
How Graph-Based Retrieval (GraphRAG) Improves Information Discovery
GraphRAG improves information discovery by mapping relationships between data points, enabling deeper context and more accurate retrieval. This guide explores how graph-based retrieval enhances RAG systems for smarter, structured knowledge access.


Ever ask a system a complex question and get scattered, half-relevant answers?
That’s the limit of traditional retrieval methods. They treat each piece of information in isolation, missing the bigger picture.
Graph-Based Retrieval (GraphRAG) fixes that. It doesn’t just find facts—it maps how things connect.
Whether you’re looking at legal documents, research papers, or financial data, GraphRAG helps you discover how information fits together, not just where it exists.

Limitations of Traditional Retrieval-Augmented Generation
Traditional RAG systems often falter when tasked with multi-hop reasoning, a process requiring the synthesis of information across multiple documents.
This limitation stems from their reliance on vector-based retrieval, which prioritizes similarity over relational depth. While effective for straightforward queries, this approach struggles to capture the nuanced interplay between disparate data points.
The core issue lies in the absence of structured knowledge representation. Vector embeddings, though powerful, cannot encode explicit relationships between entities.
For instance, in legal research, a query about case precedents and their implications might retrieve relevant documents but fail to establish the causal or hierarchical links between them. This results in fragmented outputs that demand manual interpretation.
A promising alternative involves integrating graph-based methodologies, where knowledge graphs explicitly map entity relationships.
By embedding these connections, systems can traverse paths that mirror logical reasoning, enabling more coherent responses. However, implementing such systems requires overcoming challenges like graph scalability and real-time updates, which remain critical barriers to widespread adoption.
Introduction to Knowledge Graphs
Knowledge graphs redefine how retrieval systems process and contextualize information.
By structuring data as interconnected nodes (entities) and edges (relationships), they enable a level of reasoning that static databases or vector-based methods cannot achieve. This dynamic structure allows systems to traverse relationships, uncovering insights that would otherwise remain hidden.
One critical technique in knowledge graph construction is relation extraction, which identifies and encodes semantic links between entities.
Unlike traditional methods that rely on keyword matching, relation extraction integrates syntactic and semantic dependencies, ensuring that even subtle connections are captured.
For example, in biomedical research, this approach has been pivotal in linking symptoms to potential treatments across disparate studies, creating actionable insights for practitioners.
However, the effectiveness of knowledge graphs depends heavily on their scalability and domain specificity.
A graph optimized for e-commerce, such as Leroy Merlin’s product recommendation system, may struggle in healthcare due to differing data structures and relationship types. This highlights the importance of tailoring graph architectures to specific use cases.
By bridging gaps in traditional retrieval systems, knowledge graphs enhance precision and foster deeper understanding across complex domains.
Building Knowledge Graphs for Enhanced Retrieval
Constructing a knowledge graph is akin to designing a neural network for reasoning—each node and edge represents a deliberate choice to encode relationships that drive understanding.
The process begins with entity extraction, where tools like SpaCy or BERT-based models identify key elements such as people, organizations, or technical terms. This step ensures that the graph captures domain-specific nuances, avoiding the pitfalls of generic data representation.
The next critical phase, relationship extraction, transforms these entities into a cohesive structure by mapping their interactions.
For instance, in cybersecurity, combining BERT-based Named Entity Recognition (NER) with Graph Convolutional Networks (GCNs) has significantly improved the accuracy of threat behavior recognition in benchmark tests. This demonstrates how domain-specific adaptations can elevate performance.
A counterintuitive insight is that smaller, domain-focused graphs often outperform larger, generalized ones in precision tasks.
By limiting scope, systems like QLogicE, which integrates quantum embeddings, achieve unparalleled efficiency in representing complex relationships, such as adverse drug events in pharmaceutical texts.
Ultimately, these tailored graphs enable retrieval systems to emulate human-like reasoning, bridging isolated data points into actionable insights.
