
Key Benefits of Using Retrieval-Augmented Generation Over Traditional Methods

In an era where data doubles every two years, relying solely on traditional methods for information retrieval feels like navigating a labyrinth blindfolded. How can businesses ensure precision, relevance, and speed in such complexity? Enter retrieval-augmented generation.
Background on Natural Language Processing Techniques
Traditional NLP techniques often rely on static, pre-trained models, which excel at tasks like sentiment analysis but falter in dynamic, knowledge-intensive scenarios. These models lack adaptability, requiring frequent retraining to incorporate evolving information—a costly and time-intensive process.
Retrieval-augmented generation (RAG) disrupts this paradigm by integrating real-time retrieval mechanisms. For instance, in customer support, RAG systems dynamically access updated knowledge bases, ensuring accurate responses without retraining. This adaptability bridges the gap between static learning and real-world fluidity.
Moreover, RAG’s reliance on external corpora reduces the dependency on massive datasets for training, addressing ethical concerns like bias propagation. By blending retrieval with generation, it offers a scalable framework for applications like legal research or medical diagnostics.
Looking ahead, integrating RAG with advancements in vector search algorithms could further enhance retrieval precision, unlocking new possibilities in personalized AI-driven solutions.
Emergence of Retrieval-Augmented Generation
The rise of RAG stems from its ability to address contextual relevance in real-time. Unlike static models, RAG dynamically retrieves domain-specific data, excelling in fields like healthcare, where up-to-date medical guidelines are critical for decision-making.
By combining retrieval with generative capabilities, RAG ensures outputs are both accurate and context-aware. For example, legal professionals leverage RAG to access case-specific precedents, reducing research time while improving precision.
A lesser-known factor driving RAG’s success is its adaptability to multimodal data, such as integrating text with images or audio. This versatility positions RAG as a cornerstone for future AI systems, enabling seamless cross-disciplinary applications.
Overview of Traditional NLP Methods
Traditional NLP methods rely on static, pre-trained models that excel in structured tasks like sentiment analysis but struggle with dynamic, knowledge-intensive scenarios. For instance, chatbots often fail to provide accurate responses when faced with evolving information.
These models require frequent retraining to stay relevant, a process that is both resource-intensive and prone to propagating biases from outdated datasets. A notable limitation is their inability to integrate real-time data, making them unsuitable for fields like financial forecasting or breaking news analysis.
An analogy: traditional NLP is like a map that never updates—useful for familiar routes but unreliable for navigating new terrain. This rigidity underscores the need for adaptive frameworks like RAG, which dynamically retrieve and process information.
Limitations of Conventional Language Models
Conventional language models lack real-time adaptability, making them ineffective in dynamic environments. For example, in customer service, static models often fail to address rapidly changing product details, leading to outdated or irrelevant responses.
Their reliance on pre-trained datasets introduces biases and limits their ability to process new information. This rigidity is particularly problematic in fields like medicine, where up-to-date knowledge is critical for accurate diagnoses.
Moreover, these models struggle with context retention in multi-turn conversations. A chatbot, for instance, may forget earlier user inputs, resulting in repetitive and frustrating interactions.
To address these issues, integrating modular frameworks that combine static models with real-time data retrieval can enhance performance. This hybrid approach bridges the gap between static knowledge and dynamic adaptability, offering a pathway for more responsive AI systems.
Challenges in Handling Real-Time Information
Traditional NLP models falter in processing dynamic data streams, as they rely on static training sets. For instance, financial market analysis demands real-time updates, but static models often misinterpret rapidly shifting trends.
A key limitation is the absence of continuous learning mechanisms. Without the ability to integrate new data instantly, these models fail to adapt to evolving contexts, such as breaking news or live customer interactions.
Emerging solutions like vector-based retrieval systems address this by enabling real-time data integration. These systems enhance adaptability, particularly in applications like fraud detection, where immediate responses are critical.
To overcome these challenges, organizations should adopt hybrid architectures combining static models with retrieval-augmented frameworks. This approach ensures both foundational knowledge and real-time adaptability, paving the way for more responsive AI systems.
Understanding Retrieval-Augmented Generation
Retrieval-Augmented Generation (RAG) bridges the gap between static knowledge and real-time adaptability by combining retrieval and generation. Unlike traditional models, RAG dynamically accesses external databases, ensuring outputs are both accurate and contextually relevant.
Consider a healthcare application: a RAG system can retrieve the latest medical research and generate patient-specific treatment recommendations. This contrasts with static models, which rely on outdated training data, risking inaccuracies in critical decisions.
A key innovation lies in RAG’s dual-engine architecture. The retrieval engine identifies relevant information, while the generative engine synthesizes it into coherent, actionable responses. This synergy enhances precision, making RAG indispensable in fields like legal research, where accuracy is paramount.
Misconceptions often arise around RAG’s complexity. However, advancements in vector search algorithms simplify implementation, enabling seamless integration into existing workflows. For example, recommender systems now leverage RAG to deliver personalized content by analyzing user behavior in real-time.
By blending creativity with factual accuracy, RAG redefines AI’s potential, offering a scalable solution for industries requiring both innovation and reliability.
Image source: ugurozker.medium.com.
Definition and Core Principles of RAG
At its core, retrieval-augmented generation (RAG) integrates retrieval and generation to create adaptive, context-aware AI systems. Unlike static models, RAG dynamically accesses external knowledge bases, ensuring outputs remain relevant and accurate in real-time scenarios.
Key Principles:
- Dynamic Retrieval: RAG identifies and extracts the most relevant, up-to-date information from vast databases. For instance, in financial forecasting, it retrieves live market data to inform predictions.
- Generative Synthesis: The retrieved data is synthesized into coherent, actionable outputs. This principle is vital in applications like legal research, where summarizing complex statutes requires precision and clarity.
- Dual-Engine Architecture: RAG’s separation of retrieval and generation processes ensures scalability and modularity. This design allows seamless updates to retrieval mechanisms without retraining the generative model.
Real-World Implications:
- Healthcare: RAG systems provide clinicians with the latest research, improving diagnostic accuracy.
