
Excel and RAG: Implementing Effective Retrieval Strategies for Spreadsheets
Enhancing retrieval from spreadsheets is key to optimizing data extraction. This guide explores effective strategies, query handling techniques, and AI-driven approaches to improve accuracy, efficiency, and structured data retrieval in RAG systems.


Spreadsheets hold vast amounts of critical data, but finding the right information often feels like searching for a needle in a haystack.
Traditional lookup functions struggle with scattered entries, inconsistencies, and multi-sheet dependencies.
A logistics manager looking for delayed shipments tied to a specific supplier may spend hours filtering and cross-referencing data—only to end up with incomplete results.
This is where Retrieval-Augmented Generation (RAG) for Excel changes the game. By enabling context-aware retrieval, RAG allows users to ask natural language questions—like “Which suppliers caused delays last quarter?”—and get precise, structured answers instantly.
This article explores how RAG enhances Excel retrieval, the challenges involved, and the best strategies for implementation.
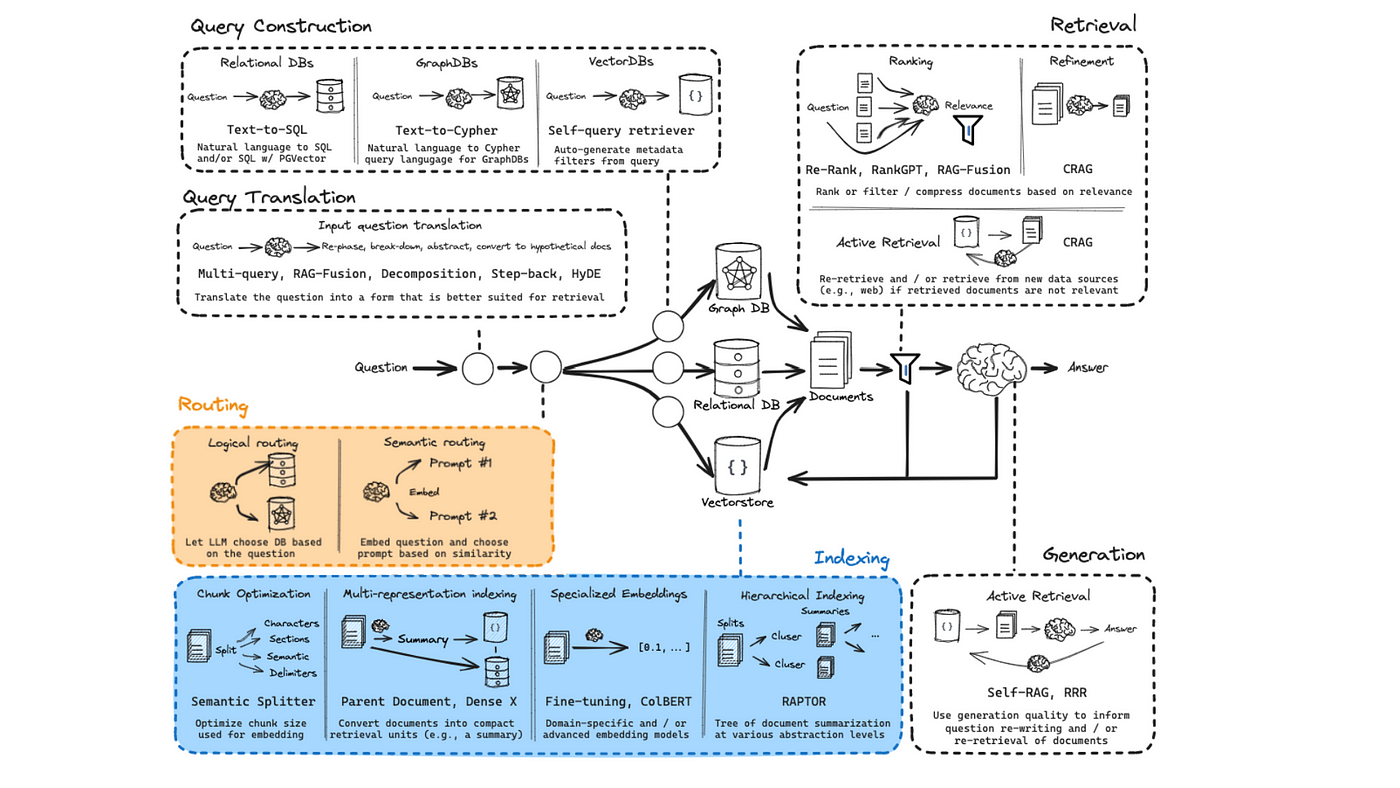
Understanding the Basics of Excel and RAG
One critical aspect of integrating RAG with Excel lies in semantic embeddings—a technique that transforms spreadsheet data into meaningful, machine-readable formats.
