
Getting Started with Cache Augmented Generation in RAG
Cache-Augmented Generation boosts RAG efficiency by storing frequently accessed data for faster retrieval. This guide covers the fundamentals, benefits, and implementation strategies to enhance AI-driven knowledge retrieval and reduce latency.


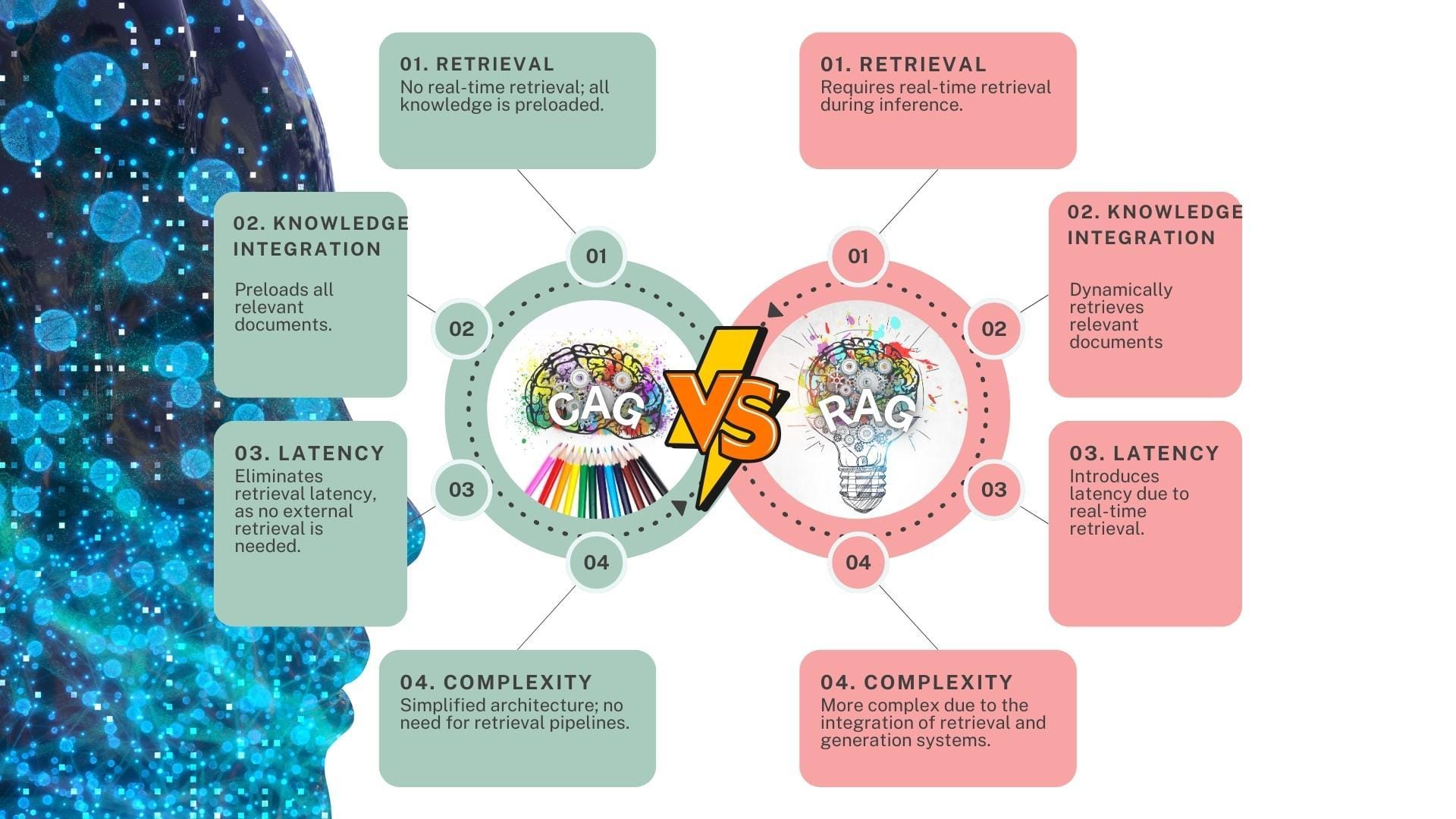
Large language models struggle with a common trade-off: speed vs. accuracy. Retrieval-Augmented Generation (RAG) has long been the standard for integrating external knowledge into AI systems, but it comes at a cost—slow retrieval times, complex pipelines, and inconsistent results.
