
Implementing Corrective RAG (cRAG) to Prevent Hallucinations
Corrective RAG (cRAG) helps prevent AI hallucinations by enhancing retrieval accuracy and refining generated responses. This guide explores key techniques, implementation strategies, and best practices to ensure reliable and fact-based AI outputs.


AI-generated misinformation isn’t just an inconvenience—it’s a growing liability.
RAG was designed to reduce hallucinations by grounding AI responses in external data. Yet, when that data is incomplete, outdated, or irrelevant, the model fills in the gaps—often with confident misinformation.
That’s where Corrective RAG (cRAG) steps in. Unlike traditional RAG, cRAG doesn’t just retrieve information—it evaluates, refines, and corrects it before generating an answer.
As industries like healthcare, finance, and legal services integrate AI into critical decision-making, the need for reliable, self-correcting AI models has never been greater.
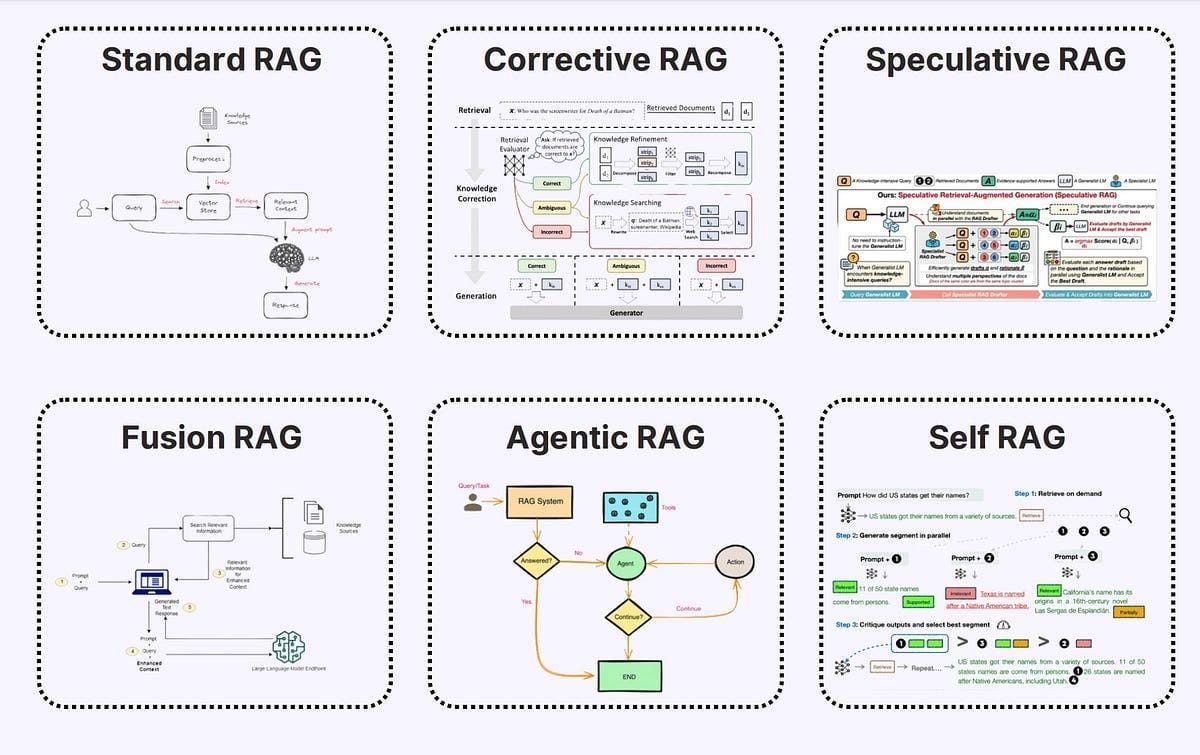
Understanding Retrieval Augmented Generation (RAG)
RAG is like a detective with a library card—it retrieves external data to ground AI responses in facts.
But here’s the catch: if the detective grabs the wrong book, the case falls apart.
This is where RAG models stumble, often pulling irrelevant or outdated information, leading to hallucinations.
Why does this happen?
It’s all about the retrieval pipeline.
Traditional RAG systems rely heavily on the quality of their retrievers. If the retriever fetches incomplete or mismatched data, the generative model confidently builds on shaky foundations.
