
Building Production-Ready RAG Applications: Essential Tips & Tools
Building a production-ready RAG application requires the right strategies and tools. This guide covers key best practices, performance optimization, and essential technologies to ensure scalability, accuracy, and efficiency in real-world AI applications.


Retrieval-Augmented Generation (RAG) is powerful, but there’s always the risk of implementations failing in real-world use.
Slow retrieval, outdated responses, and system failures make AI unreliable in high-stakes environments.
For example, let’s imagine a healthcare startup built a RAG model to help doctors find treatment guidelines. But there were multiple catches. The system lagged, queries pulled old research, and retrieval errors led to incorrect suggestions.
The bottom line? Patients’ lives were at risk.
A production-ready RAG application avoids these failures. It optimizes retrieval speed, structures data efficiently, and ensures accuracy at scale. This guide covers the essential techniques, tools, and strategies to build a production-ready RAG system that works in demanding real-world scenarios.
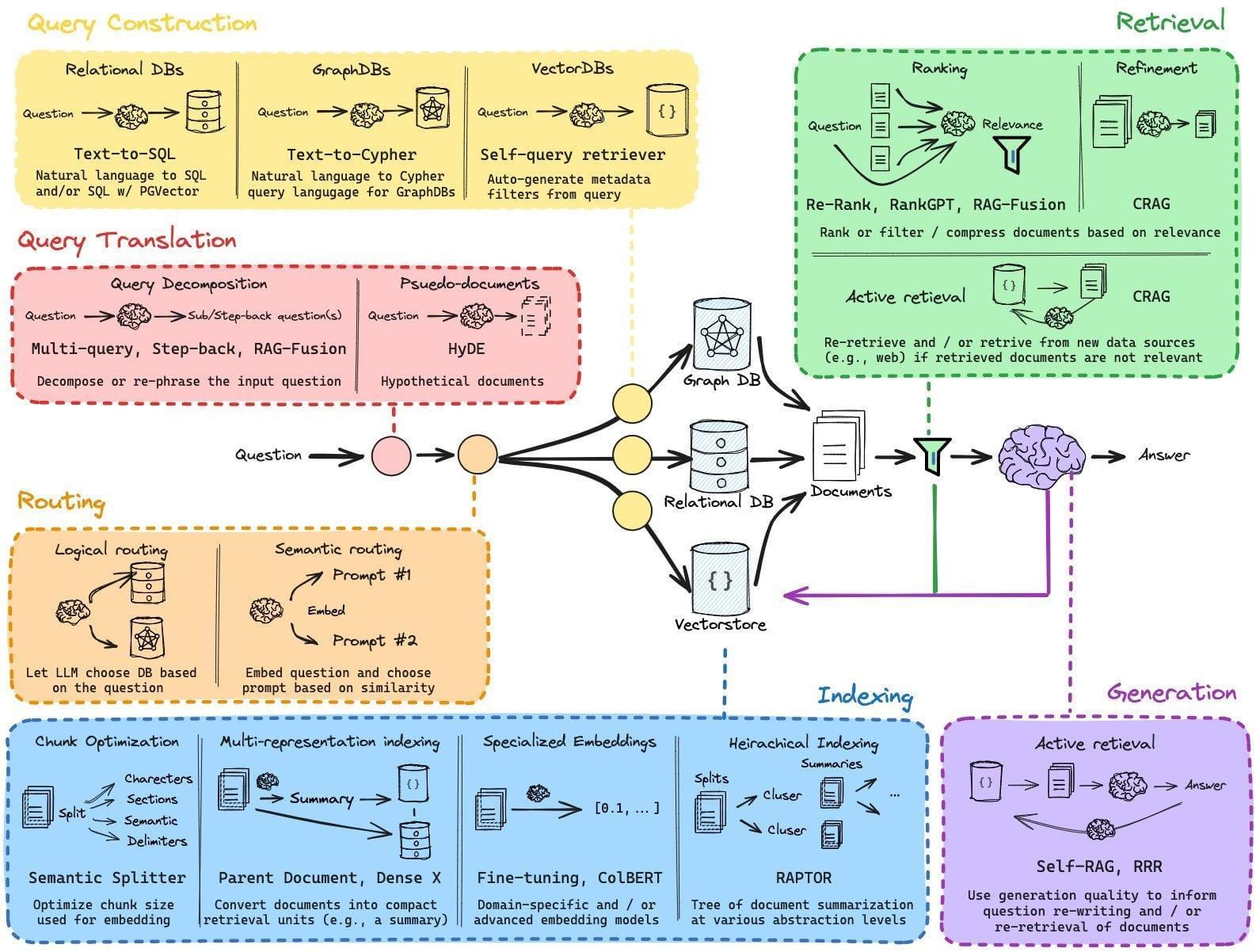
Understanding Retrieval-Augmented Generation
Let’s talk about retrieval precision—the unsung hero of RAG systems. Without it, even the most advanced generative models fall flat.