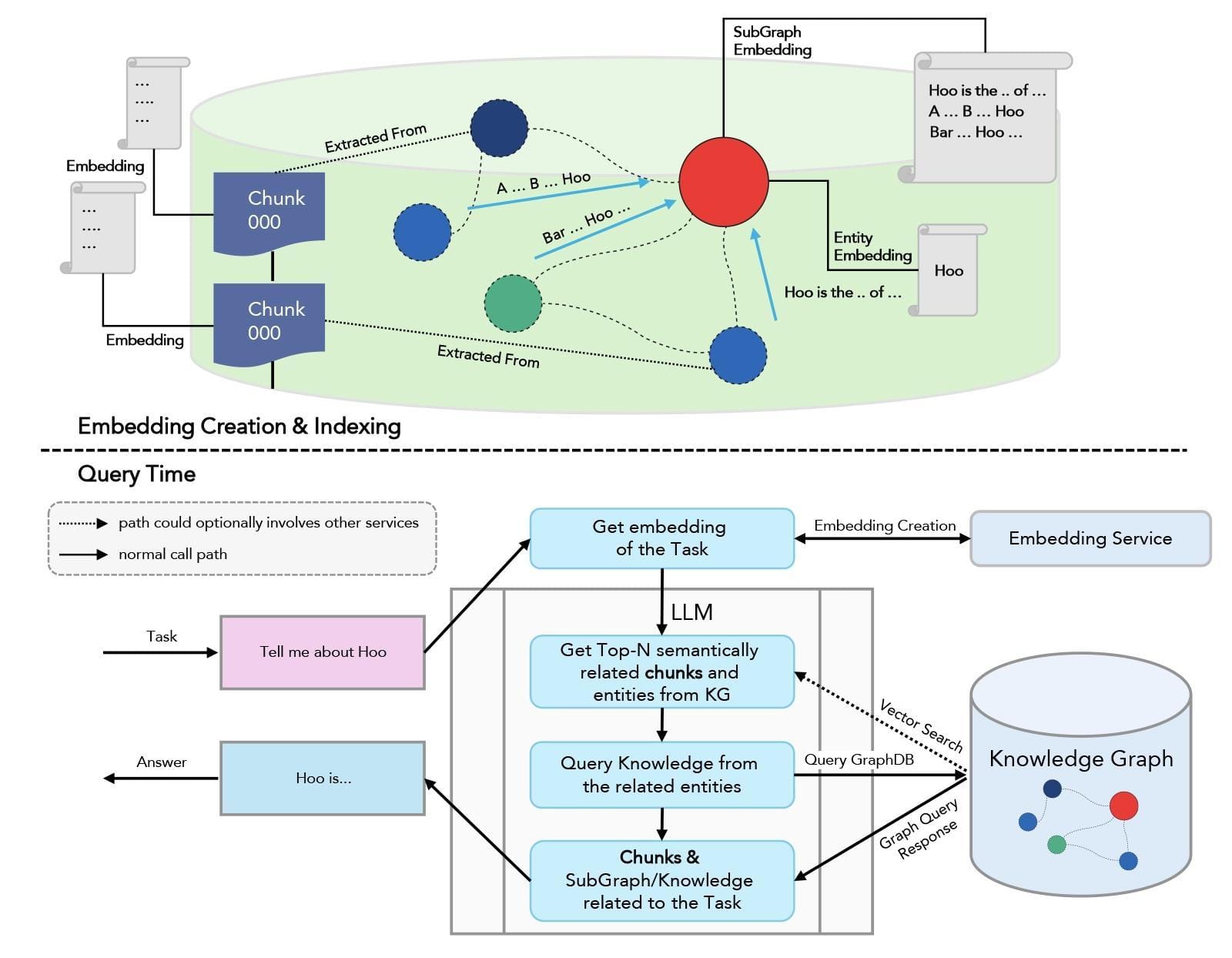
Relationship Mapping
Entity extraction is the cornerstone of effective knowledge graph construction, but its true power lies in its integration with relationship mapping.
A precise extraction process ensures that domain-specific entities are accurately identified, but mapping these entities into meaningful relationships transforms static data into actionable insights. This interplay is where the real value of GraphRAG emerges.
One advanced technique involves joint extraction models, which combine Named Entity Recognition (NER) and Relation Extraction (RE) into a unified framework.
By leveraging multi-task learning, these models reduce error propagation between tasks, ensuring greater contextual accuracy in mapping relationships.
For instance, cybersecurity applications often use this approach to link threat actors with their tactics, techniques, and procedures (TTPs), creating a cohesive threat intelligence narrative.
