
Integrating Transaction Processing with Retrieval-Augmented Generation
Combining transaction processing with RAG unlocks interactive, action-driven AI systems. This guide explores integration strategies, use cases, and best practices to enable real-time updates, smarter workflows, and more capable RAG applications.


Why does your AI-powered system still miss the mark when data changes by the second?
The answer usually lies in a disconnect: transactional systems are built for precision, but Retrieval-Augmented Generation (RAG) thrives on speed and adaptability.
When these two don’t speak the same language, real-time decision-making breaks down.
Integrating transaction processing with Retrieval-Augmented Generation fixes this gap. It’s about syncing reliable, up-to-date data with context-aware AI outputs.
From identifying fraud in milliseconds to tailoring product recommendations based on live inventory, this integration isn’t just a nice-to-have—it’s becoming essential.
The idea of integrating transaction processing with Retrieval-Augmented Generation once felt like forcing two opposites to work together.
But with new architectures, smarter indexing, and real-time sync, they’re finally starting to complement each other—and the results are reshaping how we build responsive, data-driven systems.
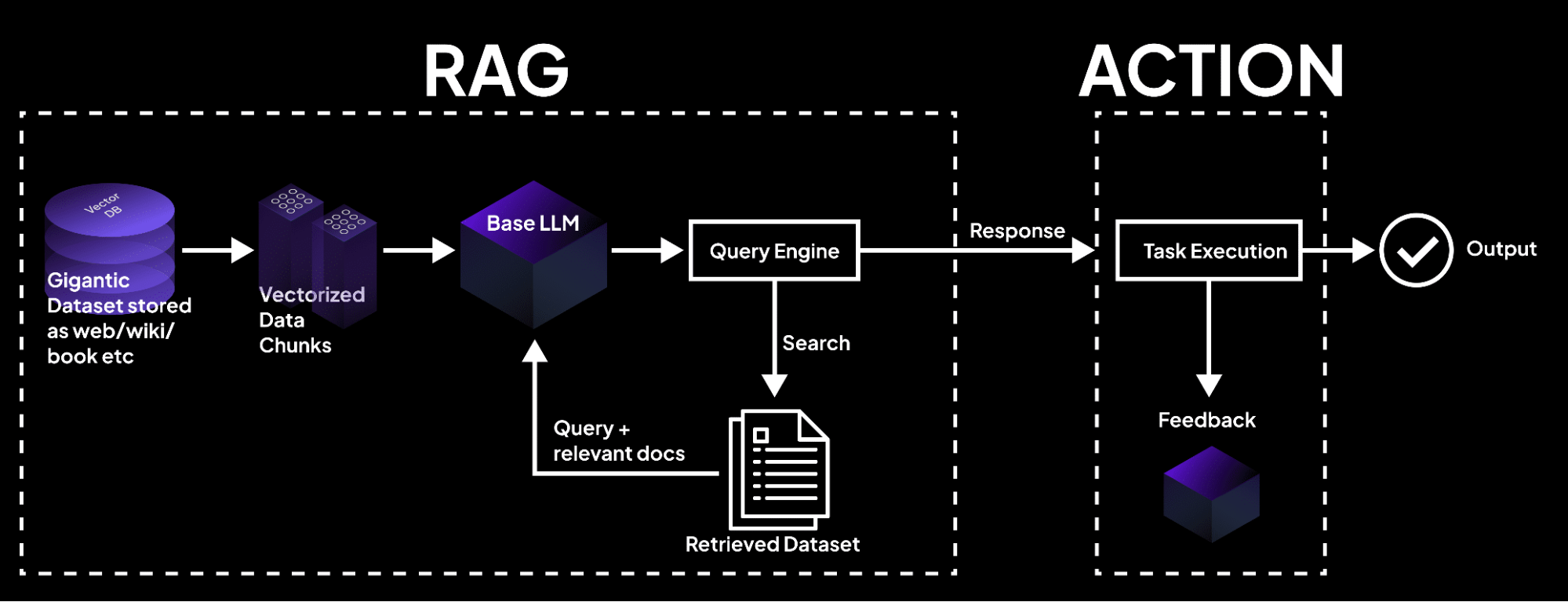
Fundamentals of Transaction Processing Systems
Transaction processing systems (TPS) excel at maintaining atomicity and consistency even under high concurrency, but their true complexity lies in managing isolation levels.