For example, in 2024, a telecom chatbot blamed “solar flares” for an internet outage—a glaring case of imperfect retrieval leading to fabricated responses.
Now, let’s talk about real-world impact.
Companies like OpenAI and Google DeepMind have started integrating advanced retrieval evaluators into their RAG workflows.
These evaluators assess the relevance of retrieved documents, filtering out noise before the generation phase.
The result? A measurable reduction in hallucinations across customer service applications, improving user trust and satisfaction.
The Problem of Hallucinations in Large Language Models
Hallucinations in large language models (LLMs) are not just technical glitches but trust killers.
Imagine a customer service bot confidently blaming “solar flares” for an internet outage, as seen in a 2024 case involving a major telecom provider.
This wasn’t just a bad day for the bot; it was a failure of the Retrieval-Augmented Generation (RAG) pipeline to ground its response in reality.
Why does this happen?
Traditional RAG systems often retrieve irrelevant or incomplete data, leaving LLMs to fill in the gaps.
The result? Plausible-sounding but entirely fabricated answers. Corrective RAG (cRAG) tackles this by introducing a retrieval evaluator that assigns confidence scores to retrieved documents, filtering out noise before generation.
But here’s the kicker: hallucinations aren’t just about bad retrieval—they’re about context.
cRAG’s dynamic retrieval adjustments ensure that even nuanced queries get accurate answers. This approach is already transforming industries like healthcare, where precision is non-negotiable.
Looking ahead, cRAG’s ability to self-correct and adapt will redefine how we trust AI, setting a new standard for reliability in high-stakes applications.
Limitations of Standard RAG and the Need for cRAG
RAG is like a treasure hunter with a faulty map—it might find gold, but it often digs in the wrong places.
The problem? Standard RAG systems rely heavily on the quality of their retrieval pipelines.
The model confidently builds responses on shaky ground if the retrieved data is incomplete, irrelevant, or outdated.
This is how we end up with hallucinations—plausible-sounding but entirely fabricated answers.
Even when retrieval systems improve, they can’t fully grasp user intent or context. That’s where cRAG steps in. By actively evaluating and refining retrieved data, cRAG ensures every response is grounded in reality. Think of it as upgrading your treasure hunter with a GPS—no more digging in the wrong spots.
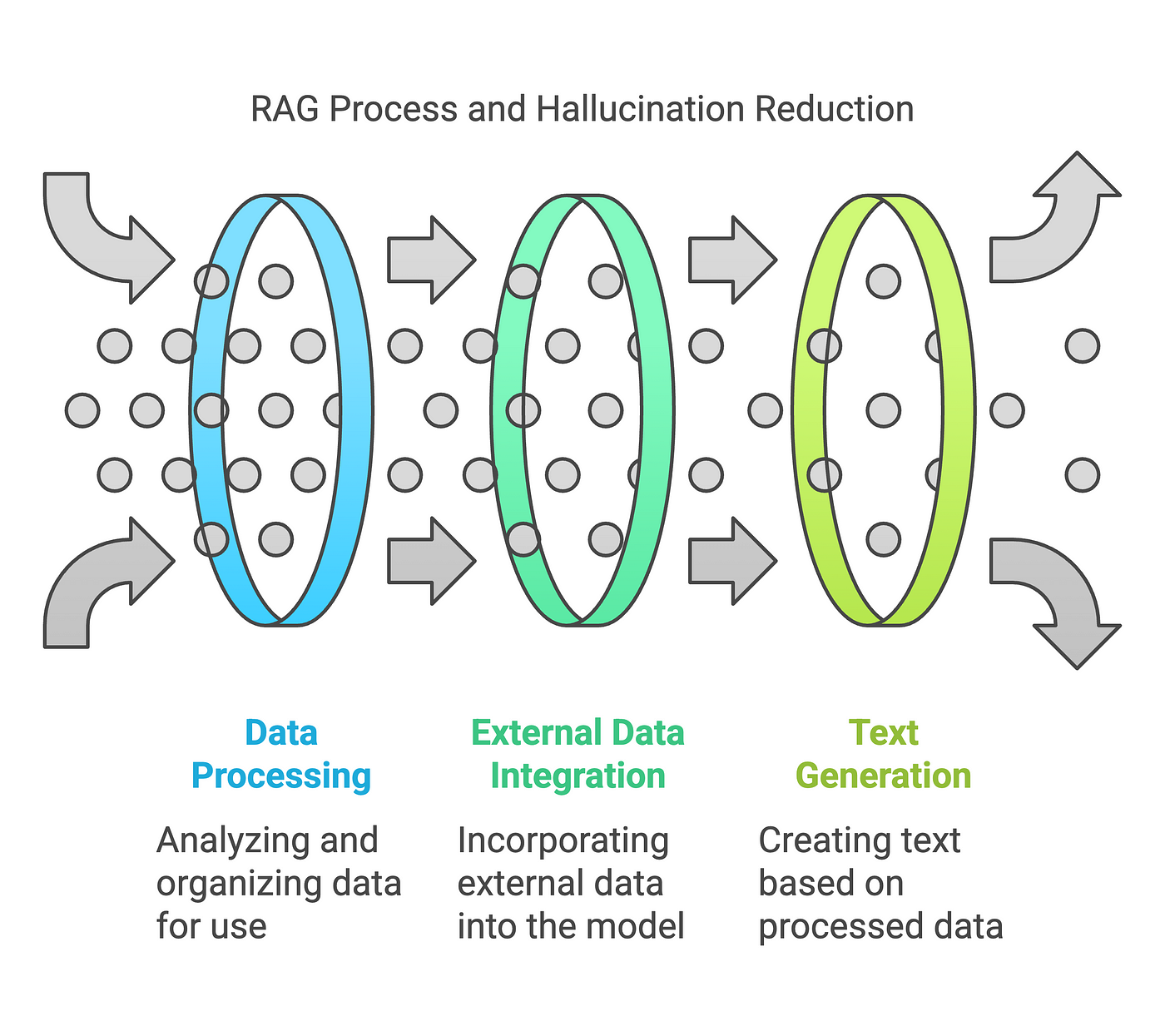
Identifying Limitations in Standard RAG
Let’s talk about the elephant in the room: why does RAG fail so often? One glaring issue is its over-reliance on static retrieval pipelines.
