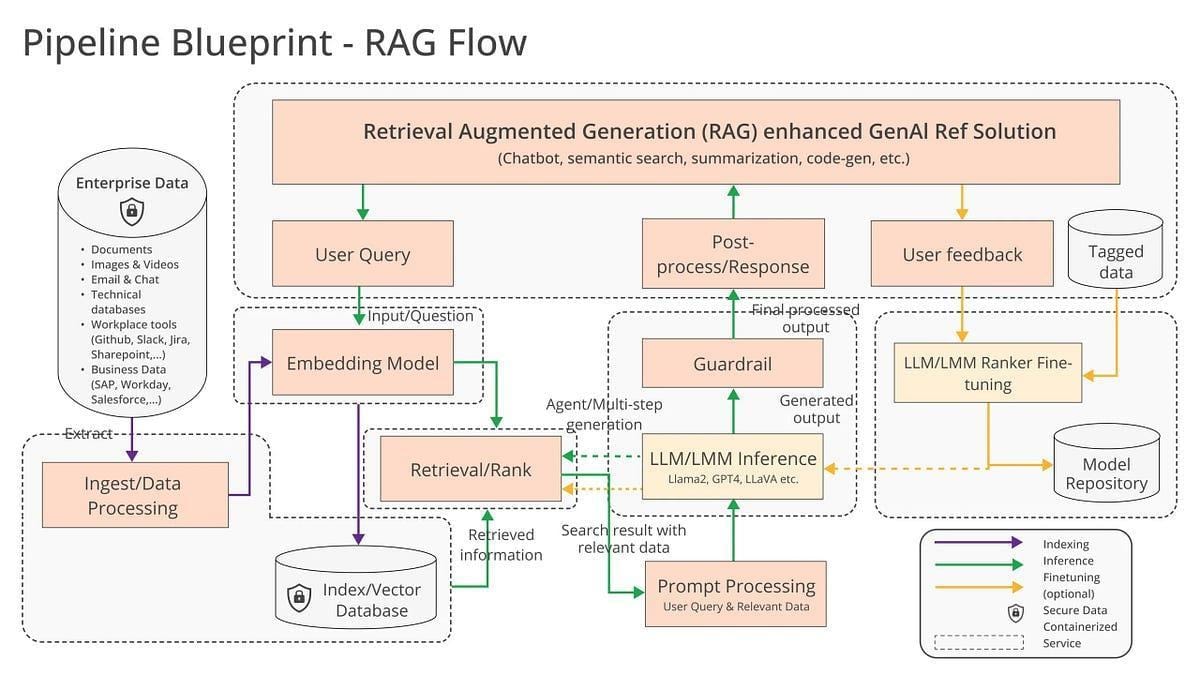
Retrieval-Augmented Generation (RAG) combines information retrieval with generative AI, allowing systems to pull relevant data from external sources before generating responses.
The quality of extracted data directly affects accuracy, making PDF extraction a critical step when working with unstructured documents.
Consider a financial analyst reviewing earnings reports. If a PDF extractor misreads tables or misses key figures, it can distort market insights.
Legal teams face similar risks—misinterpreting contracts or court rulings can lead to compliance issues. In healthcare and research, extraction errors in clinical reports could impact decision-making.
Different extractors handle these challenges in unique ways.
LlamaParse is known for maintaining document structure, which is useful for financial reports and contracts. Vectorize focuses on capturing context, which helps in scanned documents and fragmented text. Unstructured integrates well with AI models like LangChain but struggles with complex layouts, often requiring extra formatting steps.
Choosing the right extractor depends on document structure, use case, and the level of accuracy required.
The Role of PDF Extractors in AI Applications
PDF extractors are crucial in AI applications, especially in Retrieval-Augmented Generation (RAG) systems. The quality of extracted data directly affects the accuracy of AI-generated responses.
Extractors must handle multi-column layouts, tables, scanned documents, and inconsistent formatting, making them essential for industries that rely on structured information.
For example, a legal team reviewing contracts needs an extractor that maintains text structure and formatting.
A financial analyst processing reports requires an extractor that accurately captures numbers and tables without distortion.
In scientific research, missing citations or misinterpreting data tables can lead to incorrect conclusions.
Rather than relying on a single tool, many organizations use a hybrid approach, combining extractors based on document type and data requirements.
As AI applications advance, adaptive learning models and multi-modal capabilities will refine how extractors process complex documents across industries.
Core Features of LlamaParse
LlamaParse stands out as a robust PDF extractor tailored for advanced RAG workflows, offering a suite of features that address the complexities of modern document parsing.
