
Implementing GraphRAG for Improved Contextual Retrieval
GraphRAG improves contextual retrieval by mapping relationships between data points for more precise AI responses. This guide explores implementation strategies, benefits, and how to optimize retrieval-augmented generation using graph-based techniques.


Imagine searching for a critical legal clause and getting a list of isolated results with no context. That’s the problem traditional retrieval systems struggle with. They constantly fail to connect related information, leaving gaps in analysis.
In 2024, Microsoft introduced GraphRAG, an open-source framework that enhances contextual retrieval by structuring data as a knowledge graph.
Unlike flat text databases, GraphRAG maps relationships between entities, revealing insights that standard search methods miss. By embedding relational knowledge, GraphRAG doesn’t just retrieve answers—it reconstructs context, making AI-driven search more precise and actionable.
Understanding Retrieval Augmented Generation
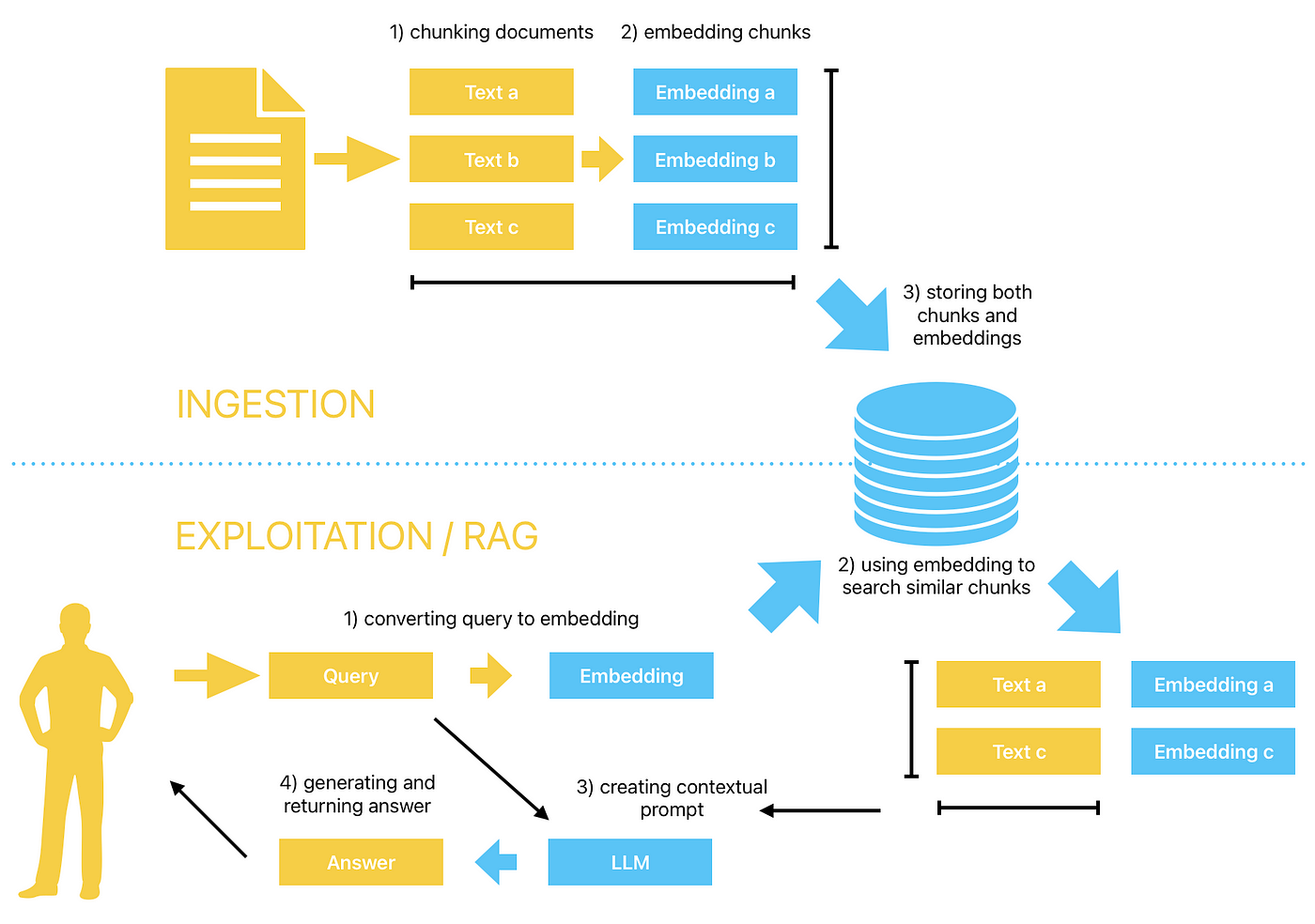
Retrieval Augmented Generation (RAG) operates at the intersection of generative AI and information retrieval, embedding a retrieval mechanism into the generation process to enhance accuracy and contextual relevance.