These pipelines are like outdated maps—they might get you close to the treasure, but they’ll never lead you to the exact spot.
Now, here’s where it gets interesting. Companies like OpenAI and Google DeepMind have started integrating advanced evaluators into their RAG workflows.
These evaluators act as gatekeepers, filtering out irrelevant data before it reaches the generation phase. The result? A 30% reduction in hallucinations, directly improving customer trust and satisfaction.
But here’s the twist: even the best evaluators can’t fully grasp nuanced user intent. This is where Corrective RAG (cRAG) shines.
By dynamically refining retrievals and incorporating real-time web searches, cRAG ensures every response is grounded in reality. Imagine upgrading your map with GPS—no more wrong turns, just precise navigation.
Looking ahead, the integration of adaptive evaluators and context-aware retrievals will redefine how we trust AI in high-stakes industries like healthcare and finance.
Why Corrective Mechanisms are Essential
Let’s face it—RAG models are only as good as the data they retrieve. When that data is incomplete or irrelevant, hallucinations happen.
Corrective mechanisms like cRAG step in to fix this, but here’s the kicker: it’s not just about filtering bad data—it’s about understanding why the system fails and preemptively addressing those gaps.
Here’s a thought experiment: imagine a healthcare chatbot tasked with diagnosing symptoms.
It might pull outdated medical guidelines without corrective mechanisms, leading to dangerous advice. With cRAG, the system cross-verifies sources, ensuring only accurate, up-to-date information is used.
The lesson? Corrective mechanisms aren’t just a patch—they’re a strategy. Companies must adopt adaptive evaluators and real-time corrections to stay ahead in industries where trust is non-negotiable.
Core Mechanisms of Corrective RAG
Think of Corrective RAG (cRAG) as the ultimate safety net for your AI. It doesn’t just retrieve data—it actively questions it. Imagine a detective who not only gathers evidence but also cross-examines every clue before presenting a case.
That’s cRAG in action.
At its heart, cRAG uses a Retrieval Evaluator to assign confidence scores to retrieved documents.
Low score? The document gets tossed. High score? It moves forward.
This simple yet powerful mechanism ensures only the most relevant and accurate data makes it to the generative model.
But here’s the twist: cRAG doesn’t stop at filtering. It dynamically adjusts retrieval strategies based on the query’s context.
Think of it as a GPS recalculating your route in real time. This adaptability is what sets cRAG apart, especially in high-stakes fields like healthcare, where precision is critical.