A new approach is challenging this norm. Cache-Augmented Generation (CAG) preloads relevant knowledge directly into the model’s extended context, eliminating retrieval delays while maintaining precision.
The implications are huge. Imagine AI models that can respond instantly to complex queries, provide consistent answers across interactions, and operate without relying on real-time search engines. Industries like finance, healthcare, and legal research stand to benefit from this shift.
This article explains how Cache-Augmented Generation works, when to use it over RAG, and how to implement it effectively.
Core Concepts of CAG
Cache-Augmented Generation (CAG) fundamentally redefines knowledge integration by embedding preloaded datasets into the extended context windows of large language models (LLMs).
This approach eliminates the need for real-time retrieval, streamlining operations and enhancing reliability. Unlike RAG, where external retrieval introduces latency and potential inconsistencies, CAG ensures that all necessary knowledge is immediately accessible.
For instance, IBM’s integration of CAG in its Granite LLMs improved query response times by leveraging preloaded regulatory documents for compliance checks.
An unexpected advantage of CAG is its ability to maintain contextual coherence over extended interactions. CAG avoids the pitfalls of fragmented retrieval pipelines by preloading domain-specific knowledge, such as medical guidelines or legal precedents.
This makes it particularly effective in high-stakes healthcare environments where consistency is critical.
However, a common misconception is that CAG is limited to static datasets.
Emerging hybrid models suggest dynamic updates to preloaded caches can bridge this gap, combining adaptability and efficiency. As LLMs evolve, CAG’s potential to balance simplicity and scalability will redefine knowledge-intensive workflows.
Preloading Relevant Documents
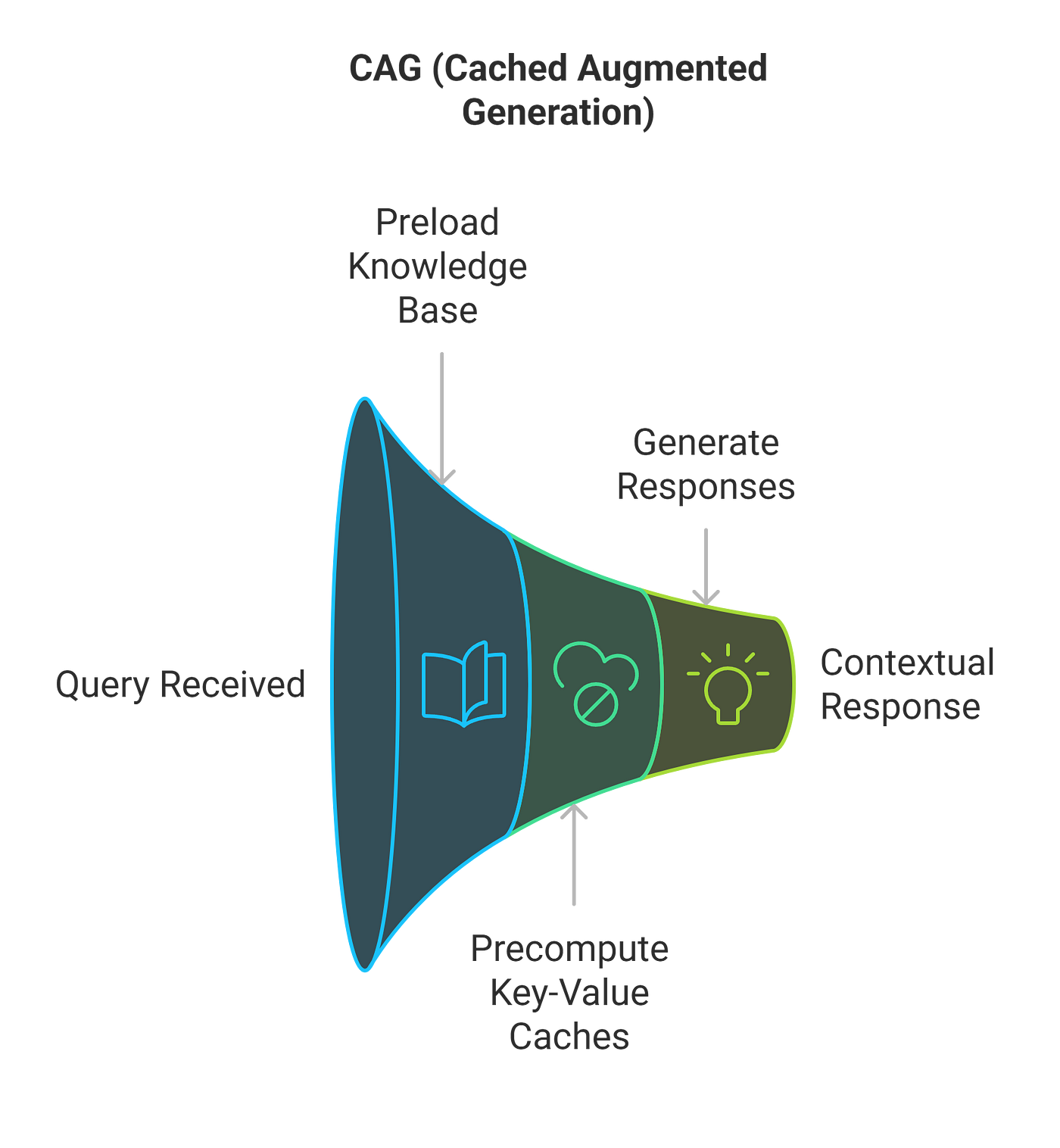
Preloading relevant documents in Cache-Augmented Generation (CAG) is a critical step that directly impacts the system’s efficiency and accuracy.
