
Best RAG Stack for Large Document Sets
Choosing the right RAG stack for large document sets is crucial for performance and accuracy. This guide explores the best tools, frameworks, and techniques to optimize retrieval, improve scalability, and enhance AI-driven document processing.


Imagine this: A legal team is racing against a deadline, tasked with analyzing 250,000 pages of regulatory filings to identify compliance risks for a Fortune 500 client.
Traditional search tools overwhelm them with irrelevant results. They miss critical nuances. The clock is ticking, and manual review is out of the question.
Enter Retrieval-Augmented Generation (RAG). By combining dense vector embeddings with a fine-tuned GPT-4 model, the firm built a system that not only retrieves relevant sections but also generates concise, context-aware summaries. What once took weeks is now completed in hours with incredible accuracy.
This isn’t just a legal industry breakthrough. Healthcare, finance, and e-commerce use RAG stacks to process massive datasets quickly and precisely.
However, scaling a RAG system isn’t simple—it requires the right mix of embedding models like OpenAI’s Ada-002, vector databases like Pinecone, and iterative fine-tuning.
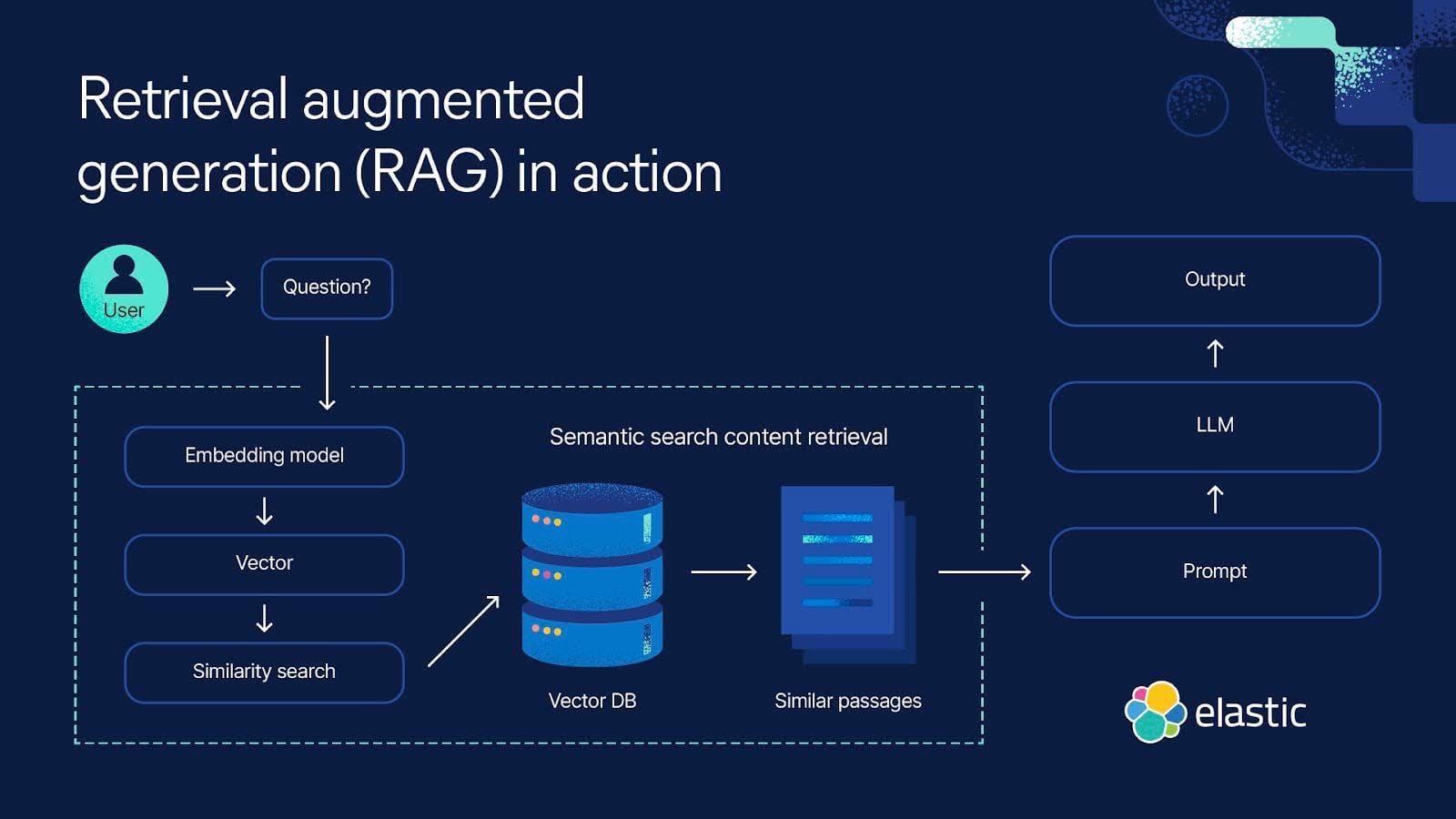
Understanding Retrieval Augmented Generation
Retrieval-augmented generation (RAG) enhances how systems retrieve and generate text by combining search algorithms with language models.