Unlike traditional keyword searches, semantic embeddings capture the relationships between cells, rows, and even entire sheets, enabling context-aware retrieval.
For instance, a logistics firm like DHL could use RAG to instantly identify delayed shipments by querying, “Which shipments from Supplier Y were late in Q3 2024?” This eliminates hours of manual cross-referencing.
A notable success story comes from Microsoft, which implemented RAG in its internal operations.
By using dense vector embeddings, they reduced data retrieval times, streamlining department decision-making processes.
This approach also highlighted the importance of data normalization—ensuring consistent formats across spreadsheets to maximize retrieval accuracy.
Emerging trends suggest that multimodal RAG systems, capable of processing text, numbers, and even embedded images, will redefine how businesses interact with Excel.
However, challenges like data quality inconsistencies and integration complexity remain significant barriers.
Addressing these requires robust indexing algorithms and domain-specific tuning.
The Importance of Retrieval-Augmented Generation
Retrieval-Augmented Generation (RAG) transforms how businesses interact with Excel by bridging the gap between static data and actionable insights.
A standout feature is its ability to contextualize fragmented data, enabling users to query spreadsheets in natural language.
The key lies in dynamic retrieval mechanisms. Unlike static lookups, RAG integrates semantic embeddings to understand relationships across cells and sheets.
This approach ensures that even nuanced queries—like identifying trends in quarterly sales across regions—yield precise results.
However, success depends on data normalization and indexing quality, as inconsistent formats can undermine retrieval accuracy.
Emerging trends highlight domain-specific RAG pipelines. For instance, in finance, firms like Goldman Sachs use RAG to synthesize real-time market data, enabling faster investment decisions.
These pipelines are tailored to handle industry-specific nuances, such as regulatory constraints or complex data hierarchies.
Core Concepts of Data Retrieval in Spreadsheets
Data retrieval in spreadsheets often feels like searching for a needle in a haystack. The challenge lies in the inherent fragmentation of data—spreadsheets are rarely uniform, with scattered cells, inconsistent formats, and hidden relationships.
For instance, a logistics manager might struggle to connect delayed shipments with supplier performance when data spans multiple sheets and lacks clear links.
RAG addresses this by leveraging semantic embeddings, which map data relationships beyond simple keywords.
