
Accelerating RAG Performance with Neural Reranking
Neural reranking enhances RAG by reordering retrieved results for higher relevance and accuracy. This guide explores how to implement neural reranking to boost retrieval precision, improve response quality, and accelerate overall RAG performance.


Accelerating RAG Performance with Neural Reranking takes more than just adding deep models—it means rethinking what relevance really looks like.
RAG systems have a bottleneck no one talks about enough: the ranking layer. You can retrieve documents and feed them into a language model, but if those documents don’t truly match the question, you’ll still get shallow, vague answers.
That’s where neural reranking steps in. It doesn’t just sort documents—it understands them in context, reshaping how RAG systems work in practice.
In this article, we’ll explain how Accelerating RAG Performance with Neural Reranking improves both speed and precision.
We’ll explore how models like MonoT5 and DuoBERT rethink relevance, and how companies are already using these rerankers to reduce latency, improve accuracy, and align answers with actual user intent.
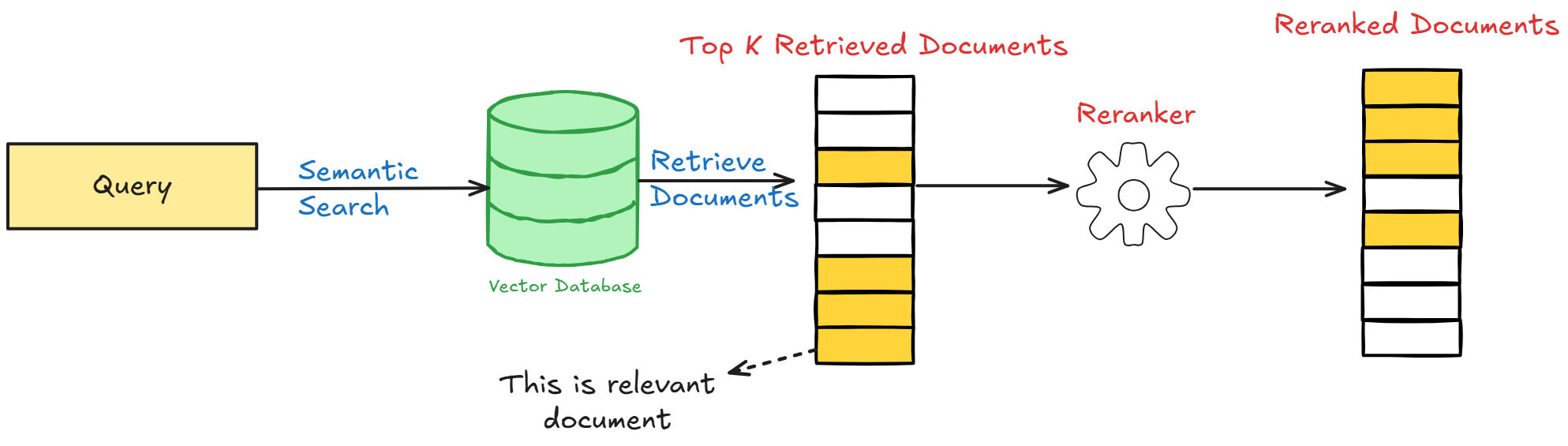
Basic Architecture and Workflow of RAG
In Retrieval-Augmented Generation (RAG), what happens before generation is just as important as the generation itself.
The retriever is at the center of it all is the retriever—responsible for converting large datasets into vector embeddings to support semantic search. But its real challenge is balance: retrieving enough relevant information without flooding the generator with noise.
Many RAG systems now use hybrid retrieval strategies, blending dense embeddings with sparse keyword search.
Dense models capture context and meaning; sparse models catch exact matches. This combination helps cover both nuance and precision—something significant in domains like law or medicine, where a single missed term can change the outcome.
Still, edge cases remain tricky. Dense embeddings often miss domain-specific jargon. Fine-tuning retrievers on curated datasets can help, but doing so introduces scalability concerns.
The solution? Iterative testing—adjusting retrieval parameters to match the needs of each dataset as they evolve.
Ultimately, the retriever’s design defines the quality of what the generator sees. The final output won’t hold up if the first step is weak. Getting retrieval right is the foundation of any strong RAG pipeline.
Traditional vs. Neural Ranking Methods
Traditional ranking methods rely on static heuristics, such as keyword matching or metadata scoring, which often fail to capture the deeper intent behind a query.
Neural ranking methods, by contrast, utilize deep learning models to interpret context dynamically, enabling a more nuanced understanding of user needs.
