
Incorporating Knowledge Graphs in Retrieval-Augmented Generation
Integrating knowledge graphs with RAG enhances context, structure, and precision in AI responses. This guide covers techniques and best practices for combining graph-based data with retrieval-augmented generation to improve overall system performance.


If a user asks, “What caused the 2008 financial crisis?” most systems return a list of documents. But that’s not what the user wants—they want context, connections, and meaning.
This is where incorporating knowledge graphs in Retrieval-Augmented Generation (RAG) changes the game.
Traditional RAG models pull relevant text, but they often miss the bigger picture. They struggle to understand relationships—between people, events, timelines, or even just ideas.
Incorporating knowledge graphs in Retrieval-Augmented Generation brings structure to that chaos. It helps systems reason, not just retrieve.
This shift—from surface-level answers to context-aware understanding—is what’s making RAG systems more accurate, scalable, and valuable across fields like healthcare, law, and finance.
And it starts with one key change: teaching models to think in terms of relationships, not keywords.
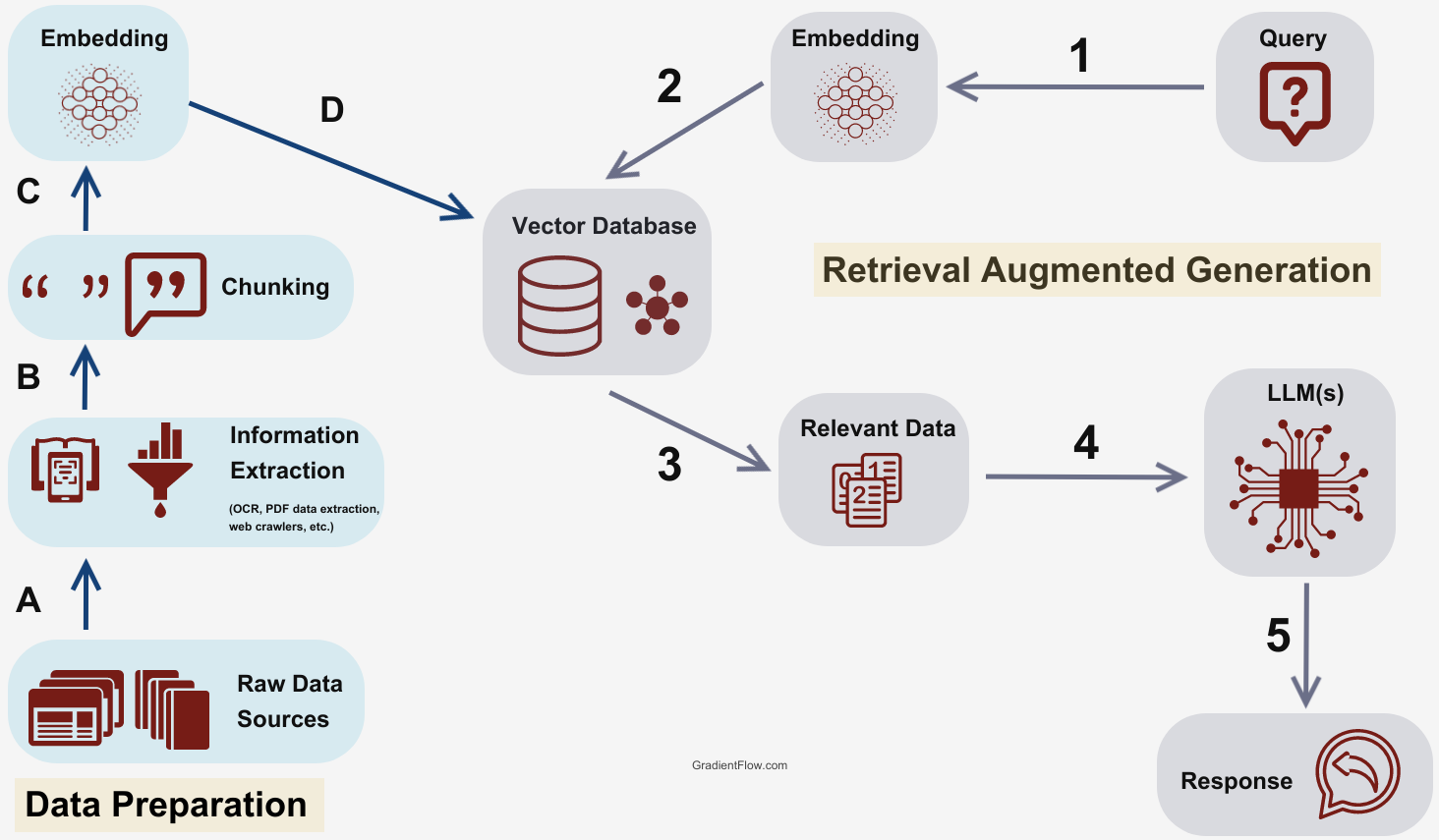
Core Principles of Retrieval-Augmented Generation
One often-overlooked aspect of Retrieval-Augmented Generation (RAG) is the interplay between contextual granularity and response coherence.
