
Graph-Based RAG vs Vector-Based RAG: A Complete Guide to Understanding the Core Differences
What if the way your AI retrieves information could redefine its efficiency? Dive into the battle of Graph-Based vs. Vector-Based RAG to uncover their core differences and find the right fit for your next breakthrough.


Despite the rapid advancements in AI, nearly 70% of organizations still struggle to extract actionable insights from their data. Why? Because the tools they rely on often fail to bridge the gap between unstructured information and meaningful context. This is where Retrieval-Augmented Generation (RAG) systems come into play, offering a lifeline to businesses drowning in data. But here’s the twist—choosing the right RAG approach isn’t as straightforward as it seems.
Graph-based RAG and Vector-based RAG, two dominant methodologies, promise to revolutionize how we retrieve and process information. Yet, their differences go far beyond technical nuances; they represent fundamentally distinct philosophies in data handling. Which one aligns with your needs? And more importantly, how do these choices shape the future of AI-driven decision-making?
This guide unpacks these questions, exploring the untapped potential and trade-offs of each approach.
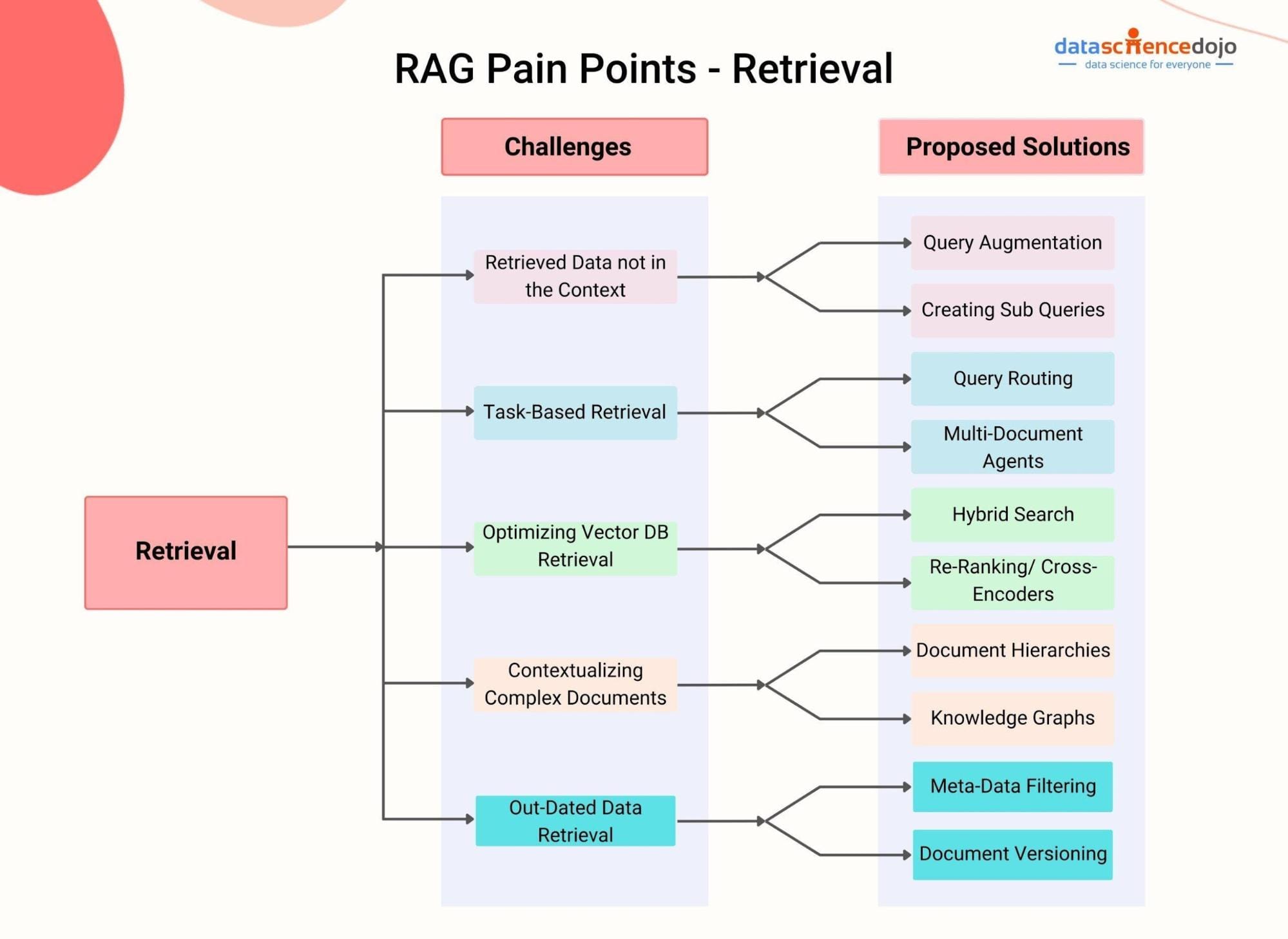
Overview of Retrieval-Augmented Generation (RAG)
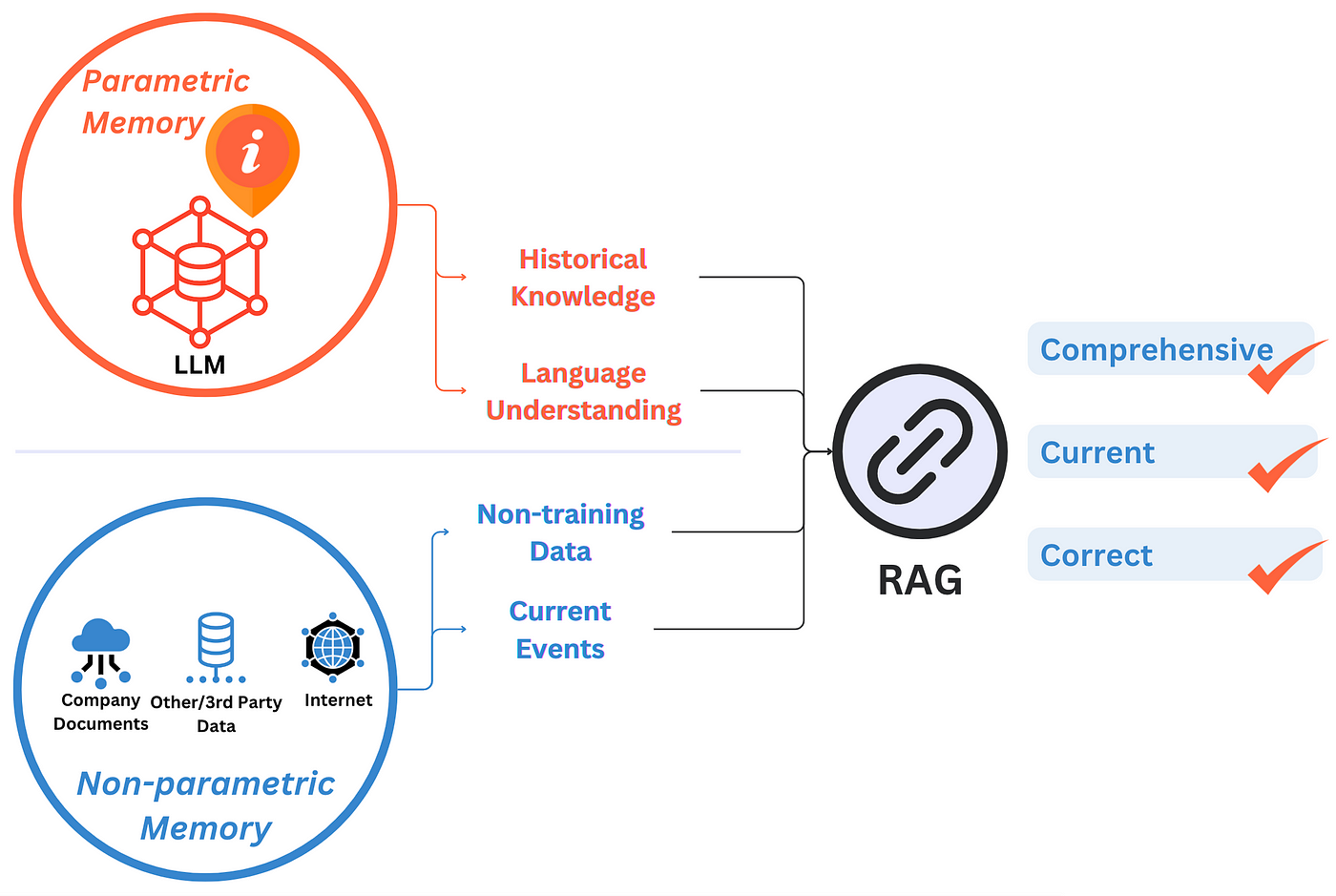
Retrieval-Augmented Generation (RAG) transforms how AI systems interact with external knowledge, but its true power lies in its adaptability to diverse data landscapes. Unlike traditional models that rely solely on pre-trained knowledge, RAG dynamically retrieves domain-specific information, enabling it to generate responses that are both contextually relevant and factually grounded. This dual-layered approach—retrieval and generation—bridges the gap between static knowledge and real-time adaptability.
Consider the healthcare sector: a Graph-based RAG system can traverse complex relationships in patient data, linking symptoms, treatments, and outcomes for precise diagnostics. Meanwhile, a Vector-based RAG excels in unstructured environments, such as analyzing vast medical literature to identify emerging treatment trends.
