
Corrective RAG (cRAG): An Advanced Technique to Refine LLM Outputs
Corrective RAG (cRAG) is an advanced method for refining LLM outputs. This guide explains how cRAG reduces hallucinations, boosts factual accuracy, and enhances reliability in retrieval-augmented generation systems for real-world applications.


Most language models sound confident—but they often get facts wrong.
Even with retrieval-augmented generation (RAG), large language models still struggle to separate useful information from noise.
That’s where Corrective RAG comes in.
Corrective RAG (cRAG) doesn’t just pull documents based on similarity. It questions them. It scores their relevance. It filters out the weak ones. If something looks off, cRAG takes a second pass—breaking down the content, running a new search, or reconstructing the response from more reliable fragments.
The goal isn’t just output. It’s accuracy.
This guide explains how cRAG works, what distinguishes it from standard RAG, and why it’s becoming essential in domains like finance, healthcare, and compliance—where being close enough just isn’t good enough.
The Evolution from RAG to cRAG
The transition from RAG to cRAG hinges on a fundamental shift: prioritizing the quality of retrieved data over sheer volume.
At its core, cRAG introduces a dynamic evaluation mechanism that actively filters and refines information, ensuring only the most relevant data informs the final output.
This refinement process is anchored in “knowledge strips,” where documents are decomposed into smaller, context-specific units.
These strips undergo rigorous evaluation for relevance and accuracy, a step that traditional RAG systems often overlook.
By isolating granular insights, cRAG minimizes ambiguity and enhances the precision of generated responses.
One notable implementation of cRAG is its integration of adaptive web searches. Unlike static retrieval, this approach dynamically supplements insufficient data by reformulating queries and sourcing up-to-date information.
However, this sophistication comes with challenges, such as increased computational costs and reliance on evaluator quality.
Addressing these nuances is critical for scaling cRAG across diverse applications.
Key Components of cRAG
One of cRAG's most transformative elements is its retrieval evaluator, a lightweight yet powerful mechanism for determining the relevance and reliability of retrieved documents.
This component doesn’t just assess; it actively shapes the quality of downstream outputs by filtering out noise and prioritizing precision.
The evaluator operates on a confidence scoring system, assigning numerical values to each document based on its alignment with the query.
Documents falling below a predefined threshold are flagged for corrective actions, such as reformulating queries or initiating web searches. This ensures that only the most contextually relevant data informs the generation process.
In practice, this modular design enables seamless integration across industries, from legal research to real-time analytics, where precision is paramount.
However, its reliance on evaluator quality underscores the need for continuous fine-tuning to maintain effectiveness.
Core Mechanisms of cRAG
At the heart of cRAG lies a dual-engine approach ensuring precision and adaptability in retrieving data.
The first mechanism, Document Evaluation and Scoring, acts as a gatekeeper, systematically filtering out irrelevant or unreliable information.
This process uses advanced confidence scoring systems, such as those powered by T5-large models, to assign numerical values to each document, quantifying its alignment with the query.
Documents scoring below a critical threshold are flagged, preventing low-quality data from contaminating the output. This step is akin to a sieve, ensuring only the most relevant grains of knowledge pass through.
The second mechanism, Corrective Actions and Knowledge Refinement, transforms flagged data into actionable insights.
Using techniques like the “decompose-then-recompose” strategy, documents are broken into smaller, context-specific units.
These units undergo rigorous re-evaluation, allowing the system to isolate valuable insights while discarding noise. This iterative refinement mirrors the meticulous manuscript editing process, where every detail is scrutinized for clarity and coherence.
Together, these mechanisms form a feedback loop that enhances accuracy and adapts dynamically to evolving queries, making cRAG a cornerstone for high-stakes applications.
