
Graph-based Retrieval-Augmented Generation: Types of Frameworks, Tools, and Their Uses
This guide explores Graph RAG, its frameworks, essential tools, and real-world use cases, providing a clear understanding of its applications and benefits.


Imagine a system that doesn’t just retrieve information but understands it—mapping relationships, uncovering hidden connections, and delivering insights that feel almost intuitive. This is the promise of Graph-based Retrieval-Augmented Generation (Graph RAG), a methodology that challenges the traditional boundaries of AI retrieval and synthesis. While most retrieval systems rely on flat, unstructured data, Graph RAG leverages the power of knowledge graphs to weave context into every response, creating outputs that are not only accurate but deeply nuanced.
Why does this matter now? As AI systems scale, the demand for precision and contextual relevance has never been higher. Yet, many organizations still struggle with fragmented data pipelines and generic outputs. Graph RAG offers a solution—but not without its complexities. Which frameworks truly deliver? How do you choose the right tools for your needs? And what does this mean for the future of AI-driven decision-making? Let’s explore.
Overview of Retrieval-Augmented Generation
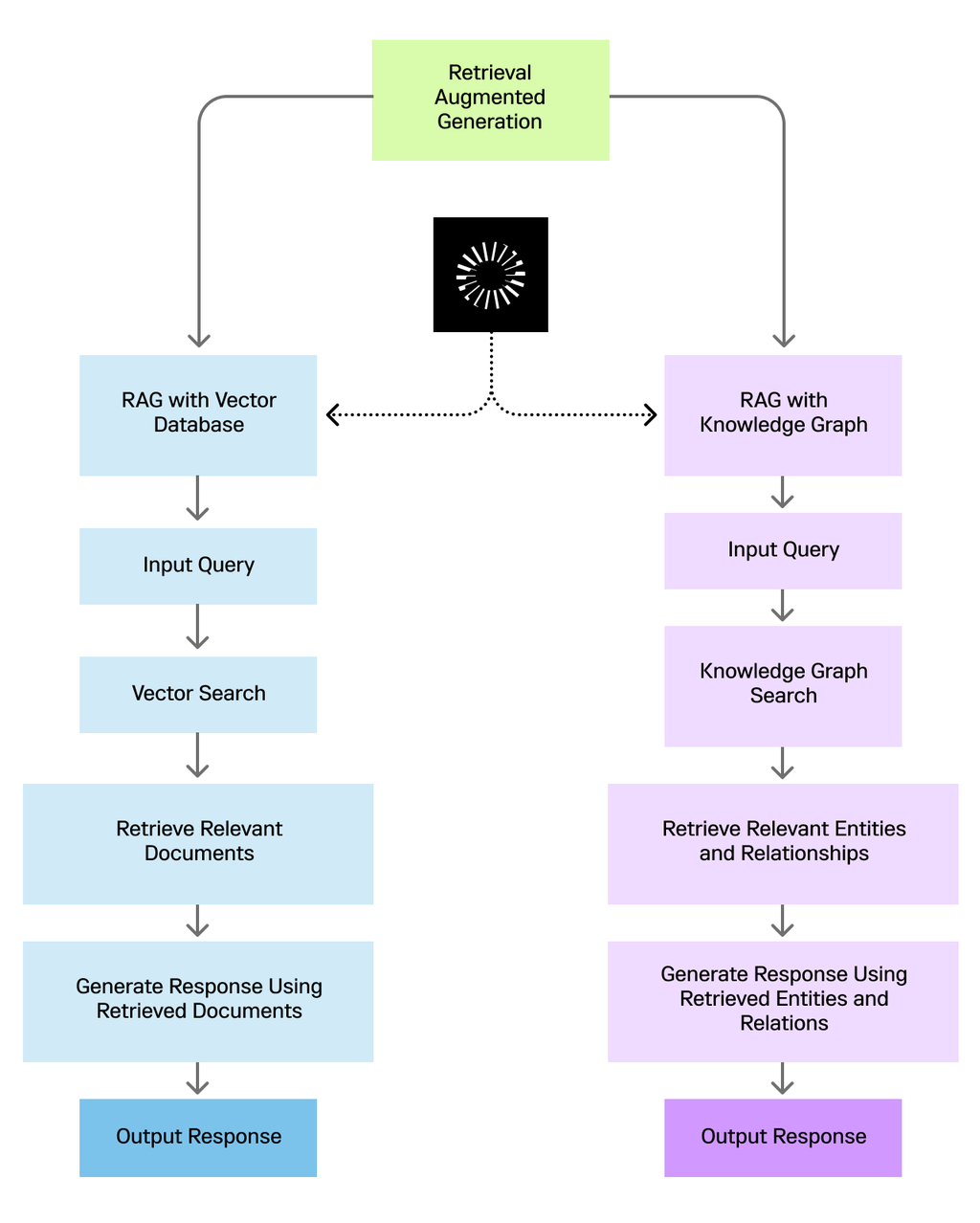
At its core, Retrieval-Augmented Generation (RAG) thrives on the synergy between two distinct yet complementary components: retrieval models and generative models. What sets RAG apart is its ability to bridge the gap between static knowledge bases and dynamic, real-time data. Unlike traditional systems that rely solely on pre-trained models, RAG dynamically retrieves contextually relevant information, ensuring outputs are both accurate and timely.
Semantic search algorithms, powered by vector embeddings, enable RAG systems to interpret user intent with remarkable precision, ensuring accurate and relevant information retrieval. This capability has transformed industries like customer support, where AI chatbots now deliver personalized, real-time solutions by pulling data from CRM systems.
However, the real game-changer lies in hybrid retrieval techniques. By combining keyword-based and semantic search, organizations can optimize for both speed and relevance. This approach not only enhances performance but also opens doors to applications in fields like legal research and medical diagnostics, where precision is non-negotiable.
