
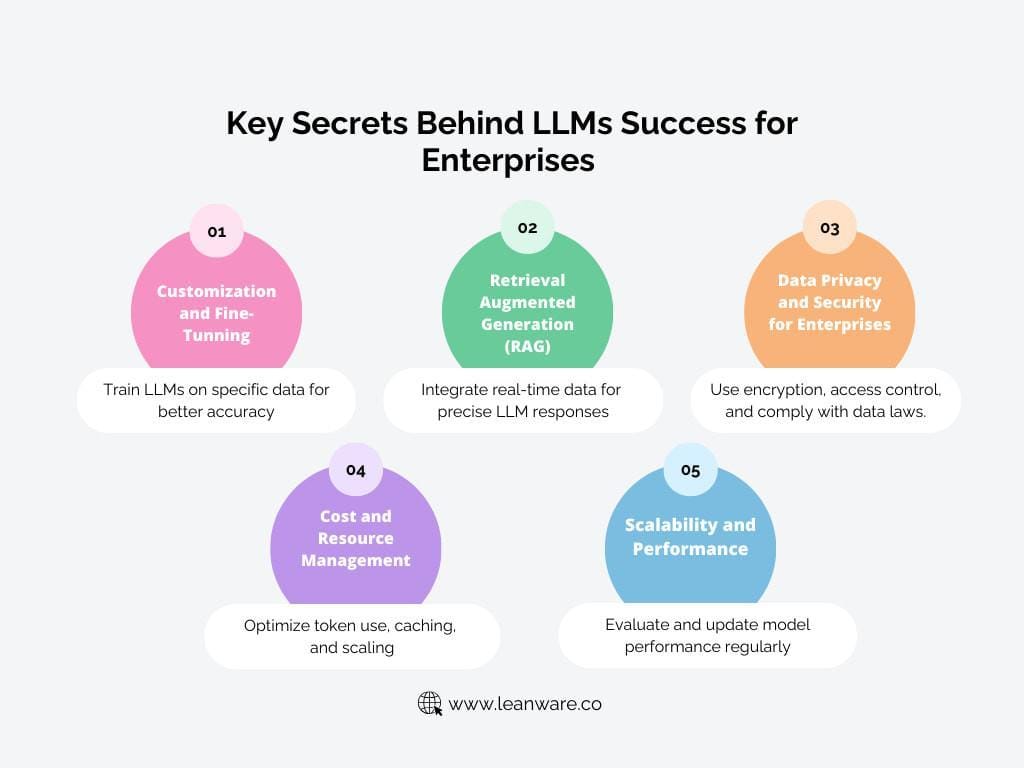
Comparing Local LLMs vs. OpenAI for RAG: Accuracy and Cost
Local LLMs and OpenAI offer different advantages for RAG. This guide compares accuracy, cost, and performance to help you decide the best approach for retrieval-augmented generation, balancing efficiency, affordability, and scalability.


Companies are racing to build AI systems that can retrieve and generate real-time information with precision.
The problem?
The choice between local large language models (LLMs) and OpenAI’s cloud-based models isn’t just about cost but accuracy, control, and long-term sustainability.
Some organizations prioritize data privacy and fine-tuning, making local LLMs the clear winner. Others prefer scalability and reduced infrastructure overhead, opting for OpenAI’s cloud models. The trade-offs go beyond technical performance, shaping how businesses adopt AI in healthcare, finance, and customer support industries.
This article explains the differences in accuracy, deployment costs, scalability, and security, helping organizations decide whether local LLMs or OpenAI are suitable for their Retrieval-Augmented Generation (RAG) systems.
This alignment becomes critical as industries like healthcare and finance increasingly adopt RAG systems to handle sensitive, domain-specific queries.
