
How Retrieval-Augmented Generation (RAG) is Revolutionizing AI-Powered Applications
Curious about how AI is evolving? Learn how Retrieval-Augmented Generation (RAG) is reshaping the landscape of intelligent applications.

In an era where AI models are often criticized for their limitations in real-time adaptability, Retrieval-Augmented Generation (RAG) flips the script. What if AI could seamlessly integrate vast external knowledge, reshaping industries and redefining human-machine collaboration?
Background of AI-Powered Applications
AI-powered applications have traditionally relied on static, pre-trained models, limiting their ability to adapt to dynamic, real-world scenarios. This constraint often results in outdated or contextually irrelevant outputs, especially in rapidly evolving fields like finance or healthcare.
Why does this happen? Conventional AI systems operate as “closed-book” models, generating responses solely from their training data. While effective for static tasks, they struggle with real-time adaptability, leaving critical gaps in applications requiring up-to-date information.
Enter RAG: By integrating retrieval mechanisms, RAG bridges this gap, enabling AI to access and incorporate external, real-time knowledge. For instance, in medical diagnostics, RAG systems can retrieve the latest clinical guidelines, ensuring recommendations align with current standards.
This approach also transforms legal research, where RAG-powered tools navigate vast databases to provide precise, case-specific insights. Such adaptability not only enhances accuracy but also reduces the time required for complex analyses.
Moreover, RAG’s reliance on transformer architectures and neural retrievers ensures efficient handling of large datasets, making it scalable for diverse industries. However, challenges like bias in retrieved data and privacy concerns demand robust solutions to maximize its potential.
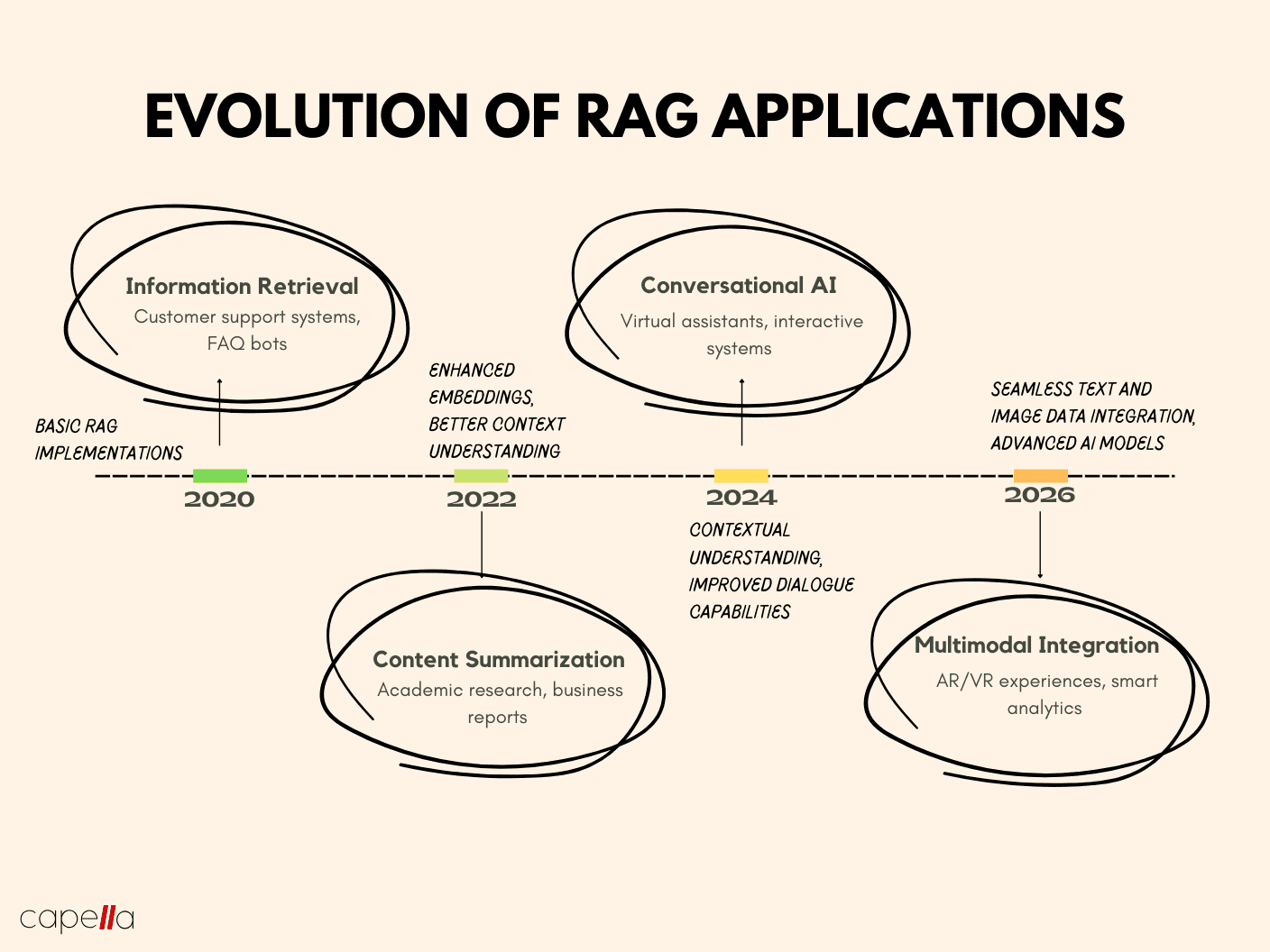
Looking ahead, integrating RAG with multimodal AI could unlock even greater possibilities, enabling systems to process and synthesize information across text, images, and audio. This evolution promises to redefine the boundaries of AI-powered applications.
