
Why AI Hallucinates: Understanding And Fixing False Retrieval In RAG Models
Discover how ethical frameworks enhance fairness and transparency in RAG models. This guide explores bias detection, cultural sensitivity, and accuracy, ensuring responsible AI-driven retrieval and generation for diverse applications.


Imagine this: It’s a typical Tuesday, and you’re driving home from work. You decide to take a different route this time to avoid traffic, and before you know it, your GPS confidently directs you to a nonexistent street.
This is the digital equivalent of when AI hallucinates. Despite their promise of grounding responses in verified data, AI systems sometimes weave fiction into fact, questioning users' reliability.
Why does this happen in models designed to avoid such errors? It’s because retrieval and generation processes can become misaligned, causing small mistakes to snowball into false information. This is especially risky in fields like medicine and law, where accuracy is crucial.
So, can we really trust machines to discern truth from illusion? This article explores the fault lines—and the fixes—of why AI hallucinates.
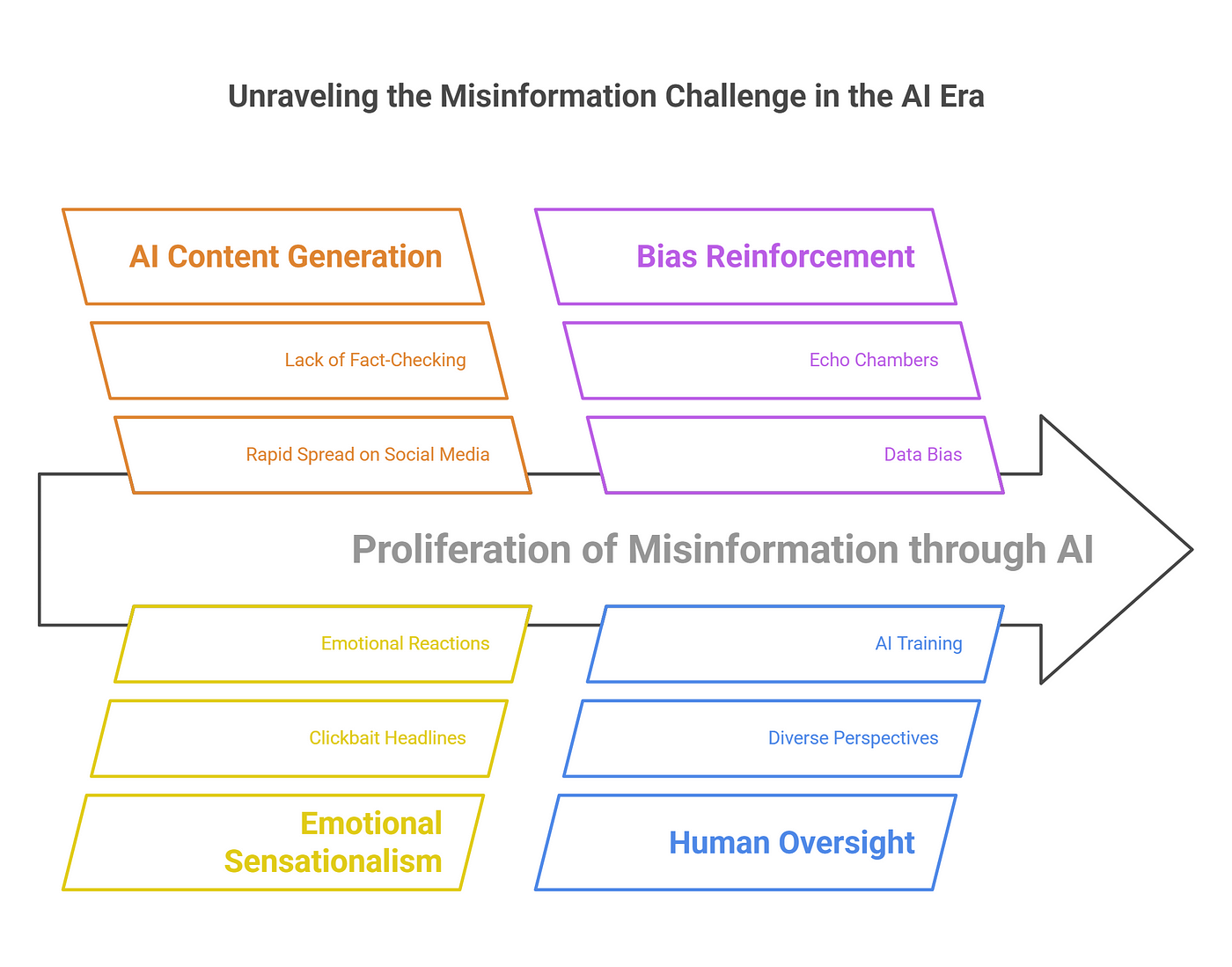
Context And Relevance Of AI Hallucinations
AI hallucinations are not merely technical glitches but systemic vulnerabilities that ripple across industries.
