
DeepSeek R1 + RAG Tutorial: Build a PDF Chatbot That Actually Works (2025 Guide)
This 2025 guide walks you through building a functional PDF chatbot with DeepSeek R1 + RAG. Learn step-by-step how to enhance AI retrieval and create an intelligent chatbot that efficiently processes and responds to document queries.


Imagine this: you’ve just deployed a chatbot to handle customer queries, but instead of impressing users, it stumbles over basic questions, spits out irrelevant answers, or worse—hallucinates entirely fabricated information.
Sound familiar? This is the reality for most AI chatbots today, even those powered by cutting-edge language models.
But what if you could build a chatbot that doesn’t just guess but knows? A system that dives into your PDFs, extracts exactly what’s needed, and delivers answers with pinpoint accuracy. That’s where Retrieval-Augmented Generation (RAG) and DeepSeek R1 come in.
So how do you make it work? Let’s find out.
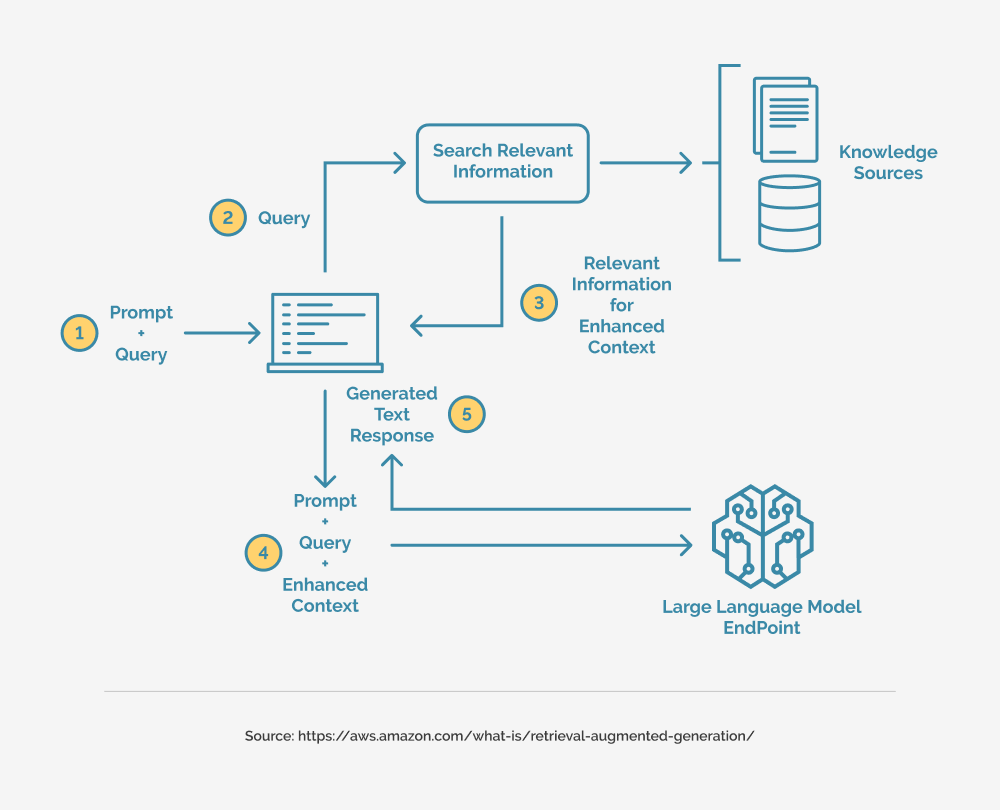
DeepSeek R1: A Smarter Approach to RAG
Traditional RAG models often retrieve irrelevant or overly broad content, but DeepSeek R1 employs advanced vectorization to surface precise, contextually relevant snippets—even from dense PDFs.
Think of it as a librarian who not only finds the right book but highlights the exact paragraph you need. In legal tech, it extracts key clauses from lengthy contracts, while in healthcare, it pinpoints dosage guidelines from medical manuals—no fluff, just facts.
Local deployment ensures data privacy, making it ideal for industries like finance and healthcare. Looking ahead, multi-modal integration could enhance its ability to bridge text with visual data for richer insights.