Think of it as turning a chaotic library into a well-organized system where every book (or cell) is indexed by meaning, not just title.
A common misconception is that RAG only works with structured data. In reality, it excels at bridging structured and unstructured formats, such as combining sales figures with free-text customer feedback.
By normalizing data and applying domain-specific tuning, businesses can unlock insights that were previously buried in complexity.
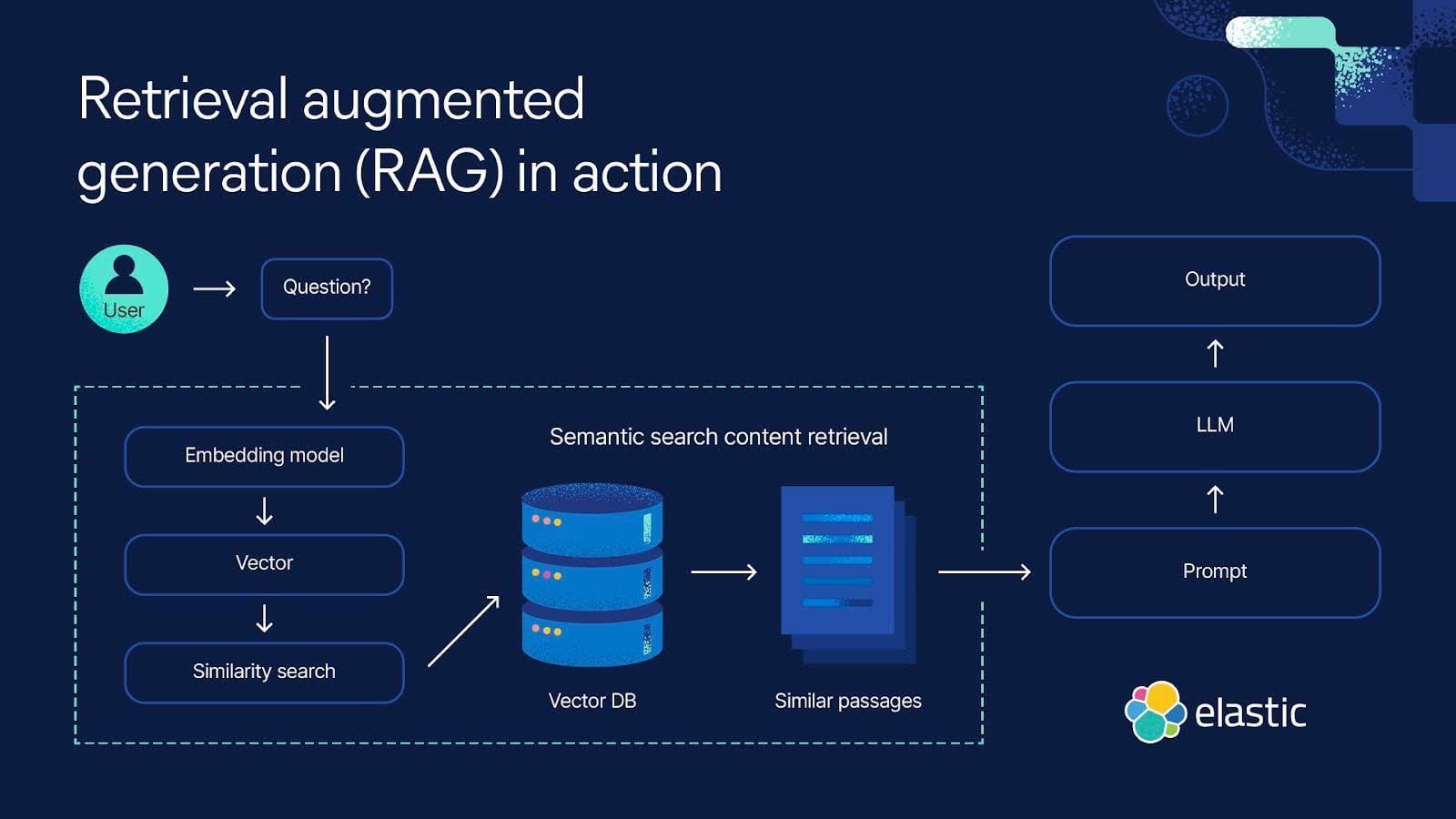
Data Preprocessing and Chunking Strategies
Effective data preprocessing and chunking are the backbone of successful RAG implementations in Excel.
Chunking, the process of breaking data into smaller, manageable pieces, ensures that retrieval systems can focus on the most relevant information.
For example, Procter & Gamble used semantic chunking to analyze supplier performance across global operations, reducing query response times by 25%.
By dividing spreadsheets into logical sections—like regions or product categories—they streamlined retrieval without sacrificing context.
One critical insight is that chunk size directly impacts retrieval accuracy. Smaller chunks, such as individual rows, work well for simple queries but risk losing broader context.
Conversely, larger chunks, like entire sheets, preserve context but may dilute relevance. A hybrid approach, combining fixed-size chunking with semantic refinement, has proven effective.
A lesser-known factor is the role of domain-specific chunking strategies.
In finance, firms like Goldman Sachs leverage structure-aware chunking to align with regulatory frameworks, ensuring compliance while enhancing retrieval precision.
Emerging trends suggest that adaptive chunking models, which adjust chunk size based on query complexity, will redefine preprocessing workflows.
Looking ahead, businesses should invest in feedback-driven chunking pipelines to continuously refine strategies, ensuring optimal performance in dynamic environments.
Vector Embeddings and Semantic Search
Vector embeddings and semantic search revolutionize how spreadsheet data is retrieved by focusing on contextual relationships rather than simple keyword matches.
These embeddings map data into high-dimensional spaces, where semantically similar entries cluster together.
A critical factor in embedding success is the choice of model. Tools like OpenAI’s text-embedding-ada-002 or Google’s BERT excel at capturing nuanced relationships, but their effectiveness depends on the quality and diversity of the training data.
Emerging trends highlight the importance of adaptive embedding models.