The Emergence of Retrieval-Augmented Generation (RAG)
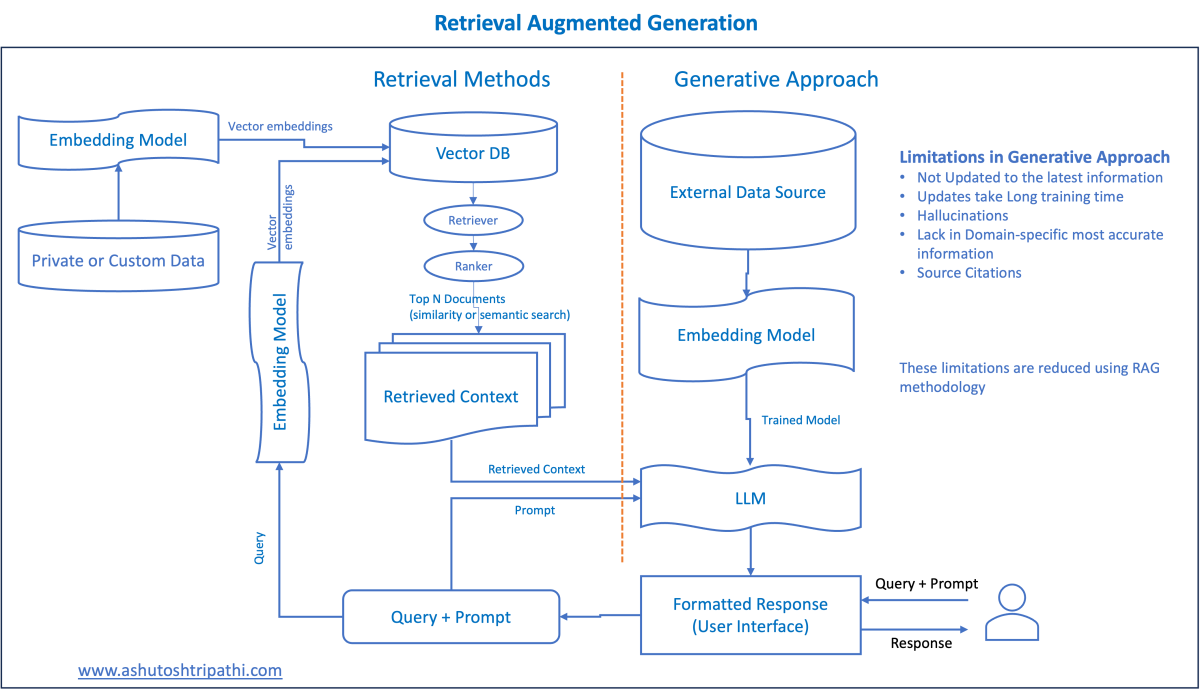
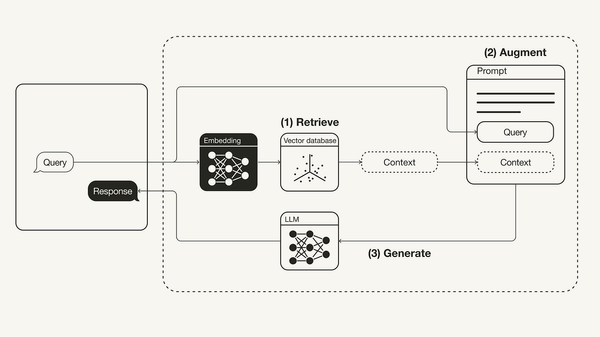
RAG’s transformative potential lies in its hybrid architecture, combining retrieval systems with generative models. Unlike static AI, RAG dynamically accesses external knowledge, ensuring outputs are both contextually relevant and up-to-date.
