
How Query Expansion (HyDE) Boosts Your RAG Accuracy
Query Expansion using HyDE enhances RAG by creating richer queries that lead to more accurate and relevant results. This guide explains how HyDE works, its benefits, and how to implement it to significantly boost your RAG system’s performance.


Retrieval-Augmented Generation systems are great—until they’re not.
You write a query, but the system brings back results that look relevant on the surface and miss the mark underneath.
The problem? Traditional retrieval often struggles to understand what you actually meant, especially when the query is vague or domain-specific.
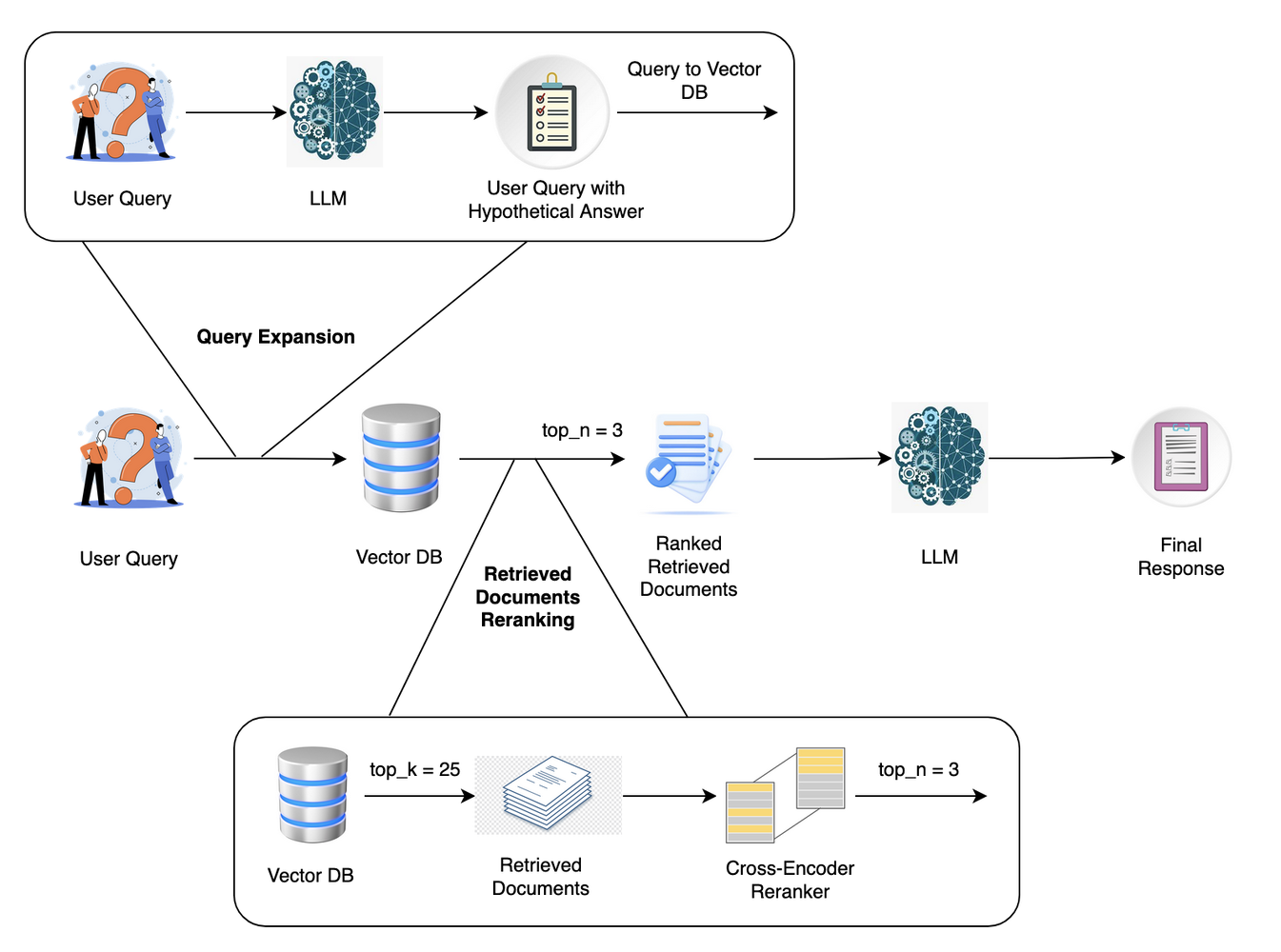
This is where query expansion with HyDE comes in. Instead of relying on keyword matches or shallow rephrasings, HyDE creates a hypothetical document reflecting your question's intent.
