
Does ChatGPT Use RAG? Answering Frequently Asked Questions
This guide explores whether ChatGPT uses Retrieval-Augmented Generation (RAG), clarifies misconceptions, and answers key questions.



A cutting-edge AI like ChatGPT, celebrated for its conversational prowess, might not actually know everything in real time. Surprising, right? Despite its ability to generate human-like responses, ChatGPT relies solely on pre-trained data, which means it can’t inherently access or retrieve up-to-date information. This limitation raises a critical question: how can AI systems bridge the gap between static knowledge and the dynamic, ever-changing world?
Enter Retrieval-Augmented Generation (RAG), a game-changing approach that combines the generative power of AI with real-time data retrieval. As businesses and researchers push for more accurate, context-aware AI, understanding whether ChatGPT employs RAG isn’t just a technical curiosity—it’s a window into the future of AI innovation.
So, does ChatGPT use RAG? And if not, what does that mean for its capabilities and limitations? Let’s unravel this tension and explore the broader implications for AI’s evolution.
Understanding ChatGPT and Its Capabilities
At its core, ChatGPT operates as a generative model built on the GPT architecture, excelling in producing coherent and contextually relevant text. However, its reliance on pre-trained data introduces a critical limitation: it cannot adapt to real-time changes or retrieve external information dynamically. This static nature makes it highly effective for general-purpose tasks but less suited for scenarios requiring up-to-date or domain-specific knowledge.
Consider customer support in industries like finance or healthcare. Here, accuracy and timeliness are non-negotiable. Without mechanisms like Retrieval-Augmented Generation (RAG), ChatGPT risks providing outdated or incomplete responses, which could erode user trust. This limitation underscores the importance of integrating retrieval systems to enhance its utility.
Interestingly, ChatGPT’s design prioritizes linguistic fluency over factual accuracy, a trade-off that works well for creative tasks but falters in high-stakes environments. Moving forward, bridging this gap could redefine how AI systems balance generative creativity with factual precision.
Introduction to Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) revolutionizes AI by combining generative models with retrieval mechanisms, enabling systems to access external, up-to-date information dynamically. Unlike traditional language models, which rely solely on pre-trained data, RAG integrates a retriever module to fetch relevant documents from a knowledge base, enhancing both accuracy and contextual relevance.
For instance, in legal research, RAG systems can retrieve case law or statutes in real time, synthesizing them into concise summaries. This approach not only improves efficiency but also reduces the risk of outdated or incomplete responses—a common limitation in static models.
Bi-directional retrieval plays a crucial role in refining query results by allowing information to flow both forward and backward, enhancing contextual relevance and accuracy. This technique, coupled with reinforcement learning, optimizes retrieval strategies over time. As industries demand more reliable AI, RAG’s ability to bridge generative creativity with factual precision positions it as a cornerstone for future advancements in AI applications.
Purpose and Structure of This Article
This article is designed to demystify the relationship between ChatGPT and Retrieval-Augmented Generation (RAG), offering a structured exploration of their interplay. By addressing common misconceptions, it highlights how RAG’s retrieval mechanisms complement generative models, particularly in scenarios requiring real-time data integration.
The structure follows a progressive inquiry model, starting with foundational concepts and advancing to nuanced technical comparisons. For example, the section on RAG’s bi-directional retrieval emphasizes its ability to refine outputs iteratively, a feature critical for applications like medical diagnostics or financial forecasting.
Unlike static models, RAG’s performance heavily depends on the quality and diversity of its external databases. This raises questions about ethical data sourcing and bias mitigation, which are explored in later sections.
By framing these discussions within actionable insights, the article equips readers to evaluate AI tools critically, fostering informed decision-making in dynamic fields.
Fundamentals of ChatGPT
ChatGPT operates on the Generative Pre-trained Transformer (GPT) architecture, a model designed to generate human-like text by predicting the next word in a sequence. Its strength lies in its ability to process vast datasets during pre-training, enabling it to produce coherent and contextually relevant responses across diverse topics. However, this reliance on static training data introduces a critical limitation: it cannot access or incorporate real-time information.