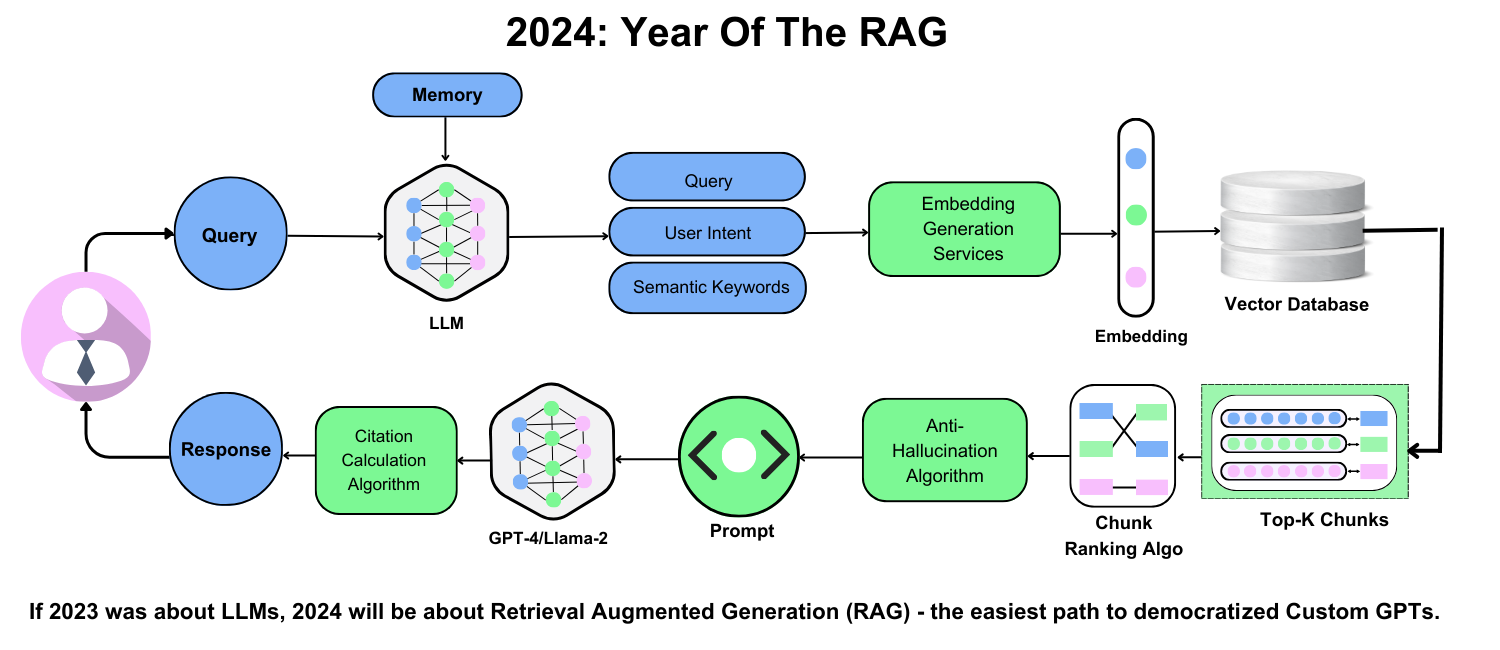
Synergy Between DeepSeek R1 and RAG Technologies
Most RAG systems fail because they treat retrieval and generation as separate silos. DeepSeek R1 changes the game by tightly integrating these processes. Its semantic vectorization doesn’t just retrieve data—it retrieves relevant data, even from dense PDFs. Relevance is everything when you’re answering complex queries.
In legal tech, DeepSeek R1 can extract case law precedents with pinpoint accuracy. It doesn’t just pull random paragraphs; it aligns retrieval with the user’s intent, ensuring the generated response is actionable.
The real magic happens when you fine-tune it with domain-specific embeddings. This approach bridges the gap between generic AI and specialized needs, making it a powerhouse for industries like healthcare, finance, and education.
Setting Up the Development Environment
Setting up a development environment can feel like assembling IKEA furniture without instructions. But with DeepSeek R1, it’s surprisingly straightforward—if you know the right steps.