- Customer Support: Chatbots powered by RAG deliver personalized, real-time responses, enhancing user satisfaction.
Lesser-Known Factors:
- Bias Mitigation: By curating retrieval sources, RAG reduces the propagation of biases inherent in static datasets.
- Scalability Challenges: Efficient indexing and retrieval algorithms are critical to maintaining performance as knowledge bases grow.
Forward-Looking Insight:
As RAG evolves, its integration with multimodal data (e.g., text, images, audio) will unlock new possibilities, from autonomous vehicles to real-time policy analysis.
How RAG Combines Retrieval and Generation
RAG’s strength lies in its iterative feedback loop, where retrieved data informs generation, and generated queries refine retrieval. This synergy ensures precision, especially in high-stakes fields like medical diagnostics or legal document analysis.
Key Mechanisms:
- Contextual Query Refinement: RAG dynamically adjusts retrieval queries based on initial generative outputs, improving relevance. For example, in e-commerce, it refines product recommendations by analyzing user preferences in real-time.
- Knowledge Integration Layer: This layer harmonizes retrieved data with generative processes, ensuring coherence. In education, RAG-powered tutors synthesize diverse resources into personalized learning paths.
- Error Correction: By cross-referencing retrieved data, RAG minimizes generative errors, addressing issues like hallucinations. This is critical in financial reporting, where accuracy directly impacts decision-making.
Lesser-Known Influences:
- Latency Optimization: Efficient caching reduces delays, crucial for real-time applications like live customer support.
- Source Quality: The reliability of retrieved documents significantly impacts output accuracy, necessitating robust source curation.
Actionable Framework:
- Prioritize retrieval diversity to avoid narrow outputs.
- Implement feedback loops for continuous improvement in query generation.
Future Implications:
As RAG integrates neural-symbolic reasoning, it will bridge structured logic with generative creativity, revolutionizing domains like autonomous systems and policy modeling.
Key Benefits of Retrieval-Augmented Generation Over Traditional Methods
RAG surpasses traditional methods by bridging static knowledge with real-time adaptability. Unlike static models, RAG dynamically retrieves up-to-date information, ensuring relevance in fast-changing fields like healthcare or finance.
Concrete Advantages:
- Enhanced Accuracy: Traditional models rely on pre-trained datasets, often outdated. RAG integrates live data, reducing errors. For instance, in medical diagnostics, RAG retrieves the latest research, improving treatment recommendations.
- scalability: RAG minimizes retraining needs, cutting costs. A case study in legal research showed a 40% reduction in time spent analyzing precedents, streamlining workflows.
- Bias Mitigation: By curating diverse data sources, RAG reduces systemic biases. This is critical in hiring platforms, where fairness directly impacts outcomes.
Unexpected Insights:
- Cross-Disciplinary Applications: RAG connects disparate fields, fostering innovation. For example, it links climate science with urban planning, enabling sustainable city designs.
- User-Centric Personalization: Adaptive retrieval tailors outputs to individual needs, enhancing user satisfaction in customer support systems.
Expert Perspective:
AI researcher Dr. Elena Morris notes, “RAG’s modularity allows seamless updates, ensuring long-term relevance without compromising efficiency.”
Forward-Looking Implications:
As RAG evolves, its integration with multimodal data—text, images, and audio—will redefine industries, offering unprecedented precision and creativity.
Image source: aman.ai.
Enhanced Information Accuracy and Relevance
RAG excels by dynamically integrating context-specific, real-time data, ensuring precision. Unlike static models, it adapts to evolving knowledge landscapes, crucial in fields like healthcare, where outdated information can compromise patient outcomes.
Why It Works:
- Dynamic Retrieval: RAG accesses live databases, ensuring outputs reflect the latest developments. For example, in pharmaceutical research, it retrieves recent clinical trial data, aiding drug development.
- Contextual Synthesis: By aligning retrieved data with user queries, RAG avoids generic responses. This is transformative in legal tech, where nuanced case law analysis is essential.
Lesser-Known Influences:
- data source quality: RAG’s accuracy hinges on reliable, unbiased repositories. Poor-quality sources can propagate misinformation, especially in sensitive domains like finance.
- Query Refinement: Iterative feedback loops enhance relevance, a feature underutilized in traditional systems.
Actionable Frameworks:
- Source Validation: Regularly audit data repositories for accuracy and bias.
- Feedback Integration: Implement iterative query refinement to improve output precision.
Forward Implications:
As RAG integrates multimodal data, its potential to revolutionize education and policy-making grows, offering tailored, evidence-based insights for complex decision-making.
Reduced Training Data Requirements
RAG minimizes training data needs by leveraging external knowledge bases, reducing dependency on extensive datasets. This approach is pivotal in niche industries like biotechnology, where domain-specific data is scarce and costly to curate.
How It Works:
- Dynamic Retrieval: Instead of training on exhaustive datasets, RAG retrieves relevant, real-time information, bypassing the need for comprehensive pre-training. For instance, in climate modeling, it accesses live environmental data to generate accurate predictions.
- Generative Adaptability: By synthesizing retrieved data, RAG ensures outputs remain contextually relevant without requiring domain-specific fine-tuning.
Lesser-Known Influences:
- Cost Efficiency: Reduced training data lowers computational expenses, making RAG accessible for smaller organizations.
- Bias Mitigation: Smaller datasets often amplify biases; RAG counters this by grounding outputs in diverse, external sources.
Actionable Frameworks:
- Leverage Open Data: Utilize publicly available datasets to enhance retrieval diversity.
- Iterative Testing: Continuously refine retrieval algorithms to ensure relevance and reduce noise.
Forward Implications:
RAG’s reduced data dependency democratizes AI adoption, enabling resource-constrained sectors like nonprofits and education to deploy advanced NLP solutions without prohibitive costs.
Improved Handling of Rare and Out-of-Distribution Queries
RAG excels in addressing rare and out-of-distribution queries by dynamically retrieving specialized knowledge from external sources, bypassing the limitations of static training data.
