
How to Get Really Good at Retrieval-Augmented Generation (RAG)
Want to get really good at RAG? This guide covers key techniques, best practices, and optimization strategies to improve retrieval-augmented generation, enhancing AI accuracy, efficiency, and contextual understanding for better performance.


Imagine two AI systems answering the same set of complex questions. One relies only on pre-trained data, while the other uses Retrieval-Augmented Generation (RAG) to pull in real-time information.
The difference is clear—the RAG system provides more accurate answers and cites up-to-date sources, proving that AI must integrate live data to stay relevant.
RAG bridges the gap between retrieval and generation, pulling precise details from vast datasets and transforming them into context-rich responses.
But mastering it isn’t simple. It requires technical expertise, from optimizing retrieval pipelines to fine-tuning language models. This article explores how to get good, and by that, we mean really good, at building an effective RAG system using real-world examples and tested strategies.
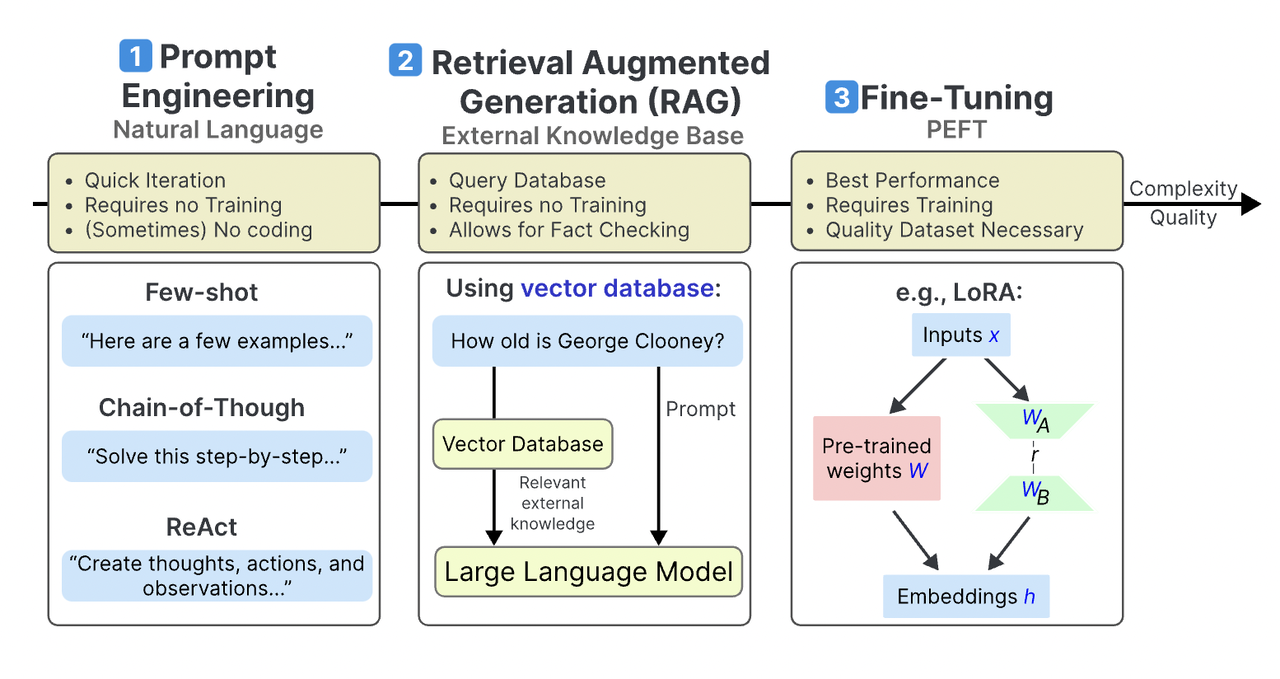
Core Components of RAG
The seamless interplay between Retrieval-Augmented Generation (RAG) 's two primary components—the retriever and the generator—is at the heart of RAG.
While this architecture may appear straightforward, its effectiveness hinges on nuanced design choices that directly impact performance.
The retriever’s role is to identify and extract the most relevant data from vast, often unstructured datasets.