Why? Because the quality of what you generate is only as good as the data you retrieve.
Think of it like cooking: even a Michelin-star chef can’t make a great dish with harmful ingredients.
Take the case of Nexla, a data operations platform. They implemented a RAG system to retrieve clinical trial data for personalized cancer treatments.
By fine-tuning their retriever with semantic search algorithms and metadata tagging, they considerably improved patient outcomes.
But here’s the kicker: retrieval isn’t just about accuracy. It’s about contextual alignment. A poorly tuned retriever might pull technically relevant data but contextually off. This is where reinforcement learning shines.
Systems can refine retrieval strategies over time by using feedback loops, ensuring better alignment with user intent.
So, what’s the takeaway for you?
Focus on adaptive retrieval mechanisms. Whether it’s caching, domain-specific indexing, or real-time feedback, these tools ensure your RAG system doesn’t just work—it excels. And that’s how you build trust, one query at a time.
The Importance of Production-Ready Systems
Let’s face it: building a prototype RAG system is one thing, but making it production-ready?
That’s a whole different ballgame. One area that deserves your laser focus is retrieval optimization. Why? Because even the best generative models crumble under the weight of irrelevant or outdated data.
Take Google Health, for example. They implemented a RAG system to assist radiologists in diagnosing rare conditions.
Integrating semantic caching and real-time indexing reduced query latency and improved diagnostic accuracy. That’s not just efficiency—it’s life-saving precision.
Here’s the kicker: most developers overlook scalability. Without distributed systems like sharding or parallel processing, your RAG system will buckle under heavy traffic. And trust me, downtime isn’t just a technical issue—it’s a trust killer.
So, start with continuous feedback loops to refine retrieval accuracy.
Layer in domain-specific indexing for contextual relevance. And always, always stress-test for scalability. The result? A system that doesn’t just work—it thrives under pressure.
Core Components of RAG Systems
If you’ve ever wondered what makes a RAG system tick, it boils down to three core components: indexing, retrieval, and generation.
Think of these as your system's engine, fuel, and driver. Without all three working in harmony, you’re not going anywhere.
Let’s start with indexing. This is where your data gets prepped and stored in a vector database. Imagine finding a book in a library with no catalog—it’s chaos. Companies like PingCAP use advanced indexing pipelines to organize massive datasets, ensuring their RAG systems can retrieve relevant information in milliseconds.
Next is retrieval, the heart of RAG. But here’s the catch: retrieval isn’t just about finding data—it’s about finding the right data.
Finally, generation ties it all together. This is where the magic happens but also where hallucinations creep in. Guardrails like human-in-the-loop moderation can save you from embarrassing missteps.
Get these right, and your RAG system won’t just work—it’ll shine.