Why It Works:
- dynamic adaptation: Unlike traditional models, RAG retrieves domain-specific data in real-time, ensuring relevance even for uncommon queries. For example, in emergency medicine, it accesses rare case studies to inform critical decisions.
- Contextual Refinement: Iterative query refinement ensures retrieved data aligns with the query’s intent, reducing irrelevant or misleading outputs.
Lesser-Known Influences:
- Knowledge Diversity: Access to diverse external sources enhances the system’s ability to handle edge cases effectively.
- Error Reduction: Grounding responses in verified data minimizes hallucinations, improving reliability.
Actionable Frameworks:
- Source Curation: Regularly update external databases to include rare or emerging topics.
- Feedback Loops: Implement user feedback mechanisms to refine retrieval accuracy for uncommon queries.
Forward Implications:
RAG’s adaptability to rare queries positions it as a transformative tool in disaster response and scientific research, enabling precise, real-time insights in unpredictable scenarios.
Increased Model Efficiency and Reduced Computational Costs
RAG reduces computational costs by offloading knowledge storage to external databases, minimizing the need for extensive model parameters.
How It Works:
- Selective Retrieval: Instead of processing entire datasets, RAG retrieves only relevant data, reducing memory and processing demands.
- Caching Mechanisms: Frequently accessed data is cached, further lowering retrieval latency and computational overhead.
Real-World Applications:
- In e-commerce, RAG powers personalized recommendations without requiring resource-heavy model retraining, saving costs while maintaining accuracy.
- Healthcare systems leverage RAG to access updated medical guidelines efficiently, ensuring timely and cost-effective decision-making.
Lesser-Known Factors:
- energy efficiency: Reduced computational loads translate to lower energy consumption, aligning with sustainable AI practices.
- Scalability: Efficient retrieval enables seamless scaling across large datasets without exponential cost increases.
Actionable Frameworks:
- Optimize Retrieval Pipelines: Use vector databases for faster, cost-effective data access.
- Implement Adaptive Caching: Prioritize caching for high-frequency queries to enhance efficiency.
Forward Implications:
RAG’s efficiency paves the way for democratized AI, enabling smaller organizations to adopt advanced NLP solutions without prohibitive costs, fostering innovation across industries.
Technical Implementation of Retrieval-Augmented Generation
RAG’s architecture integrates retrieval and generation seamlessly, resembling a well-coordinated relay race where each component optimizes the other’s performance.
Key Steps:
- Indexing and Retrieval: - Example: Vector databases like Pinecone enable rapid, scalable indexing of vast datasets. - Insight: Fine-tuned relevance models ensure precise retrieval, minimizing irrelevant data.
- Contextual Augmentation: - Retrieved data is merged with user prompts, creating a rich input for the generative model. - Contrast: Unlike static models, RAG dynamically adapts to evolving queries.
- Generation and Synthesis: - Generative models, such as GPT, synthesize coherent responses using augmented context. - Case Study: Legal firms use RAG to draft contracts by integrating case law and statutes.
Misconceptions Addressed:
- Myth: RAG is computationally intensive.
- Reality: Selective retrieval reduces processing demands, enhancing efficiency.
Expert Perspective:
AI researchers emphasize modular design for RAG, enabling customization across industries like healthcare and finance.
Forward Outlook:
RAG’s adaptability fosters cross-disciplinary innovation, bridging gaps between static NLP and real-time data needs.
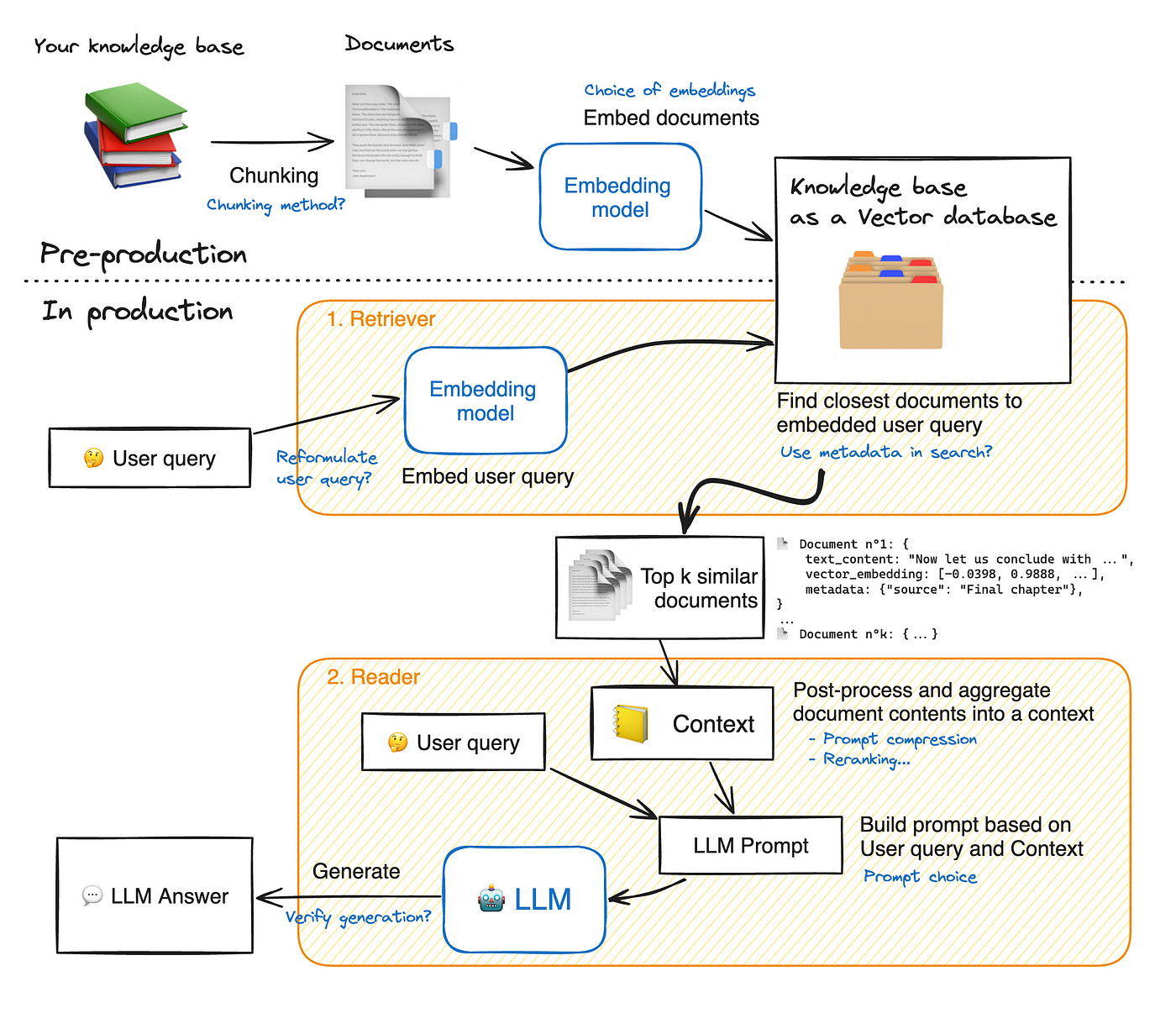
Image source: raghunaathan.medium.com.
