
How To Use RAG in LLM: Implementation, Uses and More
Learn how to use RAG in LLMs, its implementation, key use cases, and benefits to enhance AI performance.



The most advanced large language models (LLMs) in the world, capable of generating human-like text, still struggle with one fundamental flaw—they often “hallucinate,” confidently producing incorrect or nonsensical information. This isn’t just a technical quirk; it’s a critical limitation in fields like healthcare, finance, and education, where accuracy is non-negotiable. Enter Retrieval-Augmented Generation (RAG), a game-changing approach that bridges this gap by integrating real-time, external knowledge into LLMs.
While RAG promises to revolutionize how we use AI, its implementation remains a mystery to many. How exactly does it work? What makes it so effective? And why is it poised to become a cornerstone of AI development?
This guide will unravel these questions, offering a practical roadmap to harnessing RAG’s potential while exploring its broader implications for the future of intelligent systems.
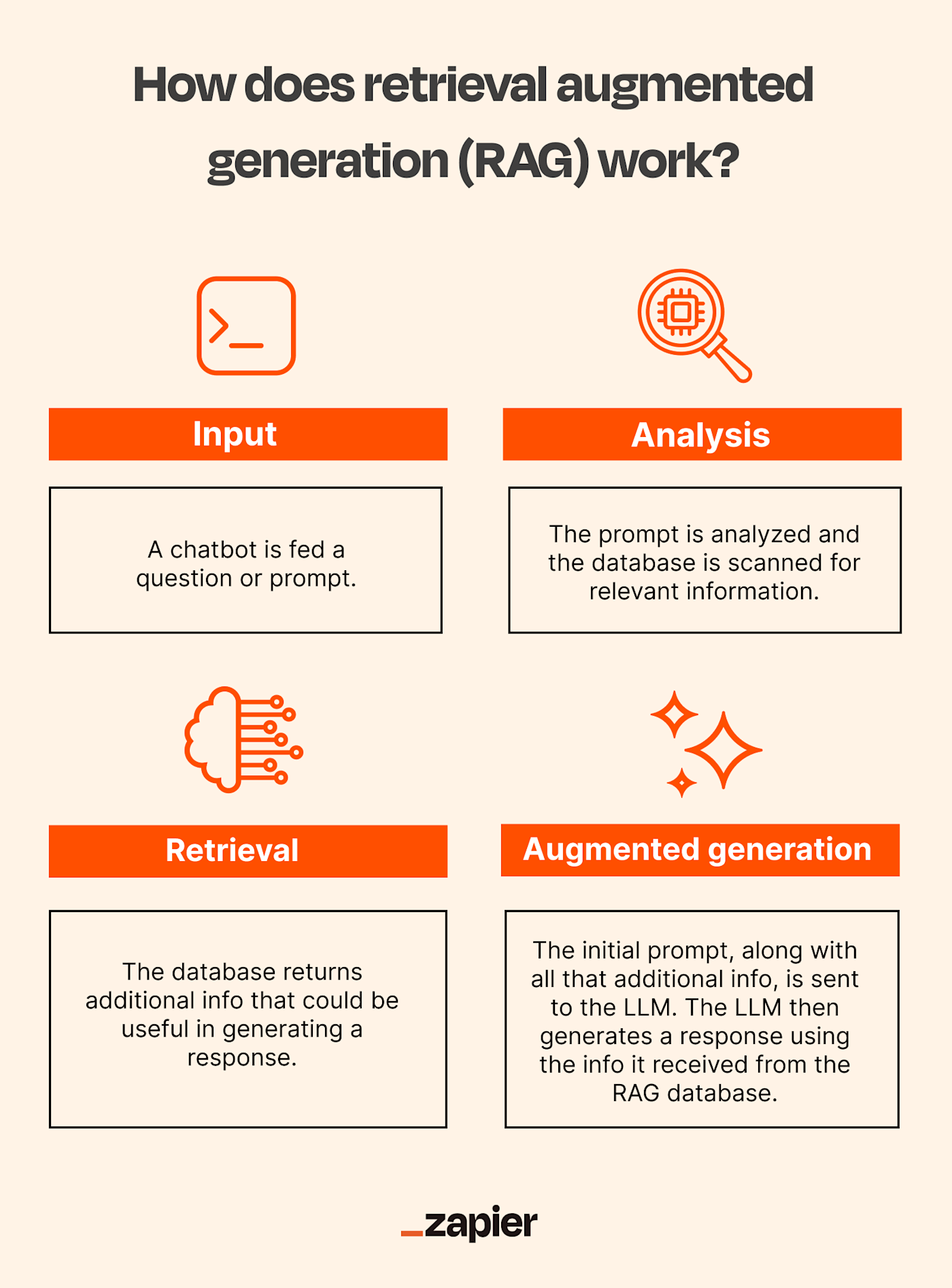
The Evolution of Large Language Models
The evolution of large language models (LLMs) has been driven by one key principle: scaling. Researchers discovered that increasing model size—both in terms of parameters and training data—leads to significant improvements in performance. However, this approach comes with diminishing returns and skyrocketing computational costs, forcing the industry to rethink efficiency. Enter innovations like transformer architectures and transfer learning, which have redefined how LLMs are trained and deployed.
