
Implementing Hybrid Retrieval (BM25 + FAISS) in RAG
Hybrid retrieval combines BM25 and FAISS to enhance RAG performance. This guide explores implementation strategies, benefits, and best practices to optimize search accuracy, improve retrieval efficiency, and ensure more relevant AI-generated responses.

Most retrieval systems fall short in one key area: precision.
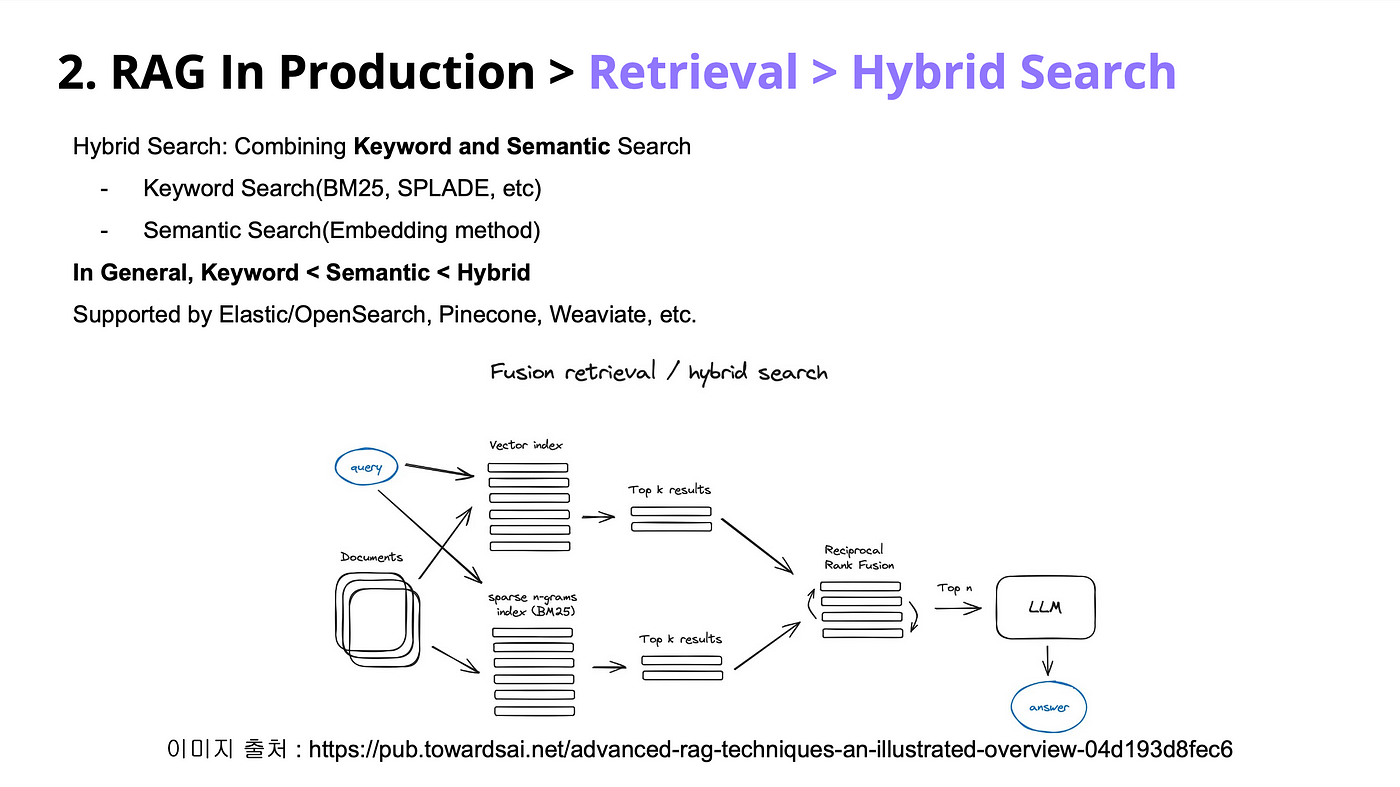
Keyword-based search like BM25 is precise but lacks semantic understanding, while dense vector search like FAISS captures meaning but often returns irrelevant results. Neither approach alone is enough for Retrieval-Augmented Generation (RAG).
