
Dynamic Model and Prompt Selection Based on File Types
Tailoring models and prompts to file types enhances RAG performance. This guide explores dynamic selection strategies that adapt to PDFs, spreadsheets, and more-ensuring accurate context handling and optimized AI-generated responses.


AI models aren’t failing because they’re underpowered. They’re failing because we keep throwing the wrong prompts at the wrong files.
That’s the quiet problem no one talks about.
A single prompt might work great for a CSV, then fall apart when used on a nested JSON or a layout-heavy PDF. And yet, we keep treating all file types the same—like they’re just buckets of data, not complex structures with specific needs.
This is where dynamic model and prompt selection based on file types changes the game. It’s not about using bigger models. It’s about using smarter strategies that adapt to the shape and structure of the data. Because a JSON isn’t just a list—it’s a tree. A PDF isn’t just text—it’s a layout. And a CSV isn’t flexible—it’s rigid.
The truth is, AI models can only perform well when both the model and the prompt match the file they’re dealing with.
That’s what dynamic model and prompt selection based on file types is all about: tailoring your tools to fit the job.
In this article, we’ll break down why file format matters, how adaptive prompts actually work, and what strategies can reduce error without increasing load.
Whether you’re working with legal documents, health records, or customer support tickets, the answer starts with treating the file as a signal—not just a container.
The Role of File Types in Model Selection
File types are more than just containers for data—they shape how AI models interpret and process information. Each format introduces unique structural challenges that demand tailored strategies for optimal performance.
Take JSON files, for instance.
Their nested hierarchies require recursive parsing, which can strain models not designed for such depth. By contrast, CSVs prioritize flat, tabular precision, making them more straightforward but unforgiving of errors in column alignment.
PDFs, with their embedded metadata and visual hierarchies, add another layer of complexity, often requiring spatial reasoning capabilities. These distinctions highlight why treating all file types uniformly undermines model efficiency.
A practical approach involves pairing file-specific preprocessing with adaptive prompt engineering. For example, when working with JSON, prompts can explicitly guide the model to focus on key-value pairs, reducing misinterpretation.
Similarly, for PDFs, leveraging tools like OCR alongside prompts that emphasize layout context can significantly enhance output accuracy.
By aligning model selection and prompt design with file-specific characteristics, practitioners can unlock higher accuracy and reliability, transforming how AI systems handle diverse data formats.
Significance of Dynamic Prompting
Dynamic prompting excels in its ability to adaptively refine AI interactions, particularly when handling diverse file types.
Unlike static approaches, it introduces real-time adjustments based on the model’s performance and the complexity of the task. This adaptability ensures that the model remains aligned with the nuances of the input data, such as the hierarchical depth of JSON files or the spatial intricacies of PDFs.
One key mechanism behind dynamic prompting is its iterative feedback loop. By analyzing the model’s intermediate outputs, prompts can be recalibrated to address misinterpretations or inefficiencies.
For instance, when parsing a JSON file, dynamic prompting might adjust to emphasize specific key-value pairs that were previously overlooked. This contrasts with static methods, which often fail to account for such evolving requirements.
However, implementing dynamic prompting is not without challenges.
It demands robust evaluation metrics to measure prompt effectiveness in real time and computational resources to support iterative adjustments. These constraints highlight the importance of balancing adaptability with efficiency.
By bridging theoretical innovation with practical application, dynamic prompting redefines how AI systems engage with structured and unstructured data.
Core Concepts in Dynamic Selection
Dynamic selection hinges on the precise alignment of AI prompts with the structural and contextual demands of specific file types. This process is not merely a technical adjustment but a strategic recalibration that transforms how models interpret and respond to data.
At its core, dynamic selection leverages the interplay between file-specific constraints and adaptive prompt engineering to optimize performance.
Consider JSON files, where nested hierarchies demand recursive parsing. A static prompt might overlook critical dependencies, but a dynamic approach can adapt in real-time, prioritizing key-value pairs based on contextual relevance.
Similarly, PDFs often encode spatial hierarchies that require spatial reasoning. Here, dynamic selection integrates layout-aware prompts, enabling the model to interpret visual structures effectively.
A pivotal concept is contextual embeddings, which dynamically adjust prompts by incorporating metadata or prior interactions.
For example, in customer support, embedding user history into prompts can reduce response errors by contextualizing queries. This adaptability not only enhances accuracy but also minimizes computational overhead by avoiding redundant processing.
Ultimately, dynamic selection redefines efficiency, transforming AI systems into agile, context-aware tools capable of navigating complex data landscapes.