This principle hinges on the system’s ability to dynamically adjust the depth of retrieved information based on the query’s complexity, ensuring that responses are both precise and contextually rich.
The mechanism behind this involves leveraging hierarchical knowledge graphs to prioritize relevant data layers.
Unlike flat retrieval methods, hierarchical structures allow the system to navigate from broad categories to specific nodes, tailoring the retrieval process to the query’s intent.
For instance, in customer service applications, this approach enables the system to differentiate between general troubleshooting steps and highly technical solutions, depending on the user’s expertise level.
However, this adaptability introduces challenges. Balancing retrieval depth with computational efficiency requires fine-tuning parameters like node traversal limits and relevance thresholds.
Misalignment in these settings can lead to either overly generic responses or excessive processing time, particularly in high-demand environments.
Ultimately, the success of this principle lies in its implementation.
Organizations like Akira AI have demonstrated that integrating hierarchical retrieval with domain-specific knowledge graphs significantly enhances response accuracy, particularly in fields like healthcare and legal advisory.
Challenges in Traditional Retrieval Methods
Traditional retrieval methods often falter when addressing the inherent complexity of real-world queries, mainly due to their reliance on static, one-dimensional vector searches.
These systems struggle to capture the intricate relationships between entities, leading to responses that lack depth and contextual relevance.
This limitation becomes especially pronounced in domains like legal research or medical diagnostics, where nuanced interdependencies are critical.
One key issue lies in the inability of flat retrieval systems to bridge the gap between local and global knowledge layers.
For instance, a query about “Amazon” might retrieve isolated facts about the company’s e-commerce operations but fail to connect these to broader insights, such as its impact on global supply chains.
This disconnect stems from insufficient mechanisms to integrate hierarchical or relational context into the retrieval process.
Incorporating knowledge graphs addresses this challenge by embedding semantic relationships directly into the retrieval framework.
By doing so, these systems can dynamically adapt to the query’s intent, offering precise and contextually rich responses.
For example, in customer support, knowledge graphs enable systems to link troubleshooting steps with user-specific histories, significantly improving resolution rates.
However, implementing such solutions is not without its challenges. Balancing computational efficiency with retrieval depth requires careful parameter tuning, such as optimizing node traversal limits.
Missteps in these configurations can lead to either excessive processing times or overly generic outputs, particularly in high-demand environments.
Ultimately, the shift from flat retrieval to graph-based systems represents a paradigm change, one that demands both technical sophistication and domain-specific customization.
Introduction to Knowledge Graphs
Knowledge graphs are the structural backbone of modern Retrieval-Augmented Generation (RAG) systems, offering a way to encode relationships and context that traditional data models simply cannot achieve. Unlike flat databases, they represent information as interconnected entities and relationships, mirroring the complexity of real-world knowledge.