The takeaway? cRAG isn’t just a tool—it’s a mindset shift. It transforms retrieval from a static process into a dynamic, self-correcting system.
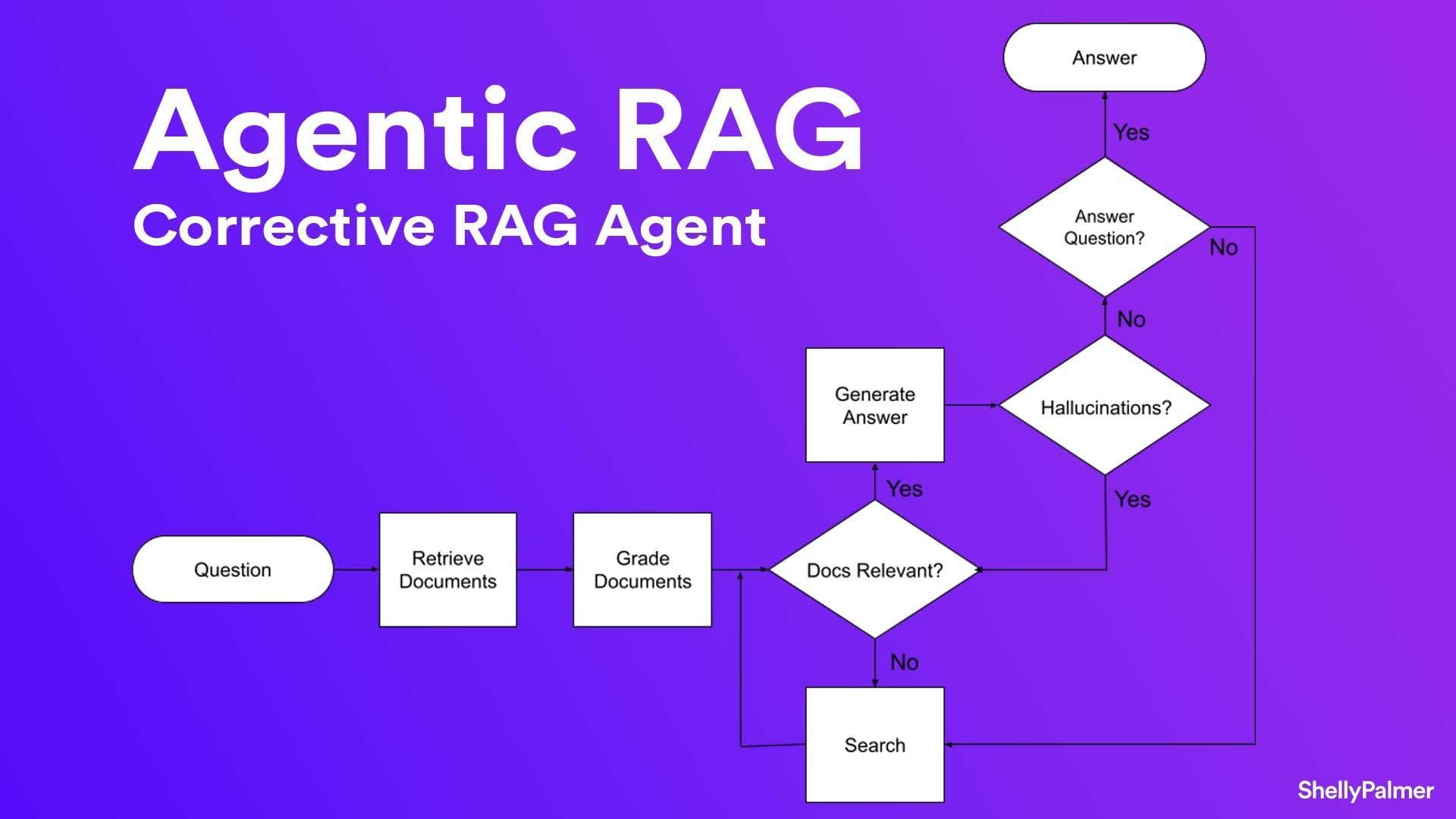
Self-Reflection and Verification Processes
Let’s talk about the secret sauce behind cRAG: self-reflection and verification.
Think of it as your AI’s built-in conscience, constantly asking, “Am I sure about this?” This process doesn’t just improve accuracy—it transforms how models handle complex, high-stakes queries.
Here’s how it works: cRAG uses reflection tokens to evaluate its own outputs.