Hybrid retrieval—combining BM25 and FAISS—bridges this gap.
BM25 filters results using exact term matching, while FAISS refines them by identifying deeper semantic connections.
Together, they enhance precision and contextual relevance, making RAG systems more reliable across legal research, healthcare, and technical documentation.
This article explores hybrid retrieval with BM25 and FAISS, breaking down how they work together, best practices for integration, and real-world applications.
If you aim to build an AI system that retrieves accurate and meaningful information, this approach delivers.
The Role of BM25 in Information Retrieval
BM25’s strength lies in its ability to balance term frequency with document length, creating a relevance score that is both precise and adaptable.
This mechanism is particularly effective when exact keyword matching, such as legal document retrieval or compliance audits, is critical.
Unlike dense vector models, which may overemphasize semantic similarity, BM25 ensures that peripheral associations do not dilute the core intent of a query.
One of the most compelling aspects of BM25 is its adaptability through parameter tuning.
For instance, the k1 parameter controls term frequency saturation, while b adjusts for document length normalization. These parameters allow practitioners to fine-tune the algorithm for domain-specific needs, such as prioritizing shorter, more concise documents in technical fields.
However, this flexibility also introduces challenges, as improper tuning can lead to suboptimal results, particularly in datasets with inconsistent document lengths.
BM25 acts as a filter in hybrid retrieval systems, narrowing down results before FAISS applies semantic refinement. This layered approach enhances accuracy and reduces computational overhead, making it indispensable in real-world applications.
FAISS: Enhancing Semantic Search with Dense Vectors
FAISS excels in transforming high-dimensional vector spaces into actionable insights, a capability that becomes indispensable when dealing with semantically rich but unstructured datasets.
Its core strength lies in its ability to map subtle relationships between terms, enabling retrieval systems to capture context that traditional methods often overlook. This makes FAISS particularly effective in scenarios where a nuanced understanding of user intent is critical.
One often-overlooked aspect of FAISS is the impact of index configuration on retrieval performance. For instance, the choice between flat and hierarchical indices can significantly influence both speed and accuracy.
Flat indices prioritize precision but may struggle with scalability, while hierarchical approaches, such as IVF (Inverted File Index), balance computational efficiency with retrieval depth.
These trade-offs highlight the importance of aligning index structures with specific application needs.
A notable implementation of FAISS can be seen in e-commerce platforms, where it refines product recommendations by analyzing user behavior patterns.
By using dense vectors, these systems identify latent preferences, such as brand affinity or style, that keyword-based methods fail to detect.
This adaptability underscores FAISS’s role as a cornerstone in hybrid retrieval, where precision and semantic depth converge seamlessly.
