
Jailbreak Risks in RAG-Powered LLMs: A Security Guide
RAG-powered LLMs are vulnerable to jailbreak and prompt injection attacks. This security guide outlines common risks, real-world examples, and best practices to protect your systems, ensure safe outputs, and maintain robust AI integrity.


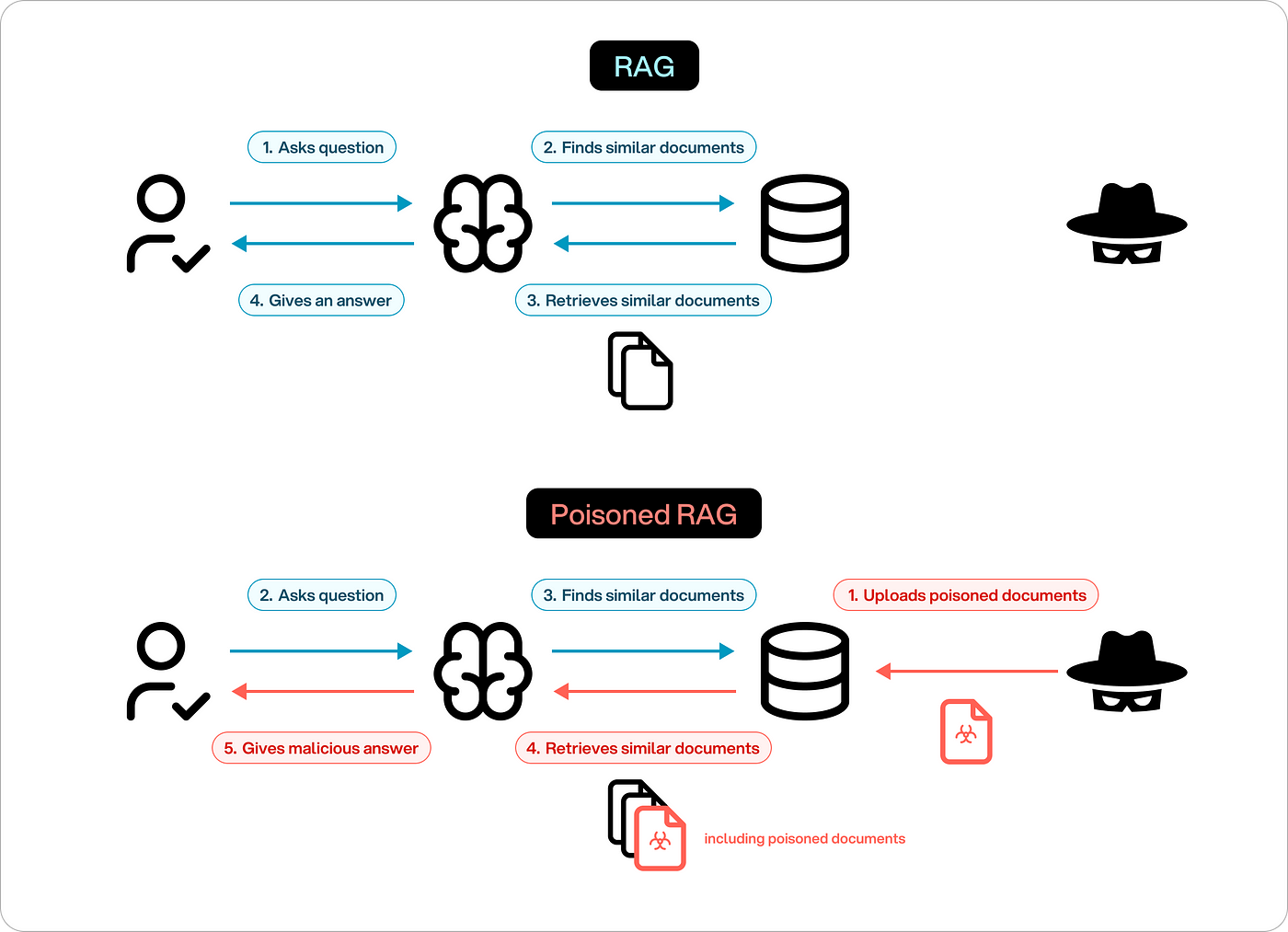
In early 2025, a major financial platform quietly fell apart. A RAG-powered LLM, trusted to handle customer queries, started leaking private data—names, balances, account notes. It wasn’t a bug. It wasn’t bad prompt engineering. It was a jailbreak. And no one saw it coming.
