
Langchain and Agno: Building 100% Local Agentic RAG Systems
Discover how Langchain and Agno enable fully local Agentic RAG systems. This guide explores key tools, implementation strategies, and best practices for optimizing retrieval, ensuring data privacy, and enhancing AI automation without cloud dependency.


AI systems are powerful, but they have a trade-off: they rely on cloud services and external APIs that expose sensitive data.
For industries handling confidential information—like finance, healthcare, and legal services—this creates a security risk and regulatory concerns.
Enter Langchain and Agno, a combination that enables 100% local agentic RAG systems, ensuring data stays private without compromising performance.
Organizations can now retrieve, analyze, and generate insights entirely offline, eliminating external dependencies while maintaining full control over knowledge workflows.
With Langchain orchestrating retrieval and Agno structuring workflows, businesses can build self-contained, adaptive AI that operates on their terms, within their infrastructure.
The future of agentic RAG systems isn’t in the cloud. It’s local, private, and built for those who demand both control and intelligence—without compromise.
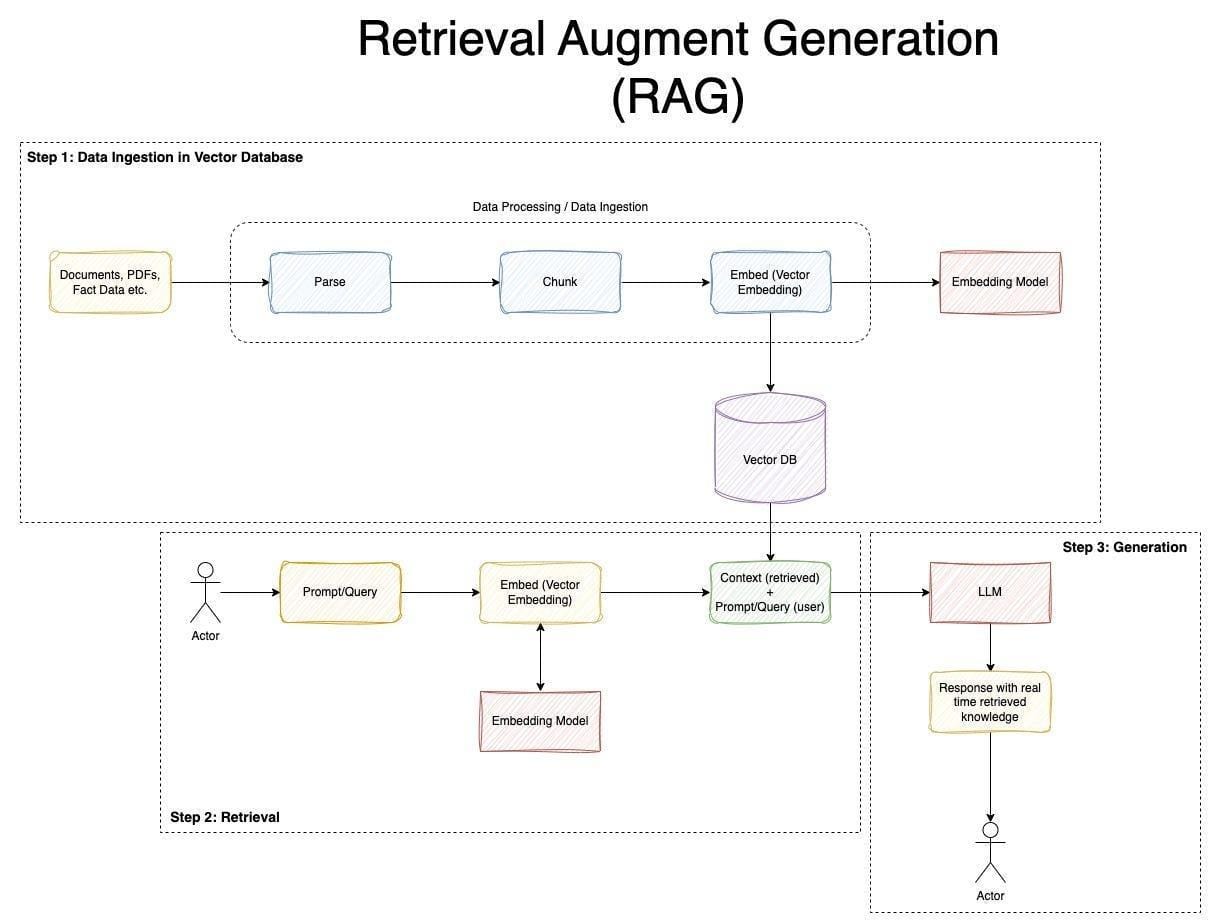
Understanding Retrieval-Augmented Generation (RAG)
Let’s zoom in on what makes RAG tick: contextual relevance.