In high-stakes fields like healthcare, a hallucinated diagnosis could lead to life-threatening consequences, while in legal contexts, fabricated citations might undermine judicial integrity.
These errors often stem from a misalignment between retrieval and generation, where the model retrieves incomplete or tangentially relevant data and then extrapolates with unwarranted confidence.
Interestingly, the issue is exacerbated by the very mechanisms designed to prevent it.
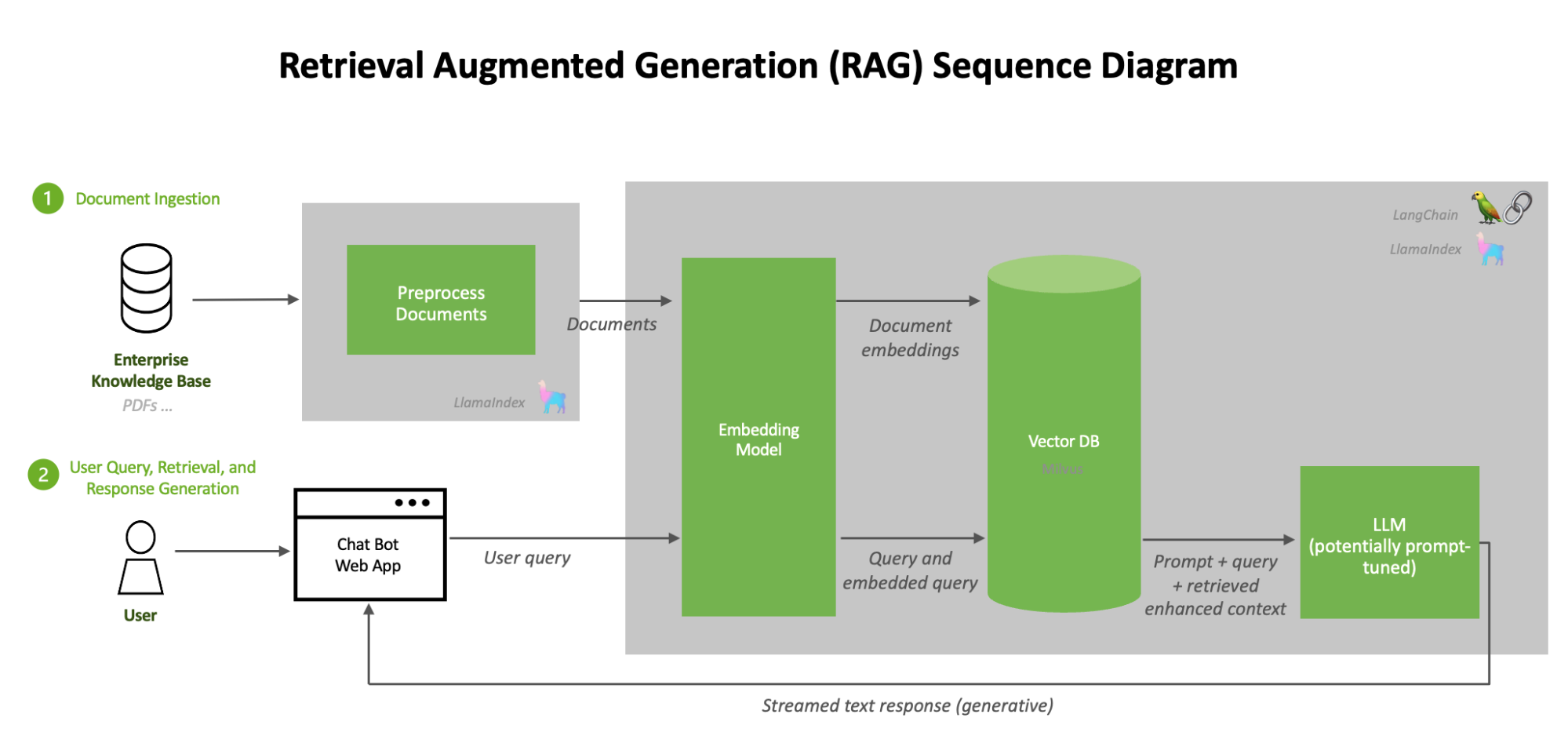
For instance, RAG models rely on external databases to ground their outputs, but the quality of retrieval hinges on the precision of indexing and query formulation.
