
Building an End-to-End RAG Pipeline: From Data Ingestion to Generation
Learn how to build an end-to-end Retrieval-Augmented Generation (RAG) pipeline, covering data ingestion, indexing, retrieval, and text generation. This guide explores best practices and tools to enhance AI-driven content creation and improve accuracy.


Despite the buzz around AI breakthroughs, organizations struggle to implement systems that deliver speed and accuracy in real-world applications.
Why? It’s because building a Retrieval-Augmented Generation (RAG) pipeline isn’t just about plugging in a generative model—it’s about finding the right balance between data ingestion, retrieval precision, and seamless generation.
So, how do you build a pipeline that doesn’t just work but thrives under real-world constraints? And what hidden opportunities lie in mastering this process? Let’s break it down.
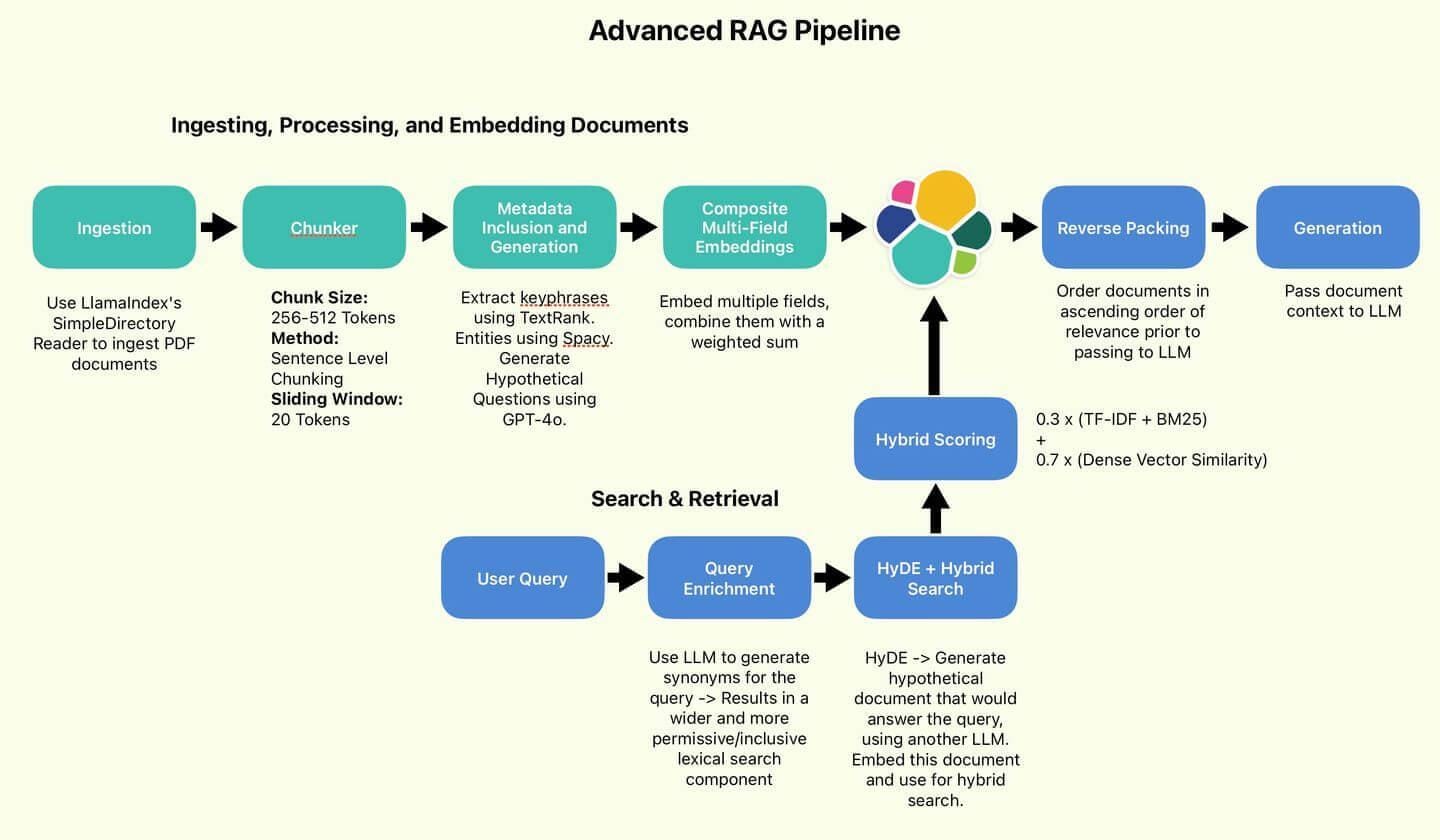
Core Components of a RAG Pipeline
First, let’s take a look at embedding models, the unsung heroes of a RAG pipeline.
