
Document Storage Strategies in RAG: Separate vs Combined with Vector DB
Choosing between separate and combined document storage with vector DBs impacts RAG performance. This guide explores pros, cons, and best practices for each approach to help you optimize retrieval speed, accuracy, and system scalability.


Most retrieval-augmented generation (RAG) systems don’t fail because of poor models—they fail because of poor document storage strategies.
When documents and vector embeddings aren’t stored right, even the most advanced pipelines slow down, drift out of sync, or surface irrelevant data.
At the core of this problem is one decision: should documents and vectors be stored together in the same system or separately?
This isn’t just about architecture—it shapes how well your RAG system scales, how easily it handles metadata, and how fast it retrieves useful results.
In some cases, the wrong choice adds latency or causes mismatched results. In others, it holds back entire applications from moving to production.
In this article, we’ll break down the two main document storage strategies in RAG—separate and combined with vector databases. We’ll look at the trade-offs, real-world examples, and which setup works best for different kinds of systems.
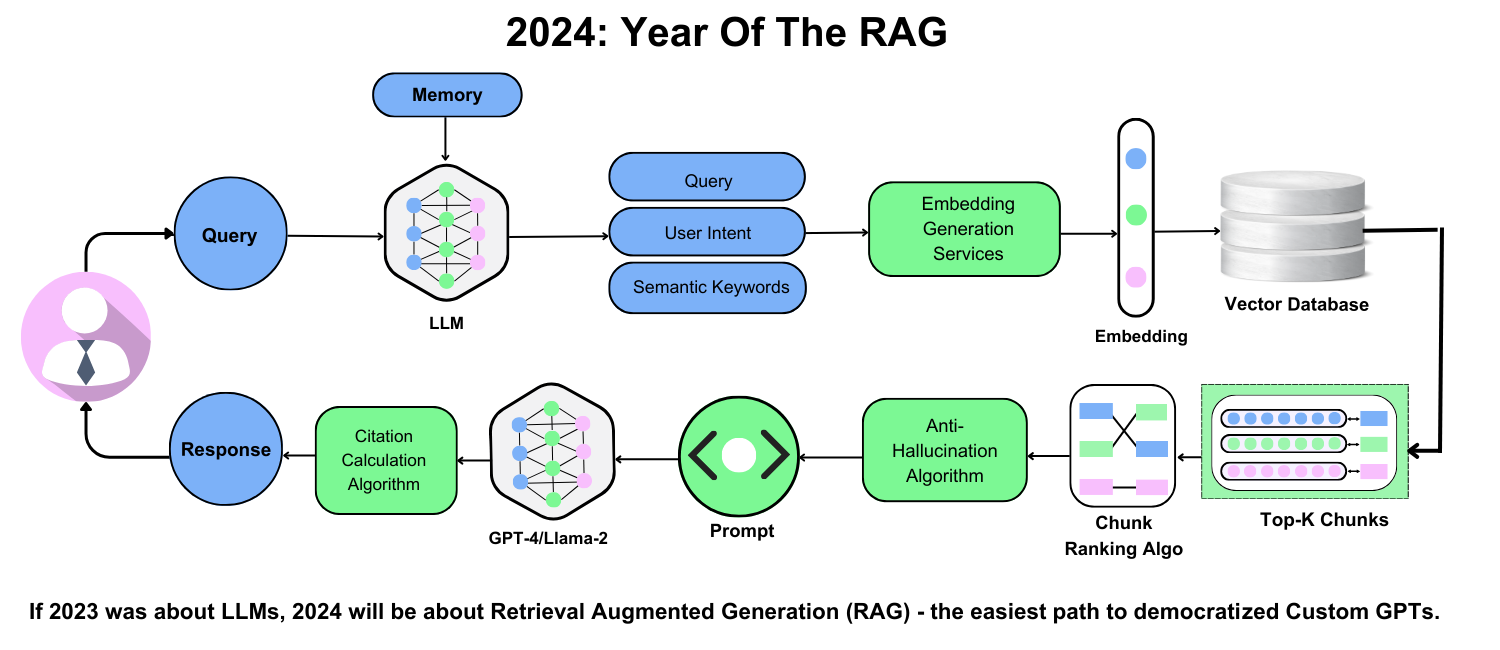
Core Concepts of RAG Systems
One often-overlooked aspect of RAG systems is the interplay between chunking strategies and embedding quality.