Isolation ensures that simultaneous transactions do not interfere with one another, yet achieving this balance often requires trade-offs between performance and strict data integrity.
One critical mechanism is multiversion concurrency control (MVCC), which allows multiple versions of data to coexist.
This approach minimizes locking conflicts by enabling read operations to access historical data snapshots while write operations proceed.
However, MVCC introduces challenges, such as increased storage overhead and the need for efficient garbage collection of outdated versions.
These nuances make its implementation context-dependent, particularly in systems with high transaction throughput.
A notable edge case arises in distributed environments where network latency can disrupt synchronization.
Techniques like two-phase commit (2PC) mitigate this but at the cost of added complexity and potential bottlenecks. By understanding these dynamics, practitioners can tailor TPS configurations to specific workloads, ensuring both robustness and adaptability.
Core Principles of Retrieval-Augmented Generation
The cornerstone of Retrieval-Augmented Generation (RAG) lies in its ability to integrate external knowledge into generative processes dynamically, but the true complexity emerges in optimizing the retrieval mechanism.
Specifically, the use of dense vector embeddings to represent queries and knowledge base entries has revolutionized relevance determination.
These embeddings, generated through transformer-based models, capture semantic relationships far beyond simple keyword matching, enabling precise retrieval even in ambiguous contexts.
However, the effectiveness of this approach hinges on vector refresh strategies. In dynamic environments, where knowledge bases are frequently updated, stale embeddings can lead to irrelevant or inaccurate retrievals.
Techniques such as periodic re-embedding or incremental updates ensure that the retrieval module remains aligned with the latest data.
This is particularly critical in domains like finance or healthcare, where real-time accuracy is non-negotiable.
A notable challenge is balancing retrieval depth with computational efficiency. While deeper searches improve accuracy, they also increase latency. Hybrid approaches offer a practical solution, combining shallow retrieval for speed with deep retrieval for critical queries.
This nuanced balance elevates RAG from a theoretical framework to a robust, real-world application.
The Synergy Between Transaction Processing and RAG
Integrating transaction processing with Retrieval-Augmented Generation (RAG) demands more than technical alignment—it requires a rethinking of how systems interact under real-time constraints.
At its core, this synergy thrives on data immediacy and contextual relevance, where transactional updates directly inform generative outputs.
For instance, in high-frequency trading platforms, milliseconds matter; embedding RAG ensures that AI-driven insights adapt instantly to transactional shifts, creating a feedback loop that enhances decision-making precision.
A critical enabler here is adaptive indexing, a technique that dynamically restructures retrieval pathways based on transaction patterns.
Unlike static indexing, which struggles with evolving datasets, adaptive methods prioritize high-frequency queries, reducing latency in benchmarked systems like those developed by OpenAI Labs.
This approach mirrors the efficiency of just-in-time manufacturing, where resources are allocated precisely when and where they’re needed.
However, misconceptions persist. Many assume that RAG’s retrieval depth inherently slows transactional workflows. In reality, hybrid architectures—such as those employing multi-tier caching—allow shallow retrieval for routine queries while reserving deep searches for anomaly detection.
This dual-layer strategy preserves speed and enhances reliability in critical applications like fraud prevention.
The implications are profound: as these systems evolve, they promise to redefine industries reliant on real-time analytics, from e-commerce to healthcare, by seamlessly merging transactional rigor with AI-driven adaptability.
