
Implementing Corrective RAG with LangChain & LangGraph
Corrective RAG enhances retrieval accuracy by refining AI responses. This guide shows how to implement it using LangChain & LangGraph to reduce hallucinations, improve reliability, and build more accurate RAG systems with structured workflows.


Most Retrieval-Augmented Generation (RAG) systems fail in one critical area: they retrieve information but don’t verify whether it’s useful. This often leads to AI-generated responses that sound confident but are irrelevant, outdated, or outright incorrect.
Imagine asking a legal AI about a recent case only to receive references from ten years ago. That’s the problem that Corrective RAG (CRAG) is designed to fix.
By integrating LangChain for retrieval and LangGraph for workflow orchestration, CRAG introduces a self-correcting layer that filters out irrelevant documents, refines queries on the fly, and ensures AI responses are contextually accurate.
Instead of just retrieving and generating, CRAG evaluates, adjusts, and retrieves again—until the answer is helpful.
This article discusses how to implement Corrective RAG with LangChain and LangGraph, covering key components like retrieval evaluators, query transformation nodes, and dynamic fallback searches.
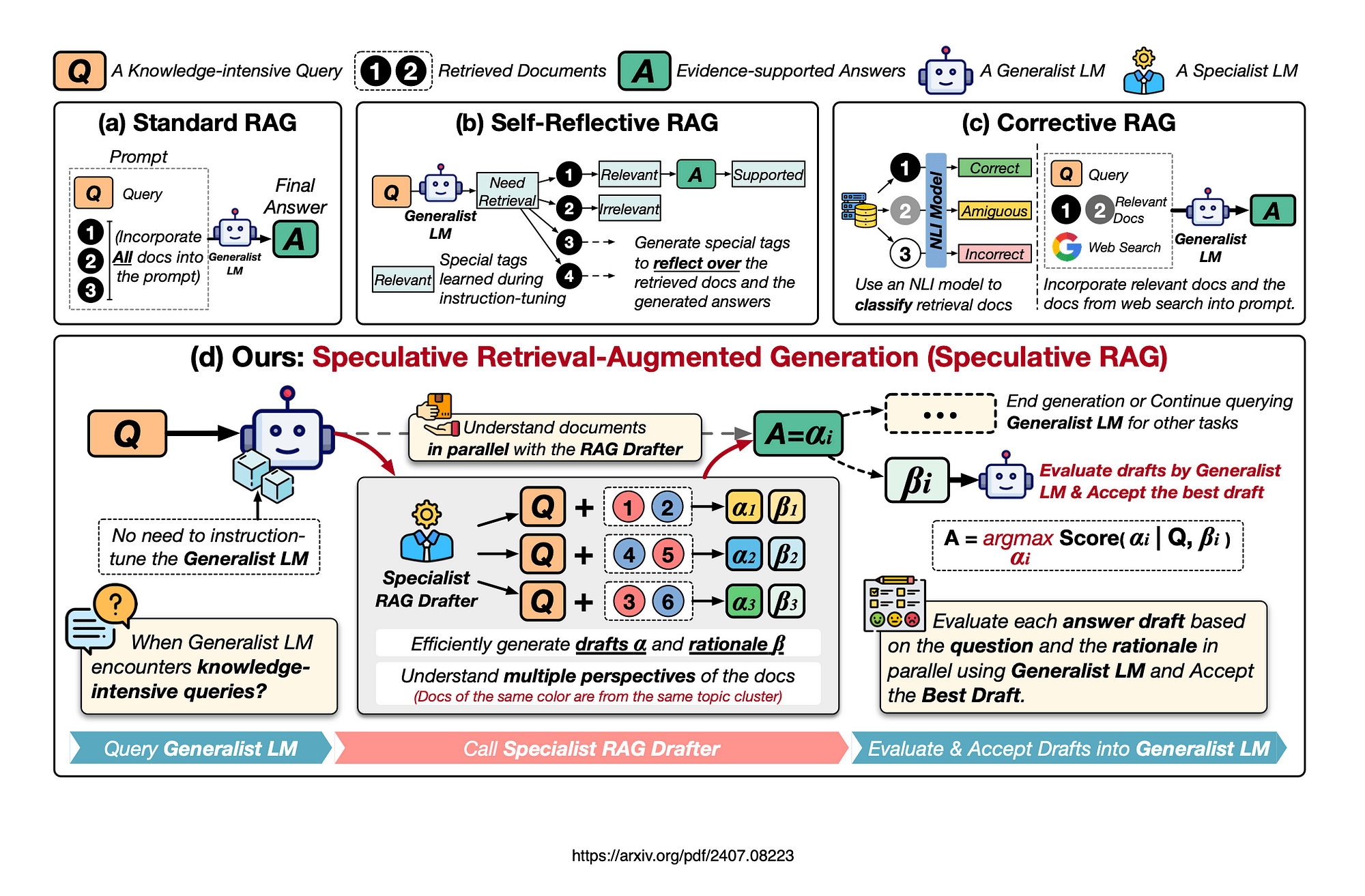
Traditional RAG Architecture and Its Limitations
Traditional RAG systems often falter when handling ambiguous queries because they rely on static retrieval mechanisms.
