
Creating Embedded Search APIs with RAG
Embedded search APIs powered by RAG deliver fast, context-aware results within applications. This guide covers building and integrating RAG-based APIs, enabling smarter search experiences tailored to your content and user needs.


Most APIs can answer questions. But very few understand them.
That’s the gap Retrieval-Augmented Generation (RAG) tries to fix—and why creating embedded search APIs with RAG is gaining serious traction.
But here’s the catch: while RAG has made waves in AI labs, it’s still missing from most real-world systems. And that’s not because the tech isn’t good enough. It’s because implementing it—creating embedded search RAG APIs that are fast, accurate, and actually useful—is hard.
The core idea is simple: combine a smart retriever with a smart generator. But doing that well? It takes more than good models.You need thoughtful chunking, real-time indexing, adaptive scoring, and tight integration between each layer. Otherwise, your system won’t retrieve the right data—or worse, will generate something that looks right but isn’t.
This article breaks down what it really takes to build embedded search APIs using RAG. No hype. No fluff. You need to understand the architecture, methods, and trade-offs if you’re serious about building something that works.
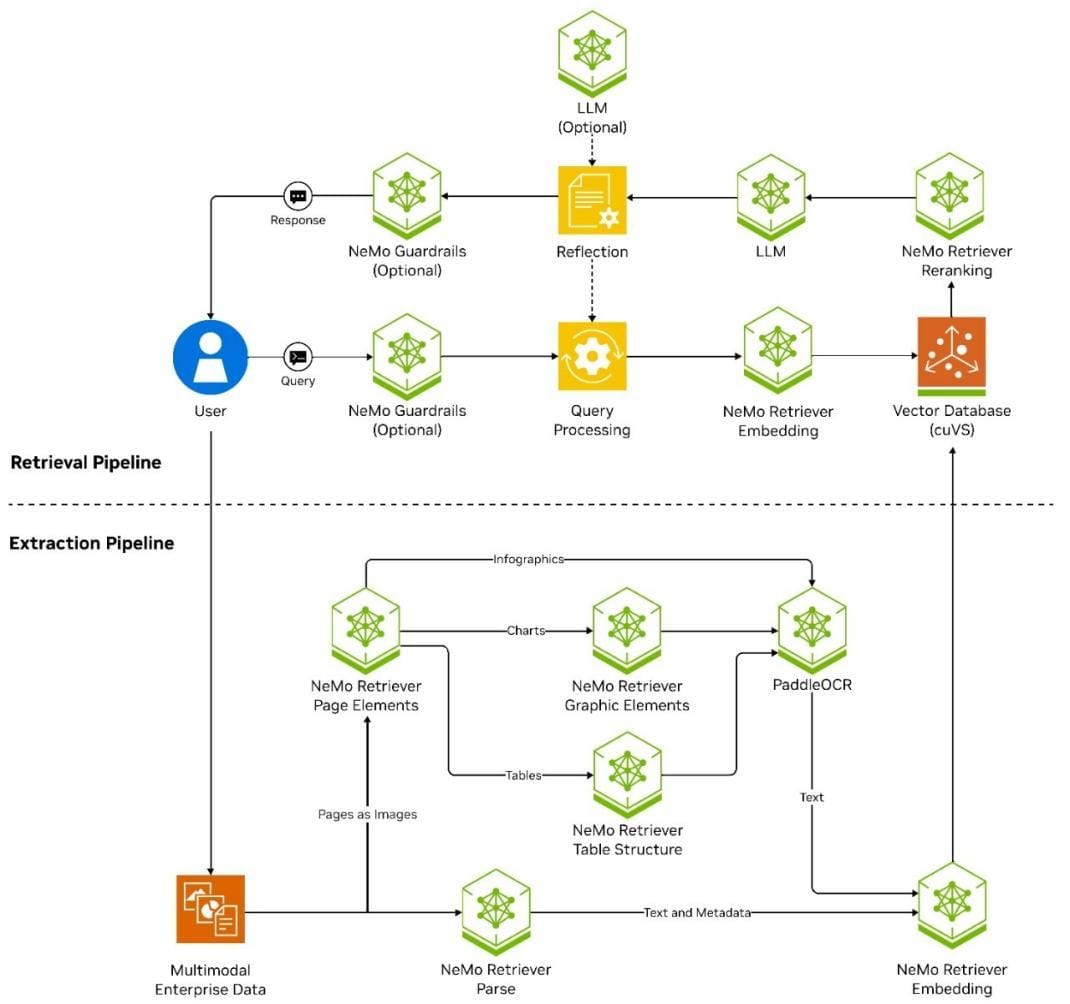
Defining RAG and Its Importance
Retrieval-Augmented Generation (RAG) thrives on its ability to bridge the gap between static data retrieval and dynamic response generation.