This design enables systems to perform reasoning tasks, such as multi-hop queries, with unparalleled precision.
A key misconception is that knowledge graphs are merely enhanced databases. In reality, they are dynamic frameworks capable of evolving with new data.
For example, Google’s Knowledge Graph, which processes over 5 billion facts, continuously updates its nodes and edges to refine search relevance.
This adaptability is critical for applications like medical diagnostics, where new research constantly reshapes the landscape.
By embedding semantic relationships, knowledge graphs transform isolated data points into a cohesive network, enabling RAG systems to deliver context-aware, nuanced responses that align with user intent.
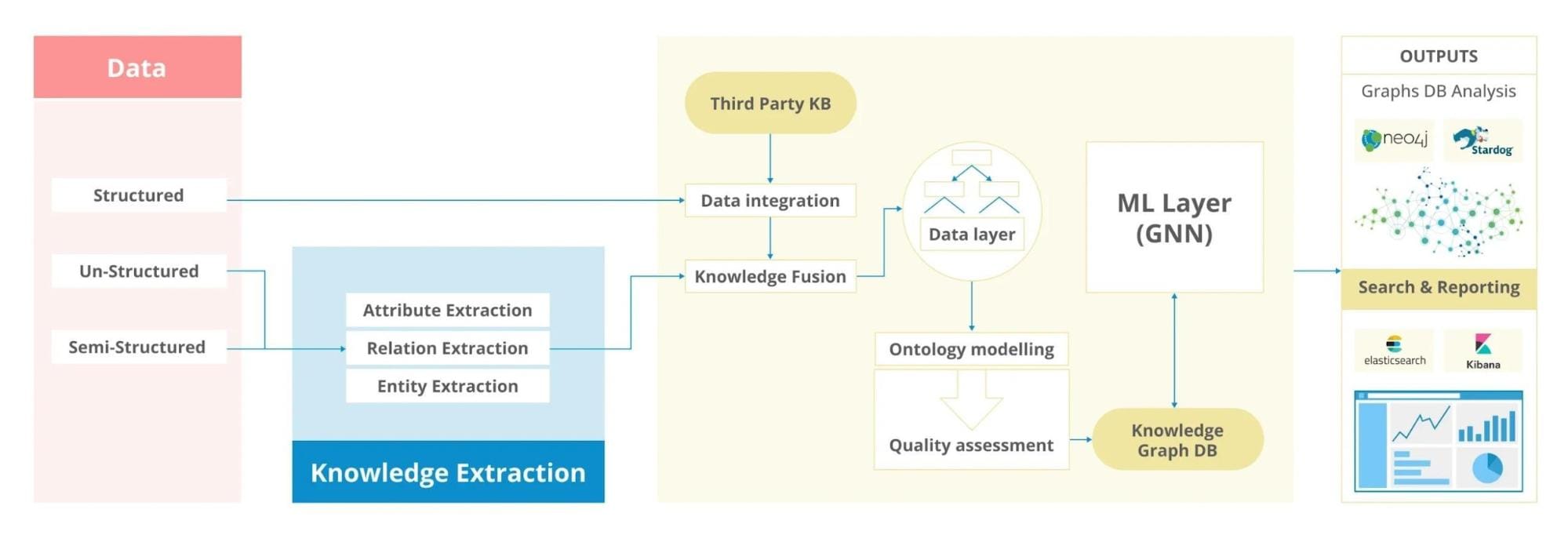
Fundamentals of Knowledge Graph Construction
The cornerstone of practical knowledge graph construction lies in the ontology design, which serves as the blueprint for defining entities, relationships, and their attributes. This step is critical because it determines how well the graph can adapt to evolving data and user needs.
A well-crafted ontology organizes information and enables logical reasoning, making it indispensable for applications like RAG systems.
One of the most nuanced challenges in ontology design is balancing specificity with generality.
Overly rigid schemas can stifle adaptability, while excessively broad ones risk diluting the graph’s utility.