What’s often overlooked is the role of retrieval quality. Poorly indexed data or irrelevant retrieval can undermine even the most advanced generative models. By integrating hybrid techniques, such as reranking algorithms or domain-specific ontologies, organizations can significantly enhance RAG’s performance, unlocking its full potential.
The Role of Data Structures in RAG Systems
Data structures are the backbone of Retrieval-Augmented Generation (RAG) systems, dictating how information is stored, retrieved, and utilized. Graph RAG leverages knowledge graphs, which excel at representing structured relationships between entities. This enables advanced reasoning, such as tracing causal links in medical diagnostics or mapping financial fraud networks. In contrast, Vector RAG relies on dense vector embeddings, optimized for semantic similarity searches across unstructured data, like retrieving relevant customer reviews or research papers.
A key consideration is the trade-off between explainability and efficiency. Graph RAG offers transparency by visualizing relationships, but it demands meticulous data curation. Vector RAG, while scalable, often sacrifices interpretability due to its reliance on abstract vector spaces.
To maximize outcomes, hybrid systems are emerging. These combine graph-based reasoning with vector-based retrieval, creating a framework that balances depth and speed. For developers, this means prioritizing use-case-specific data structuring to unlock RAG’s full potential.
Understanding Graph-Based RAG
Graph-Based RAG thrives on knowledge graphs, which organize data into nodes (entities) and edges (relationships). Think of it as a city map: nodes are landmarks, and edges are roads connecting them. This structure allows Graph RAG to perform deep reasoning, such as identifying drug interactions in healthcare or tracing supply chain dependencies in logistics.
A common misconception is that knowledge graphs are static. In reality, they evolve dynamically, integrating new data to reflect real-world changes. For instance, in financial fraud detection, updating the graph with new transaction patterns can reveal hidden networks of fraudulent activity.
What sets Graph RAG apart is its explainability. By visualizing subgraphs, users can trace the logic behind AI decisions, fostering trust. However, this comes at a cost—building and maintaining these graphs requires significant effort. Experts suggest hybridizing with vector methods to balance transparency and scalability, unlocking broader applications across industries.