This process involves curating, preprocessing, and encoding datasets into the model’s key-value (KV) cache, ensuring immediate accessibility during inference.
The success of this approach hinges on document prioritization and context optimization.
For example, Bloomberg’s financial analytics system leverages CAG by preloading datasets such as historical market trends and regulatory guidelines.
A unique insight emerges when considering chunk optimization—breaking documents into smaller, contextually relevant segments.
This technique minimizes redundancy and maximizes token efficiency, particularly in LLMs with context windows exceeding 32,000 tokens. Additionally, dynamic knowledge prioritization allows models to adapt preloaded caches based on query patterns, bridging the gap between static and dynamic datasets.
Looking forward, integrating automated document curation using machine learning could further refine preloading workflows, ensuring scalability and adaptability across diverse applications.
Precomputation of Key-Value Caches
Pre-computation of key-value (KV) caches is a cornerstone of Cache-Augmented Generation (CAG). CAG enables retrieval-free inference by storing reusable context representations.
This process involves encoding preloaded datasets into a KV cache, which captures the model’s inference state and significantly reduces computational redundancy.
A notable application is IBM’s Granite LLMs, which utilize precomputed KV caches for compliance checks. By encoding regulatory documents into the cache, IBM improved query response times while maintaining high accuracy.
This efficiency stems from eliminating repetitive computations during inference, allowing the model to focus solely on query-specific processing.
An emerging trend is adaptive cache encoding, where the KV cache dynamically adjusts based on query patterns.
This approach optimizes memory usage and ensures that high-priority data remains accessible. Additionally, cache segmentation—dividing the cache into modular components—enhances scalability by isolating domain-specific knowledge.
Future strategies should explore hierarchical caching models. In these models, multi-layered caches prioritize critical data while offloading less relevant information, ensuring sustained performance in increasingly complex workflows.
Utilizing Extended Context in LLMs
The extended context capabilities of modern LLMs, such as GPT-4 (32k tokens) and Claude 2 (100k tokens), have redefined the boundaries of Cache-Augmented Generation (CAG).
Extended context windows accommodate larger datasets within a single inference cycle, reducing the need for aggressive document chunking, preserving coherence, and improving response accuracy.
A compelling case study is Anthropic’s deployment of Claude 2 in customer support systems. By leveraging its 100k-token context window, the model preloaded comprehensive product manuals and troubleshooting guides.
This approach reduced average resolution times as users received contextually rich, uninterrupted responses without retrieval delays.
Key Insight: Extended context windows enable contextual layering, where hierarchical knowledge—such as general guidelines followed by specific case studies—is embedded seamlessly. This structure enhances the model’s ability to address complex, multi-faceted queries.
Emerging trends suggest that context prioritization algorithms will be pivotal in optimizing token allocation within extended windows. For instance, dynamically weighting high-relevance sections ensures critical information remains accessible without exceeding token limits.
Future strategies should explore context compression techniques to maximize utility, ensuring scalability as context windows expand further.
Implementing CAG in RAG Systems
Integrating Cache-Augmented Generation (CAG) into Retrieval-Augmented Generation (RAG) systems requires a strategic blend of preloading efficiency and retrieval adaptability.
