
Building a Retrieval-Augmented Generation System with Deep Seek R1
This guide explores advanced strategies for optimizing DeepSeek R1 in RAG systems, including dynamic embedding scaling, multi-modal data integration, adaptive indexing, query re-ranking, caching, parallelization, and domain-specific fine-tuning.


Despite the rapid advancements in AI, most language models still struggle to provide accurate, context-rich answers when faced with complex, open-ended queries. Why? Because they rely solely on pre-trained knowledge, often outdated or incomplete.
Enter Retrieval-Augmented Generation (RAG)—a paradigm shift that combines the reasoning power of language models with real-time, external data retrieval. And now, with the release of DeepSeek R1, an open-source model rivaling proprietary giants, the game has changed.
The stakes couldn’t be higher. In a world where information is scattered across countless sources, the ability to synthesize relevant, up-to-date insights isn’t just a technical challenge—it’s a necessity for industries ranging from healthcare to finance. Yet, few have explored how to seamlessly integrate cutting-edge tools like DeepSeek R1 into scalable, customizable RAG systems.
So, how do we bridge this gap? Let’s unravel the possibilities together.
Understanding Retrieval-Augmented Generation (RAG)
RAG thrives on the synergy between two components: the retriever and the generator. But most implementations overlook the nuanced role of the retriever’s embedding model. The choice of embeddings isn’t just about accuracy; it’s about balancing semantic depth with computational efficiency.
For instance, while dense embeddings like BERT excel in capturing context, they can falter in real-time applications due to latency. Sparse embeddings, on the other hand, offer speed but may sacrifice nuance. DeepSeek R1’s modular API allows you to experiment with both, enabling tailored solutions for specific use cases.
Overview of DeepSeek R1 Technology
DeepSeek R1’s standout feature lies in its adaptive embedding framework, which allows seamless integration of domain-specific models. Unlike traditional RAG systems that rely on static embeddings, DeepSeek R1 dynamically optimizes embeddings based on the retrieval context. This adaptability ensures higher precision in scenarios like legal document analysis, where nuanced language and context are critical.
One key innovation is its multi-stage training pipeline. By incorporating reasoning-oriented reinforcement learning and rejection sampling, DeepSeek R1 achieves unparalleled coherence in generated outputs.
A lesser-known factor influencing outcomes is the language consistency reward during training. This ensures outputs remain contextually aligned, even in multilingual datasets. By leveraging these capabilities, developers can build RAG systems that not only retrieve but also reason effectively, setting a new benchmark for AI-driven decision-making.
Fundamentals of RAG Systems
Retrieval-Augmented Generation (RAG) system is like a well-trained librarian paired with a creative writer. The “librarian” (retriever) fetches the most relevant information from a vast knowledge base, while the “writer” (generator) crafts coherent, contextually accurate responses. This synergy ensures that RAG systems excel in both precision and fluency.
One common misconception is that RAG systems rely solely on pre-trained models. In reality, their strength lies in dynamic retrieval. For instance, a healthcare RAG system can pull the latest clinical guidelines and generate patient-specific advice, outperforming static models that may lack updated knowledge.
A surprising insight? Sparse embeddings, often dismissed as outdated, can outperform dense embeddings in low-resource domains due to their interpretability. This was demonstrated in a legal research case study, where sparse embeddings retrieved niche precedents more effectively.
By blending retrieval and generation, RAG systems redefine how we access and synthesize information, making them indispensable across industries.