These models transform raw data into vector representations, enabling the system to retrieve contextually relevant information. But here’s the kicker: not all embeddings are created equal.
For example, in healthcare, embeddings trained on general datasets often miss domain-specific nuances.
Dimensionality trade-offs are another overlooked factor. High-dimensional embeddings capture more detail but can bloat storage and slow retrieval.
Techniques like Principal Component Analysis (PCA) can reduce dimensions without sacrificing relevance.
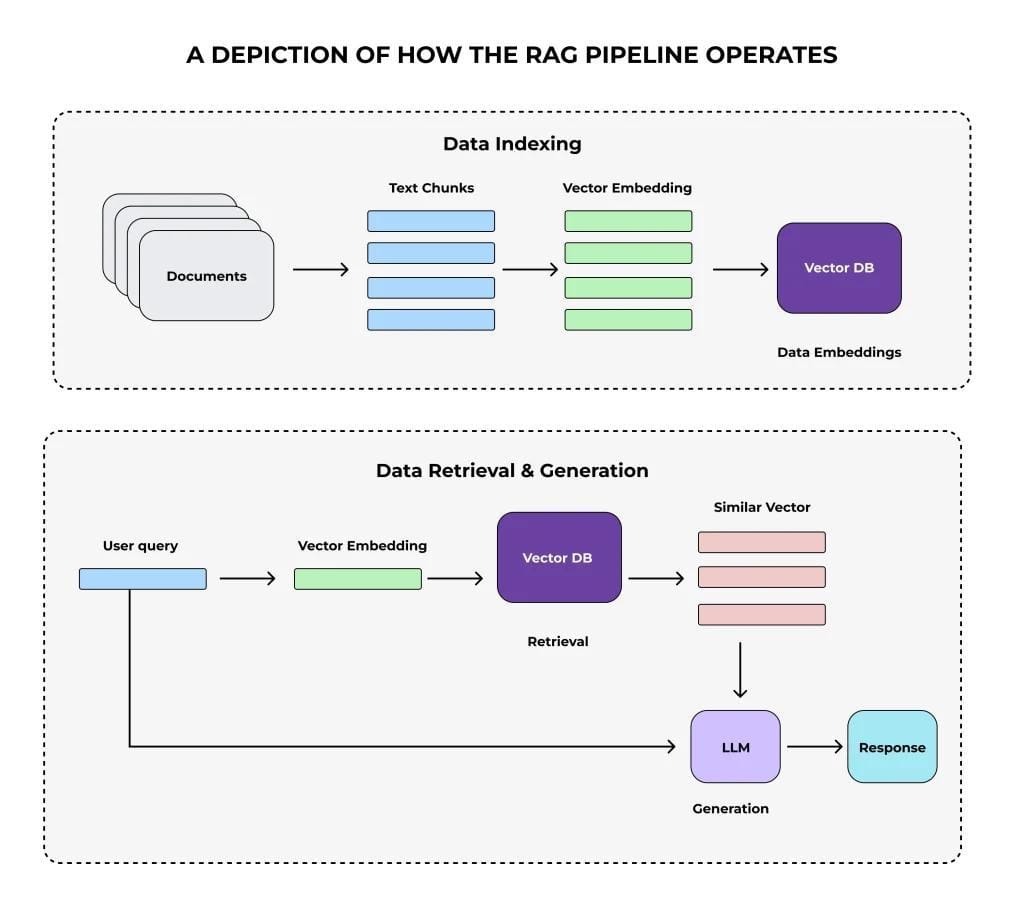
Performance Metrics and Evaluation
Let’s zero in on retrieval latency, a metric that often gets overlooked but can make or break user experience. Why? Because even the most accurate RAG pipeline fails if it’s too slow to respond
However, reducing latency isn’t just about faster hardware. Techniques like query caching and vector pruning can significantly cut down retrieval times.
But don’t stop there. Latency-accuracy trade-offs are real. Aggressive optimizations can hurt retrieval precision, especially in domains like healthcare.
The solution? Implement dynamic thresholds—adjust latency targets based on query complexity.
Data Ingestion Strategies
Data ingestion is the foundation of your RAG pipeline. If it’s shaky, everything else crumbles. The goal is to seamlessly pull data from diverse sources—structured databases, PDFs, and APIs—while keeping it clean and relevant.
Now, let’s talk real-time ingestion. Streaming data from IoT devices or social media is like drinking from a firehose. Tools like Kafka or CDC (Change Data Capture) can help manage this flow, ensuring freshness without overwhelming the system.