ChatGPT does not update its knowledge base dynamically, which can lead to outdated or inaccurate responses in fast-evolving fields like finance or healthcare.Think of ChatGPT as a well-read but isolated scholar—it excels at drawing from its pre-existing knowledge but struggles to adapt to new information without external updates. This limitation underscores the growing interest in hybrid models like RAG.
Architecture and Training of Language Models
At the core of ChatGPT’s architecture is the Transformer model, which revolutionized natural language processing by introducing the self-attention mechanism. This mechanism allows the model to weigh the importance of each word in a sentence relative to others, enabling it to capture nuanced relationships and context. For example, in a legal document, it can discern the significance of terms like “notwithstanding” in shaping the meaning of entire clauses.
Training involves two critical phases: pre-training and fine-tuning. During pre-training, the model digests massive datasets, learning linguistic patterns and structures. Fine-tuning refines this knowledge for specific tasks, often guided by techniques like Reinforcement Learning from Human Feedback (RLHF), which aligns outputs with human preferences.
The model’s reliance on tokenization—breaking text into subwords—has implications for multilingual applications. Languages with complex morphology, like Finnish, challenge tokenization efficiency, sparking innovations in adaptive tokenization strategies. These advancements hint at broader applications in cross-lingual AI systems.
Strengths and Limitations
A key strength of ChatGPT lies in its scalability and ability to generate fluent, contextually relevant text across diverse domains. This makes it invaluable for applications like customer support, where rapid, coherent responses are essential. However, its reliance on static pre-trained data introduces a critical limitation: temporal irrelevance. For instance, in dynamic fields like finance, ChatGPT may confidently provide outdated stock information, undermining trust in high-stakes scenarios.
While ChatGPT excels at summarizing broad topics, it struggles with domain-specific precision. In medicine, for example, it might misinterpret nuanced terminology, leading to plausible but incorrect advice. This highlights the need for fine-tuning on specialized datasets.
To address these gaps, integrating retrieval mechanisms like RAG could enhance real-time accuracy. Additionally, embedding domain-specific validation layers could mitigate risks in critical applications, paving the way for safer, more reliable AI deployments.
Use Cases in Various Domains
One standout use case for ChatGPT is education, where it serves as a personalized tutor. By generating tailored explanations and practice questions, it adapts to individual learning styles. For example, students preparing for standardized tests can use ChatGPT to simulate exam scenarios, receiving instant feedback and clarification on errors. However, its lack of real-time data limits its ability to address curriculum changes or recent discoveries.
In healthcare, ChatGPT supports administrative tasks like appointment scheduling and patient triage. Yet, its inability to access live medical databases restricts its utility in providing up-to-date treatment guidelines. This is where integrating RAG could revolutionize outcomes, enabling real-time retrieval of medical literature for evidence-based recommendations.
ChatGPT can flag inappropriate content, but its contextual understanding is imperfect. Combining it with RAG could enhance accuracy by referencing external guidelines, offering a scalable framework for safer digital environments.
Deep Dive into Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) transforms AI by bridging static knowledge with dynamic, real-time data. Unlike traditional models that rely solely on pre-trained datasets, RAG integrates external retrieval systems, enabling responses grounded in the latest information. Think of it as a librarian who not only remembers every book but also fetches the newest editions on demand.
RAG does not eliminates errors entirely. While it reduces “hallucinations,” its effectiveness depends on the quality of external data. By combining retrieval with robust validation mechanisms, RAG offers a scalable framework for AI systems to evolve alongside human knowledge.
