
The Most Common Reasons Why Your RAG System Is Underperforming
Is your RAG system underperforming? This guide explores the most common reasons, including retrieval inefficiencies, poor indexing, and context gaps. Learn how to troubleshoot and optimize your RAG system for better accuracy and performance.


RAG systems promise precise, context-aware responses by combining retrieval with text generation. But in practice, many fail to deliver accurate results.
The issue isn’t always the model—it’s often how the system retrieves and processes data.
Consider an e-commerce platform integrating RAG for customer support. Despite strong infrastructure, the system returned outdated policy details and irrelevant answers.
The problem? An outdated index and retrieval logic that emphasized speed over accuracy.
This is a common issue across industries. Healthcare RAG systems pull from outdated research, financial tools miss key regulatory changes, and enterprise search tools retrieve irrelevant documents.
These failures aren’t due to weak models but foundational gaps in retrieval strategies, indexing, and data structure.
Understanding these weaknesses is the first step in fixing them. Optimizing retrieval, improving query processing, and refining data indexing can turn an underperforming system into a reliable AI-powered tool. This article explores why RAG systems struggle and how to resolve these issues.
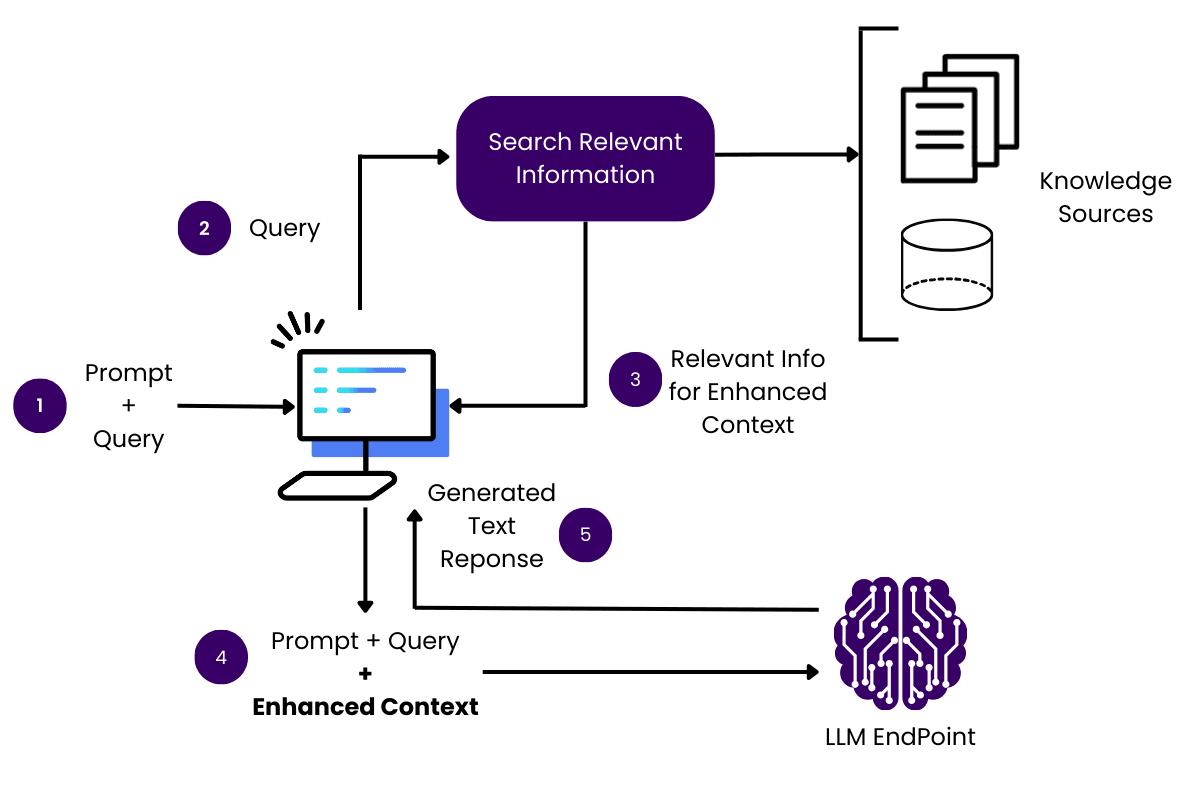
Understanding Retrieval-Augmented Generation
One critical yet often overlooked aspect of RAG systems is the trade-off between retrieval depth and latency.