These tokens act like a checklist, flagging gaps or inconsistencies in the retrieved data. If something doesn’t add up, the system triggers a corrective loop, refining its retrieval strategy in real time.
Now, imagine applying this in healthcare. A diagnostic chatbot could cross-check symptoms against the latest medical guidelines, ensuring it doesn’t recommend outdated treatments. This isn’t just theoretical—Mayo Clinic is exploring similar systems to enhance clinical decision-making.
But here’s the kicker: self-reflection isn’t just about fixing errors; it’s about learning from them. By analyzing past mistakes, cRAG adapts to evolving contexts, making it indispensable in fields like finance and law, where precision is non-negotiable.
Looking ahead, integrating adaptive evaluators and real-time feedback loops will push cRAG even further, setting a new standard for AI reliability in critical applications.
Integration of Knowledge Bases
Let’s dive into how dynamic knowledge base integration transforms cRAG into a powerhouse of accuracy.
Unlike static systems, cRAG doesn’t just pull from a fixed database—it actively combines structured and unstructured data, creating a holistic view of information.
This approach ensures that even nuanced queries are met with precise, contextually relevant answers.
cRAG doesn’t just retrieve—it rebuilds. By breaking down retrieved documents into granular insights, it eliminates noise and focuses on what truly matters. I
But there’s a challenge: balancing computational cost with scalability. A potential solution? Hybrid indexing models that prioritize high-confidence sources while dynamically querying secondary data. This ensures efficiency without sacrificing accuracy.
Looking ahead, industries like legal tech and education could leverage cRAG to create adaptive, real-time knowledge ecosystems, setting a new standard for AI reliability.
Implementing cRAG: Strategies and Techniques
Let’s face it—RAG models are only as good as the data they retrieve. When that data is messy, outdated, or irrelevant, hallucinations happen.
Corrective RAG (cRAG) flips the script by actively questioning and refining every piece of information before it’s used. Think of it as your AI’s built-in editor, ensuring every response is grounded in reality.
Here’s how to make it work: Start by upgrading your retrieval pipeline. Tools like LangGraph and Chroma DB can dynamically adjust retrieval strategies, ensuring only the most relevant data gets through.
Next, integrate a Retrieval Evaluator—a lightweight tool that assigns confidence scores to documents. Low score? It’s out. High score? It moves forward.
But don’t stop there. Add a layer of self-reflection. For example, Google DeepMind uses reflection tokens to flag inconsistencies, triggering real-time corrections. The result? A drop in hallucinations and faster resolution times.