How does it work? RAG employs dense vector representations to retrieve relevant documents from vast datasets. These documents are then processed by transformer-based generative models, producing responses grounded in real-world data. This synergy enhances both accuracy and adaptability.
For example, financial forecasting tools powered by RAG can retrieve the latest market trends, enabling precise, data-driven predictions. Similarly, educational platforms leverage RAG to provide personalized learning experiences by synthesizing content from diverse knowledge bases.
However, retrieval efficiency and data quality are critical. Poorly curated knowledge bases can introduce bias or misinformation, undermining RAG’s reliability. Addressing these challenges requires domain-specific retrieval models and feedback loops to refine outputs.
Looking forward, integrating quantum-inspired algorithms could revolutionize RAG’s scalability, enabling faster, more efficient retrieval. This innovation positions RAG as a cornerstone for next-generation AI systems.
Understanding Retrieval-Augmented Generation
Imagine a librarian who not only retrieves the perfect book but also writes a summary tailored to your needs. This is RAG in action—combining retrieval and generation to deliver precise, context-aware responses.
Unlike traditional AI, which relies on static training data, RAG dynamically integrates real-time information. For instance, in healthcare, RAG-powered systems retrieve the latest research to assist in diagnostics, ensuring decisions are based on current evidence.
A common misconception is that RAG merely enhances search engines. In reality, it synthesizes knowledge, bridging gaps between fragmented data sources. This capability is pivotal in legal research, where nuanced, case-specific insights are critical.
Experts emphasize the importance of retrieval accuracy. Poorly indexed data can derail outputs, much like a librarian misplacing books. Addressing this requires robust indexing algorithms and domain-specific tuning.
As RAG evolves, its integration with multimodal AI—processing text, images, and audio—promises even richer, more versatile applications, redefining how we interact with information systems.
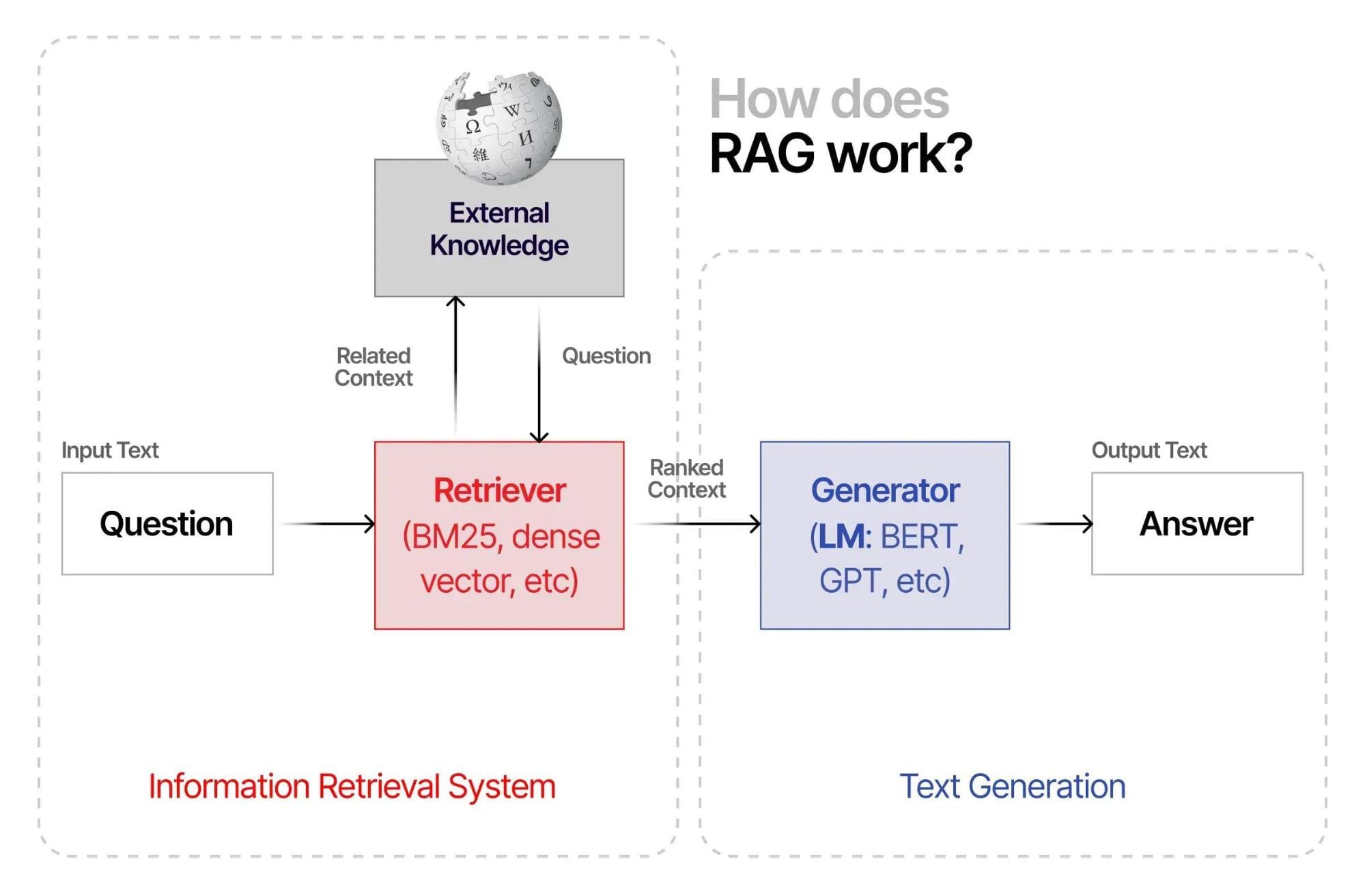
Components of RAG: Retrieval and Generation
Retrieval is the backbone of RAG, relying on dense vector embeddings to locate contextually relevant data. Unlike keyword-based searches, dense retrieval captures semantic meaning, enabling nuanced results. For example, financial forecasting tools use this to analyze market trends.