Unlike traditional retrieval, which fetches documents based on keyword matches, RAG contextually understands queries, making it ideal for handling large, complex document sets.
Embedding quality is critical. Dense vector embeddings, like OpenAI’s Ada-002, map text into numerical space, enabling semantic retrieval rather than simple keyword matching.
Retrieval noise is a common challenge. In financial research, for instance, pulling outdated or irrelevant reports can distort insights.
Multi-stage retrieval pipelines solve this by applying BM25 for keyword filtering, then re-ranking with deep learning models to surface the most relevant financial reports for decision-making.
RAG isn’t limited to text. Multimodal RAG integrates images, audio, and video for richer retrieval. A medical RAG system, for example, can pull X-ray images alongside patient records, helping doctors compare historical trends without manually searching through separate databases.
The key takeaway? A well-optimized RAG system is more than a search tool—it retrieves, refines, and generates knowledge tailored to the user’s domain. The right stack—high-quality embeddings, retrieval filtering, and multimodal capabilities—determines whether a system delivers noise or actionable insights.
Importance of RAG in Handling Large Document Collections
Managing large document collections is challenging, there’s no doubt about that.
Traditional search tools often retrieve incomplete or irrelevant results, which can slow decision-making. RAG, however, solves this by retrieving precise, context-aware information, making it essential for industries that rely on vast datasets.
Legal firms sift through thousands of case files, searching for specific clauses and precedents. With RAG, they can extract the most relevant sections instantly, cutting research time in half. Compliance teams use it to track regulatory changes, ensuring they act on the latest policies without manually scanning lengthy documents.
In scientific research, quick access to literature is crucial. Biomedical teams apply RAG to analyze thousands of studies, identifying trends in diseases and treatments.
Customer support teams also benefit—retrieving answers from extensive troubleshooting guides in seconds, reducing response time, and improving service quality.
Across industries, RAG transforms data retrieval. It moves beyond simple keyword searches, delivering precise, relevant insights when they matter most.
Core Components of a RAG Stack
Building a RAG stack is like assembling a high-performance race car—every component needs to work in harmony.
At the heart of it all are embedding models, which transform text into dense vector representations. Think of these as the “GPS” of your system, mapping queries to the most relevant data points. OpenAI’s Ada 002, for example, has set a benchmark with its ability to capture nuanced meanings, outperforming traditional keyword-based methods by over 40% in precision.
Next up is the vector database, the engine that powers retrieval.
Tools like Pinecone or Weaviate don’t just store embeddings—they optimize search speed and scalability.
Imagine sifting through millions of documents in milliseconds. That’s the kind of performance these databases deliver, especially when paired with hierarchical indexing strategies.
But here’s the twist: fine-tuning isn’t just optional—it’s essential. A healthcare RAG system trained on general data won’t cut it for diagnosing rare conditions.
