
Daisy-Chaining Multiple RAG Instances: Guide to Scaling RAG
Daisy-chaining RAG instances enables scalable, modular AI systems. This guide explains how to link multiple RAG units to improve retrieval depth, handle complex queries, and scale efficiently without sacrificing performance or accuracy.


Scaling Retrieval-Augmented Generation (RAG) systems isn’t just about throwing more compute at the problem.
It’s about working smarter. When data grows, and queries become more layered, traditional RAG architectures start to hit limits—slow responses, repeated retrievals, and models choking on noise.
That’s where daisy-chaining comes in.
Instead of one giant RAG instance trying to do everything, we split the workload across smaller, specialized RAG modules—each one handling a piece of the puzzle. It sounds simple, but this method flips the usual approach on its head. It’s not just modular—it’s strategic.
In this guide, we’ll break down how daisy-chaining multiple RAG instances can help scale RAG with more precision and less waste.
We’ll walk through the architecture, real-time retrieval, query refinement, and the trade-offs you need to manage—like latency, redundancy, and hallucination risks.
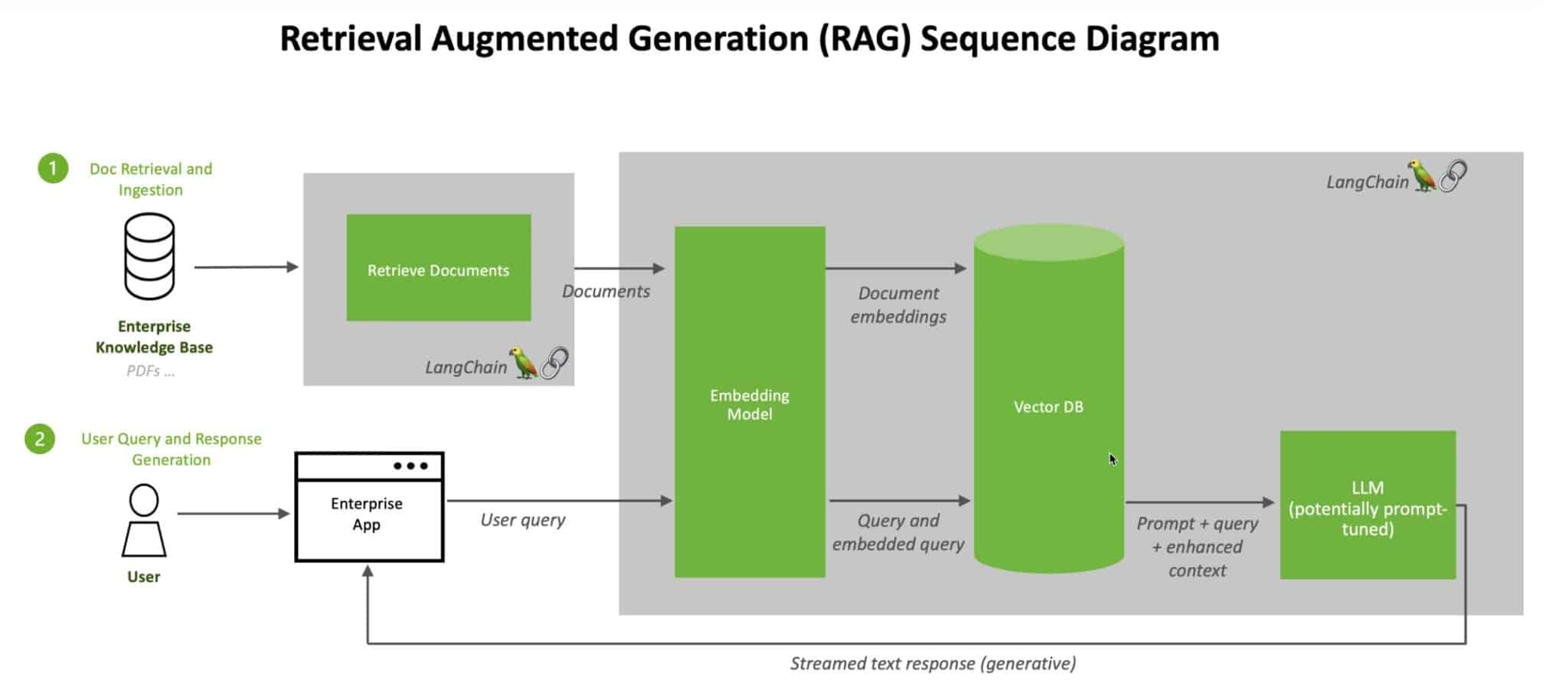
Core Components of RAG Systems
A critical yet often overlooked aspect of daisy-chained RAG systems is the retrieval overlap problem—a scenario where multiple RAG instances redundantly fetch similar data, leading to inefficiencies in both latency and resource utilization.