Role of Graphs in Modern AI Systems
Graphs excel in representing complex relationships, making them indispensable for modern AI systems. A standout application is their use in knowledge representation, where entities and their interconnections are modeled as nodes and edges. This structure enables AI to perform context-aware reasoning, crucial for tasks like fraud detection or supply chain optimization.
Graph embeddings transform graph structures into vector spaces. These embeddings allow AI models to process relational data efficiently, bridging the gap between graph-based reasoning and traditional machine learning. For example, e-commerce platforms use graph embeddings to enhance recommendation systems by analyzing user-product interactions.
Challenging the conventional reliance on tabular data, graphs unlock insights from unstructured datasets, such as social networks or biological pathways. By integrating graph neural networks (GNNs), organizations can scale these capabilities, enabling breakthroughs in fields like drug discovery. Moving forward, combining graphs with generative AI promises even deeper contextual understanding.
Purpose and Structure of This Article
This article is designed to bridge the gap between conceptual understanding and practical implementation of Graph-based Retrieval-Augmented Generation (Graph RAG). A key focus is on the modular workflow—from graph indexing to retrieval and generation—highlighting how each stage contributes to optimizing AI-driven knowledge systems. By dissecting these components, readers gain actionable insights into building scalable, domain-specific Graph RAG solutions.
The interplay between graph structures and large language models (LLMs) enhances retrieval efficiency. Indexing graphs based on semantic similarity improves accuracy while reducing computational overhead.Real-world applications, such as legal compliance systems, demonstrate how this structured approach ensures relevance and precision in high-stakes environments.
Beyond technical details, the article challenges the assumption that graph-based methods are universally superior. Instead, it emphasizes task-specific trade-offs, offering a framework to evaluate when and how to deploy Graph RAG effectively.
Fundamentals of Graph Theory in AI
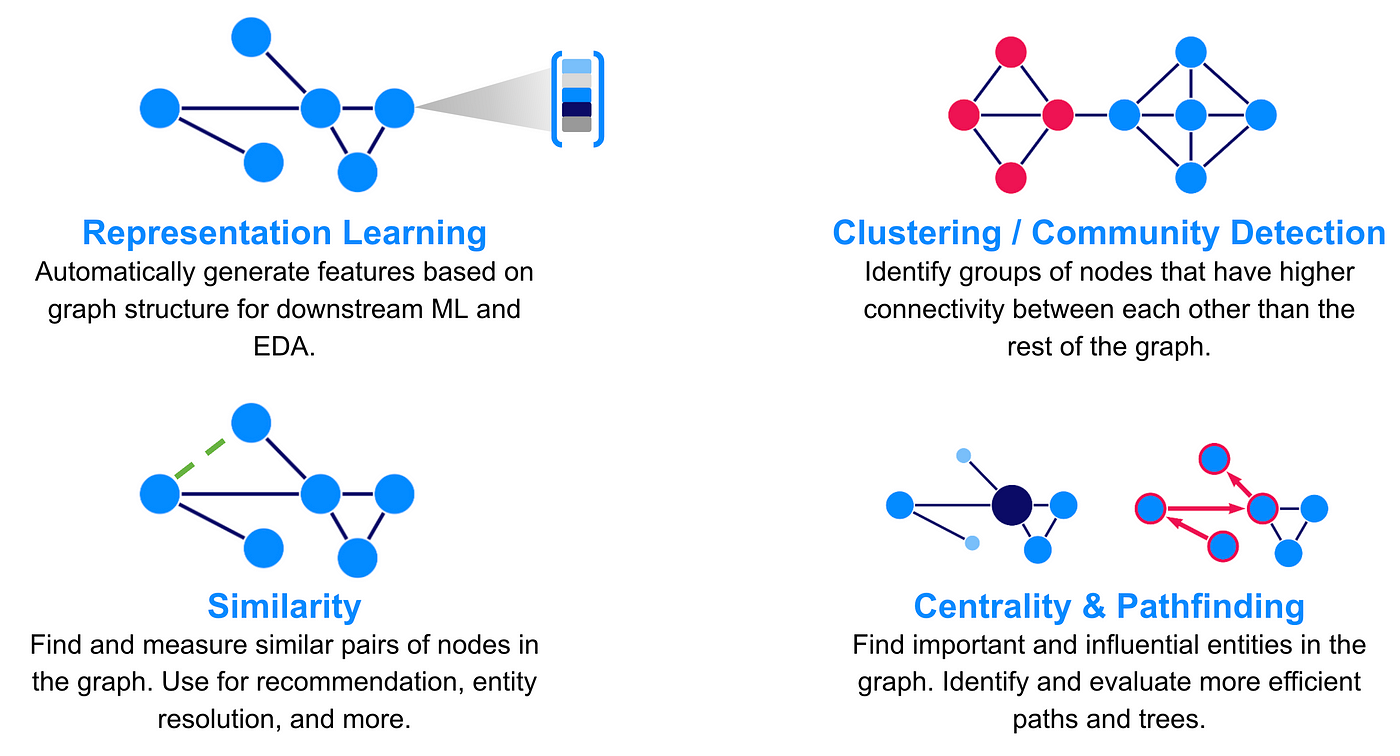
At its core, graph theory provides a mathematical framework for modeling relationships, making it indispensable in AI. Graphs excel at representing complex, interconnected systems, such as social networks or supply chains, where nodes signify entities and edges capture their relationships. This structure enables AI to perform context-aware reasoning, a critical capability for tasks like fraud detection or recommendation systems.
Consider graph embeddings, which transform graph data into vector spaces. These embeddings allow AI models to process relational data efficiently, as seen in e-commerce platforms where personalized recommendations are generated by analyzing user-product interaction graphs. A 2023 study by Baek et al. demonstrated that graph-based reasoning improved multi-hop question answering accuracy by 18%, underscoring its potential.