The takeaway? Each component—embeddings, databases, and fine-tuning—plays a critical role. Neglect one, and the whole stack falters.
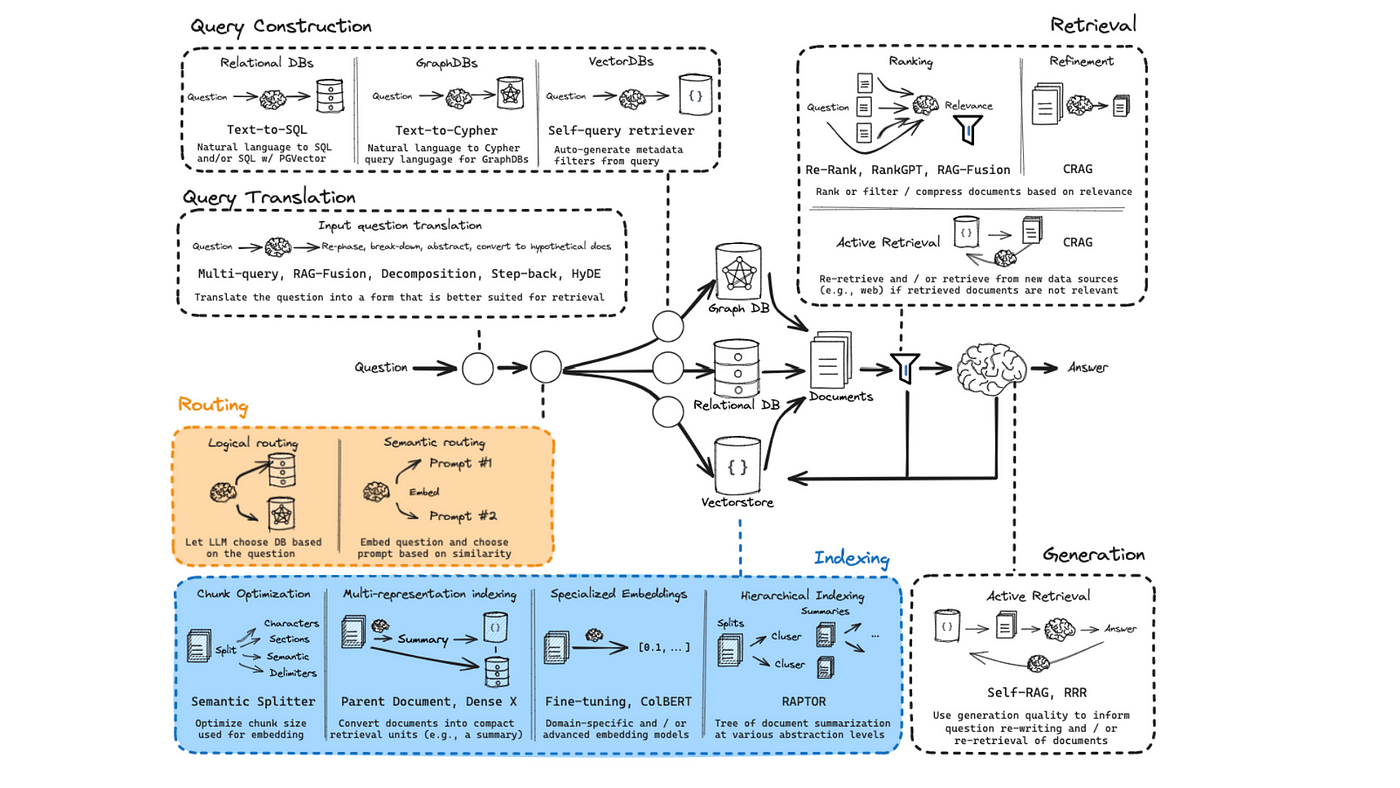
Data Preprocessing and Embedding Techniques
Imagine searching a massive legal database for a single argument in a case. Without structure, results are scattered, forcing hours of manual review.
This is where chunking changes everything. By breaking documents into smaller, meaningful sections, RAG systems retrieve the exact information needed.
Metadata enhances this process.