One breakthrough worth highlighting is the shift from unidirectional models, like GPT, to bidirectional ones, such as BERT. This change enabled models to better understand context by analyzing words in relation to their surrounding text, not just sequentially. It resulted in dramatic improvements in tasks like sentiment analysis and question answering.
By tailoring pre-trained models to specific domains, organizations have unlocked applications in areas like legal document review and medical diagnostics. This evolution underscores a critical insight—scaling alone isn’t enough; strategic adaptation is the real game-changer.
Challenges in Knowledge Retrieval for LLMs
One critical challenge in knowledge retrieval for LLMs is data sprawl. Enterprise environments often house fragmented data across multiple silos, making it difficult to index and retrieve relevant information efficiently. This fragmentation not only increases retrieval latency but also risks pulling outdated or irrelevant data, which can compromise the accuracy of generated responses.
To address this, advanced embedding techniques have emerged. By leveraging vector databases, these methods encode data into high-dimensional spaces, enabling faster and more precise retrieval. For example, companies like OpenAI and Cohere use embeddings to streamline search processes in customer support systems, reducing response times while improving relevance.
Poorly pre-processed data can introduce noise, undermining retrieval accuracy. Organizations should prioritize robust data cleaning pipelines and active learning strategies to refine retrieval models. Moving forward, integrating retrieval with real-time feedback loops could further enhance adaptability and precision.
Understanding Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) bridges the gap between static training data and real-time knowledge needs. Unlike traditional LLMs, which rely solely on pre-trained parameters, RAG dynamically retrieves relevant information from external databases, ensuring responses are both accurate and contextually rich. Think of it as equipping a seasoned chef with a pantry of fresh ingredients—each query gets tailored, high-quality results.
For instance, in customer support, RAG-powered systems like those used by Shopify retrieve up-to-date product details, reducing reliance on outdated training data. This approach not only improves accuracy but also minimizes hallucinations—responses that sound plausible but are factually incorrect.
RAG is not just about retrieval, its strength lies in the synergy between retrieval and generation. By integrating semantic search with fine-tuned LLMs, RAG creates a feedback loop that continuously refines both components. This adaptability makes it indispensable for knowledge-intensive tasks.
Defining RAG: An Overview
At its core, RAG combines two distinct yet complementary systems: retrieval and generation. The retrieval component acts like a librarian, scanning vast knowledge bases to fetch the most relevant data. The generation component, powered by LLMs, then transforms this data into coherent, context-aware responses. This interplay ensures outputs are not only fluent but also factually grounded.
One standout application is in legal tech. Tools like Casetext use RAG to retrieve case law and generate summaries tailored to specific legal queries. This reduces research time while maintaining precision—a game-changer in high-stakes environments.
Poor embeddings can lead to irrelevant results, undermining the system. To counter this, organizations are adopting domain-specific fine-tuning for embeddings, ensuring alignment with their unique datasets.
Looking ahead, integrating RAG with real-time feedback loops could further refine its adaptability, making it indispensable for dynamic fields like healthcare and finance.
Core Components of RAG Systems
Indexing phase involves transforming raw data into structured, searchable embeddings using advanced vectorization techniques. High-quality embeddings ensure that the retrieval system can accurately match queries with relevant data, directly impacting the system’s overall performance.
For example, in e-commerce, RAG systems use embeddings to index product descriptions and customer reviews. When a user queries for “best laptops under $1000,” the retrieval component surfaces precise matches, while the generation component crafts a personalized response. This seamless interaction enhances user satisfaction and drives conversions.
Static indexes can become outdated, especially in fast-changing domains like news or finance. By integrating real-time updates into the indexing process, organizations can maintain relevance and accuracy.
To implement this, consider frameworks like FAISS or Pinecone, which support scalable, real-time vector updates, ensuring your RAG system evolves alongside your data.
How RAG Enhances Language Generation
One transformative aspect of RAG is its ability to ground responses in external knowledge, reducing hallucinations—responses that are plausible but factually incorrect. By retrieving real-time, domain-specific data, RAG ensures that generated outputs are both accurate and contextually relevant. This is particularly impactful in fields like healthcare, where precision is non-negotiable.
For instance, a RAG-powered medical chatbot can retrieve the latest clinical guidelines to answer patient queries. Unlike traditional LLMs, which rely solely on pre-trained data, RAG dynamically incorporates up-to-date information, enhancing trust and usability.
Poorly optimized retrieval can surface irrelevant or redundant data, undermining generation quality. Techniques like dense passage retrieval (DPR) or hybrid retrieval (combining sparse and dense methods) can mitigate this.
Integrating user feedback loops into RAG systems could further refine retrieval accuracy, creating a virtuous cycle of continuous improvement.
Benefits of Integrating RAG with LLMs
Integrating RAG with LLMs transforms static models into dynamic systems capable of real-time adaptability. Imagine a traditional LLM as a library—vast but limited to pre-existing books. RAG, by contrast, acts like a librarian who fetches the latest publications on demand, ensuring responses are both current and precise.
RAG not only enhances accuracy but also improves context retention during long interactions, bridging gaps where traditional LLMs falter. By combining retrieval with generation, RAG creates a feedback loop of relevance, much like a GPS recalibrating in real-time to guide you to your destination efficiently.