These systems prioritize speed over contextual depth, which can result in retrieving document chunks that are tangentially related but fail to address the query’s core intent.
This limitation stems from their linear workflow—retrieving, concatenating, and generating—without iterative refinement.
The underlying issue lies in the absence of dynamic relevance assessment. Traditional RAG lacks mechanisms to evaluate the retrieved data’s contextual fit, leading to responses that may appear coherent but lack precision.
For instance, when applied in customer support scenarios, such systems might retrieve outdated policy documents, undermining user trust. This challenge is exacerbated in domains requiring real-time accuracy, such as financial compliance or medical diagnostics.
A promising alternative involves integrating lightweight evaluators, such as those used in Corrective RAG, to assign confidence scores to retrieved data. These scores enable the system to filter irrelevant chunks dynamically, ensuring higher-quality responses.
By addressing these gaps, practitioners can transform RAG workflows into robust, context-aware systems capable of meeting real-world demands.
Role of Vector Stores and Document Retrieval
Vector stores redefine document retrieval by embedding data into high-dimensional spaces. This enables semantic searches that prioritize meaning over exact phrasing.
This capability is pivotal in Corrective RAG workflows, where precision in retrieval directly impacts the quality of generated responses.
Unlike traditional keyword-based systems, vector stores allow for nuanced matching. They capture the intent behind queries and align it with the most contextually relevant documents.
One critical technique involves semantic similarity thresholding, where only documents exceeding a predefined similarity score are included in the context.
This reduces noise and ensures retrieved data aligns closely with the query’s intent.
However, setting this threshold requires careful calibration; overly strict parameters may exclude valuable information, while lenient settings risk introducing irrelevant data.
This balance is particularly challenging in dynamic domains like customer support, where queries often lack specificity.
By integrating adaptive retrieval strategies, such as multi-query approaches, LangChain and LangGraph enable iterative refinement, ensuring that retrieval evolves alongside user intent.
This adaptability transforms retrieval from a static process into a dynamic, context-aware foundation for Corrective RAG systems.
Introducing Corrective RAG: Enhancements and Innovations
Corrective RAG (CRAG) redefines the boundaries of Retrieval-Augmented Generation by embedding a self-assessment layer that dynamically evaluates and refines retrieved data.
Unlike traditional RAG systems, which often rely on static retrieval pipelines, CRAG introduces adaptive workflows that integrate document grading, query rewriting, and fallback mechanisms like web searches.
This multi-layered approach ensures that responses are relevant and contextually precise, addressing a critical gap in real-world applications.
A pivotal innovation lies in the retrieval evaluator, which assigns confidence scores to document chunks based on their alignment with the query.
This is particularly true in high-stakes domains like legal research, where minor inaccuracies can have significant consequences.
To illustrate, consider a legal AI assistant who interprets case law. CRAG’s iterative grading mechanism filters out outdated precedents while prioritizing jurisdiction-specific rulings. This process mirrors that of a skilled attorney, who systematically excludes irrelevant details to focus on actionable insights.
By combining state machine architectures with real-time adaptability, CRAG transforms static retrieval into a dynamic, self-correcting process.
This evolution enhances response quality and positions CRAG as a foundational tool for next-generation AI systems, capable of navigating complex, evolving datasets with unparalleled precision.

Components and Workflow of Corrective RAG
The retrieval evaluator is the linchpin of Corrective RAG, transforming static retrieval into a dynamic, iterative process.
Unlike traditional systems that passively accept retrieved documents, this component actively assigns confidence scores, enabling real-time decisions about query refinement or supplementary searches.
This mechanism ensures that only the most contextually relevant data informs the final response.
What makes this approach indispensable is its adaptability. For instance, when a query yields ambiguous results, the evaluator triggers a query transformation node.
This node reformulates the query to align better with retrieval parameters, capturing nuances that might otherwise be overlooked.