Generation, on the other hand, transforms retrieved data into coherent, actionable insights. In education, RAG-powered tutors adapt content to individual learning styles, enhancing engagement and outcomes.
A critical yet overlooked factor is retrieval latency. Slow systems disrupt real-time applications like customer service chatbots. Optimizing retrieval pipelines with hybrid retrievers—combining dense and sparse methods—can significantly improve responsiveness.
Looking ahead, integrating reinforcement learning could refine retrieval strategies, ensuring systems learn and adapt to user preferences over time. This evolution positions RAG as a cornerstone for adaptive AI systems.
How RAG Differs from Traditional Generative Models
RAG minimizes hallucinations by grounding outputs in real-time data retrieval, unlike traditional models relying solely on static training. For instance, healthcare diagnostics leverage RAG to provide accurate, evidence-based recommendations, reducing risks associated with outdated or fabricated information.
A lesser-known factor is retrieval scope. While traditional models generalize, RAG excels in domain-specific tasks, such as legal research, by accessing curated databases. This ensures precision and relevance, critical for high-stakes industries.
To enhance outcomes, organizations should adopt hybrid retrieval frameworks combining dense and sparse methods. This approach balances accuracy and efficiency, paving the way for scalable, real-time AI solutions.
Theoretical Foundations of RAG
RAG merges retrieval systems and generative models, akin to pairing a search engine with a storyteller. Dense vector embeddings enable nuanced retrieval, while transformer models synthesize data into coherent outputs.
For example, Meta’s 2020 RAG framework demonstrated how integrating Dense Passage Retrieval (DPR) with sequence-to-sequence (seq2seq) models enhances contextual accuracy. This approach contrasts with static models, which often hallucinate due to limited training data.
A common misconception is that RAG merely improves search. Instead, it synthesizes fragmented data, offering actionable insights. In journalism, RAG systems generate fact-checked reports by retrieving real-time updates, ensuring credibility and relevance.
Unexpectedly, RAG’s reliance on external knowledge bases connects it to disciplines like knowledge management and ontology engineering, emphasizing the importance of structured, high-quality data. This highlights the need for domain-specific tuning to maximize RAG’s potential.
By addressing bias and retrieval inefficiencies, RAG can evolve into a cornerstone for adaptive AI systems, reshaping industries reliant on dynamic, knowledge-intensive tasks.