First, ensure your system meets the minimum hardware requirements: 8 GB RAM and a modern CPU. DeepSeek R1’s semantic vectorization is computationally intensive. Think of it as a high-performance sports car—it needs the right track to shine.
Next, install Python (3.8 or higher) and the required libraries. Use this command to get started:
pip install deep-seek-r1 langchain transformers sentence-transformers
Finally, test your setup with a sample PDF. If it retrieves relevant data, you’re ready to build.
Pro tip: start with small PDFs to avoid overwhelming your system.
System Requirements and Prerequisites
DeepSeek R1 isn’t your average chatbot framework—it’s a powerhouse. But to unlock its full potential, your system needs to be up to the task.
At a minimum, you’ll need 8 GB of RAM, but for smoother performance, aim for 16 GB. DeepSeek R1’s advanced vectorization processes are memory-intensive, especially when handling large PDFs.
A solid-state drive (SSD) will drastically reduce latency when indexing documents in your vector database, ensuring faster retrieval. This is critical in real-time applications like customer support.
Finally, don’t underestimate the importance of a dedicated GPU. While not mandatory, it can accelerate tasks like semantic encoding, making your chatbot lightning-fast.
Installing DeepSeek R1 and Dependencies
When installing DeepSeek R1, the key is ensuring compatibility between your Python environment, libraries, and hardware.
Here’s where most people trip up: skipping virtual environments. Don’t.
Use venv or conda to isolate dependencies. It prevents version conflicts that can break your setup.
For example, DeepSeek R1 relies on vector databases like ChromaDB. Installing the wrong version can lead to indexing failures.
Always check the library’s documentation for version alignment. Pair this with the latest torch and transformers libraries for optimal performance.
Finally, optimize your GPU drivers. Many overlook this, but outdated drivers can bottleneck performance during semantic vectorization. Use tools like NVIDIA’s CUDA Toolkit to ensure compatibility.
Preparing Your PDF Data for Integration
Chunking your PDF data is the secret sauce for building a chatbot that doesn’t choke on complex queries.
Most people think splitting a PDF into pages is enough. It’s not. Instead, break the text into semantic chunks—small, meaningful sections that preserve context.
Smaller, context-rich chunks improve retrieval accuracy when paired with vector databases like ChromaDB.
Use libraries like PyPDF2 or pdfplumber to extract raw text. Then, apply sliding window techniques with overlap (e.g., 200 tokens with 50-token overlap). This overlap ensures no critical information gets lost between chunks.
Imagine a legal chatbot parsing contracts. Without chunking, it might miss cross-references between clauses. With it, you get precise, context-aware answers.
Building Your PDF Chatbot with DeepSeek R1 and RAG
Most PDF chatbots fail because they don’t understand the data—they just regurgitate it. That’s where DeepSeek R1 changes the game.
By combining semantic vectorization with RAG, it retrieves exactly what’s needed, no fluff, no hallucinations.
DeepSeek R1’s chain-of-thought reasoning ensures logical, context-aware responses. It’s like having a librarian who not only finds the book but flips to the exact page you need.
