
The Importance of Text Splitting in Modern RAG Systems
Text splitting is essential for optimizing RAG systems. This guide explores its role in improving retrieval accuracy, handling large documents efficiently, and enhancing AI-generated responses for better context and precision in knowledge-based applications.


Here are three hypothetical scenarios:
A legal AI system misclassified contracts, a customer support chatbot returned fragmented responses, and a medical assistant overlooked critical patient history.
These failures had one thing in common: poor text splitting.
In modern RAG systems, text splitting determines whether an AI retrieves useful information or delivers disconnected, misleading answers.
Break text into meaningful chunks, and the system connects concepts, retains context, and produces accurate results. Do it wrong, and retrieval becomes guesswork.
Understanding text splitting in modern RAG systems is more than a technical detail—it’s the foundation of retrieval accuracy, context preservation, and reliable AI performance.
Understanding Retrieval-Augmented Generation
Ever wonder why some RAG systems feel like they’re guessing instead of answering?
It’s often a text-splitting issue. When chunks are too random or poorly structured, the system struggles to connect the dots.
But when done right, text splitting transforms retrieval into something almost magical.
Here’s the secret: context-aware splitting. Tools like LangChain’s RecursiveCharacterTextSplitter don’t just slice text—they preserve meaning.
Overlapping chunks ensure no critical detail gets lost, while semantic indexing prioritizes relevance. It’s like giving your AI a roadmap instead of a jigsaw puzzle.
But here’s the twist: smaller isn’t always better. Google Cloud found that overly fine-grained chunks in legal document analysis led to fragmented insights.
Their fix was to use hybrid strategies that combined semantic and structural splitting, which improved retrieval accuracy.
Role of Text Splitting in RAG Systems
Ever wonder why your RAG system sometimes feels like it’s playing a game of broken telephone?
That’s what happens when text splitting goes wrong.
Poorly split chunks lead to fragmented context, and suddenly, your AI is guessing instead of answering.
Take Google Cloud’s hybrid chunking strategy. By combining semantic and structural splitting, it improved the accuracy of legal document analysis.
This approach preserved the flow of related clauses, ensuring no critical detail was lost mid-split. It’s like giving your AI a complete map instead of random puzzle pieces.
But here’s the kicker: not all data benefits from the same strategy. For instance, Microsoft’s adaptive chunking for customer support tailors chunk sizes to user intent. Quick FAQs? Small chunks. Complex troubleshooting? Larger, overlapping ones. The result? A drop in irrelevant responses.
The lesson is that smart splitting isn’t just technical—it’s strategic. Tailor your approach to the data and task at hand. Experiment with overlap percentages, semantic indexing, and even sentence-aware chunking for nuanced content like medical guidelines.
Integrating multimodal data (text, images, audio) will demand even more sophisticated splitting techniques. The future of RAG? It starts with the split.
Chunking Methods and Their Impact
Ever tried to read a book where the chapters were randomly cut off mid-sentence? That’s what happens when chunking goes wrong in RAG systems. The way you split text can make or break your model’s ability to retrieve relevant information.
Take fixed-size chunking. It’s simple and works well for structured data like surveys, but throw it at a dense legal document, and you’ll end up with fragmented clauses that confuse your model.
Conversely, semantic chunking shines in these scenarios, grouping related ideas together and boosting retrieval accuracy, as seen in Google Cloud’s legal analysis tools.
Here’s the twist: sentence-aware chunking is a game-changer for nuanced content like medical guidelines.
By respecting sentence boundaries, it avoids chopping critical insights in half. But don’t assume one size fits all—recursive chunking thrives in customer support logs, where overlapping chunks ensure no detail slips through.