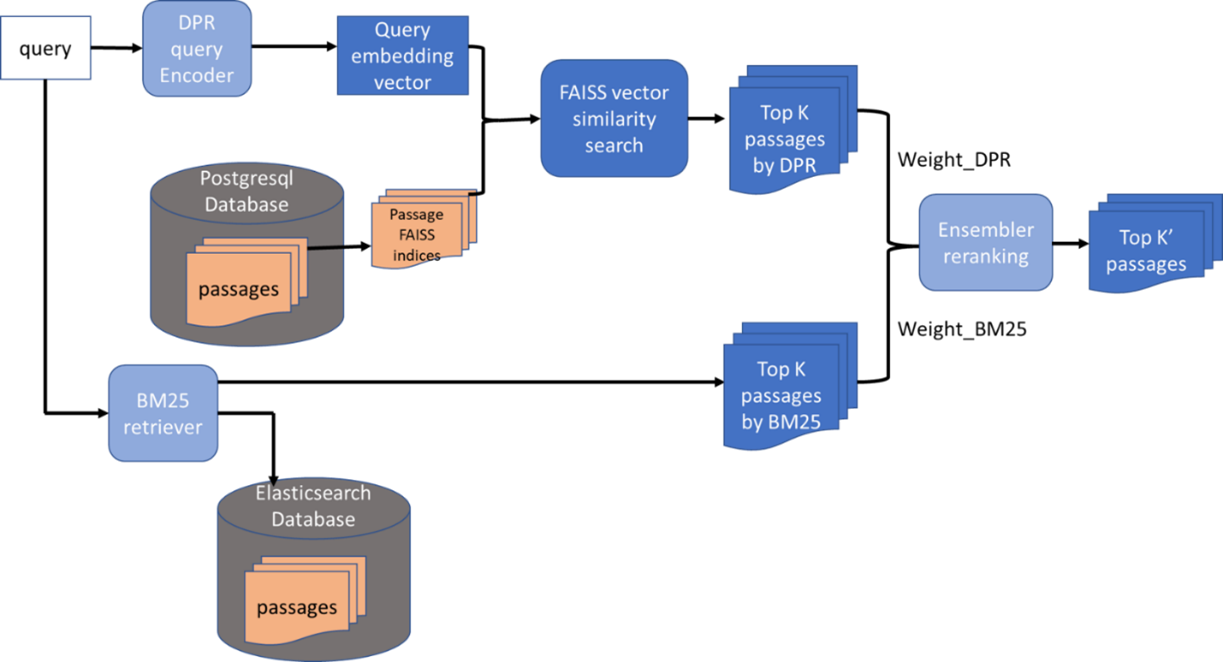
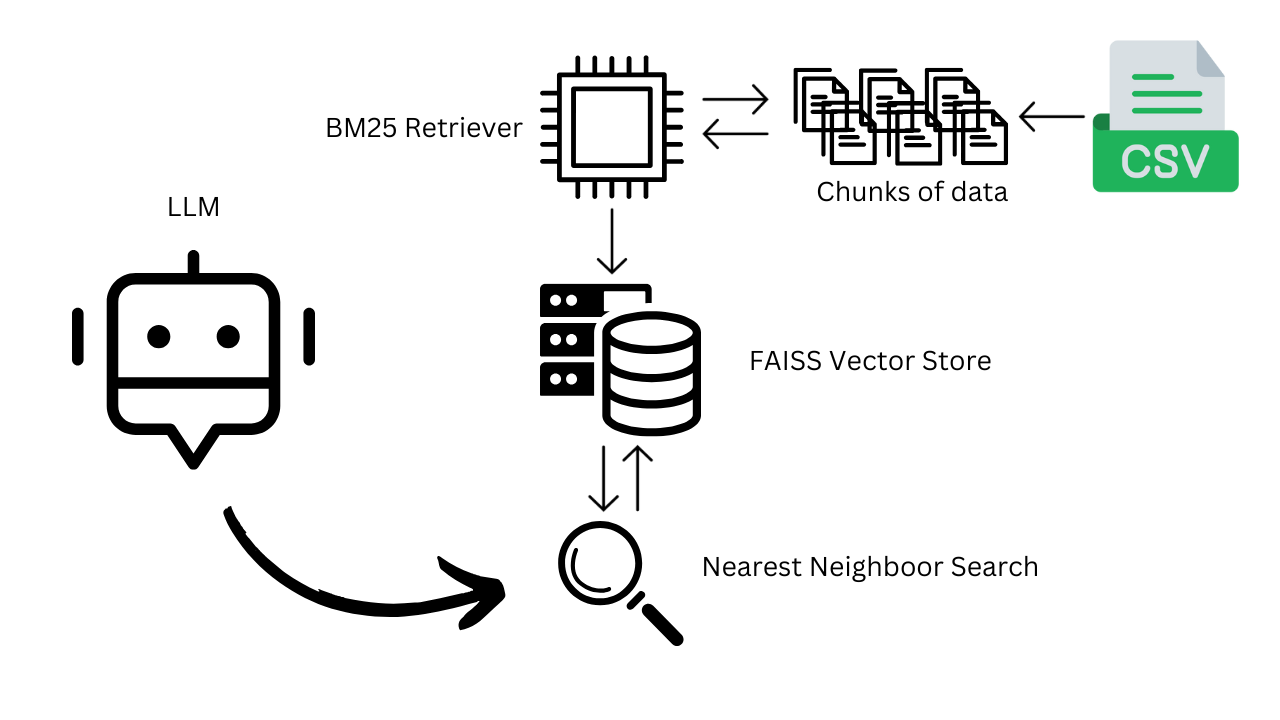
Integrating BM25 and FAISS for Hybrid Retrieval
Integrating BM25 and FAISS in hybrid retrieval systems is not merely a technical amalgamation but a deliberate orchestration of complementary strengths.