Such adaptability is particularly critical in domains like legal research, where precision is non-negotiable.
LangChain and LangGraph amplify this process by integrating state machine architectures.
These allow for conditional workflows, in which the system dynamically chooses between retrying retrieval, initiating a web search, or proceeding to response generation. This orchestration enhances efficiency and minimizes the risk of irrelevant or outdated information influencing outcomes.
By embedding these mechanisms, Corrective RAG exemplifies how iterative refinement and adaptive logic can elevate retrieval-augmented systems to meet the demands of high-stakes applications. This approach underscores the importance of precision and adaptability in modern AI workflows.
Self-Reflective Mechanisms in CRAG
Self-reflective mechanisms in CRAG operate as an internal critique system, ensuring that retrieved data aligns with the query’s intent before response generation begins.
At their core, these mechanisms leverage reflection tokens to evaluate the coherence and relevance of retrieved information.
This process resembles a meticulous editor reviewing a draft, identifying gaps or inconsistencies, and prompting real-time corrections.
What makes this approach transformative is its ability to adapt retrieval strategies dynamically.
For instance, the system initiates a corrective loop when reflection tokens detect ambiguity in the retrieved data. This loop may involve query rewriting or supplementary web searches, ensuring the final dataset is accurate and contextually relevant.
Such adaptability is particularly valuable in high-stakes fields like healthcare, where even minor inaccuracies can have significant consequences.
Integrating LangChain and LangGraph for CRAG
LangChain and LangGraph form a symbiotic relationship that transforms CRAG workflows into precision-driven systems.
LangChain excels at embedding data into high-dimensional vector spaces, enabling semantic retrieval that aligns closely with user intent.
LangGraph complements this by orchestrating workflows through state machine architectures, where each node represents a decision point, such as initiating a query rewrite or triggering a fallback web search.
This integration addresses a critical challenge: balancing retrieval accuracy with adaptability.
For instance, LangGraph’s conditional logic allows workflows to pivot dynamically when retrieval confidence scores fall below a threshold. This ensures that irrelevant or ambiguous data is filtered out before reaching the language model, a feature particularly valuable in domains like legal research, where precision is paramount.
Think of LangChain as the engine powering retrieval and LangGraph as the steering system, guiding the process with surgical precision. Together, they enable CRAG to evolve beyond static pipelines, delivering context-aware, self-correcting solutions.
LangChain Framework: Building Language Model Applications
LangChain’s modular architecture excels in creating adaptive workflows for language model applications, particularly in Corrective RAG systems.
A standout feature is its ability to integrate dynamic query refinement directly into retrieval pipelines. This capability transforms static retrieval into a responsive process, where each query iteration aligns more closely with user intent.
This adaptability is critical in high-stakes domains like legal or medical research, where precision cannot be compromised.
By embedding query transformation nodes, LangChain enables workflows to recalibrate based on real-time feedback, ensuring that irrelevant or ambiguous data is systematically excluded.
Unlike rigid retrieval systems, this approach thrives in environments where data evolves rapidly, such as regulatory compliance or scientific discovery.
A practical implementation involves combining LangChain with LangGraph’s state machines. Here, each node represents a decision point, such as initiating a fallback search or triggering a corrective loop.
This synergy ensures that workflows remain both precise and adaptable, addressing edge cases like incomplete datasets or ambiguous queries. The result is a system that retrieves and refines, delivering unparalleled contextual accuracy.
LangGraph: Implementing State Machines and Workflows
LangGraph’s state machine architecture executes workflows by breaking down complex processes into modular, decision-driven nodes.
This approach is particularly effective in Corrective RAG systems, where adaptability is paramount.
Each node represents a specific function—retrieval, evaluation, or query rewriting—while edges define conditional transitions, enabling the system to respond dynamically to real-time data.
One of LangGraph's most compelling aspects is its ability to manage global state objects.
These shared states ensure consistency across nodes, allowing the system to retain context as it navigates corrective loops.
For instance, when a retrieval evaluator flags low confidence, the state machine can seamlessly trigger a query rewrite or fallback search without losing track of prior decisions. This modularity not only simplifies debugging but also enhances scalability.
However, edge cases, such as ambiguous queries, highlight the need to carefully calibrate transition thresholds.
Misconfigured nodes can lead to infinite loops or missed opportunities for refinement, underscoring the importance of rigorous testing.
LangGraph’s flexibility, when paired with LangChain’s retrieval capabilities, creates a robust framework for adaptive, context-aware systems.
Step-by-Step Implementation of Corrective RAG
Corrective RAG workflows thrive on precision and adaptability, achieved through a series of meticulously designed components.