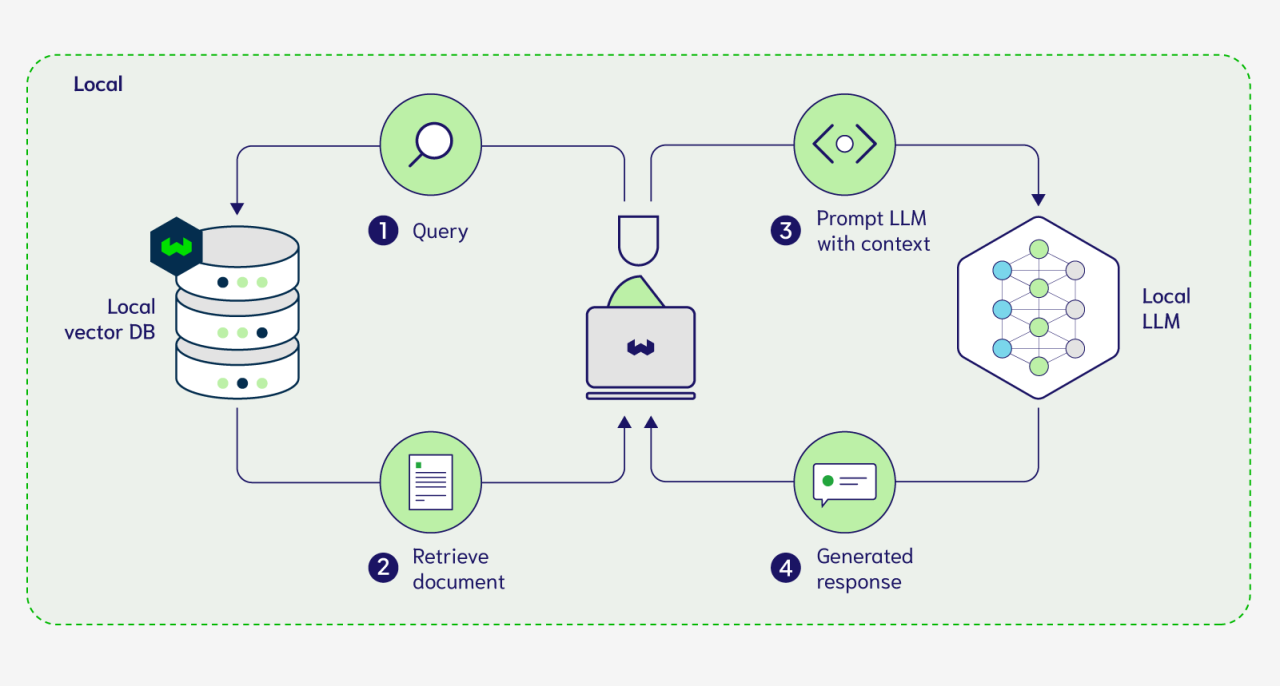
Understanding Retrieval Augmented Generation
Retrieval-Augmented Generation (RAG) thrives on its ability to bridge static model training with dynamic, real-time data retrieval, a feature that fundamentally transforms how LLMs operate.
At its core, RAG integrates two critical components: a retrieval system fetching relevant, context-specific data and a generative model synthesizing it into coherent outputs.
This synergy ensures that responses are accurate and contextually aligned with the latest information.
One often overlooked nuance is the role of retrieval precision. Poorly indexed or ambiguous data sources can derail the entire process, leading to irrelevant or misleading outputs.
For instance, a healthcare chatbot powered by RAG must retrieve the most recent medical guidelines to provide accurate advice.
Organizations must invest in robust metadata tagging and domain-specific retrieval strategies to implement RAG effectively.
This ensures that the retrieved data aligns seamlessly with user queries, maximizing relevance and reliability. By addressing these complexities, RAG becomes a practical tool for real-world applications far beyond its theoretical potential.
Overview of Local LLMs and OpenAI
Local LLMs excel in offering unparalleled customization, a feature that becomes critical when addressing niche industry needs.
Unlike OpenAI’s cloud-based models, which operate within predefined parameters, local deployments allow organizations to fine-tune models to align with specific workflows.
This capability is particularly advantageous in sectors like legal or healthcare, where domain-specific language and compliance requirements demand tailored solutions.
However, this flexibility comes with significant technical and financial overhead. Running local LLMs requires robust infrastructure, including high-performance GPUs like NVIDIA A100s, and ongoing maintenance to ensure optimal performance.
In contrast, OpenAI’s models eliminate these burdens by providing a plug-and-play solution, albeit at the cost of reduced control over data handling and model behavior.