For instance, incorporating hierarchical relationships allows for both granular and high-level queries, a feature particularly valuable in domains like healthcare, where precision is paramount.
A practical implementation example comes from Neo4j, which employs iterative design processes.
By starting with a minimal viable graph and refining it through domain expert feedback, they ensure the graph remains both accurate and contextually relevant.
This iterative approach highlights the importance of human insight in shaping machine-driven systems.
Ultimately, a knowledge graph's success hinges on its ability to bridge raw data with actionable insights, a task that requires technical precision and creative problem-solving.
Semantic Relationships and Entity Linking
Semantic relationships and entity linking are the linchpins of effective knowledge graph integration in RAG systems, enabling precise contextualization of user queries.
A critical yet often overlooked aspect is the dynamic alignment of entity linking with user intent. This involves not just mapping entities to their corresponding nodes but also capturing the nuanced relationships that evolve with real-time interactions.
One advanced technique is context-aware entity disambiguation, which leverages multi-hop retrieval to refine entity linking.
Unlike static approaches, this method dynamically evaluates the surrounding semantic context to resolve ambiguities.
For instance, in a legal advisory system, the term “appeal” could refer to either a legal process or a marketing strategy. Context-aware linking ensures the correct interpretation by analyzing adjacent entities and their relationships.
A notable implementation comes from OpenAI, where adaptive entity linking was fine-tuned using user feedback loops.
This iterative process improved accuracy and revealed edge cases, such as conflicting terminologies across industries. These insights underscore the importance of tailoring entity linking strategies to specific domains, ensuring both precision and adaptability.
The implications are profound: by embedding semantic relationships into entity linking, RAG systems can achieve unparalleled contextual depth, transforming static knowledge into dynamic, user-centric intelligence.
Integrating Knowledge Graphs with RAG
Integrating knowledge graphs into Retrieval-Augmented Generation (RAG) systems transforms how queries are understood and resolved by embedding structured relationships directly into the retrieval process.
Unlike traditional vector-based methods, which often flatten semantic nuances, knowledge graphs enable systems to navigate interconnected data precisely.
This approach is particularly effective in domains requiring multi-hop reasoning, such as healthcare or legal research, where answers depend on synthesizing information across multiple entities.
One critical advancement is the use of Chain of Explorations (CoE) algorithms, which dynamically traverse graph nodes to retrieve contextually relevant data.
For example, in financial fraud detection, CoE can link transaction histories with external regulatory data, uncovering patterns that static retrieval methods might miss.
This capability enhances accuracy and reduces retrieval latency by prioritizing high-relevance nodes.
A common misconception is that knowledge graphs merely supplement existing data models. In reality, they redefine query execution by enabling inferential reasoning.
By leveraging graph-based retrieval, RAG systems can generate responses that reflect the complexity of real-world relationships, bridging the gap between static data and dynamic intelligence.