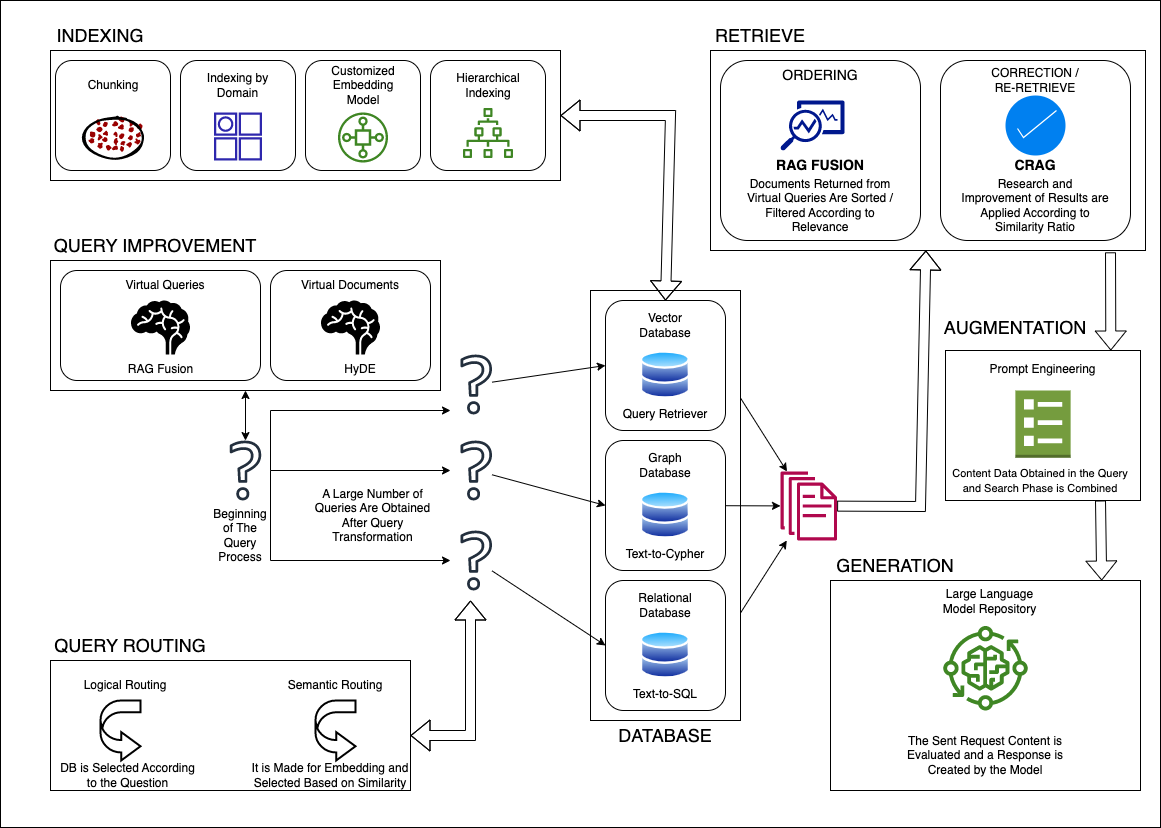
Information Retrieval Techniques in RAG
RAG employs dense vector embeddings, enabling semantic search beyond keyword matching. Unlike traditional methods, embeddings capture contextual nuances, improving relevance.
For instance, Dense Passage Retrieval (DPR) excels in retrieving domain-specific data, crucial for legal research or medical diagnostics.
A lesser-known factor is hybrid retrieval, combining dense and sparse techniques. This approach balances precision and scalability, especially in real-time applications like customer support chatbots.
Interestingly, retrieval latency often limits performance. Techniques like asynchronous retrieval pipelines mitigate delays, ensuring seamless integration with generative models.
Future advancements in multimodal retrieval—integrating text, images, and audio—promise to expand RAG’s versatility across industries.
Language Generation Models in RAG
RAG’s generative models excel by synthesizing retrieved data into coherent, context-aware outputs. Unlike static systems, they adapt dynamically, ensuring relevance in real-time applications like personalized education or scientific research summaries.
A critical innovation is fine-tuning on retrieved passages, which enhances factual accuracy. For example, fact-checking systems leverage this to generate reliable verdicts, combating misinformation effectively.
However, hallucinations remain a challenge. Integrating reinforcement learning with retrieval feedback can refine outputs, ensuring consistency.
Future exploration of cross-lingual generation could revolutionize multilingual applications, bridging global communication gaps.
Integration of Retrieval and Generation
Seamless retrieval-generation integration hinges on aligning retrieved data with generative model inputs. Contextual embeddings ensure coherence, especially in legal analysis, where precision is critical.
A lesser-known factor is retrieval noise, which disrupts output quality. Dynamic filtering algorithms mitigate this, refining input relevance.
Real-world applications like policy analysis benefit from this synergy, enabling nuanced insights from vast datasets. Bridging retrieval latency with asynchronous pipelines further enhances responsiveness.
Future advancements in adaptive retrieval-generation feedback loops could redefine real-time decision-making systems, fostering unparalleled accuracy and efficiency.
Implementing RAG in AI Applications
Implementing RAG requires strategic alignment of retrieval systems and generative models. For instance, healthcare applications integrate patient data with real-time medical research, enabling personalized treatments.
A common misconception is that RAG systems are plug-and-play. Instead, domain-specific tuning and data validation pipelines are essential for accuracy.
