
Evaluating RAG Quality: Best Practices for QA Dataset Creation
Quality evaluation is key for optimizing RAG systems. This guide covers best practices for QA dataset creation, helping improve retrieval accuracy, relevance, and AI-generated responses to ensure high-quality knowledge retrieval and performance.


The accuracy of a retrieval-augmented generation (RAG) system depends on the quality of the dataset on which it is trained.
Yet, many AI models fail because their QA datasets do not reflect real-world complexity.
Poor dataset design leads to hallucinations, misaligned retrievals, and unreliable answers, especially in domains like healthcare and law.
How can we fix this?
Creating a QA dataset is more than gathering questions and answers. It requires context-aware structuring, salience analysis, and iterative refinement to ensure retrieval precision and generative accuracy.
Without these, even the most advanced RAG systems struggle to deliver trustworthy results.
This guide explores the best practices for QA dataset creation to enhance RAG quality, ensuring AI systems produce accurate, well-grounded responses across high-stakes fields.
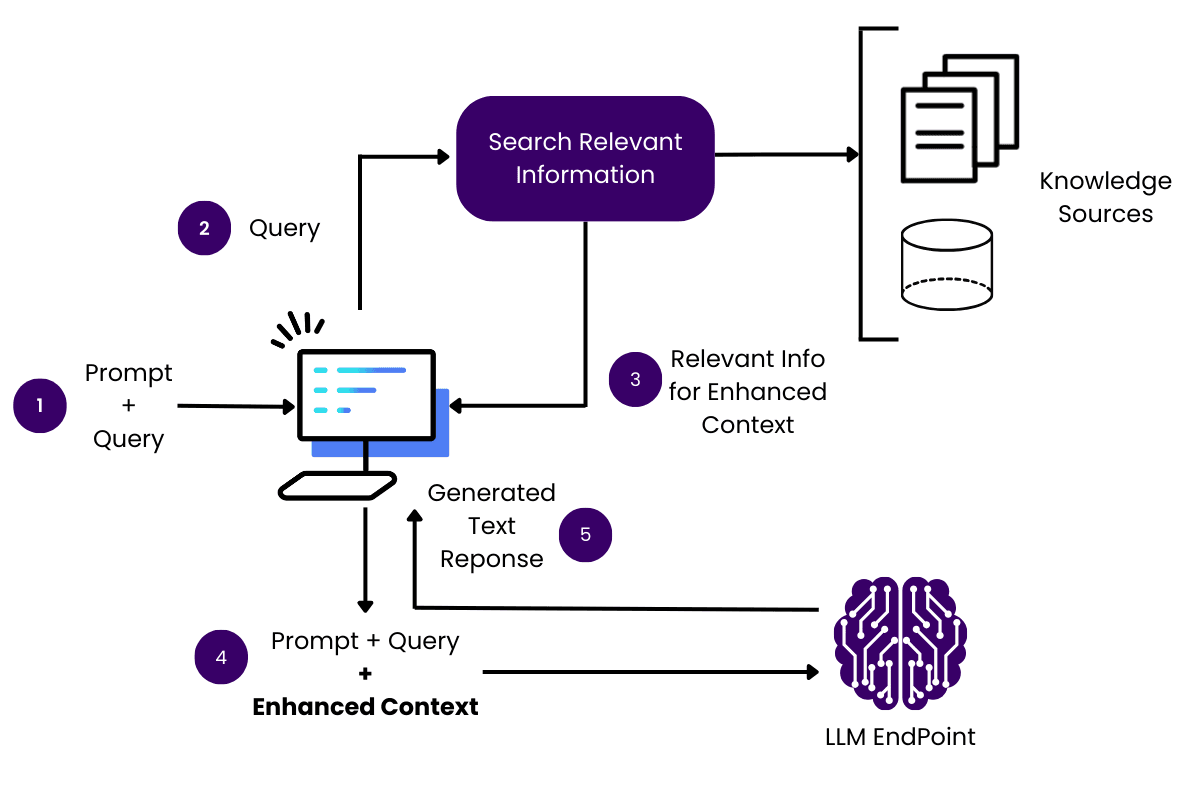
Core Concepts of RAG Systems
The alignment between retrieval and generation in RAG systems is a nuanced yet critical factor determining overall performance.
Misalignment often leads to generative outputs that, while fluent, lack factual grounding—a phenomenon known as hallucination.
This issue arises when the retrieval component fails to provide contextually relevant data, leaving the generator to extrapolate beyond its knowledge base.