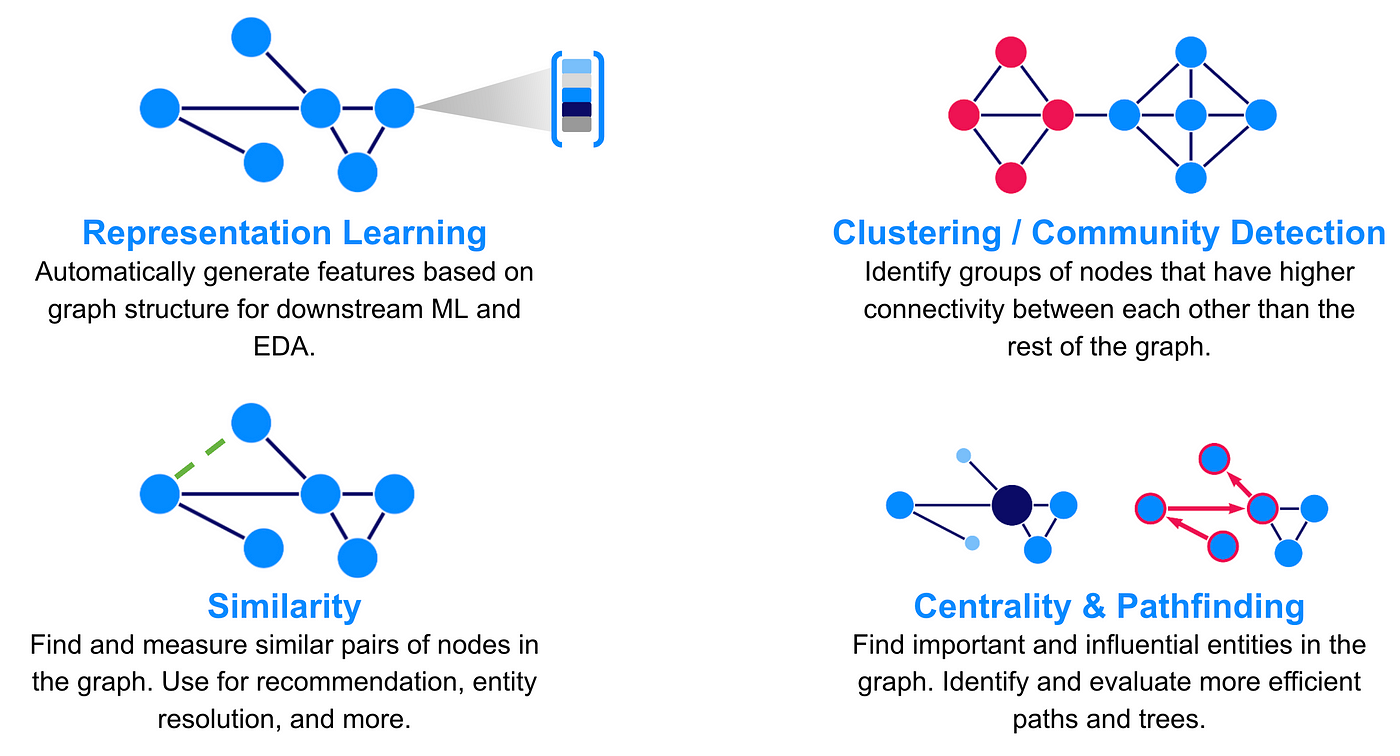
Fundamentals of Graph Theory in AI
Graph theory enables AI to model relationships rather than isolated data points. This is a game-changer for domains like recommendation systems. For example, Netflix doesn’t just suggest movies based on your viewing history—it maps relationships between genres, actors, and user preferences to predict what you’ll love next.
One overlooked factor is the role of graph traversal algorithms. Techniques like Breadth-First Search (BFS) and Depth-First Search (DFS) allow AI to uncover hidden patterns, such as identifying influencers in social networks or tracing supply chain disruptions. These algorithms excel in navigating complex, interconnected datasets.
Interestingly, graph theory also intersects with game theory. Auction platforms like eBay use graph-based models to optimize bidding strategies, a concept rooted in Nash equilibrium. Graph theory isn’t just about data—it’s about understanding interactions. For AI practitioners, mastering these fundamentals unlocks smarter, more context-aware systems.
How Graphs Enhance Knowledge Retrieval
Graphs excel at contextualizing relationships, making them indispensable for knowledge retrieval. Unlike flat databases, a graph structure connects entities (nodes) through meaningful relationships (edges). This allows systems to infer new knowledge, such as identifying indirect links between concepts. For instance, in healthcare, a graph can connect symptoms to diseases and treatments, enabling precise diagnostic support.
Graphs can organize data categorically, such as grouping products by type, brand, or price range in eCommerce. This layered approach ensures that queries retrieve not just relevant results but also logically grouped insights, improving user experience.
Conventional wisdom often favors speed over depth, but graphs challenge this by balancing efficiency with explainability. Traversal algorithms like Dijkstra’s can retrieve optimal paths while maintaining interpretability. For practitioners, integrating graph-based retrieval with domain-specific ontologies offers a framework to enhance both accuracy and transparency in AI-driven systems.
Exploring Vector-Based RAG
Vector-Based RAG thrives in scenarios involving vast, unstructured data. By encoding textual information into dense vector embeddings, it enables rapid similarity searches. For instance, in e-commerce, this approach powers product recommendation systems by matching user preferences with semantically similar items, enhancing personalization at scale.
A common misconception is that Vector RAG lacks precision. However, advancements like learning-to-rank algorithms and query expansion techniques have significantly improved its accuracy. These methods refine retrieval by prioritizing contextually relevant results, even in noisy datasets.