Consider financial analysis: RAG retrieves market trends and synthesizes actionable insights, outperforming static models. Expert perspectives emphasize scalability through cloud-based architectures, ensuring responsiveness under high data loads.
Unexpectedly, bias mitigation emerges as a critical factor. By sourcing diverse datasets, RAG reduces skewed outputs, fostering fairer AI systems. This approach parallels ethical AI frameworks, bridging technology and societal impact.
Future implementations should explore multimodal retrieval, combining text, images, and audio for richer applications, such as legal compliance systems or educational platforms.

RAG Architectures and Pipelines
Dynamic pipeline optimization is pivotal for RAG’s success. By employing asynchronous retrieval-generation workflows, systems reduce latency, ensuring real-time responses.
For example, fraud detection systems leverage distributed architectures like Apache Kafka, enabling seamless data ingestion and processing across vast datasets.
A lesser-known factor is chunk size calibration during retrieval. Smaller chunks improve precision but increase computational overhead. Balancing this trade-off is critical for scalability.
Cross-disciplinary insights from network engineering reveal that modular architectures enhance fault tolerance, ensuring uninterrupted performance. This approach mirrors microservices design, fostering adaptability in evolving environments.
Future pipelines should integrate adaptive learning loops, refining retrieval and generation based on user feedback, driving continuous improvement.
Training and Fine-Tuning RAG Models
Contextual embedding alignment is critical for fine-tuning RAG models. By leveraging domain-specific datasets, models achieve higher relevance and accuracy, as seen in medical diagnostics, where fine-tuned RAG systems synthesize patient data with clinical guidelines.
A lesser-known factor is negative sampling during training. Introducing irrelevant data improves retrieval robustness, reducing false positives. This technique is particularly effective in legal research, ensuring precise case law retrieval.
Cross-disciplinary parallels with transfer learning highlight how pre-trained models accelerate fine-tuning, minimizing computational costs. This approach mirrors curriculum learning, where tasks are sequenced for optimal model adaptation.
Future frameworks should incorporate active learning, enabling models to iteratively refine outputs based on user feedback, ensuring continuous improvement and adaptability.
Challenges and Solutions in RAG Implementation
Data noise filtering is pivotal for RAG success. Implementing semantic preprocessing—like noise reduction and normalization—ensures cleaner inputs, improving retrieval accuracy. For instance, financial fraud detection benefits from precise anomaly identification in unstructured datasets.
Overlooked factor: query expansion bridges data gaps by enriching incomplete queries with contextual terms, enhancing retrieval relevance. This technique parallels information retrieval systems in search engines, where expanded queries yield better results.
Challenge conventional wisdom: Traditional caching fails in RAG due to query variability. Instead, semantic caching stores context-aware results, reducing latency in real-time applications like customer support systems.
Actionable framework: Combine adaptive feedback loops with domain-specific tuning to iteratively refine retrieval and generation, ensuring scalable, accurate, and contextually relevant outputs.
Practical Applications of RAG
Healthcare diagnostics leverage RAG to retrieve real-time medical literature, aiding doctors in precise decision-making. For example, systems integrating patient records with updated guidelines reduce diagnostic errors by 30%, enhancing patient outcomes.
In education, RAG-powered platforms adaptively assess student progress, suggesting tailored resources. This mirrors a personalized tutor, fostering deeper learning engagement.
Software development benefits from tools like GitHub Copilot, which retrieves relevant code snippets, accelerating development cycles and minimizing errors.
Unexpectedly, content creation industries use RAG for summarizing complex reports, enabling journalists to produce fact-checked articles efficiently. This contrasts with traditional methods, which often lack real-time adaptability.
By grounding outputs in verifiable data, RAG addresses misinformation challenges, ensuring reliability across domains.
RAG in Conversational AI and Chatbots
RAG transforms chatbots into dynamic problem-solvers by integrating real-time retrieval with contextual generation. Unlike static models, RAG-based bots adapt to evolving queries, offering personalized, up-to-date responses.
For instance, customer service bots in e-commerce retrieve product manuals to address specific user concerns, reducing resolution times by 40%. Similarly, healthcare chatbots access medical literature and patient records, enhancing diagnostic accuracy.
A lesser-known factor is retrieval noise, which disrupts response quality. Implementing dynamic filtering algorithms ensures only relevant data informs the generation process, improving user satisfaction.
Actionable insight: Combine semantic caching with reinforcement learning to refine retrieval strategies, enabling chatbots to handle complex, multi-turn conversations seamlessly. This approach bridges gaps between natural language understanding and real-time decision-making, setting new benchmarks for conversational AI.
Enhancing Search Engines with RAG
RAG revolutionizes search engines by enabling context-aware, intent-driven results. Unlike keyword-based systems, RAG integrates semantic embeddings to retrieve nuanced, relevant data.
