
How to Set Up Local LLM and RAG Systems Securely
Setting up local LLM and RAG systems offers control and privacy but requires strong security practices. This guide walks you through secure deployment, data protection strategies, and compliance tips for building private, on-premise AI solutions.


Most AI tools today rely on the cloud. That’s fast, convenient—yet often a risk.
Sensitive data can leave your environment, quietly, through APIs, third-party storage, or misconfigured access.
This has made privacy a growing concern for teams working with internal data, proprietary research, or regulated workflows.
That’s where local deployment comes in.
Running large language models and Retrieval-Augmented Generation systems on your own infrastructure gives you more control, but also more responsibility. You’re now in charge of encryption, access control, compliance, and performance—all at once.
This guide breaks down how to set up local LLM and RAG systems securely, with a focus on practical architecture choices, secure indexing, query validation, and hardware configuration.
Whether you’re building for healthcare, finance, or internal enterprise tools, the goal is simple: keep your data private, keep your system fast, and make no trade-offs on security.
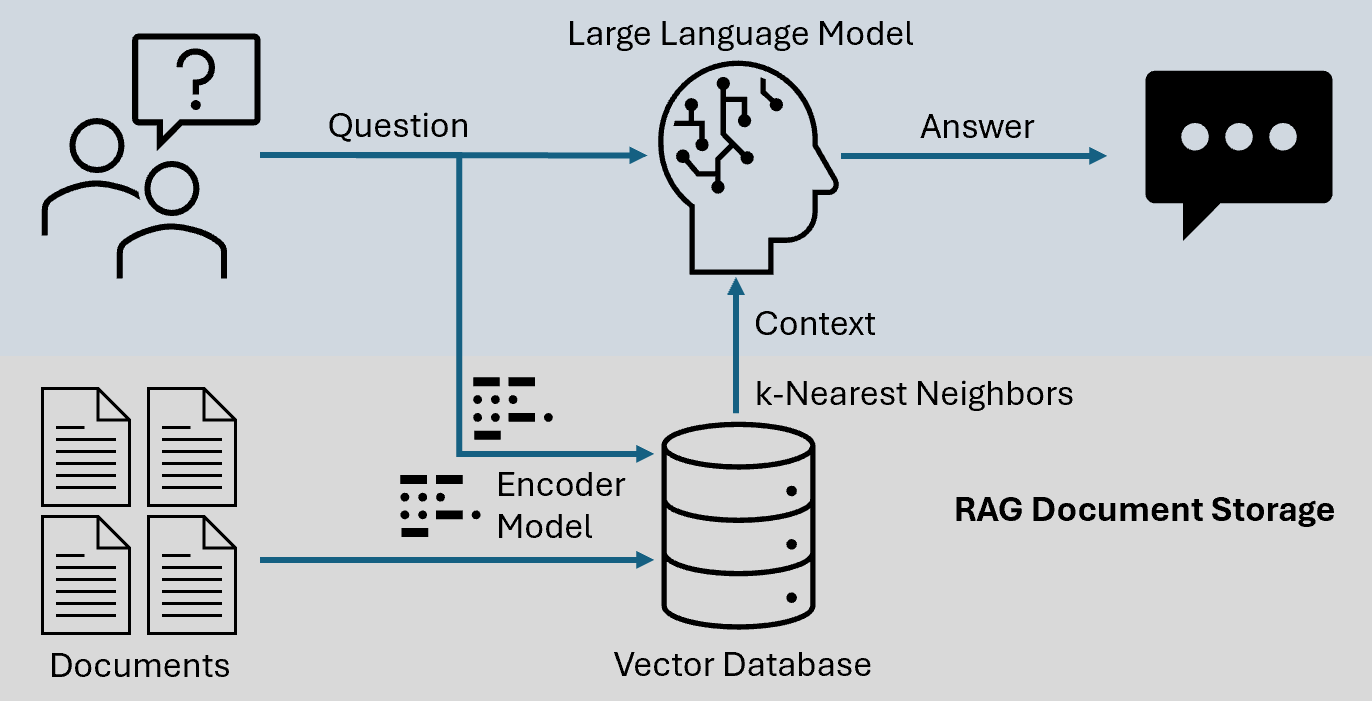
Core Concepts of LLM and RAG
The interplay between vector embeddings and semantic search forms the backbone of RAG systems, yet their nuanced role in optimizing retrieval often goes underappreciated.