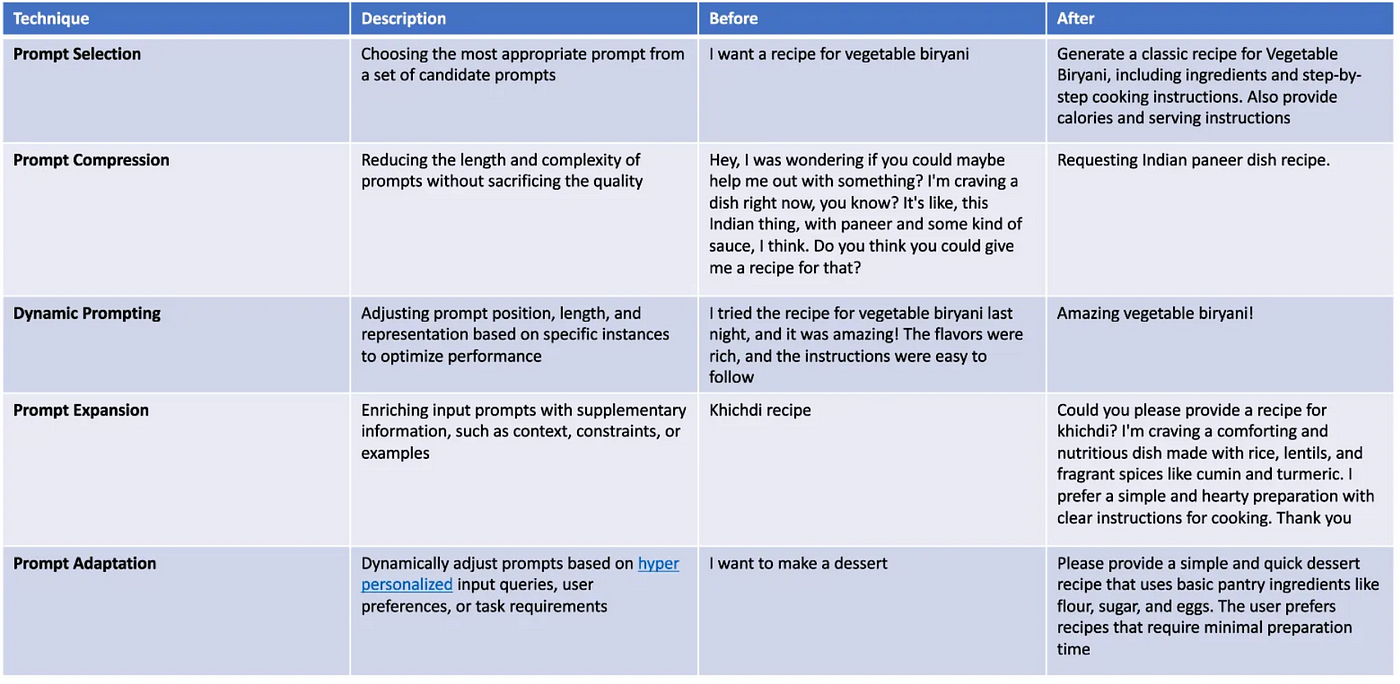
Prompt Engineering Techniques
Dynamic prompt engineering thrives on the principle of contextual alignment, where the prompt adapts to the unique structure and semantics of the input file.
One particularly effective technique is context layering, which involves embedding hierarchical cues into the prompt to guide the AI’s focus.
This approach is especially impactful when working with complex file types like JSON. By layering context—such as specifying parent-child relationships or prioritizing certain key-value pairs—the model can navigate nested structures with greater precision.
For instance, prompts can be designed to emphasize critical nodes while de-emphasizing less relevant branches, reducing cognitive load on the AI.
However, context layering, too, is not without challenges.
Overloading the prompt with excessive detail can lead to diminished performance, as the model struggles to parse competing priorities. Balancing granularity with clarity is key, often requiring iterative refinement.
In practice, this technique has been successfully implemented by organizations like OpenAI, where adaptive prompts have streamlined data extraction from hierarchical datasets.
The result? A more agile, context-aware AI system capable of delivering nuanced insights across diverse applications.
File Type Characteristics and Their Impact
The unique structural traits of file types directly influence how AI models interpret and process data.
JSON files, for example, are inherently hierarchical, requiring recursive parsing to navigate their nested layers.
This complexity demands prompts that explicitly guide the model through parent-child relationships, ensuring critical nodes are prioritized without overwhelming the system.
In contrast, CSV files, while simpler, present their own challenges. Their tabular format is rigid, leaving no room for misalignment.
A single misplaced delimiter can cascade into widespread misinterpretation, making preprocessing and validation indispensable. This rigidity underscores the importance of precision in prompt design, where clear column definitions and contextual cues can mitigate errors.
PDFs, on the other hand, combine textual data with spatial hierarchies and embedded metadata. Extracting meaningful insights from such files requires prompts that account for layout and visual structure.
Tools like OCR can complement these prompts, but the real challenge lies in integrating spatial reasoning into the model’s workflow.
By aligning prompts with the intrinsic characteristics of each file type, practitioners can transform data processing into a precise, context-aware operation.
Mechanisms of Dynamic Model Adaptation
Dynamic model adaptation thrives on the interplay between adaptive algorithms and context-aware prompting, enabling AI systems to align with the structural demands of diverse file types.