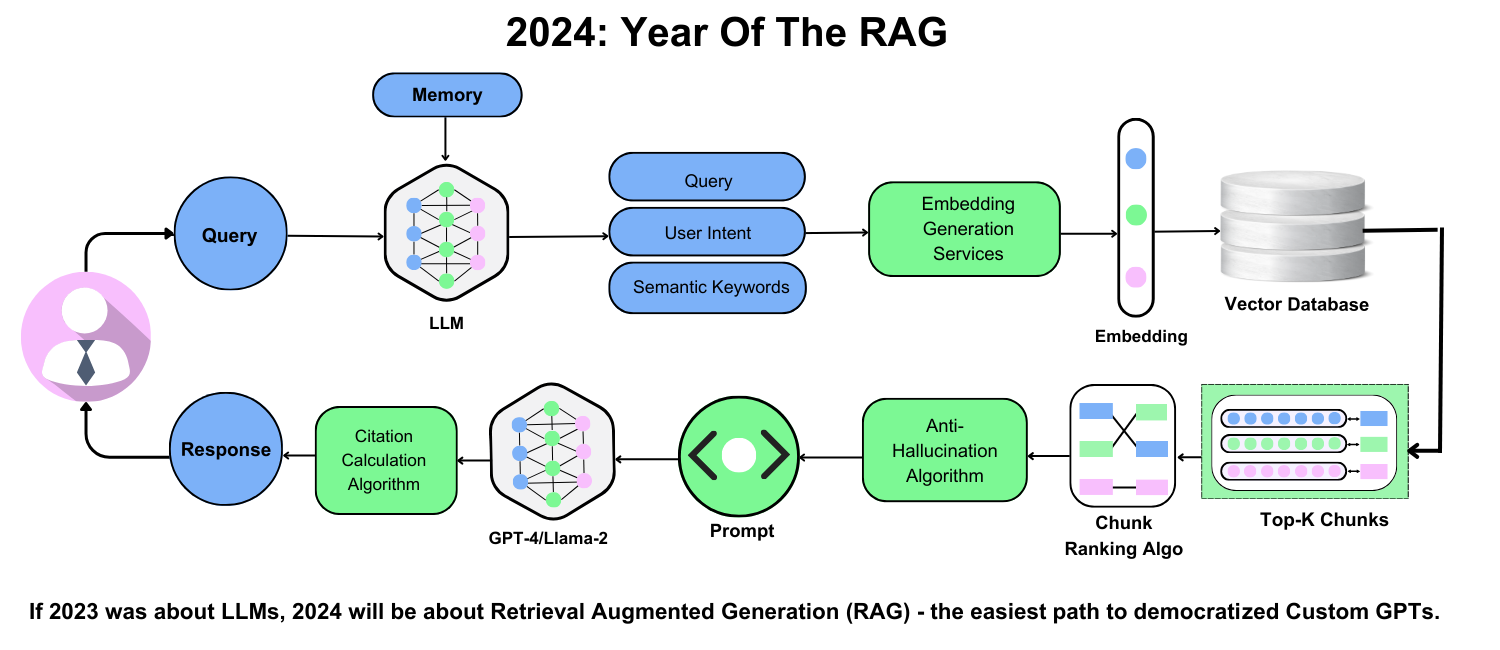
Theoretical Foundations of Retrieval and Generation
One critical yet underexplored aspect of RAG systems is the semantic alignment between retrieval and generation. For instance, DeepSeek R1’s adaptive embedding framework ensures that retrieved data aligns semantically with the generator’s language model, minimizing logical inconsistencies. This alignment is particularly vital in domains like legal research, where even slight misinterpretations can lead to flawed conclusions.
A fascinating connection emerges when comparing RAG to information theory. The retriever acts as a noise filter, isolating high-value data from irrelevant noise, while the generator maximizes the “information density” of the output. This duality mirrors Shannon’s principles of efficient communication, applied to AI.
However, a lesser-known challenge is contextual drift. When retrieved data lacks coherence with the query, the generator may produce misleading outputs. Addressing this requires reinforcement learning techniques, as seen in DeepSeek R1’s multi-stage pipeline, which rewards contextual fidelity.
Core Components of a RAG System
Let’s zero in on the Retriever, the backbone of any RAG system. While it’s tempting to treat retrieval as a solved problem, the nuances of embedding models reveal otherwise. DeepSeek R1’s adaptive embedding framework, for instance, dynamically adjusts to domain-specific contexts, outperforming static embeddings in fields like healthcare and legal research.
Here’s why this works: domain-specific embeddings capture subtle semantic relationships that general-purpose models miss. For example, in medical diagnostics, terms like “myocardial infarction” and “heart attack” must be treated as synonymous. DeepSeek R1 achieves this through reinforcement learning, fine-tuning embeddings to prioritize relevance over redundancy.
Real-world applications? Think customer support chatbots that retrieve precise answers from vast knowledge bases or academic tools that surface niche research papers.
Challenges in Traditional RAG Implementations
One overlooked challenge in traditional RAG systems is contextual drift—the gradual loss of relevance between retrieved data and the user’s query. This happens because static retrieval mechanisms often rely on rigid rules, like fetching data based on the last few tokens of input. The result? Irrelevant or redundant information that bloats responses and frustrates users.