It’s like giving your system a clear example of what you’re looking for—before it goes looking.
In this article, we’ll explore how query expansion (HyDE) boosts your RAG accuracy, especially in high-stakes and low-data settings.
From how it works to why it matters, we’ll walk through what makes HyDE different—and why it’s becoming a go-to method for precision-first retrieval.
Core Principles of RAG Systems
The interplay between retrieval and generation in RAG systems hinges on a critical yet often underappreciated factor: the alignment of semantic intent between the retriever and generator.
This alignment ensures that retrieved data matches the query and integrates seamlessly into the generated response, creating accurate and contextually coherent outputs.
At the heart of this process lies the use of dense vector representations, which encode the semantic meaning of queries and documents.
Unlike traditional keyword-based retrieval, this approach enables the system to capture nuanced intent, even when phrasing varies.
For instance, in legal research, dense vectors allow RAG systems to retrieve precedent cases that align with the underlying principles of a query, rather than just surface-level terminology.
However, achieving this alignment is not without challenges. One limitation arises when the retriever pulls conflicting or overly broad data, which can overwhelm the generator. Techniques like passage-level retrieval and advanced attention mechanisms mitigate this by narrowing the focus to the most relevant information.
By refining these principles, RAG systems evolve into tools that inform and inspire trust through precision and adaptability.
Challenges in Traditional RAG Approaches
Traditional RAG systems often struggle with query ambiguity, where literal word matching fails to capture the nuanced intent behind user inputs.
This limitation becomes particularly evident in domains with specialized language or evolving terminology, where the absence of a semantic intermediary leads to scattered, irrelevant results.
The core issue lies in the inability to bridge the gap between surface-level keywords and deeper contextual meaning.