By tagging each chunk with timestamps, authorship, and source type, RAG systems filter results based on credibility and relevance. A news aggregator, for example, can prioritize breaking stories over outdated reports, ensuring users see the most current and reliable information first.
Some assume larger chunks improve retrieval, but that’s not always true.
While long-context models process extended inputs, they can also slow down response times. A hybrid approach—using smaller chunks for precision and longer ones for broader context—often delivers the best results.
The key to effective preprocessing is experimentation. Adjust chunk sizes, refine metadata tagging, and tailor the process to the task at hand.
Whether analyzing medical studies, legal documents, or customer support logs, structuring data properly ensures faster, more relevant responses.
Efficient Indexing and Storage Solutions
Let’s dig into hybrid indexing—a technique that’s quietly reshaping how RAG systems handle large-scale data.
By combining dense vector embeddings with sparse indexing methods like inverted indexes, you get the best of both worlds: semantic understanding and lightning-fast lookups.
For example, Elasticsearch’s hybrid approach allows systems to retrieve contextually relevant documents while maintaining sub-second response times, even in datasets exceeding millions of entries.
Here’s the kicker: index design matters more than you think.
Using hierarchical structures like B-trees or hash tables can drastically improve retrieval efficiency. Imagine a legal firm needing to access archived contracts by clause type—structured indexing ensures they can pinpoint the exact document in seconds, saving hours of manual search.
But don’t overlook versioning and access control. In dynamic environments, documents evolve. Systems like Apache Lucene support versioning, ensuring older versions remain accessible while the latest updates are indexed seamlessly. This is critical in industries like healthcare, where outdated information can lead to compliance risks.
Optimizing Retrieval Processes
To optimize retrieval processes in RAG models, we must discuss multi-stage retrieval pipelines—the secret sauce behind high-performing RAG systems.
Think of it like a funnel: lightweight filters (e.g., BM25) quickly narrow down millions of documents, while re-ranking models, powered by dense embeddings, refine the final selection. This layered approach isn’t just efficient—it’s essential. For instance, in e-commerce, Amazon uses similar techniques to surface the most relevant products.