At its core, vector embeddings translate text into numerical representations, enabling the system to identify semantic relationships rather than relying on exact keyword matches. This capability is pivotal for handling ambiguous or context-heavy queries.
What makes this process transformative is its adaptability.
Organizations can significantly enhance retrieval accuracy by fine-tuning embedding models for specific domains.
For instance, a healthcare provider might train embeddings to prioritize medical terminology, ensuring that responses align with clinical relevance. However, this customization introduces challenges, such as balancing domain specificity with generalizability—a tension that requires careful calibration.
One overlooked complexity is the impact of chunking strategies on retrieval performance.
Breaking documents into smaller, semantically coherent units can improve precision but risks fragmenting context. Practical implementations often involve iterative experimentation to find the optimal chunk size for a given dataset.
These dynamics underscore the importance of tailoring RAG systems to their operational context, ensuring both accuracy and scalability.
Benefits of Local Deployment
Local deployment offers unparalleled control over sensitive data, a critical advantage in industries like healthcare and finance.
Keeping all operations within an organization’s infrastructure significantly reduces the risk of data exposure to third-party services. This control is vital when dealing with stringent regulations such as GDPR or HIPAA, where even minor breaches can lead to severe penalties.
One often-overlooked aspect is the ability to fine-tune system performance based on specific hardware configurations.
Unlike cloud-based solutions, local setups allow for precise optimization of both the model and the retrieval mechanisms, ensuring minimal latency and higher throughput. For example, a legal firm deploying a local RAG system can prioritize rapid access to case files without compromising confidentiality.
However, local deployment does come with challenges, such as higher upfront costs and the need for specialized expertise.
Yet, the benefits far outweigh these initial hurdles for organizations prioritizing data sovereignty and long-term cost efficiency.
System Architecture for Secure Local Deployment
A secure local deployment begins with a modular architecture that isolates critical components while maintaining seamless data flow.
At its core, this design ensures that sensitive data remains protected without compromising system performance.
For instance, data encryption must be implemented at multiple levels—both at rest and in transit—using advanced algorithms like AES-256. This layered encryption approach prevents unauthorized access even if one layer is breached.
Role-based access control (RBAC) should be integrated into the system to further enhance security.
Organizations can limit access to sensitive data and functions by assigning granular permissions based on user roles.
For example, a healthcare provider might restrict access to patient records to only authorized clinicians, while administrative staff can view anonymized data for operational purposes.
A critical yet often overlooked element is query validation. By implementing input sanitization and anomaly detection mechanisms, the system can identify and block malicious queries before they reach the vector database.
This proactive measure safeguards data integrity and ensures uninterrupted system availability.
The architecture must also account for scalability and fault tolerance. Distributed vector databases, such as Milvus or Pinecone, can handle high-dimensional data efficiently while maintaining redundancy to prevent downtime.
This ensures that the system remains responsive and secure even under heavy loads.
By treating each component as part of an interconnected ecosystem, organizations can balance robust security and optimal performance, setting a new standard for local LLM and RAG deployments.
Components of a Secure System
One critical yet often underestimated component of a secure system is query validation.
This mechanism acts as the first line of defense, scrutinizing every user input to detect and block malicious queries before they interact with the vector database.
By filtering out harmful prompts, query validation prevents injection attacks that could compromise sensitive data or manipulate system behavior.
What makes query validation indispensable is its adaptability to context. For instance, in healthcare, validation rules can be tailored to flag queries attempting to access unauthorized patient records.
This contextual sensitivity ensures that the system blocks generic threats and addresses domain-specific vulnerabilities.
However, implementing this requires a balance between strict validation and maintaining user experience, as overly aggressive filters can disrupt legitimate workflows.
A nuanced approach involves integrating machine learning models trained to identify malicious behaviour patterns.
These models evolve with emerging threats, offering a dynamic layer of protection.
By combining static rules with adaptive intelligence, organizations can create a robust validation framework that aligns security with usability, ensuring seamless yet secure operations.
Integrating Vector Databases
Integrating vector databases into a secure local deployment hinges on mastering adaptive indexing techniques.
These techniques ensure that high-dimensional data is not only stored efficiently but also retrieved with precision, even under complex query conditions.