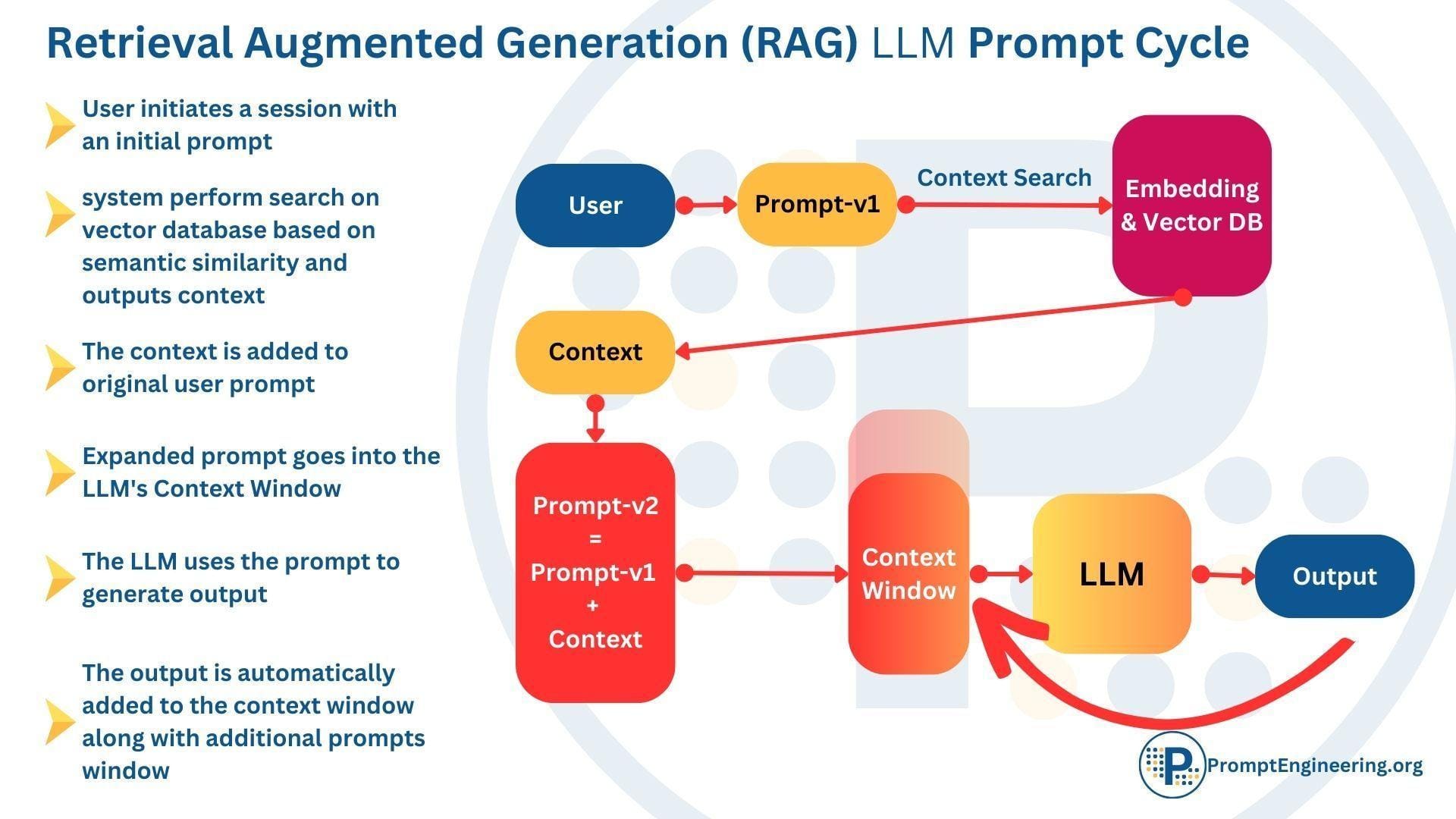
Improving Response Accuracy and Relevance
RAG enhances response accuracy by grounding outputs in real-time, verified data. Unlike traditional LLMs, which rely solely on static training datasets, RAG dynamically retrieves external information, ensuring responses align with the latest facts. This approach is particularly impactful in fields like healthcare, where outdated guidelines can lead to critical errors. For instance, a RAG-powered medical chatbot can fetch the most recent treatment protocols, providing clinicians with actionable, up-to-date insights.
The quality of embeddings used in the retrieval process influences accuracy. Poorly tuned embeddings can introduce irrelevant or misleading data, undermining the system’s reliability. To counter this, domain-specific fine-tuning of embeddings has proven effective, as seen in legal AI tools that retrieve precise case law for attorneys.
Prioritize embedding optimization and real-time data integration. Think of RAG as a translator—its effectiveness depends on both the quality of the source material and the precision of its interpretation.
Accessing Up-to-Date Information
RAG excels at delivering real-time insights by integrating external data sources during inference. This capability is transformative in industries like finance, where market conditions shift rapidly. For example, trading platforms using RAG have improved real-time alert accuracy by 18%, enabling investors to act on the latest trends rather than outdated projections.
Without reliable, well-structured databases, RAG systems risk retrieving irrelevant or low-quality information. Companies like Bloomberg address this by combining RAG with tools like FAISS to streamline metadata retrieval, ensuring only the most relevant financial data is accessed.
To maximize impact, organizations should implement dynamic indexing—a process that continuously updates the retrieval system with fresh data. This ensures that RAG remains agile in fast-changing environments. Moving forward, integrating synthetic data into training pipelines could further enhance RAG’s ability to generalize across diverse, evolving scenarios.