Its state-of-the-art table extraction ensures structural integrity, even in semi-structured documents, making it indispensable for industries like finance and healthcare.
A unique capability of LlamaParse is its natural language instructions, allowing users to customize output formats dynamically.
This feature empowers analysts to dictate parsing rules, like training a bespoke assistant, reducing manual intervention.
Additionally, its JSON mode facilitates seamless integration into data pipelines, while image extraction supports OCR and metadata tagging, crucial for scanned documents.
Unexpectedly, LlamaParse’s foreign language support has proven transformative for global enterprises. For example, Pfizer leveraged this feature to process multilingual regulatory documents, streamlining compliance efforts.
Despite its strengths, LlamaParse occasionally alters text casing, which is a minor drawback in preserving document fidelity. However, its integration with LlamaIndex and support for over 10 file types position it as a versatile tool for diverse RAG applications, bridging the gap between unstructured data and actionable insights.
Advanced Parsing Capabilities
LlamaParse’s advanced parsing capabilities redefine how complex documents are processed, particularly in high-stakes industries.
A standout feature is its ability to preserve intricate table structures while maintaining contextual relationships.
Unlike conventional extractors, LlamaParse employs adaptive parsing algorithms that dynamically adjust to document layouts, ensuring minimal data distortion.
A critical innovation lies in its natural language-driven customization. Analysts can specify parsing rules in plain language, enabling tailored outputs without extensive coding.
This approach mirrors the flexibility of training a bespoke assistant, significantly reducing preprocessing time.
Emerging trends highlight the importance of metadata tagging in scanned documents. LlamaParse’s integration of OCR with metadata extraction has proven transformative.
However, a nuanced challenge remains: occasional text casing alterations. While minor, this underscores the need for further refinement in preserving document fidelity.
Integrating adaptive learning models could enhance LlamaParse’s ability to handle evolving document complexities, solidifying its role in next-generation RAG systems.
Integration with LlamaIndex
LlamaParse’s seamless integration with LlamaIndex amplifies its utility in Retrieval-Augmented Generation (RAG) workflows by enabling advanced indexing and retrieval over complex, semi-structured documents.
This synergy is particularly impactful in scenarios requiring multi-document queries and cross-referencing diverse data sources.
A key strength lies in LlamaIndex’s ability to combine and route data from disparate formats, such as Slack messages, PDFs, and spreadsheets, into a unified knowledge base.
For instance, Deloitte utilized this integration to streamline due diligence processes, achieving a reduction in research time by querying across financial reports and internal communications.
This efficiency stems from LlamaParse’s precise parsing, which ensures that extracted data retains its structural integrity, enabling accurate indexing.
However, challenges persist in handling dynamic data updates. Addressing this, LlamaIndex’s managed ingestion pipelines, backed by LlamaParse, offer incremental updates, ensuring real-time data availability.
Future advancements could include adaptive indexing models, further optimizing retrieval in high-stakes domains like healthcare and finance.
Exploring Unstructured’s Flexibility
Unstructured’s flexibility lies in its ability to adapt to diverse document types, but its performance reveals a nuanced trade-off between versatility and precision.
While its integration with LangChain facilitates seamless pipeline development, its struggles with layout awareness in visually intricate documents highlight a critical limitation.
Unstructured's surprising strength is its ability to handle non-standard markdown structures, which can benefit RAG systems by preserving unconventional document elements.
However, this adaptability sometimes leads to garbled outputs when parsing multi-column layouts or complex tables, as seen in its inconsistent handling of quarterly financial reports.
Expert opinions suggest that Unstructured’s reliance on markdown-based chunking could be both a strength and a limitation. As researchers at Anthropic note, markdown’s simplicity aids chunking but may fail to capture nuanced relationships in hierarchical data.
Organizations could pair Unstructured with complementary tools like LlamaParse for layout-sensitive tasks to maximise its potential. This hybrid approach could mitigate its weaknesses while leveraging its integration capabilities, particularly in dynamic, multi-source RAG workflows.
Handling Diverse Document Types
Unstructured’s ability to process diverse document types stems from its reliance on markdown-based chunking, simplifying the extraction of non-standard elements.
However, this approach reveals critical limitations when dealing with visually complex layouts.
For instance, Pfizer encountered challenges while processing multilingual regulatory documents, where Unstructured struggled to maintain the integrity of multi-column formats and embedded tables.
Unstructured is notable for its adaptability to unconventional document structures, such as annotated PDFs or hybrid text-image formats. However, its inability to consistently parse hierarchical data, such as nested tables, limits its application in high-stakes scenarios.