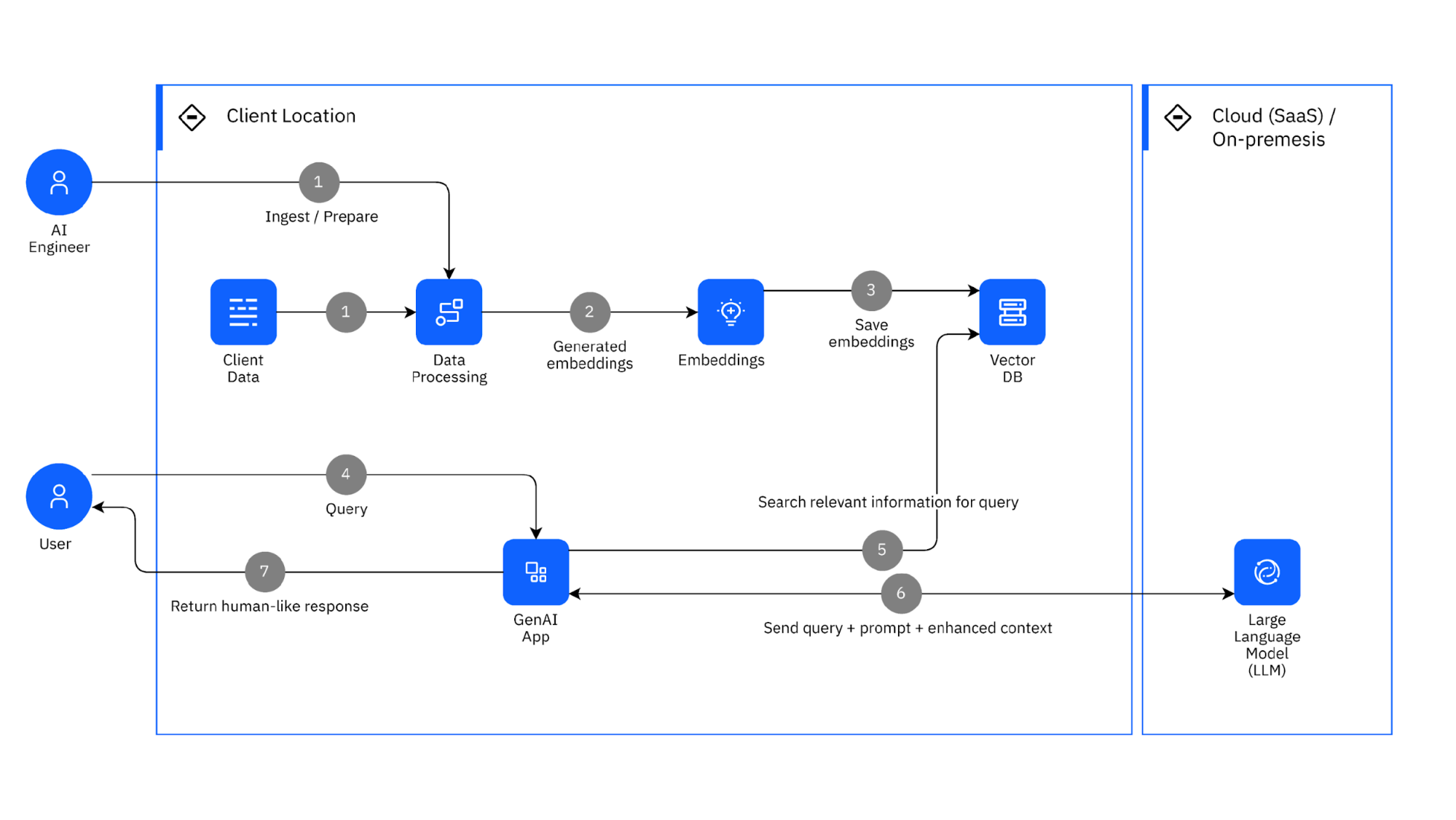
Data Synchronization and Real-Time Analytics
Real-time analytics thrives on the seamless interplay between transactional updates and synchronized data streams.