At its core, RAG bridges the gap between static training data and real-time information needs.
But here’s the kicker—Langchain and Agno take this a step further by enabling dynamic, offline workflows.
Why does this matter?
Because traditional RAG systems often falter when faced with complex, multi-step reasoning. Langchain’s modular retrieval and Agno’s workflow optimization solve this elegantly.
Take Goldman Sachs, for example.
By deploying a local RAG system powered by Langchain, they streamlined market analysis.
Their agents dynamically retrieved and synthesized data from internal financial reports, cutting decision-making time. Agno’s workflow ensured seamless integration with their proprietary tools, maintaining airtight data security.
Now, think about this: what if we measured RAG systems by a Relevance-Adaptability Index (RAI)?
This metric could quantify how well a system adapts to evolving queries. Langchain and Agno would score high, thanks to their iterative refinement capabilities.
Here’s the big picture: local RAG isn’t just about privacy but control and precision.
As industries demand smarter, faster AI, Langchain and Agno are setting the gold standard.
The Role of Langchain and Agno
Langchain and Agno are the ultimate duo for building local agentic RAG systems, but their real magic lies in how they complement each other.
Langchain excels at orchestrating complex retrieval tasks, ensuring that the right data is fetched at the right time.
Agno, on the other hand, takes this data and transforms it into actionable workflows, seamlessly executing tasks without ever leaving your local environment.
Here’s a fresh perspective: imagine a Privacy-Performance Index (PPI) that measures how well a system balances data security with operational efficiency.
Langchain and Agno would score exceptionally high, thanks to their ability to operate entirely offline while maintaining top-tier performance.
Looking ahead, this combination could redefine how industries approach AI.
From healthcare to finance, the focus will shift to domain-specific, autonomous RAG systems that prioritize control, adaptability, and privacy—all powered by Langchain and Agno.
System Architecture and Component Integration
Let’s break it down: building a fully local agentic RAG system with Langchain and Agno is like assembling a high-performance race car.
Every component has a role, and when they’re perfectly tuned, the system runs like a dream.
Langchain is your engine, powering the retrieval of relevant data with precision. It dynamically connects to your internal knowledge bases, whether that’s PDFs, databases, or even real-time logs.
Agno, on the other hand, is the transmission system that converts raw data into actionable workflows.
Together, they create a seamless pipeline in which every query is processed, reasoned, and executed offline.
With Langchain’s modular architecture and Agno’s workflow optimization, you get lightning-fast responses without sacrificing privacy.
For example, a healthcare provider used this setup to analyze patient records in seconds, ensuring compliance with strict data regulations.
The result? A system that’s not just secure but also blazing fast and ridiculously efficient.