BM25 excels in pinpointing exact matches through lexical precision, while FAISS thrives in uncovering semantic relationships within high-dimensional vector spaces.
Together, they form a retrieval framework that addresses both explicit and implicit user intents, a necessity in complex domains like regulatory compliance or technical documentation.
A critical insight lies in the sequencing of these methods. BM25 often serves as a pre-filter, rapidly narrowing down a vast corpus to a manageable subset of documents.
FAISS then refines this subset by applying dense vector similarity, ensuring that the final results align semantically with the query. This layered approach enhances retrieval accuracy and reduces computational overhead, as FAISS operates on a smaller, pre-selected dataset.
Consider a hybrid system deployed in pharmaceutical research. BM25 identifies studies containing specific drug names, while FAISS discerns nuanced connections, such as shared molecular pathways.
This synergy transforms retrieval from a keyword-centric process into a context-aware discovery tool, enabling breakthroughs in data-driven decision-making.
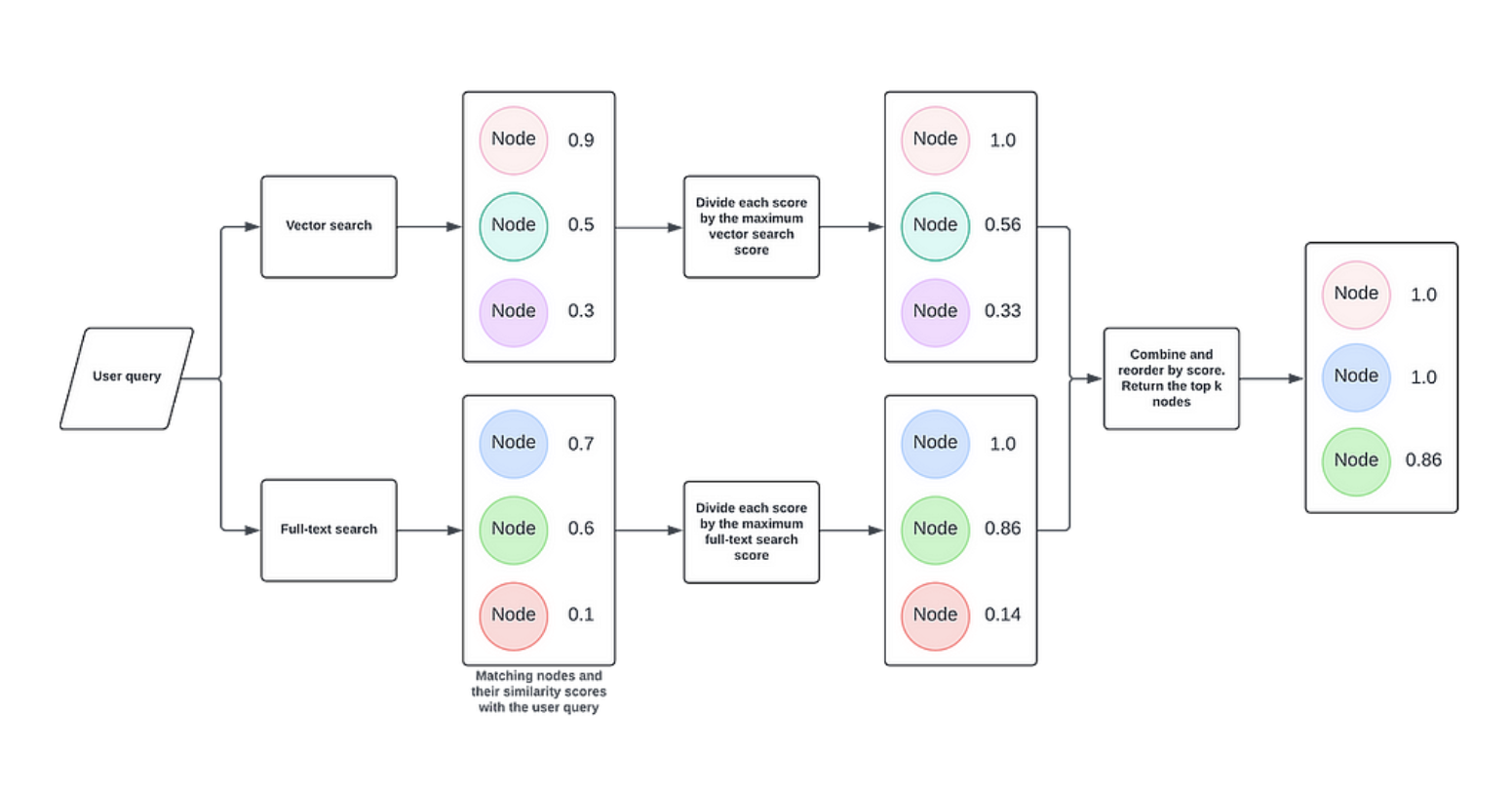
Combining Keyword and Semantic Search Techniques
The interplay between keyword precision and semantic depth is the cornerstone of hybrid retrieval systems.
BM25 acts as a lexical gatekeeper, filtering documents based on explicit keyword matches. However, its effectiveness hinges on parameter tuning, such as adjusting the k1 and b values to balance term frequency and document length.
A broader BM25 filter can provide FAISS with a richer dataset, enabling it to uncover latent semantic relationships. This sequencing ensures that FAISS operates on a curated subset, enhancing both efficiency and relevance.
For instance, in a legal document retrieval system implemented by a multinational law firm, BM25 was configured to prioritize exact matches for legal terms.