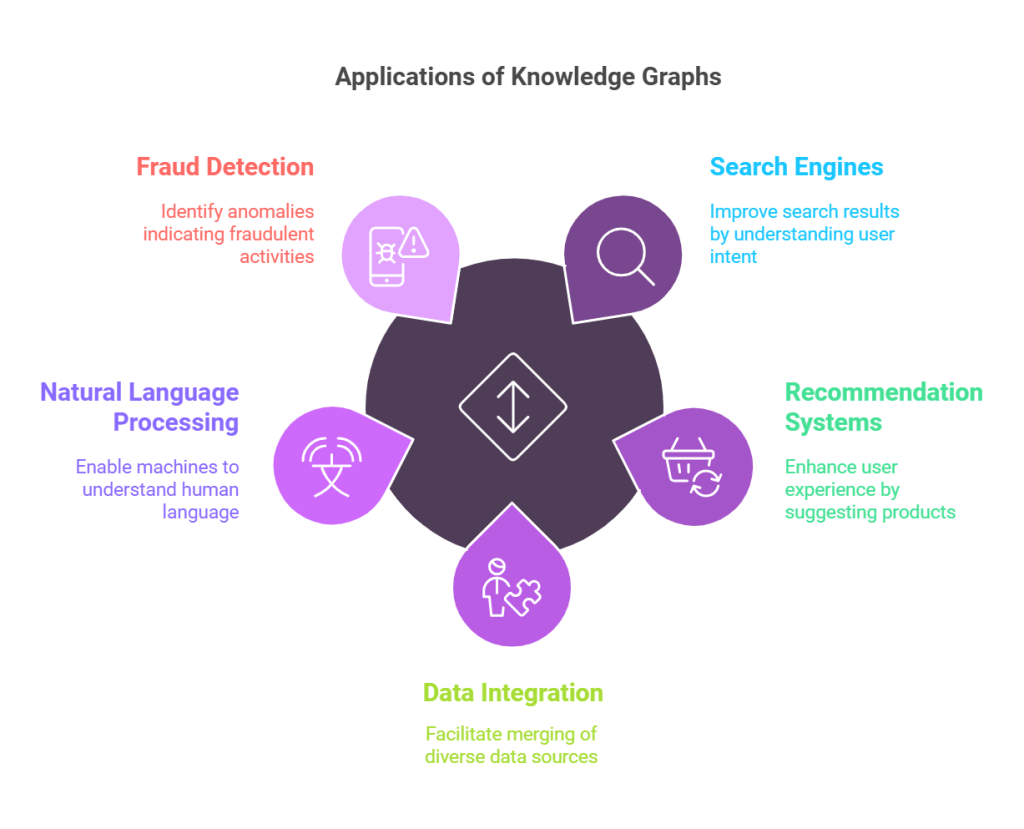
Graph-Based Retrieval Techniques
Graph-based retrieval techniques excel by leveraging the inherent structure of knowledge graphs to capture nuanced relationships that traditional methods often overlook.
These techniques rely on contextual node traversal, a process that dynamically explores interconnected entities to retrieve data aligned with the query’s intent.
This approach is particularly effective in multi-hop reasoning scenarios, such as diagnosing rare medical conditions or analyzing legal precedents.
The effectiveness of this method hinges on fine-tuning traversal parameters. For instance, limiting traversal depth ensures computational efficiency but risks missing critical connections, while excessive depth can introduce noise and redundancy.
Striking this balance requires domain-specific calibration, often guided by iterative testing and user feedback.
One underappreciated challenge is embedding alignment. Misaligned embeddings can distort the graph’s semantic integrity, leading to irrelevant results. Techniques like contrastive learning mitigate this by refining embeddings to emphasize task-specific features.
Ultimately, graph-based retrieval techniques empower RAG systems to deliver responses that are not only accurate but also contextually rich, bridging the gap between data retrieval and meaningful understanding.
Hierarchical Indexing and Semantic Retrieval
Hierarchical indexing operates as a dynamic framework, structuring knowledge graphs into layered abstractions that balance granularity with retrieval efficiency.
Organizing entities into progressively detailed layers ensures that broad conceptual overviews are accessible without sacrificing the precision of localized data.
This layered design is particularly effective in scenarios requiring both high-level insights and fine-grained details, such as regulatory compliance or medical diagnostics.
A critical mechanism underpinning this approach is semantic aggregation. Higher-layer nodes act as conceptual hubs, summarizing clusters of related entities from lower layers.
This not only reduces traversal complexity but also enhances semantic coherence. For example, in a legal advisory system, grouping case law precedents under broader legal principles allows for faster, contextually relevant retrieval.
However, achieving this balance requires meticulous parameter tuning, such as defining optimal node summarization thresholds to avoid overgeneralization.
One notable implementation is HiRAG’s HiIndex, which bridges distant yet semantically similar entities.
This technique has proven particularly effective in bridging local and global knowledge gaps, as demonstrated in financial fraud detection systems. However, edge cases, such as ambiguous entity relationships, highlight the need for adaptive algorithms that refine indexing dynamically.