At its core, chunking determines how documents are segmented, directly influencing the granularity of semantic search and the relevance of retrieved content. This process is not merely technical—it shapes the system’s ability to maintain contextual integrity.
The choice of chunking strategy matters because it dictates how embeddings capture meaning.
For instance, hierarchical chunking, which organizes content into nested sections, excels in preserving context across complex documents like legal contracts.
However, it can introduce redundancy, as overlapping sections may inflate storage requirements.
In contrast, sentence-based chunking minimizes overlap but risks losing broader context, especially in narrative-heavy texts.
A critical nuance lies in prefixing chunks with metadata. By appending concise summaries or tags to each chunk, embeddings gain an additional layer of semantic clarity.
Ultimately, the art of chunking lies in balancing granularity with coherence, ensuring retrieval systems remain precise and scalable.
Role of Vector Databases in RAG
Vector databases are not merely repositories but the operational backbone of RAG systems, enabling precise and scalable retrieval.
A critical yet underexplored feature is their ability to integrate metadata directly into the vector indexing process.
This integration allows for multi-dimensional filtering, where queries can simultaneously consider semantic similarity and metadata constraints, such as document type or timestamp.
This dual-layered retrieval ensures that results are relevant and contextually aligned with the query’s intent.
One notable implementation of this approach is seen in hybrid search systems, which combine vector similarity with keyword-based filtering.
For instance, platforms like ElasticSearch allow developers to specify weighted combinations of these methods, optimizing for both precision and recall.
However, this hybridization introduces trade-offs: while it enhances flexibility, it can increase computational overhead, particularly for large-scale datasets.
By embedding metadata into the retrieval pipeline, vector databases bridge the gap between abstract numerical representations and real-world application needs, offering a nuanced balance of performance and relevance.
Combined Storage Approach: Benefits and Challenges
Integrating document storage directly within vector databases offers a streamlined architecture that simplifies query execution and reduces system complexity.
By co-locating documents and their embeddings, retrieval pipelines eliminate the need for cross-system synchronization, enabling faster query resolution.
However, this approach introduces scalability constraints as datasets expand. Combined storage systems often face bottlenecks in indexing and retrieval when handling billions of vectors.
Ultimately, the combined storage approach is similar to a tightly packed toolbox—efficient for small-scale tasks but requiring meticulous organization to remain functional as the workload grows.