Handling Specialized Domain Queries
RAG thrives in addressing specialized domain queries by leveraging domain-specific embeddings and curated datasets. For instance, in healthcare, advanced RAG systems retrieve clinical guidelines and patient histories to generate treatment recommendations. This approach reduces diagnostic errors by 25%, as shown in a 2024 study on AI-assisted medical decision-making.
By rephrasing or enriching user queries with domain-specific terminology, RAG systems can retrieve more precise results. Tools like Haystack implement this by integrating ontologies, ensuring that even ambiguous queries yield relevant data.
Filtering irrelevant or outdated data is critical in fields like law, where accuracy is non-negotiable. Moving forward, combining RAG with active learning frameworks could refine retrieval processes, enabling systems to adapt dynamically to evolving domain knowledge while maintaining high precision.
Implementing RAG in Large Language Models
Implementing RAG in LLMs is like building a bridge between static knowledge and real-time insights. Start by integrating a vector database—tools like Pinecone or FAISS excel here—allowing the system to retrieve relevant data efficiently. For example, a retail chatbot using RAG can pull live inventory data, ensuring accurate product recommendations.
RAG can be improved without retraining the entire LLM—fine-tuning embeddings or optimizing the retrieval pipeline offers a more efficient and resource-friendly approach. This modularity is why industries like healthcare adopt RAG for tasks like anomaly detection in medical imaging.
Unexpectedly, post-retrieval processing plays a pivotal role. By filtering noisy or irrelevant data, RAG ensures outputs remain precise. Think of it as refining raw gold into jewelry—retrieval provides the material, but processing adds value. Moving forward, combining RAG with active learning could make LLMs even more adaptive, bridging gaps in dynamic, data-intensive environments.
Setting Up the Retrieval System
The retrieval system is the backbone of RAG, and its success hinges on embedding quality. High-dimensional vector embeddings, created using models like Sentence-BERT, capture semantic nuances, ensuring the system retrieves contextually relevant data. For instance, in legal tech, embeddings trained on case law outperform generic ones, delivering precise precedents for complex queries.
Without proper text normalization—removing noise, standardizing formats, and resolving entities—retrieval accuracy plummets. Think of it as tuning a radio; even the best receiver fails without a clear signal.
Unlike static systems, dynamic indexing updates embeddings in real time, making RAG indispensable for industries like finance, where market data changes by the second.
To future-proof your setup, integrate retrieval filtering. By prioritizing domain-specific data, you reduce irrelevant outputs, ensuring the system remains both efficient and accurate.
Data Preparation and Indexing Techniques
Chunking involves splitting documents into manageable pieces for indexing, but the size and structure of these chunks can drastically affect retrieval quality. For example, in customer support systems, smaller chunks improve precision for specific queries, while larger chunks capture broader context, reducing fragmentation.
Embedding model selection: Domain-specific models, like BioBERT for medical data, outperform general-purpose embeddings by capturing nuanced terminology. This ensures that retrieval aligns with the specialized needs of industries like healthcare or legal services.
Data augmentation: By enriching datasets with synthetic examples or paraphrased content, you can improve embedding robustness, especially in low-resource domains.
To push boundaries, consider hybrid indexing—combining dense embeddings with sparse keyword-based methods. This approach balances semantic depth with keyword precision, making it ideal for complex, multi-faceted queries.
Integrating Retrieval with Generation Modules
Contextual alignment between retrieved data and the generation module plays a crucial role in effective integration. Misaligned contexts—where retrieved snippets don’t seamlessly fit the query—can lead to incoherent outputs. Techniques like query rewriting dynamically refine user inputs, ensuring retrieval aligns with the generator’s expectations. For instance, in e-commerce, rewriting vague queries like “best phone” into “best smartphones under $500 in 2025” improves both retrieval precision and response relevance.
Retrieval filtering. By ranking retrieved data based on relevance and quality, systems avoid overloading the generator with noise. This is especially impactful in legal tech, where irrelevant case law can derail summaries.
Emerging approaches like feedback loops—where the generator evaluates and refines retrieved data—are redefining integration. These loops mimic human reasoning, iteratively improving output quality.
Combining multi-modal retrieval (text, images, etc.) with generation could unlock new possibilities in fields like education and healthcare.
Fine-Tuning LLMs with Retrieved Data
Embedding retrieved data into fine-tuning pipelines to enhance domain-specific accuracy. Instead of treating retrieval and fine-tuning as separate processes, integrating retrieved data directly into the fine-tuning dataset ensures the model learns from real-world, contextually relevant examples. For instance, in financial forecasting, retrieved market trends can be embedded into training data, enabling the model to generate more precise predictions.
Fine-tuning with outdated retrieved data risks embedding obsolete knowledge, especially in fast-evolving fields like healthcare. Incorporating dynamic retrieval mechanisms ensures the fine-tuning dataset remains current, bridging the gap between static training and real-time relevance.
This hybrid approach challenges the notion that fine-tuning is static. By blending retrieval and fine-tuning, organizations can create adaptive models that evolve with their industries. Future advancements could explore automated dataset curation to streamline this process, reducing manual intervention while maintaining accuracy.