One effective technique to address this is the integration of iterative feedback loops.
These loops dynamically refine retrieval outputs based on the generator’s performance, ensuring that retrieved data aligns with the system’s generative needs.
For instance, organizations like OpenAI have implemented hybrid search mechanisms combining semantic and keyword-based retrieval, significantly improving contextual relevance.
However, challenges persist.
Temporal data shifts can render retrieved information outdated, particularly in domains like finance or medicine. To mitigate this, some systems incorporate real-time indexing to maintain data freshness, though this increases computational overhead.
Importance of QA Dataset Quality
A high-quality QA dataset is not just a technical requirement but the linchpin of a reliable RAG system.
The dataset’s structure and content directly influence the system’s ability to generate accurate, contextually relevant responses.
One overlooked yet critical aspect is the alignment between the dataset’s complexity and the domain-specific challenges it aims to address. For instance, datasets designed for legal applications must incorporate multi-layered queries that reflect real-world legal reasoning rather than simplistic question-answer pairs.
The process of creating a dataset involves more than curating questions and answers. Techniques like contextual augmentation—where questions are enriched with additional metadata or scenario-based variations—can significantly enhance the system’s ability to handle nuanced queries.
However, this approach requires careful calibration to avoid introducing noise or irrelevant data, which could degrade performance.
Evaluating Retrieval Accuracy
Retrieval accuracy in RAG systems is not merely a measure of relevance but the foundation of the entire QA pipeline.
A critical insight often overlooked is that retrieval errors compound exponentially during generation, leading to outputs that may appear fluent but lack factual integrity.
This underscores the necessity of precision in the retrieval phase, where even minor inaccuracies can derail the system’s reliability.
One effective approach to enhance retrieval accuracy is using dynamic reranking algorithms.
These algorithms, such as those implemented in Google’s T5-based retrieval models, reorder retrieved documents based on contextual alignment with the query.
Another key factor is granularity in chunking strategies. Systems like Qdrant have achieved higher recall rates without sacrificing precision by segmenting documents into semantically coherent units.
This method ensures that retrieved content is relevant and contextually complete, addressing a common pitfall in which overly broad chunks dilute response accuracy.
The implications are clear: refining retrieval accuracy is a technical exercise and a strategic imperative for building trustworthy RAG systems.
Metrics for Retrieval Performance
Dynamic reranking algorithms stand out as a transformative approach to evaluating retrieval performance.
These algorithms reorder retrieved documents based on their contextual alignment with the query, prioritizing the most relevant information.
This process is not merely about ranking but refining the interplay between retrieval and generation, directly impacting the system’s reliability.
By iteratively adjusting rankings, these algorithms adapt to nuanced shifts in query intent. This feature is particularly valuable in domains like legal or medical applications, where precision is paramount.
One notable implementation is Google’s T5-based retrieval model, which leverages reranking to optimize top-K precision.
Unlike static ranking methods, dynamic reranking incorporates feedback loops that continuously refine results. This approach addresses the challenge of false positives, which can lead to generative hallucinations.
However, this technique is computationally intensive, requiring careful calibration to balance performance gains with resource constraints.
A critical limitation of reranking is its dependency on the quality of the initial retrieval. If the base retriever fails to fetch contextually relevant documents, reranking cannot compensate for foundational errors.
This highlights the importance of integrating robust retrieval mechanisms with advanced reranking strategies to achieve optimal results.
Challenges in Context Relevance
Context relevance in RAG systems hinges on the precision of query-document alignment, which determines whether retrieved data truly reflects the query’s intent.
Misalignment often arises from overly broad retrieval parameters, where semantic embeddings fail to capture nuanced query variations.
This issue is particularly acute in domains like legal research, where even slight contextual deviations can lead to misinterpretations of case law or statutes.
One practical approach to mitigate this challenge is dynamic query re-weighting, which adjusts the importance of query terms based on their contextual significance.
For instance, in a legal query, terms like “precedent” or “jurisdiction” might be weighted higher than generic terms, ensuring retrieval focuses on critical aspects.
However, this technique requires robust metadata tagging to avoid amplifying irrelevant noise—a limitation that can undermine its effectiveness in poorly structured datasets.
A notable case study involves OpenAI’s integration of semantic embeddings with domain-specific retrievers, which improved legal document summarization accuracy by aligning retrieval outputs with the generator’s contextual needs.
This demonstrates that refining context relevance is a technical exercise and a strategic imperative for ensuring reliable, domain-specific applications.