At its core, RAG’s significance lies in its capacity to ground generative outputs in factual, contextually relevant information, ensuring reliability while maintaining conversational fluidity.
The true complexity emerges in the interplay between retrieval and generative models.
Retrieval models, often powered by vector embeddings, identify the most relevant data points from vast repositories.
Generative models then synthesize this data into coherent, context-aware responses. However, the challenge lies in optimizing this handoff—ensuring that retrieved data is accurate and seamlessly integrated into the generated output.
This requires precise calibration of retrieval thresholds and contextual weighting, which varies significantly across industries.
A notable example is IBM’s application of RAG in customer support systems. By leveraging dense retrieval techniques, they reduced response inaccuracies by integrating real-time product updates into chatbot interactions.
This highlights how RAG’s success depends on tailoring retrieval strategies to specific use cases, a nuance often overlooked in theoretical discussions.
Ultimately, RAG’s importance extends beyond technical innovation—it redefines how systems interact with data, emphasizing trust and contextual relevance.
Key Components: Retrieval and Generation
The alignment between retrieval and generation in RAG systems is not just a technical necessity—it’s the linchpin of their effectiveness. One often-overlooked aspect is the role of chunking strategies in retrieval.
By segmenting data into optimally sized chunks, systems can balance granularity with relevance, ensuring that retrieved information is both precise and contextually rich.
Conversely, poor chunking can lead to fragmented or overly broad results, undermining the generator’s ability to produce coherent outputs.
A critical technique involves dynamic chunk sizing, where the system adjusts segment lengths based on query complexity.
For instance, legal document processing often benefits from larger chunks to preserve clause-level context, while customer support systems thrive on smaller, targeted segments. This adaptability enhances retrieval accuracy and minimizes noise in the generative phase.
In practice, organizations like Acorn.io have implemented recursive retrieval, refining results through iterative passes.
This approach not only improves relevance but also reduces hallucinations in generation. The interplay of these techniques demonstrates that retrieval is as much an art as it is a science, demanding constant calibration to meet diverse application needs.
Core Concepts in Embedded Search APIs
Embedded search APIs thrive on two foundational pillars: semantic search and vector embeddings.
These aren’t just technical buzzwords—they’re the mechanisms that transform raw data into actionable insights.
Semantic search, for instance, doesn’t merely match keywords; it deciphers intent and context, enabling systems to interpret queries with human-like nuance. This capability is particularly vital in domains like healthcare, where a query like “treatment for Type 2 diabetes” demands precision beyond surface-level matches.
Vector embeddings, on the other hand, act as the connective tissue of modern search systems.
Encoding data into dense numerical representations captures semantic relationships that traditional keyword searches often miss.
For example, embeddings can link “heart attack” with “myocardial infarction,” ensuring that critical information isn’t lost in translation. These embeddings are stored in vector databases, which excel at high-speed similarity searches, even across massive datasets.
Together, these components redefine search APIs, not as static tools but as dynamic systems capable of understanding and responding to complex, real-world queries. This synergy is the cornerstone of effective RAG pipelines.