Addressing this requires a nuanced understanding of retrieval dynamics and architectural design.
To mitigate overlap, context-aware retrieval mechanisms can be implemented.
These mechanisms leverage metadata tagging and query disambiguation to ensure that each RAG instance retrieves unique, non-redundant data.
For example, a healthcare application might segment retrieval tasks by medical specialties, ensuring that one instance focuses on oncology while another handles cardiology.
This segmentation reduces redundancy and enhances the specificity of downstream generation.
Another solution involves dynamic query routing, where a central controller evaluates the relevance of retrieved data at each step and redirects subsequent queries to unexplored data clusters. This approach minimizes retrieval overlap while maintaining contextual alignment.
The Role of Real-Time Data Retrieval
Real-time data retrieval is the linchpin of daisy-chained RAG systems, enabling dynamic adaptation to evolving information landscapes.
Unlike static datasets, real-time retrieval ensures that each RAG instance operates with the most current and contextually relevant data, a necessity when sequential nodes refine queries iteratively. This continuous flow of updated information mitigates the risk of outdated or irrelevant outputs propagating through the chain.
A key technique in real-time retrieval is adaptive query partitioning, where queries are dynamically segmented based on metadata and contextual relevance.
For example, in a live sports analytics system, retrieval tasks can be divided by event type—such as player statistics or game highlights—ensuring that each node processes distinct, non-overlapping data. This segmentation reduces redundancy and enhances the precision of downstream synthesis.
Another critical mechanism is asynchronous caching, which pre-fetches high-priority data streams while allowing lower-priority queries to execute in parallel. This approach minimizes latency without compromising retrieval accuracy.
By integrating these strategies, real-time retrieval transforms theoretical scalability into practical reliability, ensuring that daisy-chained RAG systems deliver both speed and precision in high-stakes applications.
Concept of Daisy-Chaining in RAG
Daisy-chaining in Retrieval-Augmented Generation (RAG) redefines scalability by structuring multiple RAG instances into interconnected modules, each performing specialized tasks.
Unlike monolithic architectures, this approach distributes computational loads, enabling systems to process vast datasets with precision.
Architecturally, daisy-chaining can follow serial or parallel patterns. In serial chaining, each node refines the query iteratively, akin to a relay race where each runner optimizes the baton’s position.
Conversely, parallel chaining divides tasks across nodes simultaneously, ideal for scenarios requiring diverse data sources.
Modular layering further enhances this design, allowing independent optimization of retrieval and generation components.
However, challenges such as latency accumulation and hallucination propagation demand innovative solutions.
Techniques like dynamic query routing—where queries adapt based on intermediate results—and context-aware retrieval mitigate these risks. For example, Google’s TPU-optimized RAG systems leverage metadata tagging to reduce retrieval overlap, ensuring efficiency.
By addressing these complexities, daisy-chaining unlocks transformative potential in domains like real-time analytics and legal research, where precision and scalability are paramount.