This shift is not merely incremental; it represents a fundamental rethinking of defining and prioritizing relevance.
At the core of neural ranking lies the ability to evaluate query-document pairs holistically. Models like BERT-based cross-encoders analyze semantic relationships within a list, ensuring that retrieved documents align closely with the query’s intent.
This approach excels in scenarios where traditional methods falter, such as multi-faceted queries or ambiguous phrasing.
However, neural methods are computationally intensive, requiring significant resources to train and deploy effectively.
A notable example comes from academic search engines, where neural rerankers have been fine-tuned to prioritize research papers based on both topical relevance and citation context. This has led to measurable improvements in retrieval precision, particularly for interdisciplinary queries.
The implications are clear: while traditional methods offer efficiency, neural ranking unlocks an indispensable depth of understanding for complex, real-world applications.
Neural Reranking: Core Concepts and Techniques
Neural reranking operates on a transformative principle: relevance is not static but deeply contextual.
Unlike traditional methods, neural models such as BERT-based cross-encoders evaluate query-document pairs holistically, capturing semantic nuances that static heuristics often miss. This dynamic approach enables rerankers to prioritize documents that align with keywords and the intent behind a query.
A key technique involves listwise context modeling, where rerankers simultaneously analyze relationships among multiple documents.
For instance, a neural reranker might identify that a document indirectly supports another through shared concepts, elevating both in the ranking.
This capability is particularly impactful in domains like legal research, where nuanced interconnections between case law and statutes are critical.
One misconception is that neural reranking is prohibitively resource-intensive. However, hybrid strategies—such as combining lightweight dual encoders for initial filtering with cross-encoders for fine-tuning—balance computational efficiency with precision.
Spotify’s session-based reordering exemplifies this, dynamically adapting rankings based on user behavior to deliver hyper-relevant results.
By refining relevance scoring, neural reranking transforms retrieval systems into adaptive, intent-driven tools, reshaping how information is discovered and utilized.
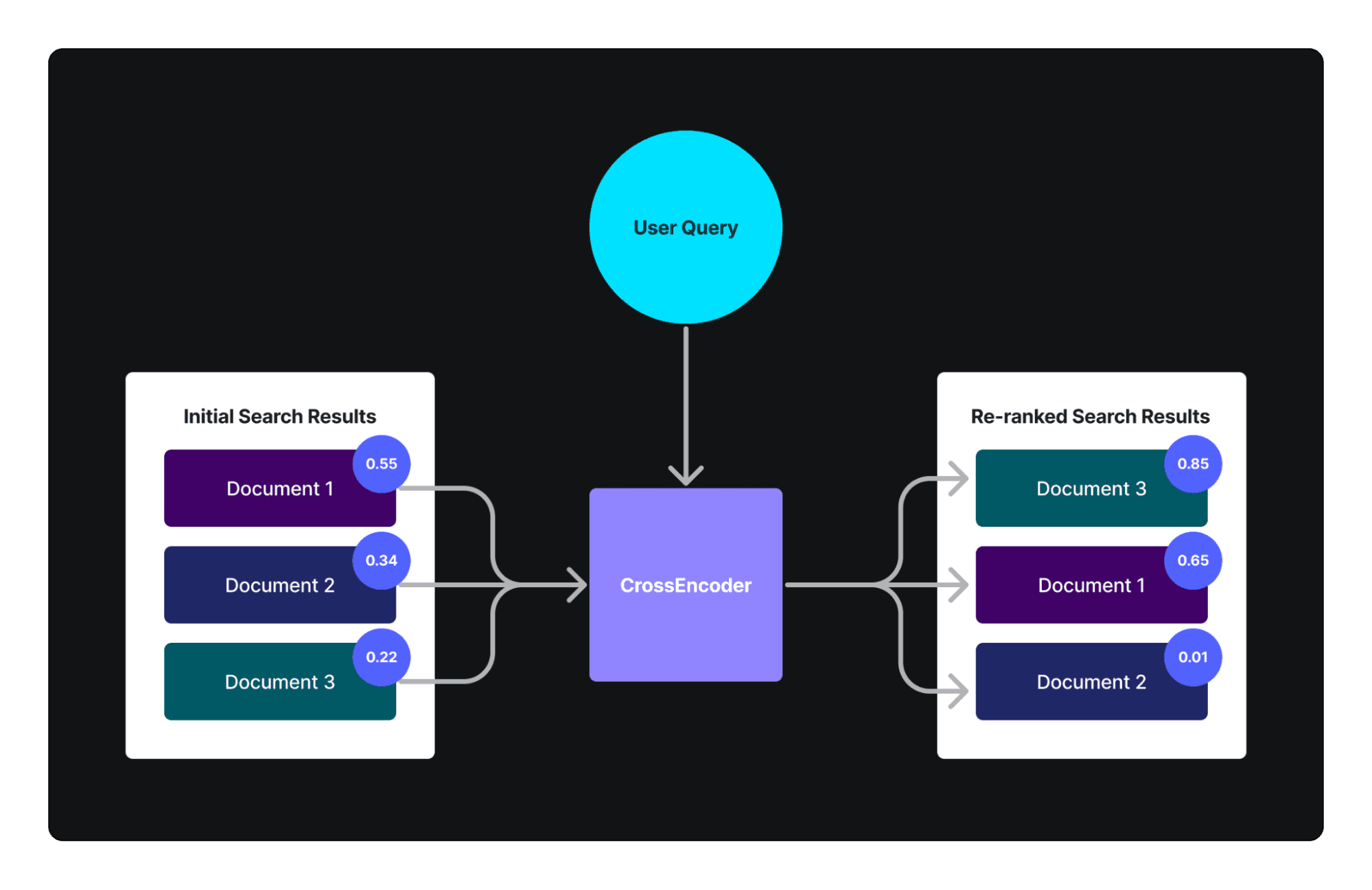
Neural Networks for Document Ranking
The dual-encoder architecture stands out for its ability to independently encode queries and documents into dense vector spaces, enabling efficient semantic matching.
This independence, however, introduces a nuanced trade-off: while pre-computed document embeddings reduce latency, the lack of query-document interaction can limit contextual depth. Addressing this, lightweight query encoders have emerged as a pivotal innovation, balancing computational efficiency with ranking precision.
These encoders, often stripped of self-attention layers, focus on extracting essential semantic features from concise queries.
They significantly reduce resource demands by simplifying the query encoding process without compromising performance.