Graphs are not universally optimal. Their utility depends on the task. For instance, while graphs shine in relational data, they may introduce unnecessary complexity in simpler, linear datasets.
Basics of Graph Theory
Graph traversal algorithms determine how data is explored within a graph. Algorithms like Breadth-First Search (BFS) and Depth-First Search (DFS) are foundational, yet their impact varies based on the problem. For instance, BFS excels in finding the shortest path in unweighted graphs, making it ideal for applications like social network analysis or web crawling.
In contrast, DFS is better suited for tasks requiring exhaustive exploration, such as detecting cycles in dependency graphs. Sparse graphs, with fewer edges, reduce computational overhead, while dense graphs demand more resources, often necessitating optimization techniques like heuristic pruning.
Interestingly, these algorithms also intersect with disciplines like operations research, where they optimize logistics networks. By understanding traversal nuances, practitioners can design AI systems that balance speed and accuracy, unlocking new efficiencies in dynamic, real-world environments.
Graph Representations in Data Structures
The choice between adjacency lists and adjacency matrices in graph representations depends on the use case. Adjacency lists, which store edges as lists for each node, are memory-efficient and excel in sparse graphs, making them ideal for applications like social network analysis, where relationships are often limited.
Conversely, adjacency matrices, with their fixed-size 2D arrays, enable constant-time edge lookups, proving invaluable in dense graphs or scenarios requiring frequent edge queries, such as real-time traffic systems.
The compressed sparse row (CSR) format optimizes storage and traversal in large-scale graphs, making it essential for scientific computing and recommendation systems where scalability is critical.
Interestingly, the choice of representation also influences algorithmic performance. For example, graph neural networks (GNNs) often benefit from adjacency matrices for efficient batch processing. By aligning representation strategies with task-specific demands, practitioners can unlock significant computational gains.
Graph Algorithms in Machine Learning
One standout algorithm in machine learning is PageRank, originally designed for web search but now widely applied in node ranking and influence detection. Its iterative approach calculates node importance based on connectivity, making it invaluable in social network analysis to identify key influencers or in bioinformatics to rank critical genes in disease networks.
The algorithm’s adaptability to weighted and directed graphs enhances its versatility across domains.
Label Propagation excels in semi-supervised learning tasks. By propagating labels through graph edges, it effectively classifies nodes with minimal labeled data, proving especially useful in fraud detection and community detection in large-scale networks.