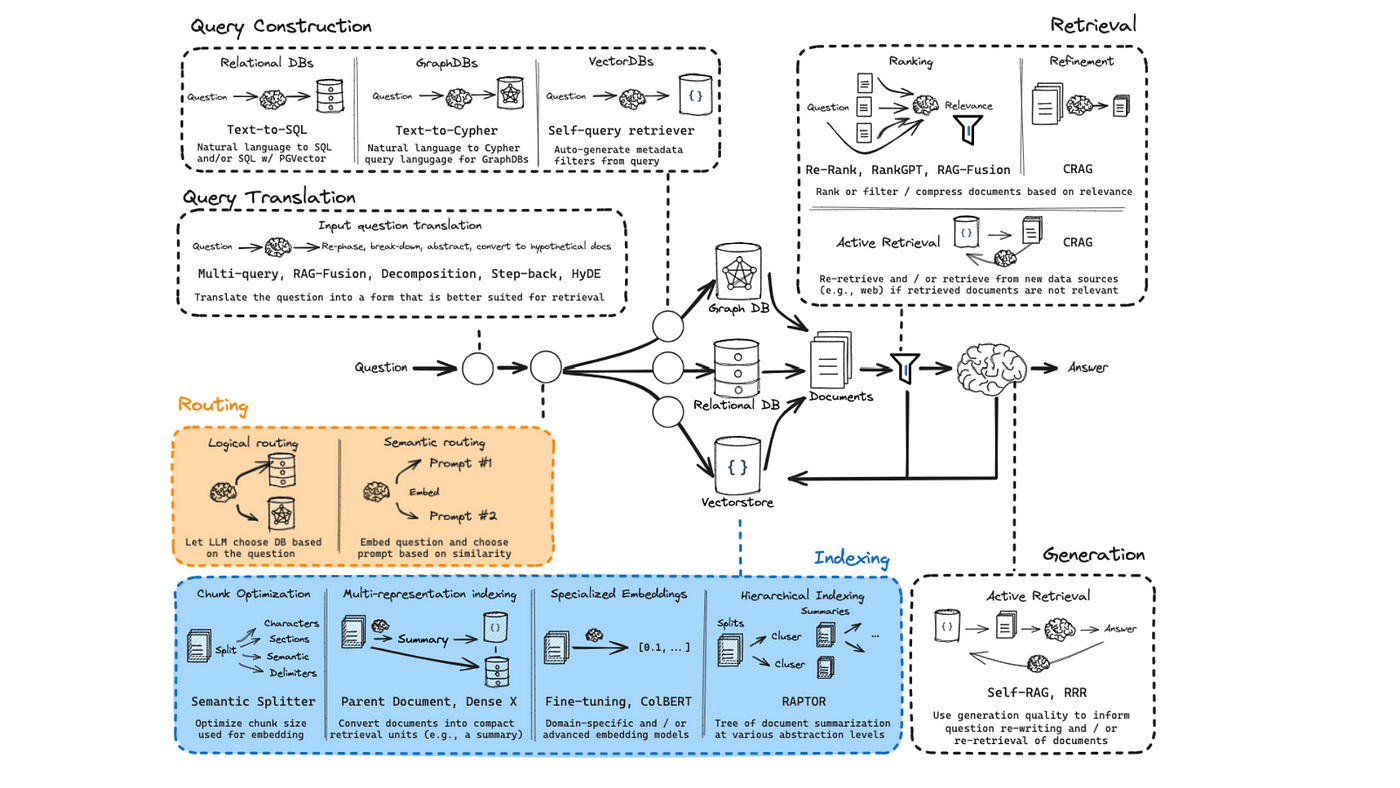
Sequential Processing in RAG Instances
Sequential processing in daisy-chained RAG systems leverages a modular relay structure, where each instance incrementally refines the query and retrieved data.
This design ensures that the system progressively narrows its focus, reducing noise and improving the relevance of outputs.
The principle of query refinement is central: each node in the chain performs a specialized task, such as filtering irrelevant data or enhancing contextual alignment, before passing the refined query downstream.