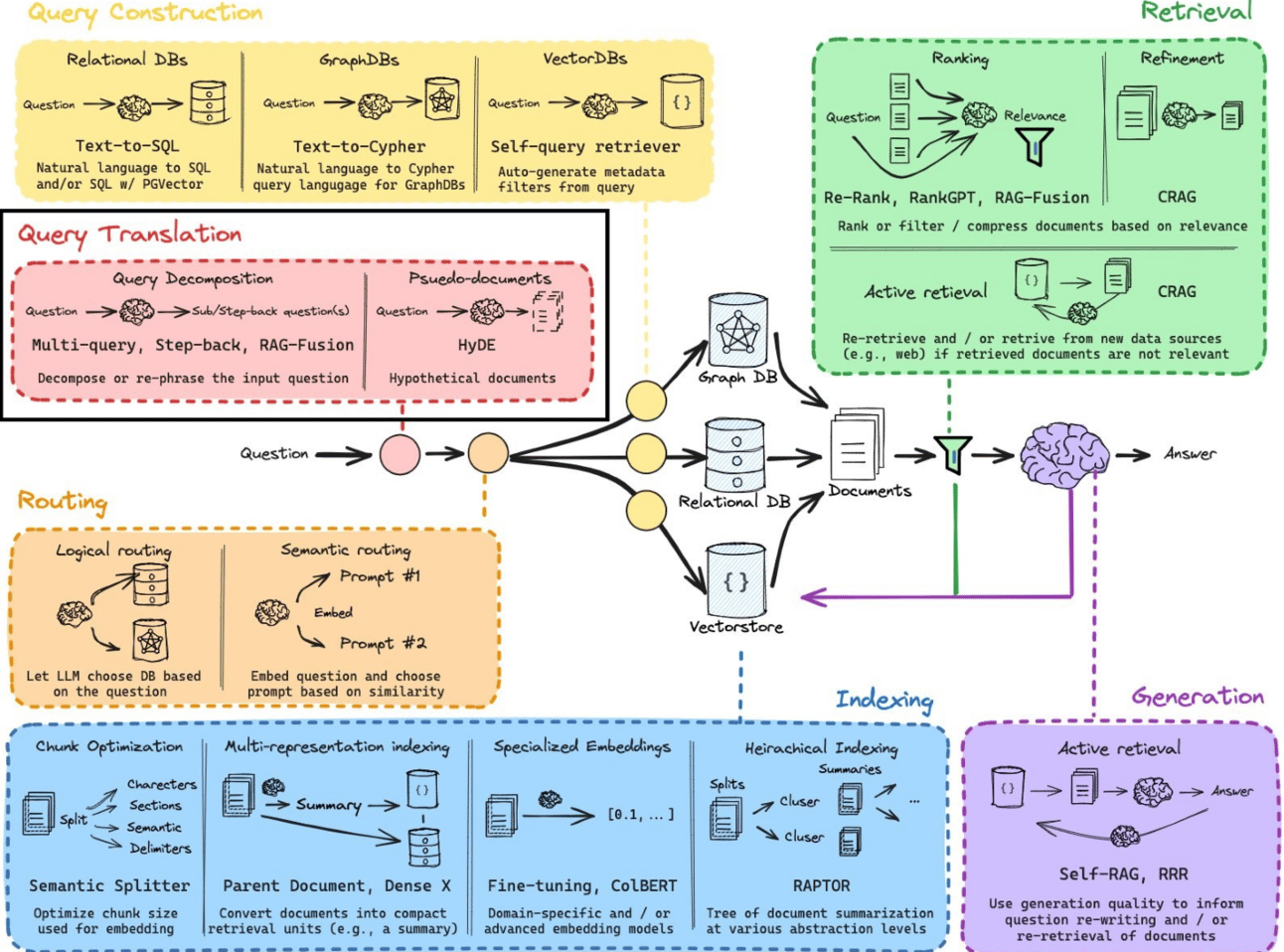
One promising solution is query expansion through hypothetical document embeddings (HyDE).
Introduction to Hypothetical Document Embeddings (HyDE)
Imagine solving a puzzle with missing pieces—this is the challenge traditional RAG systems face when interpreting ambiguous queries.
Hypothetical Document Embeddings (HyDE) address this by creating a synthetic “missing piece” that aligns user intent with document relevance.
Unlike conventional query expansion, which merely rephrases input, HyDE generates a hypothetical document that encapsulates the query’s semantic essence, transforming retrieval into a precision-driven process.
This technique leverages Large Language Models (LLMs) to craft these hypothetical documents, which are then encoded into dense vector representations.
These vectors act as a bridge, aligning the query with the latent space of relevant documents.
For instance, in a legal context, HyDE can retrieve case law that aligns with the principles of a query, even if the phrasing diverges significantly from the source material.
What sets HyDE apart is its adaptability.
It excels in zero-shot scenarios by bypassing reliance on labeled datasets, making it invaluable for domains with sparse training data.
This paradigm shift enhances retrieval accuracy and reduces irrelevant results, ensuring that the generated responses resonate with user intent.
Conceptual Framework of HyDE
At its core, HyDE redefines query expansion by transforming user input into a hypothetical document that mirrors the query’s intent.
This process is not merely about rephrasing but about constructing a semantic proxy that aligns with the latent structure of the document corpus.
By doing so, HyDE bridges the gap between user intent and document relevance, a challenge that traditional keyword-based methods often fail to address.
The mechanism hinges on leveraging Large Language Models (LLMs) to generate these hypothetical documents.
Unlike direct query embeddings, which can falter in capturing nuanced intent, the hypothetical document is a high-fidelity intermediary.