The generator, in turn, synthesizes the retrieved data into coherent, contextually relevant outputs.
A critical yet underexplored factor is the alignment between retrieval and generation.
Misaligned systems risk introducing inconsistencies or hallucinations.
Future strategies should prioritize iterative feedback loops, where retrieval outputs are dynamically refined based on generative performance, ensuring a cohesive and reliable pipeline.
The Role of Large Language Models in RAG
Large Language Models (LLMs) are the core of Retrieval-Augmented Generation (RAG), turning retrieved data into clear, relevant responses.
Their effectiveness depends on how well they integrate with retrieval systems to ensure accuracy and coherence.
New trends suggest that modular architectures improve RAG performance by separating retrieval and generation into distinct layers. This structure reduces hallucinations and increases factual accuracy.
Systems that refine LLM outputs using iterative training and user feedback also show better results.
Looking ahead, real-time retriever-generator alignment and adaptive learning will make RAG more efficient. Organizations should focus on hybrid models that balance retrieval accuracy with generative flexibility, ensuring reliable and scalable AI applications.
Data Preparation and Indexing Techniques
Adequate data preparation and indexing are foundational to optimizing Retrieval-Augmented Generation (RAG) systems.
Properly structured data ensures that retrievers can access relevant information with precision, minimizing noise and redundancy.
A compelling example is OpenAI’s use of chunking techniques, which divide large documents into smaller, semantically coherent units.
A common misconception is that raw data can be directly utilized in RAG pipelines. In reality, preprocessing steps like deduplication, normalization, and metadata tagging are critical.
For instance, metadata tagging allows retrievers to prioritize contextually significant information, similar to a librarian categorizing books to facilitate discovery.
To advance RAG performance, organizations should adopt iterative indexing strategies, incorporating user feedback to refine data structures dynamically. This ensures adaptability to evolving queries and enhances long-term system reliability.
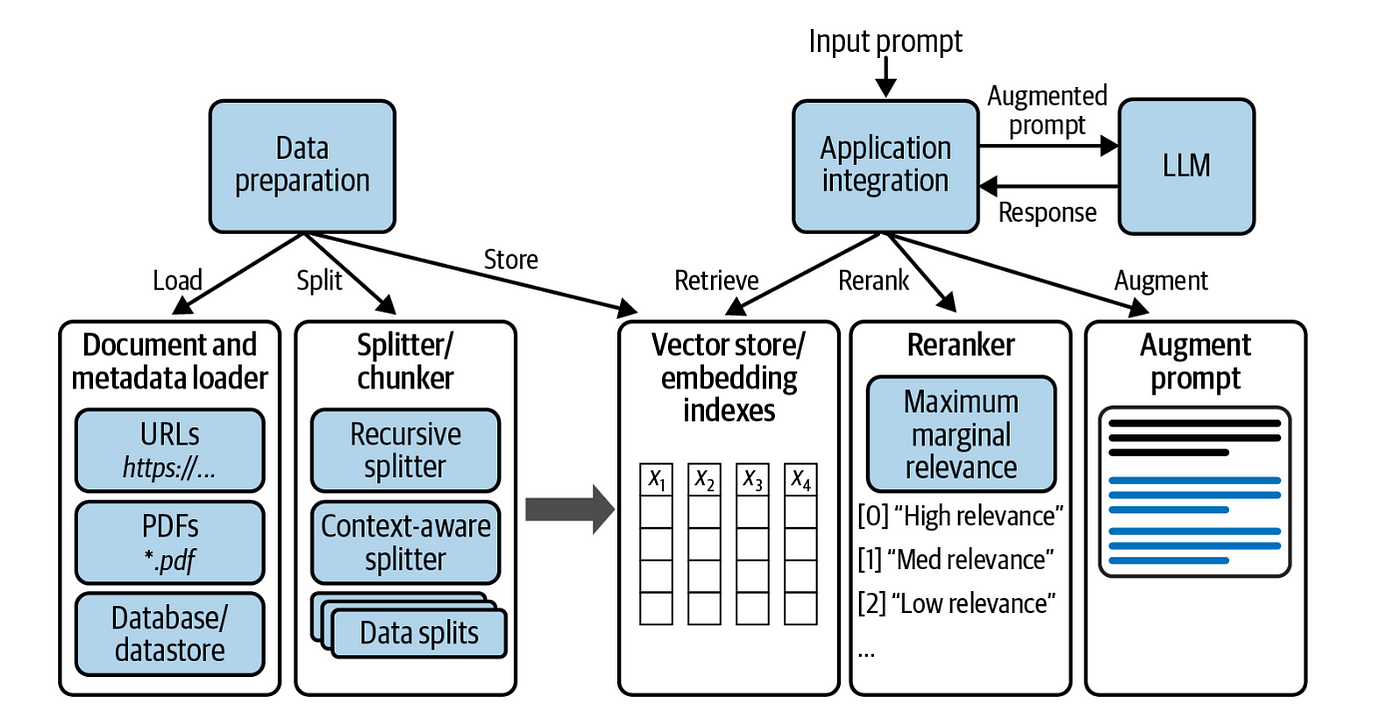
Effective Data Preprocessing for RAG
Data preprocessing is key to making RAG systems accurate and efficient. Clean, structured data improves retrieval and ensures relevant responses.