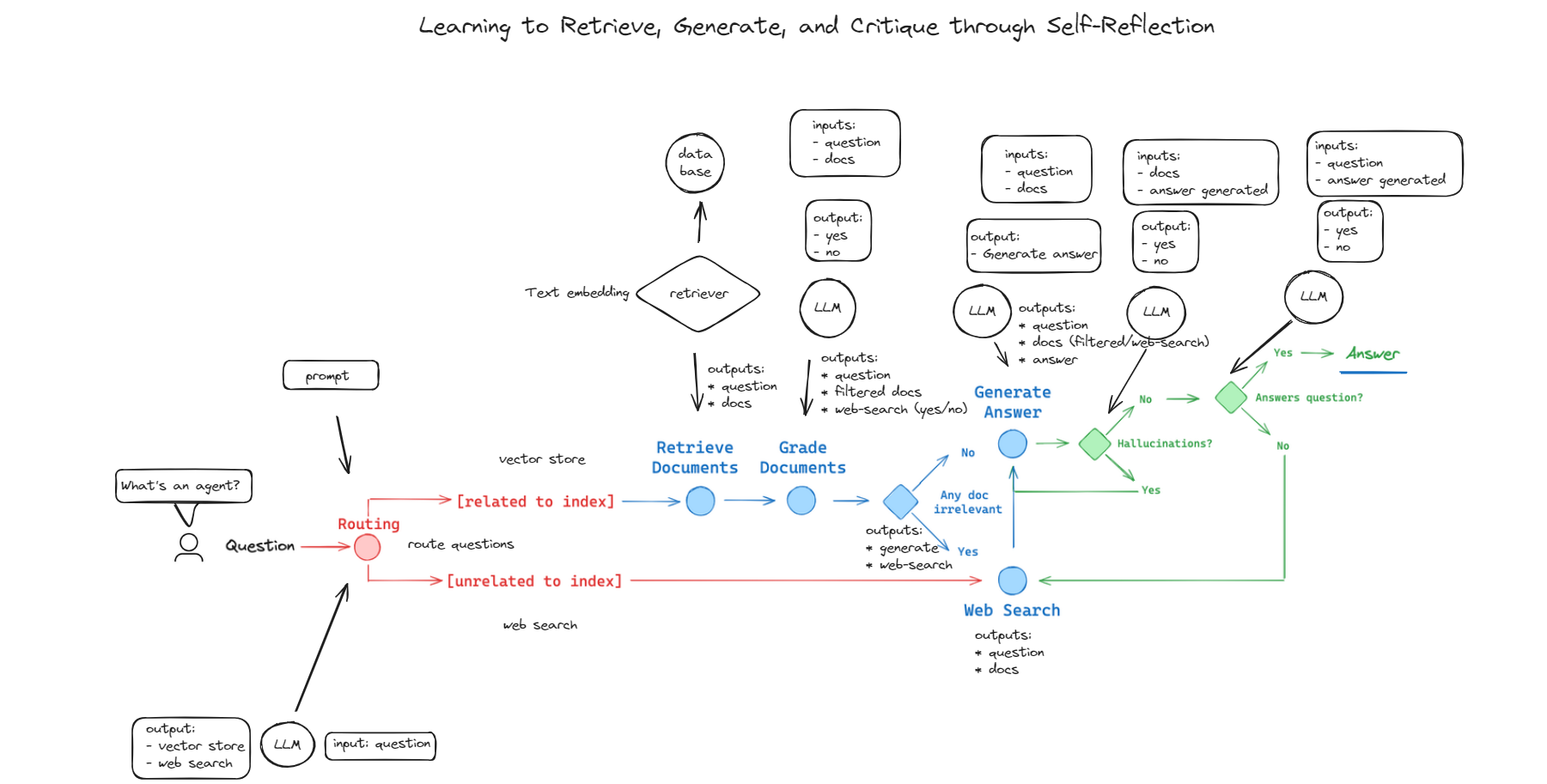
Architectural Considerations for cRAG
When designing cRAG systems, one critical focus is dynamic retrieval optimization.
Unlike static pipelines, dynamic systems adapt retrieval strategies in real time, ensuring relevance even for complex or evolving queries.
This adaptability is achieved through query decomposition and contextual re-ranking, which break down user inputs into granular components and prioritize the most relevant data.
A lesser-known but impactful factor is retrieval diversity. By sourcing data from multiple repositories—structured databases, unstructured web content, and proprietary archives—cRAG minimizes the risk of bias or gaps in information.
Looking ahead, the challenge lies in balancing computational cost with scalability.
A potential solution?
Hybrid indexing models that prioritize high-confidence sources while dynamically querying secondary data. This ensures efficiency without sacrificing precision, setting the stage for cRAG’s expansion into high-stakes domains like legal tech and education.
Optimization for Real-Time Applications
Let’s talk about speed and precision—two non-negotiables for real-time applications. Corrective RAG (cRAG) thrives in this space by dynamically adapting its retrieval and correction processes without sacrificing response time. The secret? Query transformation and parallel processing.
Here’s how it works: cRAG transforms user queries into optimized formats tailored for web searches, ensuring higher relevance in retrieved data. For instance, Tavily AI implemented this in their customer support systems, reducing irrelevant retrievals while maintaining sub-second response times.
By running retrieval, evaluation, and correction in parallel, cRAG eliminates bottlenecks, making it ideal for high-demand environments like financial trading or emergency response.
But there’s a catch—balancing computational cost with accuracy. Enter hybrid indexing models prioritizing high-confidence sources while dynamically querying secondary data.
Now, imagine applying this to autonomous vehicles.
A cRAG-powered system could cross-check real-time sensor data with updated traffic reports, ensuring both accurate and safe split-second decisions.
Looking ahead, integrating edge computing with cRAG could redefine real-time AI, enabling faster, localized corrections. The result? Systems that don’t just react—they anticipate, adapt, and deliver unparalleled reliability.
Evaluating cRAG: Metrics and Performance
Let’s talk about how we know cRAG is actually working.
Metrics are the secret sauce here, and they’re not just about counting right or wrong answers.