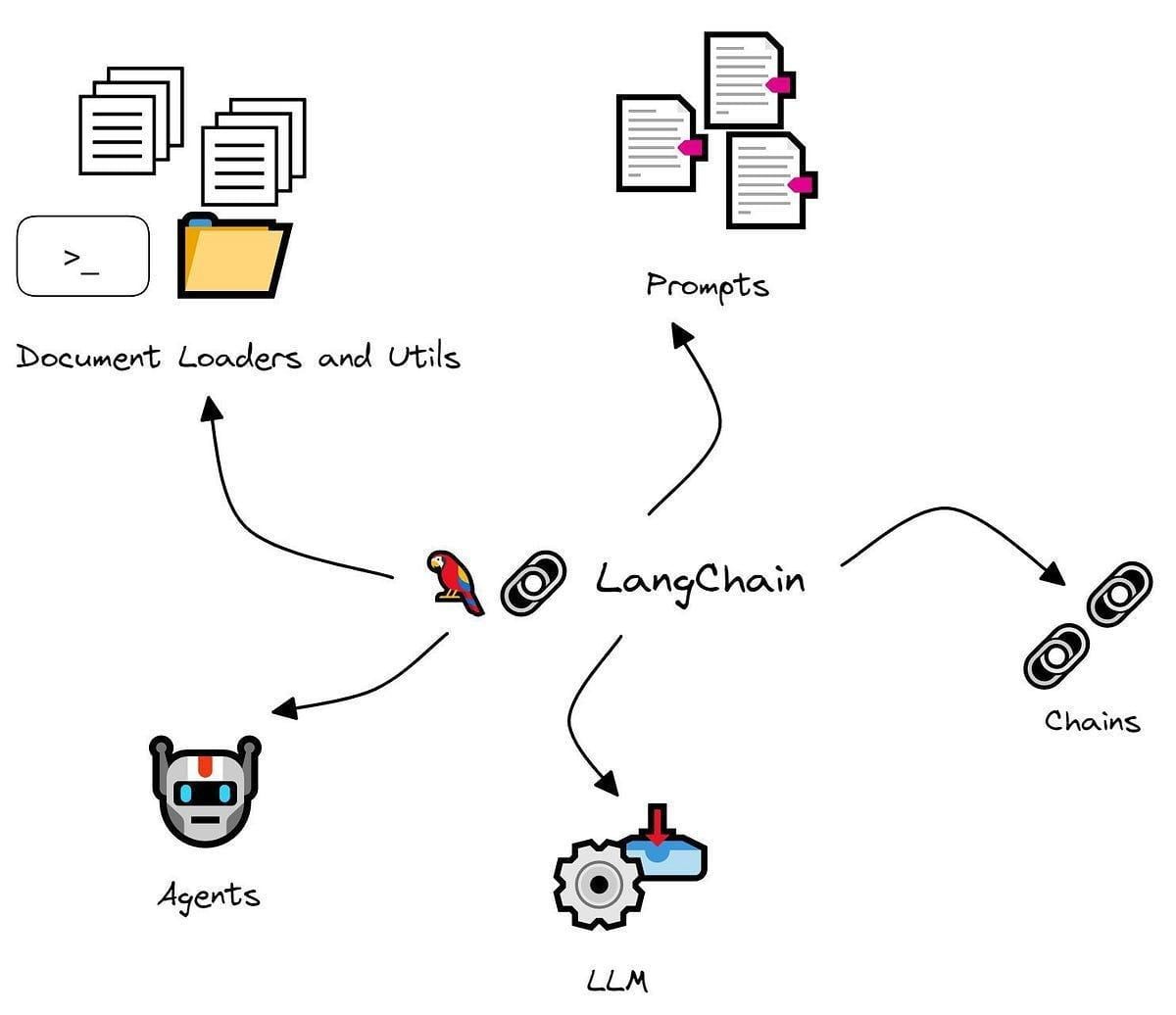
Designing a Modular System Architecture
Let’s discuss modularity—the secret sauce behind Langchain and Agno’s seamless integration.
Why does it matter?
Because modular systems let you build smarter, faster, and more adaptable RAG setups without reinventing the wheel.
Think of it like LEGO blocks: each piece (or module) has a specific role, but they create something extraordinary together.
Take Langchain’s retrieval modules.
They’re designed to connect with diverse data sources—PDFs, databases, and even live logs.
Now pair that with Agno’s workflow modules, transforming raw data into actionable insights.
The result? A system that’s not just efficient but also ridiculously flexible.
Moreover, modularity isn’t just about efficiency—it’s about resilience.
By isolating components, you reduce the risk of system-wide failures.
Imagine a Modularity-Resilience Index (MRI) to measure how well systems adapt to disruptions. Langchain and Agno would score highly.
Looking ahead, modular architectures could redefine AI scalability.
Picture healthcare systems dynamically integrating new diagnostic tools or financial firms adapting to regulatory changes—all without overhauling their core setups.
Data Processing Pipelines and Vector Storage
Let’s talk about the backbone of any great RAG system: data pipelines and vector storage.
Think of it like prepping ingredients for a gourmet meal—if your data isn’t clean, organized, and ready to go, the final dish (or in this case, the AI output) won’t impress anyone.
Here’s the magic formula: Langchain handles the heavy lifting of data ingestion and chunking, breaking down massive documents into bite-sized pieces.
Then, Agno steps in to ensure these pieces flow seamlessly into a vector database—the secret sauce for lightning-fast retrieval.