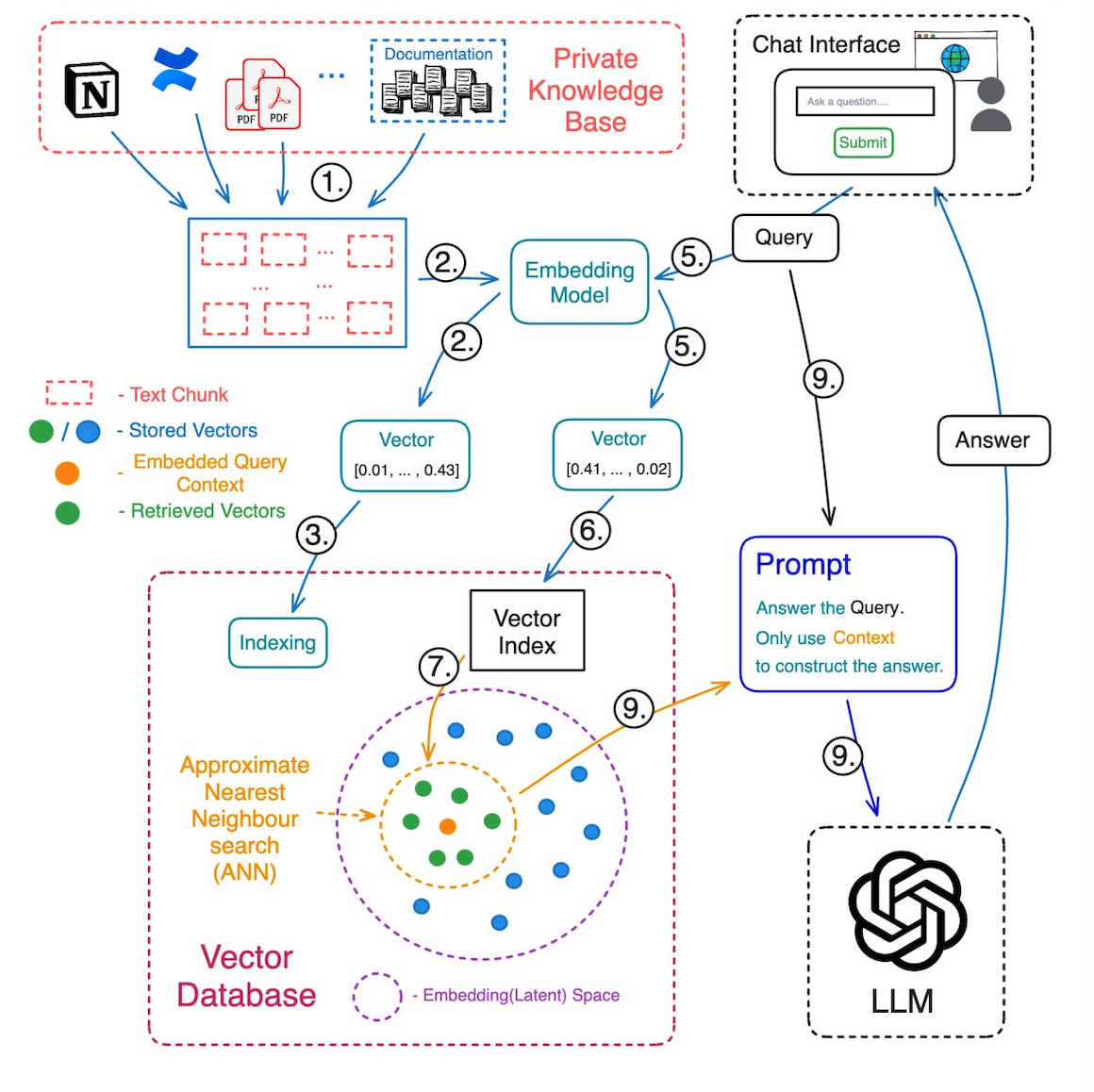
Designing the Chatbot Architecture
Without a purpose-built vector database, your chatbot is doomed to retrieve irrelevant or incomplete data. Traditional databases can’t handle the nuanced relationships between semantic chunks.
DeepSeek R1 thrives when paired with a high-performance vector database like Pinecone or Weaviate.
These systems store embeddings (think: mathematical fingerprints of your PDF chunks) and enable lightning-fast similarity searches. For example, in legal tech, this setup ensures your chatbot can instantly locate the exact clause from a 500-page contract.
Also, indexing strategy matters. Use hierarchical navigable small world (HNSW) indexing for dense datasets—it’s faster and more accurate. Ignore this, and you’ll face laggy responses and frustrated users.
Implementing Retrieval-Augmented Generation Techniques
Most people focus on retrieval algorithms, but here’s the secret: poorly structured queries can sabotage even the best systems.
With DeepSeek R1, you can leverage dynamic query reformulation to refine user inputs on the fly. This ensures the retriever fetches the most relevant chunks, even when queries are vague or overly complex.
For example, in healthcare, a doctor might ask, “What’s the recommended dosage for pediatric patients?” DeepSeek R1 can break this down semantically, prioritizing sections on dosage guidelines while ignoring unrelated content. This precision is powered by contextual embeddings, which capture subtle relationships between terms.
Best Practices and Troubleshooting
Building a PDF chatbot with DeepSeek R1 + RAG can feel like assembling IKEA furniture—straightforward on paper, but tricky in execution. Let’s simplify it.