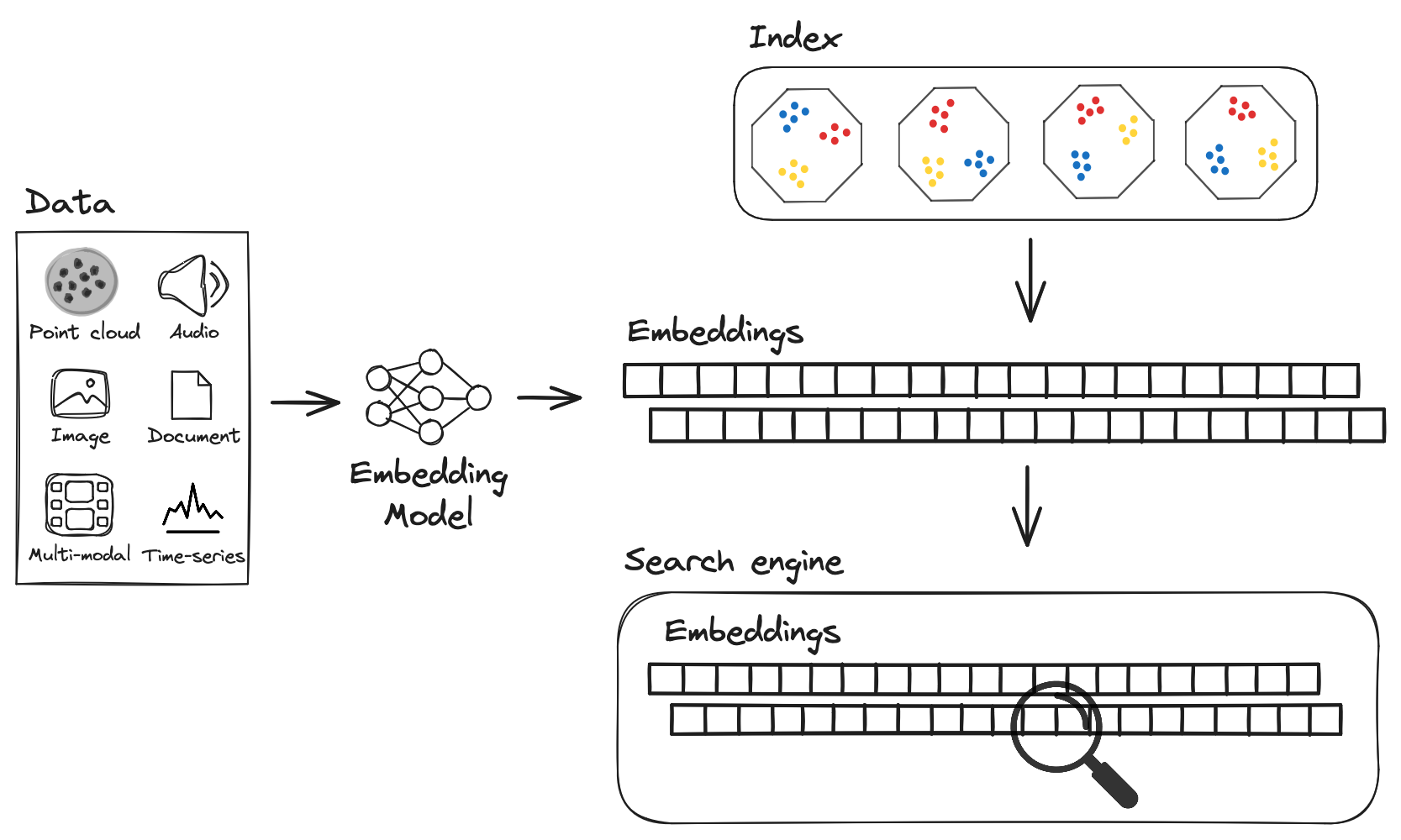
Semantic Search and Vector Embeddings
Semantic search’s true power lies in its ability to interpret intent, and vector embeddings are the silent architects behind this capability.
At their core, embeddings encode relationships between concepts, enabling systems to understand context rather than just surface-level matches.
This is particularly transformative in domains like legal research, where precision and nuance are paramount.
One often-overlooked technique is adaptive embedding tuning. By fine-tuning embeddings on domain-specific data, organizations can significantly enhance relevance.
For instance, a healthcare platform might train embeddings to prioritize synonyms like “hypertension” and “high blood pressure,” ensuring critical connections aren’t missed. However, this approach demands careful calibration to avoid overfitting, which can narrow the model’s generalizability.
A notable challenge arises in balancing computational efficiency with accuracy. While Approximate Nearest Neighbor (ANN) algorithms accelerate vector searches, they can introduce minor inaccuracies.
This trade-off becomes critical in high-stakes applications, such as medical diagnostics, where even slight deviations can have significant consequences.
Ultimately, the interplay between semantic search and embeddings is a dynamic process, requiring constant refinement to align with evolving data landscapes.
The Role of Vector Databases
Vector databases are the backbone of embedded search APIs, enabling the seamless integration of semantic search capabilities into Retrieval-Augmented Generation (RAG) systems.