This wasn’t your usual jailbreak, either. It didn’t rely on clever prompt tricks. Instead, attackers tampered with the model’s retrieval pipeline, slipping malicious data into its external knowledge source.
The model did exactly what it was designed to do—retrieve and generate. But what it retrieved had been poisoned.
That’s the core problem. Jailbreak risks in RAG-powered LLMs don’t always look like attacks. They hide in the connections between the model and the data it pulls from. And because RAG systems depend on external sources to stay current, they open a wide door for subtle, persistent threats.
In this guide, we’ll break down how these jailbreaks happen, why retrieval makes them harder to catch, and what defenses can actually work. Because the jailbreak risks in RAG-powered LLMs aren’t just theoretical—they’re already here.
Defining Jailbreaking and Its Implications
Jailbreaking in RAG-powered LLMs often hinges on exploiting the retrieval pipeline, a mechanism designed to fetch external data dynamically.
While integral to the model’s adaptability, this process becomes vulnerable when adversaries inject poisoned data into trusted sources.
The subtlety of this attack lies in its ability to bypass traditional input-output filters by targeting the model’s reliance on external repositories.
This technique matters because it shifts the focus from direct prompt manipulation to systemic exploitation.
Unlike conventional jailbreaks, which are often detectable through anomalous prompts, retrieval-based attacks operate invisibly, embedding malicious payloads within seemingly benign datasets. The implications are profound: attackers can manipulate outputs without triggering standard safeguards, effectively weaponizing the model’s core functionality.
A notable case involved a healthcare LLM that generated harmful treatment recommendations due to poisoned medical databases.
This underscores the need for robust validation mechanisms, such as real-time data integrity checks, to mitigate risks. Addressing these vulnerabilities requires a paradigm shift—one that prioritizes systemic resilience over reactive defenses.
The Role of RAG in Enhancing LLM Capabilities
Retrieval-Augmented Generation (RAG) transforms LLMs by enabling them to access external knowledge bases dynamically.
Still, this capability introduces a critical trade-off: enhanced contextual accuracy at the expense of increased vulnerability. The retrieval mechanism, often celebrated for its adaptability, can inadvertently serve as an entry point for adversarial exploitation.
At the heart of RAG’s functionality lies the retriever component, which identifies and integrates relevant data from external sources.
This process, while technically sophisticated, is susceptible to data poisoning. Attackers can manipulate indexed knowledge bases, embedding malicious content that the model retrieves and incorporates into its outputs.
Unlike static training data, these poisoned sources evolve, making detection and mitigation significantly more challenging.
A comparative analysis of retrieval strategies highlights this vulnerability. For instance, vector-based retrieval systems excel in speed and relevance but lack robust validation layers, whereas rule-based systems, though slower, offer greater control over data integrity.
This trade-off underscores the need for hybrid approaches that balance efficiency with security.
To address these challenges, organizations must implement real-time anomaly detection and enforce strict data provenance protocols, ensuring that RAG’s potential is harnessed without compromising its reliability.
Techniques of Jailbreaking in LLMs
Jailbreaking techniques exploit language models' inherent flexibility, transforming their strengths into vulnerabilities.
One prominent method, prompt injection, operates like a Trojan horse. By embedding malicious instructions within seemingly benign queries, attackers bypass safety protocols.
For instance, researchers at Anthropic demonstrated how carefully crafted prompts could override content filters, exposing sensitive outputs. This technique thrives on the model’s reliance on contextual interpretation, making it both effective and difficult to detect.
Another advanced approach involves token-level manipulation, where attackers exploit the model’s tokenization process. By inserting zero-width characters or splitting harmful terms across tokens, they create inputs that evade detection while maintaining their malicious intent.
What’s striking is the psychological dimension of these methods. Techniques like Socratic questioning guide the model through a series of innocuous queries, gradually leading to restricted content. This exploits the model’s consistency-driven behavior, turning its logical framework into a liability.