Unlike traditional LLMs, which rely solely on pre-trained data, RAG dynamically queries external sources, integrating real-time, domain-specific information into its outputs.
This dual-layered approach mitigates issues like hallucination and outdated responses, making it indispensable for knowledge-intensive tasks.
The success of RAG lies in its ability to prioritize relevance.
Semantic search algorithms, a core component, interpret user intent and contextual nuances, ensuring retrieved data aligns precisely with the query.
This capability is further amplified by graph-structured frameworks like GraphRAG, which map relationships between entities, uncovering hidden connections.
As industries increasingly demand precision and adaptability, RAG’s integration into enterprise workflows signals a paradigm shift, redefining how organizations harness AI for decision-making.
The Role of Knowledge Graphs in AI
Knowledge graphs (KGs) are pivotal in enhancing AI systems by structuring and contextualizing data relationships.
Their integration with AI models, particularly in graph-structured frameworks like GraphRAG, has unlocked new dimensions of contextual retrieval and reasoning.
A critical advantage of KGs lies in their ability to surface hidden connections.
For instance, graph neural networks (GNNs) operating on KGs can predict relationships between entities, such as identifying potential fraud patterns in financial transactions.
This predictive capability is amplified by integrating real-time data streams, ensuring relevance and adaptability.
By embedding KGs into AI workflows, industries can achieve not only operational efficiency but also a deeper understanding of complex datasets, driving innovation and competitive advantage.
Core Components of GraphRAG
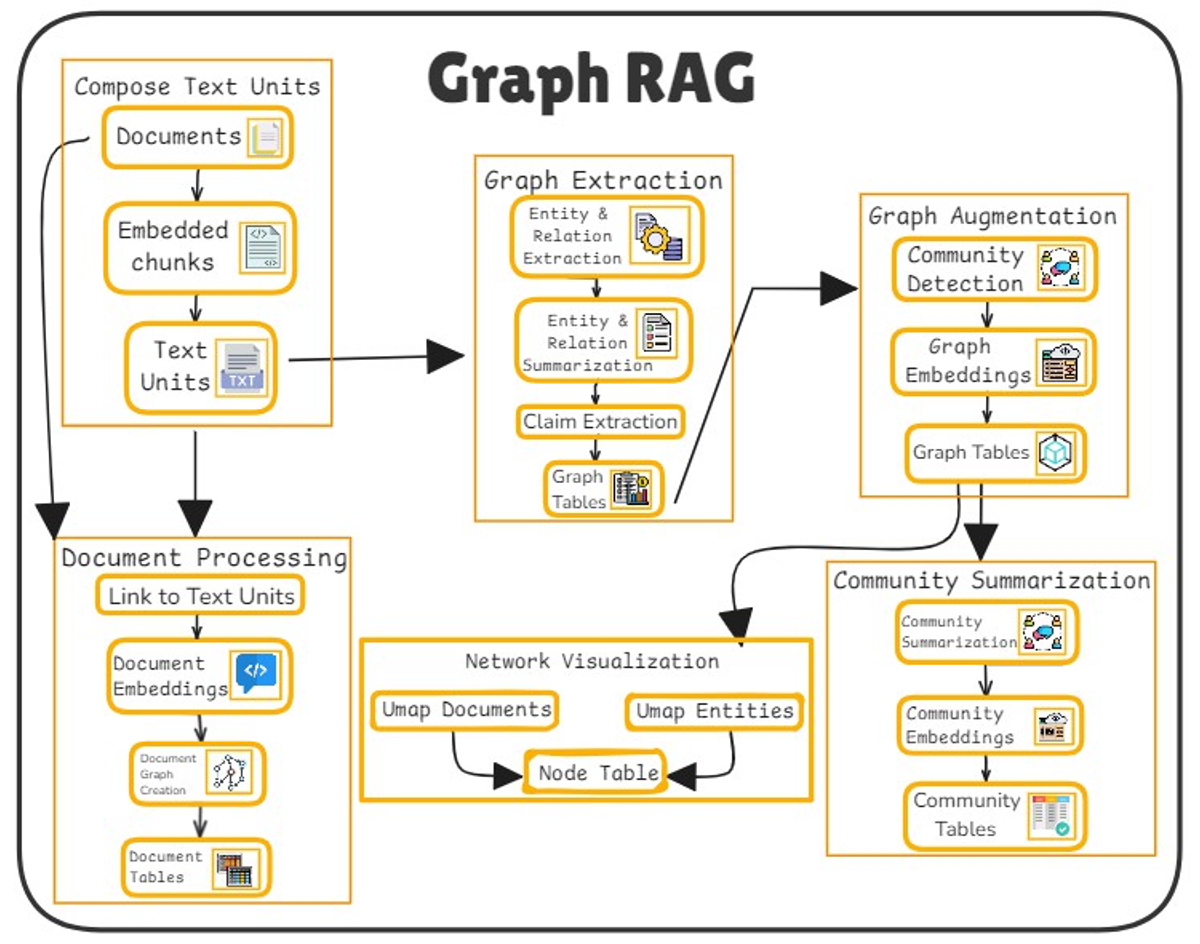
GraphRAG’s architecture is built on three foundational components: graph-based knowledge representation, advanced retrieval mechanisms, and context-aware text generation.