Identifying and Sourcing Relevant Data
Not all data is created equal, and sourcing the right data can make or break your RAG pipeline.
The secret is to start with domain-specific datasets.
For example, a healthcare chatbot thrives on peer-reviewed journals and clinical guidelines—not generic web crawls. This ensures responses are both accurate and trustworthy.
But here’s a curveball: relevance isn’t static.
Data that’s useful today might be outdated tomorrow. That’s why dynamic data sources, like APIs or real-time feeds, are game-changers. Take financial services—integrating live market data ensures your pipeline stays ahead of the curve.
Adding rich metadata (e.g., timestamps, authorship) during ingestion is also essential for precision retrieval. It’s like giving your pipeline a GPS for finding the best route to relevant information.
Techniques for Efficient Data Collection
Adaptive sampling is a game-changer for efficient data collection.
Instead of blindly ingesting everything, this technique prioritizes high-value data points based on predefined criteria like relevance, recency, or domain specificity.
For instance, in e-commerce, adaptive sampling can focus on trending product reviews, ensuring your pipeline captures what matters most to users.
Here’s why it works: it reduces noise while optimizing storage and processing costs. By leveraging active learning, you can even train your system to identify gaps in the dataset and proactively seek missing information.
Data diversity is just as critical. Over-reliance on a single source can introduce bias. Instead, combine structured databases with unstructured sources like social media or multimedia.
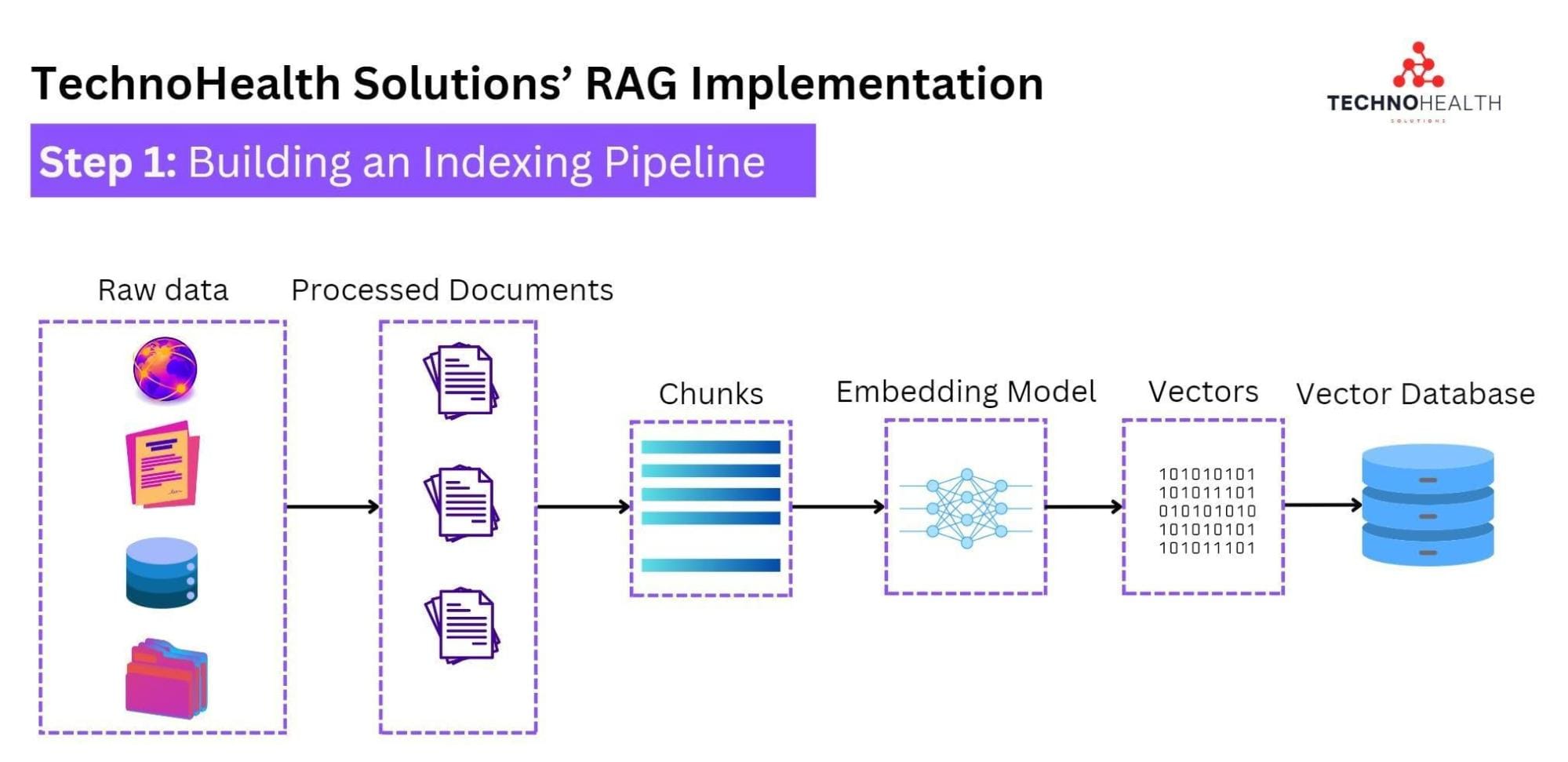
Implementing the Retrieval Component
Think of the retrieval component as the brain’s memory recall—it’s not just about finding data but finding the right data, fast.