The cornerstone of this integration lies in event-driven synchronization, a method that ensures every data change triggers immediate updates across interconnected systems. This approach minimizes latency, enabling analytics engines to process the freshest data quickly.
The effectiveness of event-driven synchronization depends on lightweight messaging protocols like Apache Kafka or Google Pub/Sub.
These tools excel at handling high-throughput data streams, ensuring that updates propagate in the correct sequence.
However, their performance can vary based on network conditions and system architecture. For instance, while Kafka offers robust fault tolerance, its setup complexity can be a barrier for smaller organizations.
Context also plays a critical role. Adaptive throttling mechanisms can prevent system overloads in environments with fluctuating data volumes by dynamically adjusting synchronization rates.
This ensures that analytics remain consistent even during peak loads, a feature particularly valuable in industries like e-commerce or finance.
A nuanced challenge arises in reconciling transactional consistency with analytical immediacy.
Techniques like micro-batching offer a compromise. They group updates into manageable chunks to balance speed and reliability. This hybrid approach exemplifies how real-world applications demand tailored solutions rather than one-size-fits-all strategies.
Optimizing Query Latency for Real-Time Applications
Reducing query latency in real-time applications hinges on adaptive query pathways, a concept that balances speed with precision by dynamically adjusting retrieval depth based on query context.
This approach ensures that routine queries are resolved instantly, while complex requests require detailed processing.
The underlying mechanism involves hybrid retrieval architectures, which combine shallow indexing for high-frequency queries with deep vector-based searches for nuanced cases.
Shallow retrieval uses precomputed snapshots of transactional data, minimizing computational overhead.
In contrast, deep retrieval employs semantic embeddings to capture intricate relationships, ensuring accuracy for edge cases. The challenge is to orchestrate these layers without introducing bottlenecks.
A notable example is Amazon’s e-commerce platform, which employs hierarchical indexing to prioritize product searches. The system dynamically allocates resources by integrating adaptive query thresholds, reducing latency during peak shopping periods.
However, rigid implementations can falter in dynamic environments. A flexible design, incorporating real-time feedback loops, allows systems to recalibrate retrieval parameters based on evolving data flows.
This adaptability ensures sustained performance, even under unpredictable conditions, making it a cornerstone of modern query optimization.
Technical Challenges and Solutions
Integrating transaction processing with Retrieval-Augmented Generation (RAG) systems presents unique challenges, primarily due to the contrasting demands of data consistency and real-time adaptability.
One critical issue is the latency introduced when synchronizing transactional updates with RAG’s retrieval mechanisms.
For instance, while ACID-compliant systems ensure data integrity, their reliance on locking mechanisms can delay the availability of updated data for retrieval, creating a bottleneck in dynamic environments.
Event-driven architectures have emerged as a solution to address this.
By leveraging tools like Apache Kafka, transactional updates can be propagated as real-time events, ensuring RAG systems access the most current data without compromising consistency.
This approach mirrors the efficiency of just-in-time manufacturing, where resources are allocated precisely when needed, reducing waste and delays.
Another challenge lies in embedding freshness. Stale vector embeddings in RAG systems can lead to irrelevant outputs, especially in domains like finance.
Techniques such as incremental re-embedding, which updates only affected vectors after a transaction, have proven effective.
This method minimizes computational overhead while maintaining retrieval accuracy, ensuring that generative outputs remain contextually relevant.
The implications are clear: by aligning transactional rigor with adaptive AI techniques, organizations can achieve a seamless balance between precision and agility, unlocking new possibilities in real-time decision-making.