Mechanisms of RAG
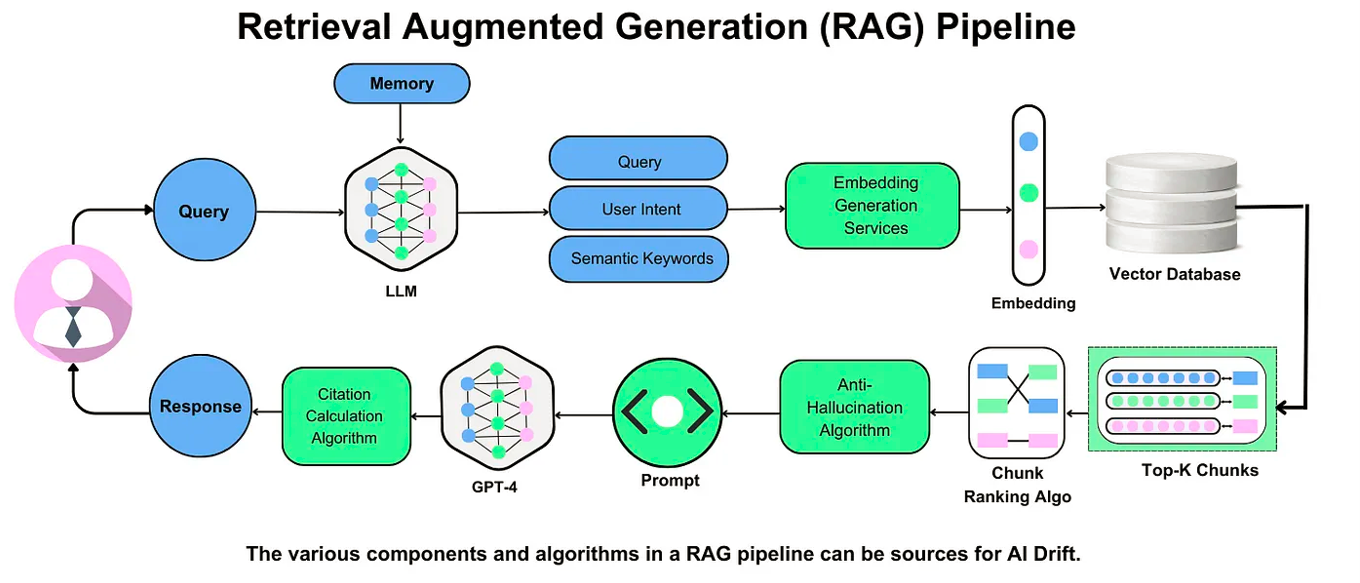
At its core, RAG operates through three tightly integrated mechanisms: retrieval, augmentation, and generation. The retrieval phase uses advanced semantic search to extract relevant data from external sources, such as APIs or real-time databases. This ensures that the model’s responses are not just fluent but also contextually accurate—a critical advantage in dynamic fields like finance or healthcare.
The augmentation step enriches the retrieved data by aligning it with the user’s query. For example, in legal research, RAG systems can cross-reference case law with statutes, creating a nuanced response tailored to the specific legal context. This process minimizes irrelevant information while enhancing precision.
Finally, the generation phase synthesizes the augmented data into coherent, actionable outputs. Reinforcement learning fine-tunes the system over time, improving its ability to prioritize high-quality sources. This iterative refinement positions RAG as a cornerstone for scalable, real-time AI solutions.
Advantages Over Traditional Language Models
One standout advantage of RAG is its ability to reduce hallucinations—a persistent issue in traditional language models. By integrating external retrieval systems, RAG grounds its responses in verifiable data, ensuring outputs are not only fluent but also factually accurate. For instance, in customer support, RAG can pull real-time product details from a database, eliminating the risk of outdated or fabricated information.
Traditional models require costly retraining to incorporate new knowledge, whereas RAG dynamically accesses updated sources. This makes it invaluable in fields like medicine, where accessing the latest research or clinical guidelines is non-negotiable.
By diversifying its retrieval sources, it reduces reliance on potentially skewed training data. Moving forward, organizations can leverage RAG to build AI systems that are not only more accurate but also more transparent and equitable.
Examples of RAG in Action
One compelling application of RAG is in legal research and document review, where precision and timeliness are paramount. By retrieving statutes, case law, and legal precedents from vast databases, RAG enables lawyers to streamline their workflow. Unlike traditional methods, which rely on static knowledge, RAG dynamically updates its outputs, ensuring relevance to the latest legal developments.
In healthcare, RAG-powered systems assist doctors by synthesizing clinical guidelines and recent medical studies. For example, a physician diagnosing a rare condition can access the most current research in seconds, improving diagnostic accuracy and patient outcomes. This capability bridges the gap between static AI models and the fast-evolving medical field.
Multimodal applications, such as combining text and image data, offer significant potential for enhancing AI capabilities and contextual understanding.For instance, RAG can analyze medical imaging alongside textual patient records, offering a holistic diagnostic tool. These innovations hint at a future where RAG reshapes decision-making across industries.
