
Building Local RAG Solutions with DeepSeek: The Complete Guide
Learn how to build local Retrieval-Augmented Generation (RAG) solutions using DeepSeek. This complete guide covers data ingestion, retrieval, indexing, and generation, helping you create efficient, scalable, and privacy-focused AI-powered applications.


While the industry races toward centralized solutions, a quieter revolution is unfolding: local RAG solutions with DeepSeek.
These setups rival their cloud counterparts and often outperform them in terms of privacy, cost, and control.
But can local solutions truly deliver the scalability and efficiency of the cloud? This guide will answer that and show how local RAG systems are reshaping the AI landscape—one secure, self-hosted model at a time.
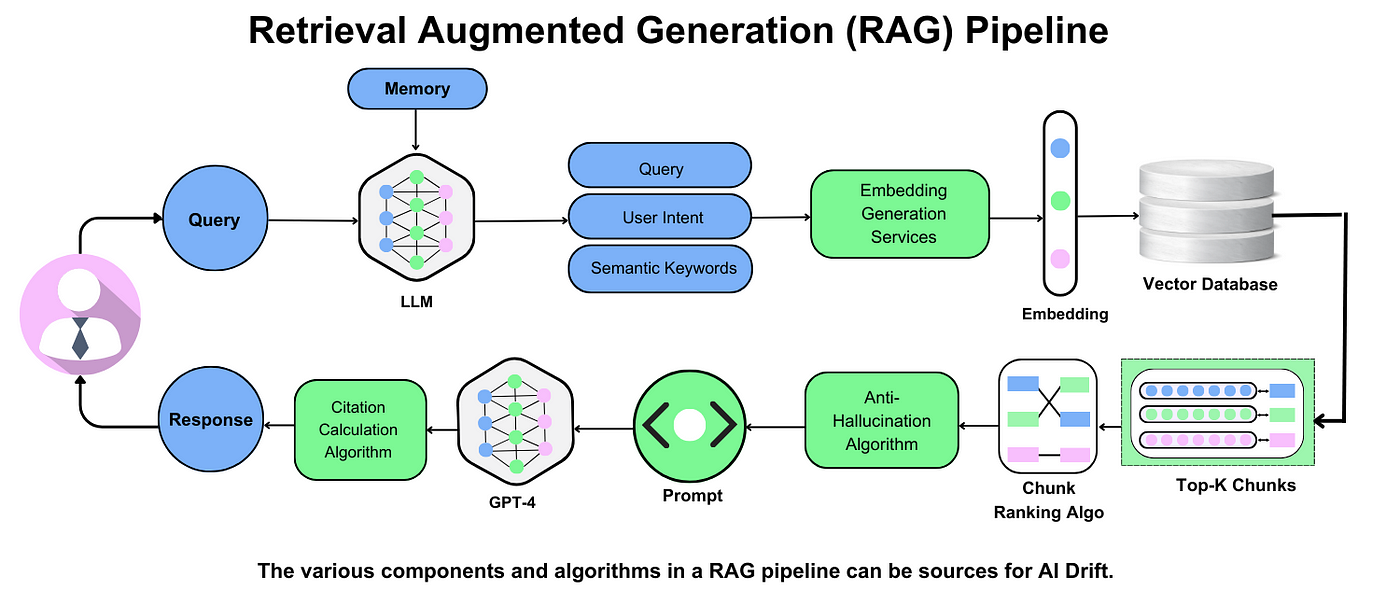
Fundamentals of Retrieval-Augmented Generation (RAG)
Imagine trying to find a needle in a haystack.
Traditional search systems might help you locate the general area, but RAG hands you the needle itself—polished and ready to use.
At its core, RAG combines two powerful engines: retrieval and generation. The retrieval engine fetches the most relevant data chunks from a vector database, while the generative model weaves these chunks into coherent, context-rich responses.
However, RAG doesn’t just retrieve—it understands. For example, in healthcare, a RAG system can pull patient-specific data and generate tailored treatment recommendations, reducing diagnostic errors.
RAG is not just a search tool—it’s a bridge between static knowledge and dynamic reasoning. Whether in healthcare, law, finance, or customer support, it transforms how AI systems generate information, making responses more precise, contextually rich, and verifiable.
Setting Up Your Local Environment
DeepSeek’s Mixture of Experts (MoE) architecture is resource-efficient, meaning you don’t need a supercomputer.
A standard GPU with 16GB VRAM can handle most workflows, making it accessible for small teams and startups.
The next thing you need to do is to prepare your data.
Think of your dataset as the fuel for this engine. Whether it’s product catalogs or legal documents, chunk your data into manageable pieces to ensure smooth indexing and retrieval.
Remember that DeepSeek’s vector search relies heavily on embedding indexing, which thrives on SSDs over traditional HDDs.
Finally, make sure your OS is compatible with the model. Linux (Ubuntu 20.04) offers better driver support and resource management than Windows or macOS. This makes it the go-to for industries like finance, where milliseconds matter. Tailor your setup to your workload, not just the specs.
Installing Necessary Dependencies
To deploy DeepSeek locally, start by setting up a clean environment to prevent compatibility issues.
Ensure your Python version is up to date and install necessary libraries, ensuring they align with your GPU drivers.
Version mismatches can degrade performance, so always verify that your deep learning framework is compatible with your hardware.
It is highly recommended that you use Docker for deployment. This approach creates an isolated environment where dependencies remain consistent across different machines. It eliminates conflicts and allows for easy replication of the setup.