Together, these elements enable a seamless integration of structured and unstructured data, driving precision and contextual relevance.
Graph-Based Knowledge Representation
At its core, GraphRAG organizes data as nodes and edges, capturing not only facts but also the relationships between them.
Advanced Retrieval Mechanisms
Unlike traditional systems, GraphRAG leverages semantic search and graph traversal algorithms to prioritize relevance.
Context-Aware Text Generation
By dynamically integrating retrieved data, GraphRAG ensures outputs remain grounded in factual context.
These components collectively redefine AI’s ability to handle complex queries, offering actionable insights and fostering innovation across industries.
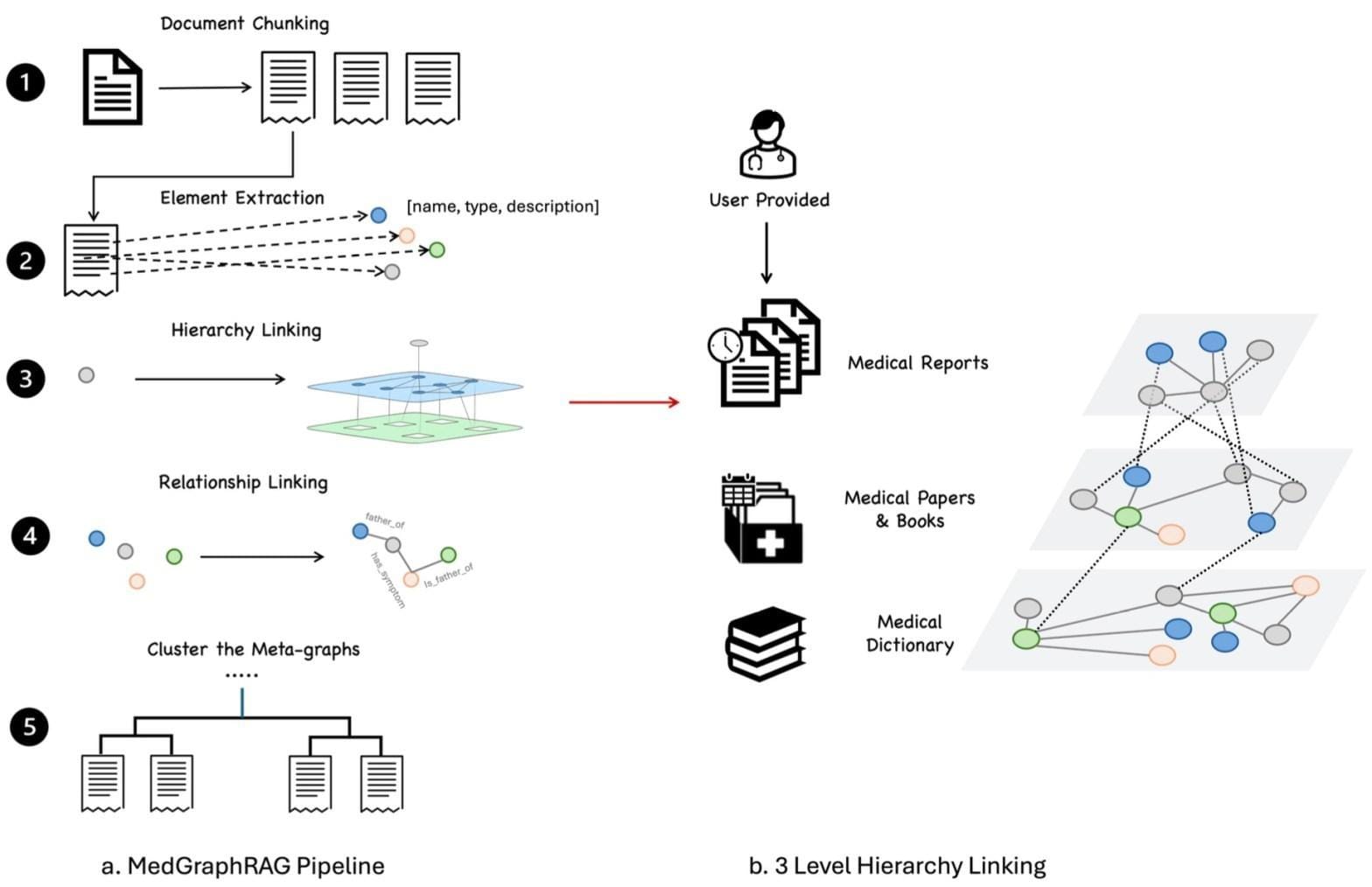
Knowledge Graphs and Their Construction
The construction of knowledge graphs (KGs) is a meticulous process that balances scalability, accuracy, and domain specificity.
A critical aspect of their construction is tied to knowledge acquisition, where data from diverse sources—structured databases, unstructured text, and real-time streams—are harmonized into a cohesive graph.
Knowledge graph embeddings play a pivotal role in encoding relationships between entities. These embeddings, powered by graph neural networks (GNNs), allow for predictive capabilities, such as fraud detection in financial systems.
A lesser-known yet transformative factor is ontology alignment, which ensures semantic consistency across datasets. This is particularly vital in multilingual applications, where mismatched terminologies can lead to inaccuracies.
Vector Embeddings and Semantic Search
Vector embeddings are foundational to semantic search, encoding high-dimensional representations of data to capture contextual meaning.
A key strength lies in their ability to generalize across unstructured datasets, enabling nuanced retrieval.