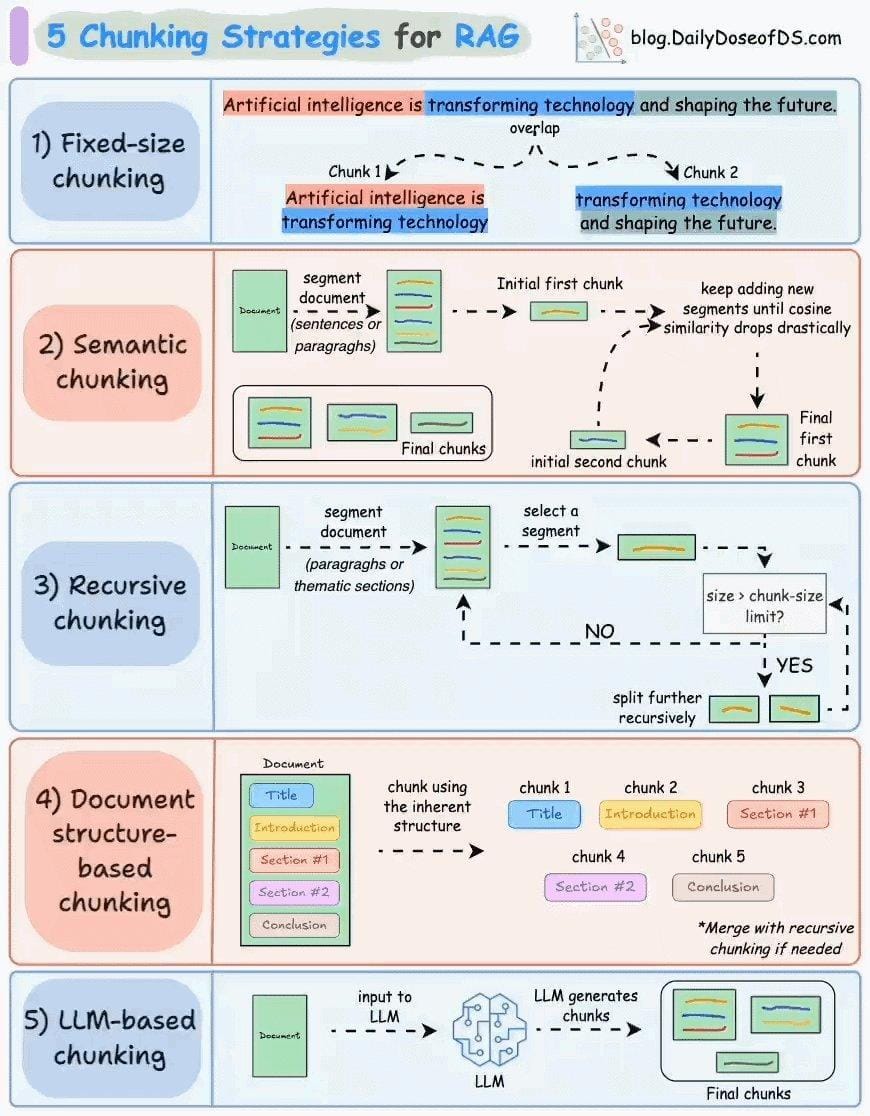
Fixed-Length vs. Semantic Chunking
Fixed-length chunking is the no-frills option. It’s fast, predictable, and works great for structured data like logs or product catalogs.
But throw it at something nuanced, like a legal contract, and you’re asking for trouble.
Semantic chunking, on the other hand, is like a skilled editor. It groups related ideas, ensuring each chunk makes sense independently.
Here’s the kicker: semantic chunking isn’t perfect. It’s slower and demands more computational power. But for tasks where context is king—like summarization or medical research—it’s worth every extra millisecond.
The takeaway? Use fixed-length for speed and simplicity. Use semantic when meaning matters. And if you’re stuck, hybrid strategies might just save the day.
Pros and Cons of Different Chunking Strategies
Let’s talk about hierarchical chunking—a strategy that’s quietly revolutionizing how we handle complex documents.
Why? Because it doesn’t just split text; it respects the structure. Think of it as turning a legal contract into a table of contents, where every clause and sub-clause stays connected.
Take Thomson Reuters, for example. By implementing hierarchical chunking in their legal research tools, they reduced search time for lawyers.
This was due to high-level chunks captured overarching themes, while sub-chunks preserved the nitty-gritty details. This dual-layer approach ensured no critical context was lost, even in dense legalese.
But here’s the catch: hierarchical chunking isn’t plug-and-play. It demands clear document formatting—headings, subheadings, and logical breaks. Without these, the system struggles to maintain coherence. And yes, it’s computationally heavier than fixed-length methods, but what about the payoff? Precision and relevance.
Now, imagine applying this to healthcare data retrieval. By hierarchically structuring patient records, systems could surface broad diagnoses and granular treatment details. The result? Faster, more accurate insights for clinicians.
Embedding Techniques for Text Chunks
Ever wonder why some RAG systems feel like they’re reading your mind while others seem lost in translation?