The key? Embedding models. These models convert text into dense vectors, enabling similarity searches. For instance, OpenAI embeddings or SentenceTransformers excel at matching user queries to relevant chunks of information.
But here’s the twist: context matters more than precision alone. A shallow similarity search might miss nuanced connections, while overly deep searches can bog down performance. Netflix tackled this by fine-tuning embeddings on user behavior, balancing speed and relevance to recommend shows in milliseconds.
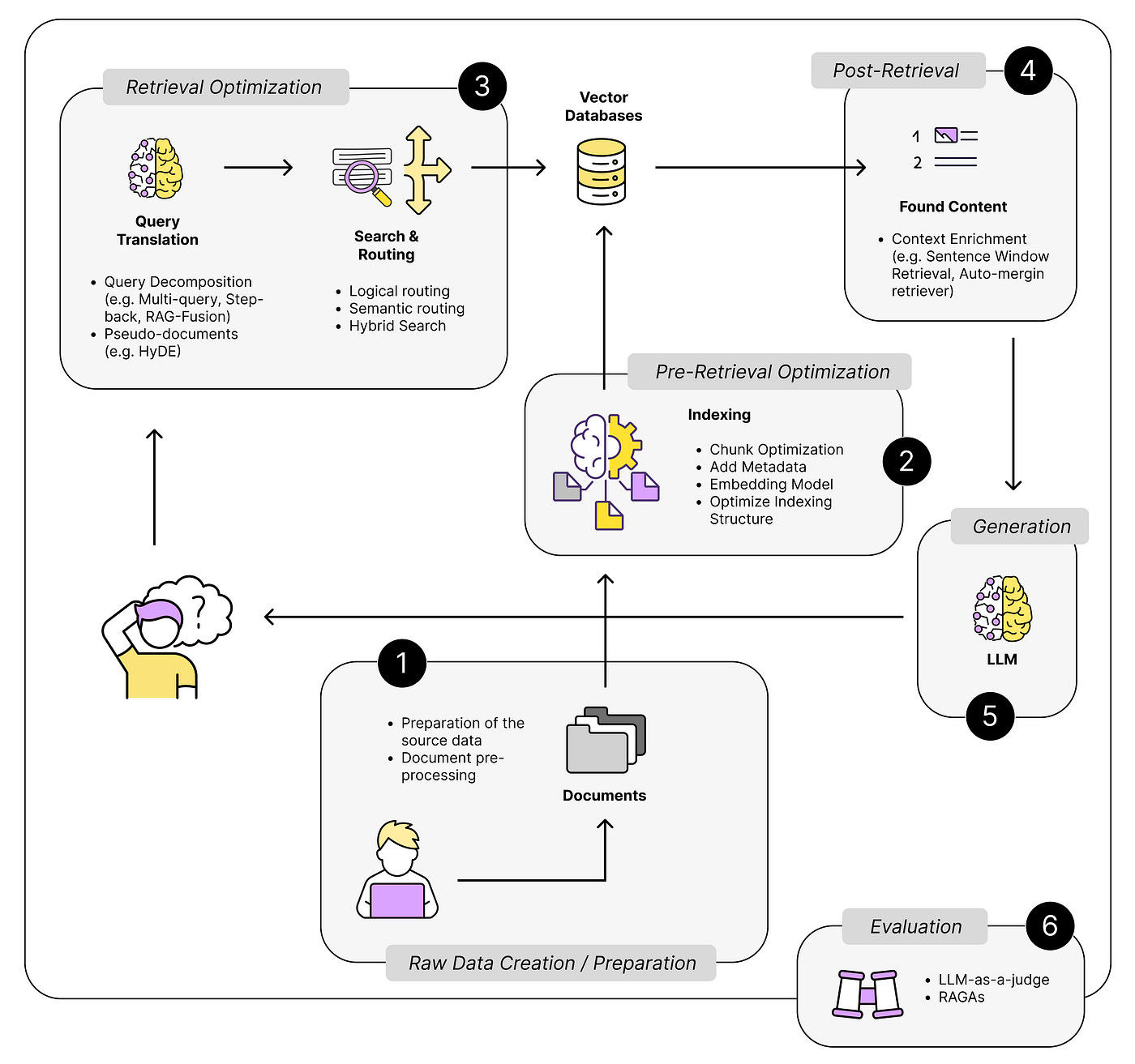
Selection of Retrieval Models
Choosing the right retrieval model is like picking the perfect tool for surgery—precision and adaptability are non-negotiable. Dense Passage Retrieval (DPR) is a standout for its ability to handle open-domain queries, leveraging bi-encoders to match queries with document embeddings.