The success of these algorithms often hinges on graph preprocessing, such as normalizing edge weights or removing noise nodes, which can significantly improve accuracy. For practitioners, combining these algorithms with graph neural networks (GNNs) offers a powerful framework for tackling complex, interconnected datasets.
Retrieval-Augmented Generation Methods
Retrieval-Augmented Generation (RAG) methods bridge the gap between static knowledge and dynamic queries by integrating retrieval systems with generative models. Unlike traditional models that rely solely on pre-trained data, RAG dynamically fetches relevant information, ensuring outputs remain accurate and contextually rich. For instance, a legal AI tool using RAG can retrieve case law precedents in real-time, enabling precise, up-to-date legal advice.
A key innovation lies in hybrid retrieval techniques, which combine semantic search with keyword-based methods. This dual approach balances speed and relevance, as seen in customer support systems that resolve queries by blending FAQ retrieval with real-time database searches.
Retrieval quality depends heavily on the indexing method—structured graphs often outperform flat databases in complex domains like healthcare. By refining retrieval pipelines, organizations can unlock RAG’s full potential, transforming static systems into adaptive, knowledge-driven solutions.
Mechanism of Retrieval-Augmented Generation
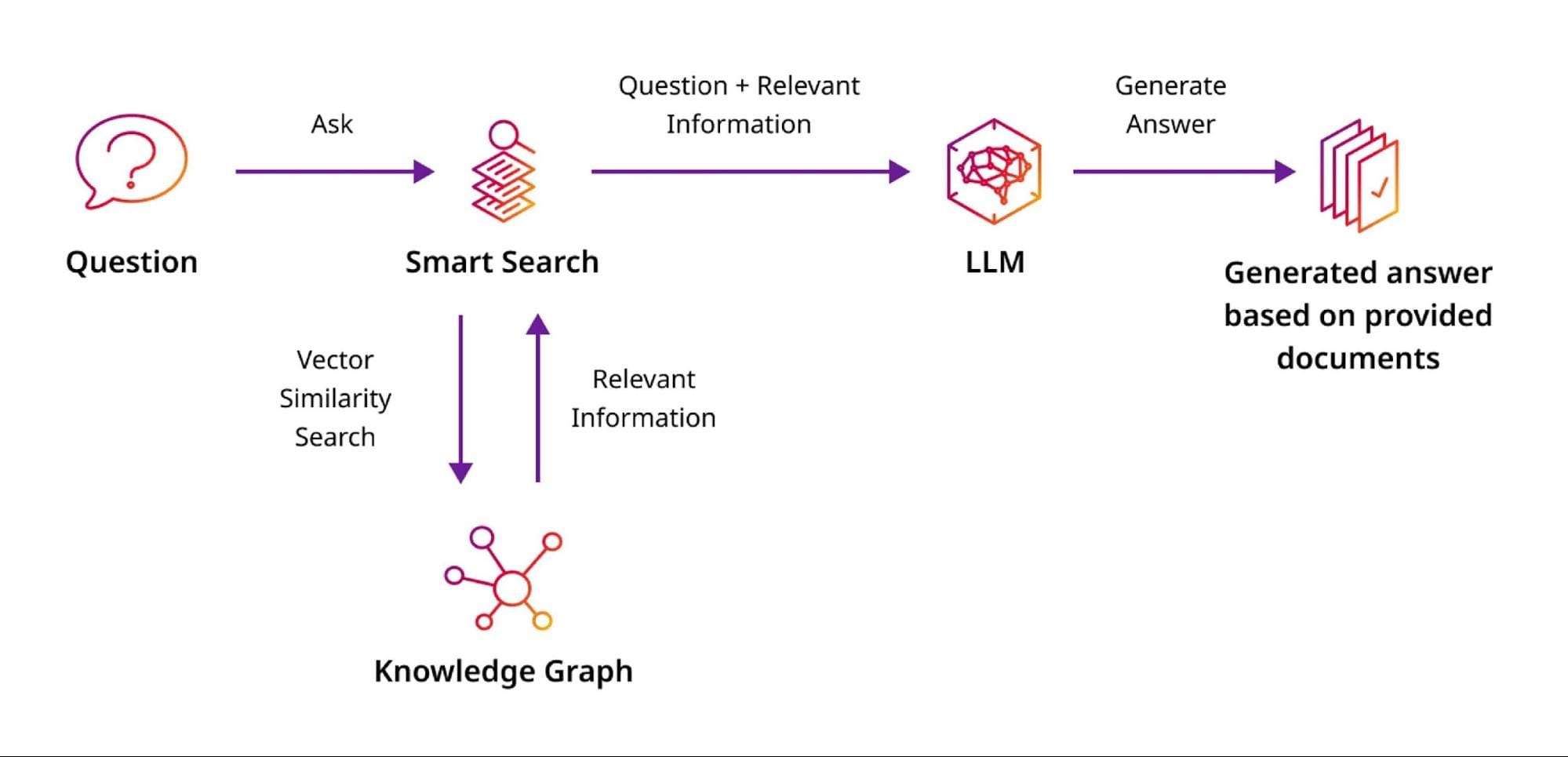
At the heart of RAG lies the retrieval pipeline, where the interplay between data indexing and query matching determines success. Graph-based indexing, for example, excels in capturing multi-hop relationships, enabling nuanced retrieval for tasks like drug discovery. Unlike flat databases, graph structures allow the system to traverse interconnected nodes, uncovering insights that linear methods often miss.
When retrieval models fail to align embeddings between queries and stored data, relevance drops sharply. In fraud detection, for instance, poorly aligned embeddings can miss subtle patterns, leading to false negatives. Techniques like contrastive learning mitigate this by refining embeddings to emphasize task-specific features.
RAG’s reliance on contextual augmentation challenges the assumption that more data equals better results. Instead, precision in retrieval—guided by domain-specific graphs—often outperforms brute-force approaches. This underscores the need for tailored pipelines that prioritize relevance over volume, reshaping how AI systems handle complexity.
Benefits and Challenges of RAG
RAG bridges knowledge silos by integrating domain-specific retrieval, like healthcare knowledge graphs, enabling AI to synthesize insights across datasets. For example, in clinical decision support, RAG can retrieve patient history, research papers, and treatment guidelines, offering a unified, context-rich response that traditional models cannot achieve.