A key insight is that CAG can act as a stabilizing layer, preloading static, high-priority datasets while RAG dynamically retrieves volatile or time-sensitive information. This hybrid approach ensures both reliability and adaptability.
For instance, a healthcare platform could preload medical guidelines and historical patient data using CAG, while employing RAG to fetch real-time updates on drug recalls or emerging research.
This dual-layered system minimizes latency and enhances decision-making accuracy in critical scenarios.
A common misconception is that CAG’s preloaded caches are inherently static. However, dynamic cache updates—triggered by query patterns or scheduled refreshes—can bridge the gap between static and dynamic data needs.
This flexibility is exemplified by IBM’s Granite LLMs, which periodically update regulatory caches to maintain compliance accuracy.
Future implementations should explore cache prioritization algorithms to optimize resource allocation, ensuring seamless integration in knowledge-intensive workflows.
Document Curation and Preprocessing
Effective document curation and preprocessing are pivotal in optimizing Cache-Augmented Generation (CAG) within hybrid RAG systems.
The process involves selecting, structuring, and encoding datasets to maximize relevance and minimize redundancy, ensuring seamless integration into the model’s key-value (KV) cache.
Chunk optimization further enhances efficiency by segmenting documents into smaller, contextually relevant units. Additionally, dynamic query analysis enables adaptive updates to preloaded caches, bridging static and dynamic data needs.
Emerging trends suggest that machine learning-driven curation will revolutionize preprocessing workflows. Algorithms that predict query patterns can automate document selection, ensuring scalability across diverse applications.
Future strategies should explore contextual compression models to optimize token allocation, ensuring sustained performance as context windows expand.
Cache Management and Reset Mechanisms
Efficient cache management and reset mechanisms are critical for maintaining the performance and adaptability of Cache-Augmented Generation (CAG) systems. A well-designed strategy ensures that preloaded knowledge remains relevant while minimizing computational overhead.
One innovative approach is priority-based cache eviction. In this approach, less frequently accessed data is replaced by high-priority updates. This method ensures that critical information remains accessible without overloading the system.
Segmented cache structures further enhance flexibility by isolating domain-specific knowledge. Bloomberg’s financial analytics platform, for instance, segments caches into regulatory, market, and historical data layers.
This modular design allows targeted resets, improving response accuracy during volatile market conditions.
Emerging trends highlight the potential of predictive cache resets driven by machine learning.
Systems can preemptively refresh caches by analysing query patterns, aligning with user needs. Additionally, hierarchical caching models prioritize core datasets while offloading less critical information to secondary layers, optimizing memory usage.
Future strategies should explore automated reset frameworks to balance stability and adaptability, ensuring long-term scalability in knowledge-intensive applications.
Adapting Inference Processes
Adapting inference processes in Cache-Augmented Generation (CAG) systems requires a nuanced balance between efficiency and contextual accuracy.
A critical innovation is dynamic query routing, where inference pathways are optimized based on query complexity.
Inference layering is another transformative approach. This method ensures that responses remain coherent while adapting to the depth of user queries.
Emerging trends emphasize contextual token prioritization, where high-relevance data is dynamically weighted during inference.
Future strategies should explore adaptive inference frameworks that integrate real-time feedback loops, enabling systems to refine their processes continuously.
This evolution will ensure that CAG systems remain robust and responsive in increasingly complex environments.
Advanced Applications and Optimization
Cache-Augmented Generation (CAG) is unlocking advanced applications by optimizing knowledge workflows in ways previously unattainable with Retrieval-Augmented Generation (RAG).
An unexpected connection emerges in personalized education platforms like Coursera, which preload course materials and adaptive learning paths into CAG systems.
A common misconception is that CAG is unsuitable for dynamic datasets. However, hybrid models integrating dynamic cache updates have bridged this gap, as seen in IBM’s compliance systems, which refresh regulatory caches weekly to maintain accuracy.
Future advancements should explore predictive cache layering, where machine learning anticipates data needs, ensuring scalability across diverse, high-stakes domains.
Optimizing CAG for Various Tasks
Optimizing Cache-Augmented Generation (CAG) for diverse tasks requires a tailored approach that aligns preloaded knowledge with task-specific demands.
A critical factor is domain-specific cache structuring, where datasets are segmented and prioritized based on relevance.
For instance, IBM’s Granite LLMs employ modular cache layers for compliance checks, isolating regulatory, financial, and operational data.