Unlike static indexing, adaptive methods dynamically adjust to the evolving structure of the data, optimizing retrieval paths in real-time.
This adaptability is critical in environments where data diversity and query complexity intersect.
For instance, in legal applications, where case law and statutes are constantly updated, adaptive indexing ensures that the most relevant precedents are surfaced immediately.
However, implementing such systems requires balancing computational overhead with retrieval speed—a challenge that demands meticulous calibration.
A notable edge case arises in multilingual datasets, where semantic nuances can skew similarity metrics.
Addressing this involves fine-tuning embedding models to account for linguistic variations, ensuring equitable retrieval across languages.
By combining adaptive indexing with domain-specific embeddings, organizations can achieve a seamless integration that prioritizes both accuracy and security, setting a new benchmark for RAG systems.
Implementing Security Measures
Securing local LLM and RAG systems demands a multi-layered approach where each component reinforces the others.
A critical starting point is role-based access control (RBAC), ensuring only authorized users interact with sensitive data. For example, a healthcare organization might restrict access to patient records to clinicians while anonymizing data for research teams.
This granular control limits exposure and aligns with stringent regulations like HIPAA.
Encryption is another cornerstone, but its implementation must go beyond the basics.
While AES-256 encryption is standard for data at rest and in transit, advanced techniques like homomorphic encryption allow computations on encrypted data without decryption.
This innovation is particularly valuable in finance, where sensitive calculations can be performed securely, reducing the risk of breaches.
A common misconception is that security measures slow down system performance.
However, integrating confidential computing—using secure enclaves to isolate sensitive operations—proves otherwise.
Microsoft Azure’s confidential VMs, for instance, demonstrate how performance and security can coexist, enabling real-time processing without compromising data integrity.
The implications are clear: robust security protects data and builds trust, ensuring these systems remain viable in high-stakes industries.
Data Access Control and Encryption
Data access control and encryption must function as a unified defense mechanism, where each layer compensates for potential vulnerabilities in the other.
The interplay between these two elements is critical, especially in environments handling sensitive or regulated data.
A key principle is embedding access control metadata directly into the data itself during the indexing process.
This ensures that every query is evaluated not just for relevance but also for compliance with user permissions.
For instance, a healthcare RAG system might encode access levels into patient records, allowing only authorized clinicians to retrieve specific details. This granular approach minimizes the risk of unauthorized access while maintaining operational efficiency.
Encryption, while foundational, must extend beyond standard protocols like AES-256. Techniques such as homomorphic encryption allow computations on encrypted data, ensuring that sensitive information remains secure even during processing.
However, this method introduces computational overhead, requiring careful optimization to balance security with performance.
Ultimately, the success of these measures depends on continuous monitoring and iterative refinement, ensuring that both access control and encryption evolve alongside emerging threats.
Ensuring Compliance with Regulations
Embedding compliance into local RAG systems requires a proactive approach directly integrating regulatory frameworks into system architecture.
One critical technique is context-based access control (CBAC), which dynamically adjusts permissions based on a query's context.
Unlike static role-based models, CBAC evaluates factors such as user location, time of access, and query intent, ensuring that data retrieval aligns with both operational needs and regulatory mandates.
This approach is particularly effective in industries like healthcare, where regulations such as HIPAA demand strict control over patient data.
For example, a hospital deploying CBAC can ensure clinicians accessing records during emergencies bypass standard restrictions, while still logging these actions for audit purposes.
This balance between flexibility and accountability is key to maintaining compliance without disrupting workflows.
However, implementing CBAC introduces challenges, such as the computational overhead of real-time evaluations.
Organizations can mitigate this by leveraging federated learning to distribute processing across local nodes, reducing latency while maintaining data sovereignty.
By embedding compliance into every layer, organizations can transform regulatory adherence from a burden into a seamless, integral part of their operations.
Tools and Frameworks for Local LLM and RAG Systems
Selecting the right tools for local LLM and RAG systems is not just a technical decision—it’s a strategic one.
Frameworks like LangChain and LlamaIndex excel in modularity, enabling seamless integration of retrieval pipelines with language models.
LangChain, for instance, simplifies context-aware reasoning by offering pre-configured chains, while LlamaIndex specializes in efficient indexing for rapid data retrieval.
For secure and high-performance vector storage, ChromaDB and FAISS stand out.