Picture it as a library where every book is indexed not just by title but by the meaning of its content.
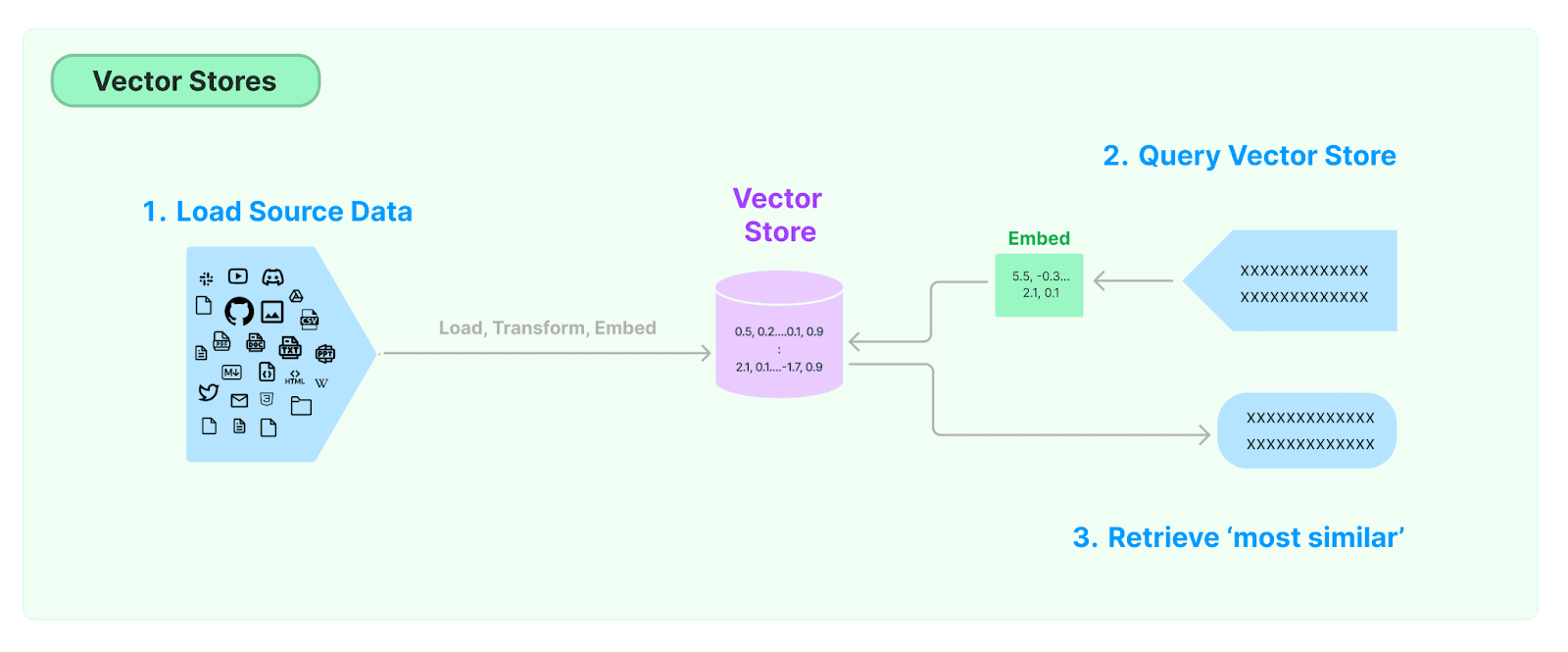
Implementing Efficient Data Pipelines
A Retrieval-Augmented Generation (RAG) system is only as strong as its data pipeline.
Chunking and embedding play critical roles in retrieval efficiency, ensuring the system fetches relevant information without unnecessary delays.
Langchain handles data chunking, breaking large datasets into structured, retrievable units. This prevents loss of key details while optimizing retrieval performance.
Agno takes over from there, embedding these chunks into a vector database—whether FAISS, Qdrant, or another local storage solution—so queries return precise, context-aware responses.
This structured pipeline ensures low-latency, high-accuracy retrieval, making 100% local agentic RAG systems viable for industries requiring privacy and performance.
For example, a financial firm could process internal compliance documents, while a healthcare provider could analyze medical records in real time, all without exposing sensitive data to external systems.