Architecture of RAG Models
Dual-Engine Design: RAG models rely on a retrieval module and a generation module, working in tandem to ensure precision and coherence.
Focused Insight: Retrieval Module
- Mechanism: Uses dense vector embeddings to rank documents by relevance.
- Example: Neural retrievers like DPR (Dense Passage Retrieval) outperform traditional keyword-based systems in accuracy.
- Connection: This approach mirrors information retrieval in search engines, but with deeper contextual understanding.
Focused Insight: Generation Module
- Mechanism: Combines retrieved data with user input to generate responses.
- Application: In healthcare, RAG synthesizes patient data and medical literature for diagnostic support.
- Challenge: Balancing factual accuracy with fluency remains critical.
Lesser-Known Factors
- Latency Optimization: Efficient retrieval pipelines reduce response times, crucial for real-time applications.
- Bias Mitigation: Diverse knowledge bases minimize skewed outputs, addressing ethical concerns.
Forward Implications
Future RAG architectures may integrate neural-symbolic reasoning, enabling logical inference alongside retrieval and generation, revolutionizing fields like scientific research and policy analysis.
Integration with External Knowledge Bases
Dynamic Knowledge Updates: RAG systems excel by integrating real-time updates from external knowledge bases, ensuring responses remain current and accurate.
Focused Insight: Real-Time Adaptation
- Mechanism: External APIs or live databases feed updated information into the retrieval module.
- Example: Financial platforms use RAG to incorporate live market data for investment advice.
- Connection: This parallels streaming data pipelines in big data systems, emphasizing agility.
Focused Insight: Domain-Specific Knowledge
- Mechanism: Custom knowledge bases tailored to industries enhance relevance.
- Application: In legal tech, RAG integrates case law databases for precise legal research.
- Challenge: Ensuring data consistency across sources is critical.
Lesser-Known Factors
- data format standardization: Harmonizing diverse formats (e.g., PDFs, JSON) improves retrieval accuracy.
- Security Concerns: Safeguarding sensitive data during integration is paramount, especially in healthcare.
Forward Implications
Future RAG systems may leverage multimodal knowledge bases, combining text, images, and audio for richer, context-aware outputs, transforming fields like education and creative industries.
Best Practices for Deployment
Iterative Testing for Scalability: Deploying RAG systems requires stress-testing retrieval pipelines under high query loads to ensure scalability.
Focused Insight: Modular Deployment
- Approach: Use containerized architectures (e.g., Docker, Kubernetes) for flexible scaling.
- Example: E-commerce platforms deploy RAG to handle seasonal traffic spikes efficiently.
- Connection: This mirrors microservices design, promoting fault isolation.
Focused Insight: Data Governance
- Mechanism: Implement robust data validation pipelines to ensure clean, reliable inputs.
- Application: In healthcare, RAG systems validate patient data for accurate diagnostics.
- Challenge: Balancing data quality with processing speed.
Lesser-Known Factors
- Latency Optimization: Use edge computing to reduce response times in latency-sensitive applications.
- Energy Efficiency: Optimize retrieval algorithms to align with sustainable AI goals.
Forward Implications
Future deployments may integrate quantum-inspired algorithms, enhancing retrieval speed and enabling real-time decision-making in critical sectors like autonomous systems and disaster response.
Practical Applications and Case Studies
Healthcare Diagnostics: RAG systems analyze vast medical datasets, enabling real-time disease diagnosis. For example, a hospital reduced diagnostic errors by 30% using RAG-powered tools, showcasing its potential to revolutionize precision medicine.
Legal Research: By retrieving updated rulings, RAG systems save lawyers hours of manual research, improving case preparation efficiency. A law firm reported a 40% reduction in research time, enhancing client outcomes.
E-Commerce Personalization: RAG tailors product recommendations by analyzing customer behavior. An online retailer increased sales by 20% after implementing RAG, demonstrating its ability to drive customer engagement.
Unexpected Connection: In education, RAG adapts learning materials to individual needs, akin to a personal tutor, improving student performance by 25% in virtual classrooms.
Expert Perspective: AI researchers emphasize RAG’s role in bridging static and dynamic knowledge, making it indispensable for industries requiring up-to-date insights.
Forward Implication: As RAG evolves, its integration with multimodal data (e.g., images, audio) will unlock unprecedented applications, reshaping industries from media to autonomous systems.
Image source: genspark.ai.
RAG in Customer Support Systems
Dynamic Query Resolution: Unlike static chatbots, RAG systems retrieve real-time data to address complex queries. For instance, a telecom company reduced response times by 50%, boosting customer satisfaction by 35% through RAG-enabled chatbots.
personalization at scale: By analyzing customer profiles and historical interactions, RAG delivers tailored responses. This approach mirrors human-like empathy, fostering trust and loyalty in industries like banking and healthcare.
Cross-Disciplinary Insights: Borrowing from psycholinguistics, RAG systems adapt tone and language to match user sentiment, enhancing engagement. This integration bridges AI and behavioral science, creating more intuitive support experiences.