While deeper retrieval pipelines can surface highly relevant information, they frequently introduce delays that undermine real-time applications.
A promising solution lies in multi-stage retrieval frameworks. These systems employ lightweight filters to narrow datasets initially, followed by computationally intensive methods for refinement.
This approach mirrors Google’s search engine ranking, where broad results are refined based on user behavior. By adopting this layered strategy, companies like Shopify have reduced retrieval latency while maintaining accuracy.
Another nuance is the impact of embedding quality. Dense embeddings, such as those from Sentence-BERT, excel when fine-tuned on domain-specific data.
Data Quality Issues in RAG Systems
Data quality is the backbone of any RAG system, yet it’s often treated as an afterthought.
Think of it like fueling a high-performance car with low-grade gasoline—no matter how advanced the engine, it’s not going to run smoothly.
One major issue? Noisy or incomplete data.
For example, a healthcare RAG system might pull outdated medical guidelines, leading to inaccurate diagnoses.
The fix? Rigorous data cleaning and preprocessing, including removing duplicates and normalizing text, ensures the system retrieves only relevant, high-quality information.
Another overlooked culprit is unstructured data. Imagine a financial report with critical insights buried in a chart.
If your RAG system can’t interpret visual elements, it’s missing the bigger picture. Companies like JPMorgan Chase have tackled this by integrating multi-modal data to boost fraud detection accuracy.
Finally, stale indexes are a silent killer. Outdated knowledge bases lead to irrelevant responses. Regular updates and automated checks can keep your system sharp, ensuring it delivers accurate, timely results every time.
Impact of Incomplete and Outdated Knowledge Bases
A RAG system without complete and updated data is like a search engine stuck in the past. It returns what it knows, but what it knows may no longer be relevant.
Information gaps create retrieval blind spots, missing data leads to incomplete answers, and outdated sources introduce errors that go unnoticed until they cause real damage.
Without frequent updates, it serves responses based on yesterday’s facts. In fields like law or healthcare, that’s a risk no one can afford.
Indexing isn’t a one-time task. It must be continuous. Systems that fail to expand their datasets eventually become unreliable, no matter how advanced their retrieval models are.
The solution is dynamic knowledge management. Systems must detect gaps, update information in real time, and refine retrieval strategies. Without that, even the best RAG models lose their edge.
Challenges with Chunking and Embedding Techniques
When it comes to chunking and embedding in RAG systems, semantic chunking stands out as a game-changer but also a double-edged sword.
While it ensures that chunks are contextually meaningful, it demands significant computational resources and precise implementation.
A critical factor is chunk size optimization.
Smaller chunks (250-500 tokens) improve retrieval precision but can overwhelm systems with excessive API calls.
Conversely, larger chunks (1,500-2,000 tokens) retain broader context but risk introducing noise.
Embedding quality further complicates the equation. Dense embeddings like Sentence-BERT excel in domain-specific tasks but require fine-tuning.
Looking ahead, hybrid chunking models that combine semantic and heuristic methods could balance precision and efficiency.
Organizations should also explore embedding compression techniques to reduce latency without sacrificing accuracy, ensuring scalable and responsive RAG systems in dynamic environments.
Retrieval Inefficiencies
Let’s face it—if your RAG system isn’t retrieving the right data, everything else falls apart. Here’s where things usually go wrong:
1. Over-Reliance on Basic Retrieval Models
Using outdated methods like TF-IDF or BM25 is like trying to find a needle in a haystack with a flashlight instead of a magnet.
These models often miss the semantic meaning behind queries, leading to irrelevant results.
For example, a financial analyst searching for “market volatility trends” might get generic articles on “market trends” instead. Switching to dense retrieval models like DPR or ColBERT can bridge this gap by understanding context, not just keywords.
2. Ignoring Domain-Specific Fine-Tuning
A one-size-fits-all retriever doesn’t cut it. Without fine-tuning on domain-specific data, your system is like a tourist trying to navigate Tokyo with a Paris map.
LexisNexis, for instance, improved legal case retrieval after training their retriever on legal jargon and structured datasets.
3. Latency vs. Depth Trade-Offs
Speed is great, but not at the cost of accuracy. Systems prioritizing speed often skip deeper, more relevant data. Multi-stage retrieval frameworks, like Shopify’s, balance this by filtering broadly first, then refining results, cutting latency without sacrificing precision.