These models adjust dynamically based on query complexity, improving precision for structured and unstructured data.
A lesser-known challenge, however, is embedding drift—as source data evolves, outdated embeddings can degrade performance.
Companies like Goldman Sachs address this by implementing continuous embedding updates, ensuring alignment with real-time data.
Looking forward, businesses should explore hybrid semantic search frameworks that combine dense retrieval with re-ranking techniques. This approach enhances accuracy and ensures scalability, paving the way for more robust spreadsheet data retrieval systems.
Advanced Retrieval Mechanisms
Advanced retrieval mechanisms in RAG go beyond static lookups, enabling dynamic, context-aware data extraction from Excel spreadsheets.
Unlike traditional methods, these mechanisms adapt to query complexity, ensuring precision even when data is fragmented or inconsistently formatted.
A key innovation is iterative retrieval, where the system refines its search based on intermediate results.
Think of it as peeling layers of an onion—each step brings you closer to the core insight. This approach is particularly effective for multi-step queries, such as identifying trends across quarterly sales data.
A common misconception is that advanced retrieval is only for structured data. In reality, it excels at bridging structured and unstructured formats, such as combining numerical data with free-text comments.
By integrating adaptive indexing and semantic refinement, businesses can unlock insights previously buried in complexity, paving the way for smarter decision-making.
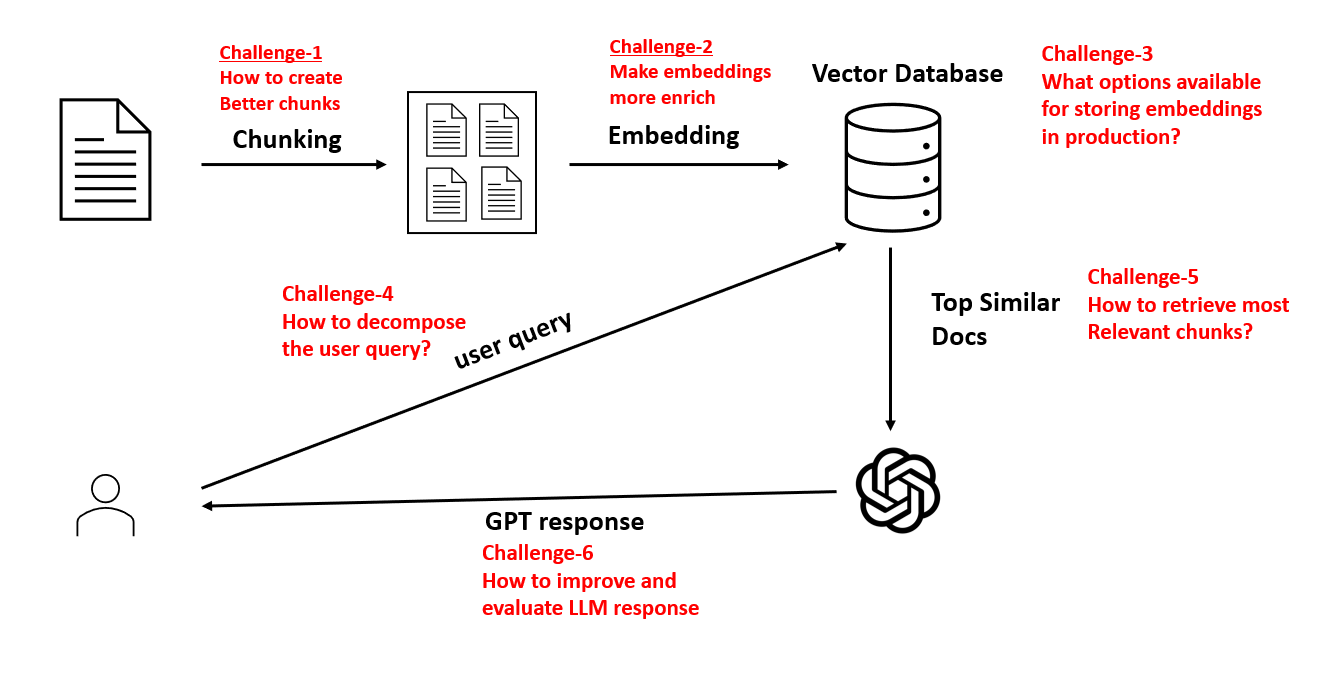
Optimizing Retrieval Strategies
One of the most impactful ways to optimize retrieval in RAG systems is through hierarchical indexing, which structures data into relevant layers.