For instance, the Fast-Forward index leverages pre-computed document embeddings alongside lightweight query encoders to achieve competitive re-ranking results, even in resource-constrained environments.
A critical challenge is maintaining robustness across diverse datasets. While lightweight encoders are efficient, they may struggle with domain-specific jargon or ambiguous phrasing.
Fine-tuning on curated datasets or employing hybrid models that combine sparse and dense retrieval methods can mitigate these limitations.
Ultimately, the success of lightweight encoders underscores the importance of tailoring neural ranking systems to specific operational contexts, ensuring both scalability and relevance in real-world applications.
Relevance Scoring and Reordering
Relevance scoring in neural reranking transcends simple keyword matching by embedding contextual relationships into the ranking process.
At its core, this involves evaluating the semantic similarity between a query and documents and the interplay among retrieved items.
This listwise approach enables rerankers to identify patterns that pairwise models often miss, such as indirect support or thematic alignment across documents.
One critical technique is contextual embedding alignment, where models like BERT-based cross-encoders analyze the query and document holistically.
Unlike sparse methods, which rely on isolated term matches, these models capture latent intent by considering the content's broader narrative structure.
For instance, in legal research, this approach ensures that case law citations are ranked higher when they substantively align with the query’s legal context, even if the exact terms differ.
However, this precision comes with trade-offs. Cross-encoders demand significant computational resources, making them less viable for real-time applications.
Hybrid strategies, such as combining dual encoders for initial filtering with cross-encoders for final reranking, mitigate this limitation.
Architectures and Training Methods for Neural Rerankers
Neural rerankers thrive on their ability to balance computational efficiency with semantic depth, and their architecture largely dictates this balance.
Cross-Encoder models, for instance, excel in capturing intricate query-document relationships by processing both inputs simultaneously through a transformer-based architecture.
This design enables precise cross-attention mechanisms, but its computational demands often make it impractical for large-scale, real-time applications.
In contrast, Bi-Encoder models independently encode queries and documents into dense vector spaces, offering faster inference at the cost of reduced contextual nuance.
Training methods further refine these architectures. Fine-tuning pre-trained language models on domain-specific datasets has proven transformative, particularly in fields like biomedical research.
A common misconception is that more complex architectures always yield better results.
However, lightweight models like ColBERT, which use token-level embeddings, often outperform heavier counterparts in latency-sensitive environments. This highlights the nuanced trade-offs between architectural complexity and operational constraints.