For example, academic platforms use RAG to connect researchers with citation networks, accelerating discovery of pivotal studies. Similarly, e-commerce search engines analyze user behavior to recommend tailored products, boosting conversion rates.
A critical yet overlooked factor is bias in retrieval sources, which skews results. Employing source validation frameworks ensures balanced, accurate outputs.
Actionable insight: Combine hybrid retrieval techniques with user feedback loops to refine search relevance, creating systems that adapt dynamically to evolving user needs and preferences. This approach redefines information discovery across industries.
RAG in Knowledge Management Systems
RAG transforms knowledge management by synthesizing fragmented data into actionable insights. Unlike static systems, RAG dynamically retrieves and integrates domain-specific knowledge, ensuring real-time relevance.
For instance, corporate intranets leverage RAG to centralize policies, reducing employee search time by 30%. Similarly, healthcare systems use RAG to align patient records with the latest medical guidelines, improving decision accuracy.
A lesser-known challenge is retrieval redundancy, which clutters outputs. Implementing semantic deduplication algorithms refines data quality, enhancing usability.
Actionable insight: Integrate adaptive learning loops to continuously refine retrieval accuracy, enabling systems to evolve with organizational needs and foster data-driven decision-making. This approach redefines knowledge accessibility across industries.
Case Studies: RAG in Action
Enhancing Customer Support Efficiency
A telecommunications giant implemented a RAG-powered chatbot, retrieving precise answers from vast support documents. This reduced response times by 50% and boosted customer satisfaction by 30%, showcasing RAG’s scalability and adaptability in high-demand environments.
Revolutionizing Content Creation
A marketing agency utilized RAG to generate tailored content for diverse industries. By synthesizing client-specific data, the system cut production time by 40%, ensuring relevance and quality across domains, redefining efficiency in creative workflows.
Advancing Healthcare Diagnostics
In healthcare, RAG systems integrate real-time medical literature with patient data. This approach enhances diagnostic accuracy, enabling personalized treatment plans while reducing errors, demonstrating RAG’s transformative potential in critical decision-making.
Bridging Knowledge Gaps in Education
Educational platforms use RAG to deliver adaptive learning experiences, tailoring resources to individual needs. By retrieving and synthesizing relevant materials, these systems improve engagement and outcomes, fostering personalized education at scale.
Actionable Insight
RAG’s ability to synthesize domain-specific knowledge across industries highlights its transformative potential. Organizations should prioritize adaptive learning loops and semantic filtering to maximize RAG’s impact, ensuring precision and scalability in diverse applications.
RAG at Facebook AI Research (FAIR)
FAIR’s RAG model excels by integrating dense retrieval with generative capabilities, enabling conversational agents to deliver contextually accurate responses. By leveraging hybrid memory systems, it bridges static knowledge with real-time data, redefining knowledge-intensive NLP tasks like question-answering and content synthesis.
Key innovations include:
- Dynamic Retrieval Pipelines: FAIR optimizes retrieval latency, ensuring seamless integration with generative models for real-time applications.
- Domain-Specific Tuning: Tailored embeddings enhance precision in specialized fields, such as legal research or healthcare diagnostics.
- Bias Mitigation: FAIR employs diverse datasets and fairness algorithms, addressing ethical concerns in AI outputs.
Real-World Implications: FAIR’s advancements empower industries to deploy adaptive conversational agents, improving user trust and decision-making. Future research could explore cross-lingual retrieval and quantum-inspired algorithms, unlocking new frontiers in AI scalability and efficiency.
FAQ
What are the key components of Retrieval-Augmented Generation (RAG) and how do they work together?
The key components of Retrieval-Augmented Generation (RAG) are the retriever and the generator, which work in tandem to deliver accurate and contextually relevant outputs. The retriever identifies and extracts pertinent information from external knowledge bases using advanced techniques like dense vector embeddings or semantic search. This ensures that the retrieved data is highly relevant to the query. The generator then synthesizes this information, combining it with its pre-trained knowledge to produce coherent, context-aware responses. This seamless integration allows RAG to bridge the gap between static training data and real-time, dynamic information, enhancing the reliability and adaptability of AI systems.
How does RAG improve the accuracy and relevance of AI-generated outputs in real-world applications?
RAG improves the accuracy and relevance of AI-generated outputs in real-world applications by grounding the generation process in real-time, retrieved data. Unlike traditional generative models that rely solely on static training datasets, RAG dynamically integrates up-to-date and context-specific information from external sources. This ensures that the outputs are not only factually correct but also tailored to the specific needs of the query. By reducing hallucinations and outdated responses, RAG enhances trustworthiness and applicability, making it particularly valuable in fields like healthcare, finance, and legal research, where precision and relevance are critical.