Indexing and Search Algorithms
Let’s talk about hierarchical indexing, which reduces search space, slashes retrieval latency, and boosts precision.
For instance, in healthcare, indexing patient records by symptoms and treatments ensures faster, more relevant results.
Adaptive indexing, unlike static methods, re-prioritize data based on query trends. This approach not only improves relevance but also keeps the system agile.
Graph-based indexing maps relationships between data points and enables multi-hop reasoning, which is critical for complex queries.
Designing the Generation Component
The generation component is where the magic happens—turning retrieved data into coherent, context-aware responses.
However, balancing creativity with factual accuracy is harder than it looks. For instance, in healthcare applications, overly creative outputs can lead to misinformation, while rigid responses may fail to engage users.
The solution is to fine-tune generation models on domain-specific datasets to align outputs with user expectations.
Take OpenAI’s GPT models as an example. When fine-tuned for legal use cases, they excel at drafting contracts by synthesizing retrieved clauses.
However, without reinforcement learning from human feedback (RLHF), these models might still hallucinate irrelevant details.
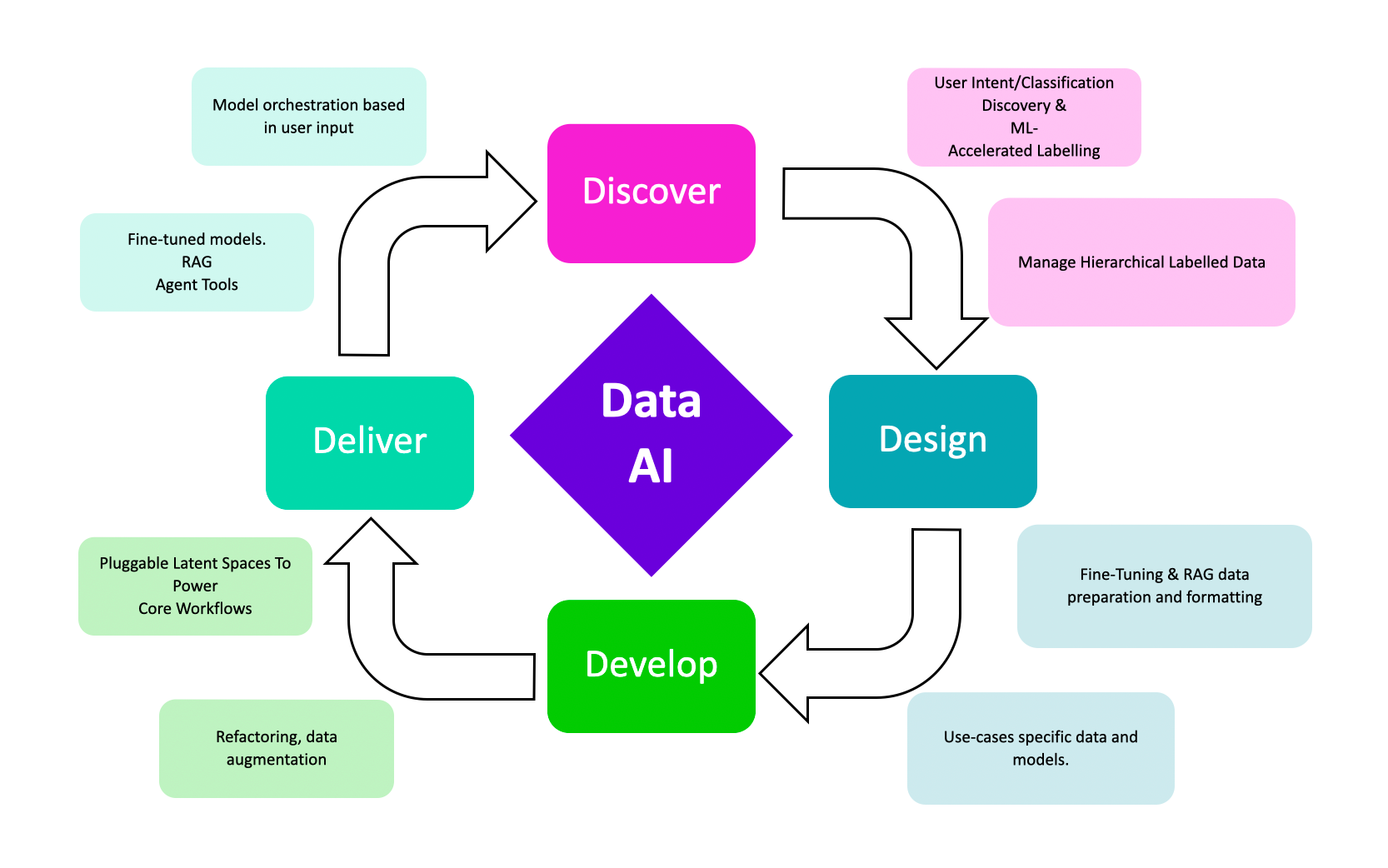
Choosing Generation Models
Not all generation models are created equal, and the choice often hinges on domain specificity and response complexity.