ChromaDB’s encryption-first design ensures data privacy, making it ideal for regulated industries, while FAISS optimizes similarity searches across massive datasets, reducing query latency.
A common misconception is that these tools are interchangeable. In reality, their strengths vary: LangChain thrives in dynamic workflows, whereas LlamaIndex is better suited for static, structured datasets. Combining them strategically can unlock unparalleled efficiency.
Think of these frameworks as the gears in a precision machine—each must align perfectly to ensure your system's speed and security.
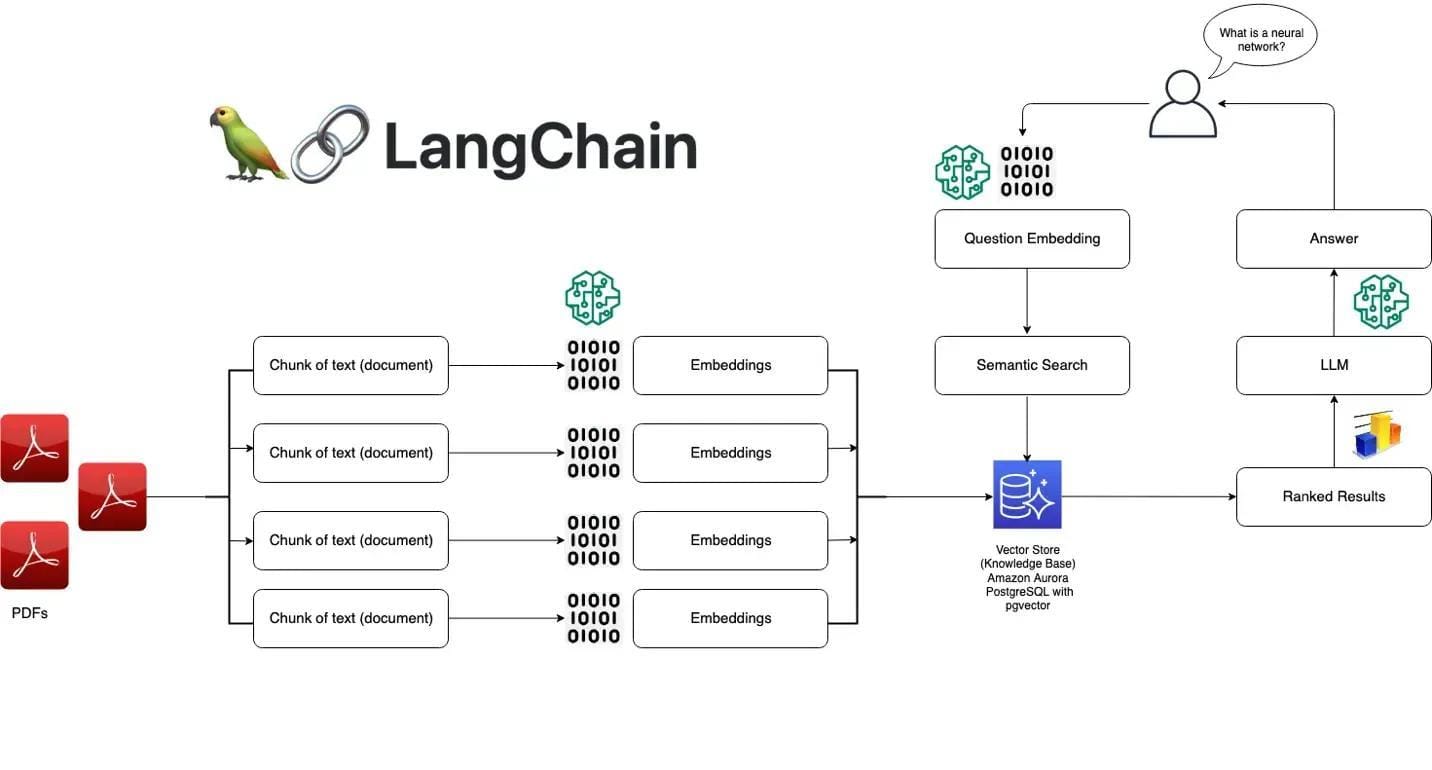
Using Ollama and LangChain
Ollama’s standout feature is its ability to run optimized models locally, offering unparalleled control over data privacy and system behavior.