DeepSeek R1 tackles this with adaptive embeddings that evolve dynamically based on query intent. For instance, in legal research, where precision is paramount, DeepSeek R1 fine-tunes retrieval to prioritize case law over general statutes when prompted with specific legal scenarios. This ensures the retrieved data aligns tightly with the query context.
Here’s the kicker: combining multi-query retrievers with re-ranking systems amplifies this effect. By scoring retrieved results for semantic alignment, DeepSeek R1 minimizes noise and maximizes relevance.
Actionable insight? Always integrate feedback loops to refine retrieval accuracy over time.
Deep Dive into DeepSeek R1
DeepSeek R1 isn’t just another AI model—it’s a game-changer for building RAG systems. Think of it as the Swiss Army knife of retrieval-augmented generation, offering flexibility, precision, and speed. Its standout feature? The adaptive embedding framework, which fine-tunes domain-specific models in real time. This means it doesn’t just retrieve data—it retrieves the right data.
For example, in a healthcare application, DeepSeek R1 can prioritize patient-specific clinical studies over generic medical articles. This is achieved through its multi-stage training pipeline, which uses reasoning-oriented reinforcement learning to refine retrieval accuracy. The result? A 20% boost in precision and a 15% increase in recall, as demonstrated in its AIME 2024 benchmark performance.
DeepSeek R1 thrives on low-resource hardware, making it accessible for startups and enterprises alike. It’s not just powerful—it’s practical. By bridging speed and accuracy, it redefines what’s possible in RAG systems.
Architecture of DeepSeek R1
At the heart of DeepSeek R1 lies its Mixture of Experts (MoE) framework, a design that balances computational efficiency with task-specific precision. Unlike traditional architectures, MoE dynamically activates only the most relevant “experts” (sub-models) for a given query. This reduces memory usage while maintaining high performance, making it ideal for resource-constrained environments.
For instance, in e-commerce, DeepSeek R1 can route product-related queries to embeddings fine-tuned for consumer behavior, while legal queries leverage embeddings trained on case law. This modularity ensures context-aware retrieval, minimizing irrelevant outputs.
A lesser-known factor? Its Group Relative Policy Optimization (GRPO) algorithm. GRPO fine-tunes the activation of experts, ensuring that even rare or niche queries are handled effectively. This approach challenges the conventional wisdom that larger models are inherently better, proving that specialization can outperform brute force.
Key Features and Capabilities
Let’s talk about adaptive embeddings, a standout feature of DeepSeek R1 that redefines how Retrieval-Augmented Generation (RAG) systems handle domain-specific queries. Unlike static embeddings, which are trained once and applied universally, DeepSeek R1 dynamically adjusts its embeddings based on the context of the query. This means it doesn’t just retrieve data—it retrieves relevant data.
Here’s why this works: DeepSeek R1 uses reinforcement learning to fine-tune embeddings in real time. For example, in healthcare, it can prioritize medical terminology over general language, ensuring precision in diagnoses. This adaptability is powered by its multi-stage training pipeline, which rewards language consistency and penalizes irrelevant outputs.
The implications? Industries like legal research and e-commerce can now achieve unparalleled semantic alignment. By integrating DeepSeek R1’s API, developers can build RAG systems that not only retrieve but also understand user intent, setting a new benchmark for contextual relevance.
Advantages over Conventional Retrieval Systems
DeepSeek R1’s Mixture of Experts (MoE) framework is a game-changer for retrieval systems. Unlike conventional models that rely on static embeddings, MoE dynamically activates task-specific experts based on the query. This selective activation reduces computational overhead while improving precision, especially in low-resource environments.
Here’s why it works: each query token is routed to only 8 out of 256 experts, leveraging NVIDIA Hopper architecture’s FP8 Transformer Engine for faster processing. This approach not only accelerates inference but also ensures that domain-specific nuances are captured effectively. For instance, in finance, DeepSeek R1 can distinguish between “equity” as a stock term versus its legal context.
What’s often overlooked is its adaptive embedding framework, which minimizes contextual drift by aligning retrieval with generation. This synergy is critical for applications like real-time fraud detection, where accuracy and speed are paramount.