A novel metric, Cache Utilization Efficiency (CUE), can evaluate the effectiveness of preloaded caches. CUE measures the ratio of relevant cache hits to total queries, offering actionable insights into cache optimization.
Emerging trends highlight the role of adaptive cache refresh cycles.
Unlike static updates, adaptive cycles leverage machine learning to predict when caches require updates, ensuring relevance without overloading resources.
To further optimize CAG, organizations should explore context-aware token allocation algorithms. These algorithms dynamically prioritize high-impact data within extended context windows, ensuring critical information remains accessible.
Integrating predictive analytics with cache management will redefine its scalability as CAG evolves, enabling seamless performance across increasingly complex workflows.
Hybrid Approaches with CAG and RAG
Hybrid approaches combining Cache-Augmented Generation (CAG) and Retrieval-Augmented Generation (RAG) offer a strategic balance between efficiency and adaptability, particularly in knowledge-intensive domains.
A key innovation is dynamic task partitioning, where static, high-priority datasets are preloaded via CAG, while RAG handles volatile or less predictable queries. This dual-layered system ensures both speed and relevance.
A compelling case study is the implementation by a leading healthcare platform, which preloaded medical guidelines and patient histories using CAG while employing RAG to retrieve real-time updates on drug recalls and emerging research.
To evaluate hybrid system performance, the Hybrid Efficiency Index (HEI) can be introduced. HEI measures the ratio of preloaded cache hits to retrieval events, weighted by query complexity.
Emerging trends suggest that context-aware hybrid frameworks will dominate future applications.
These frameworks dynamically adjust the balance between CAG and RAG based on query patterns, user intent, and domain-specific priorities.
For instance, retail platforms could preload product catalogs via CAG while using RAG to fetch inventory updates, enhancing customer experience and operational efficiency.
Future strategies should explore predictive hybrid models that leverage machine learning to optimize task allocation, ensuring scalability and precision in increasingly complex workflows.
Scaling CAG for Larger Knowledge Bases
Scaling Cache-Augmented Generation (CAG) for larger knowledge bases requires innovative strategies to overcome the inherent limitations of finite context windows and memory constraints.
A pivotal approach is hierarchical cache layering, where knowledge is segmented into prioritized tiers based on relevance and frequency of access.
This method ensures that critical data remains within the primary cache, while less essential information is offloaded to secondary layers.
Another transformative technique is context-aware compression algorithms, which optimize token allocation by dynamically summarizing low-priority data.
Anthropic’s Claude 2 demonstrated this by compressing extended product manuals into high-relevance segments. This enabled the model to handle datasets exceeding 100,000 tokens without sacrificing accuracy.
The Cache Scalability Index (CSI) can be introduced to measure scalability. CSI evaluates the efficiency of cache utilization relative to the size of the knowledge base, factoring in query complexity and response latency.
Emerging trends highlight the potential of distributed caching architectures, where multiple models share segmented caches across a network.
This reduces memory bottlenecks and enhances scalability for enterprise-level applications.
Future strategies should explore predictive cache distribution models that leverage machine learning to anticipate data needs, ensuring seamless performance across increasingly expansive knowledge domains.
FAQ
What is Cache Augmented Generation (CAG), and how does it differ from Retrieval Augmented Generation (RAG)?