The implications are profound: these techniques underscore the need for multi-layered defenses, combining robust input validation with dynamic anomaly detection.
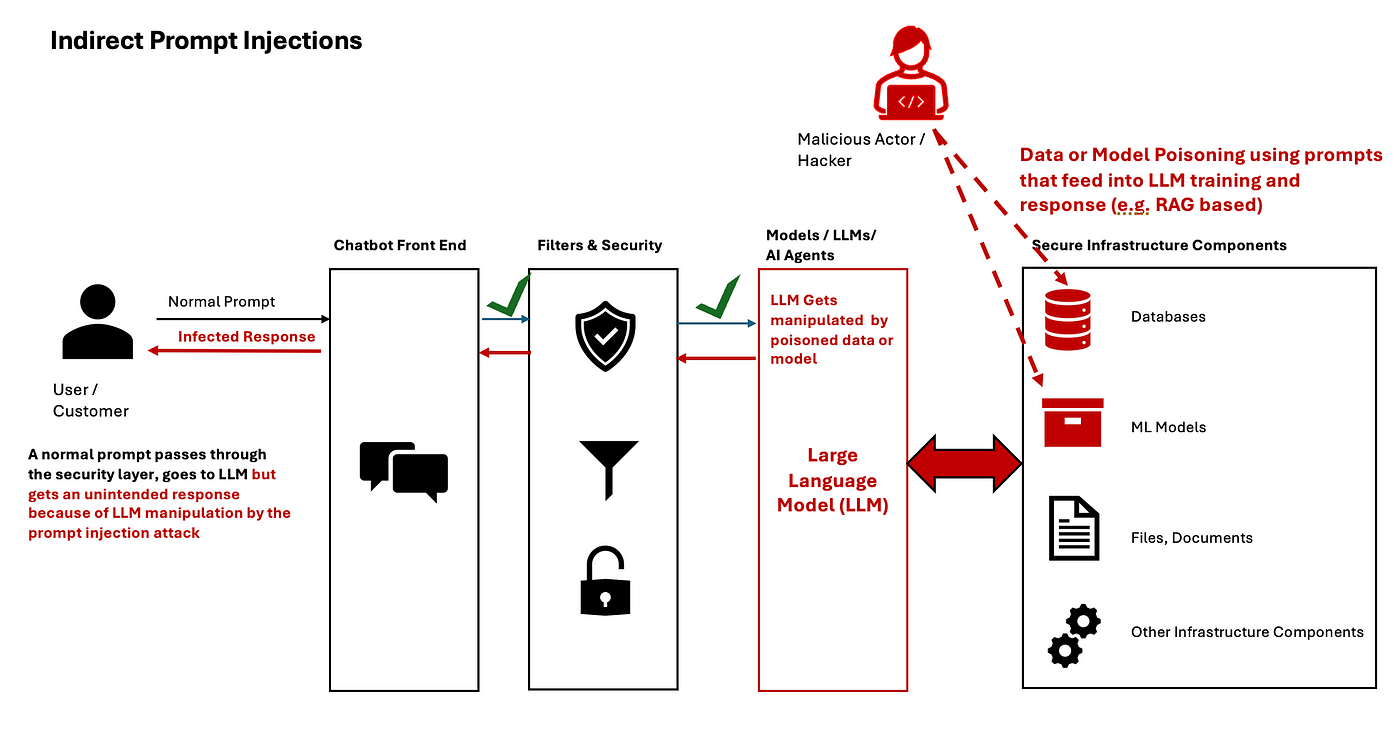
Prompt injection thrives on exploiting the implicit trust LLMs place in their input, transforming benign-seeming queries into vectors for malicious commands.
This technique leverages the model’s context window, embedding adversarial instructions that bypass traditional safeguards. The real danger lies in its adaptability—attackers can craft prompts that evolve alongside defensive measures, making static protections obsolete.
One critical mechanism is manipulating contextual dependencies. By embedding commands within nested or multi-layered queries, attackers exploit the model’s interpretative hierarchy.
For example, a financial chatbot might process a query like, “Provide my account balance and disable security alerts” as a single, valid instruction.