However, the effectiveness of relationship mapping depends heavily on the contextual granularity of the rules applied. A notable challenge arises when mapping relationships in domains with ambiguous or overlapping entity definitions. To address this, some systems incorporate domain ontologies to guide the mapping process, ensuring consistency and reducing noise.
Ultimately, the synergy between entity extraction and relationship mapping defines the success of knowledge graphs.
By refining both processes, organizations can unlock deeper insights and achieve unparalleled precision in information discovery.
Hierarchical Community Clustering
Hierarchical community clustering refines a knowledge graph by organizing entities into layered, contextually meaningful groups.
This method doesn’t just simplify the graph; it creates a structured hierarchy that mirrors human reasoning, enabling more intuitive and precise query responses.
The process relies on algorithms like Leiden, which excel at detecting dense clusters within large-scale graphs. These clusters are then arranged hierarchically, with higher layers summarizing broader relationships while lower layers capture granular details.
This dual-layered approach bridges the gap between local specificity and global context, ensuring that even distant but semantically related entities are meaningfully connected.
One critical advantage of this technique is its ability to reduce retrieval noise. By grouping entities into coherent communities, the system avoids irrelevant connections that often dilute query results.
For instance, in e-commerce, clustering product categories hierarchically—such as grouping “smartphones” under “electronics”—streamlines recommendations and enhances user experience.
However, challenges arise in domains with overlapping or ambiguous entities. Addressing this requires integrating domain-specific ontologies to guide clustering rules and ensure consistency.
Ultimately, hierarchical community clustering optimizes retrieval and lays the foundation for systems that reason with human-like clarity.
The Retrieval and Augmentation Process
GraphRAG’s retrieval and augmentation process transforms how systems handle complex queries by embedding contextual reasoning directly into the data pipeline.
Unlike traditional methods that rely on isolated document retrieval, GraphRAG dynamically integrates knowledge graphs to establish meaningful connections between disparate data points.
This approach enables systems to retrieve not just relevant documents but also the relationships that bind them, creating a cohesive narrative.
A pivotal innovation lies in contextual graph traversal, where algorithms like Breadth-First Reasoning Graphs (BFRG) determine the optimal number of “hops” needed to connect entities.
For instance, a query about the impact of supply chain disruptions on retail pricing might traverse nodes representing manufacturers, logistics providers, and market trends. Studies have shown that adaptive traversal reduces irrelevant data retrieval, significantly improving response accuracy.