By addressing these nuances, hierarchical indexing elevates RAG systems from static retrieval tools to adaptive, reasoning-driven platforms.
Advanced Techniques in Knowledge Graph-Enhanced RAG
Integrating context-aware graph traversal into RAG systems has redefined how retrieval processes adapt to complex queries.
Unlike static retrieval pipelines, this technique dynamically adjusts traversal paths based on query-specific parameters, enabling systems to prioritize semantically rich nodes.
A pivotal innovation is the application of contrastive embedding alignment, which ensures that graph embeddings remain consistent across diverse datasets.
One misconception is that larger graphs inherently improve retrieval. In reality, sparse, well-curated graphs often outperform dense, noisy ones.
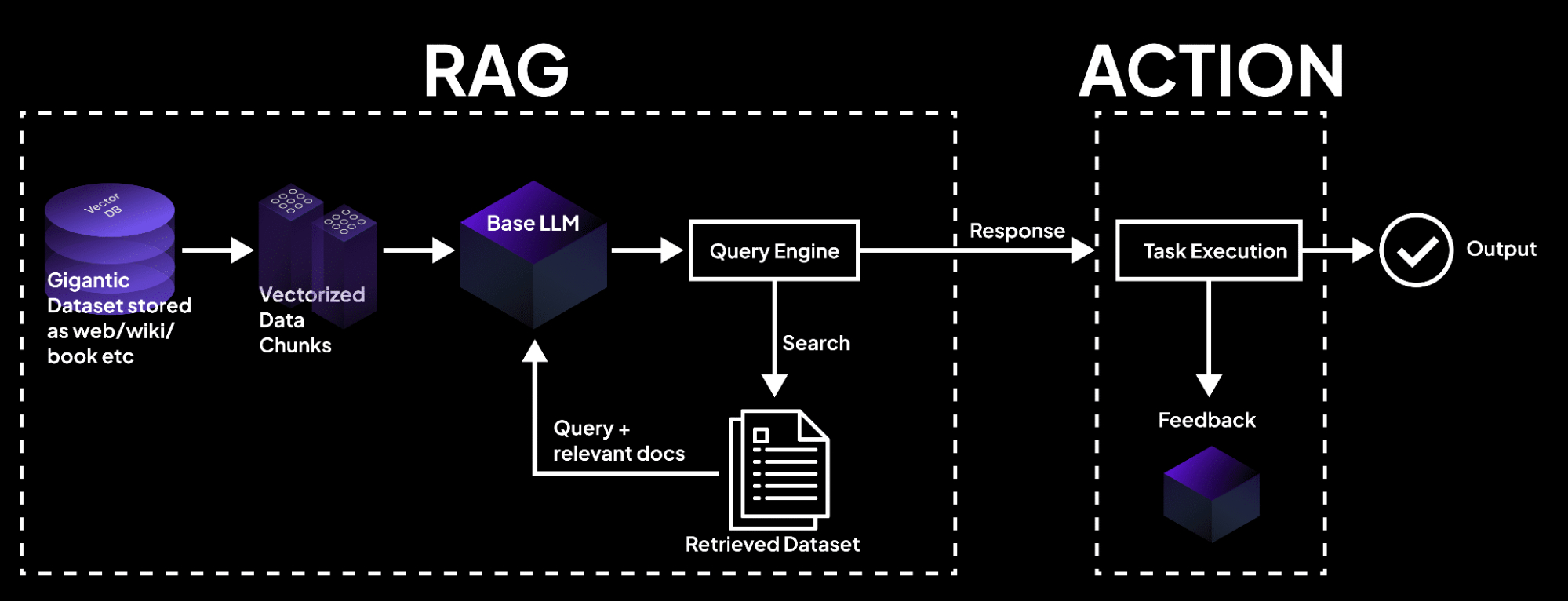
Hierarchical Matching Strategies
Hierarchical matching strategies redefine how RAG systems interpret and respond to complex queries by dynamically aligning retrieval depth with the query’s semantic structure.
