
Beyond RAG: The Future of Context-Aware AI Retrieval Systems
Dive into the future of AI retrieval beyond RAG. This guide explores next-gen context-aware systems, emerging architectures, and innovations that enhance AI's ability to understand and retrieve information with greater accuracy and relevance.


In a world flooded with information, AI’s true challenge isn’t retrieving data—it’s understanding it. Retrieval-augmented generation (RAG) models have helped bridge this gap, but they treat context as a static element.
As enterprises increasingly demand more personalised and intuitive interactions, the future of AI retrieval systems lies beyond RAG.
In this article, we’ll see how context-aware AI retrieval systems evolve with each interaction, representing the next frontier.
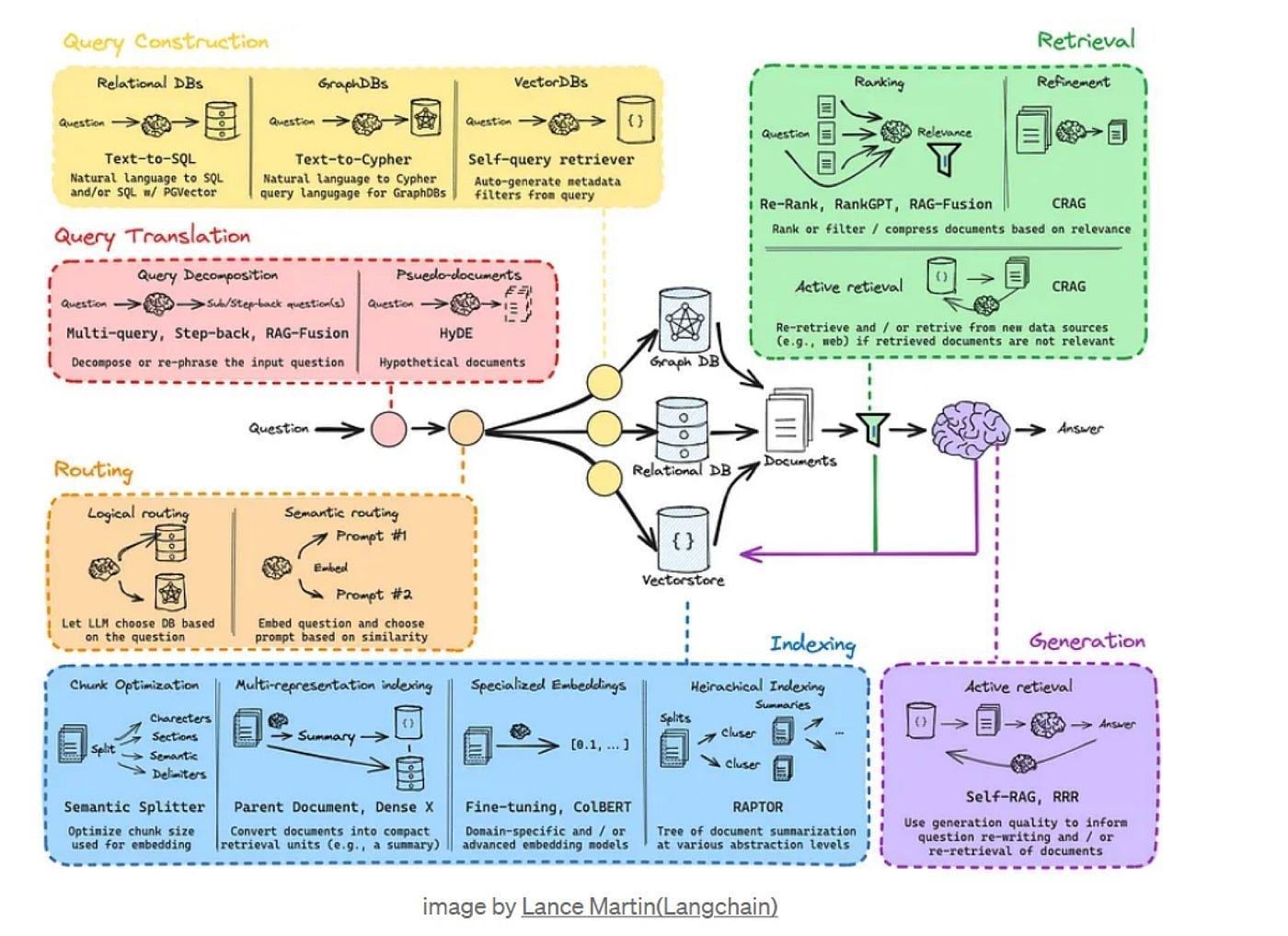
The Limitations of RAG in Context Understanding
First, let’s discuss some limitations of traditional RAG systems.