Once Docker is installed, pull the required images or define a containerized environment with all necessary packages to streamline the deployment process.
Preloading embeddings is another key step in optimizing performance. Before running DeepSeek, process your dataset by converting text into vector representations and storing them in a database designed for efficient retrieval. This reduces query latency and ensures faster response times.
Configuring DeepSeek for Local Deployment
Once dependencies are installed, the next step is structuring the dataset for efficient retrieval.
Break down large documents into smaller sections while maintaining context. The ideal size for each section is a compromise between being small enough for quick retrieval and large enough to preserve meaning.
Overlapping sections slightly can help ensure that key details are not lost between fragments.
After structuring the data, store it in an optimized database for quick lookups.
A well-configured database ensures that searches return relevant results quickly. Additionally, periodically updating embeddings ensures that newly added information is indexed properly without requiring full system retraining.
These steps ensure that DeepSeek operates efficiently in a local environment, optimizing retrieval accuracy while maintaining scalability and performance.
Building a Basic Local RAG Solution with DeepSeek
Think of building a local RAG solution with DeepSeek as assembling a custom toolkit. The first step? Set up a vector database—this is your system’s memory. Tools like ChromaDB or MongoDB work pretty well for this task since they offer fast, semantic search capabilities.
Next, focus on embedding generation.
DeepSeek’s pre-trained models are optimized for diverse domains, but fine-tuning embeddings on your specific dataset can boost accuracy.
Initializing a New DeepSeek Project
Begin by defining your data schema and choosing the right embedding model. DeepSeek offers pre-trained options, but domain-specific fine-tuning can be transformative.
Think of it like customizing a suit—it fits better and performs optimally. A law firm fine-tuned embeddings on legal jargon, cutting research time in half.
Secondly, use modular pipelines. DeepSeek’s API allows you to independently test components (like retrievers or generators). This modularity saved a healthcare startup weeks of debugging by isolating bottlenecks early.
By focusing on these foundational steps, you’re not just initializing a project—you’re setting the stage for a scalable, high-performance RAG system tailored to your needs.
Integrating Data Sources and Indexing
When integrating data sources for DeepSeek, data normalization is the unsung hero.
Because inconsistent formats—like mismatched date styles or varying text encodings—can cripple indexing accuracy.
Overlapping windows during chunking ensures context continuity, especially for long documents.
Moreover, combining text, images, and even video embeddings can unlock richer insights. Think of an e-commerce platform indexing product descriptions alongside user-uploaded photos to enhance search relevance.
Finally, always test indexing configurations on a small dataset first.
This iterative approach saves time and reveals hidden inefficiencies, setting the stage for scalable, high-performance retrieval.
Implementing the Retrieval Mechanism
When implementing retrieval in a local RAG system with DeepSeek, vector database optimization is a game-changer.
Because the speed and accuracy of retrieval hinge on how embeddings are indexed and queried.
For instance, HNSW (Hierarchical Navigable Small World) indexing can drastically reduce query latency, even for datasets with millions of entries.
While higher dimensions capture nuanced relationships, they can also bloat storage and slow down searches. Many teams find 512 dimensions balance precision and performance effectively.
Periodically re-index your database as embeddings evolve. This will ensure that your system stays sharp even as data grows or changes.
Testing the Basic RAG Workflow
Testing a RAG workflow isn’t just about running queries—it’s about stress-testing edge cases.
For example, queries with ambiguous phrasing or incomplete context often reveal gaps in retrieval accuracy. Use a diverse test set, including both straightforward and complex queries, to evaluate how well the system handles real-world variability.
Here’s where prompt engineering shines. By tweaking prompt templates (e.g., adding structured instructions or examples), you can guide the model to generate more precise responses.
Moreover, you can simulate concurrent queries to ensure the system maintains performance during peak usage. Tools like Locust or JMeter can help benchmark response times.
Looking ahead, integrating user feedback loops into testing can continuously refine the workflow, ensuring it adapts to evolving data and user needs.
FAQ
What are the key benefits of using DeepSeek for building local RAG solutions?
DeepSeek enhances data privacy by keeping processing on-premises, reducing compliance risks. It’s cost-effective, adapts in real-time without retraining, and offers an open-source framework for customization.
How does DeepSeek ensure data privacy and security in local deployments?
DeepSeek processes data locally, avoids external risks, and employs role-based access, encryption, and audit trails to maintain security and regulatory compliance.
What are the hardware and software requirements for setting up DeepSeek locally?
A minimum of 16GB RAM, a 4-core CPU, and an NVIDIA GPU (RTX 3060 or better) are recommended. DeepSeek runs best on Linux (Ubuntu 20.04+), with Python 3.8+ and Docker for deployment.
How can embedding fine-tuning improve the performance of a local RAG system?
Fine-tuning embeddings on domain-specific data enhances retrieval accuracy, reduces noise, and improves response relevance, making searches faster and more precise.
What are the best practices for optimizing retrieval accuracy in DeepSeek-based RAG solutions?
To keep retrieval efficient and contextually accurate, normalize data, use overlapping chunks, fine-tune embeddings, periodically re-index, and incorporate user feedback.
Conclusion
Building local RAG solutions with DeepSeek isn’t just about privacy or cost—it’s about control.
A common misconception is that local systems can’t match the scalability of cloud-based models. However, DeepSeek’s Mixture of Experts architecture proves otherwise, activating only the parameters needed for a task. This efficiency allows even consumer hardware, like a MacBook M1, to handle complex reasoning tasks.
By combining adaptability, security, and performance, DeepSeek redefines what’s possible in local AI deployments.