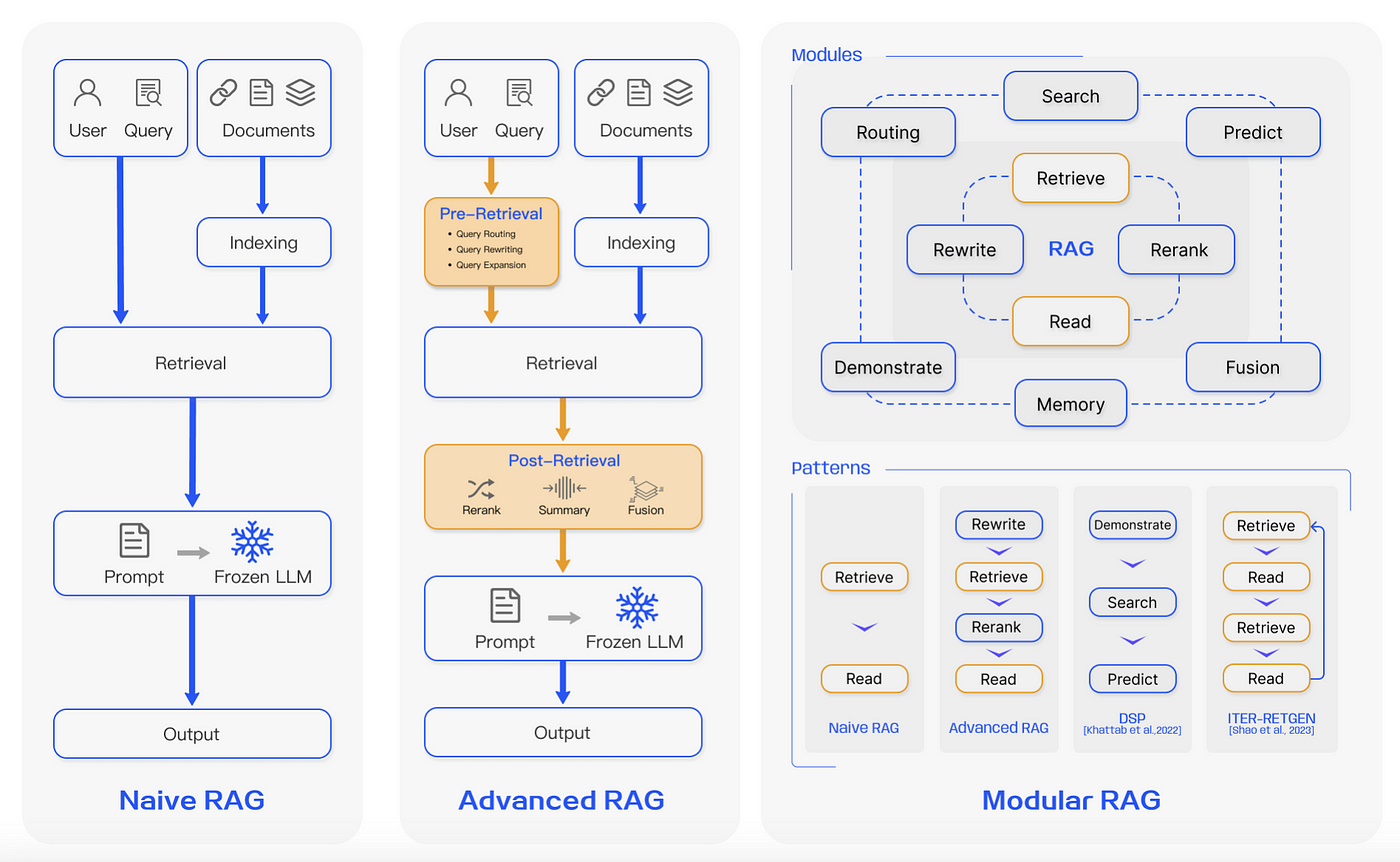
Data Ingestion and Preparation
Let’s talk about data ingestion—the foundation of any RAG system. If your data pipeline isn’t rock-solid, everything else crumbles.
I’ve seen companies like Databricks transform their RAG systems by focusing on this stage. By refining their ingestion workflows, they achieved a 30% boost in retrieval accuracy.
Here’s the deal: ingestion isn’t just about pulling data. It’s about structuring it for success. Metadata enrichment involves adding tags like source credibility or document type.
When Algo Communications implemented this, their customer service reps reported a drop in irrelevant responses. That’s real impact.
Now, consider embedding drift—a silent killer. As data evolves, embeddings lose relevance over time. Companies using recurring ingestion pipelines (like weekly updates) stay ahead, ensuring their systems remain accurate and grounded.
Embedding Generation and Vector Storage
Let’s talk about embedding generation—the heartbeat of any RAG system. If your embeddings are off, your entire system crumbles.
That’s why companies like Databricks fine-tune their embedding models on domain-specific datasets. It’s not just about generating vectors; it’s about generating smart vectors.
Here’s the kicker: dimensionality reduction. By trimming down vector dimensions without losing semantic meaning, you can cut computational costs while maintaining performance.
Tools like UMAP or PCA are game-changers here. But don’t stop there—pair this with dynamic chunking (like PingCAP does) to ensure your vectors are context-rich and retrieval-ready.