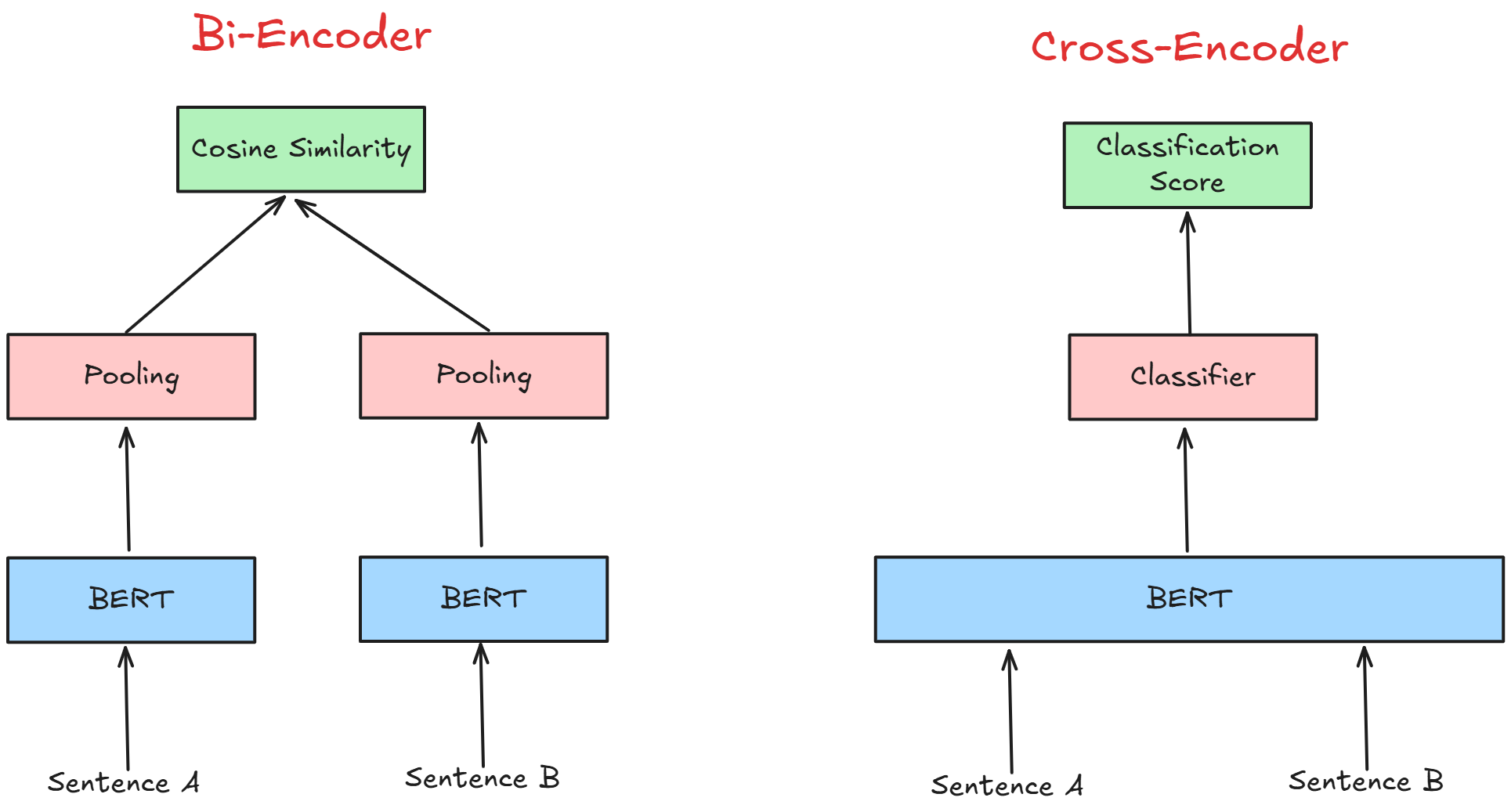
Siamese and Cross-Encoder Architectures
Siamese and cross-encoder architectures represent two fundamentally different approaches to neural ranking, each with distinct strengths and trade-offs.
Siamese models excel in efficiency by independently encoding queries and documents into fixed-size embeddings, enabling precomputation and rapid retrieval.
However, this separation can overlook intricate query-document interactions, which are often critical in domains requiring deep contextual understanding.
Cross-encoders, by contrast, process queries and documents together, leveraging transformer-based architectures to capture nuanced relationships.