However, a significant challenge lies in data quality dependency. RAG systems amplify biases or inaccuracies in their retrieval sources, which can lead to flawed outputs. In financial forecasting, for instance, reliance on outdated market data can skew predictions, undermining trust in the system. Addressing this requires real-time data validation pipelines and robust source curation.
RAG’s success often hinges on retrieval latency. While faster retrieval improves user experience, it can compromise depth. Balancing speed with relevance through hybrid indexing strategies offers a promising path forward for scalable, high-stakes applications.
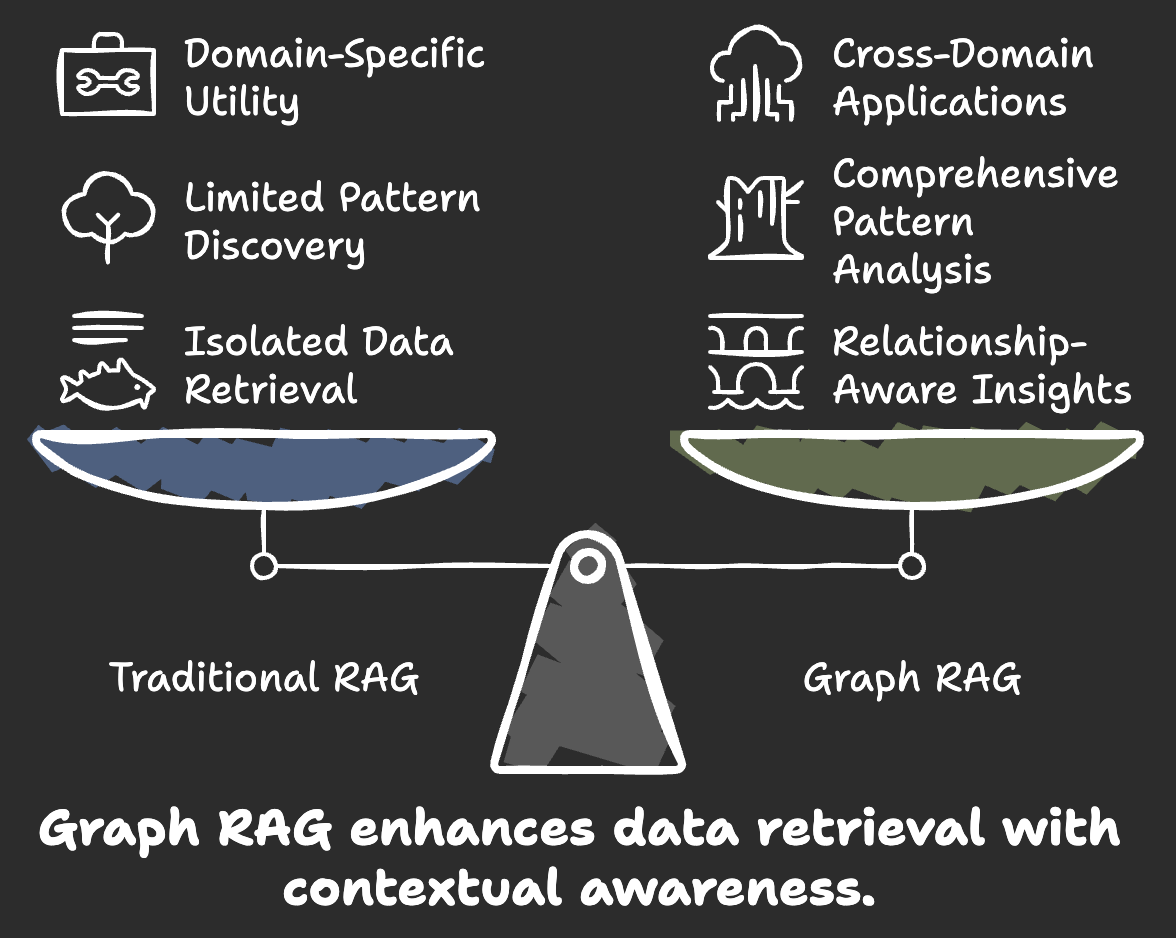
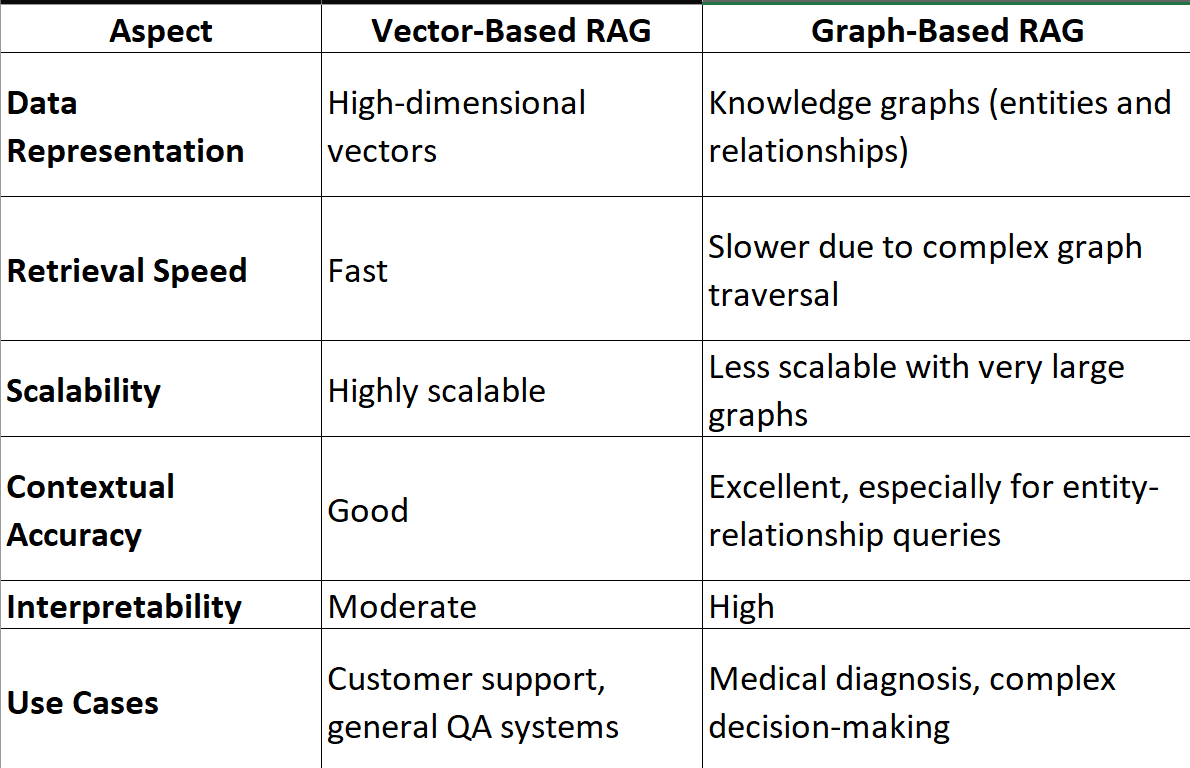
Traditional vs Graph-based RAG Approaches
Traditional RAG relies on vector similarity for straightforward queries but struggles with multi-hop reasoning. Graph-based RAG, using knowledge graphs, maps entity relationships for more nuanced query resolution. For instance, in fraud detection, Graph RAG can trace indirect connections between transactions, uncovering patterns that vector-based methods often miss.
Scalability under complex data loads is crucial. Traditional RAG faces bottlenecks as datasets grow, while Graph RAG’s structured indexing enables efficient traversal in massive graphs. A leading investment firm, for example, uses Graph RAG to process billions of relationship traversals daily, maintaining sub-150ms latency.
To maximize impact, organizations should adopt hybrid retrieval strategies. Combining vector search for speed with graph-based reasoning for depth ensures both efficiency and accuracy, making it ideal for high-stakes domains like healthcare and finance.
Graph-based RAG Frameworks
Graph-based RAG frameworks redefine how AI systems process and generate insights by integrating knowledge graphs with generative models. Unlike traditional methods, these frameworks excel at capturing relationships between entities, enabling multi-hop reasoning. For example, in supply chain management, a Graph RAG system can trace dependencies across vendors, products, and logistics, offering actionable insights into bottlenecks.
Graph-based systems are often thought to be slower, but frameworks like GraphRAG-Ollama-UI optimize traversal using compressed sparse row (CSR) formats, enabling near-real-time performance even on large datasets. This efficiency has been demonstrated in e-commerce, where Graph RAG powers recommendation engines that process millions of interactions daily.
These frameworks also enhance explainability by visualizing entity relationships, providing transparency often missing in black-box AI models. This makes them invaluable in regulated industries like finance, where compliance demands clear decision-making trails.