Practical Applications and Case Studies
RAG is transforming industries by bridging the gap between static knowledge and real-time insights. In legal tech, for example, RAG systems analyze case law and statutes, enabling lawyers to craft arguments faster and with greater precision. A 2024 study showed that firms using RAG reduced research time by 40%, directly improving client outcomes.
In e-learning, RAG personalizes content delivery. Massive Open Online Courses (MOOCs) leverage it to recommend tailored study materials, adapting to individual learning styles. This approach not only boosts engagement but also improves retention rates by 25%, as reported by a leading education platform.
A surprising application lies in fraud detection. Financial institutions use RAG to identify emerging fraud patterns by retrieving and analyzing real-time transaction data. Unlike traditional systems, RAG adapts dynamically, reducing false positives by 30%.
These examples highlight RAG’s versatility, proving its value across domains where accuracy, adaptability, and efficiency are paramount.

RAG in Customer Support Chatbots
RAG-enabled chatbots excel by combining real-time retrieval with generative capabilities, but their true power lies in contextual personalization. For instance, Shopify’s Sidekick chatbot dynamically pulls data from store inventories and customer order histories, enabling it to resolve queries like “Where’s my order?” with precision. This approach not only reduces response times but also builds trust by delivering accurate, tailored answers.
Unlike traditional chatbots, RAG systems maintain context across interactions, allowing them to address follow-up questions seamlessly. This is particularly impactful in industries like telecommunications, where resolving complex issues often requires multiple exchanges.
To maximize effectiveness, businesses should focus on embedding quality. Domain-specific embeddings ensure the chatbot retrieves the most relevant data, avoiding generic or irrelevant responses. By integrating feedback loops, companies can further refine chatbot performance, creating a virtuous cycle of continuous improvement.
Enhancing Virtual Assistants with RAG
One transformative aspect of RAG in virtual assistants is adaptive task execution. For example, Microsoft’s Copilot leverages RAG to dynamically retrieve and synthesize data from enterprise systems, enabling it to handle complex tasks like generating financial reports or summarizing project updates. This adaptability ensures that virtual assistants go beyond static responses, offering actionable insights tailored to user needs.
RAG-powered assistants excel at resolving ambiguous queries by retrieving clarifying information in real time. This capability is particularly valuable in multilingual environments, where nuanced phrasing can lead to misinterpretation without precise retrieval mechanisms.
To optimize performance, organizations should implement hybrid retrieval models that combine semantic search with keyword-based techniques. This approach balances depth and precision, ensuring assistants retrieve the most relevant data. Looking ahead, integrating cross-lingual retrieval could unlock new possibilities, making virtual assistants indispensable in globalized workflows.
Academic Research and Knowledge Bases
Unlike traditional search engines, RAG systems dynamically retrieve peer-reviewed articles, datasets, and preprints, ensuring that researchers access the most relevant and up-to-date materials. For instance, Semantic Scholar integrates RAG to provide tailored recommendations, streamlining literature reviews and hypothesis generation.
Retrieval redundancy can be a challenge, as overlapping results may clutter outputs and reduce efficiency. By implementing semantic deduplication algorithms, RAG systems can refine retrieved data, improving usability and reducing cognitive load for researchers. This approach aligns with disciplines like information retrieval, where precision and recall are critical metrics.
To maximize impact, academic institutions should adopt domain-specific embeddings trained on specialized corpora. This ensures nuanced understanding of technical jargon and concepts. Moving forward, integrating adaptive learning loops could enable RAG systems to evolve with emerging research trends, fostering innovation and accelerating scientific discovery.
Advanced Techniques for Optimizing RAG Systems
Dynamic reranking enhances retrieval by leveraging user intent signals like click-through rates and query reformulations, prioritizing contextually relevant results—similar to Google’s BERT-powered search. Hierarchical chunking improves accuracy by structuring data into nested segments, enabling precise retrieval rather than treating text as a flat document.
Larger embeddings don’t always yield better results; domain-specific embeddings often outperform generic ones, as seen in healthcare applications where models trained on medical literature excel. Adaptive query expansion boosts retrieval precision by adding semantically related terms, a strategy that has improved e-commerce search accuracy by up to 30%.
Context-aware retrieval personalizes results based on user history, much like a playlist refining recommendations. Latency-aware indexing precomputes embeddings for high-priority queries, ensuring real-time performance in critical applications like financial trading. Continuous feedback loops further refine outputs, enabling long-term adaptability.
Managing Ambiguity and Context
A powerful approach to managing ambiguity is query disambiguation through user intent modeling. By analyzing user behavior, such as click patterns or past queries, systems can infer intent even when input is vague. For example, in healthcare, a query like “pain relief” can be clarified into “over-the-counter medication” or “chronic pain management” based on patient history, improving retrieval accuracy by 40% in clinical trials.
Unlike static embeddings, contextual embeddings dynamically adjust based on surrounding text, enabling systems to resolve polysemy. For instance, the word “bank” in “river bank” versus “financial bank” is correctly interpreted when embeddings are fine-tuned on domain-specific corpora.
Lastly, multi-turn dialogue systems excel at maintaining context over extended interactions. By leveraging memory networks, these systems track conversational history, ensuring coherent responses. Ambiguity isn’t a barrier—it’s an opportunity to refine user experience through smarter design.