This joint encoding allows for precise cross-attention mechanisms, making them particularly effective for complex queries. Yet, their computational intensity can pose challenges in real-time applications, especially when scaling to large datasets.
A hybrid approach offers a compelling solution. For instance, a Siamese model can perform an initial pass to filter candidates quickly, followed by a cross-encoder to refine the top results.
This strategy balances speed and precision, as seen in a recent implementation by a leading e-commerce platform, which reduced query latency while improving relevance in product search.
One overlooked nuance is the role of domain-specific fine-tuning. When trained on curated datasets, Siamese models can mitigate their contextual limitations, while cross-encoders benefit from task-specific loss functions to optimize relevance scoring.
This adaptability underscores the importance of aligning architectural choices with operational constraints and application needs.
Fine-Tuning Language Models for Ranking
Fine-tuning language models for ranking hinges on a deceptively simple yet critical principle: aligning the model’s training dynamics with the nuanced demands of ranking tasks.
This alignment is not merely about introducing a ranking-specific loss function but about crafting a training pipeline that mirrors the complexities of real-world retrieval scenarios.
One pivotal technique is the strategic sampling of negative examples.
Unlike classification tasks, where negatives are often random, ranking requires negatives that challenge the model’s ability to discern fine-grained relevance.
Hard negatives—documents that are contextually similar but irrelevant—push the model to refine its understanding of subtle distinctions.
For instance, in a legal document retrieval system, negatives might include cases with overlapping terminology but differing precedents, forcing the model to grasp deeper contextual cues.
Another critical factor is the choice of architecture during fine-tuning. Cross-encoders excel in capturing intricate query-document relationships but are computationally expensive. In contrast, Siamese architectures offer efficiency but may lack contextual depth.
A hybrid approach, where a Siamese model pre-filters candidates and a cross-encoder refines the top results, often strikes the optimal balance.
This method has been successfully implemented in domain-specific applications, such as biomedical research, where precision is paramount.
Ultimately, fine-tuning is as much about understanding the data’s intricacies as it is about optimizing the model. By tailoring training strategies to the task’s unique challenges, practitioners can unlock the full potential of neural rerankers in diverse applications.
Integration of Neural Reranking in RAG Pipelines
Neural reranking transforms the retrieval process into a precision-driven operation, ensuring that RAG pipelines deliver contextually aligned outputs.
By leveraging models like BERT-based cross-encoders, rerankers evaluate query-document pairs with unparalleled semantic depth, refining the initial retrieval stage into a highly targeted selection.