Unexpectedly, Vector RAG intersects with natural language processing (NLP). Embedding models like BERT or GPT capture nuanced semantic relationships, making Vector RAG ideal for applications like literature search or adaptive learning platforms. Think of it as a librarian who not only finds books by title but also understands themes and genres.
Looking ahead, integrating domain-specific ontologies into vector spaces could further enhance retrieval quality, bridging gaps in semantic understanding.
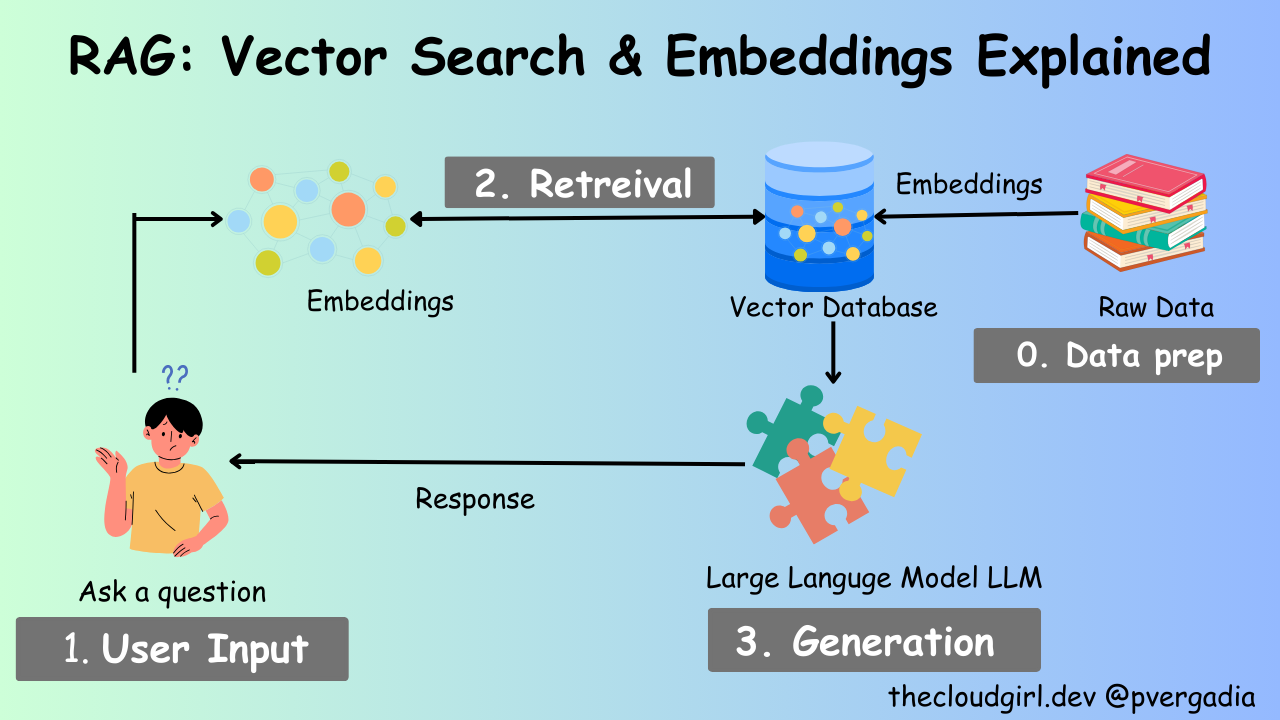
Introduction to Vector Representations
Vector representation transforms data into high-dimensional numerical embeddings, capturing semantic relationships. Unlike traditional keyword matching, vectors encode context, enabling systems to understand nuances like synonyms or idiomatic expressions. For example, in legal document retrieval, vector embeddings can identify cases with similar precedents, even if phrased differently.
While higher dimensions often improve precision, they can introduce computational overhead. Techniques like Principal Component Analysis (PCA) help balance accuracy and efficiency by reducing dimensions without losing critical information.
Interestingly, vector representations draw heavily from linear algebra. Operations like cosine similarity measure the “angle” between vectors, revealing how closely two concepts align. This principle extends beyond text—vectors now encode images, audio, and even molecular structures, revolutionizing fields like drug discovery.
To maximize impact, organizations should invest in domain-specific embedding models, ensuring vectors reflect industry-specific nuances for superior retrieval outcomes.
Utilizing Vectors for Information Retrieval
Vectors excel in semantic similarity searches, enabling retrieval systems to go beyond exact matches. By encoding data into dense embeddings, they capture subtle relationships, such as synonyms or contextual relevance. For instance, in e-commerce, vector-based retrieval can recommend products based on user intent, even if the query lacks precise keywords.
Models like BERT or Sentence Transformers perform best when fine-tuned on domain-specific corpora. Without this, retrieval accuracy can suffer, especially in specialized fields like medical diagnostics or legal research.
Interestingly, vector retrieval intersects with probabilistic models. Techniques like learning-to-rank refine results by prioritizing embeddings most likely to satisfy user intent. This approach is particularly effective in personalized content delivery, where relevance is paramount.
To optimize outcomes, organizations should combine vector search with reranking models, ensuring both semantic depth and contextual precision in retrieval pipelines.
Case Studies: Implementations of Vector-Based RAG
One standout application of Vector-Based RAG is in academic research platforms. By leveraging dense embeddings, these systems retrieve semantically relevant papers, even when user queries are vague or imprecise. For example, platforms like Semantic Scholar use vector search to connect researchers with studies that align with their intent, not just their keywords.
In multilingual research, embeddings trained on cross-lingual datasets ensure that papers in different languages are retrieved with equal precision. This approach has revolutionized global collaboration, breaking down language barriers in scientific discovery.
Interestingly, vector-based retrieval also integrates well with citation networks. By combining vector embeddings with graph-based citation data, platforms can recommend not only relevant papers but also influential works within a field. This hybrid approach enhances both relevance and contextual depth, offering a blueprint for future implementations in other knowledge-intensive domains.
