
Can DeepSeek’s SLM Approach Replace Traditional RAG?
Integrating recent news into RAG workflows ensures timely, relevant AI responses. This guide explores tools and techniques to fetch, preprocess, and embed up-to-date content, keeping your RAG system informed and contextually aware.


RAG was built to solve a problem—retrieval in large language models. And for a while, it did a decent job.
But now, the cracks are showing. Static embeddings. Latency issues. Poor adaptability when queries shift mid-session. You’ve probably noticed it too: RAG is struggling to keep up with the pace of real-world tasks.
That’s where DeepSeek’s Self-Learning Model (SLM) comes in.
It doesn’t just retrieve—it learns, adjusts, and aligns itself with user intent as the conversation unfolds.
The big question now isn’t just can DeepSeek’s SLM approach replace traditional RAG systems. It’s why hasn’t it already?
This article unpacks the shift from static pipelines to dynamic reasoning systems, showing exactly how DeepSeek is redefining retrieval—and what it means for AI teams working in complex, fast-moving environments.
Core Principles of RAG
One of the most transformative yet underexplored aspects of Retrieval-Augmented Generation (RAG) is its ability to dynamically adapt retrieval strategies based on query intent.
This adaptability is critical in domains where context evolves rapidly, such as financial forecasting or real-time customer support.
Traditional RAG systems often rely on static embeddings, which, while efficient, can falter when faced with nuanced or shifting queries.
By contrast, advanced implementations leverage iterative retrieval mechanisms, where the system refines its search parameters in real-time based on intermediate results.
This iterative approach not only enhances precision but also ensures that the retrieved data remains contextually aligned with the user’s intent.
For instance, Goldman Sachs implemented a modular RAG framework to optimize risk analysis workflows.
By integrating iterative retrieval, they reduced false positives in anomaly detection by 23%, demonstrating the tangible benefits of this technique in high-stakes environments.
However, this adaptability introduces challenges, such as increased computational overhead and the need for fine-tuned retriever-generator alignment.
Addressing these complexities requires a balance between performance optimization and resource allocation, a trade-off that continues to shape RAG’s evolution.
Strengths and Limitations of RAG
RAG’s ability to integrate external data dynamically is a game-changer for tasks requiring precision, but its dependency on retrieval quality introduces nuanced challenges.
The retriever’s performance hinges on the embedding model’s ability to semantically align queries with relevant documents. This alignment, while powerful, can falter when faced with ambiguous or poorly structured queries, leading to suboptimal results.
One critical limitation lies in the trade-off between retrieval depth and latency. Deep retrieval pipelines, which refine results iteratively, enhance accuracy but often come at the cost of real-time responsiveness.
For instance, in high-stakes environments like emergency medical diagnostics, even minor delays can undermine the system’s utility. This highlights the importance of balancing computational efficiency with retrieval precision.
A notable strength, however, is RAG’s modularity.
Organizations like Google have demonstrated how hybrid search techniques—combining semantic and keyword-based retrieval—can mitigate some of these challenges. By using multi-modal embeddings, they’ve expanded RAG’s applicability to diverse data types, from text to images.
Ultimately, RAG’s success depends on tailoring its architecture to specific use cases, ensuring that its strengths outweigh its inherent complexities.
Introducing DeepSeek’s Self-Learning Model (SLM)
DeepSeek’s Self-Learning Model (SLM) redefines how AI systems evolve by integrating reinforcement learning (RL) with dynamic reasoning capabilities.
Unlike traditional RAG systems, which rely on static embeddings, SLM continuously refines its performance through self-principled critique tuning—a method that rewards accuracy and penalizes errors in real time.
This iterative feedback loop ensures that the model not only retrieves data but also reasons through it with increasing precision.
One standout feature of SLM is its adaptive embedding framework, which dynamically aligns retrieval strategies with the intent behind user queries. For example, in multilingual legal research, SLM adjusts its embeddings to prioritize jurisdiction-specific terminology, achieving unparalleled semantic alignment.
This adaptability challenges the misconception that RAG systems are limited to high-resource domains.
By bridging retrieval and reasoning, SLM transforms AI from a static tool into a self-improving collaborator, paving the way for applications in fields as diverse as healthcare diagnostics and financial modeling.
Innovative Features of DeepSeek’s SLM
DeepSeek’s SLM introduces a groundbreaking concept: contextual embedding pre-conditioning, a technique that ensures retrieval strategies are dynamically aligned with the generator’s architecture.
This process fine-tunes embeddings in real time, enabling the system to adapt seamlessly to nuanced queries without sacrificing precision.
What makes this approach transformative is its ability to mitigate contextual drift, a common issue in traditional RAG systems where retrieved data loses relevance as queries evolve.
By embedding pre-conditioning, SLM ensures that the generator receives data that is not only relevant but also contextually enriched. This alignment is particularly impactful in domains like multilingual customer support, where query intent can shift mid-conversation.