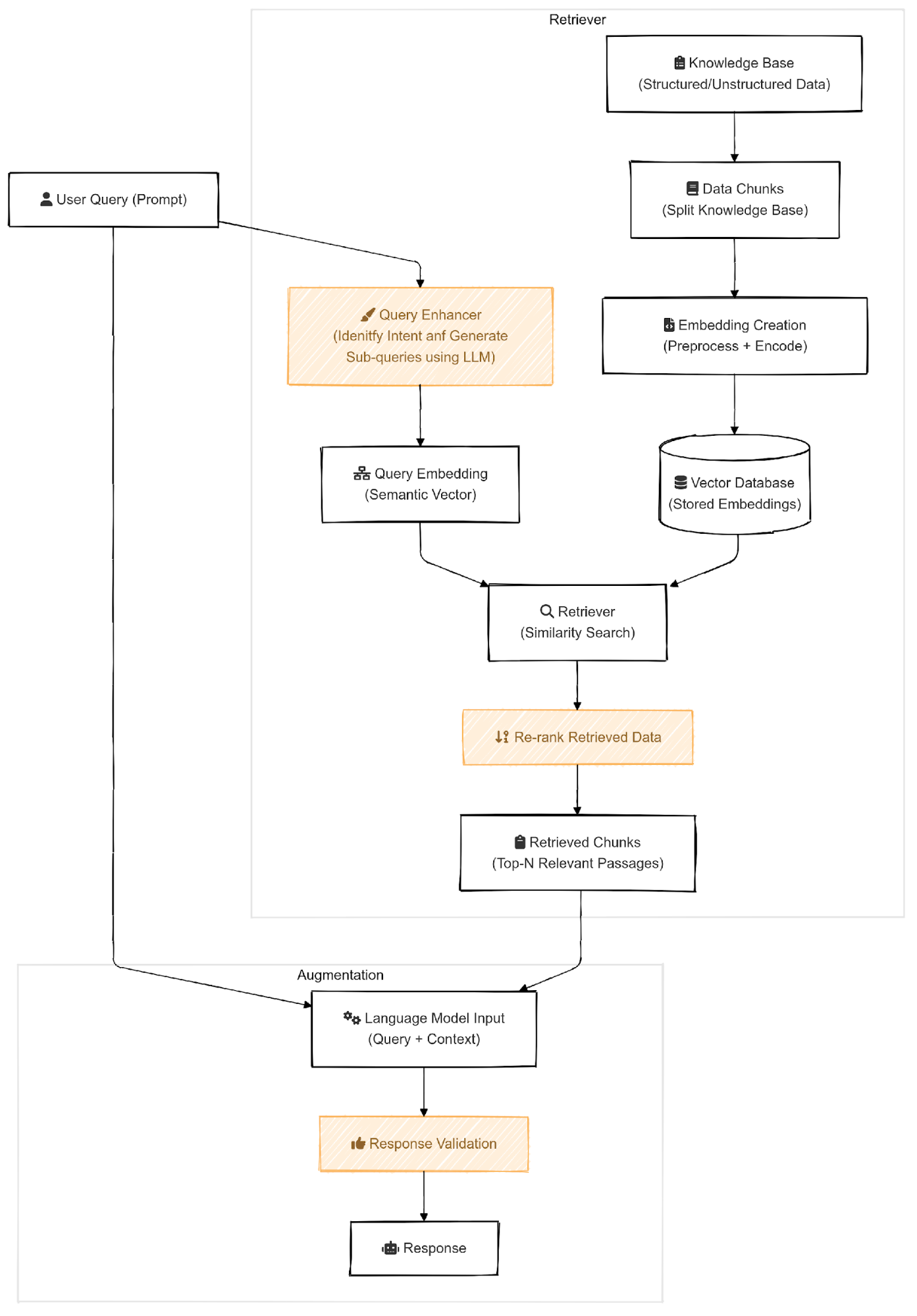
Semantic Mismatch and Keyword Over-Reliance
Relying too heavily on keywords is like trying to understand a novel by skimming for bolded words—it misses the bigger picture.
Traditional keyword-based retrieval methods, such as BM25, often fail to capture the intent behind queries, leading to irrelevant or incomplete results.
For instance, a search for “remote work benefits” might overlook documents discussing “telecommuting advantages,” even though they’re semantically identical.
Companies like JPMorgan Chase have tackled this issue by integrating semantic search models into their fraud detection pipelines.