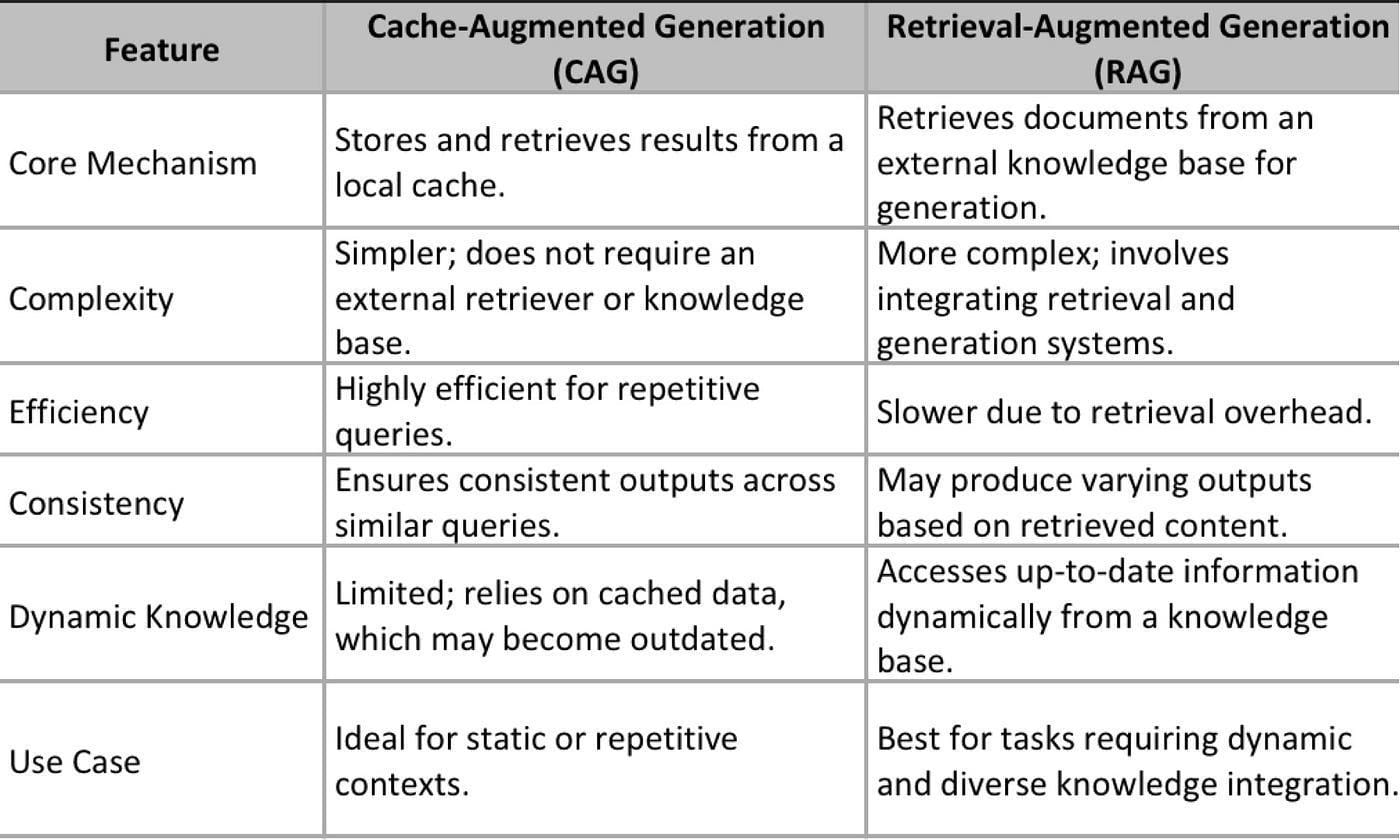
Cache-augmented generation (CAG) preloads knowledge into a model’s extended context, reducing reliance on external retrieval and eliminating latency and retrieval errors. In contrast, Retrieval-Augmented Generation (RAG) fetches data in real time, making it more adaptable to frequently changing knowledge bases.
How does Cache Augmented Generation improve efficiency in AI workflows?
CAG speeds up inference by storing precomputed knowledge in key-value caches, reducing token usage and retrieval delays. This approach ensures faster, more reliable responses in applications like finance, healthcare, and legal research where real-time accuracy is critical.
What are the key steps to implement Cache Augmented Generation in a hybrid RAG system?
CAG implementation starts with curating and preloading stable datasets. Documents are segmented for token efficiency, and cache updates are scheduled to keep data relevant. A hybrid system can balance CAG’s efficiency with RAG’s adaptability, improving both speed and accuracy.
Which industries benefit the most from Cache Augmented Generation?
Industries with static but high-value knowledge bases benefit the most. Healthcare uses CAG for fast access to medical guidelines. Finance applies it for historical market analysis. Education platforms preload learning materials, and customer support systems use it for instant responses.
What are the best practices for optimizing preloaded caches in Cache Augmented Generation?
Preloading should prioritize high-impact data, structuring caches for fast access. Cache segmentation improves efficiency, while adaptive refresh cycles keep stored information relevant. Using machine learning to optimize retrieval patterns ensures long-term scalability and accuracy.
Conclusion
Cache Augmented Generation offers a new approach to knowledge retrieval by reducing reliance on real-time search.
It improves efficiency, speeds up inference, and ensures consistent accuracy, especially for industries handling large, stable datasets.
While Retrieval Augmented Generation remains useful for dynamic content, CAG provides a scalable, reliable alternative for tasks requiring structured, preloaded information.
Future advancements will focus on refining cache optimization techniques and integrating hybrid models that balance efficiency with adaptability.