Latency is a critical yet often overlooked factor. Local models, when optimized, can deliver responses faster than cloud-based systems, especially in environments with limited internet connectivity.
This advantage is amplified in real-time applications like customer support, where response speed directly impacts user satisfaction.
Ultimately, the decision depends on whether an organization prioritizes granular control and customization over the convenience of managed services.
Evaluating Model Performance and Accuracy
Assessing accuracy in Retrieval-Augmented Generation (RAG) requires more than just measuring how often a model generates correct answers. The true test is whether responses are contextually precise and reliable in real-world applications.
Two key factors define performance: retrieval quality and response synthesis.
A system must first identify the most relevant data before ensuring the output aligns with user intent.
Models trained for general-purpose tasks often struggle with domain-specific queries, where terminology and context demand fine-tuned retrieval.
Local LLMs offer greater adaptability, allowing for custom optimizations that enhance accuracy in specialized fields like legal research, healthcare, and finance.
OpenAI’s cloud models, by contrast, maintain consistency across diverse topics but may misinterpret industry-specific language.
Choosing between local or cloud-hosted LLMs depends on whether an organization values broad adaptability or domain-specific accuracy.
While pre-trained models provide fast, general responses, fine-tuned local systems bridge knowledge gaps by adapting to specialized tasks.
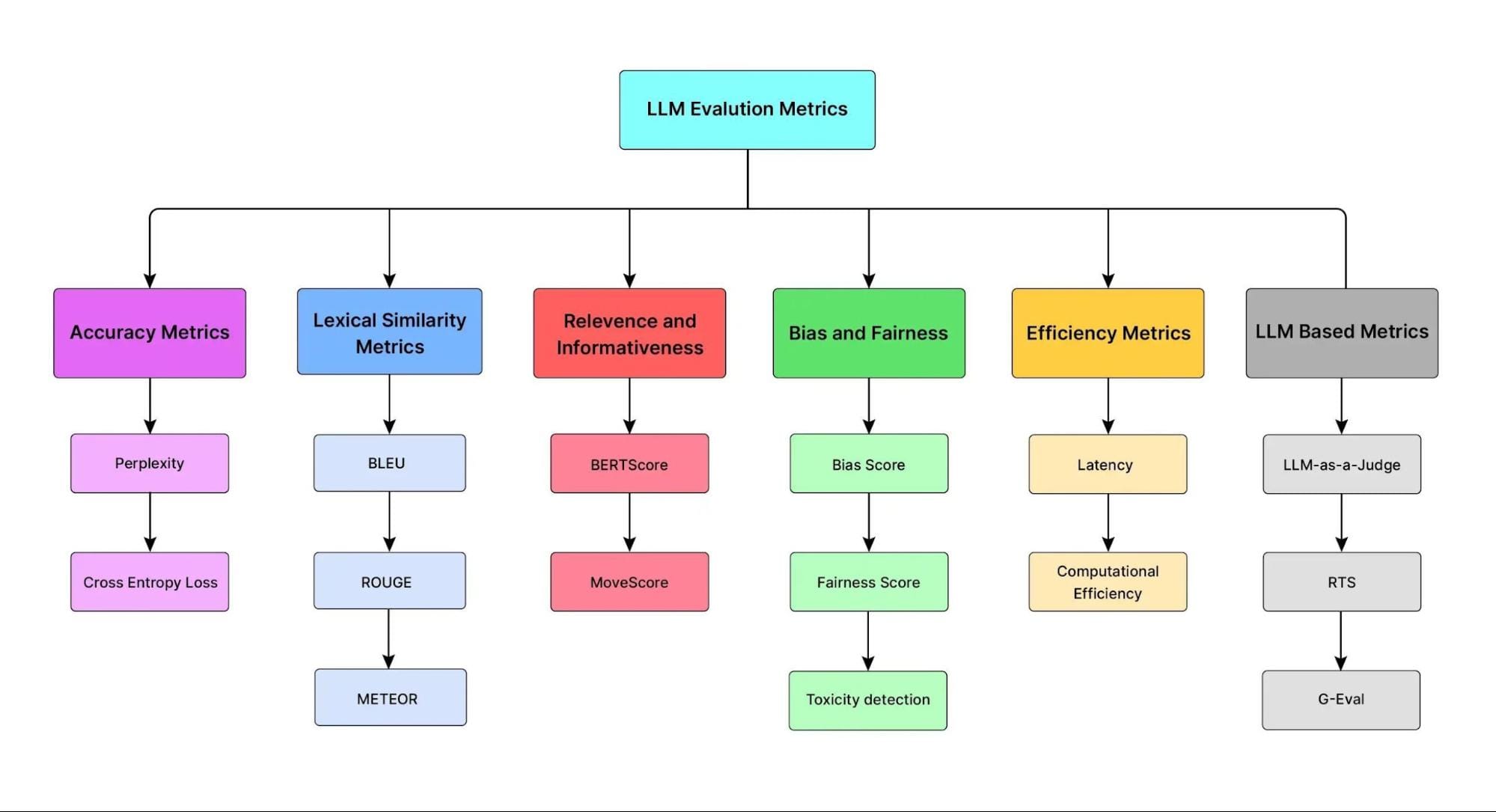
Accuracy Metrics for Local LLMs
Local LLMs excel in niche applications where domain-specific accuracy is paramount, but their evaluation often requires a tailored approach.