Core Differences Between Graph-Based and Vector-Based RAG
Graph-Based RAG thrives on structured relationships, mapping entities and their connections in a way that mirrors real-world hierarchies. Think of it as a subway map: nodes are stations (entities), and edges are the tracks (relationships). This makes it ideal for domains like healthcare, where understanding drug interactions or biological pathways requires deep reasoning over interconnected data.
Vector-Based RAG, by contrast, excels in semantic similarity. It’s like a search engine that doesn’t just match words but understands intent. For instance, in customer support, it can retrieve relevant FAQs or manuals even when queries are phrased differently. However, its reliance on embeddings means it struggles with multi-step reasoning tasks.
Hybrid systems are emerging as the sweet spot. By combining graph reasoning with vector efficiency, they balance explainability and scalability, offering a glimpse into the future of Retrieval-Augmented Generation.
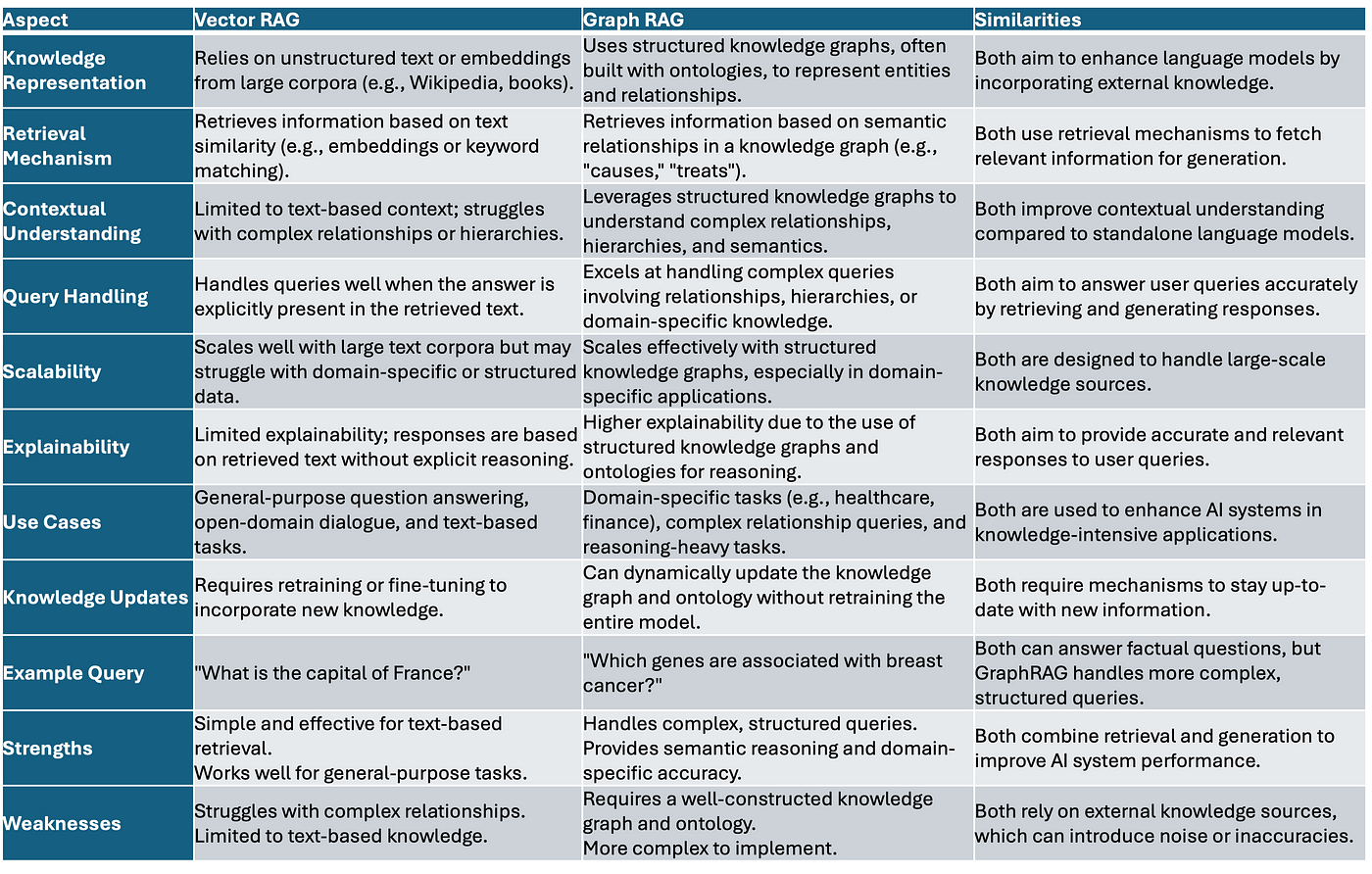
Structural Variations and Their Implications
The structural foundation of Graph-Based RAG lies in knowledge graphs, where entities and their relationships are explicitly defined. This structure enables multi-hop reasoning, making it indispensable in fields like legal research, where understanding the interplay between case law, statutes, and precedents is critical. However, maintaining these graphs demands meticulous curation, which can be resource-intensive.
Vector-Based RAG, on the other hand, leverages dense embeddings to encode semantic meaning. This approach shines in unstructured data environments, such as customer feedback analysis, where rapid retrieval of contextually relevant insights is key. Yet, its reliance on high-dimensional spaces can lead to overfitting or semantic drift, especially in niche domains.
Data sparsity impacts both systems differently. While sparse graphs lose connectivity, sparse vector datasets risk reduced retrieval accuracy. Addressing this requires hybrid models that integrate graph structures for reasoning and vectors for scalability, paving the way for more robust RAG systems.