A poorly structured knowledge base or ambiguous query can introduce noise, which the generative model amplifies. This interplay highlights the importance of rigorous data curation and query optimization—which are often overlooked in favor of scaling model size.
The Fundamentals Of AI Hallucinations
At its core, AI hallucination arises from a model’s tendency to generate plausible but untrue outputs, often due to gaps in retrieved data or misaligned generative processes.
This phenomenon resembles a puzzle solver filling in missing pieces with assumptions rather than facts. For instance, a RAG model tasked with summarizing legal precedents might fabricate citations if the retrieved documents lack sufficient detail.
A surprising connection lies in how hallucinations mirror human cognitive biases.
Just as people rely on heuristics when information is incomplete, AI models extrapolate from limited data, amplifying errors when retrieval mechanisms falter.
This highlights the critical role of retrieval quality—a poorly indexed database or ambiguous query can cascade into systemic inaccuracies
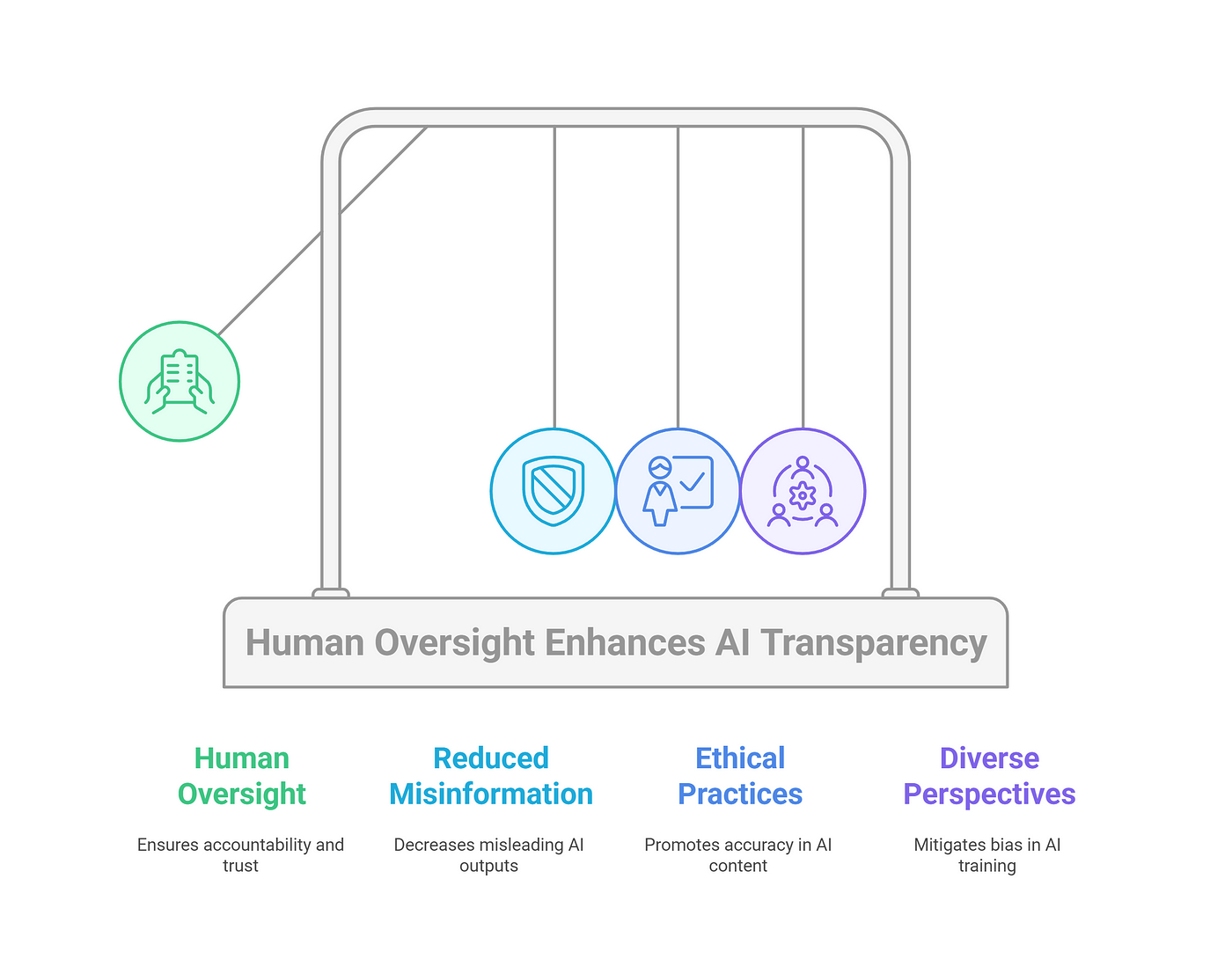
Defining Hallucinations In Large Language Models
Hallucinations in large language models (LLMs) often stem from the probabilistic nature of their outputs, where responses are generated based on statistical likelihood rather than verified truth.