Assessing Generation Quality
Generation quality in RAG systems is fundamentally about ensuring that responses are accurate, contextually coherent, and user-aligned.
A critical insight often overlooked is that even minor inconsistencies in the retrieval phase can cascade into significant generative errors, undermining the system’s reliability.
This interplay highlights the necessity of evaluating generation quality through both faithfulness—the adherence to retrieved facts—and coherence, the logical flow of the response.
One effective methodology for assessing faithfulness is using semantic similarity metrics, such as BLEURT, which compare generated answers against ground-truth data.
However, these metrics alone are insufficient; they must be paired with human evaluation to capture subtleties like tone and intent alignment.
Techniques such as contextual embeddings are invaluable for enhancing coherence for enhancing coherence. Systems like Google’s T5 achieve smoother transitions between disparate information points by embedding retrieved data into a shared semantic space.
This approach mirrors the way a skilled editor weaves multiple sources into a unified narrative, ensuring the response feels authoritative.
Ultimately, assessing generation quality is not a static process but an iterative one. By continuously refining faithfulness and coherence metrics, developers can create systems that answer questions and inspire user trust.
Evaluating Answer Faithfulness
Faithfulness in RAG systems hinges on the alignment between generated answers and their supporting context.
A critical yet often overlooked aspect is the granularity of claim verification. Instead of treating responses as monolithic outputs, breaking them into discrete claims allows for precise validation against retrieved documents.
This approach ensures that every statement in an answer can be traced to its source, reducing the risk of hallucinations.
Automated fact-checking pipelines benefit claim-level evaluation. These systems cross-reference individual claims with retrieved data, flagging inconsistencies in real time. However, their effectiveness depends heavily on the quality of the retrieval phase.
For instance, systems like Qdrant have demonstrated that integrating semantic chunking with claim verification improves faithfulness by isolating contextually relevant data.
A notable challenge arises in ambiguous contexts, where retrieved documents may support multiple interpretations.
Addressing this requires human-in-the-loop evaluations, particularly in high-stakes domains like healthcare. Organizations can balance scalability and accuracy by combining automated tools with expert oversight.
Ultimately, refining faithfulness metrics demands a nuanced approach that integrates technical precision with contextual understanding, ensuring that generated answers remain reliable and trustworthy.
Techniques for Ensuring Coherence
One advanced technique for ensuring coherence in RAG systems is attention-based fusion, which dynamically weights retrieved data based on its relevance to the query.
This method operates by assigning higher importance to contextually critical elements while deprioritizing peripheral information, creating a seamless narrative flow.
The principle behind this approach lies in leveraging transformer architectures to align retrieved snippets with the query’s intent, ensuring logical progression in the generated response.
This technique is particularly effective in domains like healthcare, where patient histories and treatment guidelines must be synthesized into actionable insights.
For example, a healthcare AI firm implemented attention-based fusion to integrate overlapping medical records, resulting in more cohesive diagnostic summaries.
However, the method’s success depends on precise calibration of attention mechanisms, as overemphasis on certain elements can inadvertently exclude relevant but less prominent data.
A notable limitation arises in sparse or conflicting data scenarios, where the system may struggle to establish a unified narrative.
Addressing this requires iterative refinement through feedback loops, allowing the model to adjust its weighting dynamically.
End-to-End RAG System Evaluation
Evaluating an end-to-end RAG system (E2E) is like diagnosing a complex machine where every component must function in harmony.
The process begins with assessing retrieval precision, ensuring that the system fetches semantically relevant data. Missteps here cascade into the generation phase, amplifying inaccuracies.
Beyond retrieval, the augmentation layer must enrich the context without introducing noise. This is where techniques like dynamic reranking shine, prioritizing documents that align closely with the query intent.
However, even the best augmentation falters if the generation model lacks fidelity. Metrics such as BLEURT and ROUGE, while useful, often miss subtleties like tone or domain-specific nuances, necessitating human evaluation for high-stakes applications.
Think of E2E evaluation as tuning an orchestra: each section—retrieval, augmentation, generation—must perform in sync. When done right, the result is a system that answers questions with precision, coherence, and trustworthiness.