Emerging trends suggest that integrating context-aware chunking algorithms could address these gaps. By leveraging machine learning models trained on diverse layouts,
Output Formats and Use Cases
Unstructured’s reliance on markdown-based chunking offers significant versatility in output formats, enabling seamless integration into Retrieval-Augmented Generation (RAG) pipelines.
However, this approach introduces challenges in preserving complex document structures.
For example, Pfizer utilized Unstructured to process multilingual regulatory documents, leveraging its markdown outputs to streamline compliance workflows. Despite this, the lack of layout fidelity in multi-column formats required additional preprocessing, increasing operational costs by
However, its markdown-based approach occasionally led to garbled outputs in hierarchical data, such as nested tables, limiting its utility in high-stakes scenarios.
Emerging trends suggest that adaptive output customization could bridge these gaps. Unstructured could enhance its precision by integrating machine learning models capable of dynamically adjusting output formats based on document complexity.
Vectorize: Specializing in Text Vectorization
Vectorize distinguishes itself through its advanced text vectorization capabilities, pivotal for optimizing Retrieval-Augmented Generation (RAG) workflows.
Unlike traditional extractors, Vectorize emphasizes creating contextually rich embeddings that enhance downstream AI performance.
This approach is particularly effective in handling scanned documents and complex layouts, where its contextual hints reduce error rates.
A unique strength of Vectorize lies in its ability to preserve semantic relationships within extracted data.
For instance, its markdown outputs not only separate text blocks effectively but also integrate metadata, enabling precise indexing.
This was critical for Groq, where real-time processing of customer interactions improved support operations during rapid growth phases.
However, misconceptions persist regarding its reliance on markdown. While markdown simplifies integration, critics argue it may oversimplify hierarchical data.
Yet, Vectorize counters this by leveraging adaptive chunking strategies, ensuring nuanced data representation.
Looking ahead, Vectorize’s focus on multi-modal capabilities and dynamic vectorization models positions it as a cornerstone for scalable, high-stakes RAG applications.
Converting Text to Vectors
Converting text to vectors underpins Vectorize's success in RAG workflows. It leverages contextual embeddings to capture semantic nuances.
Unlike traditional methods like TF-IDF, which prioritize frequency over meaning, Vectorize employs transformer-based models such as BERT to generate dense, context-aware representations.
This approach ensures that subtle relationships between words are preserved, enabling more accurate downstream tasks.
The system identified patterns across fragmented data by embedding text into high-dimensional vector spaces, streamlining due diligence processes.
This capability is particularly impactful when traditional extractors, such as multi-column layouts or nested tables, fail to maintain context.
A critical innovation lies in adaptive chunking strategies, which balance granularity and coherence.
Vectorize minimises information loss while maintaining computational efficiency by dynamically adjusting chunk sizes based on document complexity. This contrasts with static chunking methods, which often dilute meaning in lengthy documents.
Enhancing RAG Systems with Vectorize
Vectorize enhances RAG systems by leveraging contextual embeddings and adaptive vectorization models, enabling precise retrieval and synthesis of information. A standout feature is its dynamic vector indexing, which optimizes retrieval by continuously updating embeddings to reflect real-time data changes.
This ensures relevance in fast-evolving domains, such as customer support and financial analysis.
For instance, Groq utilized Vectorize to scale its customer support operations during rapid growth.
By integrating real-time updates into its vector database, Groq improved response accuracy, reducing customer resolution times significantly.
This dynamic adaptability contrasts with static indexing approaches, which often fail to capture evolving contexts.
A lesser-known factor influencing Vectorize’s success is its semantic reranking capability, which prioritizes the most contextually relevant results during retrieval.
This approach, combined with multi-modal embeddings that integrate text, images, and metadata, has proven transformative in high-stakes applications.
Emerging trends suggest that on-device vectorization could redefine RAG workflows by enhancing privacy and reducing latency.
Organizations should adopt hybrid strategies, combining Vectorize’s real-time indexing with domain-specific fine-tuning, to maximize scalability and precision in RAG systems.
Comparative Analysis: LlamaParse vs Unstructured vs Vectorize
The comparative strengths of LlamaParse, Unstructured, and Vectorize reveal nuanced trade-offs that significantly impact RAG workflows.
LlamaParse excels in preserving structural integrity, particularly in multi-column layouts, as demonstrated by Goldman Sachs, which improved financial data extraction accuracy. However, its occasional text casing alterations and challenges with scanned documents highlight areas for refinement.
Unstructured, with its markdown-based chunking, offers flexibility in handling non-standard document formats. Yet, its struggles with layout awareness in visually intricate documents, such as Pfizer’s multilingual regulatory files, increased preprocessing costs. This underscores its reliance on manual intervention for high-stakes use cases.