While these models can improve data accessibility by integrating retrieval mechanisms with generative models, they struggle when the context is ambiguous or complex. These systems primarily rely on embeddings and keyword matches, which can miss the subtle intent behind queries.
For instance, when a legal professional searches for a specific precedent, traditional RAG models may retrieve related cases based on surface-level terms rather than the intricate legal context.
This limitation underscores the need for AI retrieval systems that interpret context dynamically, adapting to variations in language, intent, and user history.
Context-Aware AI Retrieval: A Dynamic Approach
The core distinction between RAG and context-aware AI retrieval systems lies in their context treatment. Unlike static models, context-aware retrieval systems use adaptive algorithms that continuously learn from user interactions.
Through techniques like contextual embeddings, these systems can discern differences in meaning based on the surrounding text.
For instance, the word “appeal” in a legal document differs significantly from its use in marketing content. By dynamically adjusting to these contextual differences, AI retrieval systems provide more accurate, relevant results.
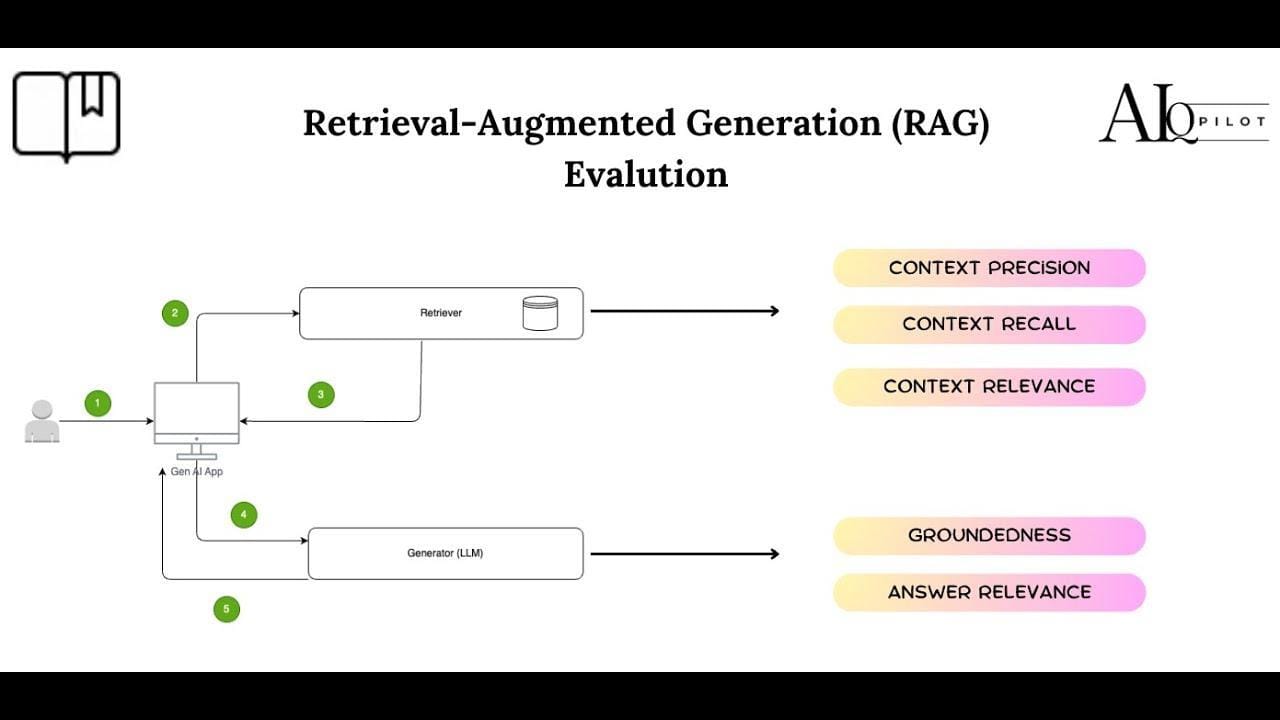
Practical Applications of Context-Aware AI Retrieval Systems
Context-aware AI retrieval systems are transforming how industries access and utilize information.