A critical advantage of this approach lies in its ability to mitigate error propagation. By isolating tasks, errors introduced in one module are less likely to cascade through the system.
For instance, a healthcare RAG system might use the first module to retrieve general medical guidelines, while subsequent nodes focus on patient-specific data. This segmentation minimizes the risk of hallucinations and ensures precision in high-stakes applications.
Techniques like asynchronous caching and dynamic query re-weighting are employed to optimize sequential processing.
This layered refinement approach exemplifies how modularity enhances both scalability and precision in complex RAG deployments.
Information Flow and Refinement
In daisy-chained RAG systems, the refinement of information flow hinges on adaptive query segmentation, a technique that ensures each module processes a distinct subset of the query.
This approach prevents redundancy and enhances the precision of downstream outputs. By dynamically partitioning queries based on metadata and contextual relevance, systems can allocate retrieval tasks more effectively.
For instance, in a legal research application, one node might focus on case law precedents while another retrieves statutory interpretations, ensuring comprehensive yet non-overlapping results.
A critical mechanism supporting this process is contextual feedback loops, where intermediate outputs are evaluated and adjusted before being passed to subsequent nodes.
This iterative refinement reduces the risk of error propagation and ensures that each module contributes uniquely to the final synthesis.
However, challenges such as balancing granularity with latency persist. Asynchronous processing pipelines can be employed to address this, allowing nodes to operate in parallel where dependencies are minimal.
This hybrid approach optimizes both speed and accuracy, making it particularly effective in high-stakes domains like healthcare diagnostics.
Scalability Challenges in RAG Systems
Scaling Retrieval-Augmented Generation (RAG) systems involves navigating a complex interplay of computational, architectural, and data management challenges.
A critical issue is retrieval granularity, where overly broad retrievals flood generative models with irrelevant data, increasing noise and reducing precision.
Another challenge is latency accumulation across chained RAG instances. Each module’s processing time compounds, creating bottlenecks in real-time applications.
Misconceptions about scaling often overlook retrieval overlap, where redundant queries waste resources. Techniques like dynamic query partitioning, which segments tasks based on metadata, have proven effective.
These challenges underscore the need for precision-engineered architectures that balance speed, accuracy, and resource utilization.
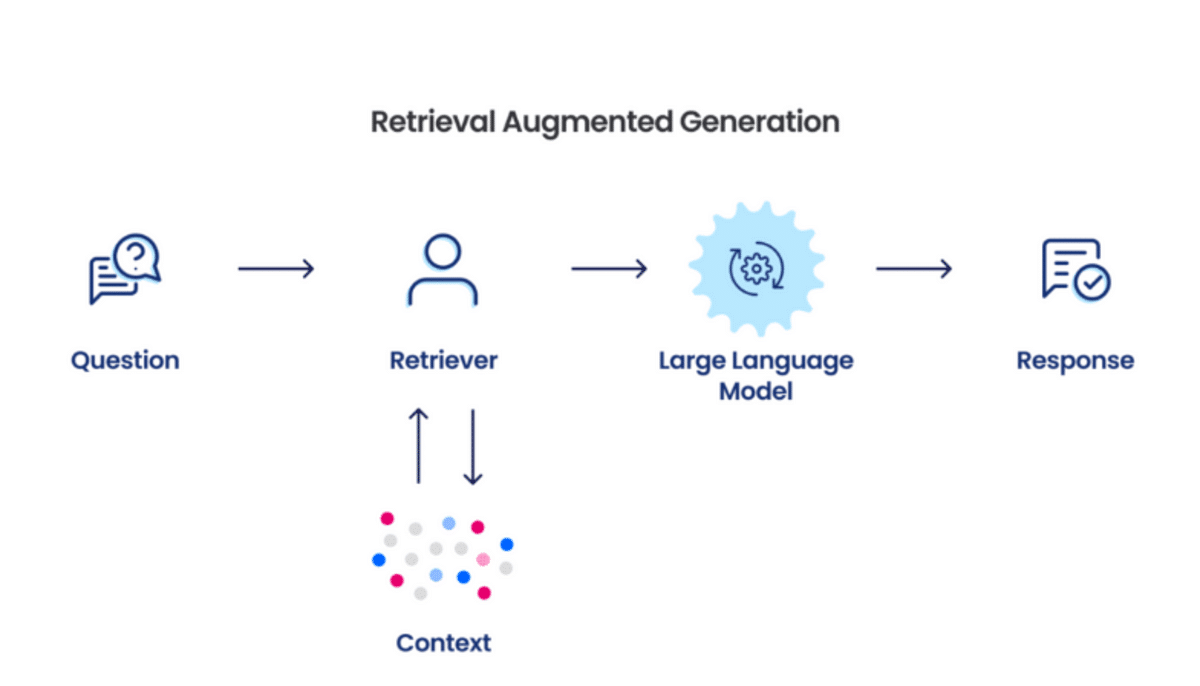
Managing Data Complexity
Efficiently managing data complexity in daisy-chained RAG systems requires addressing the interplay between retrieval granularity and contextual alignment.
A critical technique is hierarchical indexing, which organizes data into multi-level structures, enabling precise retrieval at varying levels of detail.