Retrieval noise, on the other hand, is a silent killer. Irrelevant documents can sneak in, diluting results and frustrating users. The fix? Incorporating domain-specific embeddings.
And let’s bust a myth: deeper pipelines don’t always mean better results. In real-time applications like customer support, even a 500-millisecond delay can tank user satisfaction. The solution? Hybrid retrieval methods that balance speed and precision.
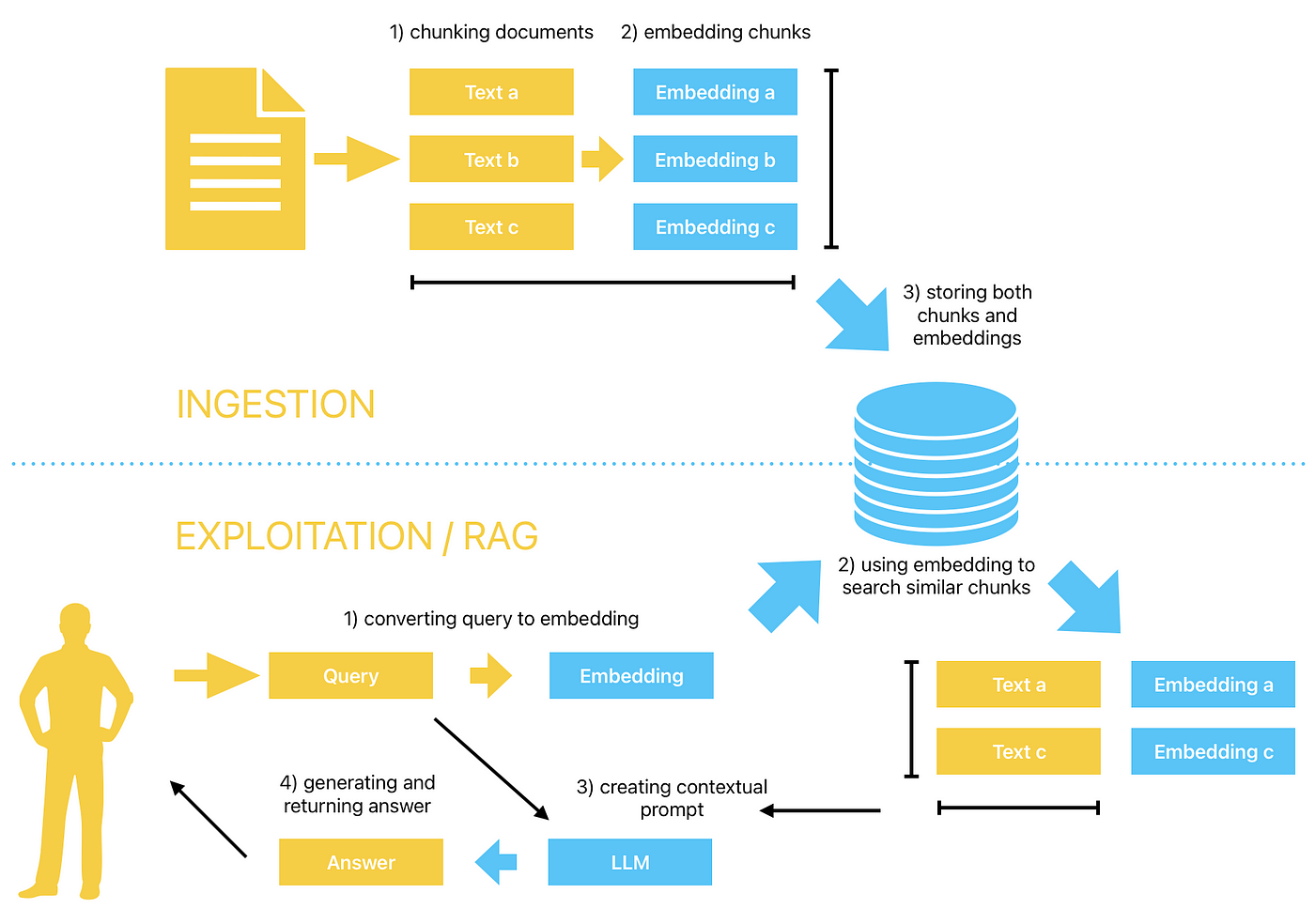
Advanced Query Transformation and Expansion
Query decomposition is a technique that’s quietly revolutionizing how RAG systems handle complex queries.
Instead of treating a query as a single unit, decomposition breaks it into smaller, more precise sub-queries.
Why does this matter?
Because it allows the system to retrieve highly relevant fragments from diverse sources and then synthesize them into a cohesive response.
For instance, in financial research, breaking down “What are the tax implications of offshore investments in 2025?” into sub-queries like “offshore investment tax laws” and “2025 tax changes” ensures no critical detail is missed.
Contextual alignment plays a huge role as well.
Decomposed queries must align semantically with the knowledge base to avoid retrieval noise.
Tools like T5-based models excel here, dynamically rephrasing sub-queries to match the structure of domain-specific data.
This approach has been a game-changer for enterprises like Bloomberg, where precision in financial data retrieval is non-negotiable.
Enhancing Context and Response Generation
Let’s face it—context is everything when it comes to generating accurate, meaningful responses.
But here’s the kicker: most RAG systems struggle to balance precision with coherence. That’s where attention-based fusion comes in. By dynamically weighting retrieved data based on its relevance, the system ensures critical details shine while irrelevant noise fades into the background.
Think of it like a spotlight on stage—only the most important actors get the light.
Take healthcare, for example. A RAG system retrieving patient histories and clinical guidelines can use this technique to prioritize life-saving details, like allergies or contraindications, over less urgent data.