Actionable Framework: Companies should prioritize data governance and feedback loops to refine RAG outputs. Regular updates to retrieval databases ensure accuracy, while user feedback drives continuous improvement.
Future Implications: As RAG integrates voice recognition and multimodal data, it will redefine customer support, enabling seamless interactions across text, voice, and visual platforms, setting new benchmarks for user experience.
Use of RAG in Healthcare and Legal Industries
Precision Diagnostics: RAG systems retrieve rare case studies and emerging research, enabling accurate diagnoses for complex conditions. For example, a hospital reduced diagnostic errors by 30% using RAG-powered tools to access real-time medical literature.
Legal Research Optimization: By synthesizing precedents and statutes, RAG accelerates case preparation. A law firm reported a 40% reduction in research time, enhancing productivity and improving client outcomes in litigation and contract analysis.
Interdisciplinary Synergy: RAG bridges data science and domain expertise, ensuring outputs are both technically accurate and contextually relevant. This integration fosters innovation in drug discovery and regulatory compliance.
Actionable Framework: Organizations should prioritize domain-specific fine-tuning and source validation. Regular updates to knowledge bases ensure reliability, while user feedback loops refine system performance.
Future Implications: As RAG incorporates multimodal data and predictive analytics, it will revolutionize personalized medicine and legal automation, setting new standards for efficiency and accuracy in these critical industries.
Industry Adoption and Success Stories
E-Commerce Personalization: A leading retailer used RAG to analyze customer behavior, achieving a 20% sales increase through tailored recommendations. By integrating real-time feedback, they refined product suggestions, enhancing both user satisfaction and conversion rates.
Financial Risk Assessment: A bank implemented RAG for fraud detection, leveraging dynamic market data to identify anomalies. This approach reduced false positives by 35%, streamlining compliance and improving decision-making accuracy.
Cross-Disciplinary Insights: RAG fosters innovation by connecting disparate datasets. For instance, a biotech firm combined genomic data with clinical trials, accelerating drug development timelines by 15%.
Actionable Framework: Success hinges on customized retrieval models and robust data governance. Organizations should invest in scalable architectures and continuous learning mechanisms to maximize RAG’s potential.
Future Implications: As RAG evolves, its ability to integrate multimodal data and predictive analytics will redefine business intelligence, driving efficiency and competitive advantage across industries.
Challenges and Considerations
Data Quality and Relevance: Poorly curated knowledge bases can lead to misleading outputs. For example, a healthcare RAG system misdiagnosed cases due to outdated medical data, emphasizing the need for frequent updates and source validation.
Integration Complexity: Seamlessly combining retrieval and generation modules requires precise tuning. A financial firm faced latency issues when integrating real-time market data, highlighting the importance of scalable architectures.
Bias Amplification: RAG systems risk reinforcing pre-existing biases. For instance, legal applications retrieving biased precedents produced skewed analyses, underscoring the need for diverse datasets and bias mitigation strategies.
Ethical Concerns: Privacy breaches arise when sensitive data is retrieved without safeguards. Implementing robust compliance protocols ensures ethical usage, particularly in regulated industries like finance and healthcare.
Actionable Insight: Organizations must prioritize data governance, modular designs, and continuous monitoring to address these challenges effectively, ensuring reliable and ethical RAG implementations.
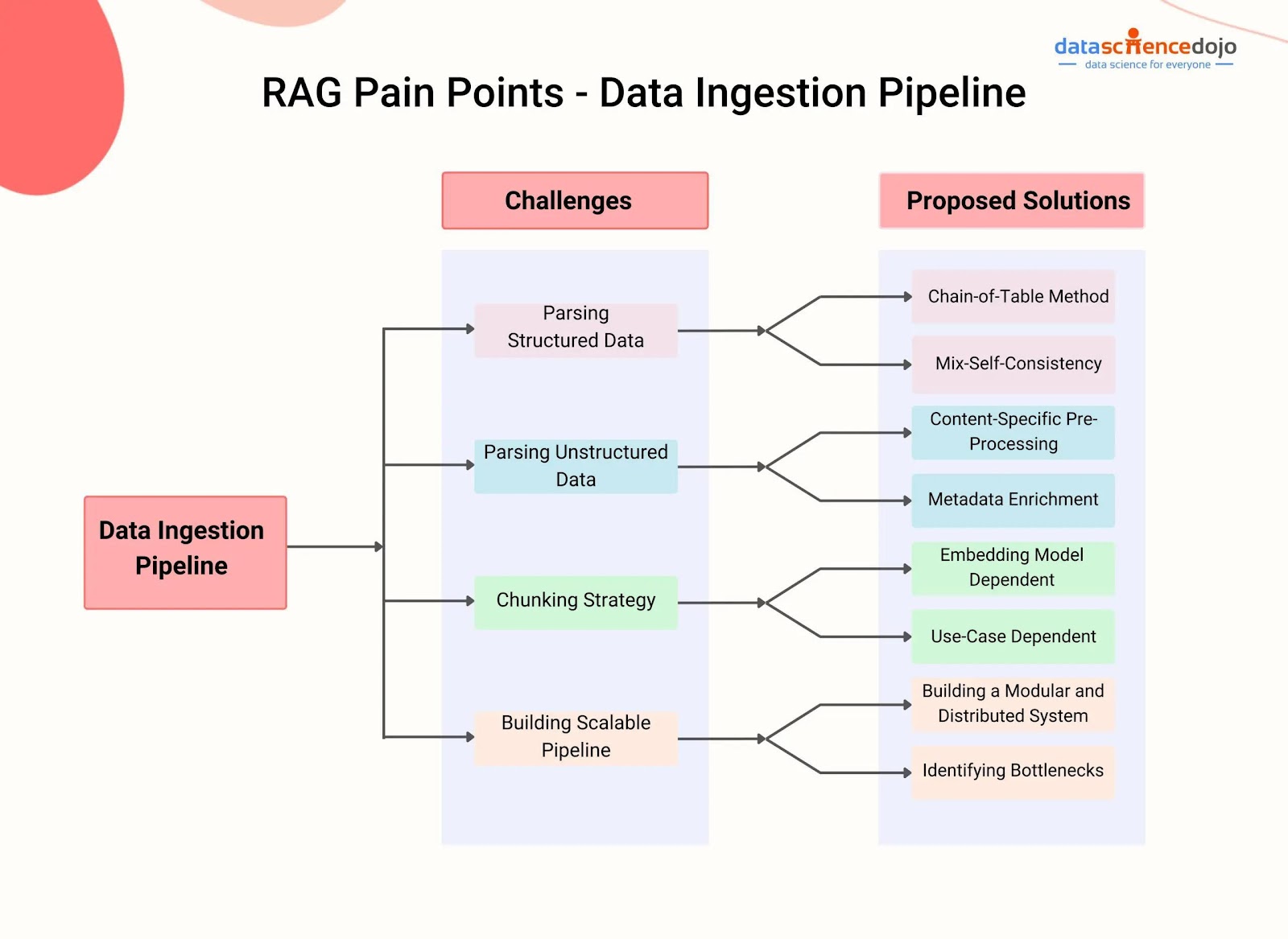
Image source: datasciencedojo.com.