Unlike traditional models that rely on static keyword matches, these advanced systems dynamically adjust to user intent and context.
These systems deliver precise, personalized, and contextually relevant insights across various domains by integrating adaptive algorithms, contextual embeddings, and hybrid retrieval techniques.
Let’s explore some key applications where context-aware AI retrieval drives significant impact.
Intelligent Research Assistance
Researchers across fields like academia, pharmaceuticals, and market analysis often spend significant time sifting through vast data.
Context-aware AI retrieval systems streamline this process by understanding complex queries' nuances and delivering results beyond simple keyword matches.
For instance, a pharmaceutical researcher investigating “novel antiviral treatments” will receive papers relevant to recent drug developments rather than generic results about historical antiviral therapies.
These systems adapt to evolving research patterns, making literature reviews faster and more comprehensive.
AI-Powered Financial Insights
In finance, data-driven decisions are critical for risk assessment, fraud detection, and investment strategies.
Context-aware retrieval systems analyze transaction records, market reports, and regulatory documents to provide timely, relevant insights.
For example, when a financial analyst queries “emerging trends in renewable energy investments,” the system retrieves historical data, recent reports, and news articles.
Over time, the model learns which sources the analyst trusts most, further refining results. This dynamic adaptation supports better-informed, real-time decision-making.
Medical Information Retrieval
In healthcare, context-aware retrieval systems assist doctors by retrieving contextually relevant patient records.
When a doctor queries “diabetes complications,” the system prioritizes information about the patient’s history and current medications rather than general knowledge.
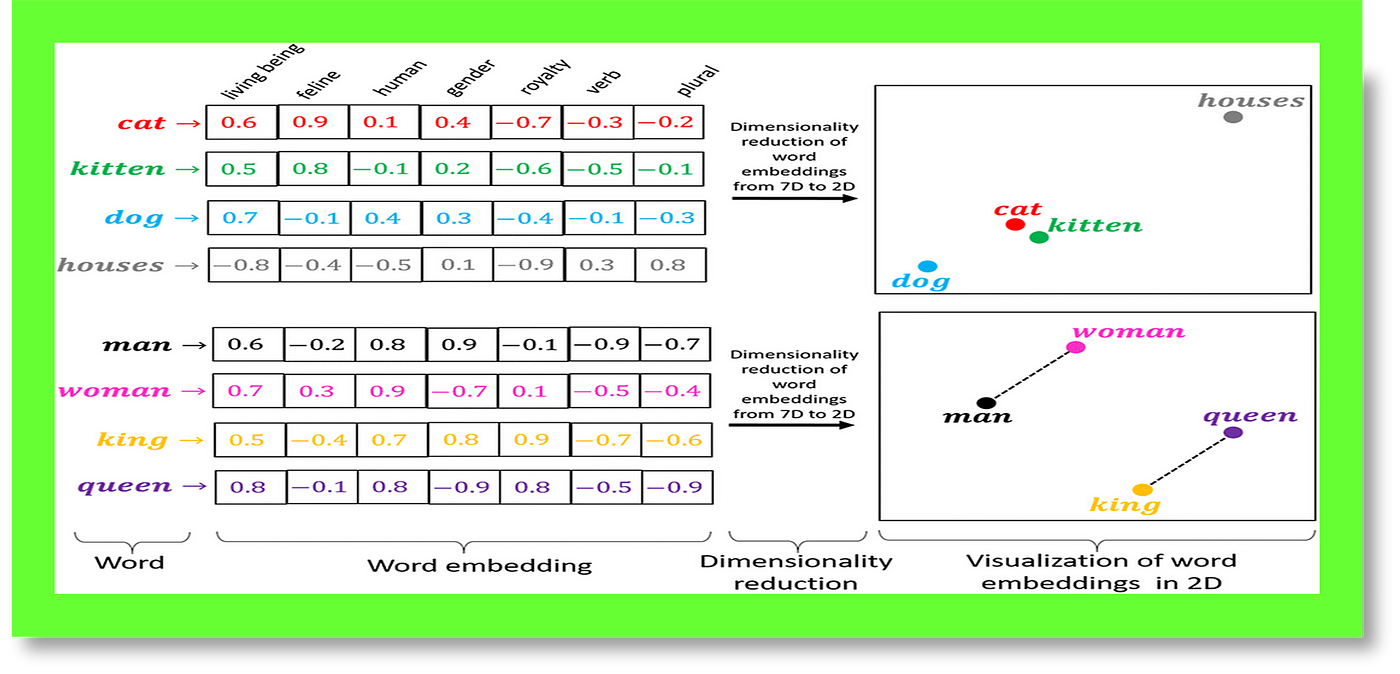
Optimization and Fine-Tuning Strategies
Optimizing context-aware AI retrieval systems requires continuous refinement to ensure accurate and efficient performance.