This flexibility is particularly valuable when integrating with LangChain, which excels at creating modular workflows for retrieval-augmented generation (RAG) systems.
Together, these tools form a robust foundation for building secure, efficient, and context-aware applications.
One critical aspect of this integration is the seamless handling of contextual embeddings.
Ollama’s architecture supports lightweight models that generate embeddings efficiently, while LangChain’s pipeline ensures these embeddings are utilized effectively for precise data retrieval.
This synergy minimizes latency without compromising accuracy, making it ideal for real-time applications like medical diagnostics or financial analysis.
However, challenges arise when balancing computational efficiency with retrieval precision. For instance, embedding models optimized for speed may struggle with nuanced queries.
By leveraging Ollama’s adaptability and LangChain’s modularity, developers can iteratively refine their systems, ensuring they meet both performance and security demands.
This iterative approach transforms static deployments into dynamic, evolving solutions tailored to real-world complexities.
Optimizing with ChromaDB
ChromaDB’s adaptive indexing is a game-changer for retrieval performance, especially in environments where data evolves rapidly.
Unlike static indexing methods, ChromaDB dynamically adjusts its retrieval paths based on the structure and frequency of incoming queries. This ensures that retrieval remains precise and efficient even as datasets grow or shift.
The real strength of this approach lies in its ability to balance speed with security.
ChromaDB ensures that sensitive data is protected without adding significant overhead by embedding encryption protocols directly into the indexing process.
This dual focus on performance and privacy makes it particularly effective in regulated industries like healthcare, where compliance is non-negotiable.
One notable edge case involves multilingual datasets. ChromaDB’s indexing can be fine-tuned to account for linguistic variations, ensuring equitable retrieval across languages.