This intermediary is encoded into dense vector representations, enabling the retrieval system to operate within a semantically enriched space.
The result is a retrieval process that is both precise and contextually aware.
One notable limitation, however, is the dependency on the quality of the LLM. The generated document may lack the granularity required in domains with highly specialized language, necessitating domain-specific fine-tuning.
HyDE vs. Traditional Query Expansion
Traditional query expansion often relies on rephrasing or appending keywords, which can dilute the query’s intent rather than refine it.
HyDE, however, introduces a paradigm shift by generating a hypothetical document that encapsulates the query’s semantic essence.
This approach doesn’t just expand the query—it reimagines it, creating a structured representation that aligns more closely with the latent space of the document corpus.
The key mechanism lies in the use of Large Language Models (LLMs) to craft these hypothetical documents.
Unlike traditional methods, which depend on surface-level keyword manipulation, HyDE leverages the LLM’s ability to infer context and intent, embedding this synthesized understanding into dense vector representations.
This enables retrieval systems to operate within a semantically enriched framework, significantly improving precision.
One critical advantage of HyDE is its adaptability across domains.
For instance, in legal research, where language is highly specialized, HyDE can generate hypothetical interpretations of complex legal queries, bridging gaps that traditional methods often leave unaddressed.
However, its reliance on LLM quality introduces challenges in domains with sparse or highly technical data, where fine-tuning becomes essential.