One critical strategy is domain-specific embedding fine-tuning, where pre-trained models are adapted to specialized datasets.
For instance, if trained on general datasets, a legal document retrieval system might struggle with terms like appeal or motion. Fine-tuning embeddings with domain-specific corpora—like case law or medical records—improves precision by aligning the model’s understanding with industry-specific language.
Another key approach is the implementation of adaptive learning pipelines.
These pipelines use real-time feedback to adjust model weights based on user interactions. For example, if users consistently favor specific results, the system learns to prioritize similar responses in future queries. This adaptive behavior ensures the model remains relevant as data patterns evolve.
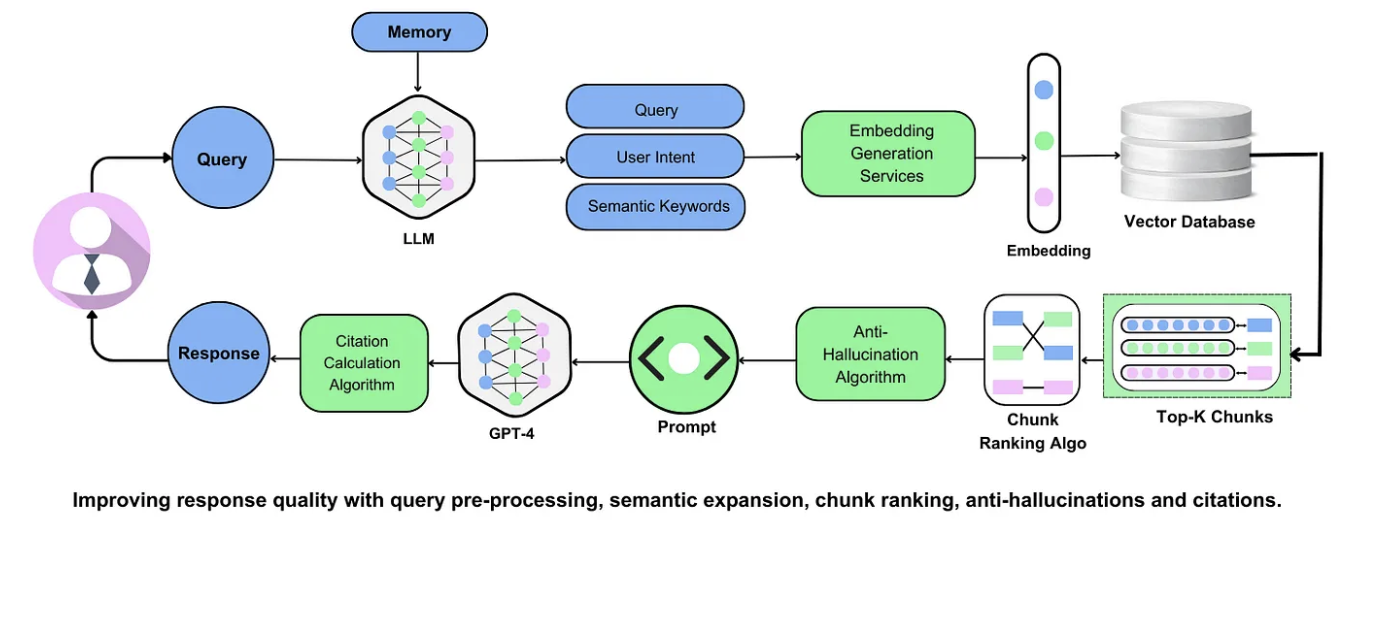
Hyperparameter Tuning for Contextual Retrieval
Hyperparameter tuning is crucial in maximizing the accuracy and efficiency of context-aware AI retrieval systems. It requires a careful balance between capturing meaningful context and minimizing computational overhead.