Traditional metrics like BLEU or F1 scores, while useful, fail to capture the nuanced performance of models fine-tuned for specialized tasks.
The key lies in combining quantitative metrics with contextual validation.
Metrics such as contextual precision and faithfulness are particularly relevant, as they measure how well the model aligns its outputs with retrieved data.
However, these metrics must be complemented by real-world testing. For example, user feedback loops can reveal gaps in contextual understanding that raw scores overlook, especially in high-stakes environments like legal compliance or financial analysis.
A critical challenge is balancing adaptability with consistency. While local models can be fine-tuned to excel in specific domains, this often introduces variability in performance across broader tasks.
Addressing this requires iterative testing and a focus on task-specific metrics that prioritize real-world applicability over theoretical precision.
Performance Benchmarks for OpenAI Models
OpenAI models consistently demonstrate exceptional performance in scenarios where latency and consistency are critical.
Their architecture is optimized for rapid token processing, ensuring near-instantaneous responses even under high-demand conditions.
This makes them particularly effective in real-time applications like fraud detection or customer support, where delays can compromise outcomes.
Their key strength is their ability to maintain contextual coherence across extended interactions. Unlike many local LLMs, OpenAI models leverage advanced fine-tuning techniques to adapt dynamically to evolving queries.
One underappreciated factor is the models’ retrieval efficiency. OpenAI’s integration of structured data pipelines ensures precise information sourcing, a feature critical for industries like healthcare.
These models set a high bar for performance by combining speed with retrieval precision. However, their reliance on cloud infrastructure may limit their adaptability in privacy-sensitive environments.
Cost Analysis of Deployment and Usage
Deploying LLMs involves a delicate balance between upfront investment and operational efficiency. The choice between local and cloud-based solutions often hinges on workload specifics.
Local LLMs demand significant infrastructure. For continuous operation of large models (100–200B parameters), high-performance GPUs like NVIDIA A100s can cost $18,000 monthly.
This setup, while expensive, offers unparalleled control and customization, particularly for industries handling sensitive data.
In contrast, OpenAI’s per-token pricing simplifies budgeting but introduces scalability challenges.
For instance, GPT-4’s generation costs are double its input costs, making high-volume applications potentially prohibitive.
However, its plug-and-play nature allows rapid deployment, reducing time-to-market by up to 90% compared to open-source alternatives, as noted by UbiOps.
A common misconception is that local deployments always yield long-term savings. In reality, hidden costs—such as data transfer, storage, and skilled personnel—can erode these benefits.