By transcending keyword-based limitations, HyDE ensures that retrieval systems deliver results that resonate deeply with user intent, making it a transformative tool in information retrieval.
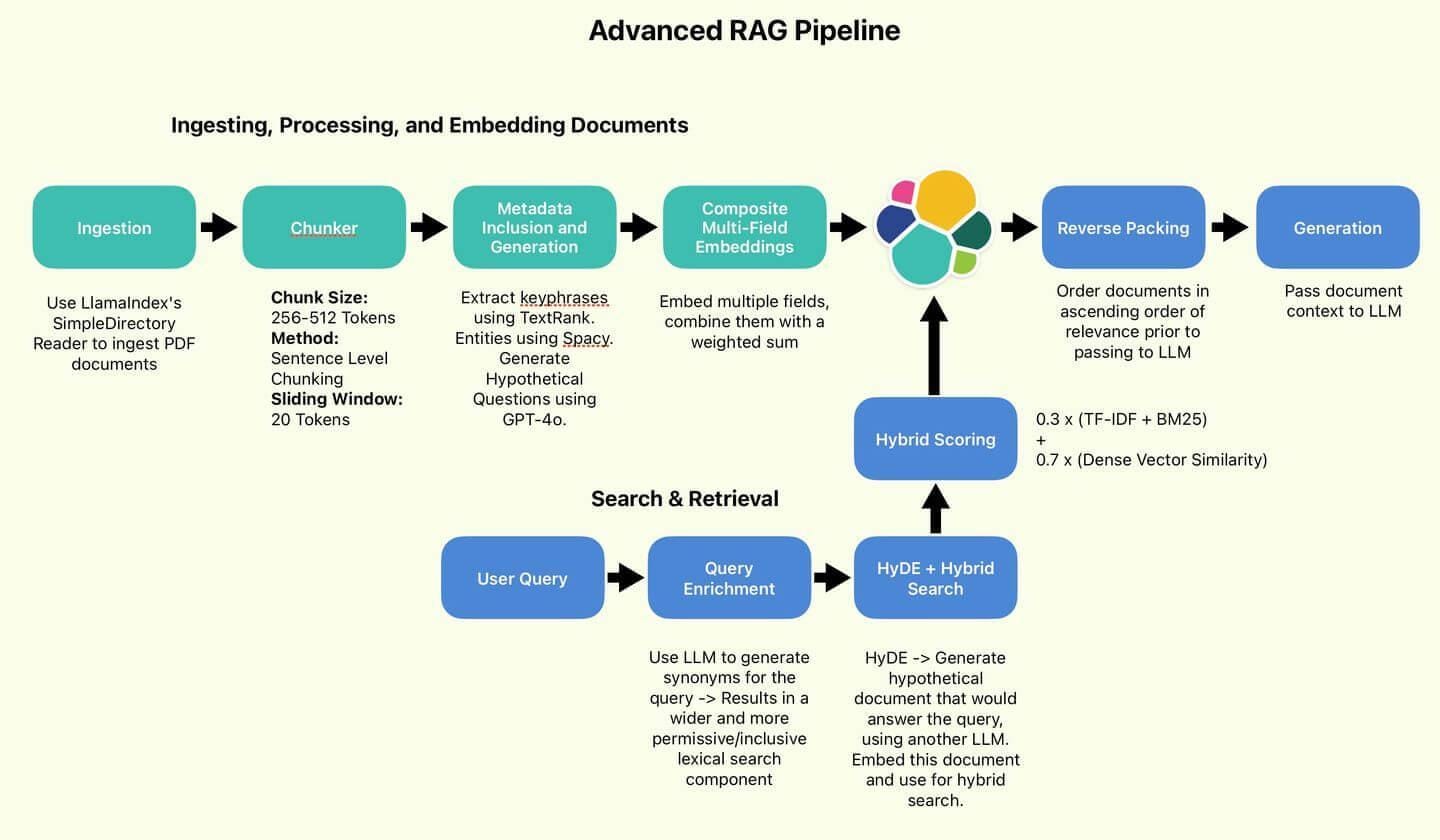
Implementing HyDE in RAG Pipelines
Implementing HyDE in RAG pipelines begins with a transformative step: generating a hypothetical document that reinterprets the query into a semantically enriched format.
This process is a rephrasing exercise and a deliberate construction of a proxy document that encapsulates the query’s latent intent.
For instance, when applied to medical research, a query like “What are the latest treatments for Alzheimer’s?” might yield a hypothetical document summarizing emerging therapies, mechanisms, and clinical trials.
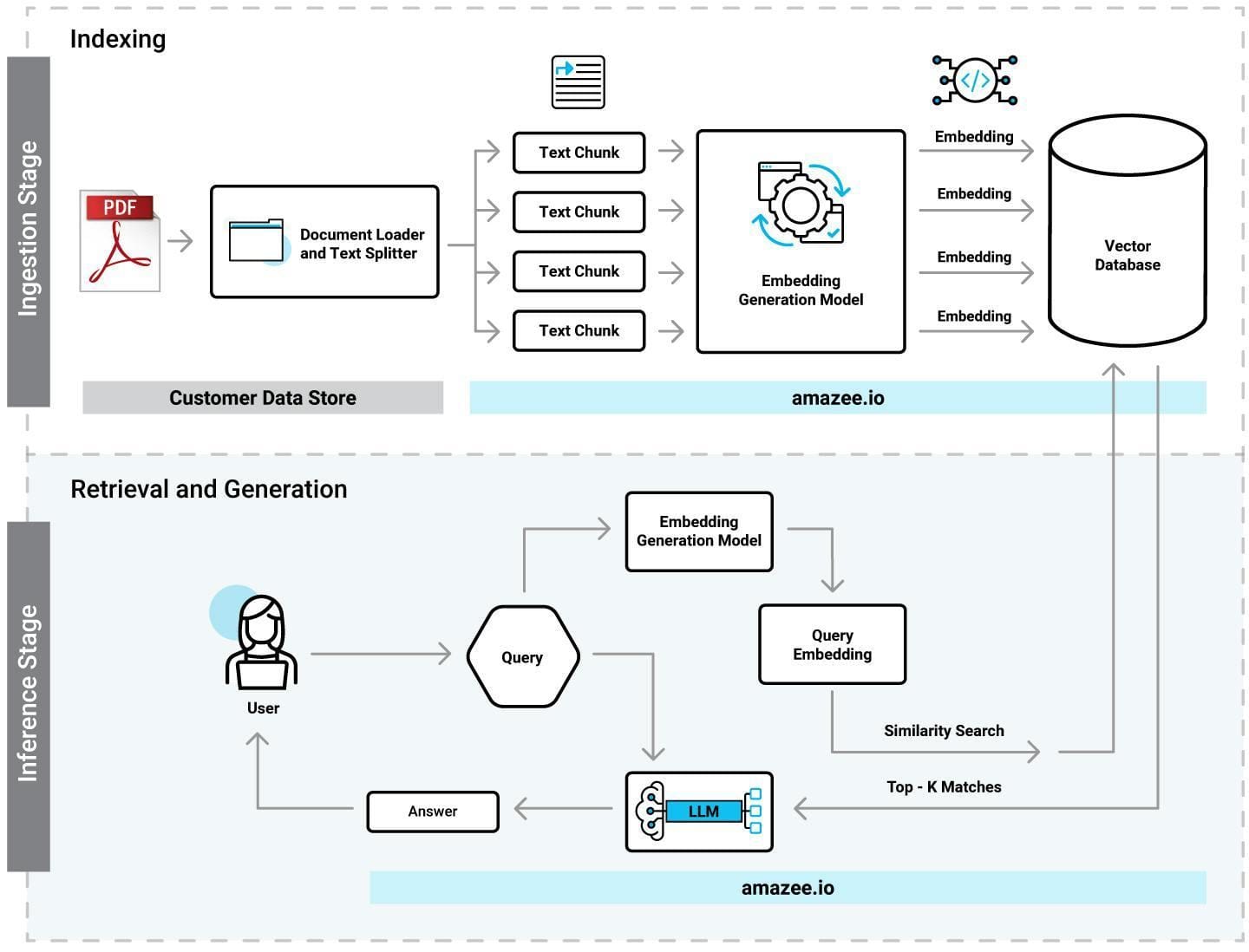
This synthesized document becomes the foundation for embedding and retrieval.
The next stage involves dense embedding generation, where the hypothetical document is encoded into a vector representation.
This vector acts as a precise locator within the document corpus, enabling the retrieval system to prioritize contextually aligned materials.
Unlike traditional keyword-based methods, this approach minimizes noise and enhances relevance, particularly in domains with complex or ambiguous queries.
By integrating HyDE, organizations can achieve a dual benefit: improved retrieval accuracy and reduced reliance on extensive labeled datasets, making it a scalable solution for diverse applications.
Generating Hypothetical Documents
The essence of generating hypothetical documents is crafting a semantic proxy that precisely mirrors the query’s intent.
This process transforms the query into a structured narrative, enabling retrieval systems to operate within a context-rich framework.