One essential technique is data normalization, which standardizes formats across different sources.
For example, companies using RAG to process customer support tickets can improve search accuracy by ensuring that variations in date formats, text structures, and metadata are consistent across records.
Another crucial step is artifact removal, which eliminates unnecessary elements like headers, watermarks, and special symbols that can interfere with retrieval.
In legal document processing, removing irrelevant formatting details helped a law firm improve contract clause retrieval, making case preparation faster.
Semantic deduplication further refines RAG systems by identifying and merging redundant data. In financial research, ensuring that multiple copies of the same regulatory updates weren’t indexed separately reduced retrieval noise and made responses more precise.
Preprocessing isn’t static—systems must evolve with user needs. Organizations are now integrating feedback loops to refine how data is chunked and tagged, ensuring that retrieval remains relevant as data grows.
Indexing Strategies for Efficient Retrieval
Efficient indexing is the cornerstone of high-performing Retrieval-Augmented Generation (RAG) systems, enabling rapid and accurate access to relevant data.
A particularly effective strategy is hybrid indexing, which combines sparse retrieval (e.g., inverted indexes) with dense vector embeddings.
This approach leverages the precision of keyword matching while capturing semantic relationships, as demonstrated by Pinecone RAG.
Dynamic indexing is another emerging technique that allows systems to incorporate incremental updates without full re-indexing. This adaptability is critical for applications requiring up-to-date information, such as financial forecasting or medical diagnostics.
A lesser-explored yet impactful method is metadata-driven indexing, in which additional contextual tags (e.g., timestamps, and authorship) enhance retrieval relevance.
Advanced Retrieval and Augmentation Strategies
RAG systems are evolving beyond simple document retrieval, incorporating advanced techniques to improve the quality and relevance of retrieved data before it reaches the language model.
The goal is not just to fetch information but to ensure it enhances generative accuracy reduces redundancy, and adapts to different query types.
One challenge in retrieval-augmented generation is maintaining a balance between precision and breadth.
Retrieving too little information can leave gaps in responses while retrieving too much can introduce noise. Strategies like iterative refinement, metadata enrichment, and query decomposition help refine retrieval results to ensure they align closely with user intent.