Analyzing ChatGPT’s Use of RAG
ChatGPT, as it stands, does not inherently use Retrieval-Augmented Generation (RAG). Instead, it relies on a static knowledge base derived from pre-training on vast datasets. This limitation means it cannot access real-time information or dynamically retrieve external data, often leading to outdated or inaccurate responses in fast-evolving contexts.
To illustrate, consider a query about recent advancements in renewable energy. ChatGPT might generate a fluent response, but without RAG, it cannot pull the latest research or policy updates. In contrast, a RAG-enabled system could retrieve and integrate live data, offering a more precise and timely answer.
ChatGPT's linguistic fluency can mimic informed responses, but this fluency is not grounded in real-time retrieval, as it does not use RAG. Integrating RAG into ChatGPT could bridge this gap, enabling it to combine generative capabilities with dynamic, context-aware accuracy—a potential game-changer for industries requiring up-to-date insights.
Current Implementation in ChatGPT
ChatGPT’s architecture is fundamentally static, relying on pre-trained data without real-time retrieval mechanisms. This design prioritizes linguistic fluency over dynamic adaptability, making it effective for general-purpose tasks but less suited for domains requiring up-to-date or domain-specific knowledge. For instance, when asked about breaking news, ChatGPT generates plausible-sounding responses but lacks the ability to verify or retrieve current facts.
Interestingly, OpenAI has explored integrations that mimic RAG-like functionality, such as browser tools or plugins. These extensions allow ChatGPT to fetch external data, bridging some gaps in its static model. However, these features are not native to all versions of ChatGPT and require deliberate activation, limiting their accessibility and scope.
The absence of built-in RAG highlights a trade-off: simplicity versus precision. While ChatGPT excels in ease of deployment, incorporating RAG could unlock transformative applications, from real-time customer support to adaptive learning systems. The challenge lies in balancing computational efficiency with the demands of dynamic retrieval.
Comparative Analysis with RAG Models
A critical distinction between ChatGPT and RAG models lies in their approach to contextual relevance. ChatGPT generates responses based on pre-trained data, excelling in fluency but often lacking precision in dynamic or specialized scenarios. RAG, by contrast, retrieves real-time information from external sources, ensuring responses are both accurate and contextually grounded. This makes RAG particularly effective in fields like medicine, where up-to-date research is non-negotiable.
However, RAG’s reliance on external databases introduces challenges, such as latency and data quality control. For example, in customer support, RAG can retrieve live product details but risks inaccuracies if the source data is outdated or poorly maintained. ChatGPT avoids this issue but sacrifices adaptability, limiting its utility in fast-evolving domains.
Integrating RAG’s retrieval mechanisms into ChatGPT could create a hybrid model, combining generative fluency with real-time accuracy. This approach could redefine applications in education, legal research, and beyond, bridging the gap between static and dynamic AI systems.
Practical Implications of Combining ChatGPT and RAG
Merging ChatGPT’s conversational fluency with RAG’s real-time data retrieval creates a synergistic model that addresses critical gaps in both systems. Imagine a healthcare chatbot that not only explains medical conditions in plain language but also retrieves the latest clinical guidelines. This dual capability could transform patient interactions, offering both clarity and accuracy in high-stakes scenarios.
One compelling case study involves legal research. A RAG-enhanced ChatGPT could instantly pull relevant statutes and precedents while maintaining conversational coherence. This reduces the time lawyers spend sifting through databases, streamlining workflows and improving decision-making.
However, challenges remain. Integrating RAG introduces latency and computational costs, which can hinder scalability. To mitigate this, modular systems could allow selective activation of RAG features, balancing performance with precision. Ultimately, this hybrid approach has the potential to redefine AI applications in fields like education, compliance, and customer support, where both depth and timeliness are paramount.
Potential Enhancements in Performance
One transformative enhancement lies in adaptive retrieval optimization, where RAG systems dynamically adjust retrieval strategies based on user intent. For instance, a customer support chatbot could prioritize product manuals for troubleshooting queries while favoring policy documents for warranty-related questions. This targeted retrieval minimizes irrelevant data, improving both response time and accuracy.