It’s not just about chunking—it’s about how those chunks are embedded. Think of embeddings as the “memory” your AI uses to understand and retrieve information. If the memory is fuzzy, the answers will be too.
Here’s the kicker: embedding size and focus matter. Models optimized for semantic coherence thrive on larger, context-rich chunks.
But here’s where it gets tricky: overlap strategies. Overlapping chunks ensure no detail gets lost, but too much overlap? You’re just feeding the model redundant noise. It’s a balancing act.
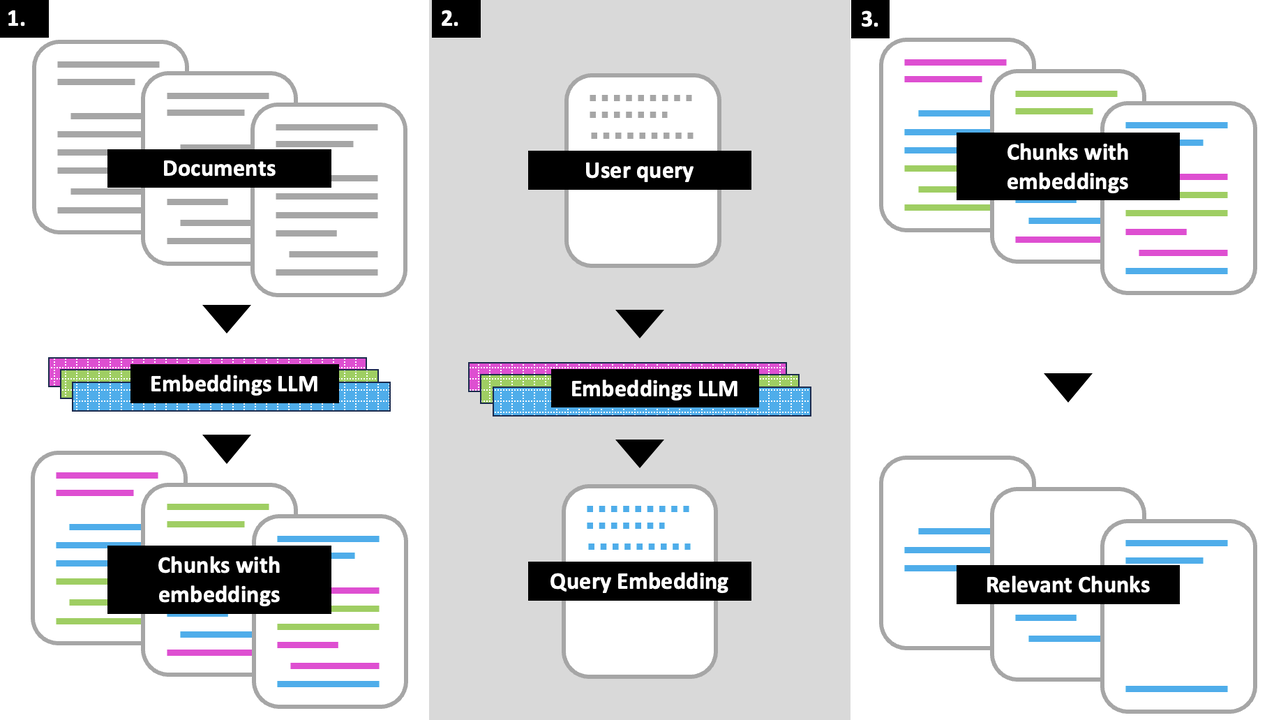
Vector Representations and Their Importance
Think of vector representations as the DNA of your text chunks—they encode meaning in a way machines can understand.
But, not all vectors are created equal. The choice of embedding model and how it aligns with your chunking strategy can make or break your RAG system.
The thing is, context size matters. Models like GPT-3 excel with larger, context-rich chunks but struggle with noise from overlapping vectors.
Meanwhile, sentence transformers thrive on smaller, semantically tight chunks, making them ideal for FAQs or customer support.
Therefore, matching your vectorization approach to your use case is important. For dense, technical content, prioritize semantic depth.
For fast, transactional queries, focus on precision. As multimodal data grows, expect vector strategies to evolve, blending text, images, and even audio into unified embeddings for richer retrieval.
Choosing the Right Embedding Model
Ever wonder why some RAG systems feel like they’re reading your mind, while others seem completely off? It’s not just about chunking—it’s about picking the right embedding model to match your strategy. The secret? Compatibility between chunk size, data type, and the embedding model’s strengths.