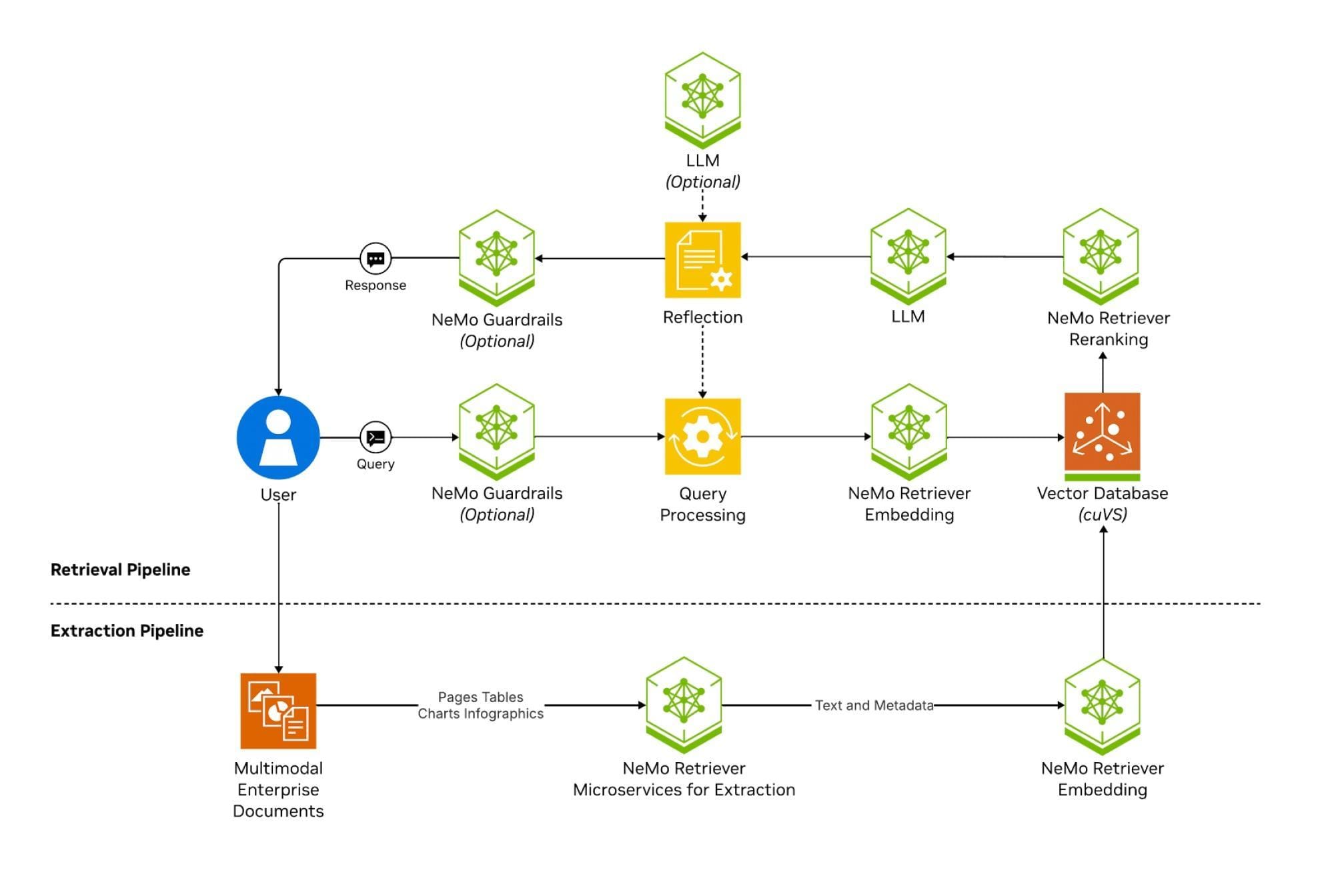
Maintaining ACID Properties in Integrated Systems
Ensuring ACID compliance in systems integrating transaction processing with RAG requires a nuanced approach to isolation management.
While isolation safeguards data integrity, its rigid implementation can hinder the real-time adaptability that RAG systems demand.