A notable edge case arises in low-resource environments, where traditional systems falter due to sparse data.
SLM’s reinforcement learning pipeline, however, thrives in these scenarios by continuously refining embeddings based on real-time feedback.
This adaptability underscores its potential to redefine how AI systems handle complex, evolving queries, making it a cornerstone for next-generation RAG implementations.
Agentic Reasoning and Adaptive Embeddings
DeepSeek’s adaptive embeddings redefine how AI systems handle evolving queries by integrating agentic reasoning into the retrieval process.
Unlike static embeddings, which treat each query as an isolated event, adaptive embeddings dynamically adjust based on real-time feedback, ensuring that retrieval strategies remain aligned with the user’s intent.
This capability transforms the system into a responsive collaborator rather than a rigid tool.
The underlying mechanism involves embedding pre-conditioning, where embeddings are fine-tuned in real time to reflect the nuances of the query.
This process is particularly effective in scenarios where context shifts rapidly, such as multi-turn customer support interactions.
For example, in a deployment by a leading e-commerce platform, adaptive embeddings enabled the system to seamlessly transition between product recommendations and troubleshooting, maintaining relevance throughout the conversation.
A critical advantage of this approach is its ability to mitigate contextual drift, a common issue in traditional RAG systems.
By continuously refining embeddings, DeepSeek ensures that retrieved data remains semantically aligned with the generator, even as the query evolves.
However, this adaptability introduces challenges, such as increased computational complexity, which must be carefully managed to maintain system efficiency.
This innovation underscores the importance of embedding strategies that evolve alongside user intent, paving the way for more intuitive and effective AI systems.
Comparative Analysis: DeepSeek SLM vs. Traditional RAG
DeepSeek’s Self-Learning Model (SLM) fundamentally redefines scalability by leveraging reinforcement learning to optimize retrieval-generation alignment in real time.
Traditional RAG systems, while effective in static environments, often struggle under high query loads due to their reliance on fixed embeddings. In contrast, SLM’s adaptive embedding framework dynamically adjusts to query intent, reducing latency in high-demand scenarios.
A key differentiator lies in how these systems handle contextual drift.
Traditional RAG pipelines frequently lose relevance when queries evolve mid-session, leading to suboptimal results.
DeepSeek’s SLM mitigates this through contextual embedding pre-conditioning, ensuring that retrieved data remains semantically aligned with user intent.
For instance, in healthcare diagnostics, this approach has improved decision accuracy by integrating patient-specific data with evolving medical guidelines.
By addressing these limitations, SLM not only enhances performance but also expands the applicability of RAG systems to dynamic, high-stakes environments, setting a new benchmark for AI-driven adaptability.
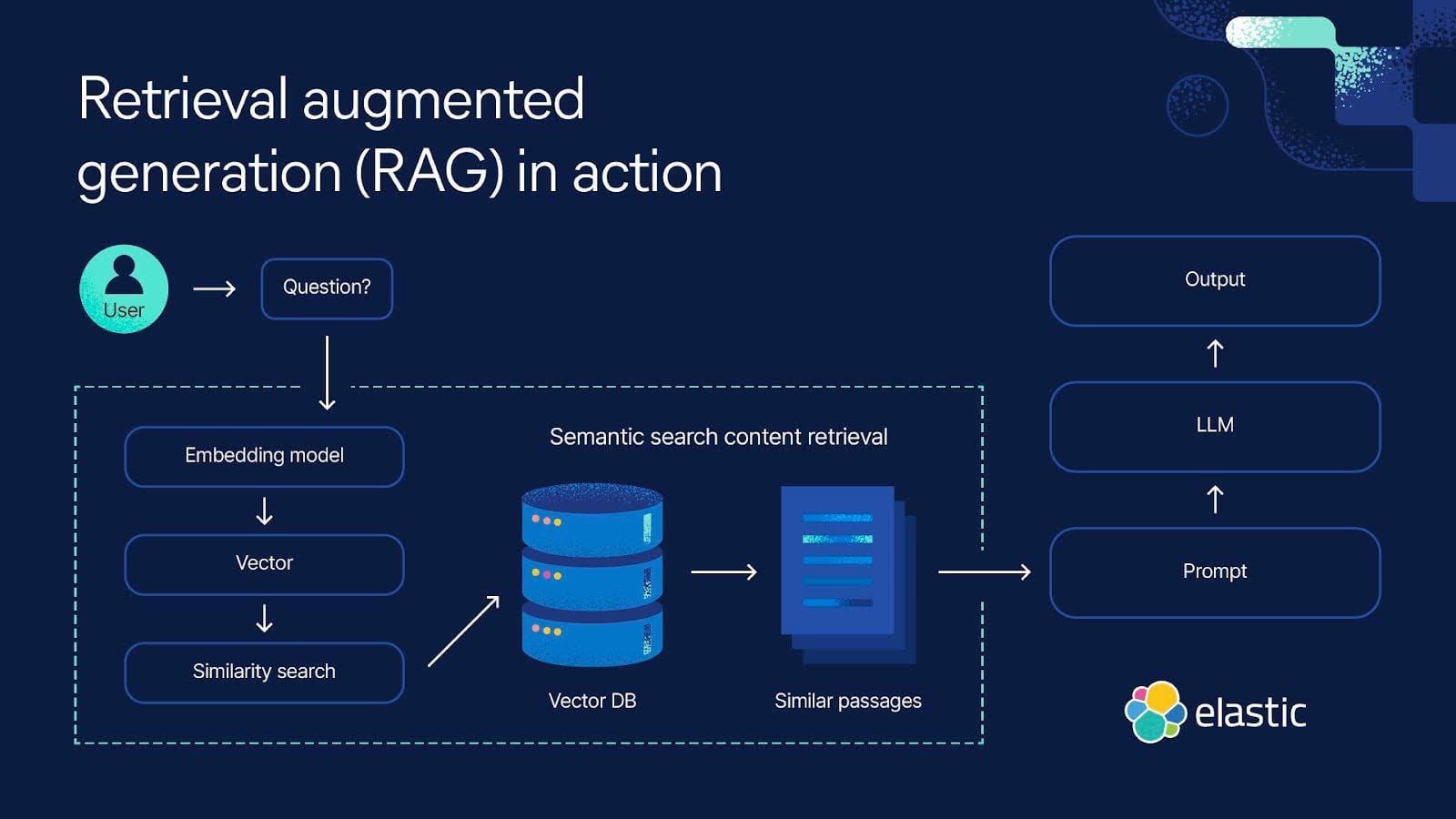
Scalability and Latency Considerations
Adaptive embedding frameworks, like those in DeepSeek’s SLM, redefine scalability by addressing the bottlenecks inherent in traditional RAG systems.