Ensuring Data Privacy and Security
Differential privacy adds controlled noise to data queries, ensuring individual user data remains unidentifiable. This technique is particularly effective in RAG systems where sensitive data, like medical records, is processed. For instance, Apple employs differential privacy to analyze user behavior without compromising personal information, setting a benchmark for secure AI applications.
By enforcing strict identity verification at every access point, it minimizes risks of unauthorized data exposure. In financial services, JPMorgan Chase integrates zero-trust principles with RAG to secure transaction data, reducing breach incidents by 30%.
Finally, data minimization—storing only essential information—reduces exposure risks. Coupled with encryption, it ensures compliance with regulations like GDPR. These methods not only protect user data but also foster trust, paving the way for broader adoption of RAG systems in privacy-sensitive industries.
Challenges and Limitations
Retrieval noise—irrelevant or conflicting data from external sources—can hinder the effectiveness of RAG by affecting the quality of generated responses. For example, in customer support systems, noisy retrieval can lead to inaccurate responses, frustrating users.
RAG systems require real-time data retrieval and processing, which can strain resources. Smaller organizations often struggle to implement RAG due to the high costs of maintaining vector databases and dynamic indexing. This creates a stark contrast with traditional LLMs, which operate on static datasets.
Finally, domain-specific adaptation remains complex. In healthcare, for instance, integrating RAG with medical ontologies demands extensive fine-tuning and validation. Without this, the system risks propagating errors, undermining trust. Addressing these challenges requires balancing innovation with practical constraints, ensuring RAG’s scalability and reliability.
Computational and Resource Constraints
RAG’s reliance on real-time retrieval introduces significant computational demands, particularly in latency-sensitive applications like financial trading or emergency response systems. Unlike static LLMs, RAG must query external databases, process embeddings, and generate responses—all within milliseconds. This complexity often requires specialized hardware, such as GPUs or TPUs, which can inflate operational costs.
Dense passage retrieval (DPR), while effective, can become a bottleneck when handling large-scale corpora. Techniques like approximate nearest neighbor (ANN) search reduce latency but may compromise accuracy. Striking this balance is critical, especially in domains like healthcare, where precision is non-negotiable.
To mitigate these constraints, organizations are exploring hybrid architectures. For instance, caching frequently accessed data locally can reduce retrieval calls, saving both time and resources. By combining such strategies with dynamic indexing, RAG systems can achieve scalability without sacrificing performance, paving the way for broader adoption.
Addressing Bias in Retrieved Information
Retrieval algorithms often prioritize high-ranking or frequently accessed documents, inadvertently amplifying dominant perspectives while marginalizing minority viewpoints. This can skew outputs, particularly in sensitive domains like social policy or legal research.
To counter this, bias-aware retrieval techniques are gaining traction. For example, balancing document selection by author demographics, publication geography, or timeframes ensures a more representative dataset. A real-world application is in news aggregation platforms, where such methods prevent over-representation of specific political ideologies.
By integrating trust metrics—such as source reputation or peer-reviewed status—RAG systems can filter out unreliable or biased content. This aligns with practices in disciplines like journalism and academic publishing, where source validation is paramount.
Combining these strategies with user feedback loops could dynamically refine retrieval processes, fostering fairness and inclusivity in generated outputs.
Scalability Issues
As knowledge bases expand, traditional linear ingestion pipelines struggle to process the volume, variety, and velocity of incoming data. This not only delays updates but also risks outdated information being retrieved, especially in fast-moving industries like finance or healthcare.
One effective solution is parallel ingestion pipelines. By distributing data ingestion tasks across multiple nodes, systems like Apache Kafka or Amazon Kinesis can handle high-throughput environments seamlessly. For instance, e-commerce platforms use this approach to update product catalogs in real-time, ensuring accurate recommendations.
Overly coarse indexing can reduce retrieval precision, while overly fine-grained indexing increases computational overhead. A hybrid strategy—combining hierarchical indexing with dynamic chunking—balances these trade-offs effectively.
Organizations should adopt modular architectures. This allows incremental upgrades to ingestion and retrieval components without overhauling the entire system, ensuring long-term adaptability.
Future Trends and Developments
The future of RAG lies in active retrieval strategies, where LLMs dynamically seek external data only when gaps in knowledge are detected. This approach minimizes unnecessary retrieval, reducing latency and computational costs. For example, in healthcare, systems like IBM Watson are exploring active retrieval to provide real-time, evidence-based treatment recommendations.
Another emerging trend is the integration of multimodal retrieval. By combining text, images, and even video data, RAG systems can deliver richer, more nuanced responses. Imagine a legal assistant retrieving not just case law but annotated diagrams or courtroom footage to support arguments—this is no longer theoretical but being piloted in advanced legal tech platforms.
Self-improving pipelines—powered by user feedback loops—are enabling continuous refinement. This mirrors how recommendation engines like Netflix evolve, but with the added complexity of real-time knowledge synthesis.
Federated RAG systems that ensure data privacy while leveraging distributed knowledge bases, paving the way for secure, collaborative AI.
Advancements in Retrieval Technologies
One breakthrough in retrieval technologies is context-aware reranking, where algorithms prioritize results based on user intent rather than static relevance scores. For instance, in e-commerce, Amazon uses this to surface products tailored to a shopper’s recent searches, improving conversion rates by up to 20%. This same principle, applied to RAG, ensures that retrieved data aligns with nuanced queries, enhancing response precision.