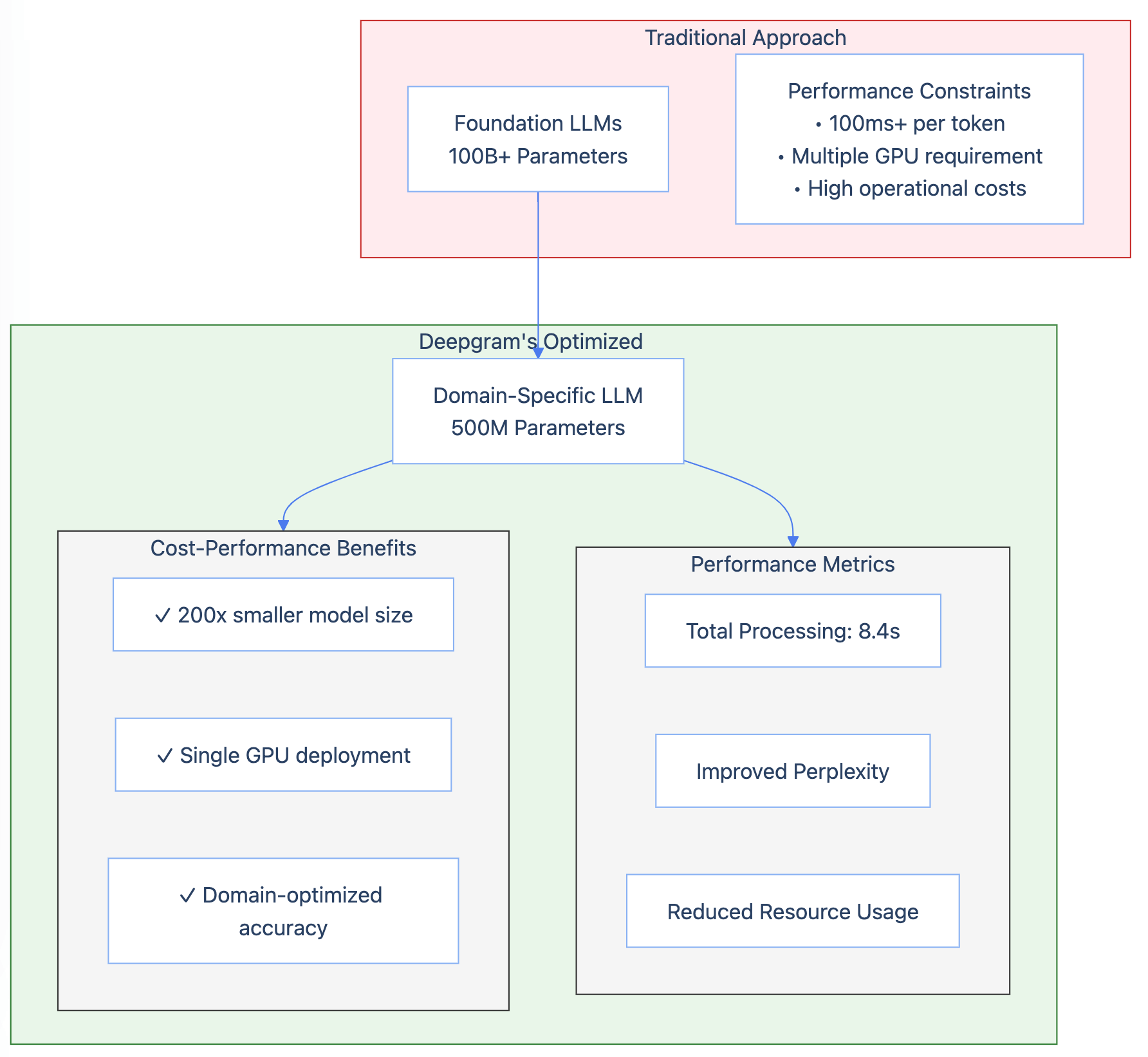
Infrastructure Costs for Local LLMs
The infrastructure costs for local LLMs hinge on more than just hardware acquisition; they represent a complex interplay of initial investment, operational demands, and scalability considerations.
High-performance GPUs like NVIDIA A100s are often the centerpiece, but their efficiency depends on complementary systems such as advanced cooling mechanisms and uninterrupted power supplies.
These elements collectively drive up costs, often exceeding $500,000 annually for mid-sized enterprises.
A critical yet underappreciated factor is resource utilization efficiency.
Techniques like model pruning and quantization can reduce computational overhead but require specialized expertise to implement effectively.
Even state-of-the-art hardware can underperform without these optimizations, leading to wasted resources and inflated costs.
Pricing Models for OpenAI Services
OpenAI’s pricing structure is deceptively simple at first glance but reveals significant complexity upon closer examination.