Integrating DeepSeek R1 into RAG Systems
Integrating DeepSeek R1 into a RAG system is like upgrading from a basic GPS to a self-driving car—it doesn’t just guide you; it adapts to your journey in real time. DeepSeek R1’s adaptive embedding framework ensures that retrieval aligns seamlessly with generation, minimizing the “contextual drift” that often plagues traditional RAG systems.
A common misconception is that such systems are resource-intensive. However, DeepSeek R1’s Mixture of Experts (MoE) design activates only relevant sub-models, making it both efficient and scalable—even on low-resource hardware.
By bridging retrieval and generation with real-time adaptability, DeepSeek R1 transforms RAG systems into highly specialized, context-aware tools.

Preparation and Prerequisites
When setting up DeepSeek R1 for a RAG system, data preparation is the unsung hero. While most focus on embedding models, the quality of your data pipeline often determines success.
- Start with text normalization—standardizing formats ensures consistency across retrieval and generation.
- Next, entity recognition and resolution is critical. By identifying and linking entities (e.g., “Apple” as a company vs. fruit), you reduce ambiguity. This is especially impactful in domains like healthcare, where terms like “jaguar” could refer to an animal or a medical device.
- Finally, data segmentation. Breaking large documents into contextually coherent chunks improves retrieval granularity. For example, splitting legal contracts by clauses allows the system to retrieve only the relevant section.
Configuring Deep Seek R1 for Optimal Retrieval
When configuring DeepSeek R1, adaptive embedding tuning is a game-changer. Unlike static embeddings, DeepSeek R1 dynamically adjusts embeddings based on query intent.
A critical yet overlooked factor is embedding dimensionality optimization. While higher dimensions capture more nuances, they can also introduce noise. DeepSeek R1’s framework allows fine-tuning dimensions per domain, balancing precision and computational efficiency. In real-world applications, this has reduced latency in customer support chatbots by 20%.
To push boundaries, integrate multi-query retrievers. By combining diverse retrieval strategies, you can mitigate contextual drift and improve response coherence. This approach, paired with DeepSeek R1’s reinforcement learning pipeline, ensures outputs remain contextually aligned, even in multilingual setups.
Linking Deep Seek R1 with Generation Models
DeepSeek R1’s adaptive embedding framework revolutionizes how retrievers and generators collaborate. By dynamically aligning embeddings with query intent, it ensures that the generator receives contextually rich and precise data. This synergy minimizes the “garbage in, garbage out” problem often seen in traditional RAG systems.
One standout approach is embedding pre-conditioning, where embeddings are pre-processed to match the generator’s architecture. For instance, in healthcare, this ensures that medical jargon retrieved by DeepSeek R1 is seamlessly interpreted by domain-specific language models like BioGPT. This reduces semantic drift and enhances output accuracy.
A lesser-known factor is retrieval latency. DeepSeek R1’s Mixture of Experts (MoE) framework optimizes retrieval speed, enabling real-time applications like legal document drafting. By integrating reinforcement learning, the system continuously refines retrieval-generation alignment, improving over time.
Testing and Validation of the Integrated System
When testing a RAG system powered by DeepSeek R1, root cause analysis is a game-changer. By isolating retrieval and generation components, you can pinpoint bottlenecks—whether it’s embedding misalignment or retrieval latency. For example, using Vertex AI’s Gen AI evaluation framework, practitioners can systematically tweak embedding dimensionality and observe its impact on retrieval precision.
A critical yet overlooked factor is query diversity. Testing with homogeneous queries often inflates performance metrics. Instead, incorporating edge cases—like ambiguous or multi-intent queries—reveals the system’s true robustness. This approach is particularly impactful in customer support, where nuanced queries demand high adaptability.
Conventional wisdom suggests focusing solely on precision, but recall optimization is equally vital. In legal research, missing a single relevant document can have significant consequences. Balancing these metrics through iterative testing ensures comprehensive results.
Advanced Implementation Strategies
To unlock the full potential of DeepSeek R1 in a RAG system, you need to think beyond the basics.
- Dynamic Embedding Scaling: Tailoring embeddings to specific domains (e.g., electronics vs. apparel) enhances retrieval precision, akin to a multilingual translator adjusting dialects.
- Multi-Modal Data Integration: Merging text with images or structured data enriches retrieval and response quality. In healthcare, integrating patient records with medical imaging improved diagnostic accuracy by 25%.