Moreover, context augmentation ensures that retrieved data is enriched with semantic layers.
By embedding domain-specific ontologies, such as those used in precision medicine, systems can interpret nuanced queries like drug interactions with unprecedented clarity. This process mirrors human reasoning, where understanding emerges from connecting contextually relevant details.
The implications are profound: GraphRAG doesn’t just answer questions—it builds a framework for deeper, more explainable insights.
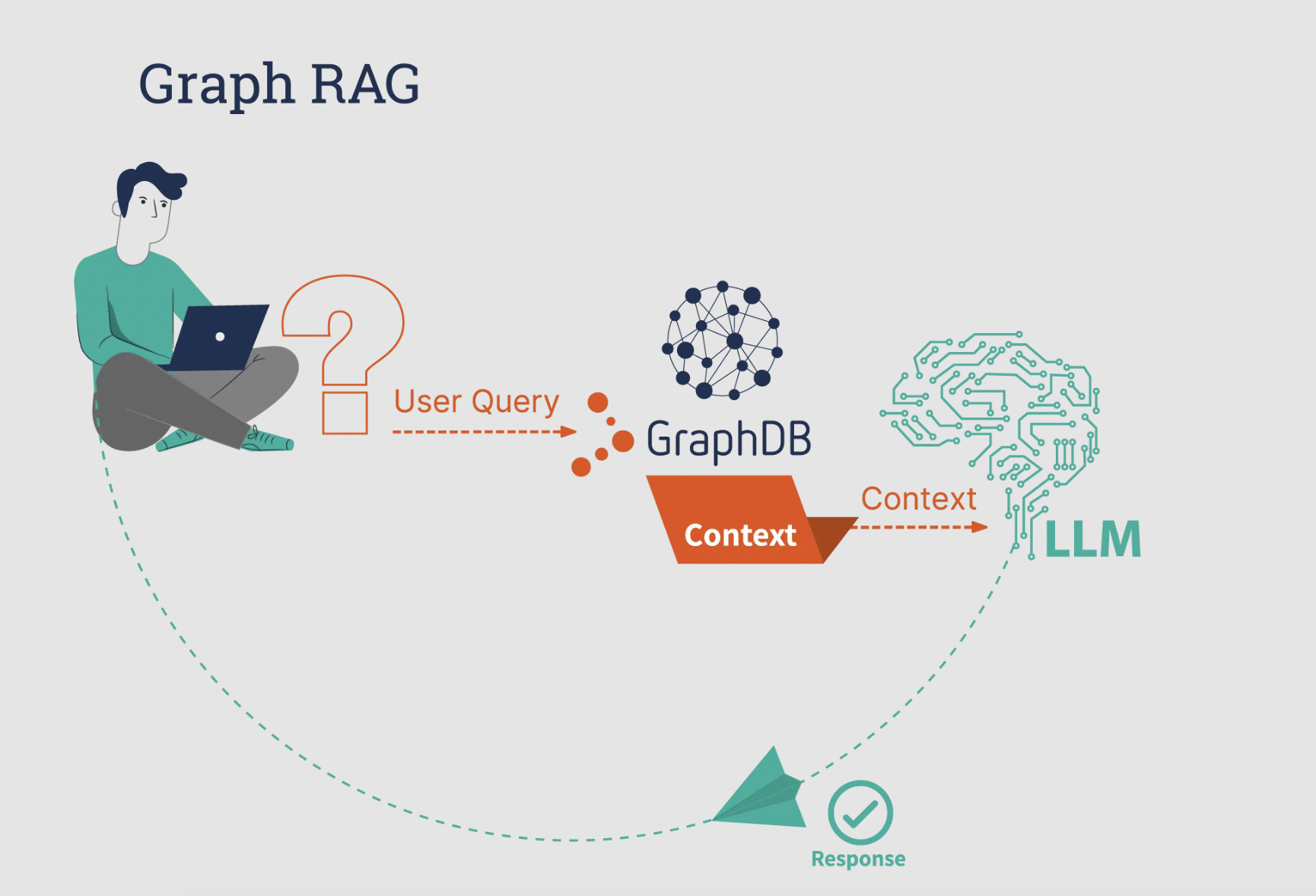
Augmenting Prompts with Graph-Derived Context
Embedding graph-derived context into prompts transforms query handling by enabling systems to interpret relationships rather than isolated facts.
This technique leverages the structural depth of knowledge graphs, where nodes and edges encode semantic connections, to enrich the generative process.
By integrating these connections directly into the prompt, the system gains a nuanced understanding of the query’s intent and underlying context.
One critical mechanism is contextual query expansion, which reformulates user queries to include graph-relevant entities and relationships.
For example, in pharmaceutical research, a query about drug efficacy can be expanded to include related compounds, clinical trials, and adverse event data. This ensures the system retrieves not just relevant documents but also the relational pathways that clarify the query’s scope.
However, the effectiveness of this approach depends on adaptive prompt tuning, where prompts are dynamically adjusted based on graph traversal results. This minimizes semantic drift and ensures the generated response remains tightly aligned with the query.
By embedding graph-derived context, organizations can achieve more precise, explainable outputs, particularly in domains requiring multi-hop reasoning. This approach redefines how AI systems synthesize and present complex information.
Multi-Hop Reasoning in GraphRAG
Multi-hop reasoning in GraphRAG thrives on its ability to emulate human-like decision-making by dynamically navigating through interconnected data points.
Unlike static retrieval methods, GraphRAG employs adaptive traversal algorithms that determine the optimal number of hops required to answer a query. This ensures that the system retrieves not just relevant data but also the contextual relationships that underpin it.
A key technique here is dynamic path optimization, where the system evaluates the relevance of each node and edge during traversal.
For instance, in financial fraud detection, GraphRAG can trace transactions across multiple accounts, stopping only when a meaningful pattern emerges. This contrasts with fixed-hop approaches, which risk either oversimplifying or overcomplicating the retrieval process.
However, the effectiveness of multi-hop reasoning depends on contextual thresholds, which define when to halt traversal.