Performance Analysis Across Different Scenarios
Graph-Based RAG thrives in highly interconnected datasets, such as healthcare systems where relationships between symptoms, treatments, and outcomes must be deeply reasoned. Its ability to perform multi-hop queries ensures precise insights, but this comes at the cost of computational overhead, especially in real-time applications.
Vector-Based RAG, by contrast, excels in scalability and speed, making it ideal for e-commerce platforms that require rapid semantic searches across millions of product descriptions. However, its reliance on dense embeddings can falter in domains where contextual nuance is critical, such as legal or scientific research.
Hybrid retrieval systems outperform both in dynamic environments. For instance, a fraud detection system could use graph reasoning to map suspicious connections while leveraging vector embeddings for semantic anomaly detection. This dual approach not only enhances accuracy but also reduces latency, offering a practical framework for balancing depth and efficiency in diverse scenarios.
Scalability and Computational Efficiency
Vector-Based RAG shines in horizontal scalability, leveraging distributed vector databases to handle billions of embeddings with minimal latency. For example, e-commerce platforms like Amazon use vector search to deliver personalized recommendations in milliseconds, even during peak traffic. This efficiency stems from approximate nearest neighbor (ANN) algorithms, which reduce computational load by prioritizing approximate matches over exact ones.
Graph-Based RAG, however, faces challenges in scaling due to the complexity of graph traversal algorithms. While it excels in domains like healthcare, where multi-hop reasoning is critical, its reliance on centralized graph databases can bottleneck performance as data grows. Techniques like graph partitioning mitigate this but often introduce trade-offs in query accuracy.
A hybrid approach could redefine scalability. By integrating vector embeddings for initial filtering and graph traversal for deeper reasoning, systems can achieve both speed and depth. This framework is particularly promising for fraud detection, where rapid yet nuanced analysis is essential.
Practical Implementation Strategies
When implementing Graph-Based RAG, data preparation is everything. Start by constructing a robust knowledge graph that captures domain-specific relationships. For instance, in healthcare, mapping diseases, symptoms, and treatments into a graph ensures accurate multi-hop reasoning. Tools like GraphRAG-SDK simplify this process by automating graph creation and traversal optimization.
Vector-Based RAG, on the other hand, thrives on high-quality embeddings. Training models on domain-specific datasets—like customer reviews for e-commerce—boosts semantic accuracy. Using generic embeddings can dilute precision. Instead, frameworks like FAISS enable scalable, efficient similarity searches tailored to your data.
Hybrid systems unlock new possibilities. Picture this: a fraud detection system uses vectors for rapid anomaly detection, then switches to graph traversal for deeper investigation. This layered approach balances speed with depth, addressing both scalability and complexity..
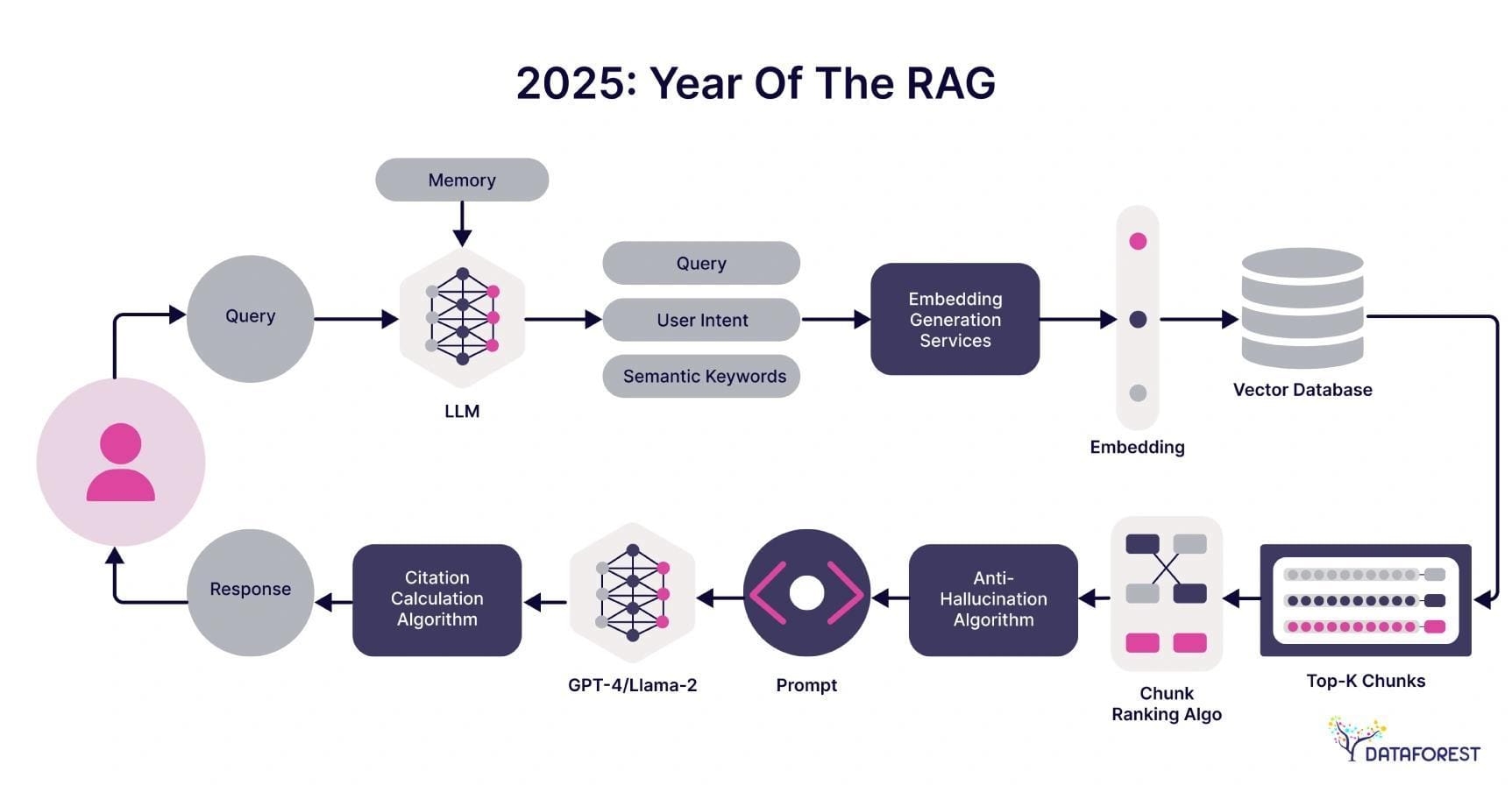
Selecting the Right Approach for Your Needs
Choosing between Graph-Based RAG and Vector-Based RAG hinges on data structure and query complexity. If your domain involves intricate relationships—like mapping supply chain dependencies—Graph RAG excels by leveraging structured knowledge graphs. For example, a logistics company can model routes, delays, and costs as interconnected nodes, enabling multi-step reasoning to optimize delivery times.