This capability is critical for global organizations managing diverse data sources. However, achieving this requires carefully calibrating embedding models to avoid skewed similarity metrics.
By integrating ChromaDB, developers can create systems that meet current demands and scale seamlessly with future complexities.
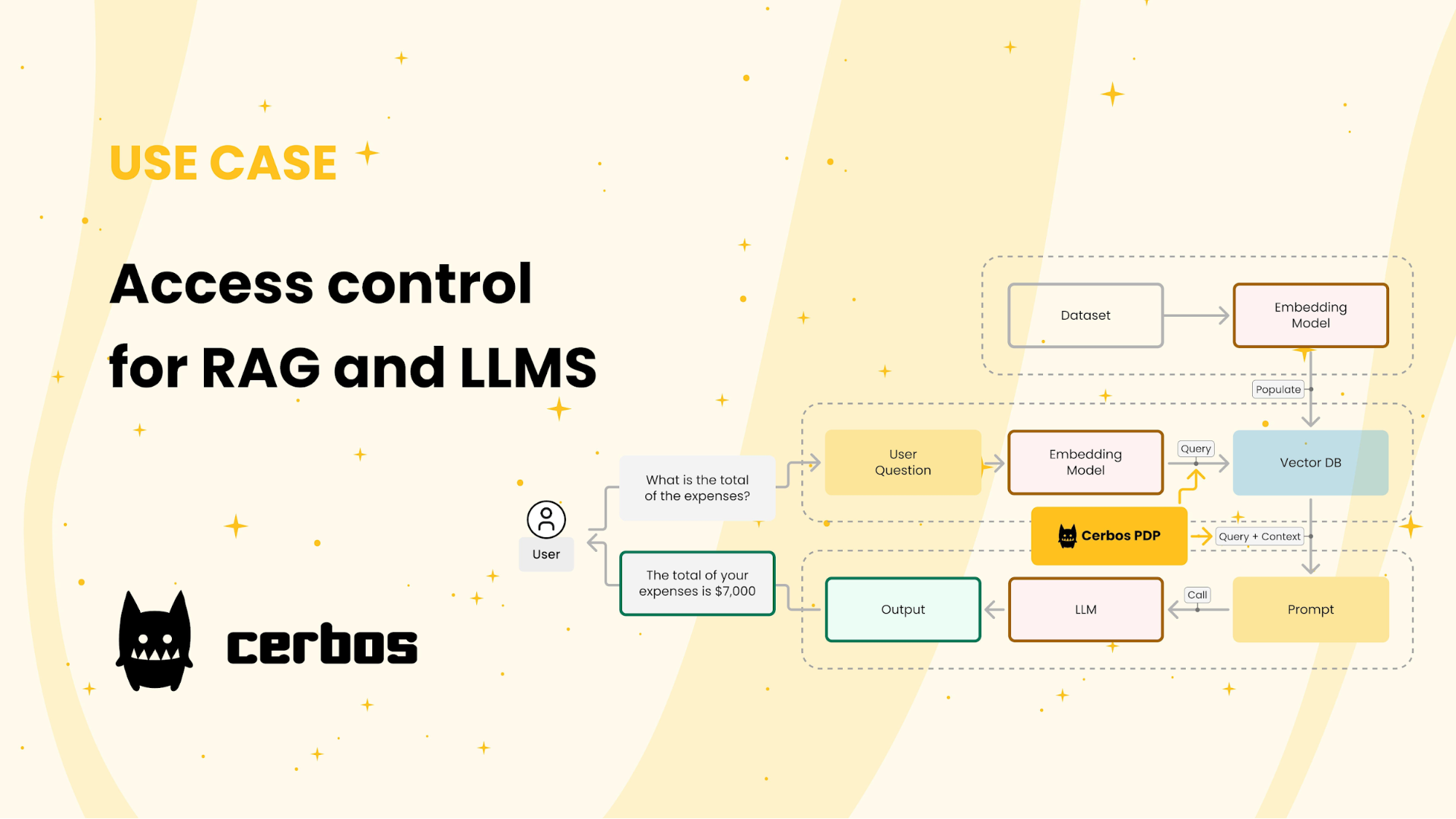
Advanced Security: Fine-Grained Authorization
Fine-grained authorization (FGA) transforms static access control into a dynamic, context-aware system, ensuring that permissions adapt in real time to organizational changes.
Unlike traditional role-based models, FGA evaluates multiple attributes—such as user roles, resource types, and contextual factors like time or location—to enforce precise access rules.
This adaptability is critical in healthcare environments where patient confidentiality and regulatory compliance intersect.
For example, a hospital using Permit.io integrates FGA with its RAG system to ensure that only authorized clinicians access specific diagnoses during their assigned shifts.
This setup prevents unauthorised access and dynamically adjusts permissions when staff roles or assignments change.
A key technical innovation here is relationship-based access control (ReBAC), which models complex hierarchies and dependencies.
Think of it as a living map of permissions, where every node reflects real-world relationships. This approach minimizes security gaps while maintaining operational fluidity, setting a new standard for secure AI applications.
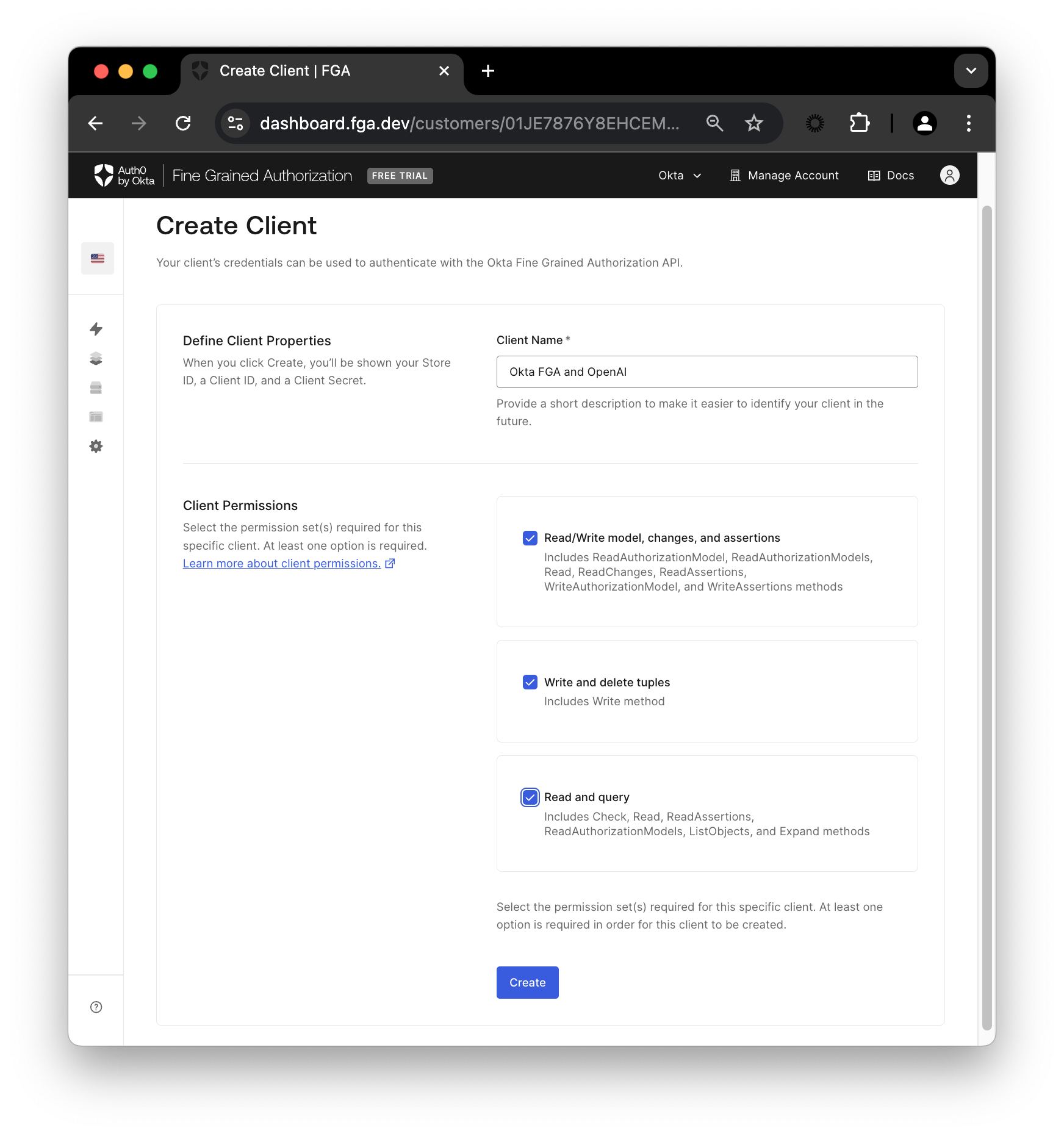
Implementing FGA in RAG Systems
Integrating fine-grained authorization (FGA) into Retrieval-Augmented Generation (RAG) systems hinges on the precise orchestration of contextual access controls.
This involves dynamically evaluating user attributes, resource types, and environmental conditions to determine access permissions in real time. This approach ensures that sensitive data remains protected while maintaining the system’s responsiveness to complex queries.
One critical technique is attribute-based query filtering, where access decisions are embedded directly into the retrieval pipeline. For instance, when a user submits a query, the system evaluates attributes such as their role, location, and time of access before even initiating a search.