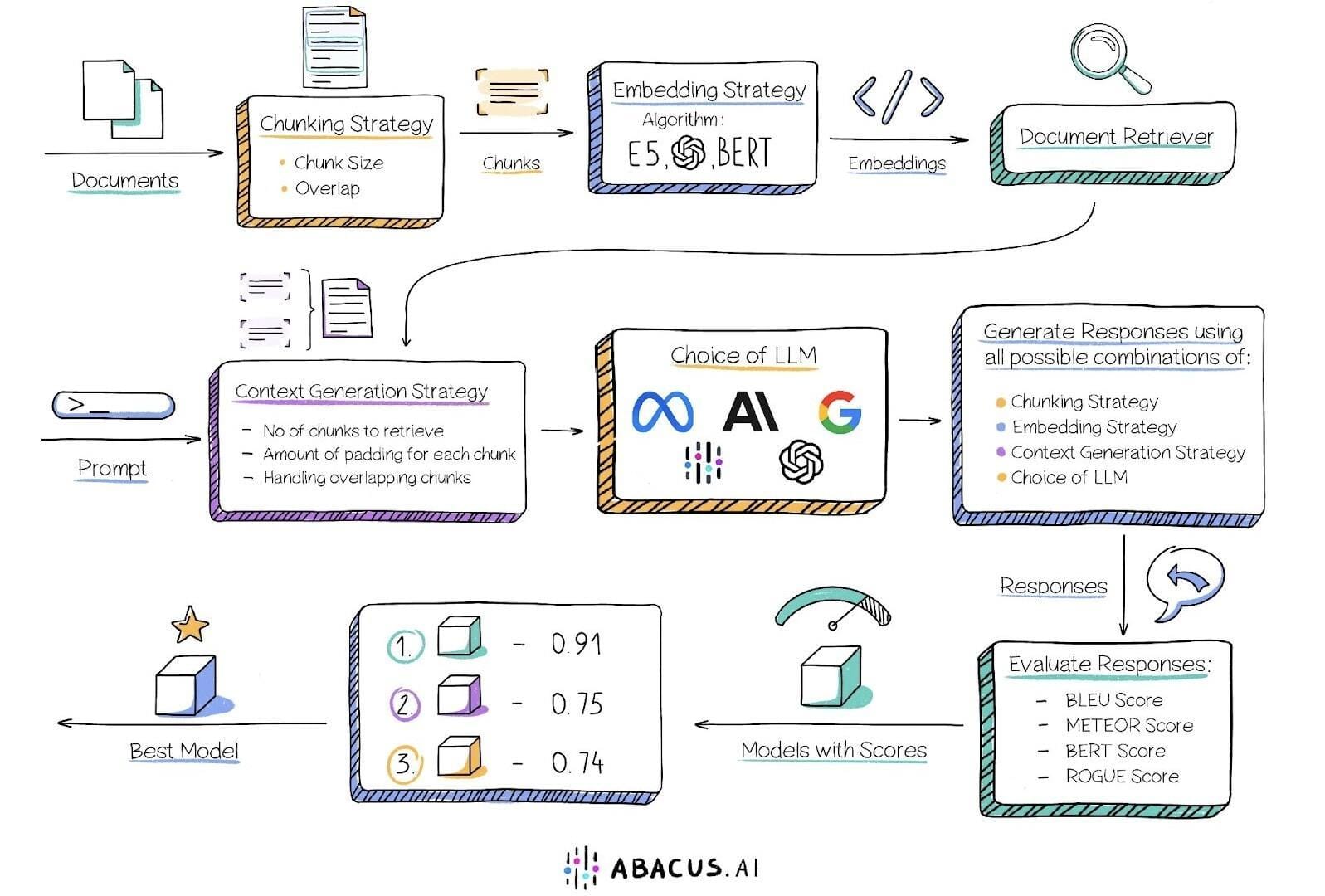
Hybrid Retrieval Methods
Hybrid retrieval methods, which combine sparse and dense retrieval techniques, have emerged as a cornerstone for optimizing RAG systems.
These methods address the limitations of standalone approaches by leveraging the precision of keyword-based searches and the semantic depth of vector embeddings.
A critical advantage of hybrid retrieval is its adaptability to diverse query types. Sparse retrieval excels at handling exact matches, while dense embeddings capture nuanced semantic relationships. This dual capability is particularly effective in domains like legal research, where precise terminology and contextual understanding are essential.
Emerging trends suggest that dynamic hybridization, where retrieval strategies adapt based on query complexity, will further enhance performance.
For instance, a system could prioritize dense embeddings for ambiguous queries while defaulting to sparse methods for well-defined terms. This adaptability ensures optimal resource allocation and retrieval relevance.
Query Expansion and Multi-step Reasoning
Query expansion and multi-step reasoning are pivotal in addressing complex queries within RAG systems, enabling nuanced understanding and precise responses.