Another promising avenue is context-aware augmentation. By integrating user-specific metadata—like location or past interactions—RAG can tailor outputs to individual needs. In e-commerce, this could mean recommending region-specific products or services, creating a more personalized experience that drives engagement.
Poorly vetted external sources can introduce bias or inaccuracies, undermining trust. Implementing rigorous validation frameworks ensures that retrieved data aligns with organizational standards, enhancing reliability.
Combining these strategies with reinforcement learning could enable RAG systems to self-improve, setting a new benchmark for performance in dynamic, high-stakes environments.
Case Studies of RAG Integration
One compelling case study involves medical diagnostics, where RAG systems have been integrated to enhance decision-making. For example, CaseGPT, a RAG-powered framework, retrieves up-to-date clinical guidelines and synthesizes recommendations based on patient data. This approach not only reduces diagnostic errors but also accelerates treatment planning, addressing a critical bottleneck in healthcare.
In the legal domain, RAG has revolutionized contract analysis. By retrieving relevant case law and statutes, systems can flag potential risks or inconsistencies in contracts. This capability streamlines workflows for legal professionals, saving time while improving accuracy in high-stakes scenarios.
Systems that incorporate iterative feedback from domain experts refine their retrieval and generation processes over time. This creates a virtuous cycle of improvement, making RAG systems increasingly reliable.
Future applications could leverage multimodal RAG, combining text, images, and structured data to tackle complex, interdisciplinary challenges.
Impact on Industries and Applications
In retail, RAG-powered systems are transforming personalized shopping experiences. By retrieving real-time inventory data and combining it with customer preferences, these systems generate tailored recommendations that drive higher conversion rates. This approach bridges the gap between static recommendation engines and dynamic, context-aware solutions.
In finance, RAG enhances fraud detection by integrating external data sources, such as transaction patterns and regulatory updates, into its analysis. This real-time capability allows financial institutions to identify anomalies faster, reducing risks and improving compliance. The adaptability of RAG to evolving fraud tactics is a game-changer in this sector.
Industries leveraging RAG must ensure that external data sources are accurate and unbiased. Without this, even the most advanced systems risk propagating errors.
Cross-industry collaboration could unlock new applications, such as combining healthcare and insurance data to optimize patient care and policy management.
Challenges in Implementing RAG with ChatGPT
Integrating RAG with ChatGPT presents a balancing act between retrieval and generation. Over-retrieval risks overwhelming users with irrelevant data, while over-generation can lead to “hallucinations”—responses ungrounded in facts. For instance, a customer support chatbot retrieving excessive product details may confuse users rather than assist them.
Maintaining conversation flow across multi-turn interactions requires precise alignment between retrieved data and user intent. A legal chatbot, for example, must dynamically adjust its retrieval strategy as a user’s query evolves, ensuring relevance without losing prior context.
Data quality directly impacts RAG systems, as they rely on external sources, and inaccuracies in these sources can propagate errors. A healthcare chatbot retrieving outdated clinical guidelines could jeopardize patient outcomes, underscoring the need for rigorous data validation.
Addressing these challenges demands modular architectures and reinforcement learning, enabling systems to adapt retrieval strategies dynamically while ensuring factual accuracy.

Technical Obstacles
One of the most pressing technical challenges in implementing RAG with ChatGPT is retrieval latency. While RAG relies on external databases to fetch relevant information, the retrieval process can introduce delays, especially when querying large or distributed datasets. For example, a customer service chatbot retrieving warranty details from multiple regional servers may experience noticeable lag, disrupting the user experience.
RAG systems use vector embeddings to match queries with relevant data, but mismatches in embedding quality can lead to irrelevant or incomplete results. This issue becomes critical in multilingual applications, where subtle linguistic nuances can skew retrieval accuracy.
Moreover, scalability poses a significant hurdle. As data sources grow, maintaining efficient indexing and retrieval pipelines requires advanced infrastructure, such as vector databases or graph-based systems. Organizations must balance computational costs with performance, often necessitating trade-offs that impact real-time usability.
To overcome these barriers, hybrid retrieval models combining dense and sparse indexing offer promising solutions, ensuring both speed and precision.