One critical parameter is the context window size.
While larger windows allow models to grasp complex semantic relationships, they can introduce irrelevant noise if incorrectly calibrated. Finding the optimal window size ensures the system retains essential contextual information without sacrificing performance.
Another impactful approach is query re-ranking threshold tuning. By adjusting the number of top-k results passed to the reranking models, systems can significantly improve the relevance of retrieved information while reducing response time.
For instance, dynamic thresholds based on query complexity can help prioritize precision in critical applications like healthcare or finance.
Looking ahead, hyperparameter tuning will become more autonomous, driven by AI models capable of self-optimization.
Future advancements will likely introduce fully adaptive retrieval pipelines that can dynamically reconfigure across diverse tasks. This will ultimately lead to retrieval systems that respond to queries and adapt to user needs with unprecedented accuracy.

Future of Enterprise Search and Customer Support
Enterprise search and customer support systems increasingly leverage context-aware retrieval to address the dual challenges of query ambiguity and response latency.
A key innovation is dynamic reranking algorithms, which prioritise results based on real-time user intent. Another lesser-known factor influencing outcomes is contextual drift during multi-turn conversations. Systems like Anthropic’s Contextual Retrieval mitigate this by dynamically updating embeddings with interaction history, ensuring continuity and relevance.
For example, a query about “subscription cancellation” evolves seamlessly into related topics like “refund policies” without requiring explicit user input.
Actionable frameworks include hybrid retrieval pipelines combining BM25 for exact matches and contextual embeddings for semantic depth.
A practical implementation might involve:
Example:
Hybrid Retrieval Pipelineresults = bm25.retrieve(query) + embeddings.retrieve(query)ranked_results = reranker.rank(results)
Future advancements should explore multimodal retrieval, integrating text, voice, and visual data to enable richer interactions. This evolution promises enhanced user satisfaction and operational efficiency, particularly in high-volume enterprise environments.
Challenges and Considerations for the Future
The development of advanced context-aware retrieval systems presents its own challenges. It is crucial to ensure that these systems maintain accuracy while minimizing computational overhead.
Additionally, ethical considerations such as data privacy and algorithmic bias must be addressed to maintain trust and compliance with global standards like GDPR and HIPAA.
FAQs
What are the key limitations of traditional RAG systems, and how do context-aware systems address them?
Traditional RAG systems handle context statically, leading to irrelevant results. Context-aware systems use dynamic context integration and advanced embeddings to improve relevance and adaptability.
How do dynamic context management and adaptive retrieval algorithms enhance AI retrieval systems?
They update context layers in real time and adjust retrieval strategies based on query complexity, improving accuracy and user experience without system interruptions.
What role do contextual embeddings play in improving semantic understanding in AI retrieval?
Contextual embeddings adapt word meanings based on surrounding text, improving query disambiguation and enhancing semantic understanding across applications.
How can hybrid retrieval models balance lexical precision and semantic depth effectively?
By combining BM25 for exact matches with contextual embeddings for semantic depth, hybrid models optimize relevance for both technical and open-ended queries.
What are the ethical considerations and challenges in implementing context-aware AI retrieval systems?
Key concerns include data privacy, bias mitigation, and algorithmic transparency, requiring robust frameworks for fairness and accountability.
Conclusion
The evolution beyond RAG toward context-aware AI retrieval systems represents a paradigm shift in how machines understand and respond to information.
Static context retrieval methods are replaced by dynamic, adaptive systems that anticipate intent, adapt to nuanced queries, and provide accurate, relevant results across domains.
Innovations like contextual embeddings, hybrid retrieval models, and dynamic reranking lead this transformation.
As these technologies mature, their applications will extend beyond enterprise search to power more intuitive and responsive AI systems in healthcare, legal research, customer support, and beyond.
The future lies in building retrieval systems that don’t just find information but truly understand it—turning data into actionable, context-rich insights that redefine how we interact with knowledge in an increasingly complex digital world.