A critical yet often overlooked aspect is the indexing strategy, which directly impacts the efficiency and accuracy of similarity searches.
Indexing in vector databases involves organizing high-dimensional embeddings into structures optimized for rapid retrieval, such as hierarchical navigable small-world (HNSW) graphs or KD-trees.
The choice of indexing algorithm is not trivial.
HNSW, for instance, excels in balancing speed and accuracy, making it ideal for real-time applications like fraud detection.
However, its memory overhead can be a limitation in resource-constrained environments. In contrast, KD-trees are more memory-efficient but struggle with high-dimensional data, highlighting the trade-offs developers must navigate.
Contextual factors, such as the nature of the data and query patterns, further influence indexing performance.
For example, multimodal datasets combining text and images require hybrid indexing approaches that can handle diverse embedding types. This complexity underscores the importance of tailoring database configurations to specific use cases.
By mastering these nuances, developers can unlock the full potential of vector databases, transforming RAG systems into precision-driven tools for complex problem-solving.
Implementing RAG: Indexing and Retrieval
Indexing in RAG systems is not merely about storing data but structuring it for precision and speed.
Think of it as designing a library where every book is shelved not just by title but by the questions it can answer.
This requires a deliberate choice of indexing strategies, such as hierarchical indexing for layered datasets or dynamic indexing to accommodate real-time updates without reprocessing the entire corpus.
Retrieval, on the other hand, is where the system’s intelligence shines. Advanced techniques like semantic routing—which directs queries to the most relevant indexed segments—ensure that the system retrieves related data and the right data. For instance, in legal tech, routing queries through topic-specific embeddings can drastically improve relevance, reducing noise in results.
The interplay between indexing and retrieval is similar to a well-rehearsed orchestra: indexing sets the stage, while retrieval delivers the performance.
When harmonized, they transform static data into actionable insights, enabling RAG systems to meet the demands of complex, real-world applications.
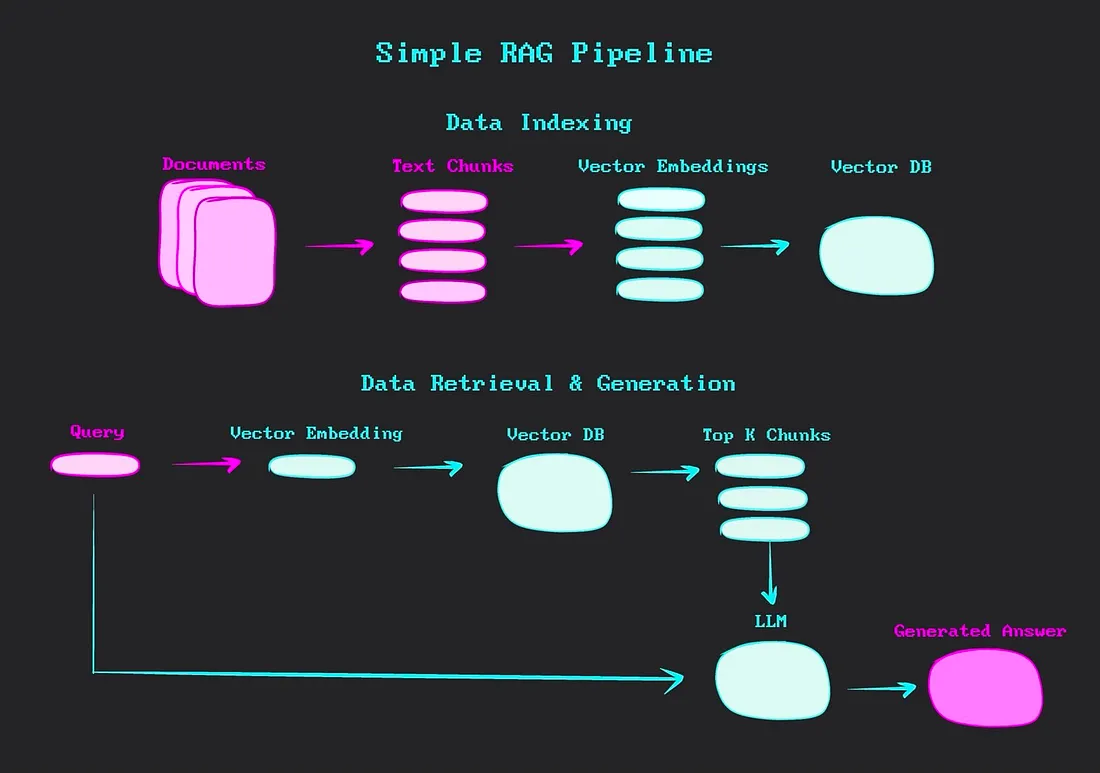
Indexing Strategies for Efficient Retrieval
Dynamic indexing is a game-changer for RAG systems, especially in environments where data evolves rapidly.