At the core lies the retrieval evaluator, a mechanism that assigns confidence scores to retrieved documents. This evaluator acts as a gatekeeper, ensuring only the most relevant data informs the language model.
Building on this, the query transformation node introduces agility into the system.
When the evaluator flags low-confidence results, this node reformulates the query to better align with retrieval parameters.
Think of it as a translator refining a vague request into a precise command. This iterative refinement mirrors the adaptability of expert researchers, who adjust their approach based on initial findings.
Finally, LangGraph’s state machine architecture orchestrates these components seamlessly.
By defining conditional transitions, it ensures the workflow dynamically adapts to real-time data, creating a truly self-correcting system.
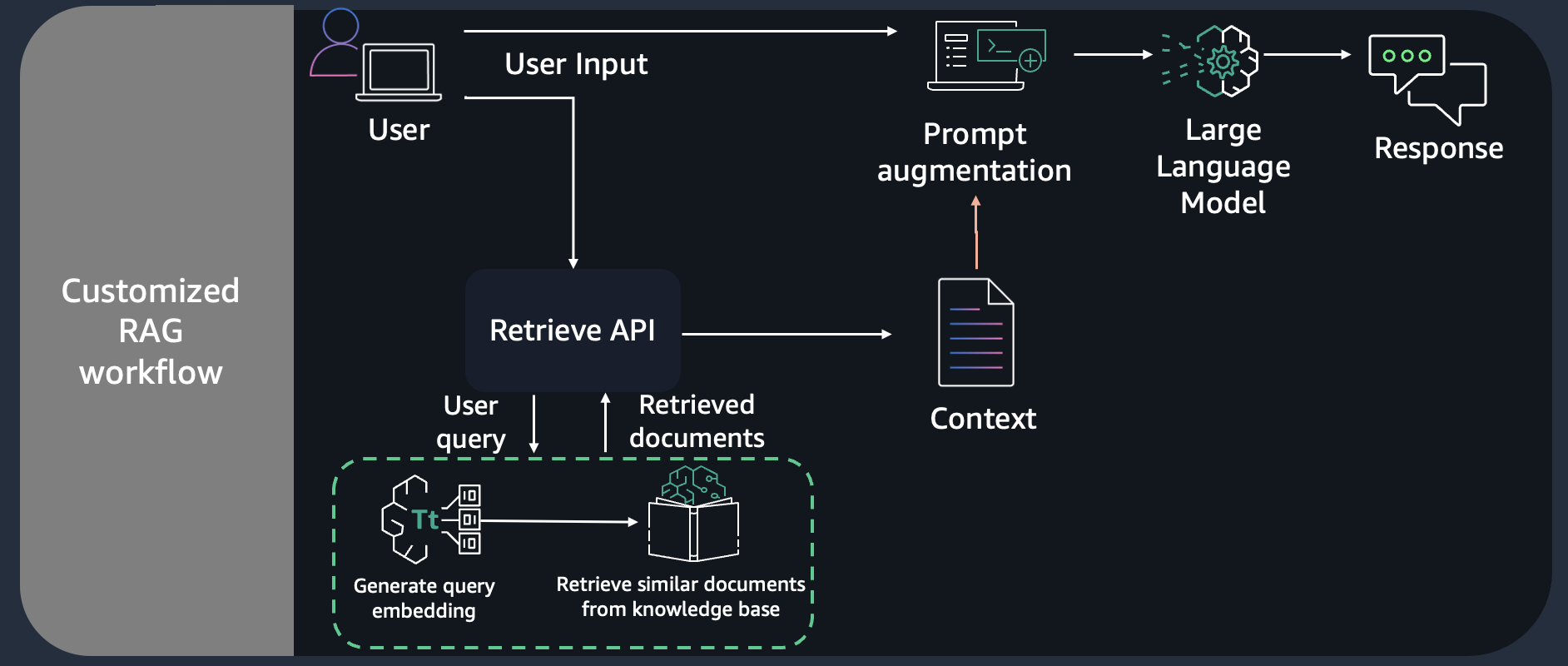
Setting Up Retrieval Evaluators with LangChain
The key to implementing retrieval evaluators in LangChain is designing a system that dynamically balances precision and adaptability.
At its core, the evaluator must act as a gatekeeper, ensuring that only the most contextually relevant documents are passed to the language model.
This process is about filtering and creating a nuanced mechanism miming human judgment in assessing relevance.
One practical approach involves leveraging confidence scoring algorithms. These algorithms assign a numerical value to each retrieved document based on its semantic alignment with the query.