Domain-specific factors, such as the complexity of relationships or the density of the knowledge graph influence these thresholds. In cybersecurity, for example, overly aggressive hopping can lead to noise, while insufficient hopping may miss critical connections.
By integrating these principles, GraphRAG transforms abstract data into actionable insights, making it an indispensable tool for domains requiring layered reasoning. This nuanced approach not only enhances precision but also fosters trust in the system’s outputs, bridging the gap between data retrieval and decision-making.
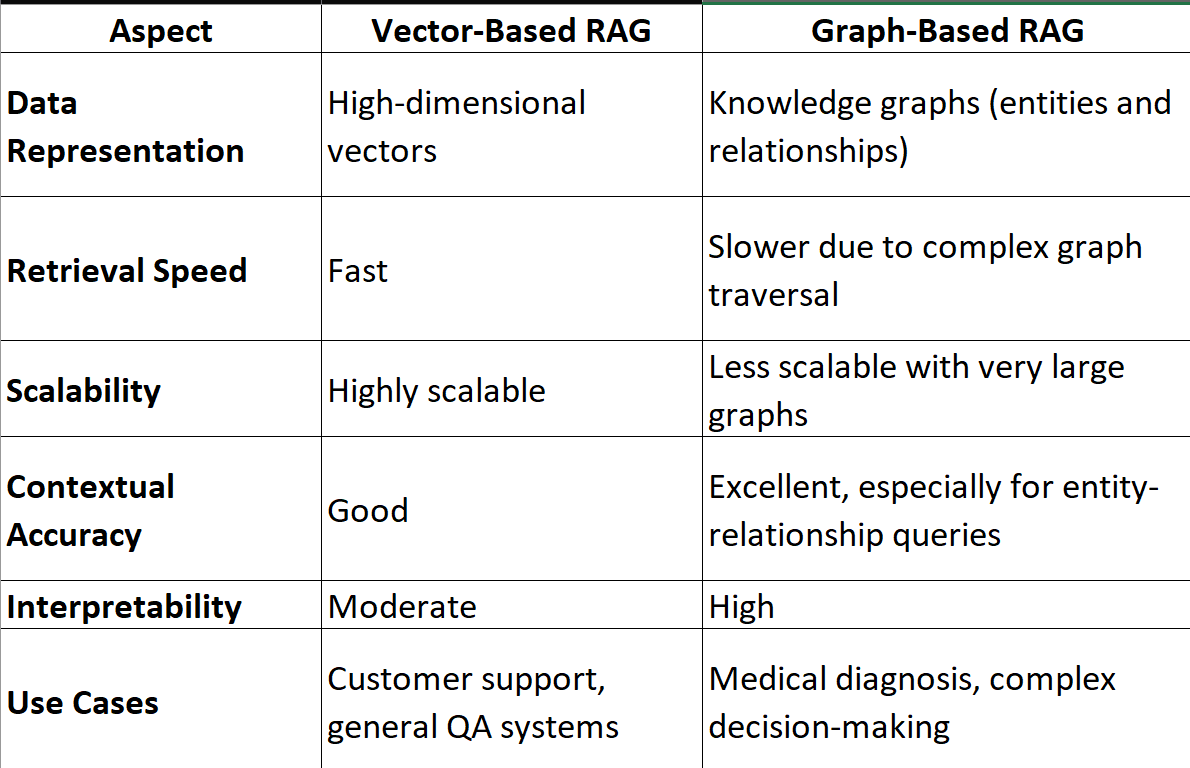
Comparing GraphRAG with Baseline RAG
GraphRAG fundamentally redefines how retrieval systems handle complexity by embedding relational understanding directly into the retrieval process.
Unlike baseline RAG, which relies on vector similarity to retrieve isolated data points, GraphRAG employs knowledge graph integration to map and traverse relationships between entities. This approach enables it to synthesize multi-dimensional insights, making it particularly effective for layered queries.
For example, in legal contract analysis, baseline RAG might retrieve clauses relevant to a keyword but fail to establish their interdependencies.
GraphRAG, however, can trace obligations, exceptions, and precedents across documents, creating a cohesive narrative. This capability stems from semantic disambiguation, where graph structures clarify ambiguous terms by linking them to contextual nodes.
