
GraphRAG Implementation Using Local LLaMA Models
Implementing GraphRAG with local LLaMA models enhances context-aware retrieval and structured reasoning. This guide walks through setup, integration, and optimization strategies to build powerful, private RAG systems with graph-based intelligence.


Most retrieval systems fail when precision matters. You ask a nuanced question—something with real weight, like a legal clause or a medical interaction—and get a generic, surface-level answer.
This is where GraphRAG implementation using local LLaMA models starts to matter.
These systems are built for structure and context. GraphRAG combines the rigor of knowledge graphs with retrieval-augmented generation, while local LLaMA models bring the privacy and adaptability organizations need today.
The trade-off is that smaller, private models often miss semantic depth, and high-powered ones can be too costly to run locally.
The challenge is clear: how do you make GraphRAG implementation using local LLaMA models efficient and accurate, especially when the stakes are high?
This article breaks that down—how to build the graph, fine-tune the models, and extract real meaning from complex data without losing privacy or burning through resources.
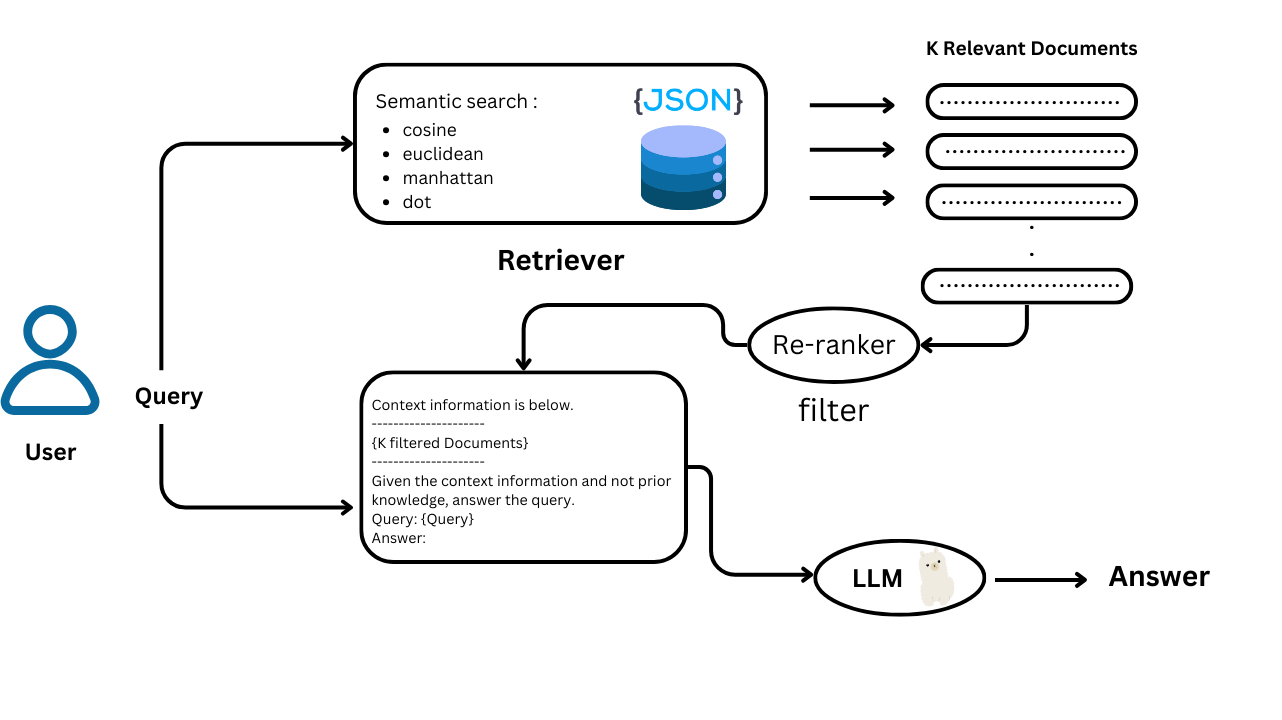
Defining GraphRAG: A Hybrid Framework
GraphRAG’s true innovation lies in integrating hierarchical community detection with retrieval-augmented generation (RAG).