The dual-token model—charging separately for input and output tokens—creates a dynamic where costs can escalate unpredictably, especially in high-volume scenarios.
For instance, generating 1 million tokens with GPT-4 can cost up to $60, while input tokens add another $15 per million, making budgeting a nuanced challenge.
This model’s strength lies in its flexibility. Businesses can scale usage up or down without long-term commitments, a feature particularly advantageous for startups or projects with fluctuating demands.
However, the lack of economies of scale at higher volumes can deter enterprises with consistent, heavy workloads.
A comparative analysis with Azure OpenAI Service highlights this limitation. Azure offers provisioned throughput options that predictably cap costs.
Contextual factors, such as language complexity, further influence pricing. Non-English languages or token-heavy scripts like Chinese can inflate costs due to higher tokenization rates.
While cost-saving techniques, cached inputs, and batch processing require a careful implementation to avoid latency trade-offs.
Ultimately, OpenAI’s pricing model rewards agility but demands meticulous planning to avoid financial pitfalls.
Scalability and Resource Management
Scaling LLM systems is a balancing act between operational efficiency and cost predictability.
While offering unparalleled control, local LLMs demand meticulous resource planning. Maintaining consistent performance under variable workloads often requires overprovisioning hardware, leading to underutilized resources.
A study by the IEEE in 2024 revealed that local deployments typically operate at only 65% hardware utilization, wasting significant computational capacity.
In contrast, OpenAI’s cloud infrastructure leverages auto-scaling to allocate resources based on demand dynamically.
A critical misconception is that cloud solutions inherently simplify scaling. While they reduce infrastructure management, they limit granular control over resource allocation.
This trade-off underscores the importance of aligning deployment strategies with workload variability and long-term scalability goals.
Scaling Challenges with Local LLMs
Managing hardware resources is one of the most intricate challenges when scaling local LLMs.
Over-provisioning to handle peak loads often results in significant idle capacity, which can inflate operational costs without delivering proportional benefits.
This inefficiency, frequently overlooked in initial planning, underscores the complexity of aligning infrastructure with fluctuating workloads.
Techniques like model pruning and quantization can mitigate this issue but require specialized expertise and careful implementation.
Another overlooked aspect is the impact of latency in resource allocation.
Unlike cloud-based systems with dynamic auto-scaling, local setups often struggle to adapt quickly to sudden demand spikes, leading to performance bottlenecks.
Addressing these challenges requires technical optimization and a strategic approach to workload forecasting and resource distribution.
Resource Allocation in OpenAI’s Cloud
OpenAI’s cloud infrastructure dynamically adjusts computing resources based on real-time demand.
This auto-scaling feature helps businesses scale efficiently without managing physical hardware.
However, unpredictable workload surges can introduce challenges, particularly in cost management.
While auto-scaling ensures optimal resource utilization, sudden spikes in usage can trigger higher processing costs, making expenses harder to predict.
How workload patterns interact with token usage directly impacts pricing, requiring businesses to monitor demand fluctuations closely.
Organizations can use proactive allocation strategies such as setting usage thresholds or batch processing non-urgent queries to maintain cost efficiency.
These approaches help balance performance needs with cost control, ensuring that AI workloads remain scalable without financial unpredictability.
Customization and Fine-Tuning Capabilities
Fine-tuning local LLMs offers unparalleled precision, enabling businesses to adapt models to highly specific tasks.
For instance, according to Huggingface benchmarks, fine-tuning Mixtral-8x7B on 5 million tokens requires 48 GPU hours on NVIDIA A100s, which costs approximately $86.
This granular control allows organizations to embed proprietary knowledge directly into the model, eliminating reliance on external data sources during inference—a critical advantage for offline or privacy-sensitive applications.
In contrast, OpenAI’s customization focuses on efficiency and scalability. Their fine-tuning API supports techniques like LoRA (Low-Rank Adaptation), which optimizes only key parameters, reducing computational overhead.
This approach is ideal for businesses needing rapid deployment without extensive infrastructure investments.
The choice hinges on priorities: local fine-tuning excels in niche precision, while OpenAI’s framework balances customization with operational simplicity.