Query expansion enriches the original input by generating semantically related sub-queries, ensuring comprehensive retrieval.
A novel metric, Query Expansion Coverage (QEC), can quantify the breadth of semantic relationships captured during expansion. Higher QEC scores correlate with improved retrieval relevance, offering a standardized evaluation framework for RAG systems.
Emerging trends emphasize contextual query decomposition, where user intent guides the segmentation of queries into hierarchical layers. This approach, combined with adaptive feedback loops, ensures iterative refinement and alignment with user needs.
Looking ahead, integrating probabilistic reasoning models with query expansion will enhance the system’s ability to manage uncertainty, paving the way for more robust applications in domains like legal research, scientific discovery, and personalized education.
Integrating and Fine-Tuning Large Language Models
Integrating and fine-tuning Large Language Models (LLMs) within RAG systems demands a balance between domain-specific precision and generative flexibility.
A common misconception is that fine-tuning always enhances performance. In reality, overfitting to narrow datasets can degrade generalization. OpenAI mitigated this by employing instruction fine-tuning, which improved adherence to user prompts across diverse contexts.
Unexpectedly, modular architectures have emerged as a solution to mitigate hallucinations. By decoupling retrieval grounding from generative adaptation, systems like Pinecone RAG reduced factual inconsistencies by a considerable margin.
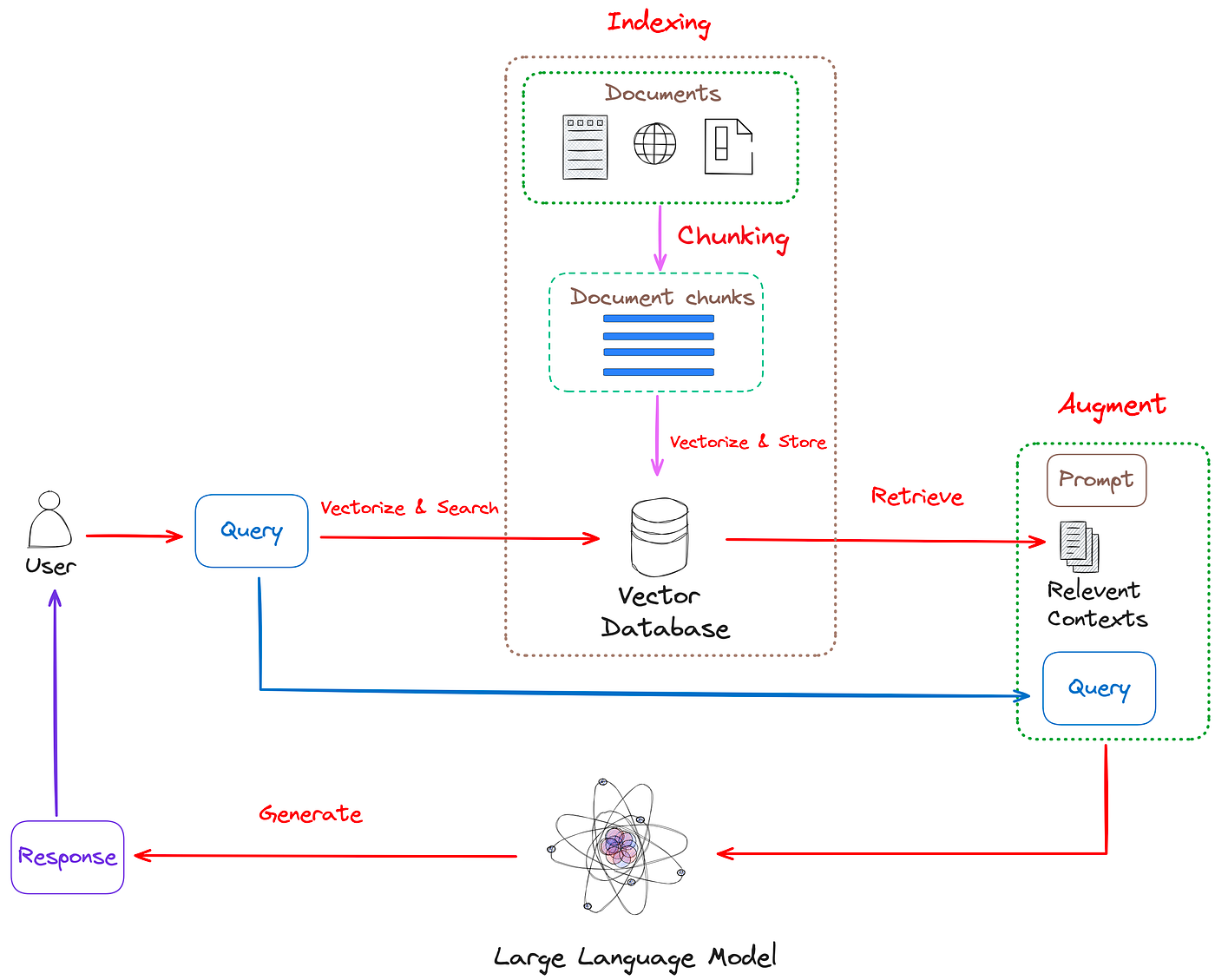
Fine-Tuning Techniques for Enhanced Performance
One critical fine-tuning technique for RAG systems is retrieval-aware fine-tuning, which aligns the generative model with the retriever’s outputs.
This approach ensures that the language model generates responses grounded in retrieved data, minimizing hallucinations.
Another impactful method is contrastive fine-tuning, where models are trained to distinguish between relevant and irrelevant retrievals.
Emerging trends suggest the adoption of modular fine-tuning pipelines, where distinct layers of the model are fine-tuned independently. This approach mitigates overfitting and enhances adaptability across domains.
Looking ahead, organizations should explore adaptive fine-tuning frameworks that incorporate real-time user feedback. By dynamically adjusting to evolving data landscapes, these systems can maintain relevance and scalability, ensuring robust performance in diverse applications.
FAQ