For example, transformer-based models like GPT-4 excel in creative tasks but may falter in highly technical fields without fine-tuning. In contrast, smaller, domain-specific models (e.g., BioGPT for medical queries) deliver precision but lack versatility.
Therefore, model size isn’t everything. While larger models offer broader generalization, they demand more computational resources, making them impractical for real-time applications.
Instead, hybrid approaches—combining a lightweight model for initial drafts with a larger model for refinement—can balance speed and accuracy.
Ensuring Coherence and Relevance
Let’s talk about response grounding—a game-changer for coherence.
By anchoring generated outputs to specific retrieved data points, you minimize the risk of hallucinations.
Techniques like data citation within responses (e.g., “According to [source],…”) not only improve relevance but also build user trust, especially in high-stakes fields like healthcare or finance.
Integrating Retrieval and Generation
Think of retrieval and generation as a relay race. The baton (data) must be passed seamlessly for the system to perform well.
A common pitfall is treating these stages as isolated silos. Instead, tight integration ensures the retrieved data aligns perfectly with the generation model’s context window, avoiding incoherent or irrelevant outputs.
Here’s a surprising insight: ranking retrieved data by user intent can drastically improve results. For example, in e-commerce, prioritizing product reviews over technical specs for casual shoppers leads to more engaging responses. This approach bridges the gap between raw data and user expectations.
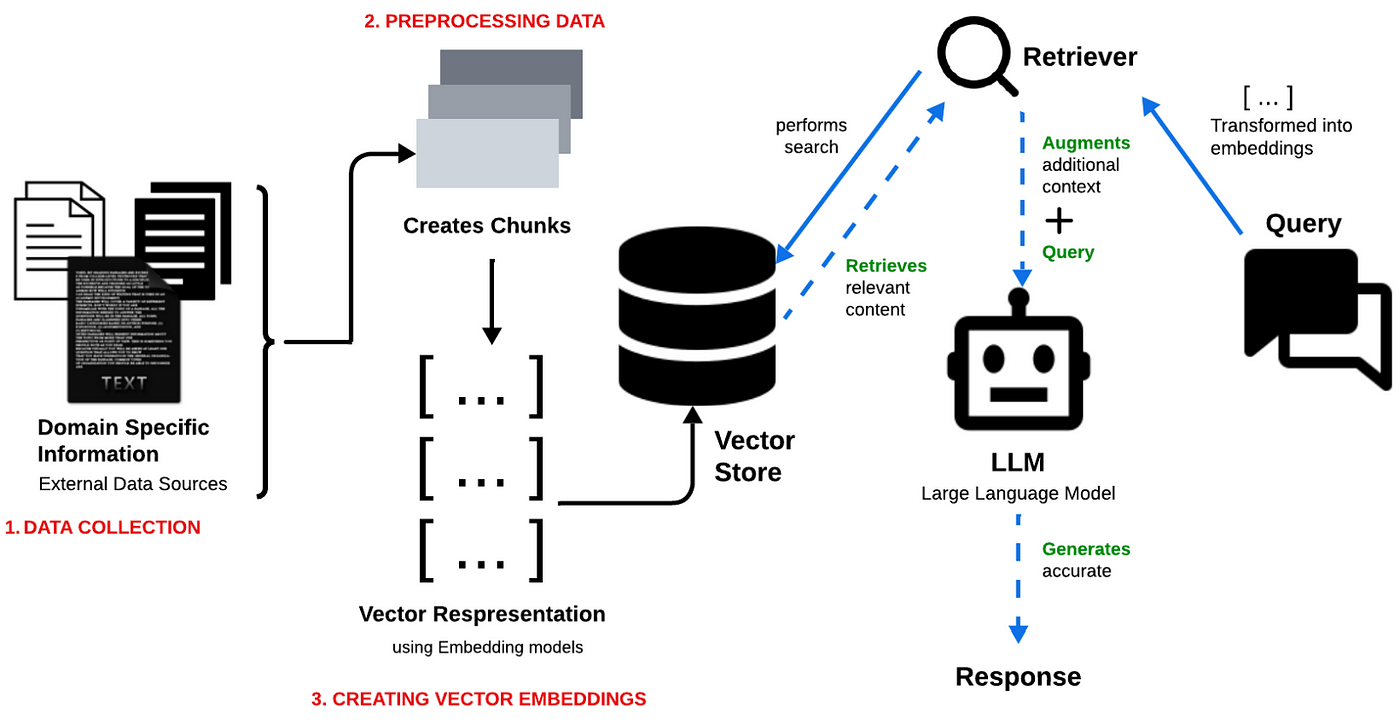
Pipeline Orchestration and Workflow
A well-designed workflow isn’t just about connecting components; it’s about dynamic task scheduling.
Tools like Apache Airflow or Prefect shine here, enabling conditional triggers based on query complexity. For instance, a legal research system might route simple queries to shallow retrieval while reserving deep retrieval for nuanced cases.
Here’s a twist: parallel processing can supercharge efficiency. By splitting retrieval and generation tasks across microservices, you reduce bottlenecks.