Vector RAG, however, shines in unstructured data environments. Think of a customer support chatbot that retrieves answers from vast, unorganized FAQs. By encoding semantic meaning into vectors, it ensures quick, relevant responses, even when user queries are vague or imprecise.
In fraud detection, vectors can flag anomalies in real-time, while graphs trace the relationships between flagged entities for deeper insights.
Start with your data’s nature. Structured? Go Graph. Unstructured? Vector. Mixed? Hybrid systems offer the best of both worlds.
Integration with Existing Systems
Integrating RAG systems with existing infrastructure requires compatibility with data pipelines and query workflows. For instance, Graph RAG often demands pre-built knowledge graphs, which can be challenging to align with legacy databases. However, tools like Neo4j or GraphRAG-SDK simplify this by offering APIs that map relational data into graph structures, enabling seamless integration.
Vector RAG integrates more easily with modern vector databases like Pinecone or Weaviate. These systems support high-dimensional embeddings, making them ideal for unstructured data environments such as customer support platforms or recommendation engines.
Hybrid systems combining graph and vector approaches can introduce delays if not optimized. Techniques like caching frequently accessed subgraphs or precomputing embeddings mitigate this issue.
Assess your system’s data flow. For structured data, prioritize graph compatibility. For unstructured data, focus on vector database integration. Optimize hybrid setups with latency-reduction strategies.
Tools and Frameworks for Development
When building RAG systems, GraphRAG-SDK stands out for its ability to streamline graph-based implementations. It simplifies the creation of knowledge graphs by automating entity extraction and relationship mapping, reducing the manual effort required. For example, in healthcare, GraphRAG-SDK can map patient data, symptoms, and treatments into a graph, enabling advanced clinical decision support.
On the vector side, FAISS by Facebook excels in high-speed similarity searches. Its GPU-accelerated indexing makes it ideal for large-scale applications like e-commerce, where rapid retrieval of semantically similar products is critical.
LangChain bridges graph and vector approaches. It enables hybrid retrieval by chaining graph traversal with vector similarity, offering flexibility for mixed data environments.
Use GraphRAG-SDK for structured domains like finance or healthcare. Leverage FAISS for unstructured, high-volume tasks. For hybrid needs, LangChain provides a scalable, adaptable framework.
Advanced Applications and Future Developments
The future of RAG systems lies in hybrid architectures that seamlessly combine Graph RAG’s structured reasoning with Vector RAG’s semantic agility. For instance, in drug discovery, researchers are exploring joint embedding spaces where molecular interactions (graphs) and scientific literature (vectors) coexist, enabling breakthroughs in identifying novel compounds.
Graph embeddings are evolving to mimic vector representations, narrowing the gap between the two approaches. This could revolutionize industries like finance, where fraud detection demands both explainability (graphs) and speed (vectors).
Graph RAG is too rigid for dynamic data. Emerging techniques like dynamic graph embeddings challenge this, allowing real-time updates without sacrificing structure.
Looking ahead, domain-specific ontologies integrated into vector spaces could redefine semantic retrieval. Imagine personalized education platforms that adapt to a student’s learning style by blending structured knowledge graphs with unstructured content recommendations.
Invest in hybrid RAG research to future-proof AI systems.
Hybrid Models Combining Graphs and Vectors
Hybrid RAG models excel by leveraging graph-based reasoning for structured insights and vector-based retrieval for semantic flexibility. A standout example is in supply chain optimization, where knowledge graphs map relationships between suppliers, products, and logistics, while vector embeddings analyze unstructured data like market trends or customer reviews. Together, they enable real-time, data-driven decisions.
Graphs provide explainability—critical for industries like healthcare—while vectors ensure scalability across vast datasets. For instance, a hybrid system in clinical trials could link patient histories (graphs) with emerging research (vectors), uncovering personalized treatment options.
Query transformation bridges the gap between these systems. By rephrasing user queries into graph-compatible and vector-compatible formats, hybrid models achieve higher precision.
Start with domain-specific graph construction and pair it with pre-trained vector models. This layered approach ensures both depth and breadth in retrieval, unlocking new possibilities for AI-driven solutions.
Emerging Trends in RAG Technologies
One emerging trend in RAG technologies is the integration of domain-specific ontologies into vector spaces. By embedding structured ontologies alongside unstructured data, systems achieve a richer semantic understanding. For example, in legal tech, combining case law ontologies with vector embeddings enables nuanced retrieval of precedents, factoring in both legal hierarchies and semantic context.
This approach works because ontologies provide conceptual scaffolding, ensuring retrieval aligns with domain-specific logic. Meanwhile, vectors enhance scalability, allowing systems to process vast legal corpora efficiently.Cross-modal embeddings—mapping text, images, and graphs into a unified space—further enrich retrieval, especially in multimedia-heavy domains like e-commerce.