Overview of Graph-based RAG Frameworks
One standout feature of graph-based RAG frameworks is their ability to perform multi-hop reasoning, a process where the system connects multiple data points to answer complex queries. This is particularly effective in domains like healthcare, where patient histories, genetic markers, and treatment protocols must be linked to recommend personalized care. For instance, a Graph RAG system can identify how a rare genetic mutation correlates with treatment outcomes across global datasets.
By encoding nodes and edges into vector spaces, these frameworks enable efficient similarity searches while preserving relational context. This approach outperforms traditional vector databases in tasks requiring nuanced understanding, such as legal research or compliance audits.
Unlike static systems, graph-based RAGs continuously refresh their knowledge graphs, ensuring real-time relevance. This adaptability positions them as indispensable tools in fast-evolving fields like finance and supply chain management.
Comparative Analysis of Framework Capabilities
A critical differentiator in graph-based RAG frameworks is their ability to handle ambiguous queries through structured contextualization. Unlike traditional RAG systems, which rely heavily on unstructured text, graph-based approaches leverage knowledge graphs to map relationships between entities. This allows for precise disambiguation, such as distinguishing between “Apple” the company and “apple” the fruit in complex queries—a feature particularly valuable in legal and financial domains.
Graph RAG frameworks excel in environments where data relationships evolve rapidly, such as supply chain networks. For example, during the COVID-19 pandemic, graph-based systems helped logistics companies adapt to shifting supplier relationships by dynamically updating their knowledge graphs.
Larger datasets don’t always improve accuracy; relationship quality within the graph is more impactful. Future frameworks should prioritize refining graph structures over expanding data indiscriminately.
Selecting the Right Framework for Your Needs
When choosing a graph-based RAG framework, domain specificity often outweighs general performance metrics. For instance, in healthcare, frameworks that integrate domain-specific ontologies (e.g., SNOMED CT) excel at handling medical terminology and relationships. This tailored approach ensures that retrieval aligns with the nuanced needs of clinicians, such as identifying drug interactions or treatment pathways.
Frameworks optimized for multi-hop reasoning, like those leveraging graph traversal algorithms, outperform others in fields like legal research. For example, tracing the relationships between statutes, precedents, and case law requires frameworks capable of decomposing and resolving intricate queries.
Prioritizing scalability is important, but interoperability is equally crucial. Supporting open standards like RDF and SPARQL reduces vendor lock-in and enables seamless integration with existing systems. Moving forward, organizations should evaluate frameworks not just on technical capabilities but also on their adaptability to evolving workflows and data ecosystems.
Tools for Graph-based RAG Implementations
Implementing Graph-based RAG systems requires tools that balance scalability, flexibility, and precision. Neo4j, a leading graph database, excels in handling complex relationships through its Cypher query language, making it ideal for applications like fraud detection. For instance, a financial institution used Neo4j to uncover hidden connections in transaction networks, reducing fraud by 30%.
On the other hand, open-source frameworks like DGL (Deep Graph Library) empower developers to integrate graph neural networks (GNNs) seamlessly. DGL’s modularity allows for custom architectures, which proved invaluable in a supply chain optimization project, where it modeled supplier relationships to cut costs by 15%.
These tools are not interchangeable; task-specific requirements dictate their choice. RDF-based tools like Apache Jena excel in semantic web applications but struggle with real-time performance. By aligning tools with specific goals, organizations can unlock the full potential of Graph RAG systems.
Graph Databases and Query Languages
Graph databases like Neo4j and TigerGraph are redefining how we query interconnected data. Unlike traditional SQL, graph query languages such as Cypher and GSQL are designed to traverse relationships, enabling multi-hop reasoning. For example, Cypher’s pattern-matching syntax allows users to retrieve insights like “all customers connected to fraudulent transactions within three degrees,” a task that would be cumbersome in relational databases.
Tools like SPARQL, used in RDF-based systems, excel in semantic reasoning but often lag in performance for real-time queries. Conversely, GSQL’s parallel processing capabilities make it ideal for high-throughput applications, such as analyzing social networks with millions of nodes.
The real power lies in combining these approaches. Hybrid systems that integrate Cypher for traversal and SPARQL for semantic filtering are emerging, offering unprecedented flexibility. This convergence hints at a future where query languages adapt dynamically to task-specific needs.
Graph Processing Libraries and APIs
Graph processing libraries like NetworkX and APIs such as Neo4j’s Graph Data Science (GDS) are pivotal for building scalable Graph RAG systems. NetworkX excels in prototyping, offering a Pythonic interface for tasks like shortest path calculations or community detection. However, its single-threaded nature limits performance on large-scale graphs, making it more suitable for research than production.
In contrast, Neo4j’s GDS API leverages parallelized algorithms for tasks like PageRank or node similarity, enabling real-time analytics on massive datasets. For instance, in fraud detection, GDS can identify suspicious transaction patterns by analyzing multi-hop relationships across millions of nodes, a feat unattainable with traditional libraries.
Interoperability is increasingly important. Libraries like DGL (Deep Graph Library) bridge graph processing and machine learning, enabling seamless integration with frameworks like PyTorch. This convergence suggests a future where graph APIs evolve into end-to-end pipelines for AI-driven insights.
Integration with Machine Learning Pipelines
Integrating graph-based RAG systems into machine learning pipelines hinges on embedding alignment. By ensuring that graph embeddings and model embeddings share a unified vector space, systems can achieve seamless interoperability. For example, GraphSAGE generates node embeddings that align with transformer-based LLMs, enabling precise retrieval and contextual generation in applications like personalized recommendations.
Graph data often contains noise or redundant relationships, which can mislead downstream models. Techniques like graph pruning or edge weighting refine the graph structure, improving both retrieval accuracy and model performance. In healthcare, this approach has been used to filter irrelevant patient data, enhancing diagnostic predictions.