By leveraging dense embeddings from Sentence-BERT, they improved retrieval precision, ensuring that subtle variations in phrasing didn’t derail critical insights. This shift highlights the importance of understanding context rather than just matching words.
A lesser-known factor? Cultural and linguistic nuances. In multilingual applications, keyword reliance often fails to account for idiomatic expressions or regional variations. Alibaba addressed this by fine-tuning their retrieval models on localized datasets, boosting e-commerce search relevance.
To move forward, organizations should adopt hybrid retrieval frameworks that combine keyword indexing for speed with semantic models for depth.
Additionally, iterative testing with user feedback can refine these systems dynamically. The future lies in retrieval pipelines that don’t just find words but truly understand meaning—unlocking relevance at scale.
Handling Complex Queries Effectively
When tackling complex queries, adaptive retrieval strategies emerge as a game-changer. Unlike static pipelines, these systems dynamically adjust based on query complexity, ensuring nuanced responses without unnecessary computational overhead.
For instance, JPMorgan Chase employs a multi-step retrieval process in fraud detection, integrating financial reports, transaction histories, and visual data. This approach improved fraud detection accuracy, demonstrating the power of layered retrieval.
A critical factor here is query classification. By categorizing queries into straightforward, simple, or complex, systems like those at Alibaba optimize retrieval depth.
Straightforward queries bypass external retrieval, while complex ones engage iterative, multi-hop retrieval. This not only reduces latency but also ensures comprehensive answers.
Emerging trends highlight the role of knowledge graphs in handling intricate queries.
To advance, organizations should adopt hybrid retrieval frameworks combining dense embeddings with sparse methods.
Additionally, real-time user feedback loops can refine query handling dynamically. Looking forward, integrating cultural and linguistic nuances into query classification could unlock new efficiencies, particularly in multilingual applications. The future lies in systems that don’t just retrieve but truly reason.
Generation Shortcomings
Let’s face it—if the retrieval is the engine of your RAG system, generation is the driver. And sometimes, that driver takes a wrong turn.
1. Hallucinated Responses
Ever had your system confidently spit out something completely wrong? That’s hallucination. It happens when the generator fills in gaps with made-up information instead of admitting it doesn’t know.