FAISS then identified semantically related precedents, such as cases with similar legal arguments. This dual-layered approach reduced retrieval times while improving contextual accuracy.
This method highlights a nuanced challenge: over-restricting BM25 can limit FAISS’s semantic potential, while overly broad filters may dilute precision. Striking this balance is key to unlocking the full potential of hybrid retrieval systems.
Technical Steps for Implementation in RAG
A critical step in implementing hybrid retrieval within Retrieval-Augmented Generation (RAG) systems is the precise orchestration of BM25 and FAISS to maximize both efficiency and relevance.
The sequencing of these methods is not merely procedural but foundational to achieving optimal results.
BM25 is the initial filter, leveraging its keyword-based precision to reduce the dataset to a manageable subset. Fine-tuning the k1 and b parameters is essential here; for instance, increasing k1 can emphasize term frequency, while adjusting b accounts for document length variability.
This ensures that the filtering process aligns with the specific characteristics of the dataset, such as document density or query specificity—however, overly restrictive tuning risks excluding semantically relevant documents, which could undermine FAISS’s subsequent role.
Once BM25 has narrowed the scope, FAISS applies dense vector similarity to refine the results further.
The choice of FAISS index type—whether flat or hierarchical—plays a pivotal role in balancing speed and accuracy. For example, hierarchical indices like IVF (Inverted File Index) are particularly effective in large-scale datasets, offering scalability without significant loss of precision.
This dual-layered approach ensures that FAISS operates on a curated dataset, reducing computational overhead while maintaining semantic depth.