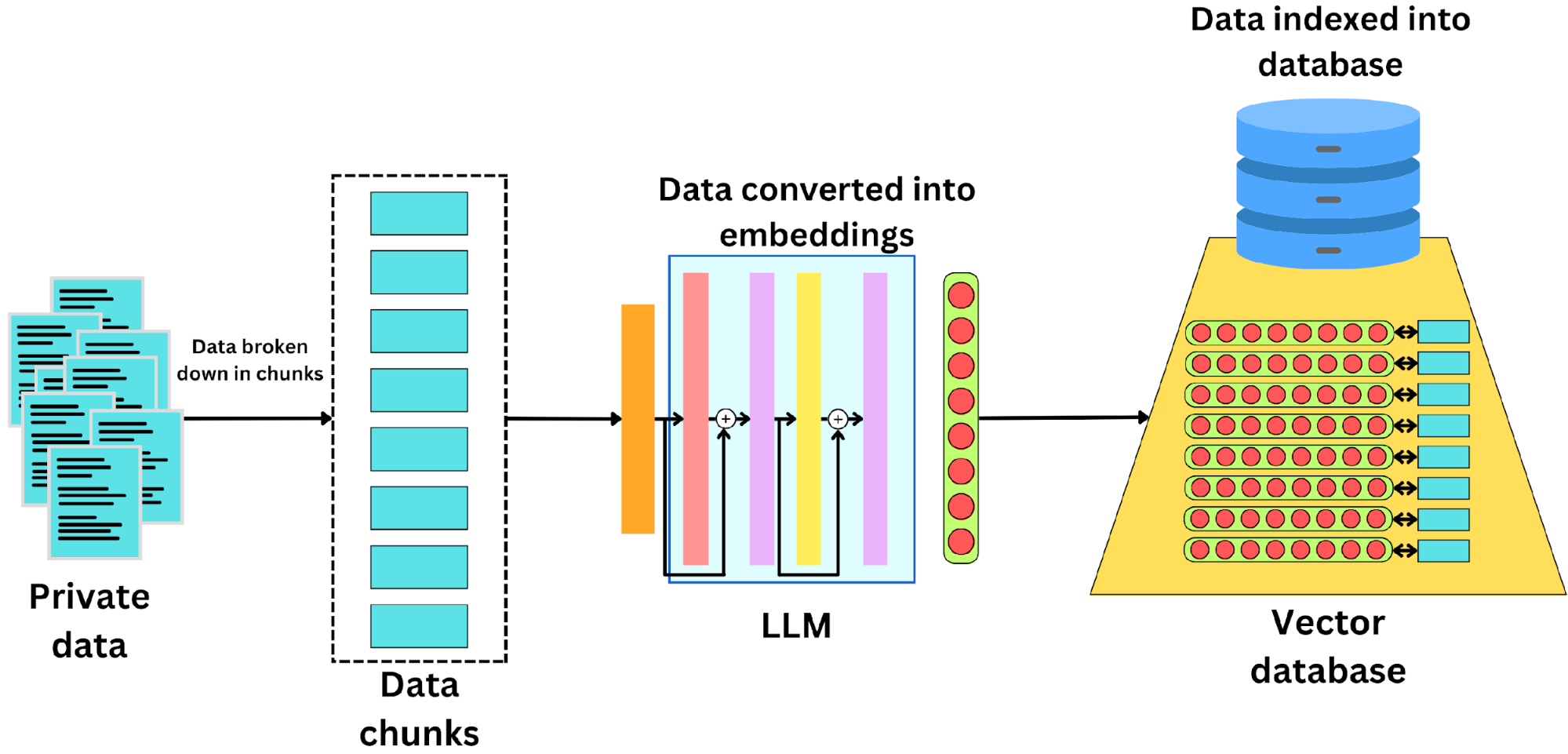
Simplifying Queries with Combined Storage
Merging document storage with vector databases fundamentally transforms query execution by eliminating the need for cross-system synchronization.
This integration allows both document content and contextual embeddings to be retrieved in a single operation, streamlining workflows and reducing latency.
The simplicity of this approach is particularly advantageous in environments where rapid prototyping and iterative development are critical.
However, the hidden complexity lies in managing metadata alongside vector embeddings.
When embedded directly, metadata becomes an intrinsic part of the retrieval process, enabling multi-dimensional filtering. Yet, this also introduces challenges in maintaining consistency and avoiding redundancy.
A practical example of this is seen in healthcare applications, where combined storage enables real-time retrieval of patient records with contextual annotations.
This approach not only accelerates query resolution but also ensures that results are contextually aligned with clinical needs.
To scale effectively, organizations must adopt advanced sharding techniques and modular indexing frameworks.
These strategies ensure that the benefits of combined storage—simplicity and speed—are not undermined by the complexities of large-scale deployments.
Scalability Concerns in Combined Storage
The scalability of combined storage systems hinges on how effectively they manage the interplay between vector embeddings and document metadata.