Fine-Tuning Techniques for Local LLMs
Fine-tuning local LLMs is a nuanced process, and one technique that stands out is gradual unfreezing.
This method involves incrementally unlocking the model’s layers during training, starting with the final layers and moving backward.
Doing so allows the model to retain its foundational knowledge while adapting progressively to domain-specific data.
This approach minimizes catastrophic forgetting—a common issue where models lose general knowledge when fine-tuned too aggressively.
The effectiveness of gradual unfreezing depends heavily on layer-specific learning rates.
Assigning higher learning rates to the later layers ensures rapid adaptation to new data, while lower rates for earlier layers preserve the model’s pre-trained capabilities.
However, this technique isn’t without challenges. It requires meticulous monitoring of training dynamics, as improper layer adjustments can lead to suboptimal convergence.
Tools like Hugging Face’s transformers library simplify this process by offering pre-configured schedules, but real-world success often hinges on iterative experimentation tailored to the dataset’s complexity.
Customization Options in OpenAI
OpenAI’s fine-tuning API leverages Low-Rank Adaptation (LoRA) to streamline customization, offering a practical balance between efficiency and precision. LoRA modifies only a subset of the model’s parameters, significantly reducing computational demands while maintaining high task-specific performance.
This approach is particularly effective for businesses aiming to adapt models to niche domains without incurring the costs of full-scale retraining.
The process involves approximating the original parameter matrices with lower-rank alternatives, which minimizes resource usage.
This efficiency allows organizations to focus on refining outputs rather than managing infrastructure, making it ideal for rapid deployment in dynamic industries like e-commerce or customer service.
However, LoRA’s effectiveness depends on the training dataset's quality and the task's specificity. Inconsistent or overly broad data can dilute the model’s focus, leading to suboptimal results.
To mitigate this, OpenAI provides hyperparameter tuning and validation tools, ensuring that fine-tuning aligns with user objectives.
OpenAI's framework combines technical efficiency with robust customization, empowering users to achieve tailored performance without the operational complexity of local setups.

FAQ
What are the key differences in accuracy between local LLMs and OpenAI models for Retrieval-Augmented Generation (RAG)?
Local LLMs provide domain-specific accuracy, excelling in specialized applications where fine-tuning is essential. OpenAI models perform well in general RAG tasks, benefiting from large-scale pre-training and advanced architectures. The choice depends on whether the focus is on task-specific precision or broad adaptability.
How do infrastructure costs for local LLMs compare to OpenAI’s per-token pricing model in RAG applications?
Local LLMs require upfront investments in GPUs, storage, and maintenance, making them cost-effective for long-term use. OpenAI’s pay-as-you-go pricing is scalable but becomes expensive at high query volumes. Businesses must assess whether predictable infrastructure costs or usage-based fees better align with their operational model.
Which industries benefit most from local LLMs versus OpenAI’s cloud models for RAG?
Healthcare, finance, and legal sectors prefer local LLMs due to data privacy laws and domain-specific accuracy needs. E-commerce and customer support benefit from OpenAI’s managed services, which offer scalability and rapid deployment without complex infrastructure.
What role does data privacy play in choosing between local LLMs and OpenAI for RAG implementations?
Local LLMs keep sensitive data on-premise, ensuring compliance with GDPR, HIPAA, and financial regulations. OpenAI’s cloud models provide encryption and access controls, but data transmission to external servers raises privacy concerns in regulated industries.
How do retrieval precision and response synthesis impact the performance of local LLMs compared to OpenAI in domain-specific RAG tasks?
Local LLMs can be fine-tuned for precise data retrieval, improving performance in specialized industries. OpenAI’s models offer consistent response synthesis, benefiting from large-scale training data but may struggle with niche terminology. The choice depends on whether task-specific accuracy or broad generalization is the priority.
Conclusion
Choosing between local LLMs and OpenAI for RAG depends on accuracy needs, cost structure, and privacy concerns.
Local models offer better security and customization, making them ideal for regulated industries. OpenAI provides scalability and ease of use, reducing infrastructure requirements but introducing higher long-term costs for large-scale applications.
Organizations must weigh the trade-offs between control, cost, and operational flexibility when selecting the right approach for RAG-driven AI systems.