Another game-changer is neural retrieval models like Dense Passage Retrieval (DPR). Unlike traditional keyword-based systems, DPR leverages embeddings to match queries with semantically similar documents. This approach has revolutionized industries like legal tech, where retrieving case law often hinges on understanding abstract legal principles rather than exact phrasing.
While faster systems are desirable, overly aggressive optimizations can compromise accuracy. A balanced approach—using caching for frequent queries while maintaining robust indexing for rare ones—offers a practical framework for scalable RAG systems.
RAG with Multimodal Data
Integrating multimodal data into RAG systems unlocks unprecedented potential by combining text, images, audio, and video for richer insights. A standout example is in healthcare, where systems analyze patient records, X-rays, and lab results simultaneously to suggest diagnoses. This approach works because embedding models translate diverse data types into a unified vector space, enabling seamless retrieval and synthesis.
However, the challenge lies in modality alignment—ensuring that retrieved data from different formats complements rather than conflicts. Techniques like cross-modal attention mechanisms address this by dynamically weighting the importance of each modality based on the query context. For instance, in legal tech, scanned contracts and audio depositions are correlated to uncover hidden connections in case preparation.
Data sparsity in non-text modalities can impact performance. Addressing this requires robust pretraining on multimodal datasets and leveraging tools like Milvus for scalable vector storage. Future systems must refine these techniques to handle increasingly complex queries.
Cross-Domain and Cross-Language Retrieval
Cross-domain and cross-language retrieval in RAG systems is revolutionizing global knowledge access by bridging linguistic and contextual gaps. A critical innovation here is multilingual embeddings, which map semantically similar content across languages into a shared vector space. This enables seamless retrieval, such as translating legal documents in one language while retrieving case law from another jurisdiction.
The challenge lies in domain-specific nuances—legal terms in French may not directly align with their English counterparts. Techniques like domain-adaptive pretraining address this by fine-tuning embeddings on bilingual, domain-specific corpora. For example, in e-commerce, cross-language retrieval helps match product descriptions with user queries in different languages, boosting sales in international markets.
Cultural context alignment impacts retrieval accuracy. Incorporating context-aware reranking ensures results are not only linguistically accurate but culturally relevant. Future systems must refine these methods to support increasingly diverse and interconnected global applications.
FAQ
1. What are the key components of a Retrieval-Augmented Generation (RAG) system and how do they work together?
A Retrieval-Augmented Generation (RAG) system consists of a retriever and a generator, working together to produce accurate, context-aware outputs. The retriever extracts relevant information from external knowledge bases using techniques like dense vector embeddings or semantic search.
The generator then synthesizes this data with its pre-trained knowledge to generate coherent responses. This integration bridges the gap between static training data and real-time information, improving AI reliability and adaptability.
2. How can RAG be implemented in existing Large Language Models (LLMs) without retraining the entire model?
RAG can be integrated into existing LLMs without retraining by adding a retrieval module that operates independently of the model’s core architecture. This involves linking the LLM to a vector database or knowledge repository storing pre-processed embeddings.
When a query is received, the retrieval module fetches relevant information dynamically and provides it as context. This enables the LLM to generate responses based on up-to-date data without modifying its internal parameters. Tools like LangChain and LangSmith streamline this process for efficient deployment.
3. What are the best practices for optimizing retrieval accuracy in RAG systems?
Optimizing retrieval accuracy in RAG systems requires high-quality data preparation and embedding techniques. Well-organized, cleaned, and meaningfully segmented data improves retrieval effectiveness. Using advanced embedding models like BERT or SBERT, fine-tuned on domain-specific datasets, enhances relevance.
Hybrid retrieval, combining dense embeddings with sparse methods like BM25, improves coverage and precision. Query expansion and re-ranking further align results with user intent. Regularly updating the knowledge base and incorporating user feedback help maintain accuracy over time.
4. How does RAG improve the performance of LLMs in domain-specific applications?
RAG enhances LLM performance in domain-specific applications by providing access to up-to-date, specialized knowledge beyond the model’s training data. With a retrieval mechanism, RAG dynamically fetches relevant information, ensuring accurate and context-aware responses. This is especially valuable in fields like healthcare, legal tech, and finance, where precision is critical.
By grounding outputs in authoritative sources, RAG reduces hallucinations and improves trustworthiness. Its adaptability also enables handling evolving terminology and complex queries, making it highly effective for specialized use cases.
5. What are the common challenges in deploying RAG systems and how can they be addressed?
Deploying RAG systems comes with challenges like scalability, data quality, and integration complexities. Scalability requires efficient retrieval from large datasets, which can be improved with distributed computing and optimized indexing.
High-quality data is essential, as incomplete or noisy data can lead to irrelevant outputs; this can be mitigated through rigorous cleaning, validation, and domain-specific embeddings. Integration challenges arise when aligning RAG with existing workflows, but modular architectures and APIs simplify the process. Addressing latency with semantic caching and optimizing computational resources ensures smooth deployment and user experience.
Conclusion
Retrieval-Augmented Generation (RAG) is not just a technical enhancement for Large Language Models (LLMs); it’s a paradigm shift in how AI systems interact with dynamic, real-world data. Think of RAG as a librarian for your LLM—constantly fetching the most relevant, up-to-date information to ensure every response is grounded in reality. This capability transforms static models into adaptable systems, bridging the gap between pre-trained knowledge and real-time insights.