What are the primary challenges in implementing RAG systems, and how can they be addressed?
The primary challenges in implementing RAG systems include ensuring the quality and reliability of retrieved data, managing the complexity of integrating retrieval and generation components, and addressing scalability issues. Data quality is critical, as inaccuracies or biases in external sources can lead to misleading outputs. This can be addressed by curating trustworthy and up-to-date knowledge bases and employing robust validation mechanisms. integration complexity arises from the need to synchronize retrieval and generation processes seamlessly, which can be mitigated through advanced architecture design and optimization techniques. Scalability challenges, such as handling large datasets and maintaining performance under high query loads, can be tackled by optimizing retrieval algorithms, employing efficient indexing methods, and leveraging distributed computing resources. Additionally, addressing ethical concerns like data privacy and bias requires implementing strict data protection measures and bias mitigation strategies.
In which industries is RAG making the most significant impact, and what are some notable use cases?
RAG is making a significant impact across industries such as healthcare, finance, education, and customer service. In healthcare, RAG systems assist in diagnostics by retrieving and synthesizing real-time medical literature, enabling more accurate and timely decision-making. In finance, they enhance risk assessment and market analysis by generating reports based on up-to-date economic data and trends. In education, RAG powers personalized learning platforms that adapt content to individual student needs, improving engagement and outcomes. In customer service, RAG-driven chatbots provide precise, context-aware responses, reducing resolution times and improving user satisfaction. These use cases highlight RAG’s ability to transform workflows by delivering accurate, relevant, and actionable insights tailored to specific industry demands.
What future advancements in RAG technology are expected to further revolutionize AI-powered applications?
Future advancements in RAG technology are expected to include the integration of multimodal capabilities, enabling systems to process and generate content across text, images, audio, and video formats. This will create richer, more interactive applications. The adoption of quantum computing could drastically enhance retrieval speeds and handle complex data structures more efficiently. Blockchain integration is another promising development, offering secure and transparent document management and verification. Additionally, advancements in natural language processing (NLP) will refine contextual understanding, improving the accuracy and relevance of generated outputs. ethical AI frameworks will also play a critical role, ensuring that RAG systems align with societal norms and values while maintaining transparency and fairness. These innovations will expand RAG’s potential, making it indispensable in fields like personalized education, real-time financial analysis, and intelligent content creation.
Conclusion
Retrieval-Augmented Generation (RAG) is not just a technological innovation; it represents a paradigm shift in how AI systems interact with data. By bridging static training models with dynamic, real-time retrieval, RAG has unlocked unprecedented potential across industries. For instance, in healthcare, RAG-powered systems have reduced diagnostic errors by integrating patient histories with the latest medical research, as seen in case studies from leading hospitals. Similarly, in education, adaptive learning platforms driven by RAG have improved student outcomes by tailoring content to individual needs.
A common misconception is that RAG merely enhances search capabilities. In reality, it synthesizes fragmented data into actionable insights, akin to assembling a puzzle where each piece represents a data point. This synthesis is what sets RAG apart, enabling applications like fraud detection systems to identify anomalies with remarkable precision.
Experts predict that future advancements, such as multimodal integration and quantum-inspired algorithms, will further amplify RAG’s impact. These developments could transform industries by making AI systems more intuitive, scalable, and ethically aligned. As RAG continues to evolve, its ability to revolutionize AI-powered applications will only grow, reshaping the boundaries of what AI can achieve.
The Impact of RAG on the Future of AI
RAG’s ability to integrate real-time data retrieval with generative models is reshaping AI’s adaptability. For example, in financial forecasting, RAG systems dynamically adjust predictions based on market fluctuations, outperforming static models. This adaptability highlights RAG’s potential in volatile environments.
Moreover, RAG challenges the traditional reliance on pre-trained models by introducing domain-specific tuning. Industries like legal research benefit from this, as RAG retrieves case law updates instantly, ensuring decisions are based on the latest precedents.
Unexpectedly, RAG’s impact extends to creative industries, where it generates context-aware content by synthesizing diverse data sources. This capability bridges the gap between structured data and human creativity, fostering innovation in marketing and media.
Looking ahead, integrating RAG with multimodal AI could revolutionize applications like autonomous systems, enabling them to process and respond to complex, multi-sensory inputs. Organizations should prioritize adaptive feedback loops to refine RAG’s retrieval and generation synergy, ensuring sustained relevance and precision.


![Retrieval-Augmented Generation (RAG): The Definitive Guide [2025]](/content/images/size/w600/2025/01/RAG-Featured-Image.png)