Ethical and Privacy Considerations
Since RAG systems access external databases, sensitive information—such as customer records or proprietary business data—may be exposed to vulnerabilities. For instance, a healthcare chatbot retrieving patient data must ensure compliance with regulations like HIPAA, which mandates strict access controls and encryption protocols.
RAG models inherit biases from their external data sources, potentially reinforcing stereotypes or misinformation. For example, a legal research chatbot might retrieve outdated or regionally biased case law, leading to skewed interpretations. Addressing this requires rigorous source validation and diverse dataset integration.
To mitigate these risks, differential privacy techniques can anonymize user data while maintaining utility. Additionally, embedding audit trails within RAG systems ensures transparency, allowing users to trace the origins of retrieved information.
Organizations must prioritize ethical AI frameworks, balancing innovation with robust privacy safeguards to build user trust.
Scalability and Resource Requirements
A key challenge in scaling RAG systems lies in managing retrieval latency. As the volume of data grows, retrieval mechanisms must process increasingly complex queries without compromising response times. Techniques like vector databases paired with optimized indexing algorithms (e.g., HNSW) have proven effective, enabling rapid similarity searches even in massive datasets.
Horizontal scaling—adding servers to distribute computational loads—can maintain performance but increases costs. Modular architectures, where retrieval and generation components scale independently, offer a cost-efficient alternative. For instance, enterprises using modular RAG systems can allocate high-performance resources to retrieval while economizing on generation tasks.
Refining user inputs through pre-processing reduces computational strain, improving both speed and accuracy. Moving forward, integrating edge computing could decentralize processing, reducing latency and enabling real-time applications in bandwidth-constrained environments like IoT.
Organizations must balance scalability with resource efficiency to unlock RAG’s full potential.
Future Prospects for ChatGPT and RAG
The integration of ChatGPT with RAG could redefine AI’s role in dynamic fields. Imagine a healthcare assistant that not only generates empathetic responses but also retrieves the latest clinical guidelines in real time. This hybrid model would bridge ChatGPT’s conversational fluency with RAG’s data-driven precision, creating tools that are both engaging and reliable.
One promising avenue is domain-specific customization. For example, legal professionals could benefit from AI systems that synthesize case law updates while maintaining conversational clarity. Early trials in legal tech have shown that RAG-enhanced models reduce research time by up to 40%, highlighting their transformative potential.
However, challenges remain. Balancing computational costs with scalability will require innovations like adaptive retrieval algorithms. Additionally, ethical concerns—such as bias in retrieved data—must be addressed through rigorous validation frameworks. As these hurdles are overcome, the synergy between ChatGPT and RAG could unlock unprecedented applications across industries.
Emerging Trends in AI Language Models
One trend reshaping AI language models is the rise of modular architectures. Unlike monolithic systems, modular designs allow components like retrieval mechanisms, generative models, and reinforcement learning to operate independently yet collaboratively. This approach not only enhances flexibility but also enables targeted upgrades—such as integrating domain-specific retrieval pipelines without retraining the entire model.
A compelling example is multimodal RAG systems, which combine text, image, and even video data. In retail, these systems can analyze customer reviews, product images, and inventory data simultaneously to generate personalized recommendations. This convergence of modalities is unlocking richer, more actionable insights across industries.
However, modularity introduces challenges, particularly in embedding alignment across diverse data types. Addressing this requires innovations in vector representation and cross-modal learning. As these solutions mature, modular AI systems will likely dominate, offering unprecedented adaptability and precision in applications ranging from education to enterprise analytics.
Anticipated Developments in RAG Technology
One pivotal development in RAG technology is the refinement of bi-directional retrieval mechanisms. Unlike traditional retrieval, which focuses on fetching data in a unidirectional flow, bi-directional retrieval enables simultaneous forward and backward look-ups. This approach ensures that the retrieved data not only aligns with the query but also anticipates follow-up questions, creating a more seamless user experience.
For instance, in legal research, bi-directional retrieval can cross-reference case law with ongoing legislative changes, offering lawyers a dynamic, context-aware toolkit. This capability reduces the risk of overlooking critical updates, a common issue in high-stakes fields.