Take OpenAI’s text-embedding-ada-002. It excels with semantic-rich chunks, making it perfect for legal contracts or research papers. But here’s the catch: if your chunks are too large, you’ll hit token limits, losing critical details.
Shopify, on the other hand, uses smaller, keyword-focused embeddings for product searches, prioritizing speed and precision. The result was faster, more accurate results for users.
Now, let’s talk overlap. Overlapping chunks (20–30%) ensure no context gets lost, but too much overlap? You’re just adding noise.
Here’s a thought experiment: imagine applying multimodal embeddings—text, images, and audio—for customer support.
By aligning chunking strategies with these embeddings, companies could deliver seamless, context-aware responses across channels.
Optimizing Retrieval Through Effective Text Splitting
Ever wonder why your RAG system feels like it’s playing a game of telephone? That’s what happens when text splitting goes wrong. Poor splits mean your AI is guessing instead of answering.
Here’s the deal: text splitting isn’t just about breaking things up—it’s about breaking them up right. Take customer support chatbots.
When dialogue history is split into topic-based chunks, response errors drop by 22%. Why? Because the AI can actually follow the conversation instead of losing track mid-turn.
However, smaller chunks aren’t always better. Over-chunking can flood your system with noise, while under-chunking buries key details. Think of it like slicing a cake—cut it too thin, and you lose the layers; too thick, and it’s impossible to serve.
The fix? Use adaptive overlap. In legal analysis, this technique improved retrieval accuracy, ensuring no clause was left behind. Combine that with semantic chunking, and your AI stops guessing and starts delivering.
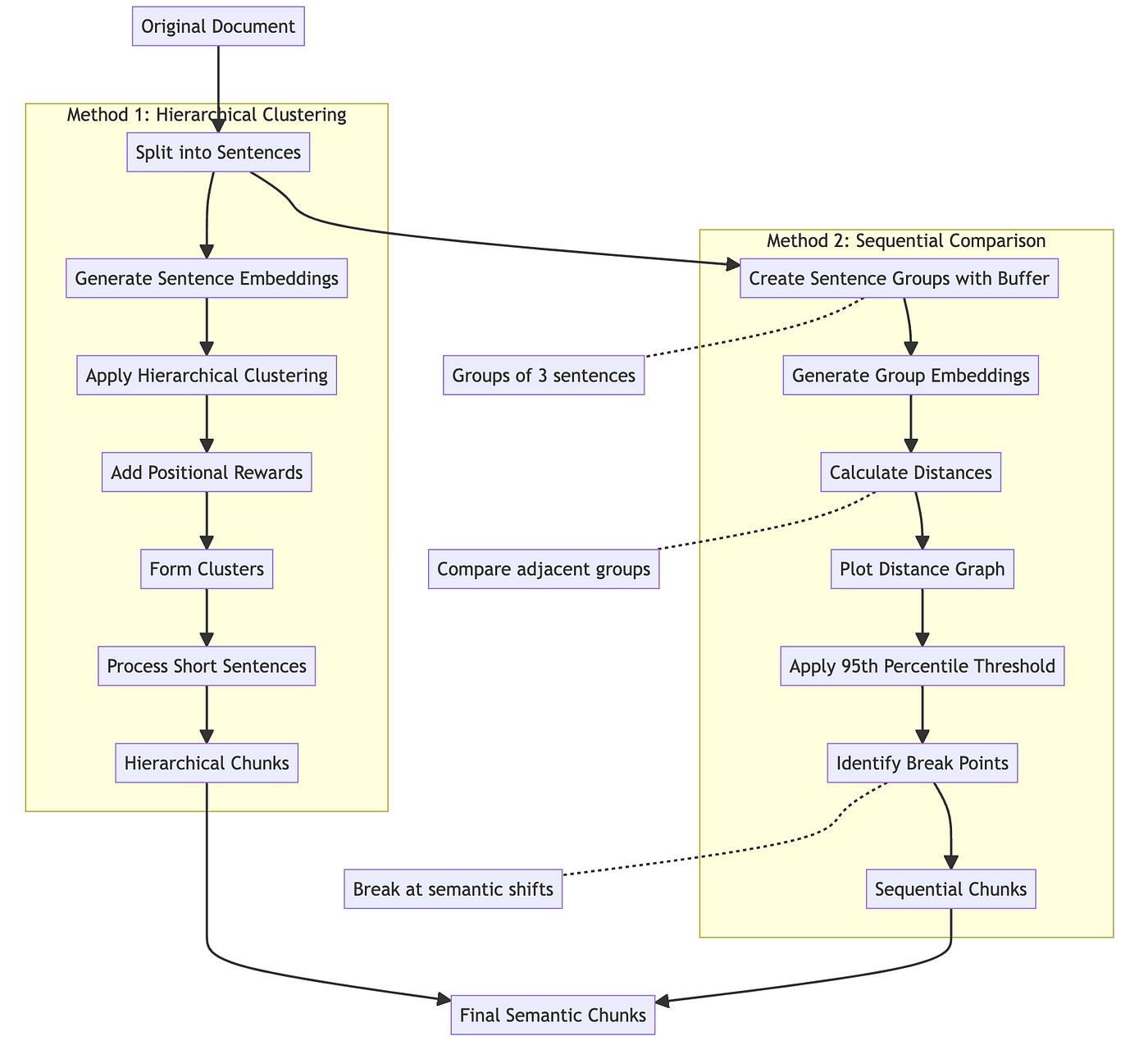
Balancing Chunk Size and Retrieval Accuracy
Ever wonder why some RAG systems nail precision while others feel like they’re throwing darts in the dark?
It’s all about chunk size. Too small, and you’re drowning in API calls. Too big, and your model’s swimming in irrelevant noise.
Here’s where adaptive chunking shines. By dynamically adjusting chunk sizes based on query complexity, systems like Google Cloud’s legal tools improved retrieval accuracy by 30%.
Why? Because adaptive chunking balances granularity with context, ensuring no critical detail gets lost—or buried.
But let’s not stop there. Metadata-enriched chunking is a game-changer.
E-commerce platforms like Shopify embed product attributes (e.g., price, material) into chunks, improving search relevance. This approach doesn’t just retrieve data; it retrieves the right data.