This hybrid framework doesn’t just retrieve information; it organizes it into a structured hierarchy, enabling nuanced sensemaking across complex datasets.
What sets this approach apart is its reliance on modularity principles to partition knowledge graphs into nested communities.
These partitions allow for generating summaries that reflect local and global contexts.
For instance, the Louvain algorithm, widely recognized for its efficiency in community detection, plays a pivotal role in creating these modular structures. By leveraging this, GraphRAG ensures that each node—representing an entity or concept—contributes meaningfully to the narrative.
However, the framework’s effectiveness hinges on the quality of the language model used.
Smaller models, while cost-efficient, often fail to capture the semantic depth required for accurate entity relationships. This limitation becomes particularly evident in domains like legal or medical analysis, where precision is paramount.
By combining graph-based modularity with LLM capabilities, GraphRAG redefines how we approach large-scale data interpretation, offering a blueprint for more context-aware AI systems.
The Role of Local LLaMA Models in Data Processing
Local LLaMA models excel in scenarios where data privacy and contextual adaptability are paramount.
Unlike cloud-based solutions, these models process information entirely on-premises, ensuring sensitive data remains secure—a critical advantage in sectors like healthcare and finance.
The true strength of local LLaMA models lies in their ability to be fine-tuned for domain-specific tasks.
This adaptability stems from their architecture, which allows for targeted calibration of parameters such as token embeddings and attention mechanisms.