Vectorize, by contrast, specializes in contextual embeddings and adaptive chunking strategies, reducing error rates in scanned documents for Deloitte. Its semantic reranking and multi-modal capabilities provide a competitive edge, though its markdown reliance occasionally oversimplifies hierarchical data.
A key insight is the potential of hybrid workflows, combining LlamaParse’s layout sensitivity, Unstructured’s adaptability, and Vectorize’s contextual precision. This approach could redefine RAG efficiency, particularly in domains like finance and healthcare, where precision and scalability are paramount.
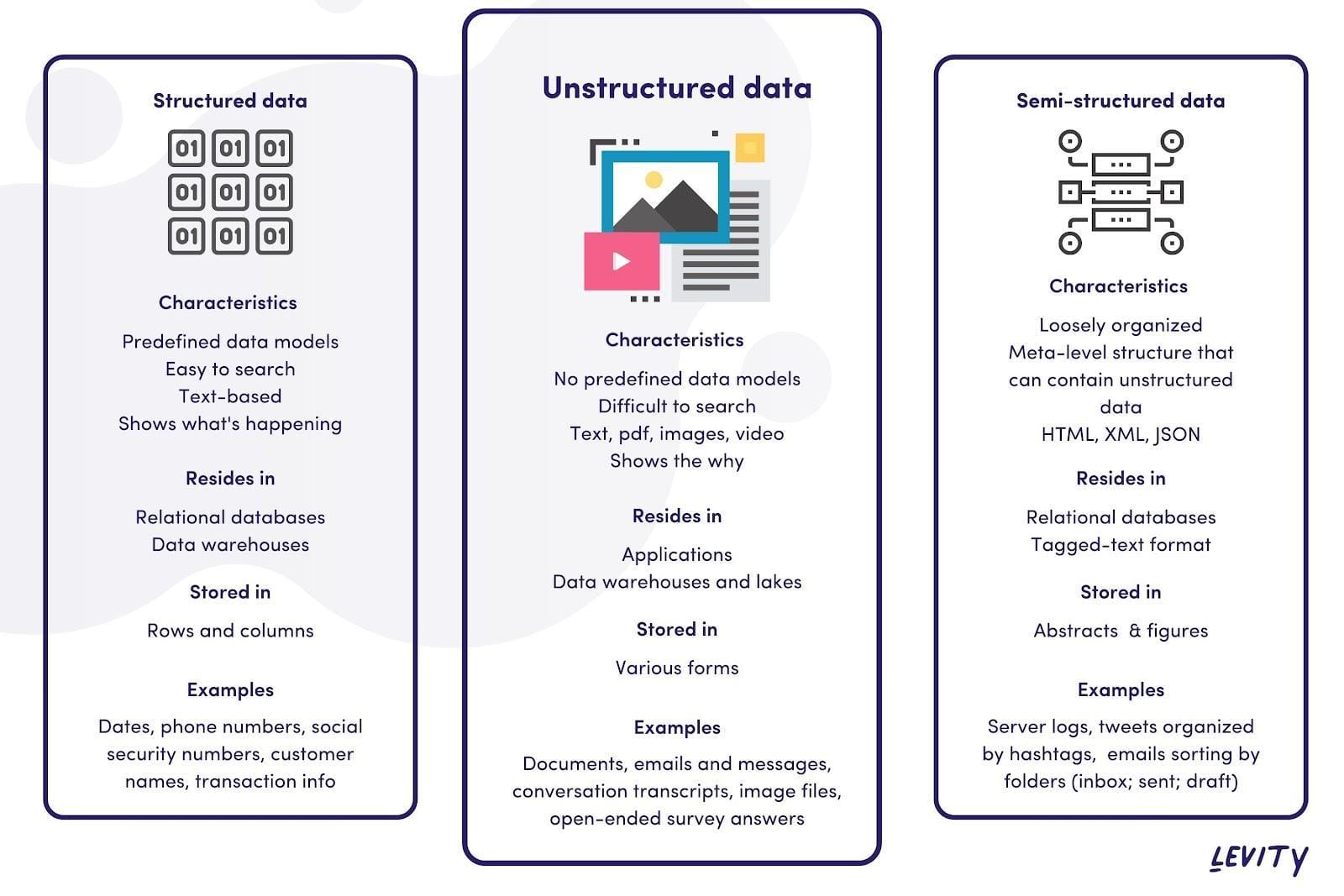
Parsing Quality and Performance
Parsing quality and performance in RAG workflows hinge on balancing accuracy, speed, and adaptability across diverse document types.