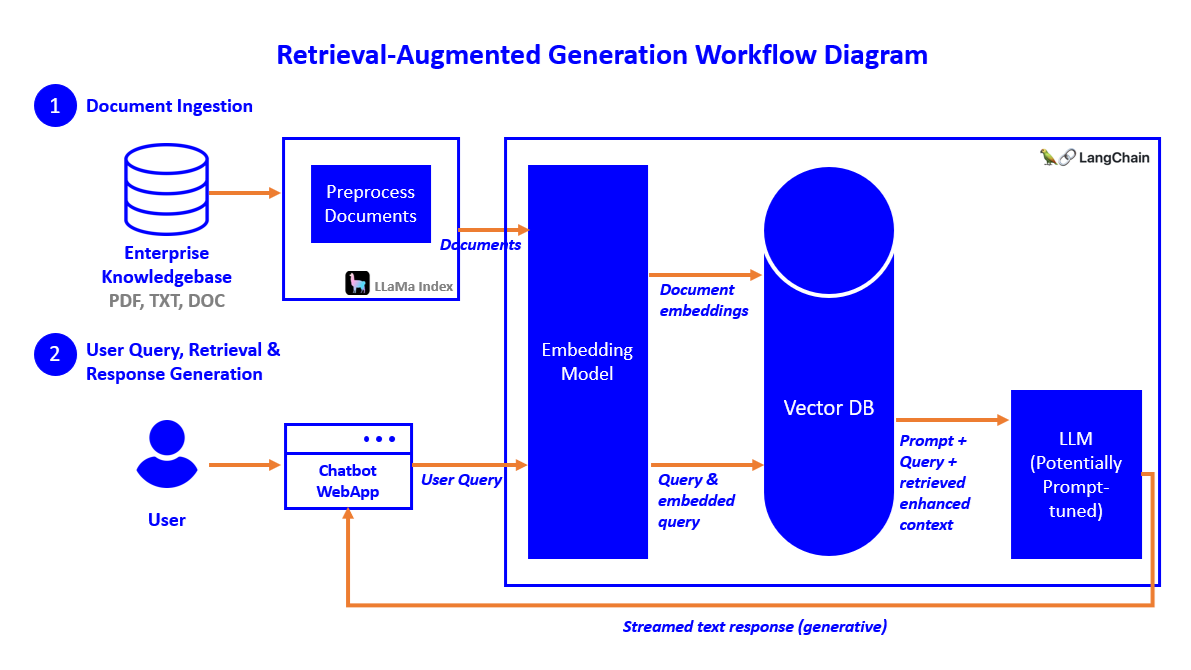
Dynamic Chunk Retrieval and Context Augmentation
Here’s the thing about dynamic chunk retrieval—it’s not just about grabbing the right data; it’s about understanding why that data matters in the first place.
Systems like LlamaIndex analyze user intent to prioritize chunks that align with the query’s purpose.
For example, in troubleshooting technical issues, the system doesn’t just pull generic manuals—it retrieves task-specific sections, like error codes or step-by-step fixes. This targeted approach slashes response times and boosts user satisfaction.
Context augmentation is where the magic happens. By layering metadata—like timestamps or document authorship—onto retrieved chunks, systems can filter out outdated or irrelevant information.
Imagine a financial analyst querying market trends. Without metadata, they might get last year’s projections. With it? They’re looking at real-time insights, tailored to their exact needs.
Response Generation and Refinement Techniques
Let’s talk about attention-based fusion—a technique that’s quietly redefining how RAG systems generate responses.
Instead of treating all retrieved data equally, this method dynamically weights information based on its relevance to the query.
For instance, in legal drafting, it ensures that critical precedents take center stage while less relevant cases fade into the background. The result? Responses that are not only accurate but also contextually sharp.
Here’s where it gets interesting: auto-merging retrieved snippets.
This approach synthesizes overlapping information into a cohesive narrative, eliminating redundancy. In healthcare, for example, patient histories and clinical guidelines are seamlessly integrated, enabling doctors to make faster, more informed decisions. It’s like having a personal assistant who organizes your notes before you even ask.
But let’s challenge a common belief: bigger models don’t always mean better results. Smaller, fine-tuned models often outperform their larger counterparts when paired with techniques like chain-of-thought prompting.