A critical challenge arises when indexing strategies fail to account for the exponential growth of both data volume and query complexity.
This often leads to index fragmentation, where retrieval efficiency deteriorates as datasets expand.
One overlooked factor is the role of shard alignment with query patterns.
Poorly aligned shards can create hotspots, overloading specific nodes while others remain underutilized.
For instance, Netflix mitigates this by dynamically redistributing shards based on real-time usage, ensuring balanced workloads.
However, this approach demands robust monitoring and adaptive algorithms, which can introduce additional computational overhead.
A novel approach involves modular indexing frameworks that decouple metadata from embeddings, allowing independent scaling.
Spotify employs this method, which reduces redundancy and optimizes retrieval latency. Yet, it requires meticulous governance to prevent inconsistencies, especially in distributed environments.
Ultimately, scalability in combined storage is a balancing act.
Success depends on proactive measures like shard optimization, modular indexing, and continuous performance audits, ensuring systems remain efficient as they scale.
Separate Storage Approach: Advantages and Trade-offs
Separating document storage from vector embeddings offers unparalleled flexibility, particularly in environments where metadata precision is paramount.
Organizations can independently optimize each layer by isolating these components, enabling faster reindexing and more granular metadata updates.
This approach also enhances fault tolerance. In the event of system failures, embedding databases can be restored without impacting the raw document storage, ensuring data integrity.
However, the trade-off lies in the complexity of synchronization. Maintaining alignment between disparate systems requires robust APIs and real-time indexing mechanisms, which can introduce latency if not meticulously designed.
A practical analogy is a modular kitchen: while separate components like ovens and refrigerators offer customization, they demand seamless coordination.
Similarly, separate storage systems excel in adaptability but require advanced orchestration to avoid inefficiencies. This trade-off is often worth the investment for organisations prioritising scalability and precision.
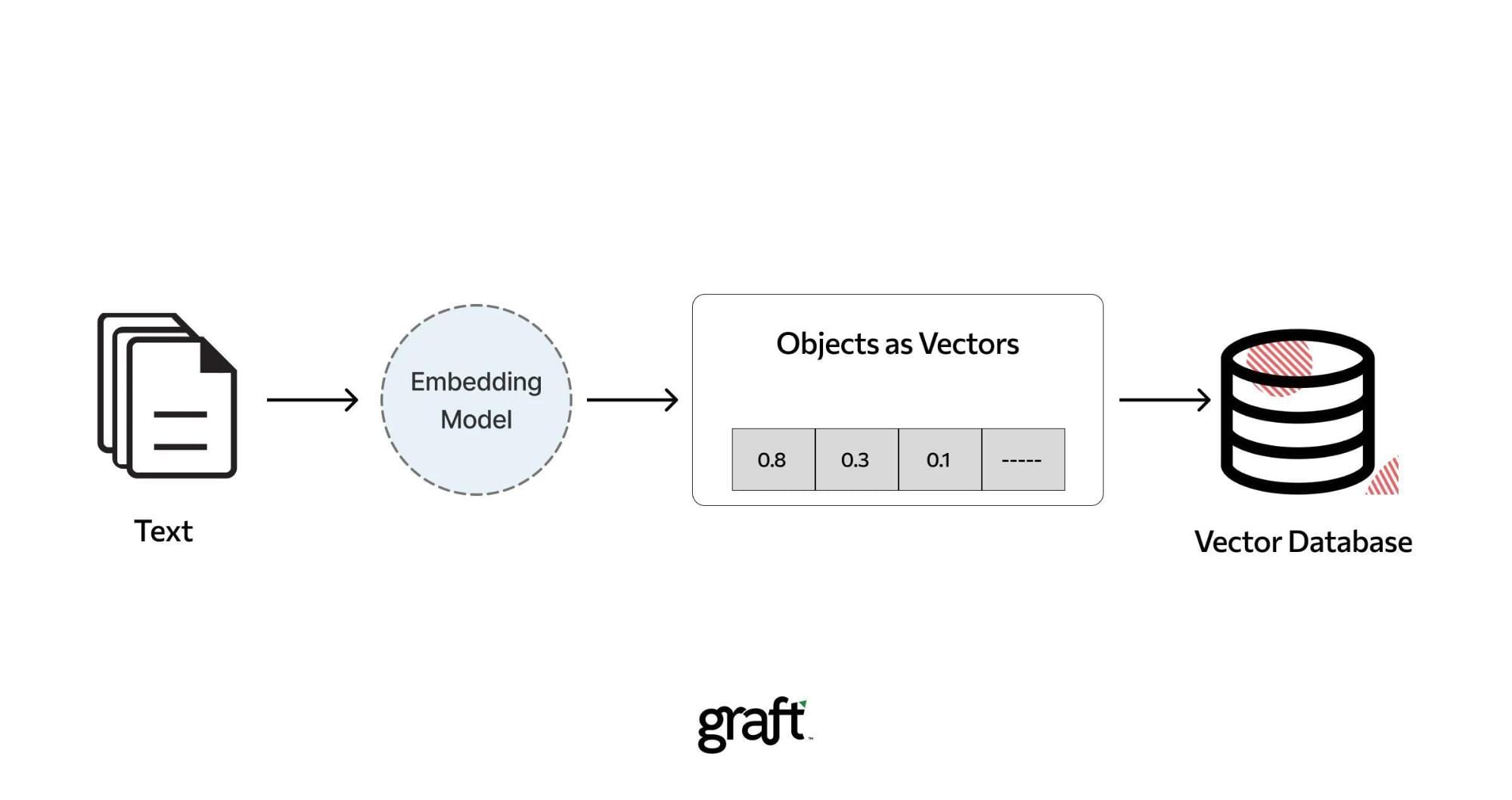
Enhanced Metadata Management