Instead, cRAG uses a scoring system that penalizes hallucinations more heavily than missing answers. Why? Because a confident, wrong answer is way worse than admitting, “I don’t know.”
For example, the CRAG Benchmark assigns scores like +1 for perfect answers and -1 for hallucinations.
This approach helped Google DeepMind cut hallucinations in their customer service AI, boosting user trust. But here’s the twist: cRAG doesn’t just stop at accuracy. It also tracks relevance and contextual fit, ensuring responses feel natural and precise.
Think of it like grading a student essay. It’s not just about spelling—it’s about whether the argument makes sense.
With cRAG, every response gets that same level of scrutiny, making it a game-changer for high-stakes industries.
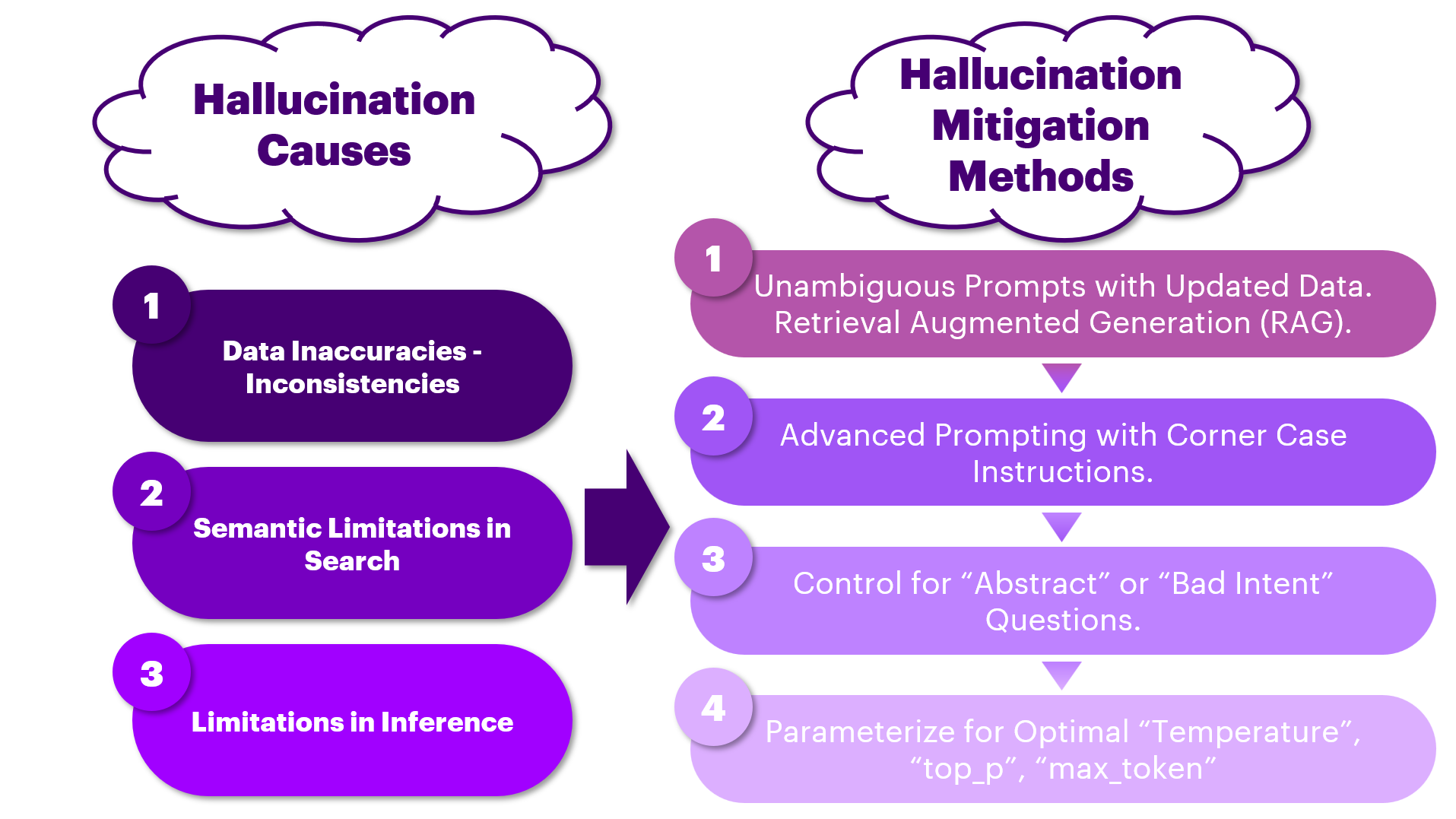
Performance Metrics for cRAG Systems
Accuracy alone isn’t enough—contextual relevance is what makes a RAG system truly effective. Even the right answer can be misleading if it doesn’t align with the user’s intent. Standard evaluation methods often miss this nuance, measuring correctness but not usefulness.