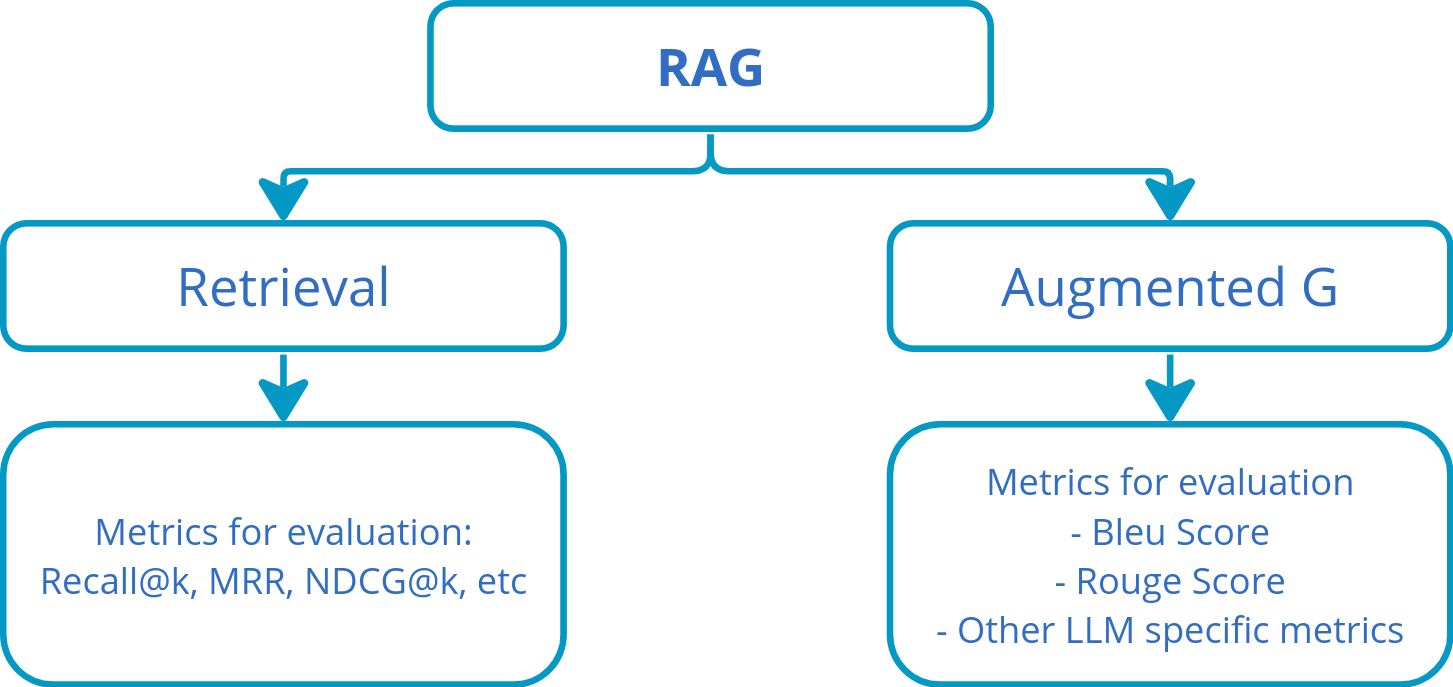
Integrating Retrieval and Generation Metrics
The interplay between retrieval and generation metrics reveals a critical dynamic: the quality of one directly shapes the effectiveness of the other.
This relationship is particularly evident in scenarios where retrieval precision is high, but the retrieved data lacks contextual depth, forcing the generation model to extrapolate beyond its scope.
Such misalignments often result in fluent outputs yet factually compromised, underscoring the need for integrated evaluation.
One effective approach is contextual alignment scoring, which measures how well-retrieved documents support the generator’s output.
Unlike traditional metrics that evaluate retrieval and generation separately, this method assesses the coherence of the entire pipeline.
For example, OpenAI’s integration of semantic embeddings with retrieval metrics has demonstrated how aligning these components can reduce generative errors in legal and medical applications.
However, challenges arise in domains with ambiguous queries or sparse data. In these cases, iterative feedback loops become indispensable.
These loops ensure that both components adapt to evolving user needs by continuously refining retrieval outputs based on generative performance.
This approach has been successfully implemented by organizations like Google, where hybrid retrieval models dynamically adjust to query intent.
Ultimately, integrating these metrics transforms evaluation from a fragmented process into a cohesive strategy. This not only enhances system reliability but also fosters trust in high-stakes applications like healthcare and finance.
Best Practices for QA Dataset Creation
Creating QA datasets for RAG systems demands precision akin to curating a specialized library. Each dataset must reflect the domain’s complexity and anticipate the system’s operational challenges.