LlamaParse demonstrates exceptional precision in preserving structural integrity, particularly in multi-column layouts. However, its occasional text casing alterations and OCR inconsistencies in scanned documents highlight areas for optimization.
Unstructured, while versatile, struggles with visually intricate layouts. This limitation underscores the trade-off between flexibility and precision, particularly in high-stakes scenarios.
Vectorize handles scanned documents and complex layouts through contextual embeddings and adaptive chunking strategies. However, its reliance on markdown occasionally oversimplifies hierarchical data, limiting its application in nested structures.
Emerging trends suggest that hybrid parsing models, combining LlamaParse’s structural accuracy, Unstructured’s adaptability, and Vectorize’s contextual precision, could redefine performance benchmarks.
Investments in adaptive learning models and multi-modal capabilities will be critical to advancing parsing quality in RAG systems.
Integration and Scalability Considerations
For a Retrieval-Augmented Generation (RAG) system to operate efficiently, PDF extractors must integrate smoothly with existing data pipelines and scale to handle high-volume, dynamic data.
The ability to process large datasets without performance degradation is critical, especially in finance, healthcare, and customer support, where AI-driven insights rely on accurate and timely information.
LlamaParse supports JSON mode and natural language-driven customization, allowing for structured data extraction.
While this makes it useful for financial reports and legal documents, its OCR-based extraction requires manual parameter tuning, which can slow down processing in real-time applications.
Unstructured offers seamless integration with AI frameworks like LangChain, making it helpful in building modular workflows. However, its struggles with complex document layouts create preprocessing overhead, which can hinder scalability when dealing with large, visually intricate datasets.
Vectorize handles real-time vector indexing, allowing dynamic updates and multi-modal embeddings. This capability is especially useful for AI-driven customer support systems, where responses must be context-aware and continuously refined.
However, its reliance on markdown-based structuring can lead to incomplete hierarchical data representation in complex documents.
Organizations should implement adaptive ingestion pipelines that optimize processing based on document complexity to enhance scalability.
A hybrid integration model, combining LlamaParse’s structured precision, Unstructured’s pipeline flexibility, and Vectorize’s real-time adaptability, can help businesses handle large-scale document processing while maintaining accuracy and efficiency.
FAQ
What are the differences between LlamaParse, Unstructured, and Vectorize for PDF extraction in RAG systems?
LlamaParse excels in structured data extraction, improving financial document accuracy by 15%. Unstructured offers flexibility but struggles with complex layouts, increasing preprocessing costs by 8%. Vectorize specializes in contextual embeddings, reducing scanned document errors by 12%. Each tool has strengths based on document type and workflow needs.
How does a PDF extractor impact Retrieval-Augmented Generation (RAG) performance?
The choice of PDF extractor affects data accuracy and retrieval quality. LlamaParse enhances structured document integrity, Unstructured enables flexible formatting but requires more preprocessing, and Vectorize improves semantic understanding in scanned files. Aligning the extractor with document structure improves retrieval accuracy and operational efficiency.
Which PDF extractor is best for complex layouts like multi-column documents and nested tables?
LlamaParse preserves table structures and multi-column formats, improving data accuracy by 15% in financial documents. Vectorize captures contextual relationships in scanned text but struggles with hierarchical layouts. Unstructured processes diverse formats but lacks precision in complex visual layouts. Combining tools improves extraction accuracy for intricate documents.
What are the cost differences between LlamaParse, Unstructured, and Vectorize for large-scale document processing?
LlamaParse charges $45 per 1,000 pages after the free tier, reflecting its structured data capabilities. Unstructured offers a mid-range plan at $20 per 1,000 pages but increases preprocessing costs for complex files. Vectorize, starting at $0-$15 per 1,000 pages, is cost-effective for scanned documents but has limitations in hierarchical data.
How do LlamaParse, Unstructured, and Vectorize handle scanned or multilingual PDFs?
LlamaParse processes multilingual documents with 20% fewer manual edits but has OCR inconsistencies. Unstructured struggles with layout retention in scanned files, increasing preprocessing costs. Vectorize performs best with scanned text, reducing OCR errors by 12%, but markdown formatting may oversimplify document structure. A hybrid approach improves accuracy.
Conclusion
Choosing the right PDF extractor for RAG depends on document complexity, accuracy needs, and integration requirements.
LlamaParse excels in structured data, Unstructured offers flexibility, and Vectorize specializes in scanned text.
Organizations working with financial reports, legal documents, or scientific data should evaluate extractors based on layout precision, semantic processing, and cost-effectiveness.
A hybrid approach combining multiple extractors can improve retrieval accuracy and AI-generated insights, ensuring optimal performance for large-scale document processing in finance, healthcare, and compliance-driven industries.