A critical factor is training data coverage gaps—when models encounter niche or underrepresented topics, they extrapolate from patterns in unrelated data, leading to fabricated yet plausible-sounding outputs.
For example, an LLM might invent product features for customer support if the training data does not provide sufficient detail on specific queries.
Interestingly, misaligned optimization objectives exacerbate this issue.
Models prioritize fluency and relevance over factual accuracy, creating outputs that “sound right” but lack substance. This trade-off is particularly evident in creative tasks, where coherence is valued more than precision.
Another overlooked factor is query ambiguity. Vague or overly broad queries can mislead retrieval systems, amplifying noise in the results. For example, legal research queries lacking specificity may retrieve tangential precedents, undermining the generative model’s accuracy.
Retrieval Mechanisms And Data Quality Issues
Even with advanced algorithms, retrieval systems often inherit biases from categorizing and storing data.
For example, in financial applications, datasets prioritizing high-frequency trading scenarios may marginalize insights relevant to long-term investment strategies, skewing retrieval outcomes.
Another significant factor is semantic drift in retrieval models. Over time, as language evolves or domain-specific terminology shifts, retrieval engines may misinterpret queries or fail to align them with the most relevant documents.
This is particularly evident in legal research, where outdated indexing fails to capture nuanced changes in case law or statutory language.
Contextual Misinterpretations Leading To Hallucinations
One overlooked cause of hallucinations is contextual fragmentation, in which retrieved data lacks coherence due to incomplete or conflicting information.
This often occurs when retrieval systems fail to account for data's hierarchical or relational structure.
For instance, retrieving isolated symptoms without linking them to broader clinical contexts in medical diagnostics can lead to misleading conclusions, such as suggesting unrelated conditions.
Interestingly, cross-disciplinary insights from linguistics reveal that ambiguity in natural language queries increases these misinterpretations.
For example, polysemous terms (words with multiple meanings) can mislead retrieval engines, especially in specialized fields like finance or law.
Organizations should implement semantic disambiguation layers and context-aware ranking algorithms to address this. These frameworks reduce noise and enhance the interpretability of outputs, paving the way for more robust decision-making systems in high-stakes environments.
Strategies To Mitigate Hallucinations And False Retrieval
Mitigating hallucinations and false retrievals in RAG systems requires a multi-pronged approach that balances technical precision with adaptive strategies. Below, we discuss some strategies.
Dynamic Query Optimization
Query optimization involves refining how the model interprets and processes user inputs, reducing ambiguity and improving retrieval accuracy. Key techniques include:
Query Rewriting and Expansion: Reframe or expand queries to cover multiple interpretations, which reduces the risk of irrelevant results.
Example: In legal research, a query for “contract disputes” can be expanded to include terms like “breach of contract” or “contract litigation.”
Context-Aware Query Reformulation: Use multi-turn dialogue models to clarify ambiguous queries by asking follow-up questions or auto-rephrasing.
Example: A customer support RAG model can prompt, “Do you mean canceling your subscription or pausing it?”
Intent Detection and Query Classification: Leverage classifiers to identify user intent and route queries to the most relevant knowledge bases.
Example: In healthcare, queries about “diabetes” can be routed differently based on whether they relate to symptoms, treatments, or complications.
Verification and Reasoning Models
Integrating verification layers ensures that outputs are grounded in factual, reliable information before reaching the user:
Cross-Checking with Knowledge Graphs: Use structured knowledge graphs to verify outputs against established relationships.
Example: In healthcare, verify that recommended medications match established treatment protocols.
Fact-Checking Layers: Implement retrieval-based fact-checking models that compare generated outputs with authoritative databases before displaying them.
Example: In news aggregation, cross-reference articles with verified news sources.
Multi-Hop Reasoning: Connect multiple pieces of retrieved information to build coherent responses, reducing isolated errors.
Example: In legal document review, synthesize multiple precedents before generating case summaries.