A common pitfall is assuming that more data equates to better performance. In reality, data quality—not quantity—drives system reliability.
For instance, datasets enriched with contextual augmentation (e.g., metadata tagging or scenario-based variations) have been shown to improve retrieval precision by aligning context with nuanced queries.
One overlooked insight is the importance of query diversity. Homogeneous datasets often lead to overfitting, where systems excel in narrow scenarios but falter in real-world applications.
By incorporating varied phrasing and multi-turn queries, developers can simulate the unpredictability of user interactions. This approach mirrors how a chess player practices against diverse strategies to build adaptability.
Think of QA datasets as the scaffolding for a skyscraper: poorly constructed datasets compromise the entire structure.
By integrating domain-specific challenges, iterative refinement, and robust metadata, practitioners can ensure their RAG systems deliver both answers and trust.
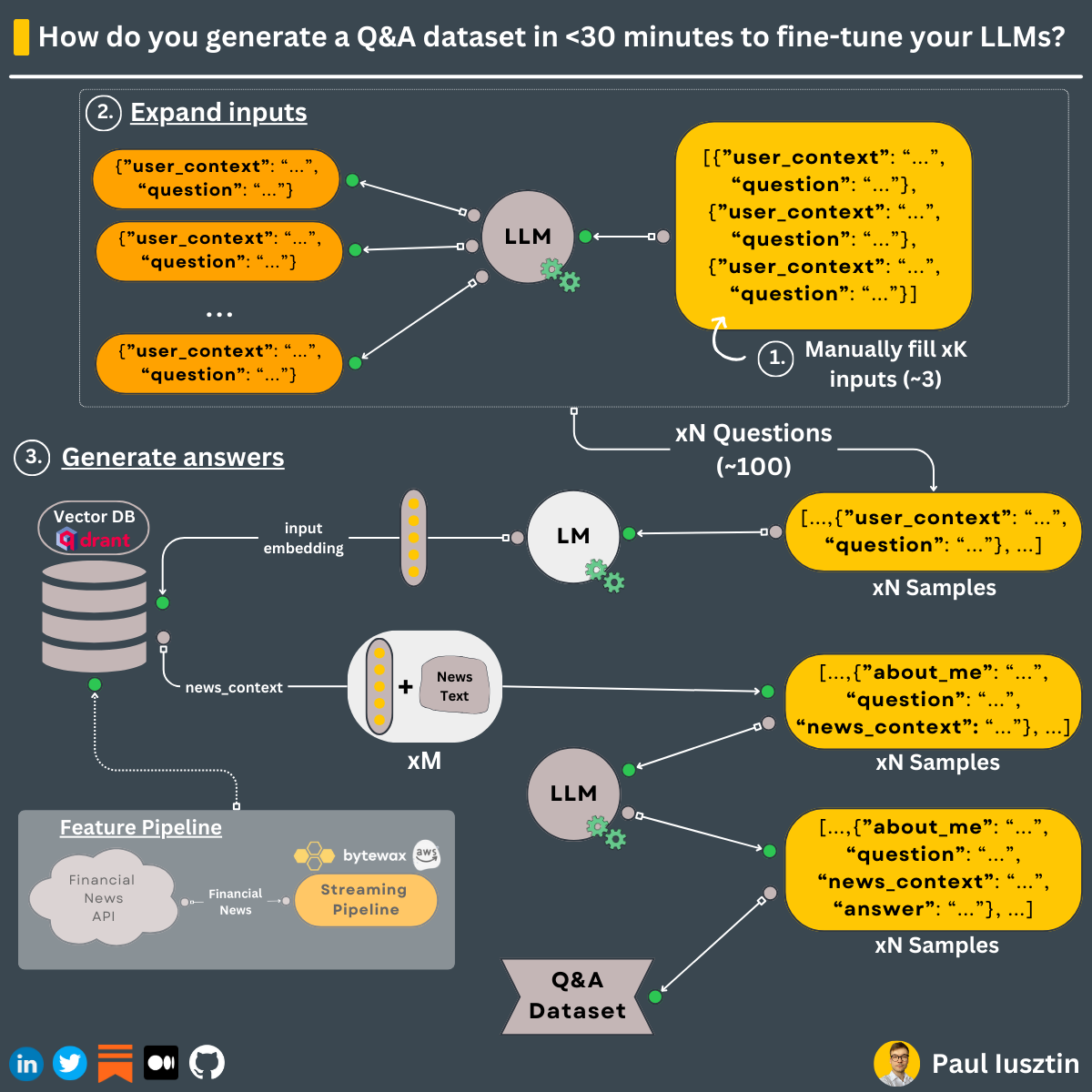
Designing High-Quality Datasets
The cornerstone of a high-quality QA dataset lies in its ability to simulate the unpredictability of real-world queries.