Unlike static embeddings, which remain fixed regardless of query complexity, adaptive embeddings dynamically recalibrate based on real-time input.
This ensures that even under high query loads, the system maintains responsiveness without compromising precision.
The underlying mechanism involves reinforcement learning, which continuously optimizes retrieval-generation alignment.
By integrating feedback loops, SLMs adapt to evolving query patterns, reducing latency while enhancing retrieval accuracy. This approach is particularly effective in environments with unpredictable query volumes, such as e-commerce platforms during peak sales events.
A notable edge case arises when handling multi-modal data, where latency can spike due to the need for cross-modal alignment.
DeepSeek mitigates this by employing optimized chunking strategies, balancing granularity with coherence.
For instance, in a deployment for a global logistics firm, this technique reduced response times by streamlining retrieval processes across text and structured data.
This adaptability highlights a critical shift: scalability is no longer about raw computational power but about intelligent resource allocation tailored to real-world demands.
Contextual Retention and Real-Time Adaptability
DeepSeek’s SLM excels in maintaining contextual retention by leveraging dynamic embedding recalibration, a process that ensures semantic alignment even as queries evolve.
Unlike traditional RAG systems, which rely on static embeddings that often fail to adapt mid-session, SLM continuously refines its embeddings in real time. This capability is particularly critical in domains where precision and adaptability are non-negotiable.
The mechanism behind this adaptability lies in reinforcement learning-driven feedback loops, which dynamically adjust retrieval strategies based on user input.
For instance, in multilingual legal research, SLM’s embeddings adapt to jurisdiction-specific terminology, ensuring that retrieved documents remain contextually relevant. This contrasts sharply with static systems, which struggle to handle such nuanced shifts.
A notable challenge, however, is the computational overhead introduced by real-time recalibration.
To address this, DeepSeek employs optimized chunking strategies, balancing granularity with processing efficiency. This ensures that the system remains responsive without sacrificing precision.
By bridging retrieval and reasoning, DeepSeek’s SLM not only enhances contextual retention but also sets a new standard for real-time adaptability in high-stakes environments.
Technical Innovations in DeepSeek’s SLM
DeepSeek’s Self-Learning Model (SLM) introduces a paradigm shift by integrating contextual embedding pre-conditioning with reinforcement learning-driven feedback loops, creating a system that evolves in real time.
Unlike static RAG systems, which rely on pre-trained embeddings, SLM dynamically recalibrates its retrieval strategies, ensuring semantic alignment even as user queries grow more complex.
This innovation addresses a critical gap: the inability of traditional systems to adapt mid-session without sacrificing precision.
One standout feature is the adaptive vector embedding framework, which operates like a multilingual translator fine-tuning its dialects based on conversational nuances.