Unlike traditional query expansion, which often dilutes intent with redundant keywords, HyDE leverages the generative capabilities of LLMs to construct a hypothetical document that encapsulates the query’s latent meaning.
The LLM’s ability to infer subtle contextual cues is a critical factor in this process.
For instance, the generated document might incorporate nuanced terminology and case-specific phrasing in a legal domain application, ensuring alignment with the corpus.
This approach nenhances retrieval accuracy andreduces dependency on extensive labeled datasets, making it particularly effective in zero-shot scenarios.
However, the quality of the generated document is pivotal. In highly specialized fields, inadequate fine-tuning of the LLM can lead to oversimplified or contextually irrelevant outputs, underscoring the need for domain-specific optimization.
This balance between adaptability and precision defines HyDE’s transformative potential.
Embedding and Retrieval Process
The embedding and retrieval process in HyDE transforms the retrieval landscape by prioritizing semantic alignment over surface-level keyword matching.
At its core, this approach leverages the dense embeddings of hypothetical documents to navigate a multidimensional vector space, ensuring that retrieved documents resonate with the query’s deeper intent.
his shift from direct query embeddings to hypothetical document embeddings addresses a critical gap in traditional retrieval systems: the inability to capture nuanced, context-rich queries.
One of the most compelling aspects of this process is its adaptability across domains. For instance, HyDE embeddings maintain semantic fidelity in multilingual applications without requiring separate models for each language.
This capability stems from the use of instruction-tuned LLMs, which generate hypothetical documents that encode the query’s latent meaning, regardless of linguistic variations.