Decoupling document storage from vector embeddings unlocks a unique advantage: the ability to independently refine metadata schemas without disrupting the embedding layer.
This separation allows organizations to craft domain-specific metadata structures, enabling more precise filtering and retrieval.
For instance, in industries like life sciences, where datasets often include intricate hierarchies, tailored metadata schemas can significantly enhance the relevance of search results.
A critical mechanism underpinning this approach is the use of API-driven synchronization. By leveraging APIs to manage real-time updates, organizations can mitigate the synchronization overhead often cited as a drawback of separate storage.
This orchestration ensures that metadata remains consistent across systems, even as datasets evolve.
The flexibility to update metadata independently also supports agile workflows, particularly in environments requiring frequent schema adjustments.
However, this approach is not without challenges.
The complexity of maintaining alignment between metadata and embeddings can introduce latency if poorly managed.
Yet, when executed effectively, the ability to fine-tune metadata independently transforms it into a strategic asset, driving both operational efficiency and data-driven decision-making.
Flexibility and System Maintenance
Decoupling document storage from vector embeddings offers unparalleled flexibility in system maintenance, particularly when metadata updates are frequent or complex.
This separation allows metadata schemas to evolve independently, enabling organizations to adapt to changing requirements without disrupting the embedding layer.
For instance, industries like finance benefit significantly from this modularity, where compliance regulations shift rapidly.
The underlying mechanism driving this flexibility is the use of real-time synchronization protocols.
These protocols ensure that updates to metadata are immediately reflected across systems, minimizing latency and maintaining consistency.
However, achieving this requires robust API frameworks and advanced indexing algorithms. Without these, synchronization delays can lead to mismatches, undermining the system’s reliability.
Technical Considerations in Document Chunking
Effective document chunking hinges on three interdependent factors: chunk boundaries, overlap configuration, and metadata integration. Each decision here directly impacts retrieval precision and system scalability.