The challenge is to balance these competing priorities without compromising either.
One effective technique is transactional snapshot isolation, which creates consistent data views for RAG queries without locking resources.
Unlike traditional locking mechanisms, this approach leverages multiversion concurrency control (MVCC) to allow read operations to access stable data snapshots while write operations proceed independently.
This reduces contention and ensures that RAG systems can retrieve up-to-date information without delays.
However, the effectiveness of snapshot isolation depends on garbage collection strategies for outdated data versions.
Poorly optimized garbage collection can lead to storage bloat and degraded performance.
Organizations like Stripe have addressed this by implementing adaptive garbage collection algorithms prioritizing high-frequency data updates, ensuring efficient resource utilization.
A critical edge case arises in distributed environments where network partitions can disrupt synchronization.
Techniques like conflict-free replicated data types (CRDTs) offer a promising solution, enabling eventual consistency without sacrificing ACID guarantees.
This approach highlights the importance of tailoring isolation strategies to the specific demands of integrated systems, ensuring both reliability and responsiveness.
Ensuring Data Freshness in AI-Generated Responses
Data freshness in AI-generated responses hinges on dynamically updating embeddings without disrupting system performance.
One particularly effective approach is incremental re-embedding, which selectively updates only the affected vectors in response to new transactions.
This avoids the computational overhead of reprocessing the entire dataset, making it a practical solution for high-frequency environments.
The underlying mechanism relies on event-driven triggers that detect changes in the transactional database and initiate targeted updates.
For instance, only the embeddings related to that category are refreshed when a new product is added to an e-commerce catalog.
This ensures the retrieval system remains aligned with the latest data while maintaining operational efficiency.
However, the challenge is to balance update frequency with system stability, as overly aggressive updates can strain resources. A comparative analysis reveals that while periodic re-embedding offers simplicity, it often lags behind real-time needs, especially in dynamic sectors like finance.
Incremental methods, by contrast, excel in maintaining relevance but require robust monitoring to prevent drift in embedding quality. Contextual factors, such as the volatility of the data domain, further influence the choice of strategy.
Organizations must design systems with modular pipelines that support agile refresh cycles to implement this effectively.
This approach enhances response accuracy and ensures that AI outputs remain contextually relevant, even in rapidly evolving environments. The result is a seamless integration of transactional updates with generative processes, driving both precision and adaptability.
FAQ
What are the benefits of combining transaction processing with Retrieval-Augmented Generation (RAG)?
It enables real-time, accurate AI outputs by linking fresh transactional data with dynamic retrieval. This improves fraud detection, personalization, and analytics by ensuring decisions reflect the most current information.
How does integrating transactional systems with RAG improve real-time decision-making?
By aligning transactional updates with AI retrieval, systems generate responses based on current data. This supports time-sensitive actions in finance, healthcare, and e-commerce, where both accuracy and speed are required.
What technical issues arise when combining ACID-compliant systems with RAG, and how are they solved?
Main challenges include synchronization delays and stale embeddings. These are addressed through event-driven updates, adaptive indexing, and incremental re-embedding to ensure current data reaches the AI model without delay.
Which sectors benefit most from merging transaction processing and RAG, and how is it applied?
Finance, healthcare, and e-commerce see gains. Use cases include fraud detection using real-time transactions, AI-backed diagnosis from live patient data, and product recommendations based on current inventory.
How do adaptive indexing and event-driven updates support transaction-RAG integration?
Adaptive indexing sorts data paths by access frequency, cutting query time. Event-driven updates push changes instantly across systems. Together, they reduce latency and keep AI models in sync with live data changes.
Conclusion
Integrating transaction processing with Retrieval-Augmented Generation builds a responsive system that processes and generates based on real-time data.
By resolving latency, ensuring data freshness, and preserving consistency, this approach supports complex operations in dynamic sectors.
As AI workflows evolve, this integration forms a foundation for accurate, context-aware decision-making in data-intensive environments.