However, implementing bi-directional retrieval requires reinforcement learning to optimize query strategies. By continuously refining retrieval paths based on user feedback, RAG systems can achieve higher precision and relevance. As this technology evolves, it will likely redefine how industries like healthcare and finance handle complex, multi-layered information retrieval, setting new standards for AI-driven decision-making.
Potential Directions for OpenAI
A critical direction for OpenAI lies in modular architecture development. By enabling selective activation of RAG components, OpenAI could create hybrid models that dynamically switch between generative fluency and retrieval-based precision. This approach would allow ChatGPT to adapt to diverse use cases, from casual conversations to high-stakes domains like healthcare or legal advisory.
For example, in customer support, a modular system could prioritize RAG for technical queries while relying on ChatGPT’s conversational depth for general interactions. This flexibility minimizes computational overhead while maintaining response quality, addressing scalability concerns.
Another promising avenue is domain-specific fine-tuning. By integrating RAG with curated datasets, OpenAI can enhance accuracy in specialized fields without compromising general usability. However, this requires robust data validation pipelines to mitigate bias and ensure ethical compliance.
These innovations could position OpenAI as a leader in creating adaptable, context-aware AI systems that balance efficiency with precision.
Cross-Domain Perspectives
The interplay between ChatGPT and RAG reveals fascinating cross-domain implications. In education, ChatGPT excels at fostering engagement through conversational fluency, but it struggles with delivering up-to-date academic references. A RAG-enabled system could bridge this gap by retrieving the latest research, offering students a blend of dynamic interaction and factual accuracy.
In healthcare, the contrast is even starker. While ChatGPT can assist with administrative tasks like appointment scheduling, RAG’s ability to pull real-time clinical guidelines makes it indispensable for decision support. For instance, a hybrid model could provide doctors with the latest treatment protocols while maintaining conversational clarity for patient interactions.
Unexpectedly, creative industries also benefit. RAG’s retrieval capabilities can source niche inspirations—like historical art styles—while ChatGPT refines the narrative. This synergy challenges the misconception that RAG is purely technical, showcasing its versatility across domains.
Ultimately, these examples highlight how combining ChatGPT and RAG can redefine AI’s role in diverse fields.
RAG in the Context of AI Research
One of the most compelling aspects of RAG in AI research is its ability to reduce hallucinations—a persistent issue in generative models. Unlike traditional fine-tuning, which updates model weights, RAG dynamically retrieves external data, ensuring responses are grounded in verifiable sources. For example, in legal AI, RAG systems can pull statutes or precedents directly from trusted databases, minimizing errors in high-stakes scenarios.
Research shows that smaller, RAG-enabled models can outperform massive LLMs by leveraging real-time retrieval, reducing computational costs while maintaining accuracy. This shift has implications for democratizing AI, making advanced capabilities accessible to smaller organizations.
Integrating multimodal RAG systems—combining text, image, and audio retrieval—could redefine how AI interacts with complex datasets. By bridging generative fluency with factual precision, RAG is poised to become a cornerstone of next-generation AI research.
RAG’s Impact on AI Systems and Interdisciplinary Applications
RAG enables dynamic, user-specific data retrieval, fostering hyper-personalized experiences. In e-commerce, it enhances product recommendations by combining real-time inventory with browsing history, creating seamless shopping experiences. Its modular design allows independent fine-tuning of retrieval components, reducing retraining costs and improving adaptability for domain-specific needs.
Beyond traditional AI, RAG bridges disciplines by integrating diverse data sources. In climate science, it combines real-time satellite data with historical models for disaster prediction. In healthcare, it merges patient records with clinical guidelines for tailored treatments. RAG’s ability to contextualize information makes it invaluable in research, education, and other evolving fields.
Maximizing RAG’s potential requires standardized data pipelines to improve interoperability, fostering collaboration across traditionally siloed industries. Its modularity, adaptability, and precision make it a powerful tool for scalable, context-aware AI solutions.
FAQ
1. What is Retrieval-Augmented Generation (RAG) and how does it differ from ChatGPT’s architecture?
Retrieval-Augmented Generation (RAG) combines generative models with real-time information retrieval, unlike ChatGPT, which relies solely on pre-trained data and cannot access external sources dynamically. RAG integrates a retrieval component to fetch up-to-date information, ensuring contextually accurate responses.