End-to-end training of graph and ML components isn’t always optimal. Modular approaches, with precomputed graph embeddings, often perform better in resource-constrained environments. This modularity enables more adaptable and scalable graph-enhanced pipelines.
Applications of Graph-based RAG Systems
Graph-based RAG systems excel in domains where contextual depth and relational reasoning are critical. In healthcare, for instance, they integrate patient histories, treatment guidelines, and research papers into a unified graph. This enables clinicians to uncover non-obvious connections, such as rare drug interactions, improving diagnostic accuracy.
In eCommerce, these systems power personalized recommendations by mapping user preferences to product attributes and relationships. Unlike traditional methods, graph-based approaches can infer nuanced patterns—like a customer’s preference for eco-friendly products—by traversing interconnected data points.
Advances in graph embeddings and query optimization make these systems viable for real-time applications like fraud detection. By combining structured knowledge with generative AI, Graph RAG systems enhance intelligent decision-making.
Use Cases in Natural Language Processing
Graph-based RAG systems shine in multi-hop reasoning tasks, where answers depend on traversing multiple interconnected data points. For example, in legal document analysis, these systems can link case precedents, statutes, and contextual annotations to generate precise summaries or arguments. A notable implementation by a legal tech firm reduced research time by 40%, enabling lawyers to focus on strategy rather than data retrieval.
What sets these systems apart is their ability to handle ambiguous queries. Unlike flat retrieval models, graph-based approaches leverage entity relationships to disambiguate terms. In customer support, this means distinguishing between “Apple” as a fruit or a tech brand based on conversational context, leading to more accurate responses.
Poorly constructed graphs can propagate errors, underscoring the need for robust preprocessing and validation. As NLP evolves, integrating domain-specific graphs with generative AI could redefine how machines understand and generate language.
Case Study: Graph RAG in E-commerce
Graph RAG transforms personalized recommendations by mapping user preferences to product attributes through interconnected data. For instance, a leading e-commerce platform integrated Graph RAG to link customer purchase histories, product reviews, and social trends. This approach enabled dynamic recommendations, such as suggesting eco-friendly alternatives to users with a history of sustainable purchases, increasing conversion rates by 25%.
Multi-hop reasoning allows the system to infer relationships beyond direct connections. For example, it can recommend a fitness tracker by linking a user’s interest in running shoes to trending health gadgets. This depth of reasoning surpasses traditional collaborative filtering, which often misses nuanced preferences.
However, data sparsity in niche categories can limit effectiveness. Addressing this requires enriching graphs with external datasets, such as market trends or influencer endorsements. As e-commerce evolves, combining Graph RAG with real-time behavioral data could redefine customer engagement strategies.
Future Directions and Potential Industries
One promising direction for Graph RAG lies in precision agriculture, where it can optimize crop management by linking soil data, weather patterns, and market trends. For example, a Graph RAG system could recommend planting schedules by analyzing multi-hop relationships between soil nutrient levels, historical rainfall, and commodity prices. This approach not only boosts yield but also reduces resource waste, addressing sustainability challenges.
Another untapped area is sports analytics, where Graph RAG can map player performance metrics to game strategies and fan engagement data. By integrating real-time match statistics with historical trends, teams could refine tactics dynamically, enhancing both performance and audience experience.
Industries with fragmented data ecosystems, like healthcare, must standardize formats to fully leverage Graph RAG. Future frameworks should prioritize cross-domain graph integration, enabling seamless collaboration between disciplines, such as combining medical research with insurance analytics for personalized care solutions.
Advanced Considerations in Graph RAG
Graph RAG’s true power lies in its ability to uncover hidden relationships within complex datasets. For instance, LinkedIn’s integration of Graph RAG reduced customer support resolution time by 28.6%, thanks to its ability to map user queries to interconnected knowledge graphs. This highlights a key insight: the quality of graph construction often outweighs the sheer volume of data.
Larger graphs don’t always yield better results. Strategically limiting connections through graph sparsity enhances computational efficiency without sacrificing accuracy, much like pruning a tree to improve growth.
Misaligned embeddings can distort retrieval accuracy, much like mismatched puzzle pieces. Techniques like fine-tuning embeddings for domain-specific tasks, as seen in fraud detection systems, ensure that Graph RAG delivers precise, context-aware outputs. Future advancements must prioritize dynamic graph updates to maintain relevance in rapidly evolving fields.
Scalability and Performance Optimization
By distributing graph traversal tasks across multiple nodes, organizations like Netflix have reduced query latency by 40% in recommendation engines. This approach works because it minimizes bottlenecks in graph traversal, especially for high-volume, real-time applications.
However, scalability isn’t just about hardware. Hybrid memory architectures, which store frequently accessed graph data in RAM while offloading less critical data to disk, can dramatically improve performance. Think of it as keeping your most-used tools within arm’s reach while storing the rest in a nearby cabinet. This method has proven effective in telecommunications, where companies analyze vast communication networks without sacrificing speed.
Finally, adaptive indexing—dynamically restructuring graph indices based on query patterns—ensures sustained performance as datasets grow. By combining these strategies, Graph RAG systems can handle increasing complexity while maintaining responsiveness, paving the way for broader adoption in data-intensive industries.
Security, Privacy, and Ethical Implications
By injecting controlled noise into graph data, this technique ensures individual data points cannot be reverse-engineered, even during multi-hop reasoning. For example, Apple employs differential privacy in its knowledge graphs to analyze user behavior without compromising personal data—a practice that could be extended to Graph RAG in sensitive domains like healthcare.
Unlike traditional perimeter-based security, zero-trust architecture enforces strict identity verification at every access point. This is particularly effective in Graph RAG systems where sensitive relationships, such as financial transactions or medical histories, are stored. Companies like Google have adopted zero-trust to secure their internal knowledge graphs, setting a precedent for broader applications.