Netflix’s recommendation engine uses a similar approach, processing user preferences and content metadata simultaneously to deliver real-time suggestions.
But don’t overlook error handling. Conventional wisdom says retries are enough, but graceful degradation—returning partial results when failures occur—keeps users engaged. This is critical in high-stakes fields like healthcare, where incomplete but relevant data can still inform decisions.
Testing End-to-End Functionality
When testing end-to-end functionality, user simulation is crucial.
Instead of relying solely on static test cases, simulate real-world user behavior with tools like Locust or custom scripts.
For example, in a customer support chatbot, simulate diverse queries—ranging from simple FAQs to complex, multi-turn conversations—to stress-test both retrieval and generation components.
Challenges and Solutions
Building a RAG pipeline isn’t a walk in the park. Data consistency is a significant challenge.
Imagine pulling data from multiple sources—some structured, others messy and unstructured. Without rigorous preprocessing, you’re left with a chaotic soup of information.
However, this can be tackled by mplementing data validation pipelines that flag inconsistencies early.
Another hurdle is retrieval latency. Users expect instant results, but large datasets can bog down performance.
Here’s where query caching shines. For example, e-commerce platforms cache frequent queries like “best laptops under $1000,” slashing response times dramatically.
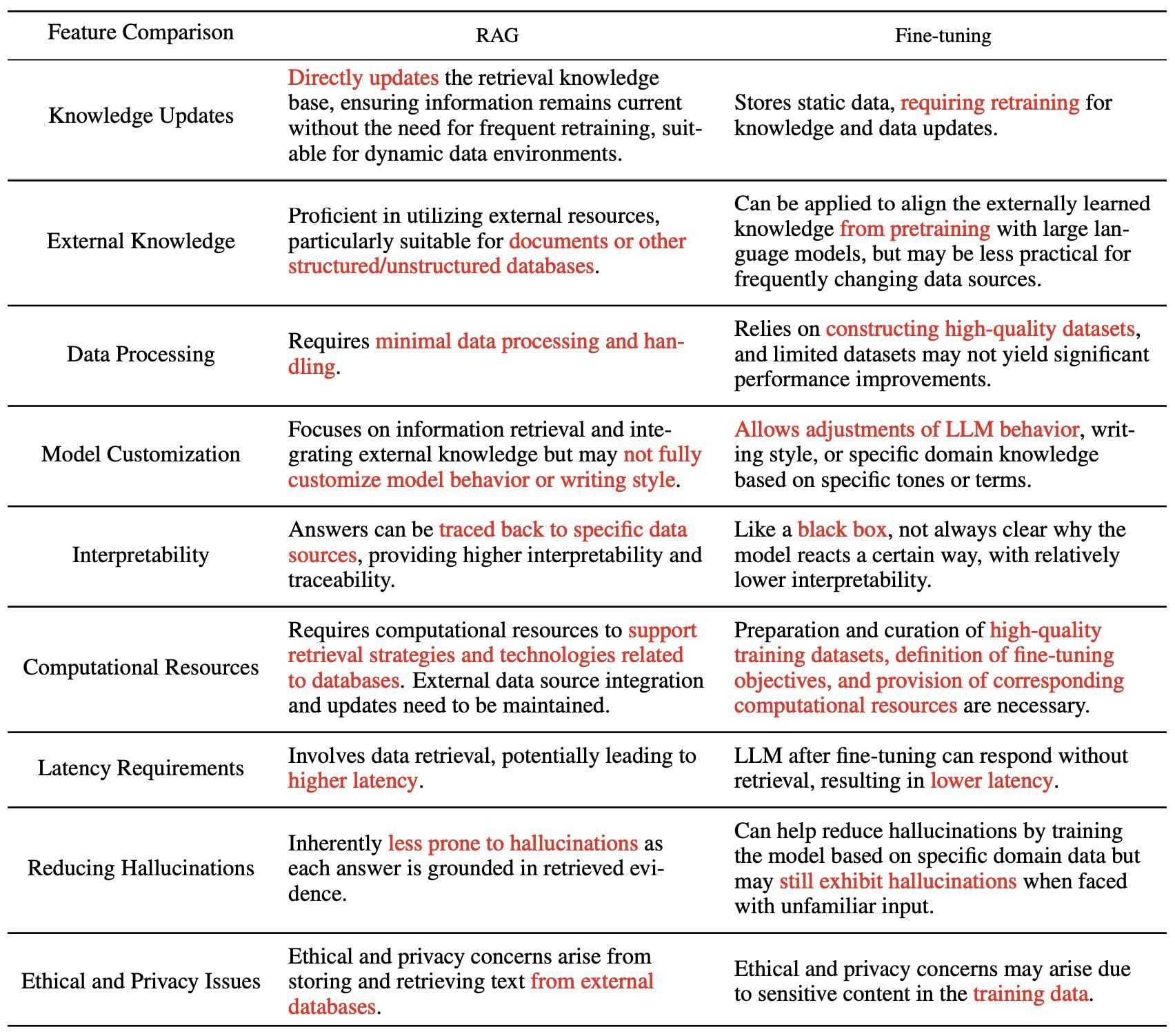
Addressing Data Quality Issues
Let’s face it: garbage in, garbage out.
If your RAG pipeline ingests low-quality data, no amount of fancy algorithms will save it. The key? Metadata enrichment.
By tagging data with attributes like source credibility, timestamp, and domain relevance, you can filter out noise before it even enters the pipeline. For instance, a financial RAG system might prioritize SEC filings over unverified blog posts.