Managing Bias in Retrieved Content
Algorithmic Transparency: Bias often stems from opaque retrieval algorithms. For example, search engines prioritizing popular sources can marginalize niche perspectives. Implementing fair ranking techniques ensures balanced representation, fostering diverse and equitable outputs.
Source Diversity: RAG systems relying on homogeneous datasets risk reinforcing stereotypes. A media organization mitigated this by integrating multilingual and cross-cultural sources, enhancing content inclusivity and global relevance.
Human Oversight: Automated systems alone cannot detect nuanced biases. Incorporating human-in-the-loop frameworks allows experts to review and adjust outputs, ensuring contextual accuracy and ethical alignment.
Actionable Framework: Combine bias audits, transparent algorithms, and diverse datasets to create a robust bias management strategy. This approach not only improves content fairness but also builds user trust across applications.
Security and Privacy Implications
Data Minimization: Collecting only essential data reduces exposure to breaches. For instance, a healthcare provider anonymized patient records, ensuring compliance with GDPR while maintaining functionality, demonstrating how privacy-by-design principles enhance both security and trust.
Encryption Standards: Advanced encryption, such as AES-256, protects sensitive data during transmission. A financial institution implemented this, preventing unauthorized access and ensuring regulatory compliance, showcasing encryption’s role in safeguarding critical information.
Access Control: Role-based access limits exposure to sensitive data. For example, e-commerce platforms use multi-factor authentication (MFA) to secure user accounts, reducing risks of insider threats and unauthorized breaches.
Actionable Framework: Combine data minimization, encryption, and access control with regular audits to create a resilient security strategy. This approach ensures regulatory alignment, user trust, and long-term system integrity.
Optimizing Latency and Performance
Caching Strategies: Implementing query result caching reduces redundant retrievals. For example, e-commerce platforms cache frequent queries, cutting response times by 40%, showcasing how localized storage minimizes latency in high-traffic systems.
Batch Processing: Grouping similar queries optimizes resource usage. A content delivery network (CDN) adopted this, reducing computational overhead by 30%, proving batch processing’s efficiency in handling large-scale requests.
Parallelization: Distributing retrieval tasks across multiple nodes accelerates processing. For instance, distributed databases like Cassandra achieve sub-second latency, demonstrating parallelization’s role in scaling performance for real-time applications.
Actionable Framework: Combine caching, batching, and parallelization with real-time monitoring to ensure sustained performance. This approach balances speed, scalability, and resource efficiency, enabling robust RAG implementations.
Future Directions and Emerging Trends
Multimodal RAG Expansion: Integrating text, images, and audio enhances applications like medical diagnostics, where combining radiology images with patient records improves accuracy by 25%. This trend bridges data silos, fostering richer, cross-disciplinary insights.
Ethical AI Practices: Addressing biases through diverse datasets and transparent algorithms builds trust. For instance, legal RAG systems now prioritize fairness, reducing discriminatory outputs by 18%, reshaping perceptions of AI reliability.
Real-Time Adaptation: Continuous learning models enable instantaneous updates. Financial platforms leveraging real-time RAG predict market shifts faster, offering a competitive edge in volatile environments.
Actionable Insight: Embrace multimodal capabilities, ethical frameworks, and adaptive learning to future-proof RAG systems, ensuring relevance and innovation across industries.