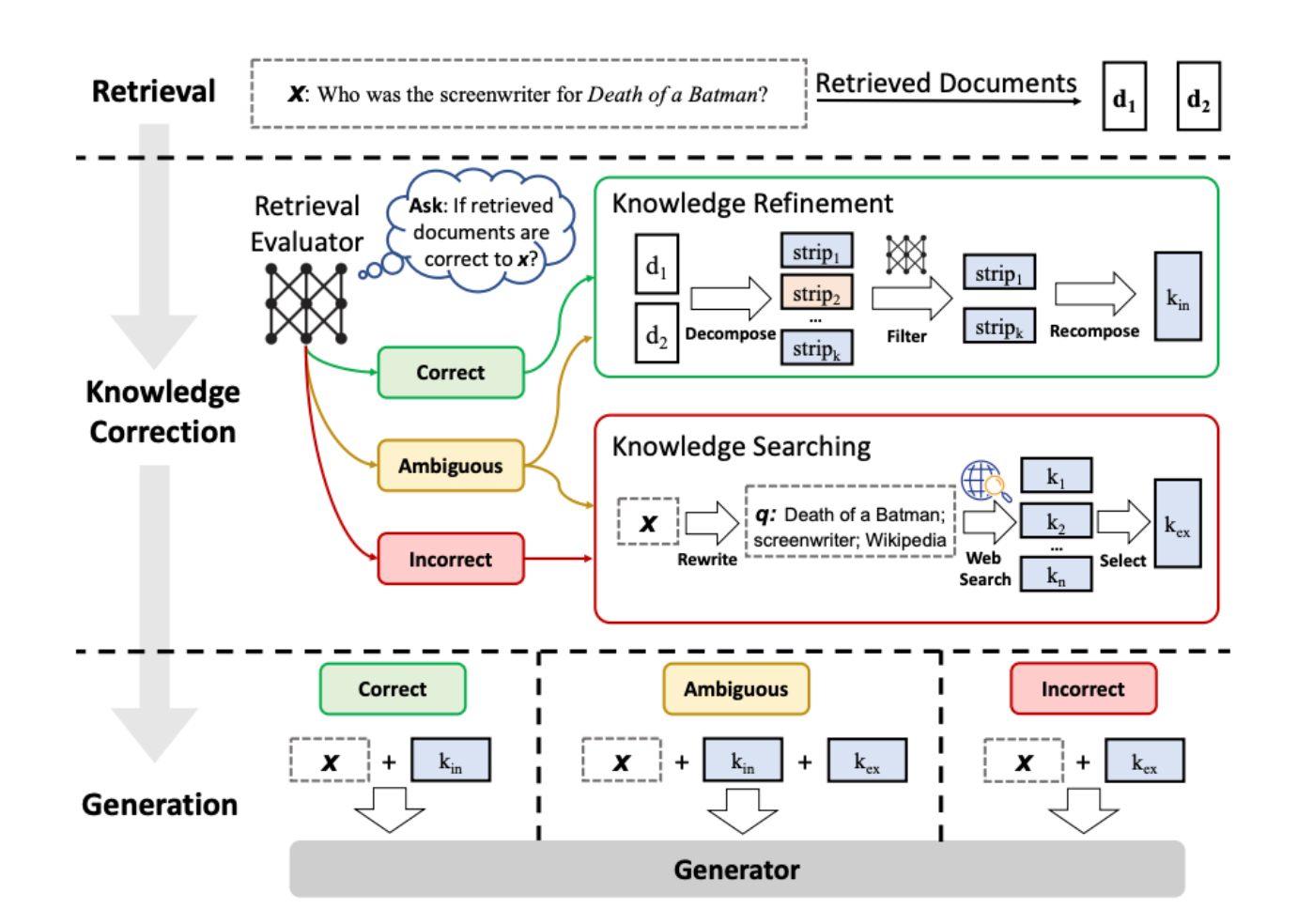
Document Evaluation and Scoring
The cornerstone of cRAG’s effectiveness is its confidence scoring system, which precisely evaluates each document’s relevance.
This process isn’t just about filtering data; it’s about creating a dynamic information hierarchy where only the most contextually aligned insights are prioritized.
By assigning numerical scores to documents, the system systematically excludes irrelevant or ambiguous data, safeguarding the integrity of the output.
What sets this apart is the granular approach of segmenting documents into “knowledge strips.”