However, the effectiveness of this approach hinges on the quality of the embedding model and the vector similarity search algorithm, which must balance precision with computational efficiency.
A notable challenge arises in edge cases where the generated hypothetical document diverges from the query’s true intent.
This underscores the importance of fine-tuning LLMs for domain-specific contexts, ensuring that embeddings remain both accurate and relevant. By addressing these complexities, HyDE redefines retrieval as a process of semantic discovery rather than mere data matching.
Benefits and Performance Enhancements of HyDE
HyDE revolutionizes retrieval by addressing a critical flaw in traditional RAG systems: their reliance on direct query-document matching.
By generating hypothetical documents that encapsulate user intent, HyDE enables retrieval systems to operate within a semantically enriched framework, significantly improving precision.
A key advantage lies in its zero-shot retrieval capability, which eliminates the need for extensive labeled datasets. Think of HyDE as a translator that doesn’t just interpret words but understands their intent, ensuring that even poorly phrased queries yield meaningful results.
Improved Retrieval Accuracy
HyDE enhances retrieval accuracy by transforming vague queries into semantically rich hypothetical documents, aligning them more closely with the latent structure of the document corpus.
This process addresses a critical challenge: the semantic gap between user intent and document representation.
HyDE ensures that retrieval systems prioritize relevance over superficial keyword matches by embedding the hypothetical document into a dense vector space.
One of the most compelling aspects of this approach is its ability to adapt to complex, open-ended queries.
For instance, in a collaboration with a legal research firm, HyDE was implemented to handle intricate case law queries.
The system generated hypothetical documents that mirrored the nuanced phrasing of legal arguments, significantly improving retrieval precision. This adaptability highlights HyDE’s strength in domains where traditional methods often falter.
However, the technique is not without limitations. In highly specialized fields, the quality of the generated document depends heavily on the underlying LLM’s training.
Fine-tuning these models for domain-specific contexts is essential to maintain accuracy. This balance between adaptability and precision underscores HyDE’s transformative potential.
Zero-shot Capabilities and Generalization
HyDE’s zero-shot capabilities redefine how retrieval systems handle unfamiliar queries, particularly in domains with limited labeled data.
By leveraging hypothetical document generation, HyDE creates a semantic intermediary that bridges the gap between ambiguous inputs and relevant outputs.
This mechanism eliminates the need for extensive retraining, making it a practical solution for dynamic, data-scarce environments.
HyDE’s ability to generalize across tasks and languages without task-specific fine-tuning is a key differentiator.
Unlike traditional systems that falter when encountering novel contexts, HyDE’s reliance on contrastive text encoders ensures robust performance.
For instance, HyDE seamlessly aligns diverse linguistic inputs with relevant knowledge bases in multilingual applications, demonstrating its adaptability.
However, this flexibility comes with challenges. The quality of generated hypothetical documents heavily depends on the underlying language model’s training.
In highly specialized fields, domain-specific fine-tuning may still be required to maintain precision. Despite this, HyDE’s zero-shot generalization offers a transformative approach, enabling retrieval systems to operate effectively in unpredictable and evolving contexts.
Advanced Applications and Optimizations
HyDE’s integration into domain-specific RAG systems has unlocked unprecedented precision in fields like healthcare and e-commerce.
For instance, in clinical decision support, HyDE dynamically generates hypothetical documents that align with nuanced medical terminologies, enabling retrieval systems to surface critical patient data in real-time.
This approach not only enhances diagnostic accuracy but also reduces the cognitive load on healthcare providers by filtering irrelevant information.
A key optimization lies in adaptive embedding models, which fine-tune HyDE’s performance for specialized datasets.
By leveraging contrastive learning techniques, these models ensure that embeddings capture subtle semantic variations, such as legal precedents or multilingual customer queries.
This adaptability transforms HyDE into a versatile tool capable of addressing the unique challenges of each domain.
Think of HyDE as a semantic lens: it doesn’t just magnify relevant data but refines it, ensuring clarity and precision. This capability redefines retrieval as a process of contextual understanding rather than mere data matching.