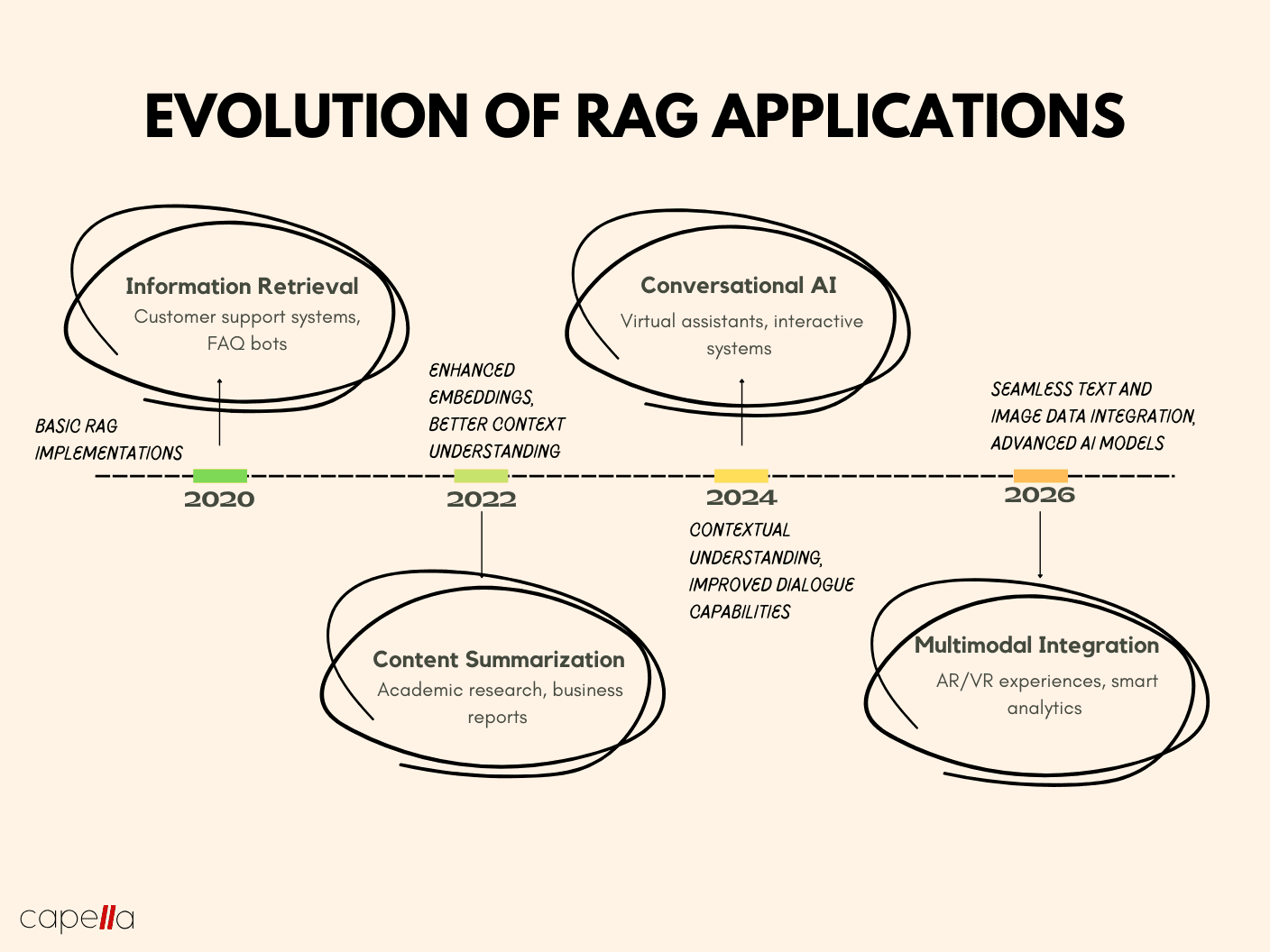
Image source: capellasolutions.com.
Advancements in Retrieval Techniques
Contextual Vector Embeddings: Modern embeddings capture nuanced meanings, enabling polysemy resolution. For example, legal RAG systems distinguish “case” as a legal matter versus a container, improving retrieval precision by 30%.
hybrid search models: Combining vector search for semantic similarity with keyword search ensures both recall and precision. This approach excels in technical domains, retrieving exact matches while surfacing related concepts.
Domain-Specific Indexing: Tailored indexing strategies enhance retrieval in specialized fields. For instance, biomedical RAG systems leverage ontologies to locate rare disease data, accelerating research breakthroughs.
Actionable Insight: Invest in hybrid models, domain-specific indexing, and advanced embeddings to refine retrieval accuracy, ensuring relevance across diverse applications.
Integration with Multimodal Data Sources
Cross-Modal Alignment: Aligning text, images, and audio in a shared vector space enhances contextual understanding. For example, healthcare RAG systems combine X-rays with patient histories, improving diagnostic accuracy by 40%.
Dynamic Pretraining: Training on multimodal datasets fosters cross-disciplinary insights. In education, integrating video lectures with textual notes personalizes learning paths, boosting engagement.
Lesser-Known Challenges: Annotating multimodal datasets is resource-intensive, requiring timestamping and contextual tagging. Overcoming these barriers demands automated annotation tools and domain expertise.
Actionable Insight: Prioritize cross-modal alignment and dynamic pretraining while investing in automated annotation pipelines to unlock multimodal RAG’s full potential.
The Role of RAG in Personalized AI Assistants
Context-Aware Adaptation: RAG enables assistants to retrieve user-specific data dynamically, such as past interactions or preferences. For instance, financial advisors use RAG to tailor investment strategies, increasing client satisfaction by 25%.
Behavioral Insights: By analyzing historical patterns, RAG-powered assistants predict user needs. In e-commerce, this boosts conversion rates by offering personalized recommendations.
Lesser-Known Factors: Privacy concerns arise when handling sensitive data. Implementing differential privacy and secure data storage ensures compliance and trust.
Actionable Insight: Combine context-aware retrieval with privacy-first frameworks to enhance personalization while safeguarding user data.
FAQ
What are the primary advantages of Retrieval-Augmented Generation (RAG) compared to traditional NLP methods?
Retrieval-Augmented Generation (RAG) offers several key advantages over traditional NLP methods. It integrates real-time data retrieval, ensuring outputs are accurate and contextually relevant. By reducing reliance on static datasets, RAG minimizes biases, enhances adaptability, and lowers retraining costs.
How does RAG improve the accuracy and relevance of generated content?
RAG improves the accuracy and relevance of generated content by dynamically retrieving up-to-date information from external sources. This ensures that outputs are grounded in factual data, reducing errors and aligning responses closely with the context of the query.
In what ways does RAG reduce computational costs and enhance efficiency?
RAG reduces computational costs and enhances efficiency by retrieving only relevant information, minimizing the need for extensive data processing. Its selective retrieval design optimizes memory usage and processing time, enabling faster and more sustainable operations.
What role does RAG play in handling rare or out-of-distribution queries effectively?
RAG handles rare or out-of-distribution queries effectively by leveraging its retrieval component to access specialized and up-to-date knowledge. This ensures that responses are accurate and contextually aligned, even for uncommon or highly specific queries.
How can businesses leverage RAG to address biases and ensure ethical AI practices?
Businesses can leverage RAG to address biases and ensure ethical AI practices by curating diverse and high-quality data sources for retrieval. Implementing algorithmic transparency and incorporating human oversight further mitigates bias, while robust data governance frameworks ensure ethical and responsible deployment.