In practice, iterative testing and dataset-specific adjustments are indispensable. For instance, in a healthcare application, BM25 might prioritize exact matches for medical terminology, while FAISS uncovers latent connections, such as symptom-disease relationships.
Performance Evaluation of Hybrid Retrieval Systems
Evaluating hybrid retrieval systems like BM25 and FAISS requires more than standard metrics; it demands a nuanced approach that captures both precision and contextual relevance.
Traditional measures such as Mean Reciprocal Rank (MRR) and Normalized Discounted Cumulative Gain (nDCG) are essential but insufficient alone.
These systems excel when tested against real-world datasets where user intent varies unpredictably, revealing their ability to adapt dynamically.
Performance evaluation, therefore, is not just validation—it’s a diagnostic tool. It identifies optimization opportunities, ensuring these systems meet the intricate demands of modern data retrieval.
Metrics for Assessing Retrieval Effectiveness
Evaluating hybrid retrieval systems demands metrics beyond surface-level precision, capturing the interplay between lexical accuracy and semantic depth.
One often-overlooked aspect is the role of query ambiguity in skewing traditional metrics like MRR and nDCG.
While valuable, these measures fail to account for user-specific context, critical in real-world applications.
A nuanced approach involves integrating query-specific feedback loops into the evaluation process. For instance, in a pharmaceutical company deployment, user feedback on ambiguous queries revealed gaps in BM25’s keyword prioritization.
Adjusting the k1 parameter to reduce term frequency saturation improved initial filtering, allowing FAISS to utilize its semantic capabilities better. This iterative refinement highlighted the importance of aligning metrics with user intent rather than static benchmarks.
Another challenge lies in edge cases, where hybrid systems struggle with conflicting signals from BM25 and FAISS. For example, overly broad BM25 filters can overwhelm FAISS, diluting semantic refinement.
Addressing this requires a hybrid metric that dynamically weights lexical and semantic contributions, ensuring balanced performance across diverse query types. This approach transforms evaluation into a tool for continuous optimization rather than a static validation step.
Benchmarking Against Traditional Methods
When comparing hybrid retrieval systems to traditional methods, the critical insight is to understand how these systems handle query complexity.
Traditional approaches, like standalone BM25, excel in straightforward keyword matching but falter when queries demand nuanced semantic interpretation.
Conversely, dense vector models often overgeneralize, missing precise lexical matches. The hybrid approach bridges this gap, but its effectiveness hinges on fine-tuning the interplay between BM25 and FAISS.
A key challenge emerges in parameter calibration. For instance, overly restrictive BM25 filters can suppress FAISS’s ability to identify latent semantic relationships.
In a legal research platform deployment, adjusting BM25’s k1 parameter to reduce term frequency saturation revealed a marked improvement in FAISS’s semantic refinement, particularly for ambiguous legal terms.
This underscores the importance of iterative tuning to align system behavior with user intent.
Ultimately, benchmarking hybrid systems requires moving beyond static metrics like nDCG. Instead, practitioners must evaluate how well these systems balance precision and semantic depth across diverse, context-specific queries. This dynamic approach ensures relevance in practical applications.
Challenges and Considerations in Hybrid Retrieval
Building an effective hybrid retrieval system with BM25 and FAISS involves careful trade-offs.
One of the biggest challenges is balancing computational efficiency with retrieval accuracy. BM25 is fast at filtering large document sets, but if its filtering is too strict, it may exclude useful documents that FAISS could refine for relevance.
On the other hand, if BM25 retrieves too many documents, FAISS must process excessive noise, reducing efficiency and increasing retrieval time.
Another challenge is index alignment between BM25’s sparse representations and FAISS’s dense vector embeddings.
BM25 relies on exact term matches, while FAISS operates in high-dimensional space, capturing semantic meaning. If these indices are not appropriately calibrated, retrieval inconsistencies can emerge.