Conventional wisdom suggests ontologies are too rigid for dynamic systems. However, dynamic ontology updates challenge this, enabling real-time adaptability.
Invest in ontology-driven vector training pipelines. This hybrid strategy ensures precision without sacrificing scalability, paving the way for more intelligent, domain-aware RAG systems.
Cross-Domain Perspectives and Innovations
A key innovation in cross-domain RAG systems is the use of transfer learning to bridge domain gaps. By pre-training models on general datasets and fine-tuning them with domain-specific knowledge, systems can adapt to diverse fields like healthcare and e-commerce. For instance, a Graph RAG model trained on biomedical ontologies can be repurposed for supply chain optimization by integrating logistics-specific graphs.
This works because transfer learning leverages shared patterns across domains, reducing the need for extensive retraining. Domain adaptation techniques, such as adversarial training, help models retain generalization while aligning with new domain-specific nuances.
Conventional wisdom assumes cross-domain systems sacrifice precision for flexibility. However, hybrid RAG architectures—combining graph reasoning with vector scalability—prove otherwise, delivering both adaptability and accuracy.
Develop modular RAG pipelines that allow seamless integration of domain-specific components. This ensures scalability while maintaining relevance across industries.
FAQ
1. What are the fundamental differences between Graph-Based RAG and Vector-Based RAG?
Graph-Based RAG and Vector-Based RAG differ in data representation and retrieval. Graph-Based RAG organizes information as knowledge graphs with nodes and edges for deep reasoning and explainability, excelling in complex domains like fraud detection but requiring significant computational effort.
Vector-Based RAG uses high-dimensional embeddings for efficient semantic searches, ideal for large-scale unstructured data like document retrieval, offering scalability and speed but lacking multi-step reasoning and explainability. Hybrid systems often combine their strengths for balanced performance.
2. In which scenarios is Graph-Based RAG more effective than Vector-Based RAG?
Graph-Based RAG is more effective in scenarios that require modeling and reasoning over complex, structured relationships. For example, in domains like healthcare and legal systems, where understanding intricate connections between entities such as patient histories, legal precedents, or regulatory frameworks is critical, Graph-Based RAG excels by leveraging knowledge graphs. Its ability to perform multi-hop reasoning and provide explainable insights makes it particularly valuable in these contexts.
Additionally, applications like fraud detection and scientific research benefit from the structured nature of Graph-Based RAG. By mapping transactions or scientific entities into a graph, it can uncover hidden patterns and relationships that are not immediately apparent in unstructured data. This structured approach ensures a deeper contextual understanding, making it indispensable for tasks requiring high fidelity and interpretability.
3. How does the explainability of Graph-Based RAG compare to the efficiency of Vector-Based RAG?
Graph-Based RAG offers superior explainability due to its structured representation of data in the form of knowledge graphs. By explicitly mapping entities and their relationships, it allows users to trace the reasoning process through graph traversal, providing clear and interpretable insights. This level of transparency is particularly advantageous in domains like finance or healthcare, where trust and accountability are paramount.
On the other hand, Vector-Based RAG prioritizes efficiency, leveraging high-dimensional embeddings and similarity searches to retrieve relevant information quickly. Its ability to handle large-scale, unstructured datasets with minimal latency makes it ideal for applications like customer support or content recommendation.
However, this efficiency comes at the cost of reduced explainability, as the retrieval process relies on semantic similarity rather than explicit relationships, making it less transparent compared to Graph-Based RAG.
4. What are the key challenges in implementing hybrid RAG systems combining graphs and vectors?
Implementing hybrid RAG systems combining graphs and vectors faces several challenges. Synchronizing knowledge graphs and vector databases as data evolves requires robust pipelines and high computational resources. Integrating graph reasoning with vector-based retrieval complicates query processing and design, often increasing latency due to dual retrieval processes.
Cost and scalability are also concerns, as knowledge graphs demand intensive maintenance, while vector databases require significant storage and computing power for high-dimensional embeddings. Despite these challenges, hybrid systems balance explainability and efficiency, making them valuable for complex, data-rich applications.
5. How do Graph-Based and Vector-Based RAG approaches impact real-world applications like healthcare and finance?
Graph-Based and Vector-Based RAG approaches address distinct needs in real-world applications like healthcare and finance. In healthcare, Graph-Based RAG leverages knowledge graphs to model relationships between diseases, symptoms, and treatments, improving diagnostics, workflows, and error reduction with explainable insights. In finance, it aids fraud detection by mapping transactions and identifying hidden patterns through multi-hop reasoning, uncovering complex fraud networks.
Vector-Based RAG offers scalability and efficiency, excelling in handling unstructured data. In healthcare, it enables fast retrieval of semantically similar medical literature or patient records, supporting research and personalized care. In finance, it powers customer support and recommendation systems by efficiently processing large volumes of queries or transaction data. Graph-Based RAG emphasizes depth and explainability, while Vector-Based RAG focuses on speed and flexibility, making both essential for their respective domains.
Conclusion
Choosing between Graph-Based RAG and Vector-Based RAG is not a matter of superiority but of alignment with specific application needs. Graph-Based RAG thrives in domains like healthcare, where explainability is non-negotiable. For instance, a hospital system using knowledge graphs can trace the relationship between symptoms and treatments, ensuring decisions are transparent and evidence-based. However, this comes with the challenge of maintaining graph structures, akin to curating a vast, ever-evolving library.
Vector-Based RAG, by contrast, shines in unstructured environments like e-commerce. Imagine a platform recommending products based on semantic similarity—quick, scalable, and intuitive. Yet, its “black-box” nature often leaves users questioning the “why” behind results, a trade-off for speed.
A hybrid approach may seem ideal, but integrating these systems is like merging two languages—powerful yet complex. Ultimately, the choice depends on whether your priority is clarity or velocity.