Unlike static methods, dynamic indexing allows systems to incorporate new information incrementally, avoiding the need for complete re-indexing.
This adaptability ensures that retrieval remains both timely and contextually relevant, even as datasets grow or shift.
The core mechanism behind dynamic indexing lies in its ability to update specific index segments without disrupting the entire structure.
For instance, metadata-driven indexing enhances this process by tagging data with contextual markers like timestamps or authorship. This enables the system to prioritize the most recent or authoritative information during retrieval, a critical feature in fields like financial forecasting or medical diagnostics.
However, dynamic indexing isn’t without challenges.
Balancing speed and accuracy during updates can be complex, particularly when dealing with high-dimensional data. Techniques like hierarchical indexing, which organizes data into layered structures, mitigate this by isolating updates to specific nodes, reducing computational overhead.
By integrating dynamic indexing, organizations can achieve a retrieval process that feels intuitive, precise, and responsive to ever-changing demands.
Retrieval Techniques: From Basic to Advanced
The transition from basic to advanced retrieval techniques hinges on one critical factor: the ability to align retrieval precision with the complexity of user queries.
At its core, this evolution is driven by the integration of semantic routing, a method that dynamically directs queries to the most contextually relevant data segments.
Unlike static retrieval, semantic routing adapts in real-time, ensuring that even nuanced queries are matched with the most appropriate data.
This process relies heavily on advanced embedding techniques. The system identifies semantic relationships that traditional keyword searches miss by encoding both the query and the data into high-dimensional vector spaces.
However, the real innovation lies in combining these embeddings with re-ranking algorithms.
Re-ranking assigns relevance scores to retrieved results, prioritizing those that align most closely with the query’s intent. This dual-layered approach minimizes noise and enhances the contextual richness of the output.
A notable implementation of this is seen in healthcare AI systems, where semantic routing paired with re-ranking has improved diagnostic accuracy.
By routing queries through domain-specific embeddings, these systems retrieve not just relevant data but the right data.
This nuanced interplay of techniques transforms retrieval into a dynamic, context-aware process, redefining its role in RAG systems.
FAQ
What are the key components of embedded search APIs using Retrieval-Augmented Generation (RAG)?
Embedded search APIs built with RAG consist of a retriever, a knowledge base, and a generator. The retriever uses vector embeddings for semantic search. The generator uses this retrieved context to produce responses. Dynamic indexing and scoring ensure real-time, relevant output.
How do knowledge graphs and entity relationships improve RAG-based embedded search APIs?
Knowledge graphs structure data by linking entities and relationships. This helps RAG systems understand complex queries, perform multi-hop reasoning, and return context-aware results. They reduce ambiguity by guiding retrieval based on structured relationships between concepts.
What is salience analysis and how does it help embedded search APIs with RAG?
Salience analysis identifies the most important entities in a query. It boosts retrieval accuracy by focusing on core concepts rather than surface terms. In RAG systems, it helps align query embeddings with relevant data, reducing irrelevant or noisy results.
How does co-occurrence optimization improve semantic search in RAG-powered APIs?
Co-occurrence optimization tracks which entities often appear together. It strengthens semantic relationships in embeddings, allowing RAG systems to prioritize data that aligns with user intent. This improves result accuracy in complex, data-driven domains.
What are best practices for combining vector embeddings and hybrid search in RAG search APIs?
Use fine-tuned embeddings on domain-specific data. Combine them with keyword-based retrieval for better recall. Apply entity-based salience scoring and dynamic indexing. Use rank fusion techniques like RRF to merge results from both methods while maintaining semantic accuracy.
Conclusion
Creating embedded search APIs with RAG depends on balancing precision in retrieval with accuracy in generation. From semantic embeddings to dynamic indexing, each step must align with query complexity. When built correctly, RAG-based APIs transform how systems access and generate information—shifting search from static lookup to active understanding.