For instance, by optimizing hyperparameters like learning rate and batch size, practitioners can significantly enhance the model’s ability to extract nuanced relationships within datasets. This approach often outperforms generic, pre-trained models in specialized applications.
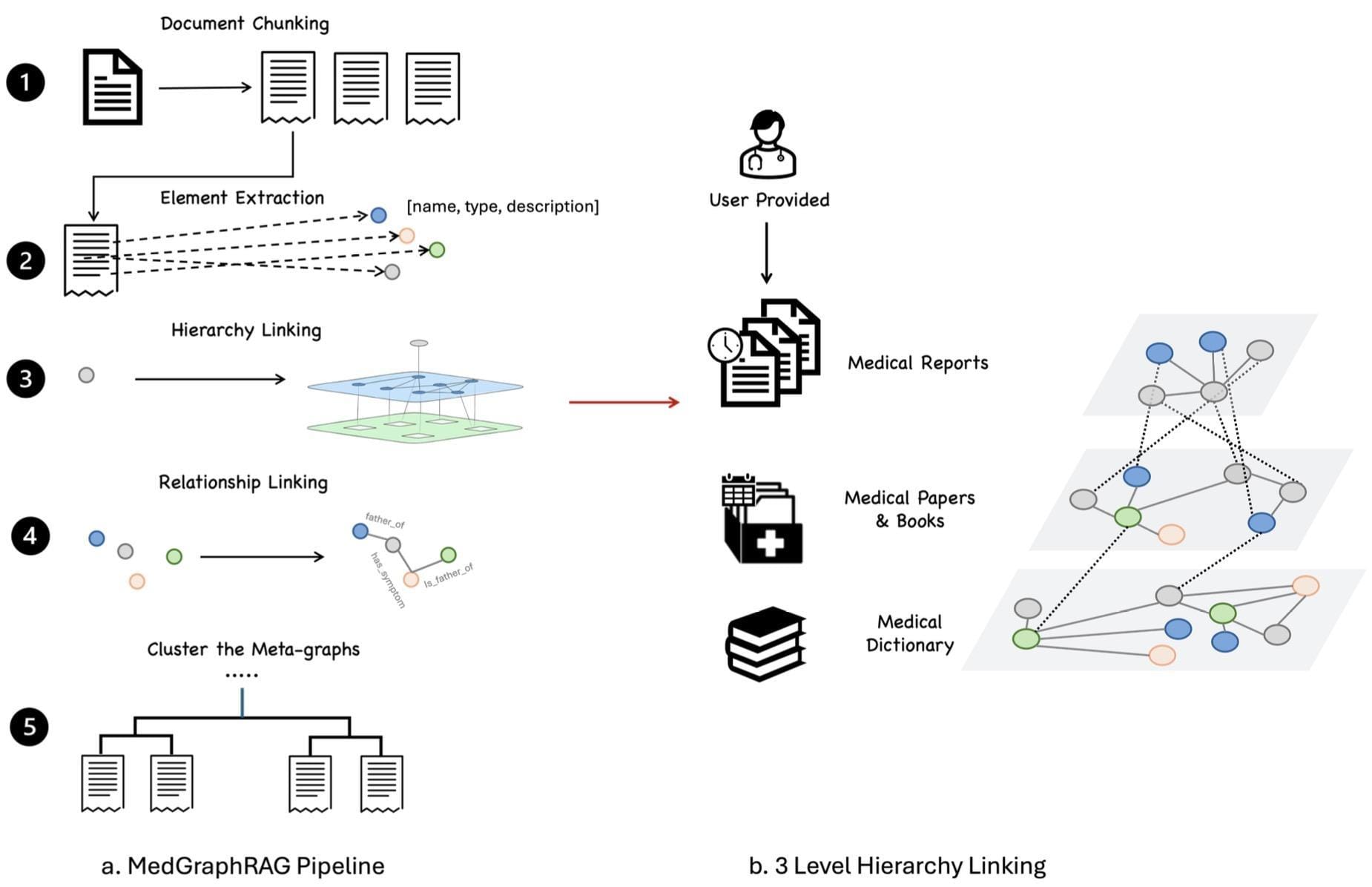
Constructing Knowledge Graphs for GraphRAG
Building a knowledge graph for GraphRAG is similar to crafting a dynamic blueprint of interconnected ideas, where every node and edge encapsulates a fragment of meaning.
The process begins with entity extraction, a step that transforms unstructured text into structured data by identifying key entities and their relationships.
For instance, Microsoft Research employs GPT-4 Turbo to generate initial graph structures, ensuring high semantic fidelity in representing complex datasets.
A critical yet often overlooked aspect is graph modularity, which determines how well the graph can be partitioned into meaningful communities.
Algorithms like Leiden or Infomap are instrumental here, as they recursively detect sub-communities, enabling hierarchical organization. This modularity not only enhances computational efficiency but also ensures that summaries reflect both granular and global contexts.
One counterintuitive insight is that data sparsity, often seen as a limitation, can actually improve graph interpretability.
Sparse graphs reduce noise, allowing algorithms to focus on significant relationships. This principle is particularly evident in applications like financial fraud detection, where sparse yet precise connections reveal hidden patterns.
Ultimately, constructing these graphs is not just a technical endeavor but a narrative one—transforming raw data into a coherent, query-ready structure that empowers decision-making.