This preemptive filtering enhances security and reduces computational overhead by narrowing the scope of data retrieval.
A notable challenge arises in multi-tenant environments, where overlapping permissions can lead to conflicts.
To address this, organizations like WorkOS have implemented hierarchical policy models that resolve ambiguities by prioritizing the most restrictive rules. This ensures that no unauthorized data is inadvertently exposed, even in highly complex setups.
By embedding FGA into RAG workflows, organizations achieve a seamless balance between robust security and operational efficiency, setting a new benchmark for secure AI applications.
Case Studies in Healthcare and Finance
In healthcare, fine-grained authorization (FGA) becomes indispensable when managing access to sensitive patient data.
A standout example is the implementation of context-aware access controls in a hospital network. Here, permissions dynamically adjust based on real-time factors such as the clinician’s current assignment or the situation's urgency.
For instance, an attending physician might gain temporary access to a patient’s full medical history during an emergency, while administrative staff are restricted to anonymized records. This approach safeguards privacy and ensures operational efficiency during critical moments.
FGA plays a pivotal role in securing transaction data in the financial sector.
A notable case involved a multinational bank that integrated attribute-based access control (ABAC) to filter access based on transaction sensitivity and user roles.
By embedding access policies directly into the retrieval pipeline, the system could evaluate attributes like transaction type, time, and user department before granting access. This granular control minimized the risk of unauthorized access while maintaining seamless workflows.
These cases highlight how FGA transforms security from a static framework into a dynamic, context-sensitive system when tailored to specific industry needs.
Hardware Optimization for Performance
Achieving peak performance in local LLM and RAG systems hinges on aligning hardware capabilities with workload demands.