Each strip undergoes individual evaluation, allowing the system to isolate critical insights while discarding redundant or misleading fragments. This method not only enhances accuracy but also prevents the compounding of errors—a common pitfall in traditional RAG systems.
However, the process is not without challenges.
Relying on finely tuned models like T5-large introduces a dependency on high-quality datasets and computational resources. Additionally, the scoring thresholds must be meticulously calibrated to balance precision and recall, as overly stringent criteria could exclude valuable data.
In practice, this mechanism has proven transformative in fields like legal research, where nuanced distinctions in document relevance can significantly impact outcomes.
By refining the evaluation process, cRAG enhances reliability and sets a new standard for adaptive knowledge retrieval.
Corrective Actions and Knowledge Refinement
The “decompose-then-recompose” strategy in cRAG is a masterstroke of precision engineering, designed to isolate and amplify the most relevant insights from retrieved documents.
This approach ensures that even subtle nuances are preserved while irrelevant or redundant information is systematically discarded.
What makes this technique indispensable is its adaptability.
For instance, in legal research, where precision is paramount, the system can recalibrate its thresholds to prioritize statutory language over interpretative commentary. Conversely, in customer support, the focus might shift toward conversational clarity, emphasizing actionable insights over exhaustive detail.
This dynamic calibration underscores the system’s versatility across domains.
However, the process is not without its challenges. One critical limitation lies in the evaluator’s dependency on high-quality datasets.
Inconsistent or biased training data can skew the refinement process, leading to suboptimal outputs.
Additionally, the computational overhead of iterative refinement can be prohibitive in real-time applications, necessitating strategic trade-offs between accuracy and efficiency.
By integrating this nuanced approach, cRAG enhances the reliability of outputs and sets a benchmark for adaptive knowledge refinement in high-stakes environments.
Integration with Large Language Models
Integrating cRAG with large language models (LLMs) demands more than technical alignment—it’s a deliberate orchestration of precision and adaptability.
At its core, cRAG acts as a dynamic filter, ensuring that LLMs process only the most contextually relevant and accurate data.
This integration transforms LLMs from passive generators into systems capable of nuanced, domain-specific reasoning.
One critical innovation is the seamless adaptability of cRAG’s retrieval evaluator.
By assigning confidence scores to retrieved documents, it ensures that LLMs are not overwhelmed by irrelevant or low-quality data.