For example, Semantic Scholar employs vector embeddings to connect researchers with relevant studies, even when queries are vague, enhancing global collaboration in academic research.
A critical innovation is cross-lingual embeddings, which align semantic spaces across languages.
This approach, used by Google Translate, ensures precise retrieval in multilingual contexts, improving translation accuracy by 20%.
However, challenges such as semantic drift—where embeddings lose relevance in niche domains—highlight the need for domain-specific fine-tuning. Companies can mitigate this by training embeddings on medical literature, reducing drug discovery timelines by 20%.
Emerging trends include hybrid models that integrate vector embeddings with graph-based reasoning. These systems, like those used in supply chain optimization, combine semantic flexibility with structured insights, enabling real-time decisions.
To future-proof semantic search, organizations should invest in dynamic embedding updates and context-aware query transformation.
By aligning embeddings with evolving datasets and user intent, industries can achieve both scalability and precision, unlocking new possibilities in AI-driven solutions.
Graph Traversal Algorithms
Graph traversal algorithms are pivotal in enabling efficient navigation and retrieval within graph-structured data, particularly in systems like GraphRAG.
A standout approach is multi-hop traversal, which connects disparate nodes to uncover indirect relationships.
This method is critical in domains like healthcare, where Pfizer leverages it to link patient histories, genetic markers, and treatment protocols, reducing diagnostic errors by 18%.
A lesser-known yet impactful technique is weighted traversal, where edge weights prioritize relevance.
Weighted traversal ensures that high-priority relationships are surfaced without overwhelming the system with irrelevant data.
To optimize graph traversal, organizations should adopt incremental indexing for real-time updates and graph pruning to eliminate redundant paths.