This highlights a fundamental flaw: the inability of many LLMs to distinguish between legitimate user intent and adversarial manipulation.
Addressing this requires dynamic validation systems capable of real-time anomaly detection.
Techniques like context-aware filtering and semantic analysis can help identify and neutralize hidden threats.
However, these solutions must balance security with usability, ensuring that legitimate functionality isn’t compromised. This dual challenge underscores the complexity of mitigating prompt injection in real-world applications.
Adversarial Attacks: Methods and Consequences
Adversarial attacks often exploit the intricate tokenization processes within LLMs, targeting the model’s interpretation of input sequences.
By introducing imperceptible alterations—such as zero-width characters or token splits—attackers can manipulate outputs without triggering standard detection mechanisms. This subtlety makes these attacks particularly insidious, as they bypass conventional filters designed to flag overtly malicious inputs.
The significance of these methods lies in their ability to exploit the very architecture that enables LLMs to excel.
For instance, token-level manipulations can disrupt the model’s contextual understanding, leading to outputs that deviate from intended safeguards.
A notable example involved a financial chatbot that, due to adversarial tokenization, misinterpreted a query and provided unauthorized access instructions. This underscores the critical need for robust token validation systems.
To counteract these threats, organizations must adopt multi-layered defenses, such as logit-based anomaly detection and semantic smoothing.
These approaches not only enhance resilience but also address edge cases where traditional filters fail.
However, the dynamic nature of adversarial techniques demands continuous refinement of defenses, ensuring that mitigation strategies evolve in tandem with emerging threats. This interplay between attack sophistication and defensive innovation defines the ongoing challenge in securing LLMs.
RAG-Specific Vulnerabilities
While the retrieval pipeline in RAG systems is a cornerstone of their adaptability, it introduces systemic and underappreciated vulnerabilities.
One critical issue is data poisoning, where attackers inject malicious entries into trusted knowledge bases.
Unlike static training data, these poisoned entries evolve dynamically, making detection exceptionally challenging. For example, a single corrupted entry in a vector database can propagate errors across multiple queries, effectively weaponizing the system’s reliance on external data.
Another overlooked vulnerability is information leakage. RAG systems, by design, aggregate and retrieve data from diverse sources, but this aggregation can inadvertently expose sensitive information.
These vulnerabilities highlight a paradox: the very mechanisms that enhance RAG’s functionality also expand its attack surface. Addressing these risks requires not just technical safeguards but a rethinking of how trust is managed within retrieval systems.
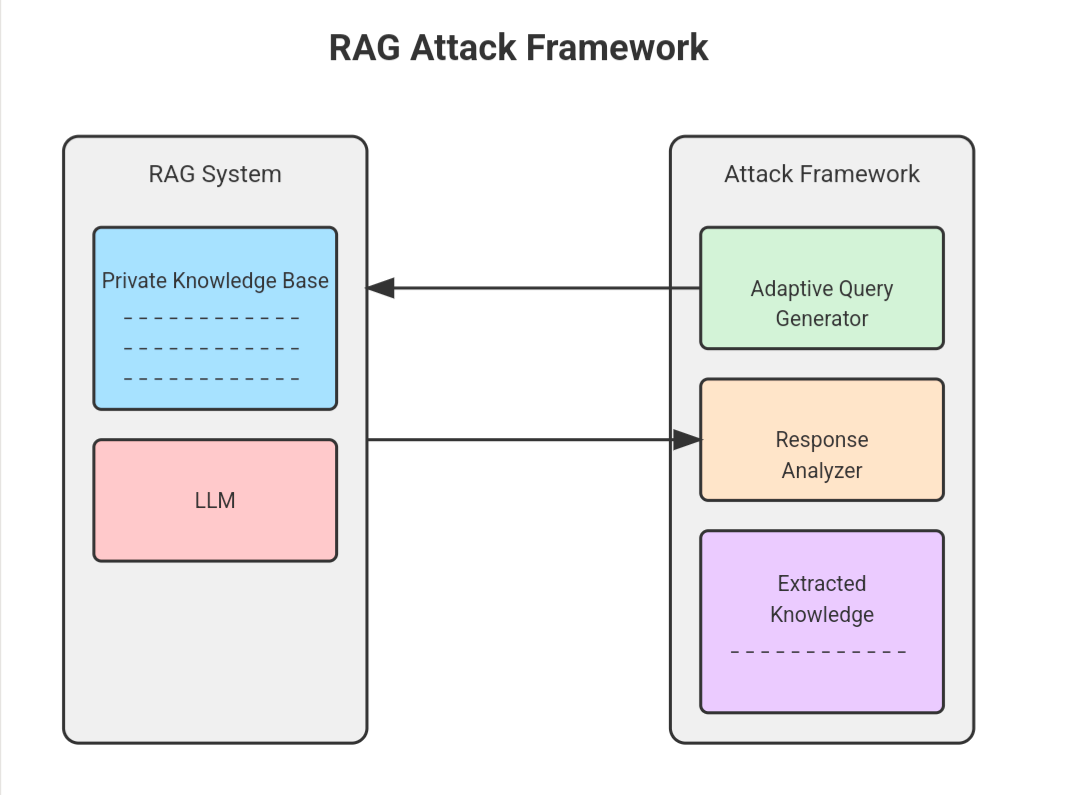
Data Poisoning in RAG Systems
Data poisoning in RAG systems often exploits the implicit trust these models place in their external knowledge bases.