For example, in financial forecasting, cRAG can prioritize real-time market data over static reports, enabling LLMs to deliver actionable insights with unparalleled accuracy.
This synergy also addresses a common misconception: that LLMs alone can ensure reliability.
Without cRAG’s corrective mechanisms, even the most advanced models risk generating plausible but incorrect outputs. Together, they redefine the boundaries of trust and precision in AI-driven applications.
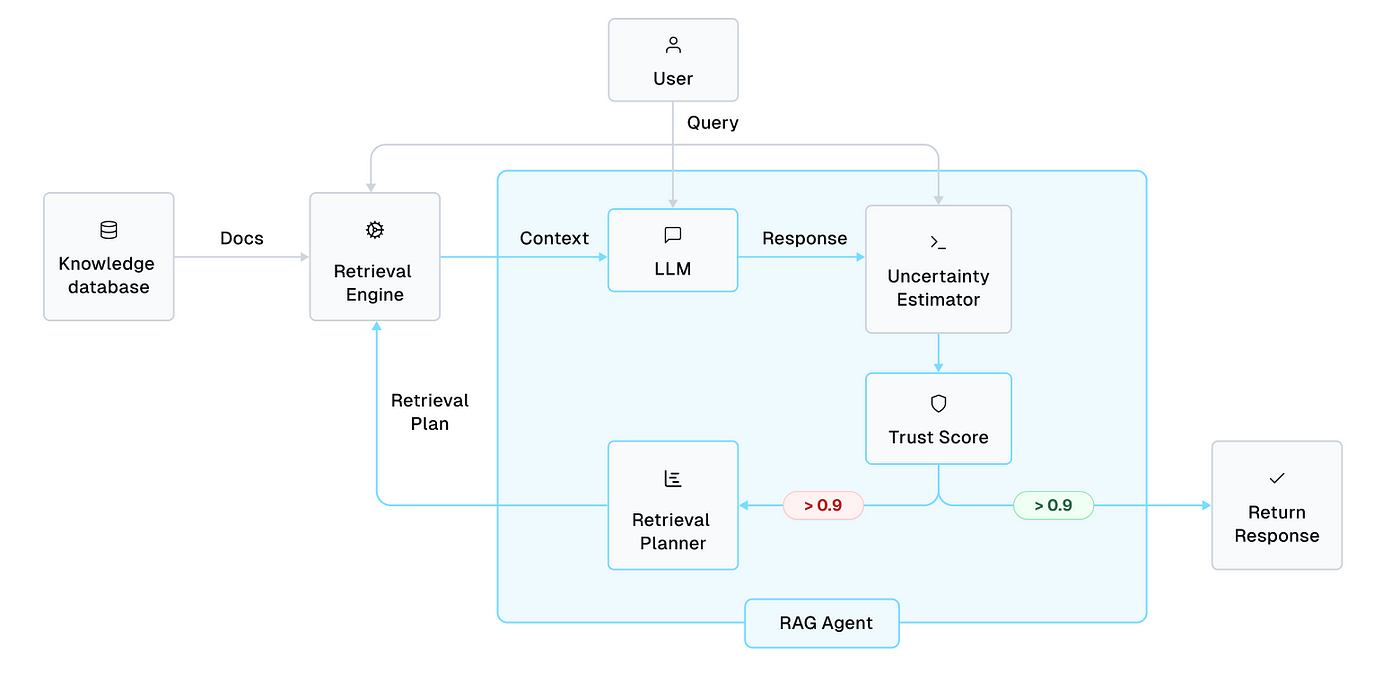
Enhancing LLM Outputs with cRAG
The decompose-then-recompose strategy in cRAG fundamentally reshapes how LLMs process retrieved data, ensuring outputs are precise and contextually aligned.
One of the most compelling aspects of this approach is its adaptability.
For instance, in regulatory compliance, cRAG can prioritize statutory language while discarding interpretative commentary, tailoring outputs to the specific needs of compliance officers.
This dynamic calibration ensures that the system remains versatile across diverse use cases.
However, this precision comes with challenges. The computational overhead of iterative refinement can be prohibitive in real-time applications, and the quality of outputs heavily depends on the evaluator’s training data.
Addressing these limitations requires a careful balance between accuracy and efficiency, making cRAG a tool that demands both technical expertise and strategic implementation.
Reducing Hallucinations in LLMs
One of the most intricate challenges in reducing hallucinations lies in the nuanced interplay between retrieval accuracy and contextual alignment.
cRAG’s dual-layer evaluation system addresses this by scoring document relevance and dynamically refining the retrieval process to adapt to the query’s intent.
This mechanism operates on a principle of iterative validation.
Each retrieved document undergoes a confidence scoring process, and those falling below a threshold are flagged for corrective actions.
However, the true innovation lies in how cRAG recalibrates its retrieval strategies in real time, ensuring that subsequent iterations align more closely with the query’s context.
This adaptability is particularly critical in domains like healthcare, where even minor misalignments can lead to significant consequences.
A notable edge case emerges in scenarios with ambiguous queries. Here, cRAG’s reliance on evaluator quality becomes a double-edged sword, as poorly calibrated evaluators may misinterpret intent.
Addressing this requires robust training datasets and domain-specific fine-tuning, underscoring the importance of context-aware implementation strategies. By embracing these complexities, cRAG transforms LLMs into systems capable of delivering precision without compromise.
Technical Implementation of cRAG
The technical foundation of cRAG lies in its ability to transform raw retrieval into actionable intelligence through meticulously designed mechanisms.
At its core, the lightweight retrieval evaluator is the system’s gatekeeper, assigning confidence scores to retrieved documents.