For example, a healthcare RAG system might invent a treatment protocol if the retrieved data is incomplete. The fix? Tighten the integration between retrieval and generation to ensure the generator sticks to the facts.
2. Lack of Context Awareness
If your generator feels like it’s answering in a vacuum, it probably is. Without proper contextual alignment, responses can feel generic or irrelevant. Imagine asking for legal advice and getting a Wikipedia-level answer. Embedding optimization and fine-tuning on domain-specific data can help bridge this gap.
3. Overly Complex Outputs
Sometimes, less is more. Overloading users with jargon-filled, verbose responses can be just as bad as being wrong. Clear, concise prompts and iterative testing can keep your outputs user-friendly and actionable.
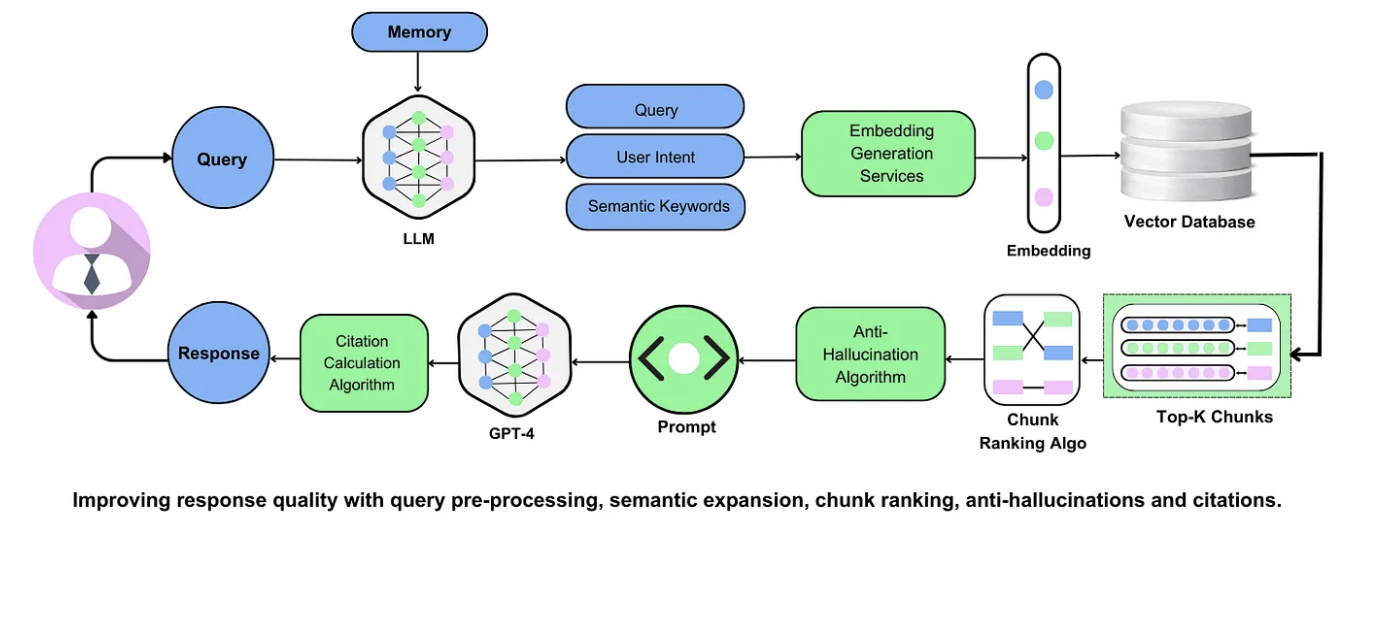
Advanced Optimization Techniques
Optimizing a RAG system isn’t about massive overhauls. It’s about refining what already exists. Small, deliberate changes can push performance from adequate to exceptional.
1. Dynamic Query Reformulation
Query reformulation is one of the most effective strategies. A rigid system treats every query the same way, but intelligent reformulation adapts based on intent. It rewrites vague or overly specific queries into something the system can process more effectively.
2. Embedding Compression
Embedding compression reduces resource consumption without sacrificing accuracy. Large embeddings capture rich details but slow everything down. By refining embeddings through techniques like pruning or distillation, a system can maintain precision while improving speed.
3. Iterative Feedback Loops
Feedback loops turn real-world interactions into optimization fuel. A RAG system that analyzes failed queries, incorrect responses, and user behavior can refine retrieval over time. Without this, performance remains static, and errors repeat.
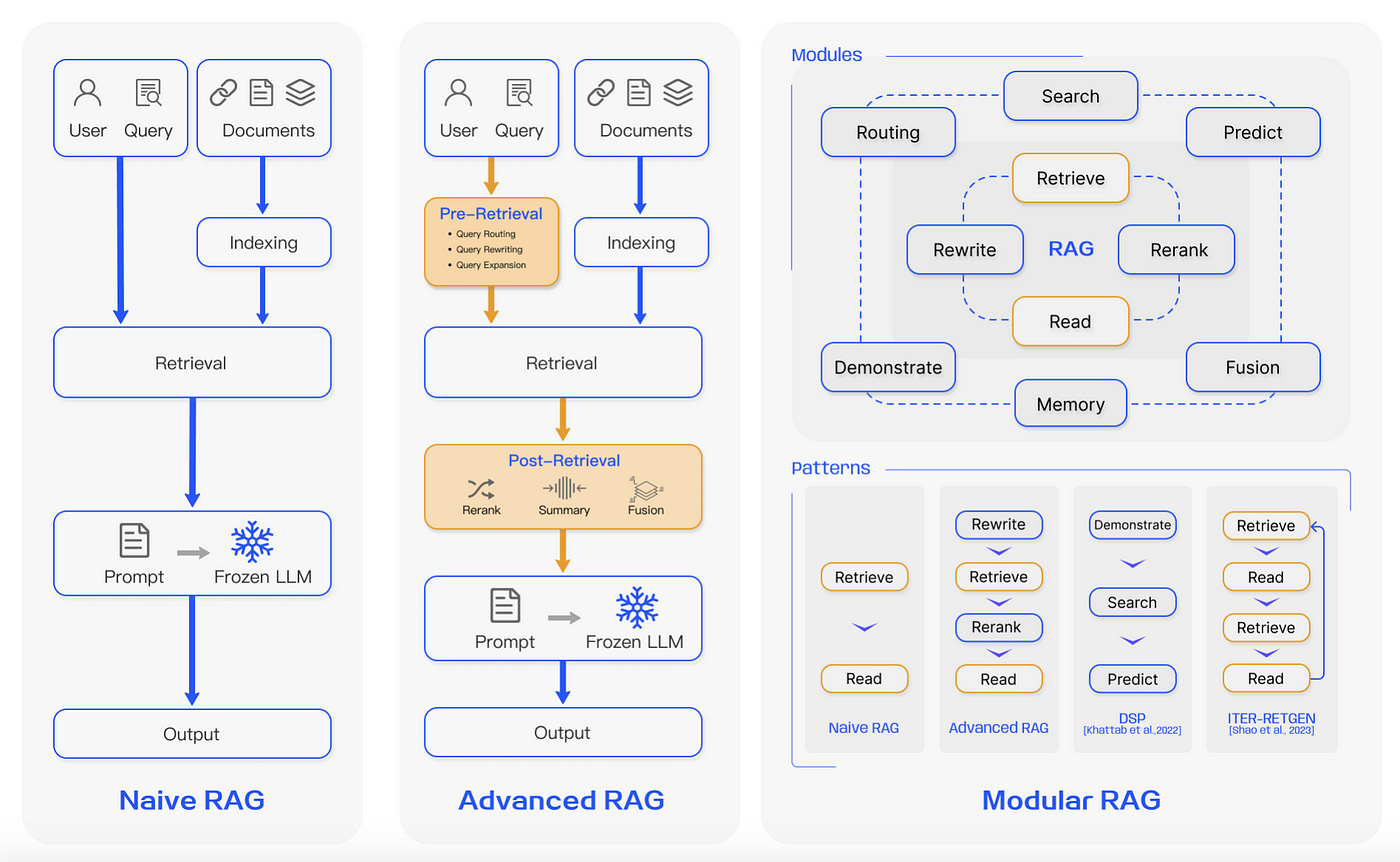
Re-Ranking and Multi-Hop Retrieval
A RAG system’s first attempt at retrieval isn’t always the best. Re-ranking allows it to refine results, pushing the most relevant information to the top.
Instead of presenting documents based on simple keyword matching, a well-designed system prioritizes content based on context, relevance, and query intent.
Multi-hop retrieval goes even further. Instead of relying on a single document, it connects information across multiple sources, filling in gaps that a single search might miss.
This is crucial for complex queries that require pulling from different contexts, like legal research or technical documentation.