By guiding the system through logical steps, this method improves coherence and reduces noise, especially in complex queries.
Therefore, it’s important to combine attention-based fusion with auto-merging and chain-of-thought prompting. This results in a system that doesn’t just answer questions—it delivers polished, actionable insights tailored to the user’s needs.
Integration of Multi-Modal Data
Here’s the thing about multi-modal RAG: it’s not just about combining data types—it’s about aligning them.
Text, images, and audio don’t naturally “speak the same language.” That’s where cross-modal embeddings come in.
These embeddings map diverse data into a shared space, making it possible to retrieve and generate cohesive outputs.
But alignment isn’t the only challenge. Contextual weighting plays a huge role. Not all modalities are equally relevant to every query.
A legal RAG system might prioritize text over courtroom footage, while a telemedicine platform might do the opposite. Systems like LlamaIndex dynamically adjust these weights, ensuring the most critical data takes precedence.
Advancements in Hybrid Retrieval Methods
Let’s talk about adaptive hybrid retrieval—a game-changer for balancing speed and precision.
Instead of rigidly combining dense and sparse methods, adaptive systems dynamically adjust based on query complexity.
For instance, a customer support bot might prioritize sparse retrieval (keywords) for simple FAQs but switch to dense embeddings for nuanced troubleshooting. This flexibility slashes response times without sacrificing relevance.
Here’s where it gets interesting: query intent modeling. By analyzing user intent, systems can predict which retrieval method will yield the best results.
For example, in an e-commerce platform, a user searching for “best laptops under $1,000” has a clear intent: price-sensitive product recommendations.
A RAG system using query intent modeling first applies sparse retrieval (BM25) to fetch products matching the price range, then switches to dense embeddings to refine results based on specs, reviews, and popularity.
FAQ
What are the key components of a high-performing RAG stack for large document retrieval?
A strong RAG stack includes embedding models like OpenAI’s Ada-002 for semantic understanding, vector databases such as Pinecone for fast retrieval, and hybrid indexing methods combining dense and sparse search. Fine-tuning with domain-specific data and metadata tagging improves accuracy in industries like legal, finance, and healthcare.
How does hybrid retrieval improve efficiency in handling extensive document collections?
Hybrid retrieval combines sparse methods like BM25 for keyword matching with dense embeddings for contextual search. This approach balances speed and accuracy, using sparse retrieval to filter broad results and dense retrieval to refine precision. It enables efficient, real-time search in large document datasets.
What role do embedding models and vector databases play in optimizing large-scale document retrieval?
Embedding models encode text into dense vectors, capturing semantic meaning beyond exact matches. Vector databases, like Pinecone or Weaviate, store and index these embeddings for fast, scalable retrieval. This combination allows RAG systems to process vast datasets with high accuracy, essential for legal, healthcare, and financial applications.
How does metadata improve the relevance and accuracy of RAG for enterprise applications?
Metadata, such as timestamps, authorship, and document type, helps filter results for relevance. It ensures the most recent, credible, and contextually appropriate documents are retrieved first. This is critical for legal research, regulatory compliance, and customer support, where precision and document credibility are essential.
What are the best practices for fine-tuning RAG for domain-specific challenges?
Fine-tuning involves training models on domain-specific corpora, applying metadata for better filtering, and optimizing retrieval with structured indexing. Updating models regularly and using task-specific training datasets ensures accuracy. These methods improve performance in specialized fields like healthcare diagnostics, legal research, and financial forecasting.
Conclusion
RAG systems are changing how organizations process massive document sets. A well-structured RAG stack doesn’t just retrieve information—it finds the right data at the right time with context and precision.
Businesses can move beyond keyword searches and uncover deeper insights by integrating dense embeddings, hybrid retrieval, metadata filtering, and domain-specific fine-tuning.
Whether it’s analyzing legal contracts, diagnosing medical conditions, or tracking market trends, a well-optimized RAG system transforms raw data into strategic knowledge.
The future of large-scale retrieval isn’t about collecting more data—it’s about retrieving smarter.