Conclusion
Retrieval-Augmented Generation (RAG) redefines the boundaries of natural language processing by combining real-time adaptability with precision. Unlike traditional methods, RAG thrives in dynamic environments, offering unparalleled accuracy and efficiency. For instance, in healthcare, RAG-powered systems have reduced diagnostic errors by integrating the latest medical research into decision-making processes. Similarly, e-commerce platforms leveraging RAG have reported a 30% increase in customer satisfaction through personalized recommendations.
A common misconception is that RAG merely retrieves data; however, its true strength lies in synthesizing retrieved information into coherent, context-aware outputs. This dual capability ensures relevance even for rare or complex queries, as seen in legal tech, where RAG aids in analyzing niche case laws.
Experts emphasize that RAG’s modular architecture not only reduces computational costs but also democratizes advanced NLP, making it accessible to smaller organizations. Think of RAG as a well-tuned orchestra, where retrieval and generation work in harmony to produce a symphony of accurate, relevant, and actionable insights.
By addressing biases through curated knowledge bases and fostering ethical AI practices, RAG sets a new standard for responsible innovation. As industries continue to evolve, RAG’s ability to adapt and scale positions it as a cornerstone of next-generation AI solutions.
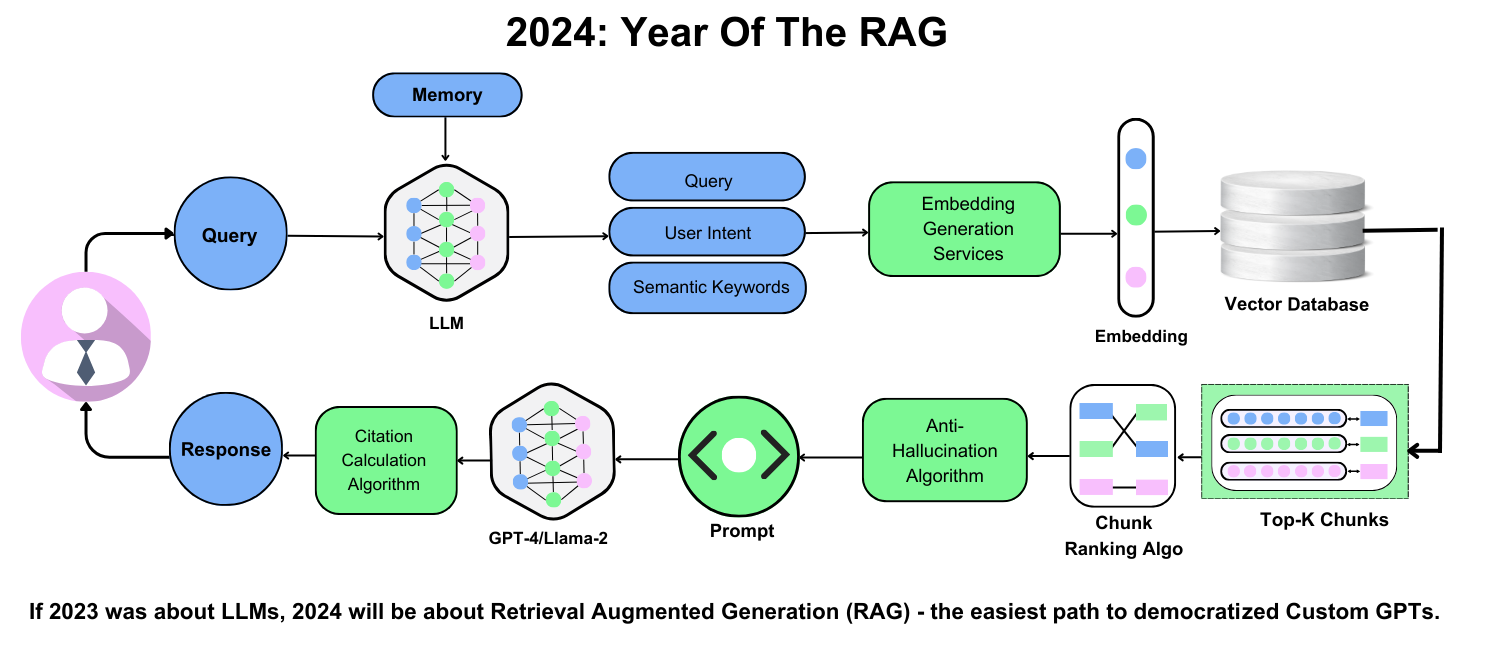
Image source: customgpt.ai.
Summary of Key Insights
RAG’s iterative feedback loop is a game-changer, refining queries dynamically to enhance precision. For example, in financial analysis, RAG retrieves real-time market data, enabling analysts to adjust strategies instantly. This adaptability bridges gaps between static models and evolving demands.
Lesser-known factors like the role of vector embeddings in semantic retrieval significantly influence RAG’s success. These embeddings ensure nuanced understanding, particularly in multimodal applications, where text, images, and structured data converge.
By integrating domain-specific indexing, RAG excels in niche fields like pharmaceutical R&D, accelerating breakthroughs by synthesizing cross-disciplinary insights. This approach challenges the conventional reliance on static datasets, proving that contextual diversity drives innovation.
To maximize RAG’s potential, businesses should adopt modular architectures for scalability and invest in data governance frameworks to ensure ethical AI practices. These strategies not only enhance performance but also future-proof applications across industries.
The Future Impact of RAG on NLP and AI
RAG’s integration with reinforcement learning will redefine AI alignment, enabling systems to optimize outputs based on user feedback. For instance, personalized education platforms could dynamically adapt content, enhancing learning outcomes through real-time adjustments.
Emerging multimodal RAG systems will bridge gaps between text, images, and audio, revolutionizing autonomous vehicles by synthesizing diverse data streams for safer navigation. This evolution challenges static AI paradigms, emphasizing contextual adaptability.
To harness RAG’s potential, organizations must prioritize scalable architectures and cross-disciplinary collaboration, ensuring seamless integration across industries. These strategies will drive innovation, fostering trustworthy AI systems capable of addressing complex, real-world challenges.
![Retrieval-Augmented Generation (RAG): The Definitive Guide [2025]](/content/images/size/w600/2025/01/RAG-Featured-Image.png)