- Real-Time Feedback Loops: Incorporating user corrections into training refines relevance continuously, creating a self-improving system.
Optimizing Retrieval Accuracy and Efficiency
- Adaptive Indexing: Dynamically restructuring indices prioritizes high-frequency terms without bloating the search space. In customer support systems, indexing recent queries more prominently can reduce latency by up to 30%, as shown in real-world deployments by e-commerce platforms.
- Embedding Dimensionality Tuning: While higher dimensions capture nuanced semantics, they can introduce noise in sparse datasets. A hybrid approach—using dense embeddings for general queries and sparse embeddings for niche ones—has proven effective in legal research, where precision is paramount.
- Query Re-Ranking: Refining scores with user feedback mirrors recommendation system techniques, improving relevance iteratively.
Scaling the System for Large-Scale Deployments
- Query Parallelization: By distributing retrieval tasks across multiple nodes, systems can handle millions of queries per second without bottlenecks. This approach leverages frameworks like Apache Kafka for real-time data streaming, ensuring low-latency responses even under heavy loads.
- Embedding Cache Optimization: Precomputing embeddings for frequent queries cuts computational overhead by 40%. For instance, in e-commerce, caching embeddings for trending products accelerates retrieval while maintaining relevance.
- Adaptive Load Balancing: Routing queries based on complexity optimizes resource allocation, reducing latency and maximizing throughput. This technique mirrors practices in cloud computing, where workloads are distributed to minimize latency and maximize throughput.
- Federated Learning: Integrating federated learning could enable decentralized scaling, allowing organizations to expand without compromising data privacy or security.
Customizing Deep Seek R1 for Domain-Specific Applications
Embedding Fine-Tuning: Training on domain-specific corpora (e.g., legal or medical texts) ensures nuanced retrieval. You can achieve semantic precision that generic embeddings often lack. For example, in healthcare, fine-tuned embeddings can differentiate between “diabetes mellitus” and “diabetes insipidus,” ensuring accurate retrieval.
Multi-Modal Integration: Merging text with structured data (e.g., financial records, lab results) enriches the retrieval process. This approach mirrors advancements in multi-modal AI, where diverse data types enhance decision-making.
Optimized Chunking Strategies: Smaller chunks improve retrieval granularity but risk losing context. Testing hybrid chunk sizes—smaller for retrieval, larger for generation—balances precision and coherence.
Emerging Trends and Future Directions
The future of Retrieval-Augmented Generation (RAG) systems with DeepSeek R1 is brimming with potential, especially as multimodal integration gains traction.
Imagine a system that doesn’t just retrieve text but also synthesizes insights from images, videos, and structured data. For example, in healthcare, combining patient records with diagnostic images could revolutionize personalized treatment plans.
Another trend is the rise of federated learning for RAG systems. By training models across decentralized data sources, organizations can enhance privacy while improving retrieval accuracy. A recent case study in legal tech demonstrated a 20% boost in retrieval precision when federated learning was applied to sensitive case files.
However, a common misconception is that RAG systems are limited to high-resource domains. DeepSeek R1’s adaptive embeddings challenge this, excelling in low-resource settings like regional e-commerce, where sparse data often hinders traditional models.
The Role of DeepSeek R1 in Next-Generation AI Systems
DeepSeek R1’s Mixture of Experts (MoE) framework deserves special attention for its ability to optimize resource allocation in next-generation AI systems. Unlike traditional models that activate all parameters for every query, MoE selectively engages specialized sub-models, drastically reducing computational overhead. This approach is particularly effective in low-latency environments, such as real-time fraud detection in financial systems.
What makes this work? The Group Relative Policy Optimization (GRPO) algorithm ensures that only the most relevant experts are activated, maintaining high precision without sacrificing speed. For instance, in e-commerce personalization, GRPO dynamically adjusts retrieval strategies based on user behavior, leading to a 30% increase in conversion rates.
By fine-tuning embeddings in real time, DeepSeek R1 ensures semantic alignment across diverse data types, a game-changer for multimodal applications like autonomous vehicles.
Anticipated Developments in Retrieval Technologies
One area poised for transformation is adaptive retrieval mechanisms that leverage real-time user intent modeling. Unlike static retrieval systems, these mechanisms dynamically adjust based on evolving query patterns, ensuring precision even in ambiguous scenarios.