For instance, RAPTOR-based indexing aggregates data from granular to broad categories, ensuring that each RAG instance processes only the most relevant subset of information.
A comparative analysis reveals that hierarchical indexing outperforms flat indexing in high-dimensional datasets, particularly in domains like legal research, where nuanced distinctions between statutes and case law are essential.
However, its effectiveness depends on robust metadata tagging, as poorly annotated data can lead to misaligned retrieval paths.
This highlights the importance of metadata-driven query refinement, where queries dynamically adapt based on the indexed structure.
An unexpected limitation arises in real-time applications, where hierarchical indexing may introduce latency due to multi-level lookups. To mitigate this, asynchronous query execution can be employed, allowing parallel processing across index levels.
By integrating these strategies, organizations can scale RAG systems while maintaining precision and efficiency.
Performance Optimization Techniques
A pivotal technique for optimizing performance in daisy-chained RAG systems is adaptive query re-weighting, which dynamically adjusts the priority of retrieval tasks based on intermediate results.
This method ensures that computational resources are allocated to the most contextually relevant queries, reducing redundancy and improving overall efficiency.
Unlike static retrieval pipelines, adaptive re-weighting introduces a feedback loop where each node evaluates the relevance of its outputs before passing them downstream.
However, implementation challenges arise in scenarios with high query variability. In such cases, the system may over-prioritize certain data paths, leading to bottlenecks.
Organizations can mitigate this by employing multi-threaded execution frameworks that parallelize low-priority tasks, ensuring consistent throughput.
By combining adaptive re-weighting with parallel execution, daisy-chained RAG systems achieve scalable performance without compromising accuracy.
Advanced Techniques for Scaling RAG
Scaling Retrieval-Augmented Generation (RAG) systems through daisy-chaining requires precision in both architecture and execution.
A critical insight is the use of multi-tiered retrieval pipelines, where each node specializes in refining specific query dimensions.
This approach minimizes noise and ensures that downstream nodes process only the most relevant data. To address latency—a common bottleneck in chained architectures—asynchronous query execution frameworks are indispensable.These frameworks allow nodes to operate independently, leveraging distributed vector databases to pre-fetch and cache high-priority data.
An often-overlooked challenge is context window limitations in generative models. Systems can optimize context utilization by segmenting queries dynamically and employing metadata-driven routing without sacrificing accuracy.
This layered refinement transforms scalability into a practical reality, enabling RAG systems to excel in high-stakes domains like healthcare diagnostics and financial forecasting.