Optimizing Retrieval Processes
If your RAG system’s retrieval isn’t sharp, everything else falls apart. Think of it like a GPS: even the best car won’t get you anywhere if the directions are wrong. So, how do you make retrieval work? Let’s break it down.
First, hybrid search is a game-changer. By combining sparse methods (like TF-IDF) with dense embeddings, you get the best of both worlds: precision and context.
Next, don’t underestimate active learning. Systems that adapt based on user feedback get smarter over time. Take Nexla, for example. They used feedback loops to refine clinical trial retrieval, improving patient outcomes. It’s like teaching your system to think like your users.
Finally, avoid the trap of “more data = better results.” Without contextual filters, irrelevant noise creeps in. Instead, prioritize metadata tagging—Algo Communications saw a drop in irrelevant results by doing just that.
The takeaway? Retrieval isn’t just a step—it’s the step. Nail it, and everything else clicks.
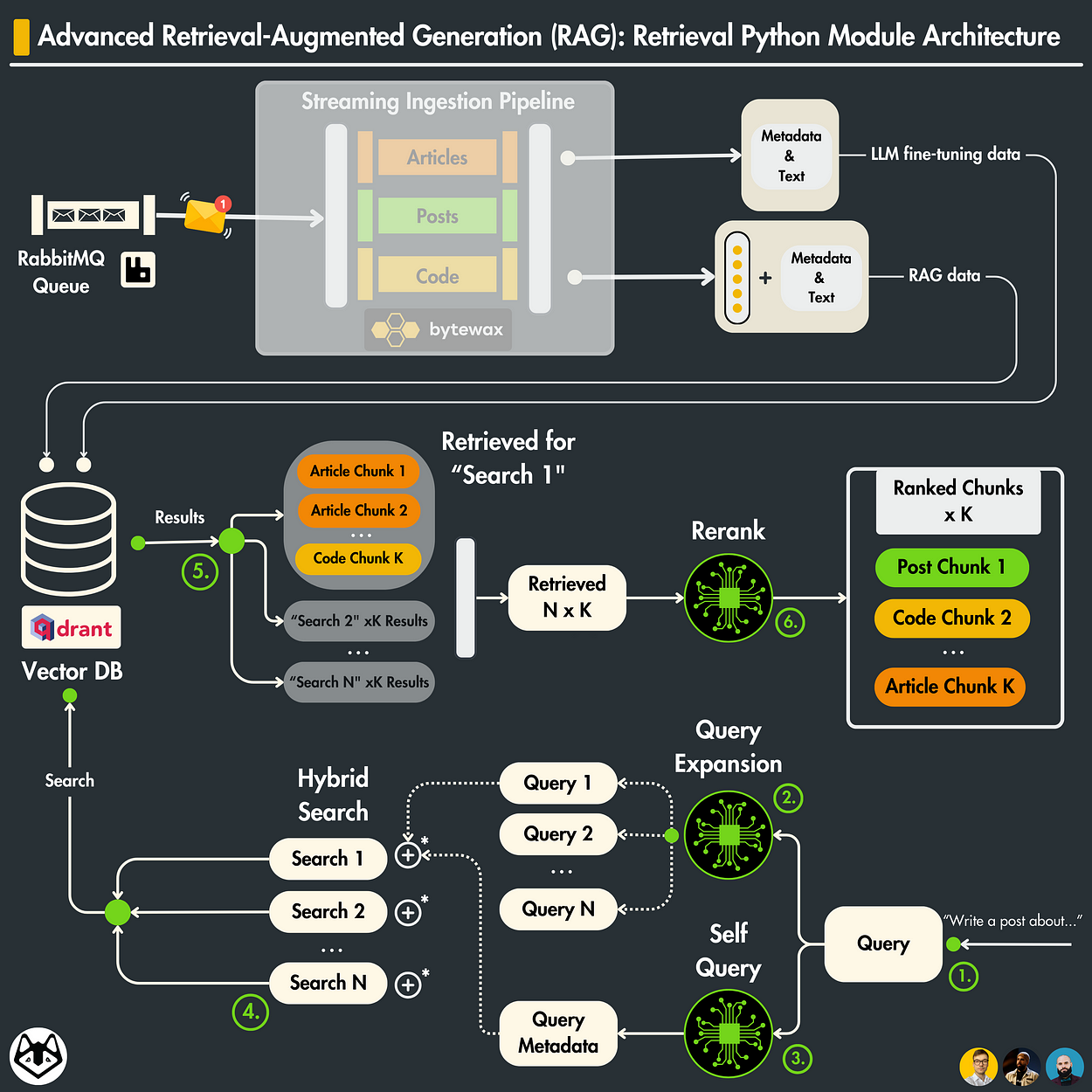
Advanced Retrieval Techniques
Let’s talk about re-ranking—the secret sauce behind precision in RAG systems.