First, the choice of chunk boundaries—whether semantic, syntactic, or token-based—determines how well the system preserves context.
For instance, semantic chunking, which aligns with natural topic shifts, often outperforms rigid token-based methods in maintaining coherence, especially in unstructured datasets like customer reviews.
Overlap configuration is equally critical.
While overlapping chunks enhance cross-chunk context, excessive overlap inflates storage and retrieval costs.
Finally, metadata integration transforms chunks into actionable units. Embedding metadata such as source, position, or creation time enables multi-dimensional filtering, crucial for applications like legal research.
This interplay between structure and retrieval precision underscores the strategic importance of chunking in RAG pipelines.
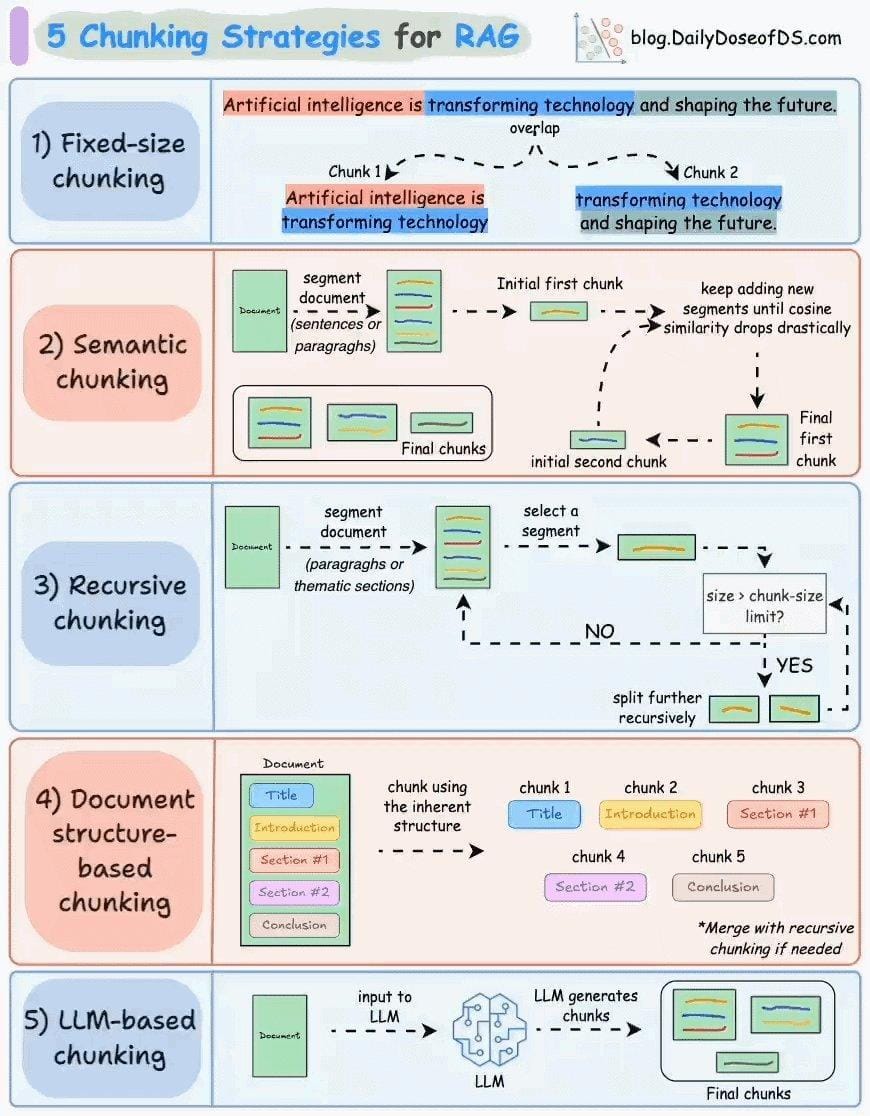
Effective Chunking Strategies
Semantic chunking is a transformative approach for maintaining contextual integrity in RAG systems.