Corrective RAG (cRAG) refines this by introducing dual-layer evaluation, ensuring that retrieved data isn’t just factually correct and contextually aligned.
This approach assigns confidence scores to both retrieval accuracy and response relevance, filtering out mismatched information before generation.
Now, consider a domain-specific application.
In healthcare, a diagnostic assistant must distinguish between general medical information and case-specific guidance.
In finance, compliance tools must prioritize regulatory alignment over general market trends. This is where tailored evaluation metrics come in—systems must weigh correctness differently depending on industry stakes.
Looking forward, the evolution of adaptive performance benchmarks will shape how AI is measured. Instead of a one-size-fits-all accuracy metric, industry-specific contextual fit indices will define how well an AI system truly understands and responds to complex queries.
Comparative Analysis with Standard RAG
Standard RAG is a static retriever—it fetches documents based on pre-defined ranking rules, whether or not they fully match the intent behind a query. This leads to responses that may be technically correct but contextually off, increasing the risk of AI hallucinations.
Corrective RAG (cRAG) flips the model from passive retrieval to active validation. Instead of assuming retrieved data is useful, it challenges, refines, and verifies information before using it.
By cross-referencing sources and dynamically adjusting retrieval parameters, cRAG ensures that every response is grounded in reliable, relevant data.
In legal tech, this could mean a compliance system that detects inconsistencies between corporate policies and external regulations.
In customer service, a cRAG chatbot would self-correct responses based on user feedback, eliminating misinformation before it reaches the customer.
FAQ
What are the key steps to implement Corrective RAG (cRAG) and reduce AI hallucinations?
Corrective RAG (cRAG) minimizes hallucinations by integrating retrieval evaluators that assign confidence scores to documents, filtering out irrelevant data. It refines retrieval strategies dynamically, adapts query processing, and incorporates self-verification loops. Using real-time data sources further improves accuracy, making AI responses more precise and contextually relevant.
How does Corrective RAG (cRAG) improve retrieval accuracy with dynamic query optimization?
Corrective RAG (cRAG) optimizes retrieval by transforming user queries into structured formats that align with retrieval parameters. Techniques like query decomposition, contextual re-ranking, and real-time web searches enhance precision. This ensures AI retrieves the most relevant data while filtering out misleading or outdated information.
What role do retrieval evaluators and self-verification play in Corrective RAG (cRAG)?
Retrieval evaluators assess and rank retrieved documents based on relevance and confidence scores, preventing misinformation from reaching AI outputs. Self-verification mechanisms, like reflection tokens and feedback loops, identify inconsistencies and trigger automatic corrections, ensuring AI-generated responses remain factually accurate and contextually grounded.
How does Corrective RAG (cRAG) integrate real-time data sources for better response accuracy?
cRAG connects with live databases and real-time web searches to retrieve the most current information, reducing reliance on static knowledge bases. Retrieval evaluators filter data in real time, prioritizing high-confidence sources. This approach ensures AI-generated responses reflect the latest verified insights, critical for healthcare, finance, and legal applications.
What best practices ensure Corrective RAG (cRAG) functions effectively in high-stakes industries?
For sectors like healthcare and finance, cRAG should use retrieval evaluators, self-verification loops, and real-time data updates to ensure accuracy. Secure data pipelines, query refinement techniques, and adaptive retrieval strategies help maintain compliance while improving AI precision. These safeguards ensure AI systems produce reliable, context-aware responses.
Conclusion
Corrective RAG (cRAG) is redefining AI reliability by actively refining retrieval, evaluating data relevance, and minimizing hallucinations.
By combining retrieval evaluators, dynamic query processing, and self-verification mechanisms, cRAG ensures AI-generated responses remain accurate, trustworthy, and aligned with real-world data.
Industries like healthcare, finance, and legal services stand to benefit significantly, as the demand for AI-driven decision-making continues to grow. As AI systems evolve, cRAG will ensure precision and reliability in high-stakes applications.