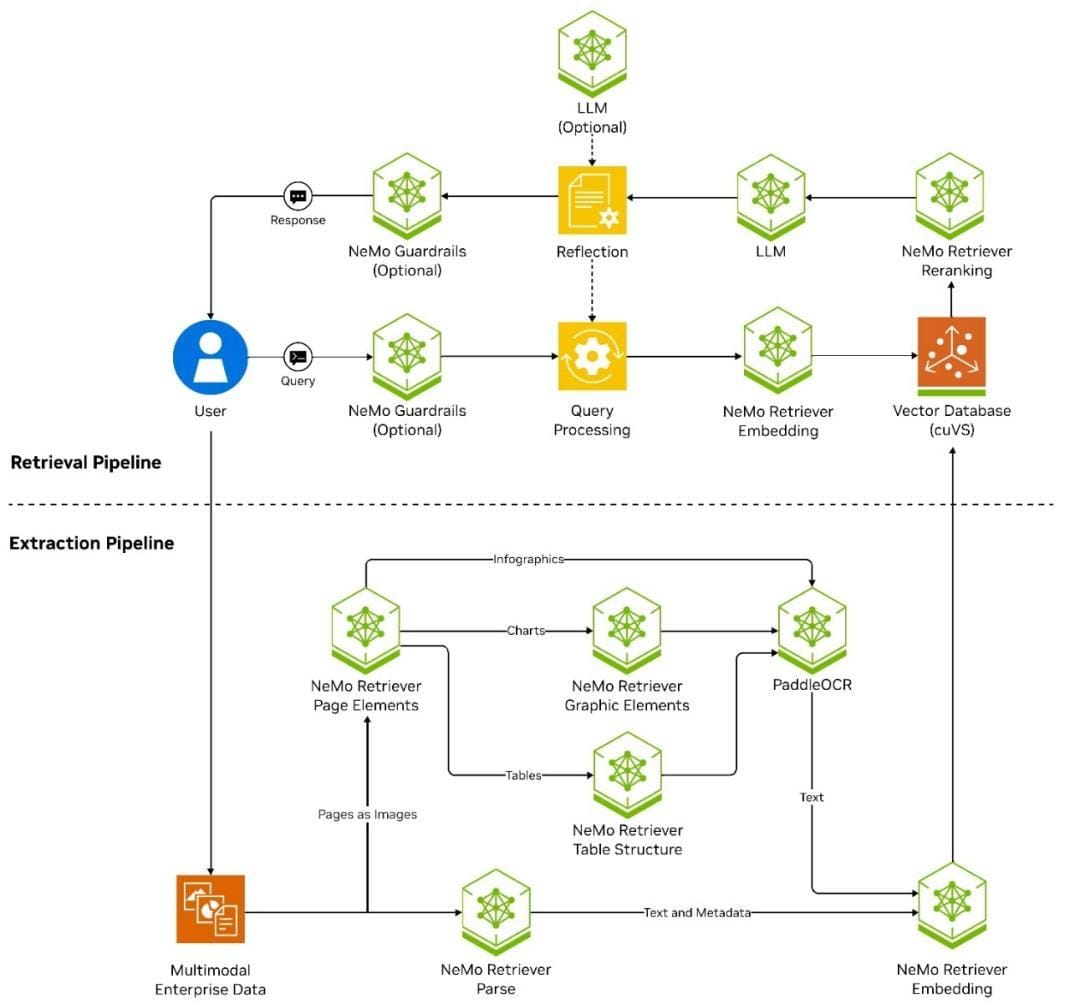
Implementing Multi-Tiered Retrieval Architectures
A pivotal aspect of multi-tiered retrieval architectures in daisy-chained RAG systems is the segmentation of retrieval tasks into hierarchical layers, each optimized for a specific function.
This approach addresses the inefficiencies of monolithic retrieval by distributing computational loads and refining data relevance at each stage.
For instance, the first tier might perform broad-spectrum filtering, while subsequent layers focus on domain-specific or contextually nuanced data extraction.