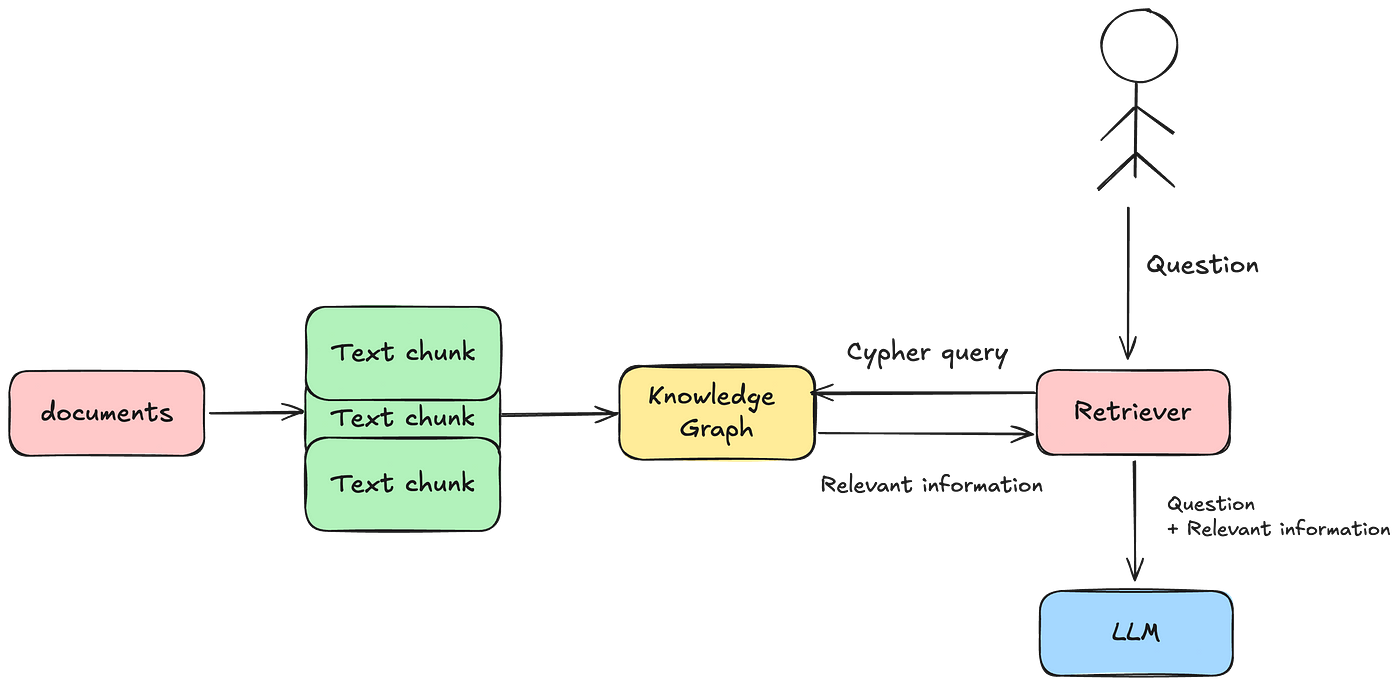
Basics of Knowledge Graph Construction
The foundation of effective knowledge graph construction lies in entity disambiguation, a process that ensures each node represents a unique and contextually accurate entity.
This step is critical because ambiguous or overlapping entities can distort the graph’s integrity, leading to flawed downstream applications.
By using advanced natural language processing (NLP) techniques, such as contextual embeddings, practitioners can differentiate between entities with similar names but distinct meanings, like “Apple” the company versus “apple” the fruit.
One approach that stands out is incremental graph updates, which allow for real-time integration of new data without rebuilding the entire graph.
This method not only preserves computational resources but also ensures the graph remains relevant as new information emerges.
For instance, in maritime logistics, companies like COSCO Shipping have implemented dynamic updates to track vessel movements, enabling more accurate scheduling and resource allocation.
However, challenges persist, such as balancing graph sparsity with completeness. Sparse graphs enhance interpretability but risk omitting critical relationships.
Addressing this requires domain-specific tuning, where algorithms prioritize high-value connections over exhaustive coverage. This nuanced approach ensures that knowledge graphs remain both actionable and efficient.
Community Detection and Summarization Techniques
Community detection in knowledge graphs is not a one-size-fits-all process; its success hinges on tailoring algorithms to the dataset’s unique structure.
For instance, the Leiden algorithm, while efficient, often requires iterative parameter tuning to balance granularity and coherence. This step ensures that detected communities reflect meaningful relationships rather than arbitrary clusters.
The principle of hierarchical organization is central to effective summarization. By structuring communities into nested layers, practitioners can generate summaries ranging from granular details to overarching themes.
However, this approach introduces challenges, such as determining the optimal hierarchy depth. Too shallow, and critical nuances are lost; too deep, and summaries become fragmented.