When used together, re-ranking and multi-hop retrieval turn scattered information into a coherent response. The system not only finds relevant documents but also organizes them in a way that makes sense.
Without these techniques, retrieval is often shallow—good for basic queries but unreliable for deeper searches.
FAQ
What causes Retrieval-Augmented Generation (RAG) systems to underperform?
RAG systems often fail due to outdated knowledge bases, weak retrieval strategies, and poor data quality. Issues like incomplete indexing, reliance on basic retrieval models, and unoptimized embeddings reduce accuracy. Addressing these with adaptive retrieval, fine-tuned embeddings, and regular data updates improves performance.
How does data quality and indexing affect RAG system accuracy?
Low-quality or outdated data leads to incorrect retrieval, while poor indexing prevents relevant documents from surfacing. Systems using structured indexing and real-time updates improve accuracy. Regular audits, metadata filtering, and semantic search help maintain data integrity in dynamic environments.
Why is embedding optimization and domain-specific fine-tuning important in RAG systems?
Embedding optimization refines retrieval by improving contextual understanding. Domain-specific fine-tuning aligns responses with industry needs, ensuring accurate outputs. Systems trained on specialized datasets, like legal or medical texts, retrieve more precise information and reduce irrelevant responses.
Why is retrieval depth and latency balance critical in RAG systems?
Deep retrieval finds relevant data but increases latency. Shallow retrieval speeds up responses but reduces accuracy. Multi-stage retrieval solves this by filtering broadly before refining results. This approach ensures that real-time applications remain fast while maintaining precision in complex queries.
How can organizations improve retrieval in RAG systems and reduce semantic mismatches?
Combining dense and sparse retrieval models improves accuracy. Using semantic search alongside keyword-based indexing enhances relevance. Fine-tuned embeddings aligned with industry-specific data improve precision. User feedback loops refine retrieval over time, ensuring continuous improvement in system performance.
Conclusion
Underperforming RAG systems often struggle due to outdated data, weak retrieval pipelines, and unoptimized embeddings.
Addressing these issues with structured indexing, multi-stage retrieval, and fine-tuned models improves accuracy.
Future advancements in adaptive learning and query refinement will further enhance RAG systems, making them more efficient across industries like healthcare, legal research, and enterprise search.