One often-overlooked technique is contextual layering, where questions are embedded with multi-dimensional metadata—such as temporal markers, domain-specific terminology, or user intent classifications.
This approach ensures that the dataset tests retrieval accuracy and challenges the system’s ability to adapt to nuanced contexts.
A critical distinction emerges when comparing static datasets to those enriched with contextual layering.
While static datasets are easier to construct, they often fail to expose retrieval systems to edge cases or ambiguous scenarios.
In contrast, layered datasets introduce variability that mirrors real-world complexities, such as overlapping intents or conflicting evidence.
However, this technique has challenges. Overloading questions with metadata can inadvertently introduce noise, diluting retrieval precision.
To mitigate this, iterative validation cycles—combining automated checks with domain expert reviews—are essential.
Continuous Dataset Refinement
Refining a QA dataset is less about fixing errors and more about evolving its alignment with real-world complexities.
One critical technique is adaptive feedback integration, where user interactions and system outputs are continuously analyzed to identify gaps or inconsistencies in the dataset.
This approach ensures the dataset remains relevant as user needs and domain knowledge evolve.
The process begins with automated tools that flag anomalies, such as mismatched answers or low-confidence retrievals.
However, these tools often miss subtleties like ambiguous phrasing or context-specific nuances. Organizations like OpenAI have implemented hybrid workflows combining automated checks with expert reviews to address this.
This dual-layered approach enhances dataset precision and uncovers latent issues that could compromise system performance.
A notable challenge arises when datasets are updated too frequently, potentially destabilizing model performance.
To mitigate this, practitioners employ version-controlled refinement cycles, testing changes in isolated environments before full integration. This method preserves system stability while enabling iterative improvements.
By treating datasets as dynamic assets rather than static resources, developers can ensure their QA systems remain robust, adaptable, and capable of addressing increasingly complex queries. This mindset transforms refinement from a maintenance task into a strategic advantage.
FAQ
What metrics are most important for evaluating QA dataset quality in RAG systems?
Key metrics for evaluating QA datasets in RAG systems include precision, recall, and F1 score to measure retrieval relevance and completeness. Mean Reciprocal Rank (MRR) assesses ranking quality, while BLEU and ROUGE evaluate generative accuracy. Salience analysis and co-occurrence optimization enhance dataset structure for better query alignment.
How does dataset complexity impact the accuracy and reliability of RAG systems?
A well-designed dataset improves RAG system accuracy by preserving domain-specific relationships and enhancing retrieval precision. Overly complex datasets introduce noise, reducing reliability. Salience analysis ensures critical information is prioritized, while co-occurrence optimization helps identify meaningful patterns in domain-specific applications like legal, financial, and medical AI.
What are the best practices for aligning QA datasets with retrieval and generation in RAG pipelines?
To improve query-document alignment, QA datasets should include contextual augmentation, entity mapping, and salience analysis. Co-occurrence optimization ensures frequent entity pairs remain together, improving retrieval precision. Iterative refinement with expert feedback adjusts dataset structures to maintain alignment with evolving RAG system needs.
How can semantic SEO techniques improve QA dataset creation for RAG systems?
Entity relationships improve dataset structure by mapping key concepts for precise retrieval. Salience analysis filters noise and prioritizes relevant content. Co-occurrence optimization ensures related terms remain linked in queries, enhancing retrieval and generation accuracy. These methods help RAG systems produce more accurate, user-aligned responses.
Why is iterative refinement essential for maintaining high-quality QA datasets in RAG applications?
Iterative refinement updates datasets with new patterns, emerging terminology, and domain shifts. Entity relationships preserve contextual integrity, while salience analysis filters outdated or redundant content. Feedback loops ensure RAG systems adapt to user needs, maintaining high retrieval precision and response accuracy over time.
Conclusion
A well-structured QA dataset is the foundation of an effective RAG system. AI models produce unreliable outputs without precision in retrieval and alignment in generation.
Contextual augmentation, salience analysis, and iterative refinement ensure datasets stay accurate, adaptable, and domain-relevant.
As RAG systems evolve, high-quality datasets will define their success in law, medicine, finance, and research applications.