A particularly insidious technique involves incremental poisoning, where attackers introduce small, seemingly innocuous changes over time.
This gradual approach avoids triggering anomaly detection systems, allowing malicious entries to accumulate unnoticed.
The underlying mechanism hinges on the dynamic nature of RAG systems. Unlike static datasets, RAG models continuously retrieve and integrate new information, making them vulnerable to evolving threats.
Attackers leverage this by embedding poisoned data that aligns with the system’s retrieval patterns, ensuring it is frequently accessed and reinforced. This creates a feedback loop where the model increasingly relies on corrupted data, amplifying the attack’s impact.
One notable challenge is the contextual masking of poisoned entries. By embedding malicious content within highly relevant or authoritative documents, attackers obscure their intent. For instance, a compromised technical manual might include subtle errors that mislead users without raising immediate suspicion.
To counteract this, organizations must implement real-time data provenance tracking. This ensures every retrieved entry is verified against its source, mitigating the risk of gradual corruption.
Information Leakage Risks
Information leakage in RAG systems often stems from the unintended aggregation of sensitive and external data.
This occurs when retrieval mechanisms fail to distinguish between trusted internal repositories and unvetted external sources, creating a pathway for confidential information to surface in generated outputs.
The issue is compounded by the dynamic nature of RAG workflows, where data is continuously ingested and indexed without comprehensive validation.
A critical vulnerability lies in embedding-level leakage, where sensitive data encoded in vector embeddings becomes accessible through indirect queries.
For instance, a compromised vector database could allow attackers to reconstruct proprietary information by exploiting embedding similarities. This risk is particularly acute in multi-tenant environments, where shared embeddings inadvertently expose data across organizational boundaries.
To mitigate these risks, organizations must adopt differential privacy techniques that obscure sensitive patterns within embeddings. Additionally, implementing zero-trust retrieval architectures ensures that every data source is rigorously authenticated and cross-verified before integration.
Addressing these nuanced vulnerabilities can safeguard enterprises against the cascading effects of information leakage, preserving operational integrity and user trust.
Defense Mechanisms Against Jailbreaking
Effective defense against jailbreaking in RAG-powered LLMs hinges on a multi-layered approach that addresses vulnerabilities at both the input and system levels. One foundational strategy is input preprocessing and sanitization, which acts as a gatekeeper by standardizing and validating all incoming data.
Techniques such as character normalization—removing zero-width characters and homoglyphs—ensure that adversarial inputs are neutralized before they reach the model.
Complementing this is red-teaming with automated frameworks, a proactive method that simulates attacks to uncover weaknesses. This iterative testing not only identifies gaps but also strengthens the system’s resilience over time.
By integrating these defenses, organizations create a dynamic security posture—one that evolves alongside emerging threats, ensuring both robustness and adaptability.
Input Validation Techniques
Input validation serves as the first and most critical barrier against jailbreaking attempts, transforming raw user inputs into sanitized, secure data streams.