Re-ranking isn’t just about sorting results; it’s about reshaping relevance. For instance, when Google Health applied re-ranking to radiology reports, they reduced diagnostic errors.
Why? Because re-ranking prioritizes context over raw similarity, ensuring the most meaningful data rises to the top.
Now, here’s where it gets interesting: hierarchical indexing. Think of it as a layered treasure map. Instead of searching everything at once, you start broad and zoom in. FalkorDB used this to organize legal documents, cutting retrieval times.
It’s like finding a needle in a haystack—except it is sorted into neat piles.
But here’s the kicker: dynamic query reformulation.
Picture this: you pose a question, and the system adjusts it in real-time during the search to deliver precisely what you require. This illustrates the strength of adaptability.
The misconception is that more data equals better results. Without metadata optimization, you’re just adding noise. Algo Communications saw a drop in irrelevant results after tagging datasets with domain-specific attributes.
Integrating real-time feedback loops could make retrieval even smarter. Imagine a system that learns from every query, evolving with your needs. That’s not just advanced—it’s transformative.
Hybrid Search and Re-ranking
If you’re serious about improving retrieval accuracy, you must focus on combining hybrid search and re-ranking. Why? Because this duo doesn’t just retrieve data—it ensures the right data surfaces, even in complex scenarios.
Take Dify.AI, for example. They integrated hybrid search (vector + keyword) with re-ranking to power their question-answering system.
By blending retrieval modes and prioritizing semantic relevance, they improved recall effectiveness. That’s not just a number—it’s a game-changer for user trust.
But let’s challenge the norm. Many assume more data equals better results. Wrong. Without metadata tagging, hybrid systems can drown in noise. Algo Communications avoided this by tagging datasets with domain-specific attributes, cutting irrelevant results.
Looking ahead, dynamic query reformulation could redefine hybrid search. Imagine a system that evolves mid-query, adapting to user intent in real-time. That’s not just innovation—it’s the future of retrieval.
Enhancing Response Generation
If your RAG system retrieves gold but generates gibberish, you’ve got a problem. Response generation is where everything comes together—or falls apart.
Here’s the deal: contextual coherence is king. I’ve seen companies like Nexla fine-tune their models on domain-specific datasets, boosting response accuracy. Generic models don’t cut it when precision matters.
But here’s a twist: bigger isn’t always better. A biotech firm once swapped a massive model for a smaller, fine-tuned one.
The result? An improvement in clinical trial insights. It’s proof that tailoring beats brute force.
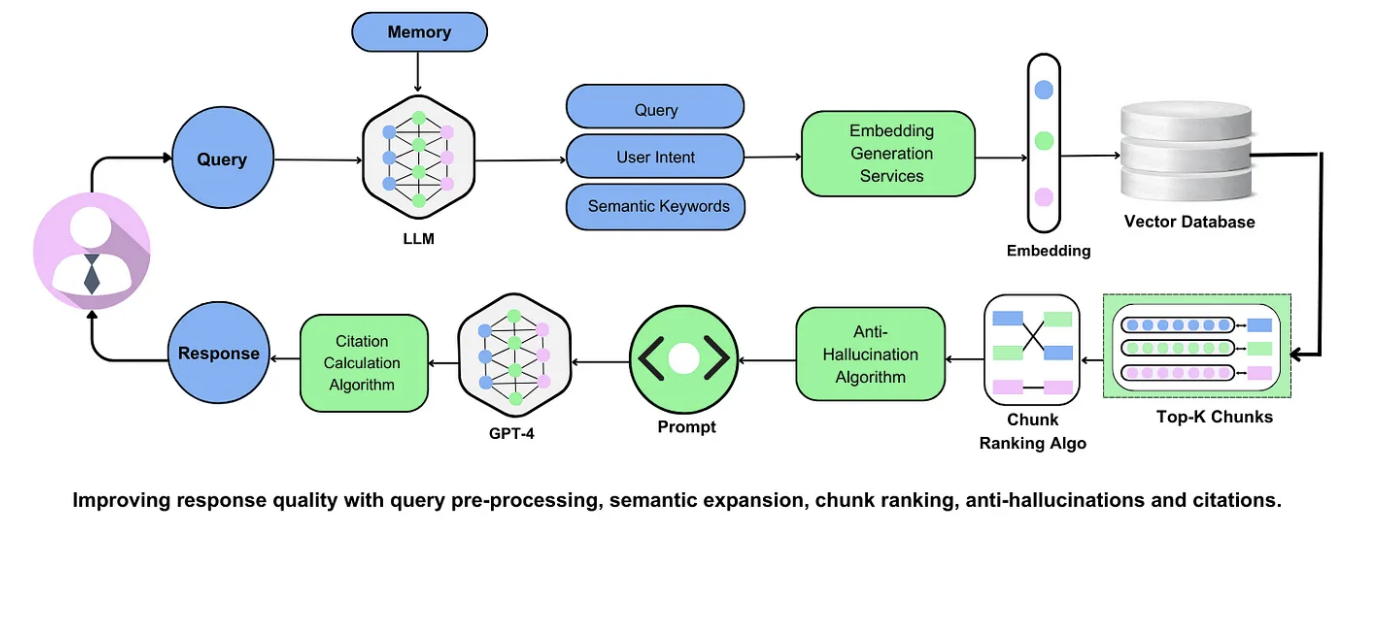
Implementing Caching Strategies
If you’re not using caching in your RAG system, you’re leaving performance on the table. Let’s talk about multi-layered caching—a strategy that balances speed and freshness like a pro.