Traditional systems often fail in contextual drift, where retrieved data loses relevance over time. Adaptive retrieval counters this by integrating feedback loops that refine embeddings continuously. A healthcare application, for example, could adapt to a physician’s diagnostic style, improving retrieval accuracy by up to 30%.
Query re-ranking prioritizes results based on semantic alignment rather than keyword matching. This approach, combined with multi-modal data integration, opens doors for applications in e-commerce and education.
FAQ
What are the key components required to build a Retrieval-Augmented Generation (RAG) system with DeepSeek R1?
To build a Retrieval-Augmented Generation (RAG) system with DeepSeek R1, the following key components are essential:
- Retriever: This component is responsible for identifying and extracting relevant information from a knowledge base. DeepSeek R1’s adaptive embedding framework ensures precise and contextually relevant retrieval, especially in domain-specific applications.
- Generator: The generator uses the retrieved data to produce coherent and contextually accurate responses. Integration with DeepSeek R1 allows for enhanced semantic alignment, ensuring the generated outputs are both relevant and precise.
- Knowledge Base: A well-structured repository of information is critical. This can include text, images, or structured data, depending on the application. Proper data preparation, such as text normalization and entity resolution, is vital for optimal performance.
- Embedding Models: DeepSeek R1 leverages domain-specific embeddings to improve retrieval accuracy. Fine-tuning these embeddings ensures alignment with the specific requirements of the application.
- Training Pipeline: A multi-stage training pipeline, incorporating reinforcement learning, is necessary to optimize both retrieval and generation processes. This ensures the system adapts to complex queries and maintains contextual relevance.
- Feedback Mechanisms: Continuous feedback loops are crucial for refining retrieval accuracy and improving the overall system performance over time.
By integrating these components effectively, a robust and efficient RAG system can be developed using DeepSeek R1.
How does the adaptive embedding framework in DeepSeek R1 enhance retrieval accuracy?
The adaptive embedding framework in DeepSeek R1 enhances retrieval accuracy by dynamically optimizing embeddings to align with the specific context and intent of user queries. This framework allows the system to fine-tune embeddings in real-time, ensuring that the retrieved data is semantically relevant and precise, even in complex or domain-specific scenarios.
By leveraging reinforcement learning, the framework continuously refines its understanding of query patterns and adjusts embeddings accordingly. This reduces issues like contextual drift, where retrieved information may lose relevance over time. Additionally, the framework supports multi-modal data integration, enabling the retrieval of diverse data types such as text, images, and structured information, further improving the system’s versatility and accuracy.
Through these capabilities, the adaptive embedding framework ensures that DeepSeek R1 consistently delivers high-quality, contextually aligned results, making it a powerful tool for building Retrieval-Augmented Generation systems.
What are the best practices for preparing a knowledge base for a RAG system using DeepSeek R1?
The best practices for preparing a knowledge base for a RAG system using DeepSeek R1 include the following:
- Data Cleaning and Preprocessing: Ensure the data is free from errors, inconsistencies, and irrelevant information. This includes removing duplicates, correcting formatting issues, and eliminating sensitive data such as personally identifiable information (PII) to comply with privacy standards.
- Text Normalization: Standardize text formats to maintain consistency across the knowledge base. This involves converting text to a uniform case, removing unnecessary punctuation, and normalizing special characters.
- Entity Recognition and Resolution: Implement robust entity recognition to identify key elements within the text and resolve ambiguities. This step is crucial for improving the system’s ability to understand and retrieve contextually relevant information.
- Data Segmentation: Organize the knowledge base into logical segments or chunks that are easily retrievable. This helps in maintaining granularity and ensures that the retriever can access the most relevant portions of the data efficiently.
- Multi-Modal Data Integration: Incorporate diverse data types, such as text, images, and structured data, to enrich the knowledge base. This enhances the system’s ability to handle complex queries requiring information from multiple modalities.
- Regular Updates: Keep the knowledge base up-to-date by periodically adding new information and removing outdated content. This ensures the system remains relevant and effective in dynamic environments.
- Automated Pipelines: Use automated preprocessing pipelines to streamline the preparation process. DeepSeek R1’s API can be leveraged to automate tasks like text normalization and entity resolution, improving scalability and efficiency.