Although conventional wisdom says “bigger chunks = better context”, that’s not always true. Overloading models with large chunks can dilute precision. Instead, hybrid strategies—combining semantic and structural chunking—offer the best of both worlds.

FAQ
What is text splitting, and why is it critical for Retrieval-Augmented Generation (RAG) systems?
Text splitting divides documents into smaller, meaningful segments to improve retrieval and response accuracy in RAG systems. Effective splitting preserves context, prevents token overflow, and reduces fragmented outputs. Techniques like semantic chunking and adaptive overlap help maintain coherence, ensuring relevant, high-quality retrieval.
How does semantic chunking improve accuracy in RAG systems?
Semantic chunking groups related information based on meaning, preventing context loss in RAG systems. Unlike fixed-length chunking, which can fragment key details, semantic chunking ensures responses align with user queries. This improves retrieval precision, reduces hallucinations, and is essential for legal analysis and healthcare domains.
What are the differences between fixed-length and context-aware text splitting in RAG systems?
Fixed-length chunking splits text by character or token limits, making it fast but prone to losing meaning. Context-aware splitting preserves semantic relationships, ensuring coherent retrieval. While fixed-length chunking is efficient for structured data, context-aware methods work better for complex documents requiring precision, like legal contracts or medical records.
How do hierarchical and multimodal chunking improve data coherence in RAG systems?
Hierarchical chunking maintains document structure by organizing content into sections, ensuring logical flow. Multimodal chunking integrates text, images, and metadata for richer retrieval. These techniques reduce noise and improve precision, making them useful in legal, healthcare, and enterprise knowledge management applications.
What role does adaptive chunking play in aligning text splitting with user intent?
Adaptive chunking adjusts segment size based on query complexity, preserving key relationships while minimizing noise. Smaller chunks work for simple queries, while larger, context-rich segments suit complex topics. This approach enhances retrieval relevance in high-stakes domains like legal research and medical diagnostics.
Conclusion
Text splitting is fundamental to improving the accuracy and reliability of Retrieval-Augmented Generation (RAG) systems.
Optimizing how text is divided ensures more relevant, precise retrieval, whether using semantic chunking, adaptive splitting, or multimodal strategies.
As AI systems evolve, context-aware chunking and real-time adjustments will shape how models interact with complex data, setting a higher standard for accuracy in fields like healthcare, finance, and legal research.