But caching isn’t just about speed. It’s about smart invalidation. Imagine a customer support bot caching FAQs.
If the source data changes, stale responses can erode trust. Companies like Zilliz use time-to-live (TTL) policies and real-time monitoring to keep caches fresh and ensure relevance.
Here’s a thought experiment: What if you prioritized caching based on query cost? High-frequency, high-complexity queries would be cached first. This approach could save compute resources while maintaining responsiveness.
Looking ahead, integrating adaptive caching—where the system learns which queries to cache based on usage patterns—could redefine efficiency. The takeaway? Caching isn’t just a technical add-on; it’s a strategic lever for scaling RAG systems.
FAQ
What are the core components of a production-ready Retrieval-Augmented Generation (RAG) system?
A production-ready RAG system has three key parts: retrieval, generation, and storage. The retrieval engine fetches relevant data, the generation model processes it into coherent responses, and the knowledge repository stores structured and unstructured data. These elements must work together to ensure accuracy, efficiency, and scalability.
How does metadata tagging and semantic indexing improve retrieval accuracy?
Metadata tagging organizes data with labels like timestamps and categories, allowing for precise filtering. Semantic indexing converts data into vector representations, making retrieval more context-aware. Together, they reduce irrelevant results, speed up searches, and ensure retrieved data aligns with user intent.
What are the best practices for optimizing data ingestion pipelines in large-scale RAG systems?
A strong data ingestion pipeline includes dynamic chunking, metadata tagging, and frequent updates. It should clean data to remove duplicates and inconsistencies. Distributed processing helps scale the pipeline for large datasets. Regular updates prevent outdated retrievals, improving response accuracy and system reliability.
How does fine-tuning embedding models improve RAG accuracy?
Fine-tuning embeddings ensures they capture domain-specific nuances, improving relevance in retrieval. It reduces hallucinations by aligning retrieved documents with query intent. Techniques like synthetic data training and negative sampling further refine the model. Regular updates prevent drift, keeping results accurate over time.
What tools and techniques ensure scalability and low latency in RAG applications?
Vector databases like Pinecone and Milvus enable fast, scalable retrieval. Sharding and Kubernetes improve resource allocation. Semantic caching reduces redundant queries. Auto-scaling and load balancing optimize performance. Real-time indexing keeps responses accurate. Monitoring tools like Prometheus track system efficiency.
Conclusion
Building a production-ready Retrieval-Augmented Generation (RAG) system requires fine-tuned retrieval, structured data ingestion, and real-time indexing.
Metadata tagging, semantic search, and caching improve efficiency. Optimizing retrieval ensures the system remains accurate under heavy loads.
With the right techniques, RAG applications can deliver reliable, fast, and scalable AI-driven responses.