For instance, LangChain allows developers to integrate custom scoring functions that evaluate factors like keyword density, semantic similarity, and contextual overlap. The evaluator can dynamically adjust thresholds by fine-tuning these parameters, ensuring optimal retrieval without excluding potentially valuable edge cases.
Balancing inclusivity and precision is a critical challenge. Overly strict thresholds may exclude documents with indirect but valuable insights, while lenient settings risk introducing noise.
To address this, developers can implement adaptive scoring models that recalibrate thresholds based on real-time feedback. For example, if user feedback indicates dissatisfaction with response quality, the evaluator can automatically adjust its scoring criteria to prioritize higher relevance.
In practice, this setup transforms the evaluator into a dynamic decision-making tool. By incorporating conditional logic and real-time adjustments, LangChain enables retrieval evaluators to evolve alongside user needs, ensuring both precision and flexibility in high-stakes applications.
Creating Query Transformation Nodes
Query transformation nodes are pivotal in refining ambiguous or overly broad user queries into actionable, precise instructions.
These nodes operate as dynamic interpreters, bridging the gap between user intent and system retrieval capabilities.
Their importance lies in their ability to recalibrate the retrieval process, ensuring that the system aligns more closely with the user’s actual needs.
The underlying mechanism involves leveraging LangChain’s query rewriting capabilities in tandem with LangGraph’s state machine architecture.
When a query fails to meet confidence thresholds, the node reformulates it by incorporating semantic adjustments or breaking it into sub-queries.
This iterative refinement not only enhances retrieval accuracy but also minimizes the inclusion of irrelevant data. For instance, in legal research, this approach can transform a vague “contract law” query into a jurisdiction-specific, time-bound inquiry, significantly improving the relevance of retrieved documents.
However, implementation nuances matter.
Overly aggressive transformations risk distorting user intent, while conservative adjustments may fail to resolve ambiguity.
Balancing these extremes requires carefully calibrating transformation parameters, informed by domain-specific requirements. This adaptability ensures that query transformation nodes remain a cornerstone of effective CRAG workflows.
FAQ
What are the key components needed to implement Corrective RAG with LangChain and LangGraph?
Corrective RAG requires a vector database for semantic retrieval, retrieval evaluators for confidence scoring, and query transformation nodes to refine ambiguous queries. LangGraph’s state machine manages workflow transitions, ensuring adaptive query refinement and fallback web searches. These elements create a self-correcting system for precise AI-generated responses.
How does LangGraph’s state machine architecture improve Corrective RAG workflows?
LangGraph’s state machine enables dynamic query processing by structuring workflows into modular decision nodes. Based on retrieval confidence scores, these nodes trigger conditional actions, such as query rewriting or supplemental searches. This adaptability ensures Corrective RAG systems remain responsive to evolving queries, reducing errors in generated responses.
What role do retrieval evaluators play in improving Corrective RAG precision?
Retrieval evaluators filter retrieved data by assigning confidence scores, ensuring only relevant content informs AI responses. If confidence is low, they trigger query refinements or fallback searches. This process reduces irrelevant data inclusion, improves retrieval accuracy, and aligns generated answers with user intent in Corrective RAG implementations.
How do query transformation nodes enhance document retrieval in Corrective RAG?
Query transformation nodes refine user queries to improve retrieval accuracy. They restructure ambiguous inputs, rephrase key terms, or break complex questions into subqueries. This ensures the system retrieves the most relevant information, improving response accuracy. These nodes help Corrective RAG maintain high precision in complex, evolving datasets.
What best practices ensure successful integration of web searches with vector databases in Corrective RAG?
To integrate web searches effectively, use retrieval evaluators to assess database results before querying external sources. Query transformation nodes refine search terms, while semantic scoring merges retrieved web data with vector-based results. Maintaining a global state in LangGraph prevents redundancy and improves efficiency in Corrective RAG workflows.
Conclusion
Corrective RAG represents a shift in how AI systems refine retrieved data to improve response accuracy.
By integrating LangChain’s retrieval capabilities with LangGraph’s state machine architecture, developers can create dynamic, self-correcting workflows that optimize query processing.
Key innovations, such as retrieval evaluators, query transformation nodes, and fallback web searches, ensure that AI-generated responses align with user intent.
As industries increasingly demand AI solutions that adapt to evolving information, Corrective RAG offers a scalable framework for improving retrieval precision.
This approach enhances AI reliability by filtering irrelevant data and refining query responses in real time, whether applied in legal research, healthcare, or enterprise chatbots.