By grouping related ideas into cohesive units, it ensures that each chunk represents a complete and meaningful concept.
This technique is particularly effective for unstructured or multi-topic documents, where logical flow is paramount.
The underlying mechanism involves leveraging natural language processing (NLP) models to detect semantic boundaries, such as topic shifts or narrative transitions.
Unlike token-based methods, which risk fragmenting ideas, semantic chunking aligns with the document’s inherent structure, preserving coherence. However, its computational demands can be significant, as it requires advanced models to identify nuanced shifts in meaning.
A comparative analysis reveals that while fixed-size chunking offers simplicity, it often disrupts logical flow, making semantic chunking a superior choice for applications like legal research or academic retrieval.
Yet, edge cases, such as ambiguous transitions between topics, can challenge even the most sophisticated algorithms.
Organizations should combine semantic chunking with metadata tagging to implement this effectively, enabling multi-dimensional filtering.
This hybrid approach enhances retrieval precision and adapts seamlessly to diverse document types, making it a cornerstone of advanced RAG pipelines.
Choosing the Right Embedding Models
The choice of embedding model profoundly shapes the semantic fidelity of document chunks, particularly in domain-specific applications.
A critical yet underappreciated factor is the alignment between the embedding model’s training data and the structural nuances of your content.
Models pre-trained on general datasets often fail to capture the intricate relationships within specialized texts, such as legal contracts or medical records.
To address this, fine-tuning embedding models on domain-specific corpora can significantly enhance their contextual sensitivity.
This process involves retraining the model on a curated dataset that mirrors your documents' tone, terminology, and structure.
Another advanced technique is multi-model integration, where embeddings from multiple models are combined to capture diverse semantic dimensions.
While computationally intensive, this approach excels in high-level abstraction and granular detail scenarios.
Ultimately, selecting and refining embedding models demands a balance between domain alignment, computational efficiency, and retrieval precision, ensuring the system meets technical and operational goals.
FAQ
What are the key differences between RAG systems' separate and combined document storage strategies?
Separate storage splits documents and vector embeddings, allowing flexible metadata updates and easier scaling. Combined storage keeps both together in one system, simplifying queries but increasing the risk of performance issues as data grows.
How does metadata management impact the efficiency of separate vs combined storage in vector databases?
Separate storage supports more flexible metadata changes, useful for evolving schemas. Combined storage simplifies retrieval by bundling metadata with vectors but may cause redundancy. Efficiency depends on aligning storage design with system needs.
What scalability challenges arise when integrating document storage with vector embeddings in RAG architectures?
Due to redundant indexing and latency across distributed nodes, combined storage can create bottlenecks as data grows. It also increases resource demand during updates. Scalable solutions need adaptive sharding and modular indexing to keep performance steady.
Which industries benefit most from separate document storage strategies in retrieval-augmented generation systems?
Due to strict metadata rules and frequent updates, sectors like healthcare, finance, and legal services benefit from separate storage. This setup supports better control over compliance, document structures, and long-term flexibility in dynamic environments.
How do combined storage approaches influence query performance and latency in large-scale RAG deployments?
Combined storage improves speed for frequent queries by avoiding system hops. But at scale, it can raise latency from storage duplication and indexing limits. Efficient indexing and workload balancing are needed to keep queries fast in large deployments.
Conclusion
Choosing between separate and combined document storage strategies in RAG systems depends on data volume, metadata complexity, and long-term performance needs.
Combined storage offers speed and simplicity for smaller or static workloads. Separate storage allows fine control and better scalability in data-heavy, regulated environments.
As RAG systems grow more complex, hybrid models are gaining ground—blending flexibility with performance by adapting storage to real-time needs.
Whether optimizing for compliance or latency, the right strategy aligns storage with how information is retrieved, indexed, and maintained across the RAG pipeline.