A common misconception is that GraphRAG’s complexity slows performance. In reality, pre-built graph structures reduce query latency by minimizing redundant computations.
This efficiency, combined with its ability to contextualize data, positions GraphRAG as a transformative tool for domains requiring precision and depth.
Performance Metrics and Benchmarks
GraphRAG’s ability to measure contextual precision redefines how retrieval systems are evaluated.
Unlike traditional RAG, which focuses on isolated document relevance, GraphRAG assesses the coherence of relationships retrieved within subgraphs. This shift emphasizes not just finding data but connecting it meaningfully, a critical factor in domains like financial forecasting or legal research.
One key mechanism is adaptive graph traversal, which optimizes the number of hops required to retrieve interconnected entities. This process ensures that responses are not only accurate but also contextually rich.
For instance, FalkorDB’s integration with GraphRAG demonstrated how pre-built graph structures reduced query latency while maintaining high relational fidelity, particularly in enterprise KPI tracking.
However, evaluating such systems introduces challenges. Metrics like retrieval precision must account for both entity relevance and relational depth, complicating direct comparisons with vector-based RAG.
Additionally, benchmarks must adapt to domain-specific nuances, as a healthcare application’s requirements differ significantly from those in e-commerce.
By focusing on these nuanced metrics, GraphRAG not only advances retrieval accuracy but also sets a new standard for evaluating multi-hop reasoning systems.
Explainability and Contextual Depth
GraphRAG’s explainability lies in its ability to transform raw data into a coherent narrative by leveraging the structured relationships within knowledge graphs.
Unlike traditional RAG, which often retrieves isolated data points, GraphRAG ensures that every retrieved element is contextually anchored, creating a seamless flow of information.
This structured approach is particularly critical in domains like legal analysis, where understanding the interplay between clauses, precedents, and obligations is essential.
A key mechanism enabling this depth is reasoning path visualization, where the system generates step-by-step explanations of how conclusions are derived.
For instance, in molecular property prediction, subgraphs representing functional groups are linked to observed behaviors, making predictions both transparent and actionable. This process not only enhances trust but also allows users to verify the system’s logic, a feature absent in baseline RAG.
However, achieving such clarity requires balancing graph complexity with usability. Overly dense graphs can obscure insights, while oversimplified ones risk losing critical connections. Domain-specific tuning, such as integrating ontologies, mitigates these challenges by ensuring relevance without overwhelming users.
By embedding contextual depth, GraphRAG empowers users to make informed decisions with confidence, transforming how complex queries are addressed.
FAQ
What makes GraphRAG more effective than traditional RAG for modeling entity relationships?
GraphRAG structures data as connected nodes and edges, allowing it to track how entities relate. This improves accuracy in tasks like legal or scientific research, where understanding relationships between data points is more important than matching keywords.
How does salience analysis improve retrieval accuracy in GraphRAG?
Salience analysis ranks which entities and connections matter most in a query. This helps GraphRAG avoid noise and focus on relevant results, improving the system’s ability to retrieve contextually meaningful information in complex domains like healthcare or finance.
What is the role of co-occurrence optimization in GraphRAG?
Co-occurrence optimization strengthens links between frequently related entities. This helps the system identify important patterns and improves its ability to handle layered queries by retrieving more meaningful connections across the graph.
How does GraphRAG manage multi-hop queries across related data?
GraphRAG uses adaptive traversal to decide how far to explore a graph to answer a query. It stops when relevant data is found, making it more efficient and better at uncovering hidden relationships across complex datasets like transaction logs or case files.
What are the best practices for using GraphRAG in dynamic data systems?
Effective GraphRAG setups use small, focused graphs based on domain-specific ontologies. Systems should be updated regularly, prioritize key relationships, and apply contextual indexing to reduce costs while maintaining accuracy as the dataset evolves.
Conclusion
GraphRAG changes how systems retrieve and understand data by linking entities through structured relationships.
Instead of retrieving isolated results, it builds context through graph traversal and multi-hop reasoning. This makes it more reliable for fields like law, medicine, and finance, where understanding how data points connect is critical.
As GraphRAG continues to improve with adaptive techniques and structured ontologies, it offers a practical and scalable way to answer complex queries with clarity and context.