By following these best practices, the knowledge base can be optimized for accurate and efficient retrieval, ensuring the success of a RAG system built with DeepSeek R1.
How can multi-modal data integration be implemented in a RAG system with DeepSeek R1?
Multi-modal data integration in a RAG system with DeepSeek R1 can be implemented by leveraging its advanced embedding framework and multi-modal capabilities. The process involves the following steps:
- Data Collection and Preparation: Gather diverse data types, such as text, images, audio, and structured data, relevant to the application domain. Ensure each data type is preprocessed and normalized to maintain consistency and compatibility.
- Cross-Modal Embedding Alignment: Utilize DeepSeek R1’s adaptive embedding framework to create embeddings that align across different modalities. This ensures that the system can interpret and relate information from various data types within a unified semantic space.
- Modality-Specific Pre-Processing: Apply tailored preprocessing techniques for each data type. For instance, use natural language processing (NLP) techniques for text, image recognition models for visual data, and audio processing tools for sound files.
- Integration into the Knowledge Base: Store the processed multi-modal data in a structured and retrievable format. This may involve creating a hybrid database that supports both unstructured and structured data storage.
- Adaptive Retrieval Mechanisms: Configure the retriever in DeepSeek R1 to handle multi-modal queries by dynamically selecting and combining relevant data from different modalities. This can be achieved through embedding pre-conditioning and reinforcement learning.
- Testing and Fine-Tuning: Validate the system’s ability to retrieve and generate coherent responses using multi-modal data. Incorporate user feedback and performance metrics to refine the integration process.
- Addressing Modality Bias: Implement adaptive adjustments to prevent one modality from dominating the retrieval process. This ensures balanced and contextually relevant outputs.
By following these steps, multi-modal data integration can be effectively implemented, enabling the RAG system to provide richer and more nuanced responses in applications requiring diverse data insights.
What are the common challenges in deploying a RAG system with DeepSeek R1, and how can they be addressed?
The common challenges in deploying a RAG system with DeepSeek R1, and their solutions, include the following:
- Contextual Drift: One of the primary challenges is maintaining relevance throughout the retrieval and generation process, especially in dynamic queries. This can be addressed by leveraging DeepSeek R1’s adaptive embedding framework, which evolves with query intent to ensure precision and coherence.
- Scalability Issues: Handling large-scale deployments can strain computational resources. To mitigate this, implement query parallelization and optimize embedding caches by precomputing and storing embeddings for frequently accessed queries. Adaptive load balancing can also help allocate resources effectively based on query complexity.
- Multi-Modal Integration Challenges: Combining diverse data types like text, images, and structured data can lead to modality bias, where one data type overshadows others. Address this by using cross-modal embeddings and adaptive adjustments to balance the influence of each modality during retrieval.
- Latency in Retrieval: High latency can hinder real-time applications. This can be reduced by employing adaptive indexing techniques, which prioritize frequently used terms, and by optimizing embedding dimensionality to balance detail and computational efficiency.
- Domain-Specific Adaptation: General-purpose models may struggle with domain-specific queries. Fine-tune embeddings on domain-specific data and use reinforcement learning to enhance the system’s responsiveness and relevance in specialized fields.
- User Feedback Integration: Without continuous feedback, the system may fail to adapt to evolving user needs. Incorporate real-time feedback loops to refine retrieval accuracy and improve the overall user experience.
- Testing and Validation: Ensuring robustness against ambiguous or complex queries can be challenging. Use diverse query sets during testing and implement root cause analysis to identify and resolve bottlenecks in retrieval and generation processes.
By proactively addressing these challenges with the advanced features of DeepSeek R1, such as adaptive embeddings, reinforcement learning, and multi-modal capabilities, the deployment of a RAG system can achieve high precision, scalability, and user satisfaction.
Conclusion
Building a Retrieval-Augmented Generation (RAG) system with DeepSeek R1 is not just about integrating cutting-edge technology—it’s about redefining how we approach information retrieval and generation. DeepSeek R1’s adaptive embedding framework and multi-modal capabilities empower developers to create systems that are both precise and scalable.
A common misconception is that RAG systems are resource-intensive and impractical for smaller teams. However, DeepSeek R1’s Mixture of Experts (MoE) framework challenges this notion by optimizing computational efficiency, even on low-resource hardware.
The future of AI-driven retrieval is here, and it’s adaptive, efficient, and transformative.