Utilizing Qdrant for Vector Storage
Let’s talk about Qdrant, the unsung hero of vector storage in local RAG systems. Why does it matter?
Because Qdrant doesn’t just store data—it transforms how your system retrieves and uses it.
By leveraging dense vector embeddings, Qdrant ensures that every query connects with the most contextually relevant data, even in high-dimensional spaces.
Here’s a fresh perspective: imagine a Vector Precision Index (VPI) to measure how well a system balances retrieval accuracy with computational efficiency.
Qdrant would score exceptionally high, thanks to its advanced filtering and scalability.
Looking ahead, industries like healthcare could use Qdrant to analyze patient data in real-time, ensuring compliance with strict regulations while delivering faster diagnoses.
The takeaway? Qdrant isn’t just a storage solution—it’s a strategic enabler for smarter, faster, and more secure decision-making.
Embedding Generation and Local LLM Deployment
Here’s the thing: embedding generation is the backbone of any RAG system, and doing it locally?
That’s where the magic happens.
By generating embeddings on your own hardware, you’re not just cutting out the middleman—you’re taking full control of your data pipeline. Tools like FastEmbed (by Qdrant) make this process lightweight and blazing fast, even on modest setups.
Now, let’s talk about local LLM deployment.
Sure, running a massive 450B model locally might sound like a pipe dream, but smaller, optimized models like Ollama are changing the game.
They’re designed to deliver high-quality results without requiring a supercomputer.
The misconception? Local equals slow. Not true.
With the right optimizations, local systems can rival cloud-based solutions in speed and precision. The result? A fully autonomous, secure, and efficient RAG system that’s entirely on your terms.
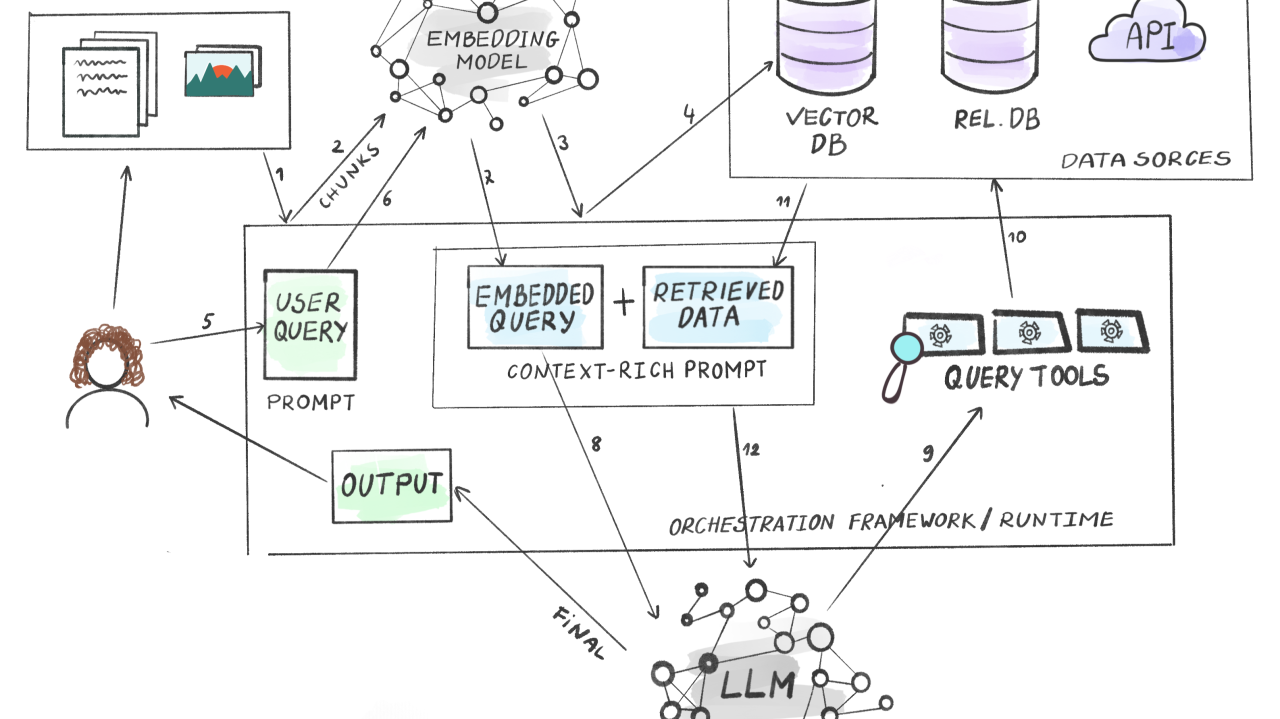
Generating Embeddings with FastEmbed
Let’s get real—embedding generation is where the magic starts, and FastEmbed is rewriting the rules.