What are the core components of Retrieval-Augmented Generation (RAG)?
RAG consists of a retriever, knowledge base, and generator. The retriever identifies relevant data, the knowledge base stores structured and unstructured information, and the generator synthesizes coherent responses. Optimizing retrieval and generation alignment improves accuracy, reduces hallucinations, and enhances RAG’s effectiveness in applications like finance and healthcare.
How does RAG improve content generation and fact-checking?
RAG ensures accuracy by retrieving real-time data before generating content. Metadata enrichment and contextual augmentation further improve factual consistency in areas like journalism, legal analysis, and healthcare.
What are the best practices for data preparation and indexing in RAG?
Adequate data preparation involves chunking, metadata tagging, and hierarchical indexing. Chunking breaks documents into semantically relevant units, improving retrieval precision. Metadata adds contextual layers, while hierarchical indexing organizes data for faster searches. Iterative indexing strategies ensure adaptability to evolving queries, boosting retrieval efficiency.
How can organizations fine-tune Large Language Models (LLMs) for RAG?
LLMs in RAG require retrieval-aware fine-tuning to align generative outputs with retrieved data. Modular architectures separate retrieval grounding from generation, reducing inconsistencies. Techniques like contrastive learning refine relevance ranking. Real-time feedback loops improve adaptability, making LLMs more reliable in financial, legal, and medical applications.
What metrics are used to evaluate RAG system performance?
RAG performance is measured using retrieval precision metrics like Hit Rate and MRR, as well as generative quality scores such as BLEU and ROUGE. Contextual Relevance Index (CRI) evaluates the alignment between retrieved data and user intent. Latency-aware metrics ensure fast response times, which is critical for applications like customer support and financial analysis.
Conclusion
Retrieval-Augmented Generation (RAG) is reshaping AI by integrating real-time information retrieval with advanced language models.
Organizations using RAG benefit from improved accuracy, reduced misinformation, and scalable knowledge retrieval.
Optimizing retrievers, indexing methods, and fine-tuning LLMs ensures high performance across industries like finance, healthcare, and enterprise knowledge management.
As RAG evolves, adaptive retrieval techniques and feedback-driven refinements will be key to maintaining relevance and precision in increasingly complex data environments.