But here’s the kicker—data drift. Over time, even high-quality datasets lose relevance. A retail RAG system trained on last year’s trends won’t cut it for this year’s holiday season. The solution? Real-time synchronization. Techniques like change data capture (CDC) ensure your pipeline stays fresh by updating only what’s changed.
And don’t underestimate human oversight. Collaborating with domain experts to audit datasets can uncover blind spots algorithms miss. Think of it as pairing AI’s speed with human intuition for unbeatable results.
FAQ
What are the key components of an end-to-end RAG pipeline?
Key components include data ingestion, preprocessing and transformation, embedding and indexing, retrieval and generation components, pipeline orchestration, and monitoring with feedback loops. Each stage ensures efficient and accurate information flow.
How does data ingestion impact the performance of a RAG pipeline?
Effective data ingestion ensures high-quality, well-structured data flows into the pipeline, reducing errors and improving retrieval accuracy. Poor ingestion can lead to irrelevant results and degraded model performance.
What are the best practices for integrating retrieval and generation models?
Ensure context alignment, use ranking mechanisms, fine-tune both models on domain-specific datasets, and optimize retrieval depth to balance latency and accuracy for seamless interaction.
How can bias and ethical considerations be addressed in a RAG pipeline?
Use diverse datasets, integrate post-generation filtering, involve human evaluation, and leverage explainable AI techniques. Regular audits and ethical subroutines can further minimize bias.
What metrics should be used to evaluate the effectiveness of a RAG pipeline?
Key metrics include precision, recall, F1 score, latency, response accuracy, coherence, and scalability. These ensure the pipeline delivers accurate, timely, and context-relevant results.
Conclusion
Building an end-to-end RAG pipeline isn’t just about connecting retrieval and generation models—it’s about creating a system that thrives on precision, adaptability, and relevance.
A robust RAG pipeline is less about technology and more about strategy. When done right, it transforms unstructured data into actionable insights, unlocking value across industries.