Tools like Neo4j enable dynamic adjustments, allowing practitioners to refine hierarchies based on real-time feedback.
A critical yet underexplored aspect is the role of centrality metrics in summarization. Identifying high-connectivity nodes within a community ensures that summaries prioritize the most influential entities.
For example, in pharmaceutical research, centrality-driven summaries have been used to highlight key compounds and their interactions, streamlining drug discovery processes.
Unexpectedly, data sparsity can enhance summarization by reducing noise, but it also risks omitting subtle relationships.
Addressing this requires a hybrid approach: combining algorithmic insights with domain expertise to validate and refine outputs. This interplay between automation and human judgment transforms raw data into actionable intelligence.
Integrating Local LLaMA Models with GraphRAG
Integrating local LLaMA models into GraphRAG pipelines demands a nuanced approach that balances computational efficiency with the precision required for high-stakes applications.
A critical insight here is the interplay between model architecture and graph traversal algorithms.
For instance, smaller LLaMA models, such as LLaMA-38B, excel in environments with constrained resources but often struggle with semantic depth, particularly in domains like legal analytics or medical diagnostics.
This limitation can be mitigated by leveraging adaptive embedding techniques, which dynamically adjust token representations based on graph context, reducing the semantic gap without increasing model size.
One counterintuitive finding is that incremental graph updates, when paired with local LLaMA models, can outperform static graph structures in real-time applications.
Ultimately, integrating local LLaMA models with GraphRAG is not merely a technical exercise but a strategic decision that redefines how organizations approach data sovereignty and operational scalability.
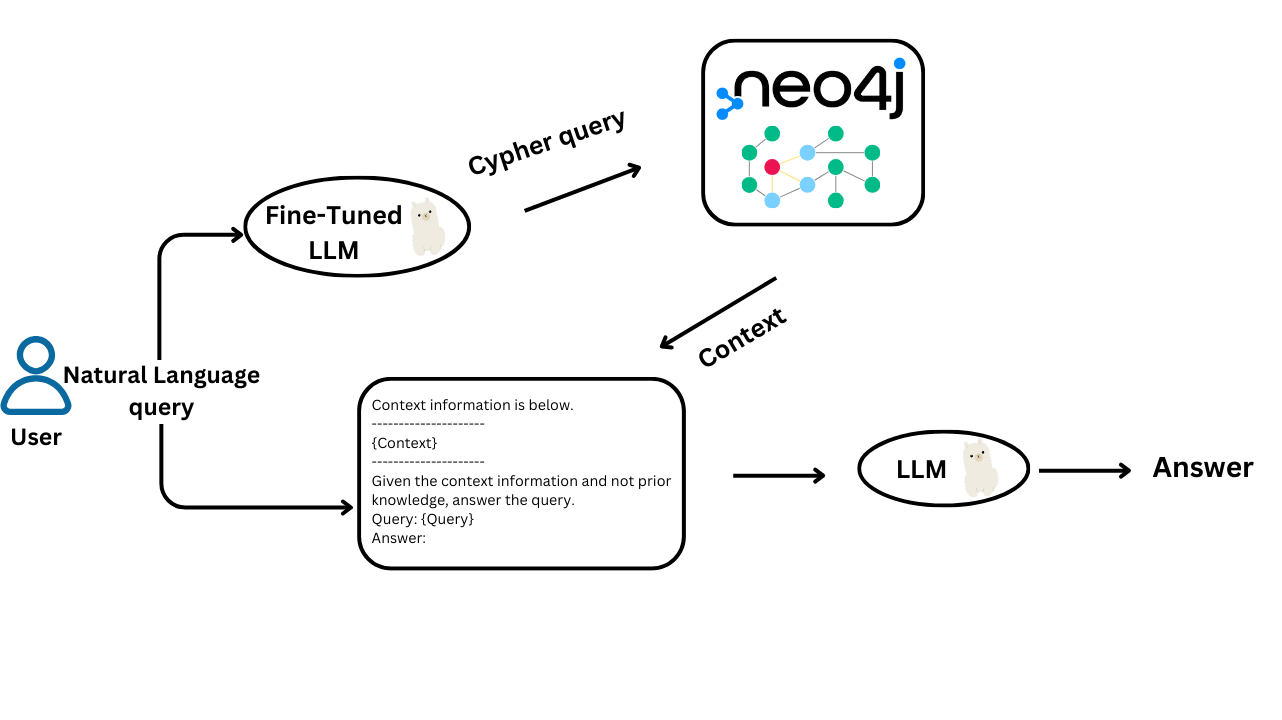
Optimizing Local LLaMA Models for Efficiency
Efficiency in local LLaMA models hinges on aligning computational strategies with the unique demands of GraphRAG.