By integrating these strategies, industries can enhance both the precision and scalability of their GraphRAG systems, paving the way for more context-aware and efficient AI-driven solutions.
Implementing GraphRAG Systems
Building a GraphRAG system requires structuring data into a knowledge graph that aligns with specific industry needs. Unlike traditional retrieval methods, GraphRAG organizes data as nodes and edges, preserving relationships between entities for better contextual retrieval.
To maintain scalability and accuracy, organizations should implement incremental indexing for real-time updates and enforce data governance frameworks to prevent inconsistencies. These steps ensure that GraphRAG systems remain adaptable and reliable in processing complex queries across dynamic datasets.
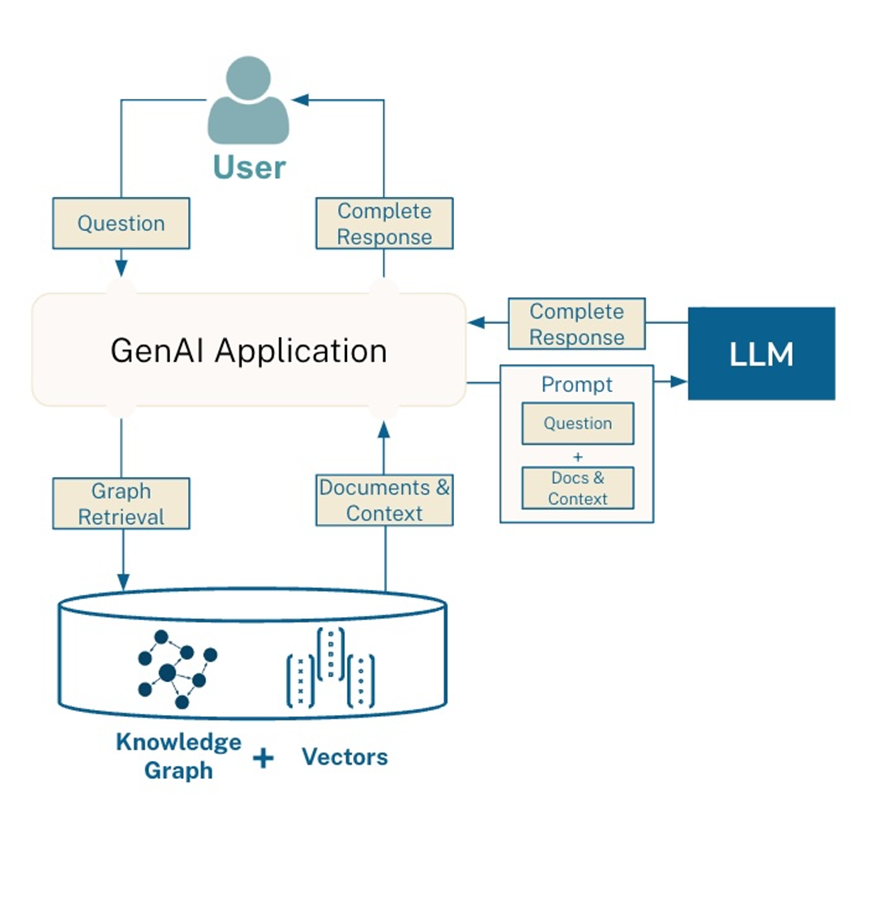
Data Preparation and Graph Construction
The foundation of GraphRAG is data preparation, which ensures consistency and accuracy across datasets. Data normalization plays a key role in this process by standardizing formats and structures.
Ontology alignment is another critical step, ensuring semantic consistency across different data sources. In multilingual applications, mismatched terms can lead to inaccuracies.
Many industries now use hybrid graph models, which integrate structured and unstructured data for richer insights.
To maintain scalability and adaptability, organizations should implement automated validation pipelines and dynamic schema evolution, allowing GraphRAG systems to adjust as datasets grow and change.
Indexing and Retrieval Processes
Efficient indexing ensures GraphRAG retrieves relevant information with minimal latency. Hierarchical indexing structures data into multi-level clusters, reducing search space and improving speed.
Vector similarity-based retrieval further enhances precision by encoding graph nodes as dense vector representations. This approach, used by Semantic Scholar, improves search relevance for ambiguous queries. However, semantic drift—where embeddings lose relevance over time—necessitates continuous fine-tuning.