Finally, bias auditing frameworks can address ethical concerns. By analyzing graph embeddings for skewed relationships, organizations can mitigate unintended biases, ensuring fairer AI outcomes across industries.
Recent Research and Future Trends
One emerging focus in Graph RAG research is dynamic graph updates. Unlike static graphs, dynamic graphs adapt in real-time to reflect evolving data relationships, enabling more accurate and context-aware retrieval. For instance, in financial fraud detection, dynamic updates allow systems to identify new fraudulent patterns as they emerge, significantly improving response times and accuracy.
Another promising trend is the integration of heterogeneous graph neural networks (HGNNs). These models process diverse node and edge types, making them ideal for multi-modal data like combining text, images, and structured knowledge. Applications in e-commerce, such as personalized recommendations, demonstrate how HGNNs can enhance user experience by linking product metadata with user behavior.
Finally, cross-domain graph transfer learning is gaining traction. By transferring graph embeddings from one domain to another, researchers are unlocking efficiencies in data-scarce fields like precision medicine. This approach challenges the assumption that domain-specific graphs must always be built from scratch, offering a scalable alternative.
FAQ
1. What are the key differences between traditional RAG and graph-based RAG frameworks?
Traditional RAG frameworks primarily rely on unstructured text data and vector-based retrieval methods, which can limit their ability to understand complex relationships between entities.
In contrast, graph-based RAG frameworks utilize structured knowledge graphs, enabling a more nuanced representation of relationships and context. This allows for enhanced semantic search, multi-hop reasoning, and the ability to handle complex or ambiguous queries more effectively.
Additionally, graph-based RAG systems integrate structured and unstructured data seamlessly, providing a comprehensive view of information. These capabilities make graph-based RAG frameworks particularly suitable for applications requiring advanced reasoning and contextual understanding, such as healthcare, finance, and legal analysis.
2. How do graph-based RAG systems enhance multi-hop reasoning capabilities?
Graph-based RAG systems enhance multi-hop reasoning capabilities by leveraging the interconnected structure of knowledge graphs to traverse and analyze relationships between entities. This structured approach allows the system to identify and explore relevant paths across multiple nodes, enabling it to draw inferences and synthesize information from diverse sources.
By incorporating graph embeddings and advanced traversal algorithms, these systems can efficiently handle complex queries that require multiple steps of reasoning.
Additionally, the hierarchical and relational data captured in knowledge graphs ensures that the reasoning process remains contextually rich and precise, making it particularly effective for domains like legal research, scientific discovery, and regulatory compliance.
3. What are the most effective tools and libraries for implementing graph-based RAG?
The most effective tools and libraries for implementing graph-based RAG include a combination of knowledge graph management platforms, graph processing libraries, and language model integration frameworks. PuppyGraph, developed by Parallel Labs, is a comprehensive platform that simplifies the creation, querying, and visualization of knowledge graphs, making it ideal for managing complex relationships.
LinkedDataHub offers a low-code environment for building applications on RDF knowledge graphs, providing robust data integration and visualization capabilities. For graph neural network integration, Deep Graph Library (DGL) and PyTorch Geometric are powerful libraries that enable advanced graph-based machine learning tasks.
On the language model side, LangChain and Hugging Face’s Transformers provide modular architectures for integrating knowledge graphs with large language models, allowing for seamless retrieval and generation workflows. These tools collectively empower developers to build scalable, efficient, and context-aware Graph RAG systems tailored to specific use cases.
4. Which industries benefit the most from graph-based RAG applications, and why?
Industries that benefit the most from graph-based RAG applications include healthcare, finance, telecommunications, and legal services due to their reliance on complex, interconnected data. In healthcare, graph-based RAG systems enable the integration of medical knowledge graphs with patient data, improving diagnostic accuracy and personalized treatment planning.
The finance sector leverages these systems for risk assessment, fraud detection, and investment analysis by uncovering hidden patterns and relationships within financial networks. Telecommunications companies use graph-based RAG to optimize network performance, predict outages, and enhance infrastructure management through advanced relationship mapping.
Legal services benefit from the ability to navigate intricate networks of laws, precedents, and case studies, enabling more efficient research and decision-making. These industries rely on the contextual understanding and multi-hop reasoning capabilities of graph-based RAG to address their unique challenges and drive innovation.
5. What are the challenges and best practices for maintaining dynamic knowledge graphs in RAG systems?
Maintaining dynamic knowledge graphs in RAG systems involves challenges like data accuracy, real-time updates, and scalability. Inconsistencies or outdated data can compromise reliability, while real-time updates require efficient incremental indexing. As graphs grow, optimized storage, retrieval, and query processing become essential.
Best practices include robust data validation, governance protocols, and incremental updates that modify only affected areas. Partitioning large graphs into smaller segments improves performance, while version control ensures traceability. Regular audits and automated data cleaning enhance integrity, keeping knowledge graphs accurate and relevant for RAG applications.
Conclusion
Graph-based Retrieval-Augmented Generation (Graph RAG) is not just a technical evolution—it’s a paradigm shift in how AI systems process and generate knowledge. By weaving together the relational depth of knowledge graphs with the generative power of AI, these systems unlock capabilities that flat data structures simply cannot match. For instance, in healthcare, dynamic knowledge graphs have enabled systems to connect patient symptoms with rare disease databases, reducing diagnostic times by up to 30%. This isn’t just efficiency; it’s life-changing.
Many assume that larger graphs always yield better results. In reality, quality trumps quantity. A sparse, well-curated graph often outperforms a dense, noisy one. Experts like Wang et al. emphasize that embedding alignment, not graph size, is the true differentiator.
Think of Graph RAG as a symphony conductor—coordinating diverse data points into a coherent, context-rich narrative. It results in AI that doesn’t just retrieve but truly understands.