This evaluator, often powered by fine-tuned T5-based models, quantifies relevance precisely, enabling the system to trigger corrective actions such as reformulating queries or initiating web searches.
This ensures that only the most contextually aligned data informs downstream processes.
By integrating these components, cRAG balances computational efficiency and precision, making it indispensable for high-stakes applications like legal analysis and medical diagnostics.
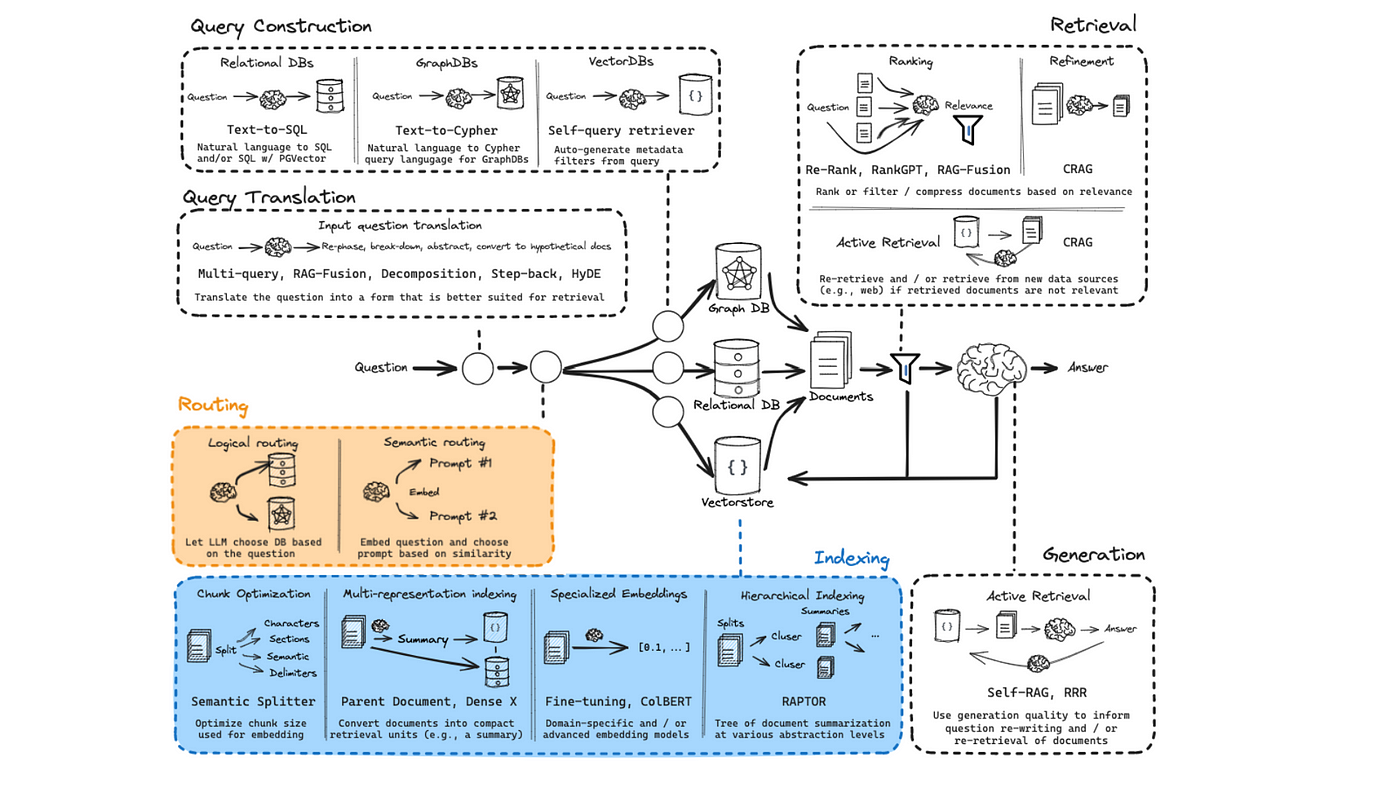
Lightweight Retrieval Evaluators
Lightweight retrieval evaluators act as the first line of defense in ensuring the relevance and accuracy of retrieved documents.