Domain-specific HyDE Optimizations
Fine-tuning HyDE for domain-specific applications hinges on adapting the hypothetical document generation process to reflect the specialized language and context of the field.
This customization ensures that the generated embeddings align more closely with the semantic structure of the target corpus, significantly improving retrieval precision.
In healthcare, for example, tailoring the LLM to recognize clinical terminologies and diagnostic patterns allows HyDE to generate hypothetical documents that resonate with the intricacies of medical literature. This approach not only enhances retrieval accuracy but also reduces the risk of retrieving irrelevant or misleading information.
The process involves training the LLM on domain-specific datasets, enabling it to capture subtle contextual cues that generic models often overlook.
A comparative analysis reveals that while general-purpose HyDE excels in broad applications, its performance diminishes in fields requiring high granularity.
Domain-specific tuning addresses this gap by embedding nuanced intent into the retrieval pipeline.
However, this approach demands careful calibration to avoid overfitting, which could limit the model’s adaptability to new queries.
By integrating adaptive embedding techniques, organizations can transform HyDE into a precision tool, capable of navigating the complexities of specialized domains with unparalleled accuracy.
Integration with Emerging AI Technologies
Integrating HyDE with emerging AI technologies transforms retrieval systems into dynamic, context-aware tools capable of adapting to real-time complexities.
One particularly impactful synergy lies in combining HyDE with reinforcement learning frameworks.
This approach enables systems to refine hypothetical document generation based on iterative feedback, ensuring that retrieval aligns more closely with evolving user intent.
The underlying mechanism involves leveraging reinforcement learning agents to evaluate the relevance of retrieved documents against user interactions.
By scoring and iteratively optimizing the hypothetical document embeddings, the system learns to prioritize contextually significant data.
This dynamic adjustment is especially valuable in domains like financial analytics, where query relevance can shift rapidly based on market conditions.
A notable challenge arises in balancing computational efficiency with the depth of optimization. Reinforcement learning models, while powerful, can introduce latency if not carefully tuned.
Techniques such as reward shaping and parallel processing mitigate these issues, ensuring that performance gains do not come at the expense of speed.
This convergence of technologies enhances retrieval precision and paves the way for systems that intuitively adapt to complex, real-world scenarios, redefining the boundaries of information retrieval.
FAQ
What is Query Expansion in RAG and how does HyDE improve accuracy?
Query Expansion in RAG refines a user query to retrieve better-matching documents. HyDE improves this by generating a hypothetical document that represents the query’s meaning, improving retrieval precision without relying on keyword overlap.
How does HyDE use entity relationships in Retrieval-Augmented Generation?
HyDE maps related entities from the query into a structured form that mirrors how they appear in documents. This mapping helps retrieve more contextually accurate results in RAG systems by aligning document content with the query’s deeper meaning.
What is salience analysis and how does it improve retrieval in HyDE?
Salience analysis identifies key terms in the query and generated text that matter most for retrieval. HyDE uses this to prioritize relevant content and reduce noise, improving RAG performance by returning more focused results.
How does co-occurrence optimization reduce noise in HyDE-based retrieval?
Co-occurrence optimization detects patterns of how terms appear together across documents. In HyDE, this helps filter irrelevant results by guiding the retrieval system toward documents with stronger conceptual links to the query.
What are the main benefits of HyDE in domain-specific RAG applications?
HyDE improves domain-specific retrieval by generating documents that match specialized language and context. It adapts to legal, medical, or technical fields, improving accuracy in RAG systems without needing large labeled datasets.
Conclusion
Query Expansion using HyDE is reshaping how Retrieval-Augmented Generation systems understand and respond to complex queries. By generating hypothetical documents, HyDE captures intent and context that keyword-based methods miss. This leads to improved RAG accuracy, better handling of ambiguous inputs, and stronger performance in zero-shot and domain-specific use cases. As retrieval systems continue to evolve, HyDE offers a structured way to bridge the gap between language and meaning.