Unlike heavyweight models that demand massive resources, FastEmbed thrives in low-resource environments, making it perfect for edge deployments or real-time applications.
Its lightweight architecture doesn’t just save costs; it accelerates workflows without compromising on semantic precision.
Now, let’s push the envelope.
Imagine a Semantic Efficiency Index (SEI)—a metric that balances embedding quality with computational cost.
FastEmbed would dominate this index, thanks to its optimized architecture and blazing-fast performance.
FastEmbed isn’t just about speed. Its adaptability allows industries like healthcare to embed patient records for real-time diagnostics, ensuring compliance with strict regulations.
Deploying Local LLMs with Ollama
Running a local LLM might sound like a tech marathon, but Ollama makes it feel like a sprint. Here’s the standout feature: privacy without compromise.
By deploying LLMs entirely offline, Ollama ensures sensitive data never leaves your environment. This isn’t just about security—it’s about control. You decide how the model behaves, adapts, and evolves.
Take a leading financial institution that used Ollama to build an internal chatbot. The result was a boost in response times while staying fully compliant with data protection laws.
The secret sauce? Ollama’s compatibility with smaller, optimized models like Ollama Llama 2, which deliver high-quality results without demanding supercomputer-level hardware.
Now, let’s challenge the myth that local equals slow. With advancements in chip technology and Ollama’s streamlined architecture, even mid-tier setups can run LLMs efficiently.
Imagine a Local Efficiency Index (LEI) measuring performance against resource use. Ollama would dominate, proving that local deployment is not only feasible but also game-changing.
Industries like healthcare could leverage Ollama for real-time diagnostics, ensuring compliance while delivering faster results.
FAQ
What are the benefits of using Langchain and Agno for building 100% local agentic RAG systems?
Langchain and Agno enable fully local RAG systems by ensuring privacy, efficiency, and adaptability. Langchain retrieves precise data from internal sources, while Agno transforms it into structured workflows. This setup eliminates external dependencies, reduces security risks, and ensures compliance with regulations like HIPAA and GDPR.
How do Langchain’s retrieval capabilities integrate with Agno’s workflow system to improve security and efficiency?
Langchain dynamically retrieves relevant data from internal knowledge bases, while Agno structures this data into workflows that execute tasks locally. This integration minimizes exposure to external networks, reducing security vulnerabilities. The system optimizes retrieval speed and task execution, making it practical for industries requiring strict data privacy.
Which industries benefit most from 100% local agentic RAG systems with Langchain and Agno?
The healthcare, finance, and legal industries benefit the most from these systems. Healthcare organizations process patient data securely, financial institutions analyze market trends without external exposure, and legal firms review case law while maintaining confidentiality. The manufacturing and government sectors also use these systems for private, domain-specific knowledge management.
How do Langchain and Agno ensure compliance with HIPAA, GDPR, and other data privacy laws?
Langchain and Agno operate entirely offline, preventing unauthorized data access. To restrict data exposure, they implement field-level encryption, differential privacy, and access controls.Keepingg processing within internal infrastructure, they help organizations comply with HIPAA, GDPR, and similar regulations without sacrificing retrieval and workflow performance.
What are the technical requirements and best practices for deploying Langchain and Agno in an offline RAG system?
Deploying Langchain and Agno offline requires high-performance local storage for vector databases, sufficient computational resources for embeddings, and optimized local LLMs. Best practices include modular system design, encryption, efficient chunking, and embedding generation. Regular audits and workflow monitoring further enhance security and operational efficiency.
Conclusion
Building 100% local agentic RAG systems with Langchain and Agno transforms AI applications by ensuring data privacy, security, and operational control.
Organizations gain autonomy over their knowledge workflows, eliminating reliance on external infrastructure.
As industries move toward domain-specific AI, these systems will define the next generation of retrieval-augmented intelligence—secure, adaptable, and efficient.