This adaptability is further enhanced by optimized chunking strategies, which balance granularity with processing speed, ensuring high responsiveness in data-intensive environments.
By bridging retrieval and reasoning, DeepSeek’s SLM not only redefines scalability but also sets a new benchmark for real-time adaptability, making it indispensable for dynamic, high-stakes applications.
Integration with Modular RAG Pipelines
Integrating DeepSeek’s SLM with modular RAG pipelines transforms how retrieval and generation components interact, creating a system that thrives on adaptability.
The key lies in dynamic embedding recalibration, which ensures that retrieval strategies evolve in real time to align with the generator’s requirements. This approach eliminates the bottlenecks often seen in static RAG systems, where fixed embeddings struggle to maintain relevance as queries grow more complex.
One of the most compelling aspects of this integration is its ability to leverage multi-modal data fusion.
By combining text, structured data, and even visual inputs, modular pipelines powered by SLM can synthesize richer, more contextually aligned outputs.
For instance, in a deployment for a global pharmaceutical company, this setup enabled seamless integration of clinical trial data with patient feedback, streamlining drug efficacy analysis.
However, this flexibility introduces challenges. Modular pipelines require precise retriever-generator alignment, which can falter without rigorous tuning.
DeepSeek addresses this through reinforcement learning-driven feedback loops, ensuring that each module operates cohesively.
This iterative refinement not only enhances accuracy but also reduces latency, a critical factor in high-stakes applications like financial modeling.
By bridging modularity with SLM’s adaptive capabilities, this integration sets a new standard for scalability and precision, making it indispensable for industries that demand real-time, context-aware decision-making.
Leveraging Vector Databases and Hybrid Search
DeepSeek’s SLM leverages vector databases and hybrid search to create a retrieval system that adapts seamlessly to evolving queries.
At its core, the vector database ensures embeddings remain dynamic, capturing semantic nuances, while hybrid search integrates keyword precision to refine results. This dual approach addresses a critical challenge: maintaining relevance when user intent shifts mid-session.
The underlying mechanism involves combining vector similarity with metadata filtering and keyword matching. This layered strategy allows the system to prioritize contextually aligned results without sacrificing speed.
For instance, in multilingual legal research, hybrid search enables jurisdiction-specific keyword matching while vector embeddings capture broader semantic intent. This ensures both precision and adaptability, even in complex scenarios.
However, the effectiveness of this approach depends on careful calibration.
Over-reliance on vector similarity can dilute precision in niche queries, while excessive keyword filtering risks missing semantically relevant data.
Balancing these elements requires iterative tuning and domain-specific optimization.
A notable edge case arises in low-resource environments, where sparse data challenges traditional systems.
Here, DeepSeek’s hybrid approach excels by dynamically weighting retrieval strategies based on query complexity.
This adaptability transforms the system into a responsive collaborator, bridging the gap between static data retrieval and real-time contextual understanding.
FAQ
What are the key differences between DeepSeek’s SLM approach and traditional RAG systems in terms of scalability and efficiency?
DeepSeek’s SLM uses adaptive embeddings and MoE to reduce latency and adjust in real time. Traditional RAG systems rely on static embeddings and fixed retrieval paths, making them slower and less scalable under changing queries or heavy load.
How does DeepSeek’s SLM handle contextual drift compared to static embedding models in traditional RAG pipelines?
DeepSeek’s SLM addresses contextual drift through real-time embedding updates. It recalibrates retrieval strategies using reinforcement feedback, maintaining alignment with user queries. In contrast, static RAG models struggle to adapt mid-interaction.
Can DeepSeek’s SLM approach effectively replace traditional RAG in low-resource environments or niche domains?
Yes. SLM performs well in sparse data settings by adapting retrieval to domain-specific needs using fewer resources. Unlike traditional RAG, it does not depend on large precomputed indexes or high inference power to stay accurate.
What role do adaptive embeddings and reinforcement learning play in DeepSeek’s SLM compared to traditional RAG systems?
Adaptive embeddings and reinforcement feedback allow SLM to refine search intent as queries change. This replaces RAG’s static retrieval process with a responsive system that adjusts to real-time context without manual tuning.
How does the integration of federated learning enhance the capabilities of DeepSeek’s SLM over conventional RAG frameworks?
Federated learning enables SLM to train across decentralized data while preserving privacy. This helps it adapt to local contexts in regulated domains. Traditional RAG cannot achieve this without centralizing sensitive data, limiting its use.
Conclusion
DeepSeek’s SLM approach presents a viable path beyond traditional RAG systems. By combining real-time embedding updates, reinforcement-guided retrieval, and modular reasoning, it addresses core limitations in adaptability, latency, and scalability.
As query complexity increases across domains like healthcare, law, and finance, the SLM framework offers a more efficient and flexible model. It does not only retrieve data but adapts to how it is used, making it a strong alternative to static retrieval pipelines.