A common misconception is that more powerful hardware always equates to better results. In reality, efficiency stems from tailoring resources to specific tasks. For instance, as demonstrated by llama, hybrid inference, which combines CPU and GPU processing, can significantly reduce latency when VRAM is limited.cpp’s ability to optimize resource use dynamically.
Consider the interplay between quantization levels and hardware constraints. Lower-bit quantization, such as 4-bit or 5-bit, reduces memory consumption while maintaining model accuracy, enabling even mid-tier setups to handle complex queries.
This approach transforms hardware limitations into opportunities for cost-effective scaling.
Think of hardware optimization as tuning an orchestra: each component—CPU, GPU, RAM—must harmonize with the system’s architecture.
By leveraging modular designs and adaptive configurations, organizations can achieve speed and security without overprovisioning resources.
Balancing CPU and GPU Resources
Calibrating the interplay between CPUs and GPUs in local LLM and RAG systems is less about raw power and more about strategic task allocation. GPUs excel at parallel processing, making them indispensable for computationally heavy tasks like matrix multiplications in model inference.
However, CPUs are pivotal in orchestrating these operations, handling data preprocessing, and managing I/O tasks.
Neglecting this balance can lead to underutilized CPUs becoming bottlenecks, even when GPUs operate at peak efficiency.
Profiling workflows is essential to identify which tasks demand GPU acceleration and which can be offloaded to CPUs.
For instance, embedding generation benefits from GPU parallelism, while query validation and data sanitization are often better suited for CPUs due to their sequential nature. This division optimises performance and reduces energy consumption and hardware strain.
A nuanced approach, such as dynamically adjusting workloads based on real-time resource availability, ensures harmony between components.
This orchestration enhances throughput and mitigates risks of overloading, reinforcing system efficiency and security.
Selecting the Right Hardware
Choosing hardware for local LLM and RAG systems is less about raw power and more about achieving synergy between components.
A common pitfall is overinvesting in GPUs while neglecting the CPU’s role in managing data preprocessing and orchestration. This imbalance often leads to underutilized GPUs, wasting both potential and budget.
The key lies in tailoring hardware to workload demands.
GPUs excel at parallel tasks like model inference, while CPUs handle sequential operations such as query validation and I/O management.
For instance, hybrid inference setups, which distribute tasks between CPUs and GPUs, can optimize performance when VRAM is limited. This approach ensures that neither component becomes a bottleneck.
An overlooked factor is the impact of quantization levels.
Lower-bit quantization reduces memory usage, enabling even mid-tier hardware to support complex models. However, this requires careful calibration to maintain accuracy, particularly in nuanced applications like legal or medical RAG systems.
By focusing on balance and adaptability, organizations can achieve high performance without overprovisioning, ensuring that every component contributes effectively to the system’s overall efficiency.

FAQ
What key components are required to set up a secure local LLM and RAG system?
A secure local LLM and RAG setup needs strong encryption, a reliable vector database, access control, query validation, and tuned hardware. Each part must work together to keep data protected while supporting real-time performance.
How does data encryption enhance the security of local LLM and RAG deployments?
Encryption protects local LLM and RAG systems by securing data during storage and transfer. Advanced methods like homomorphic encryption allow safe processing without exposing raw data, reducing the risk of leaks or misuse.
What are the best practices for integrating vector databases into a secure local RAG architecture?
Use encryption and access control when adding a vector database to a local RAG system. Apply adaptive indexing, limit network access, and validate all queries to keep data safe without slowing down retrieval.
How can role-based access control (RBAC) and fine-grained authorization improve data protection in local LLM systems?
RBAC limits access by user role, while fine-grained authorization adds real-time checks like location or task. Together, they block unauthorized use and reduce data exposure in local LLM systems.
What hardware configurations are optimal for balancing performance and security in local LLM and RAG setups?
The best setup combines CPUs and GPUs for shared workloads. Use quantized models to lower memory use. Secure enclaves and encrypted memory help keep sensitive data safe during processing.
Conclusion
Local LLM and RAG systems offer a way to run advanced AI without sending data offsite, but they require thoughtful design.
Secure setup means more than turning on encryption—it involves choosing the right tools, managing access, and staying aligned with regulations.
By focusing on simple rules like isolation, validation, and tuned hardware, organizations can build systems that are both safe and fast. As AI grows, local deployment isn’t just a privacy choice—it’s becoming a necessity.