ChatGPT, based on the Generative Pre-trained Transformer (GPT), excels at fluent text generation but lacks real-time adaptability without plugins. This key difference makes RAG ideal for fields like healthcare, legal research, and customer support, where timely and precise information is crucial.
2. Does ChatGPT currently integrate RAG for real-time data retrieval?
ChatGPT does not integrate RAG for real-time data retrieval by default. Its responses rely on pre-trained data, limiting access to up-to-date information. However, certain versions can mimic RAG-like functionality through external tools or plugins, such as web browsers or database integrations.
These enhancements enable real-time data access in specific cases but are not universally available across all models. This distinction highlights the difference between ChatGPT’s static knowledge base and RAG’s dynamic capabilities.
3. What are the advantages of combining ChatGPT with RAG in practical applications?
Combining ChatGPT with RAG enhances accuracy by integrating real-time data retrieval, ensuring responses are grounded in the latest information. This is crucial in fields like healthcare, legal research, and customer support, where precision matters. The integration also improves handling of complex queries by retrieving relevant external data while leveraging ChatGPT’s fluency.
Additionally, it reduces hallucinations by supporting responses with verifiable sources. Finally, it enables domain-specific customization, allowing tailored solutions for specialized industries while preserving ChatGPT’s conversational depth and engagement.
4. How does RAG improve the accuracy and relevance of AI-generated responses?
RAG enhances accuracy by retrieving external, up-to-date information, preventing reliance on outdated pre-trained knowledge. This grounding in verifiable sources reduces hallucinations and ensures contextually relevant responses.
By aligning retrieved data with user queries, RAG generates more precise and informed outputs. Its dynamic integration of retrieval and generation makes it especially effective for open-domain questions and delivering timely, accurate information across various applications.
5. What challenges exist in implementing RAG within ChatGPT or similar language models?
Implementing RAG in ChatGPT or similar models comes with challenges. Real-time data retrieval increases computational complexity, leading to potential latency issues.
Ensuring data quality and relevance requires advanced ranking algorithms and validation mechanisms to prevent inaccuracies. Scalability is another concern, as managing large knowledge bases efficiently demands significant resources.
Seamless integration between retrieval and generation components is technically complex, especially in multilingual or domain-specific contexts. Ethical considerations, including data privacy and bias mitigation, must also be addressed for responsible and secure deployment.
Conclusion
RAG represents a transformative leap in AI, bridging the gap between static knowledge and real-time adaptability. While ChatGPT currently operates without RAG integration, the potential synergy between these technologies is undeniable. Imagine ChatGPT as a skilled storyteller, fluent and engaging, but limited to a library frozen in time. RAG, on the other hand, acts as a dynamic researcher, constantly pulling fresh insights from the world. Together, they could redefine how AI handles complex, evolving queries.
For instance, in healthcare, a hybrid model could combine ChatGPT’s conversational ease with RAG’s ability to retrieve the latest clinical guidelines, ensuring both accuracy and empathy. However, challenges like retrieval latency and data validation remain significant hurdles. Experts suggest modular architectures and reinforcement learning as solutions, paving the way for scalable, ethical implementations.
Ultimately, integrating RAG into ChatGPT isn’t just an upgrade—it’s a step toward AI systems that are both intelligent and contextually aware.
Final Thoughts and Future Outlook
The future of AI lies in hybrid architectures that combine the conversational fluency of models like ChatGPT with the real-time accuracy of RAG. This synergy could redefine how AI systems operate, enabling them to deliver both engaging interactions and factually grounded insights. For example, in telemedicine, such a model could provide empathetic patient communication while retrieving the latest clinical guidelines for accurate recommendations.
As datasets grow, retrieval systems must balance speed and relevance without overwhelming computational resources. Techniques like vector-based indexing and edge computing could mitigate these issues, ensuring seamless integration into high-demand environments like financial trading or emergency response systems.
Modular AI frameworks—allowing dynamic toggling between generative and retrieval modes—could become the standard. This approach would empower industries to customize AI solutions, driving innovation while maintaining ethical and operational integrity.