This approach moves beyond static indexing, enabling systems to traverse layered knowledge graphs in a way that mirrors human reasoning.
The key lies in adaptive traversal, where the system evaluates the specificity of a query and adjusts its depth accordingly, ensuring both precision and efficiency.
At its core, this method relies on contextual relevance tuning, a process that prioritizes nodes based on their semantic alignment with the query.
For example, in regulatory compliance systems, broad legal principles might serve as entry points, with traversal narrowing to specific case law only when the query demands granular detail. This adaptability minimizes computational overhead while maintaining response accuracy.
A critical challenge, however, is balancing traversal depth with retrieval latency. Overly shallow searches risk omitting crucial details, while excessive depth can introduce noise.
Techniques like dynamic node weighting, which assigns relevance scores to nodes based on query context, address this by guiding the system toward optimal traversal paths.
In practice, organizations like Neo4j have demonstrated the effectiveness of this strategy by integrating user feedback loops to refine traversal algorithms.
This iterative approach enhances system accuracy and reveals edge cases, such as ambiguous queries, that require further optimization. The result is a retrieval process that feels intuitive, almost conversational, bridging the gap between static data and dynamic intelligence.
Attributed Community Detection and C-HNSW
Attributed community detection transforms hierarchical indexing by focusing on shared attributes rather than mere connectivity.
This nuanced method enables the creation of clusters that reflect both thematic coherence and structural density, making the graph a more intuitive and efficient tool for retrieval.
Integrating these communities into the Community-based HNSW (C-HNSW) index further amplifies this efficiency by enabling rapid, context-aware navigation through high-dimensional data.
The process begins with a novel LLM-based clustering framework that iteratively refines community boundaries.
Unlike traditional methods, which rely solely on link density, this approach incorporates node attributes to detect communities aligning with local and global contexts.
This dual-layered understanding is critical for addressing complex queries, as it allows the system to balance granularity with abstraction dynamically.
One of the standout features of C-HNSW is its ability to map attributed communities into hierarchical layers, where higher levels summarize broader themes and lower levels delve into specifics.
This structure reduces retrieval latency and enhances results' relevance by prioritizing semantically rich nodes.
FAQ
What are the key benefits of integrating knowledge graphs into Retrieval-Augmented Generation systems?
Knowledge graphs in Retrieval-Augmented Generation systems improve accuracy by structuring data into entities and relationships. They reduce irrelevant outputs, support context-aware reasoning, and help scale responses across domains like healthcare and legal services where data complexity and precision matter.
How do entity relationships enhance the contextual accuracy of responses in RAG systems?
Entity relationships give structure to data in RAG systems, helping match user queries with relevant responses. They improve precision by linking related facts, allowing the system to handle complex or ambiguous queries with better context and fewer errors.
What role does salience analysis play in optimizing knowledge graph-based retrieval processes?
Salience analysis improves retrieval by ranking important entities and links within the knowledge graph. It filters out less relevant data, helping the system focus on key information. This leads to faster, more accurate responses that reflect the intent of the query.
How can co-occurrence optimization improve the performance of knowledge graph-enhanced RAG systems?
Co-occurrence optimization improves retrieval by finding patterns of related entities that often appear together. These links help the system understand context and strengthen the structure of the knowledge graph, leading to more relevant and accurate results in RAG applications.
What are the best practices for constructing and maintaining dynamic knowledge graphs for RAG applications?
Start with clear schema definitions to build meaningful entity links. Update data often and monitor for errors. Use salience analysis to identify key nodes and co-occurrence data to refine connections. Strong maintenance keeps the graph useful, accurate, and scalable for RAG systems.
Conclusion
Incorporating knowledge graphs in Retrieval-Augmented Generation systems brings structure to unstructured data, enabling better understanding, context, and precision.
From entity linking to graph traversal, these techniques reduce noise and align outputs with user intent. As data grows more complex, knowledge graphs provide a path toward scalable, efficient, and intelligent RAG pipelines.