The underlying mechanism relies on adaptive query partitioning, where metadata and contextual cues guide the routing of queries through specialized tiers.
This ensures that each layer processes only the most relevant subset of data, reducing redundancy and enhancing precision.
However, the effectiveness of this approach hinges on dynamic query routing algorithms. These algorithms evaluate intermediate results to determine the optimal path for subsequent queries.
For example, in a financial analytics system, if the initial layer identifies a high-relevance cluster, the query is routed to a deeper tier for granular analysis. This dynamic adaptability minimizes retrieval overlap and ensures contextual alignment.
Despite its advantages, this architecture introduces complexities, such as balancing granularity with processing speed.
Addressing these requires robust feedback loops and asynchronous execution frameworks, which allow tiers to operate independently while maintaining coherence.
By integrating these strategies, multi-tiered retrieval architectures unlock new possibilities for scaling RAG systems in high-stakes domains like healthcare and legal research.
Leveraging Distributed Vector Databases
Distributed vector databases redefine scalability in daisy-chained RAG systems by decentralizing data storage and retrieval processes.
Unlike centralized databases, which often become bottlenecks under high query loads, distributed systems partition data across multiple nodes, enabling parallel processing and reducing latency. This architecture ensures that each RAG instance operates on a localized data subset, optimizing retrieval speed and resource utilization.
A key mechanism underpinning this approach is data sharding, where high-dimensional vector data is divided into smaller, manageable partitions.
Each shard is assigned to a specific node, allowing queries to be processed independently and concurrently.
For example, in a customer support RAG system, one node might handle product-related queries while another focuses on service issues, ensuring minimal overlap and faster response times.
Comparatively, distributed vector databases outperform centralized systems in handling large-scale, dynamic datasets. While centralized architectures struggle with retrieval overlap and single-point failures, distributed setups excel in fault tolerance and scalability.
However, challenges such as maintaining consistency across nodes and managing inter-node communication require robust synchronization protocols.
By decentralizing data access, distributed vector databases empower daisy-chained RAG systems to handle enterprise-scale workloads, mitigating retrieval inefficiencies and unlocking new performance levels.
FAQ
What are the key benefits of daisy-chaining multiple RAG instances?
Daisy-chaining RAG instances improves scalability by assigning distinct roles to each node. This reduces redundancy, improves retrieval accuracy, and lowers latency. It allows systems to process large datasets efficiently by refining queries step-by-step across specialized modules.
How does query refinement improve accuracy in a daisy-chained RAG system?
Query refinement improves accuracy by narrowing the scope of each query at every step. Each RAG node applies filters or context-based rules, reducing noise and helping the system return precise, relevant results aligned with the user’s intent.
What are the main challenges in scaling RAG systems using daisy-chaining?
Key challenges include latency build-up, retrieval overlap, and error propagation. These can be addressed with asynchronous execution, query partitioning, and feedback loops. Proper architecture ensures each module works efficiently without repeating work or passing on flawed outputs.
How do entity relationships and metadata tagging support RAG efficiency?
Entity relationships and metadata tagging guide the system to retrieve only relevant data. They prevent overlap, improve context understanding, and ensure each node processes unique content. This structure reduces errors and supports faster, more accurate responses.
What are best practices for dynamic query routing in daisy-chained RAG systems?
Use semantic analysis and metadata tagging to guide queries to the right node. Adaptive feedback helps fine-tune paths in real-time. Pair this with asynchronous execution to reduce delays and ensure nodes contribute meaningful, non-redundant results.
Conclusion
Daisy-chaining multiple RAG instances allows systems to scale without relying on rigid, centralized setups.
By distributing tasks and refining queries across connected modules, these systems improve accuracy, lower latency, and manage large datasets more effectively.
With careful design—using dynamic routing, entity linking, and metadata tagging—organizations can use daisy-chained RAG architectures for real-time, high-stakes applications in healthcare, finance, and law.