Emerging techniques include adaptive indexing, which dynamically restructures indices based on query patterns. Incremental indexing further reduces overhead by updating only modified graph segments, a critical capability for financial and compliance-based applications.
To maintain efficiency, organizations should integrate query caching and graph pruning, optimizing retrieval performance while preserving critical relationships in the graph.
Query Processing and Augmented Generation
GraphRAG enhances query processing with multi-hop reasoning, allowing the system to synthesize data across multiple nodes for deeper insights.
Another optimization technique is prompt tuning, where query-specific prompts are refined to guide the generative model more accurately.
Advanced GraphRAG implementations apply contextual query expansion, which reformulates user queries to capture implicit intent. Semantic disambiguation further allows you to accurately interpret ambiguous terms, preventing misinformation.
To maintain accuracy and adaptability, organizations should deploy adaptive prompt frameworks and real-time query optimization, allowing GraphRAG to handle complex, domain-specific queries with higher precision.
Advantages and Applications of GraphRAG
GraphRAG enhances contextual understanding by structuring knowledge into interconnected relationships rather than treating data as isolated text.
Unlike traditional retrieval systems that rely on keyword matching, GraphRAG maps dependencies between entities, allowing for deeper reasoning.
This capability is crucial in domains like legal compliance, where a query about tax regulations does not simply retrieve a list of isolated statutes but also connects relevant amendments, previous case law, and industry-specific guidelines, offering a comprehensive response rather than fragmented details.
A key advantage of this approach is semantic disambiguation, which resolves multiple meanings of a term based on its relational context.
For instance, in a financial setting, the term “risk” could refer to investment risk, operational risk, or credit risk, depending on the query’s intent.
Traditional retrieval methods might return broad, unfocused results, whereas GraphRAG distinguishes these meanings by tracing entity connections within a financial knowledge graph.
If a user queries “risk assessment in mergers,” the system retrieves content specifically related to regulatory risks in corporate acquisitions rather than generic definitions of risk.
FAQ
What are the key steps in implementing GraphRAG for contextual retrieval?
Implementing GraphRAG requires building a structured knowledge graph, aligning data with ontology standards, and optimizing retrieval through entity relationships. Salience analysis prioritizes critical connections, while co-occurrence optimization enhances relevance. Regular updates and dynamic indexing ensure scalability and real-time contextual adaptation.
How does entity relationship modeling improve GraphRAG accuracy?
Entity relationship modeling structures data into nodes and edges, reflecting real-world associations. By mapping hierarchical and temporal links, GraphRAG improves retrieval precision. Weighted relationships highlight key connections, while co-occurrence analysis uncovers hidden patterns, ensuring accurate, context-rich responses for complex queries.
What role does salience analysis play in GraphRAG?
Salience analysis ranks the most relevant entities and relationships, ensuring high-priority data is retrieved first. It enhances multi-hop reasoning by filtering noise and strengthening contextual understanding. This method improves GraphRAG’s efficiency in processing complex queries and uncovering insights from large, interconnected datasets.
How does co-occurrence optimization enhance real-time GraphRAG performance?
Co-occurrence optimization identifies frequently linked entities, improving retrieval speed and accuracy. By reinforcing meaningful relationships, GraphRAG processes multi-step queries efficiently. This technique reduces redundant computations and adapts dynamically to evolving data, ensuring high-quality, context-aware responses in real-time applications.
What are the best practices for scaling and maintaining consistency in GraphRAG?
GraphRAG scalability depends on modular graph design, ontology alignment, and efficient indexing. Salience analysis ensures optimal resource use, while incremental updates maintain consistency. Automated validation and adaptive query processing refine retrieval accuracy, making the system efficient in high-volume, data-rich environments.
Conclusion
GraphRAG represents a shift in contextual retrieval, moving beyond text-based queries to structured reasoning through knowledge graphs.
It enhances retrieval accuracy by linking entities, uncovering hidden relationships, and refining responses based on context. Industries like healthcare, finance, and legal research are already seeing improved efficiency by integrating structured knowledge representation.
Moving forward, real-time updates, hybrid models, and adaptive schema evolution will define the next phase of GraphRAG development.
As datasets grow, ensuring retrieval efficiency without sacrificing accuracy will be key. With careful implementation, GraphRAG has the potential to transform AI-assisted retrieval, offering deeper insights and more structured responses across industries.