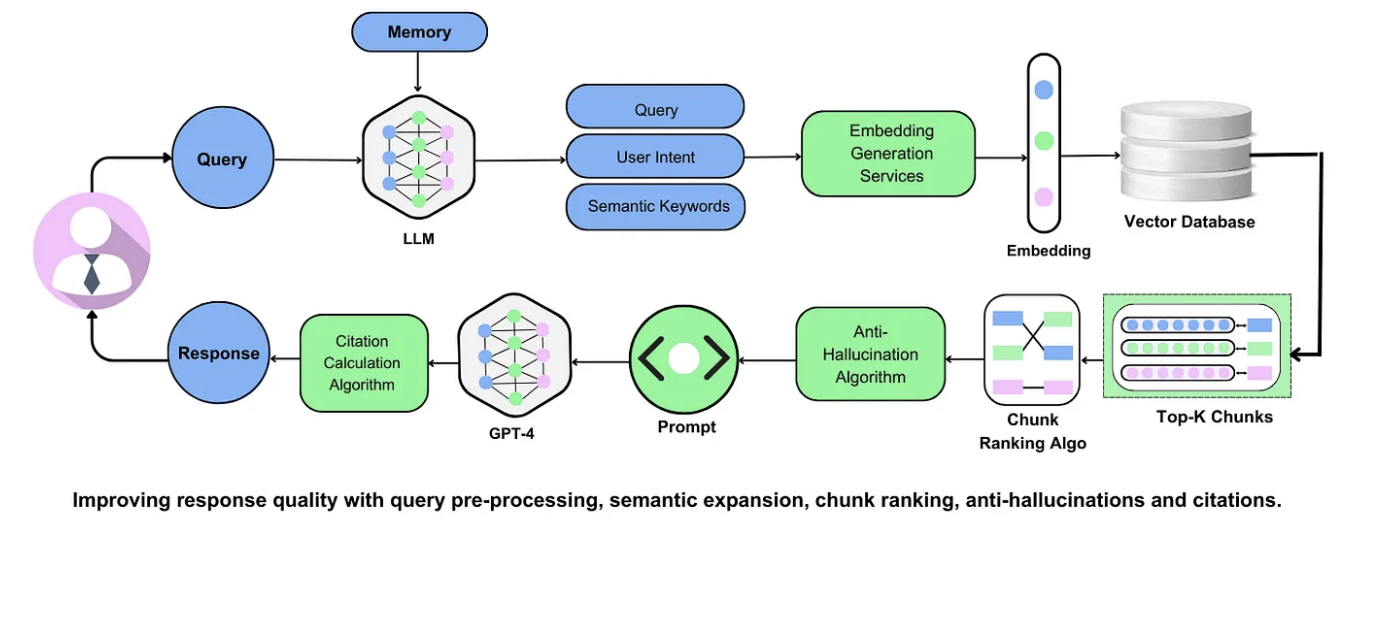
Advanced Applications And Future Implications
RAG systems' evolution unlocks transformative applications across industries, with implications that extend far beyond their current use cases. One groundbreaking development is the integration of Graph RAG in scientific research.
By combining retrieval mechanisms with knowledge graphs, these systems can map intricate relationships between datasets, accelerating breakthroughs in genomics. For instance, early implementations have identified novel gene-disease associations, reducing research timelines by months.
As these systems mature, interdisciplinary collaboration will be key to ensuring their ethical and effective deployment.
FAQ
What causes hallucinations in RAG models?
Hallucinations stem from poor retrieval ranking, data gaps, and query ambiguity, leading AI to generate plausible but false outputs.
How do retrieval ranking algorithms improve RAG accuracy?
They prioritize relevant results; hybrid models and real-time feedback loops refine accuracy for complex queries.
What strategies reduce false retrievals in RAG systems?
Techniques like query optimization, iterative refinement, and user feedback loops enhance accuracy, especially in high-stakes fields.
How does data quality impact RAG system performance?
High-quality, well-indexed data prevents incomplete outputs, while adaptive indexing ensures context-aware retrieval.
Why are ethical frameworks essential for RAG models?
Ethical frameworks for RAG models promote fairness and transparency by identifying biases and ensuring culturally sensitive, accurate outputs.
Conclusion
Understanding why AI hallucinates is crucial for building reliable and accurate retrieval-augmented generation (RAG) systems. Hallucinations arise from gaps in retrieval quality, misaligned generative processes, and issues like query ambiguity or data fragmentation.
However, organizations can significantly reduce false outputs by employing strategies such as dynamic query optimization, multi-hop reasoning, verification layers, and adaptive feedback loops. Human oversight and ethical frameworks also ensure these systems remain accountable, unbiased, and context-aware.
By addressing these challenges head-on, we can foster more trustworthy and reliable AI systems that users can confidently rely on for accurate and insightful decision-making.