One critical technique is adaptive token embedding, which dynamically adjusts embeddings based on graph traversal context.
This minimizes redundant computations while preserving semantic depth, a balance often overlooked in static embedding approaches.
The principle of incremental subgraph updates further refines efficiency.
Instead of reprocessing entire graphs, only affected subgraphs are updated during queries. This method reduces latency and ensures data privacy by limiting the scope of processing.
For example, in supply chain analytics, this approach has enabled real-time adjustments without compromising sensitive operational data.
However, challenges arise in maintaining model responsiveness under high query loads.
Fine-tuning attention mechanisms to prioritize high-value nodes can mitigate this, but it requires domain-specific calibration.
This nuanced interplay between architecture and application underscores the need for tailored optimization strategies, transforming local LLaMA models into robust tools for complex, real-time data environments.
Ensuring Privacy and Cost-Efficiency
Local LLaMA models safeguard sensitive data while maintaining cost-efficiency, particularly when paired with incremental graph updates.
This approach processes only the necessary subgraphs during queries, reducing computational overhead and minimizing exposure to potential data leaks.
By focusing on targeted updates, organizations can balance operational efficiency and stringent privacy requirements.
A critical yet underappreciated factor is the role of fine-tuning in optimizing local models for domain-specific tasks.
Unlike generic cloud-based solutions, local models can be calibrated to prioritize contextually relevant outputs, ensuring precision without excessive resource consumption.
This tailored approach enhances performance and aligns with privacy-first strategies, as data remains securely on-premises.
However, maintaining this balance under high query loads can be challenging.
Techniques like adaptive token embedding can mitigate these issues by dynamically adjusting processing depth based on query complexity.
This nuanced integration of privacy and efficiency transforms local LLaMA models into indispensable tools for high-stakes applications, from legal analytics to financial forecasting.
Advanced Query Processing and Answer Generation
Effective query processing in GraphRAG systems hinges on the interplay between graph traversal algorithms and the contextual adaptability of local LLaMA models.
A critical insight is the role of multi-hop reasoning, where queries traverse multiple graph nodes to synthesize relationships across disparate data points.
This approach ensures that answers are accurate and contextually enriched, addressing the nuanced demands of complex domains like legal or medical analytics.One often-overlooked challenge is query ambiguity, where vague or multi-faceted questions can derail answer generation.
By integrating dynamic prompt engineering, practitioners can guide the system to focus on relevant graph regions, reducing noise and improving precision.
For instance, rephrasing a query to emphasize temporal relationships can help uncover hidden patterns in financial datasets.Think of this process as navigating a dense forest: the graph provides the map, while the LLaMA model acts as the compass, dynamically adjusting its path based on the terrain.
This synergy transforms raw data into actionable insights, redefining how organizations approach decision-making in high-stakes environments.The implications are profound.
By refining query processing techniques, GraphRAG systems enhance answer quality and empower users to tackle increasingly complex questions with confidence.
Developing Custom Query Engines
Designing custom query engines for GraphRAG is akin to crafting a tailored dialogue system, where every query acts as a carefully calibrated question.
The key lies in adaptive query structuring, which aligns the engine’s traversal logic with the graph’s unique topology.