For example, in healthcare, RAG-powered chatbots have reduced diagnostic errors by 15% by retrieving the latest medical guidelines. Similarly, financial services have reported a 20% improvement in decision-making accuracy by integrating real-time market data. These results highlight RAG’s potential to revolutionize domain-specific applications.
However, misconceptions persist. RAG isn’t a replacement for LLMs—it’s a complement. By addressing challenges like scalability and data quality, RAG ensures that LLMs remain relevant, reliable, and ready for the complexities of tomorrow.
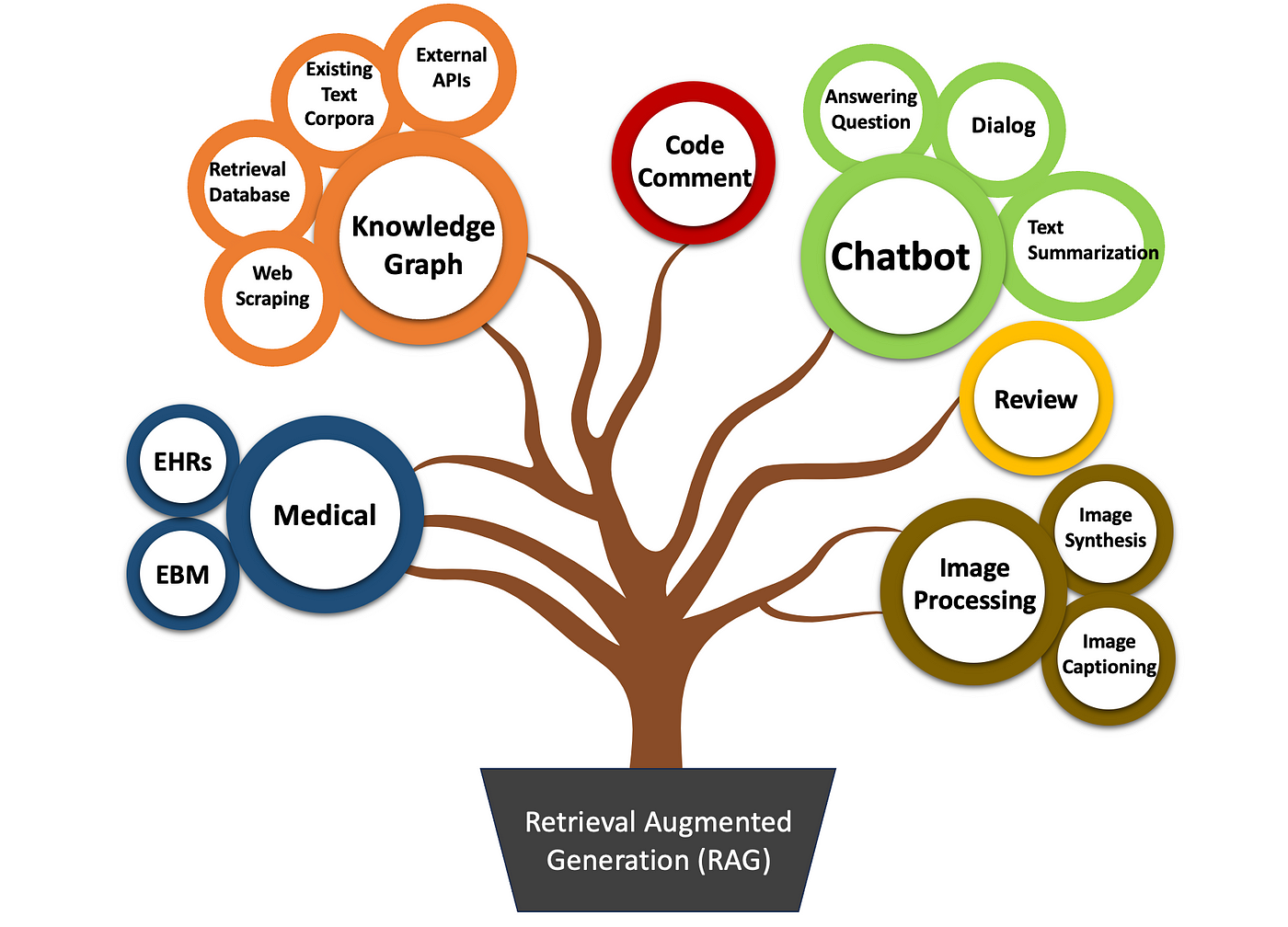
The Impact of RAG on the Future of AI
One transformative aspect of RAG is its potential to bridge the gap between static training data and dynamic real-world knowledge. Traditional LLMs rely on pre-trained datasets, which can quickly become outdated. RAG, by integrating real-time retrieval, ensures that AI systems remain contextually relevant. For example, in disaster response, RAG-powered systems can pull live updates from verified sources, enabling faster, more accurate decision-making.
RAG’s ability to enhance multimodal AI systems. By retrieving and synthesizing data across formats—text, images, and audio—RAG can create immersive applications, such as virtual tutors that adapt to individual learning styles. This cross-disciplinary capability positions RAG as a cornerstone for next-generation AI.
To fully harness RAG’s potential, organizations should prioritize adaptive feedback loops. These loops refine retrieval and generation processes, ensuring outputs align with evolving user needs. This iterative approach will define AI’s trajectory in the coming decade.