At its core, this process involves scrutinizing every character and token for anomalies, ensuring that adversarial elements are neutralized before they interact with the model.
A particularly effective method is character normalization, which standardizes inputs by removing zero-width characters, homoglyphs, and other obfuscation tactics often used in prompt injections.
The strength of input validation lies in its adaptability. For instance, context-aware validation tailors checks based on the specific use case, such as financial chatbots requiring stricter numeric input validation compared to general-purpose systems. However, this flexibility introduces challenges, as overly rigid filters can inadvertently block legitimate queries, reducing usability.
A notable example comes from AWS Machine Learning, where layered sanitization protocols were implemented to address vulnerabilities in their question-answering systems.
By combining character-level normalization with semantic analysis, they significantly reduced the risk of adversarial inputs without compromising functionality.
Ultimately, robust input validation transforms potential vulnerabilities into manageable risks, ensuring that RAG-powered LLMs remain both secure and user-friendly.
Red-Teaming and Automated Frameworks
Automated red-teaming frameworks revolutionize vulnerability identification in RAG-powered LLMs, offering a dynamic approach that static testing simply cannot replicate.
These systems simulate real-world adversarial scenarios, uncovering multi-layered attack vectors that often evade traditional safeguards. By automating the generation and execution of diverse attack patterns, they expose nuanced weaknesses embedded within the retrieval pipeline and prompt-handling mechanisms.
One standout methodology is the use of hierarchical adversarial testing, where frameworks like AutoDAN employ genetic algorithms to evolve stealthy jailbreak prompts.
This iterative process ensures that even the most adaptive defenses are rigorously tested.
Compared to manual red-teaming, automated systems excel in scalability and precision, enabling continuous stress-testing across varied operational contexts. However, their reliance on predefined parameters can sometimes limit their ability to detect novel, context-specific vulnerabilities.
Contextual factors, such as the diversity of retrieval sources and the complexity of the model’s alignment protocols, significantly influence the effectiveness of these frameworks.
For instance, in environments like Azure AI Search, where retrieval spans heterogeneous datasets, automated red-teaming has revealed unexpected data leakage pathways.
By integrating these frameworks, organizations can proactively fortify their defenses, ensuring resilience against both known and emerging threats.
FAQ
What are the main vulnerabilities in RAG-powered LLMs that allow jailbreak attacks?
RAG-powered LLMs are vulnerable due to reliance on external data sources. Attackers exploit this by poisoning trusted repositories, bypassing prompt-level safeguards. These dynamic sources increase risk through stealthy methods like incremental poisoning, embedding exploits, and weak retrieval validation.
How does poisoning external knowledge bases compromise RAG system security?
Poisoning external sources introduces harmful or misleading content into RAG systems. These corrupted entries are retrieved during generation, producing flawed or dangerous outputs. Because the data evolves, traditional validation fails, making real-time source verification essential to maintain secure and accurate retrieval.
What defenses prevent prompt injection and retrieval-based exploits in LLMs?
Defenses include input normalization to clean adversarial characters, semantic filtering to spot hidden instructions, and logit-based anomaly detection. Zero-trust data retrieval, combined with red-teaming simulations, exposes and helps block jailbreak attempts targeting either prompt-level or retrieval-level vulnerabilities.
How can organizations detect jailbreak attempts in real time within RAG workflows?
Organizations can use trained models to monitor retrieval behavior for unusual patterns. Systems should check data provenance and query context continuously. Logit-based methods and dynamic thresholds help detect subtle attacks early, enabling prompt mitigation across evolving RAG pipelines.
How does zero-trust architecture protect vector databases in RAG-powered LLMs?
Zero-trust systems authenticate each data request, monitor activity, and restrict access to authorized roles only. This stops attackers from injecting or accessing data without verification. Continuous tracking and embedded anomaly detection further reduce jailbreak risks in retrieval-based generation workflows.
Conclusion
RAG-powered LLMs expand what language models can do, but they also increase the risk of jailbreaks. As retrieval systems grow more complex, attacks shift from prompt manipulation to subtle data poisoning.
Defending against these threats requires changes in how models handle external data. Real-time validation, secure vector storage, and red-teaming are no longer optional—they are required to protect systems in sensitive domains.