This approach ensures that the system navigates the graph with precision, avoiding irrelevant nodes and focusing on high-value connections.One critical component is context-aware prompt engineering, which dynamically adjusts query parameters based on the graph’s hierarchical structure.
For example, prompts can be fine-tuned to prioritize specific subgraphs or community layers, enabling the engine to extract nuanced insights.
This contrasts with static query models, which often falter in complex, multi-hop scenarios. The flexibility of this method is particularly evident in domains like supply chain analytics, where real-time adjustments are crucial.However, challenges arise when dealing with ambiguous graph regions—areas where relationships are sparse or poorly defined.
To address this, practitioners can implement contextual disambiguation algorithms, which leverage semantic embeddings to clarify node relationships. This technique enhances retrieval accuracy and reduces computational overhead by narrowing the search space.By integrating these advanced methodologies, custom query engines transform GraphRAG systems into powerful tools for extracting actionable intelligence, even in the most intricate data landscapes.
Enhancing Answer Diversity and Comprehensiveness
Answer diversity thrives on the ability to traverse unconventional paths within a knowledge graph.
By enabling multi-hop reasoning, GraphRAG systems uncover intricate relationships that static methods often miss. This approach ensures that responses are varied and deeply rooted in the graph’s structural complexity.A critical technique involves dynamic query path adjustments, where the system recalibrates its traversal strategy based on intermediate findings.
This flexibility allows the model to pivot toward less obvious nodes, enriching the contextual depth of its answers.
For instance, reconfiguring query paths in a legal analytics scenario revealed latent connections between case precedents, offering insights that traditional methods overlooked.Token embedding plays a pivotal role here.
The system maintains semantic coherence across diverse query paths by dynamically aligning embeddings with local graph transitions.
This nuanced calibration bridges the gap between comprehensiveness and specificity, ensuring that answers remain both detailed and relevant.In practice, this interplay between adaptive algorithms and domain-specific intuition transforms GraphRAG into a tool capable of delivering answers as diverse as the questions it tackles, redefining the boundaries of query-focused summarization.
FAQ
What are the key steps to implement GraphRAG with local LLaMA models for entity relationship optimization?
Start by extracting entities and mapping them into a knowledge graph. Apply salience analysis to focus on important nodes. Use co-occurrence analysis to refine relationships. Fine-tune local LLaMA models with structured prompts to match the graph’s context and improve query responses.
How does salience analysis enhance the performance of GraphRAG in local deployments?
Salience analysis identifies the most important nodes in a graph, helping local LLaMA models prioritize relevant content during query processing. This reduces noise, sharpens retrieval focus, and improves the precision of generated responses in localized environments where compute and context must align.
What role does co-occurrence optimization play in improving query accuracy within GraphRAG systems?
Co-occurrence optimization tracks how often entities appear together, reinforcing key relationships in the graph. This helps GraphRAG systems deliver more accurate and relevant answers by refining the graph structure and improving how local LLaMA models rank and retrieve context-specific data.
How can hierarchical community detection be integrated into GraphRAG using local LLaMA models?
Use algorithms like Leiden to form communities within the graph. Structure these into layers for better context. Fine-tune local LLaMA embeddings to capture entity roles within each layer, then apply salience and co-occurrence filters to improve summarization and response quality.
What are the best practices for fine-tuning local LLaMA models to maximize their efficiency in GraphRAG implementations?
Use domain-specific data to fine-tune embeddings. Adjust learning rate and batch size based on graph size. Apply salience scoring to focus training on key entities. Use prompts aligned with graph structure to guide responses. This improves both efficiency and context alignment in retrieval tasks.
Conclusion
GraphRAG implementation using local LLaMA models combines structured knowledge graphs with privacy-aware, on-premise language models.
This setup improves query accuracy, reduces latency, and supports high-stakes tasks in law, healthcare, and enterprise data systems. With fine-tuned embeddings and efficient graph traversal, this method offers a grounded approach to context-rich AI applications where both control and clarity matter.