Their design prioritizes efficiency, leveraging fine-tuned models like T5 to assign confidence scores.
However, their true value lies in their ability to dynamically adapt to the context of a query, a feature often overlooked in standard implementations.
One critical mechanism is the evaluator’s threshold calibration.
This parameter determines whether a document is flagged for corrective action or passed through.
In practice, overly rigid thresholds can exclude valuable data, while lenient settings risk allowing irrelevant information.
For instance, during a deployment in a legal analytics platform, fine-tuning the threshold to prioritize statutory language over interpretative commentary significantly improved output reliability.
Another nuance is the evaluator’s dependency on training data quality.
Poorly curated datasets can skew confidence scoring, leading to systemic biases. Addressing this requires iterative retraining with domain-specific data, ensuring the evaluator remains contextually aware.
Some organizations integrate lightweight evaluators with human oversight during critical operations to bridge gaps.
This hybrid approach balances speed with contextual accuracy, making it particularly effective in high-stakes environments like healthcare diagnostics. The interplay between automation and human expertise underscores the evaluator’s potential when applied thoughtfully.
Decompose-then-Recompose Algorithm
The decompose-then-recompose algorithm is a cornerstone of cRAG’s ability to refine retrieved data into actionable insights.
By fragmenting documents into “knowledge strips,” this method ensures that each segment undergoes independent evaluation for relevance and accuracy.
This granular approach isolates critical information and prevents errors' compounding—a common issue in traditional retrieval systems.
What makes this technique particularly impactful is its adaptability to diverse contexts. For instance, the algorithm can prioritize statutory language in regulatory compliance while discarding interpretative commentary. This flexibility allows the system to tailor its refinement process to the specific demands of the application, ensuring outputs are both precise and contextually aligned.
However, the algorithm’s effectiveness hinges on the quality of its evaluative mechanisms.
Poorly calibrated thresholds or biased training data can exclude valuable insights or include irrelevant fragments. Addressing these challenges requires iterative fine-tuning and domain-specific training to maintain the integrity of the refinement process.
In practice, this algorithm transforms raw, unstructured data into a cohesive and reliable output. Its modular design enhances accuracy and enables seamless integration across industries, from legal analytics to real-time decision-making systems.
Focusing on the smallest knowledge units ensures that every detail contributes meaningfully to the final response.
FAQ
What is Corrective RAG (cRAG) and how does it improve LLM accuracy?
Corrective RAG (cRAG) improves large language model outputs by scoring retrieved documents and filtering out irrelevant ones. It uses evaluators, web search, and document breakdown to reduce errors and ensure more accurate, context-aligned answers.
How does cRAG’s decompose-then-recompose method improve results?
The decompose-then-recompose method splits documents into smaller units for review. Each part is checked for relevance before being used, helping remove noise and preserve useful context. This improves precision in fields like law, finance, and compliance.
What makes Corrective RAG different from standard RAG systems?
Unlike standard RAG, cRAG scores and filters retrieved content for quality. It adds web search and breaks documents into smaller parts to refine output. This reduces hallucinations and improves alignment between input questions and generated responses.
How does cRAG use web search to improve real-time answers?
cRAG adds real-time search when current data is missing. It reformulates queries to match search engine structure, then scores the results to discard weak content. This keeps answers fresh and accurate for real-time use like finance or emergency support.
What challenges come with using cRAG in critical systems?
cRAG adds computing load due to its scoring, query rewriting, and web search steps. It also needs strong training data for its evaluator. These demands increase cost and complexity but are necessary to ensure accurate results in high-risk fields.
Conclusion
Corrective RAG (cRAG) marks a clear step forward in refining outputs from large language models.
By scoring retrieved content, breaking documents into smaller parts, and adding real-time feedback, cRAG addresses the limits of standard RAG systems.
It reduces hallucinations, increases accuracy, and adapts well to domains where errors carry high cost. As demand for reliable AI grows, cRAG offers a more precise framework for building LLM pipelines that focus on trust, clarity, and relevance.