At its core, this mechanism leverages real-time feedback loops to iteratively refine both model behavior and prompt design, ensuring precision and efficiency.
One pivotal technique is hierarchical task decomposition, where complex problems are broken into manageable sub-tasks.
For instance, when processing a JSON file, the model dynamically adjusts its parsing depth based on the file’s nested structure, prioritizing critical nodes while minimizing computational overhead.
This approach mirrors human problem-solving, where focus shifts fluidly between broader patterns and granular details.
Another cornerstone is contextual embedding integration, which embeds metadata and prior interactions into the model’s reasoning process.
For example, when handling PDFs with spatial hierarchies, embedding layout-specific cues into prompts allows the model to interpret visual structures more effectively, reducing errors in experimental setups.
By combining these strategies, dynamic adaptation transforms AI systems into agile, context-sensitive tools, capable of navigating the intricacies of real-world data with unparalleled precision.
Dynamic Selection Algorithms
Dynamic selection algorithms excel by leveraging real-time feedback to adaptively refine their decision-making processes.
A critical yet underexplored aspect is the integration of weighted sliding-window techniques, which balance historical data relevance with immediate computational demands.
This method ensures that the algorithm remains responsive to evolving data patterns without being overwhelmed by outdated information.
The sliding-window approach operates by assigning dynamic weights to recent and past data points, prioritizing the most contextually relevant inputs.
This mechanism is particularly effective in scenarios where data characteristics shift unpredictably, such as in anomaly detection or real-time predictions.
By continuously recalibrating the window’s scope, the algorithm maintains a fine balance between adaptability and stability, avoiding the pitfalls of overfitting to transient trends.
One notable implementation of this technique is in online algorithm selection frameworks, where it has demonstrated significant improvements in both accuracy and computational efficiency.
By embedding such nuanced mechanisms, dynamic selection algorithms not only enhance precision but also redefine the boundaries of real-time adaptability in complex computational environments.
Hierarchical Prompting Strategies
Hierarchical prompting strategies excel by structuring tasks into progressive layers of complexity, ensuring models can navigate intricate file structures like nested JSON or spatially complex PDFs without becoming overwhelmed.
This approach mirrors human cognitive processes, where understanding builds incrementally, allowing for more precise and context-aware outputs.
A key mechanism is the least-to-most prompting technique, which begins with simple, foundational prompts and gradually introduces complexity. This method ensures that the model establishes a baseline understanding before tackling nuanced elements.
For instance, when processing a JSON file, the initial prompt might focus solely on identifying top-level keys, while subsequent layers guide the model through nested relationships. This layered approach minimizes cognitive overload and enhances interpretive accuracy.
However, the effectiveness of hierarchical prompting depends heavily on balancing granularity with clarity.
Overloading prompts with excessive detail can lead to diminished performance, as the model struggles to prioritize relevant information. Contextual embedding, which integrates metadata or prior interactions, can mitigate this by dynamically adjusting prompts based on the task’s evolving demands.
By aligning prompt design with the structural demands of specific file types, hierarchical strategies improve task performance and redefine how models interact with diverse data formats.
This nuanced approach bridges theoretical innovation with practical application, offering a robust framework for real-world challenges.
FAQ
What is dynamic model and prompt selection, and how does it optimize AI performance for different file types?
Dynamic model and prompt selection is a method that matches an AI model and prompt to the structure of a file. For example, it uses recursive prompts for JSON and layout-aware prompts for PDFs. This improves accuracy and reduces errors when handling complex data formats.
How do file type characteristics, such as JSON hierarchies or PDF metadata, influence prompt engineering strategies?
File types affect how prompts should be designed. JSON needs prompts that follow its nested keys. PDFs require layout-aware prompts that understand visual structure. Prompt design must reflect how the file stores data to help the model extract useful information accurately.
What are the key benefits of aligning AI models and prompts with specific file structures in industries like finance and healthcare?
Using file-specific prompts improves accuracy and decision-making. In finance, prompts tailored for CSVs ensure clean data extraction. In healthcare, structured prompts help identify key patient data in JSON records. This reduces mistakes and supports better results in complex, high-risk environments.
Which advanced techniques enhance dynamic prompt selection for complex data formats?
Salience analysis helps focus prompts on the most useful data. Contextual embeddings add past knowledge or metadata into the prompt. These tools guide the AI through complex formats like PDFs or JSONs by helping it find what matters most in the input.
How can businesses implement dynamic model and prompt selection to improve accuracy and efficiency in automated document processing?
Businesses can start by adding file-specific preprocessing—like OCR for PDFs or recursive logic for JSON. They can then use real-time feedback to update prompts. This setup improves data accuracy and reduces processing time across systems that handle different file types.
Conclusion
Dynamic model and prompt selection helps AI systems match the structure of the files they process.
It works by combining file-specific prompts, adaptive techniques, and preprocessing steps. This improves how models handle formats like JSON, PDFs, and CSVs, making them more accurate, efficient, and reliable in real-world use.