The challenge is ensuring that BM25 retrieves documents that provide FAISS with enough context to refine, rather than conflicting signals that reduce retrieval accuracy.
Parameter tuning further complicates hybrid retrieval. BM25’s k1 and b parameters influence how term frequency and document length affect ranking.
FAISS requires carefully selecting indexing methods like IVF (Inverted File Index) or HNSW (Hierarchical Navigable Small Worlds). If these parameters are not optimized together, one method may overpower the other, leading to suboptimal retrieval.
Fine-tuning these parameters is an iterative process that requires constant testing with real queries to balance precision and contextual relevance.
Hybrid retrieval is not a plug-and-play solution. It requires domain-specific adjustments, continuous evaluation, and strategic system design to ensure BM25 and FAISS complement each other instead of working at cross-purposes.
Balancing Keyword and Semantic Relevance
Achieving equilibrium between BM25’s keyword precision and FAISS’s semantic depth requires a nuanced understanding of their interplay.
A critical yet often overlooked factor is the dynamic adjustment of BM25’s filtering scope to ensure FAISS has sufficient data to extract meaningful semantic relationships. This balance is not merely technical but deeply contextual, varying significantly across datasets and use cases.
One effective technique involves adaptive parameter tuning based on query complexity.
For instance, in scenarios with highly specific queries, BM25’s k1 parameter can be increased to emphasize term frequency, ensuring precise keyword matches.
However, relaxing BM25’s constraints in broader queries allows FAISS to explore latent semantic connections, such as thematic overlaps or contextual nuances. This adaptive approach ensures that neither method undermines the other’s strengths.
Ultimately, balancing these methods demands iterative testing and domain-specific adjustments, transforming hybrid retrieval into a craft that evolves with real-world application.
FAQ
What are the key benefits of combining BM25 and FAISS in a hybrid retrieval system for RAG?
BM25 ensures precise keyword-based retrieval, while FAISS captures semantic relationships. This hybrid approach balances exact term matching with contextual depth, improving retrieval accuracy. It reduces irrelevant results, optimizes computational efficiency, and enhances AI-generated responses in research, healthcare, and legal applications.
How does parameter tuning in BM25 and index configuration in FAISS impact retrieval performance?
Tuning BM25’s k1 and b parameters controls term frequency weighting and document length normalization, refining keyword-based search. FAISS indexing, such as IVF or HNSW, balances speed and accuracy. Proper tuning ensures BM25 filters results effectively while FAISS extracts deeper meaning, improving retrieval precision.
What are the best practices for integrating BM25 and FAISS to optimize retrieval in RAG systems?
BM25 should act as an initial filter to reduce noise, while FAISS ranks results based on meaning. To ensure efficiency, fine-tune BM25’s parameters for term weighting and FAISS’s indexing. Maintain consistent embedding spaces and test retrieval pipelines iteratively to ensure keyword precision and semantic accuracy work together.
How can hybrid retrieval systems improve domain-specific queries and contextual relevance?
Hybrid retrieval enhances domain-specific searches by combining BM25’s term matching with FAISS’s contextual awareness. This approach ensures the accurate retrieval of technical, medical, or legal documents. Fine-tuning embeddings and incorporating metadata further improve results, enabling more precise and meaningful document retrieval.
What tools and frameworks are recommended for implementing hybrid retrieval in RAG workflows?
BM25 can be implemented with Elasticsearch or OpenSearch, while FAISS handles dense vector search. LangChain integrates retrieval into AI applications, and Hugging Face Transformers assist with embedding generation. For scalability, Kubernetes and Apache Kafka manage large-scale hybrid retrieval systems efficiently.
Conclusion
Hybrid retrieval using BM25 and FAISS improves how RAG systems process and retrieve information. BM25 ensures accurate term-based filtering, while FAISS refines results using vector similarity.
This dual-layered approach reduces irrelevant data and enhances precision, making AI-driven retrieval more reliable across industries. As AI applications expand, optimizing hybrid search will be essential for improving knowledge-based systems.