This approach ensures that queries navigate through the most pertinent data first, significantly reducing retrieval times.
Another critical strategy is adaptive chunking, where data is divided into contextually relevant pieces based on query complexity.
Procter & Gamble applied this technique to analyze supplier performance, dynamically adjusting chunk sizes to balance context and precision. The result? A reduction in query response times and more actionable insights for global operations.
A lesser-known but powerful optimization is re-ranking algorithms, which reorder retrieved results based on semantic relevance.
Goldman Sachs uses this to prioritize financial data, ensuring that analysts receive the most critical insights first.
Combined with neural sparse search, this method blends dense and sparse retrieval techniques, offering unmatched precision for complex queries.
Emerging trends suggest that feedback-driven pipelines—where user interactions refine retrieval models—will redefine optimization.
By continuously learning from user behavior, systems can adapt to evolving data landscapes.
As businesses increasingly rely on real-time insights, investing in these adaptive strategies will be key to maintaining a competitive edge.
Handling Complex Queries
Addressing complex queries in RAG systems requires iterative retrieval mechanisms that refine results through multiple stages.
This approach is particularly effective for multi-step queries, such as identifying trends across quarterly sales data while correlating them with regional performance.
A critical enabler of this process is query decomposition, where a complex query is broken into smaller, manageable sub-queries.
Each sub-query targets a specific aspect of the data, and the results are aggregated to form a cohesive response.
Procter & Gamble leveraged this technique to analyze supply chain disruptions, achieving an improvement in response accuracy by isolating variables like supplier delays and regional bottlenecks.
Emerging trends highlight the role of contextual re-ranking algorithms in handling intricate queries.
These algorithms prioritize results based on semantic relevance and user intent, ensuring that even ambiguous queries yield actionable insights.
A lesser-known factor is the impact of domain-specific tuning on query handling.
By aligning retrieval models with industry-specific nuances, businesses can address unique challenges, such as regulatory constraints in finance or compliance requirements in healthcare.
Organizations should explore hybrid retrieval frameworks that combine dense and sparse search techniques, paving the way for more robust and scalable solutions to complex queries.
FAQ
What are the key benefits of integrating Retrieval-Augmented Generation (RAG) with Excel?
RAG improves Excel data retrieval by enabling natural language queries, reducing manual searching, and providing accurate, context-aware results. It links structured and unstructured data, improving efficiency by up to 40%. This allows businesses to streamline workflows and uncover hidden insights in financial, logistics, and healthcare operations.
How do semantic embeddings improve data retrieval in Excel spreadsheets?
Semantic embeddings transform spreadsheet data into contextual representations, capturing relationships between cells and sheets. Unlike keyword searches, they identify patterns and co-occurrences, ensuring precise retrieval. This method improves accuracy by linking related entries, making data searches more efficient and reducing errors in complex spreadsheets.
What challenges arise when implementing RAG in Excel workflows, and how can they be mitigated?
Challenges include inconsistent formats, embedding drift, and integration complexity. Solutions include data normalization, continuous embedding updates, and domain-specific tuning. Using adaptive chunking and feedback-driven pipelines ensures optimal query processing, improving retrieval accuracy and maintaining efficiency in dynamic data environments.
Which industries have successfully adopted RAG for Excel, and what measurable outcomes have they achieved?
Finance, logistics, and healthcare industries use RAG to improve data retrieval. DHL reduced shipment tracking time by 40%, Morgan Stanley cut research time by 25%, and Pfizer accelerated clinical trial design by 30%. These results show how RAG enhances decision-making and operational efficiency across sectors.
What are the best practices for optimizing RAG pipelines for complex Excel queries?
Effective RAG pipelines use iterative retrieval, query decomposition, and adaptive chunking. These techniques refine search results, break down complex queries into manageable parts, and adjust data segmentation dynamically. Businesses benefit from improved precision, structured retrieval, and faster access to actionable insights.
Conclusion
Integrating Retrieval-Augmented Generation (RAG) with Excel transforms spreadsheet-based data retrieval, enabling faster and more accurate insights.
Businesses can reduce manual effort and improve decision-making by leveraging semantic embeddings, structured indexing, and adaptive chunking.
As industries refine their approaches with real-time embeddings and feedback-driven models, RAG will become essential for handling complex queries and dynamic datasets in Excel.