Start with clean data. Think of your PDFs as ingredients for a recipe. If they’re messy—filled with irrelevant metadata or poorly scanned pages—your chatbot will serve up junk. Use tools like PyPDF2 to extract clean, structured text, and apply semantic chunking to preserve context.
Optimize your vector database. A slow database is like a bad Wi-Fi connection—it frustrates users. Choose high-performance options like Pinecone or Weaviate, and fine-tune embeddings for your domain. For example, a legal chatbot benefits from embeddings trained in case law.
Watch for hallucinations. If your chatbot starts making things up, it’s likely due to poor alignment between retrieval and generation. Implement feedback loops to refine responses over time.
Finally, test relentlessly. A chatbot is only as good as its weakest query.
Context Drifting in Long Queries and How to Overcome Them
When users ask complex, multi-part questions, chatbots often lose track of context midway. This happens because traditional RAG systems struggle to maintain semantic coherence across multiple retrievals.
Solution: Use context layering.
DeepSeek R1 excels here by embedding prior responses into follow-up queries, creating a conversational memory. For instance, in a legal chatbot, if a user asks about “precedents for breach of contract” and follows up with “how does this apply to healthcare?”, DeepSeek R1 ensures the second query retains the legal context.
Implement recursive chunking with overlapping windows. This ensures no critical information is lost during retrieval, especially in dense PDFs like medical journals or financial reports.
Context drift doesn’t just frustrate users—it undermines trust. By addressing it, you’re not just fixing a bug; you’re building a chatbot that feels intuitive and reliable.
Designing for User Experience and Accessibility
If you want your chatbot to truly resonate with users, focus on context persistence.
Most chatbots fail when users ask follow-up questions because they lose track of the conversation flow. DeepSeek R1’s context layering solves this by maintaining a memory of previous interactions, ensuring seamless transitions between queries.
Imagine a healthcare chatbot assisting a patient. If the user first asks about symptoms and then follows up with, “What should I do next?”, the chatbot must connect the dots. Without context layering, the response risks being generic or irrelevant. With it, the system retrieves actionable advice tailored to the initial query.
To implement this, use hierarchical indexing in your vector database. This organizes data by relevance and context, improving retrieval speed and accuracy.
Test accessibility with diverse user groups. Small tweaks, like simplifying medical jargon, can make your chatbot more inclusive and user-friendly.
FAQ
What are the key features of DeepSeek R1 that make it ideal for building a PDF chatbot?
DeepSeek R1’s semantic vectorization ensures precise data retrieval, while chain-of-thought reasoning enhances logical consistency. Its local deployment prioritizes privacy, and multilingual support expands accessibility, making it ideal for sensitive domains like legal, healthcare, and finance.
How does Retrieval-Augmented Generation (RAG) enhance the accuracy of chatbot responses?
RAG retrieves relevant, up-to-date data before generating responses, reducing inaccuracies. It leverages embeddings and similarity scoring to extract precise answers, minimizing hallucinations and ensuring factual accuracy with source citations.
What are the hardware and software requirements for setting up DeepSeek R1 locally?
Minimum: 16GB RAM (32GB recommended), SSD, multi-core CPU, or GPU for better performance.
Software: Python 3.8+, vector database (ChromaDB), and updated CUDA drivers for optimal retrieval speeds.
How can semantic chunking improve the performance of a PDF chatbot built with DeepSeek R1?
By breaking PDFs into meaningful, overlapping sections, semantic chunking preserves context while optimizing retrieval accuracy. This technique prevents misinterpretation of fragmented data, improving response precision for complex queries.
What are the best practices for integrating a vector database with DeepSeek R1 for efficient data retrieval?
Use high-performance databases like Pinecone or Weaviate with HNSW indexing. Preprocess PDFs with semantic chunking, keep embeddings updated, and refine query structure for better results. Testing with real queries ensures seamless integration.
Conclusion
Building a PDF chatbot with DeepSeek R1 and RAG isn’t just about creating another AI tool—it’s about solving real-world problems with precision and efficiency.
Think of it as upgrading from a flashlight to a laser: instead of scattering light everywhere, you’re focusing it exactly where it’s needed. This is what makes DeepSeek R1 stand out—it retrieves exactly the right information, even from dense, unstructured PDFs.