This interplay between retrieval and reranking is similar to a two-step lens: the retriever casts a wide net, while the reranker focuses the view, eliminating noise and sharpening relevance.
A critical misconception is that reranking merely adds computational overhead. In practice, hybrid approaches—where lightweight retrievers pre-filter candidates for computationally intensive rerankers—achieve both efficiency and precision.
This integration is not just technical but strategic. It aligns retrieval outputs with user intent, enabling RAG systems to adapt dynamically across domains, from personalized education to legal research, where precision is non-negotiable.
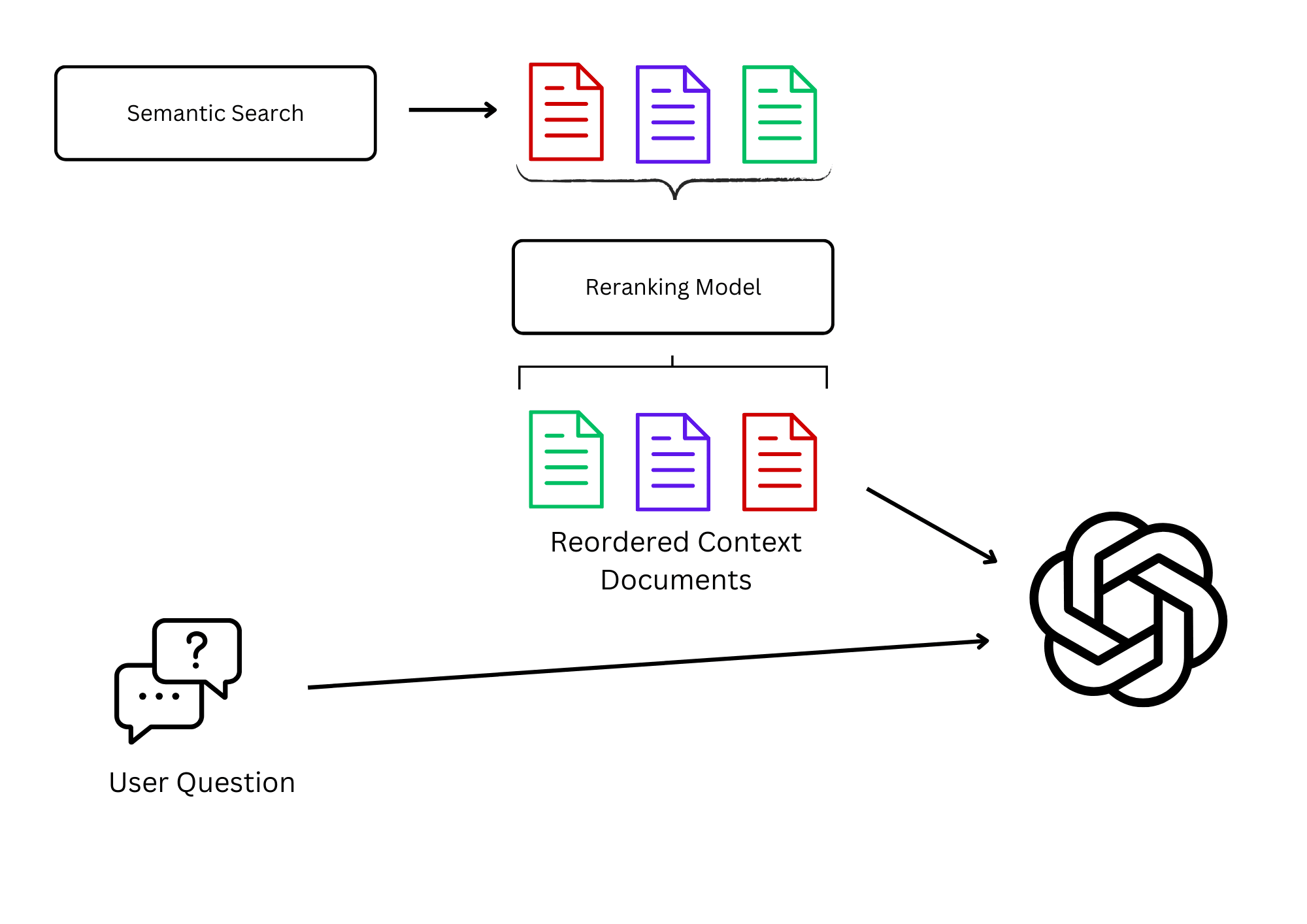
Enhancing RAG with Dense Retrievers
Dense retrievers excel at capturing semantic richness, making them indispensable for retrieving contextually relevant documents in RAG pipelines.
However, their reliance on embedding-based similarity can sometimes prioritize broad relevance over precise alignment with user intent.
This is where neural rerankers become critical, acting as precision tools to refine and reorder results for maximum contextual coherence.
One key challenge with dense retrievers is their sensitivity to embedding quality and query formulation.
For instance, in dynamic domains like healthcare, dense retrievers may surface documents that are semantically similar but lack domain-specific accuracy.
To address this, rerankers like BERT-based cross-encoders evaluate query-document pairs holistically, ensuring that the final output aligns with user needs. This layered approach not only reduces noise but also enhances the generator’s ability to produce coherent responses.
By combining dense retrievers with neural rerankers, RAG systems achieve a balance of scalability and precision, transforming raw retrieval into a refined, user-centric process.
Multi-Stage Ranking Pipelines
Multi-stage ranking pipelines redefine how RAG systems balance computational efficiency with semantic precision.
By structuring retrieval into distinct phases, these pipelines ensure that each stage optimally contributes to the final output.
The initial stage typically employs a lightweight retriever, such as BM25 or a dense vector model, to generate a broad set of candidates.
This is followed by a more computationally intensive reranker, like a BERT-based cross-encoder, which refines the results by evaluating deeper semantic relationships.
The strength of this approach lies in its adaptability. For instance, in legal research, where precision is paramount, the initial retriever can be fine-tuned to prioritize domain-specific terminology, while the reranker ensures contextual alignment with the query’s intent.
This layered methodology reduces noise and enhances the final output's coherence, making it particularly effective in high-stakes applications.
However, multi-stage pipelines are not without challenges. One critical limitation is the potential for bottlenecks during reranking, especially when processing large datasets.
To mitigate this, hybrid strategies—such as using dual encoders for initial filtering—can more effectively distribute computational load.
Ultimately, multi-stage ranking pipelines exemplify how modular design can address the competing demands of scalability and precision, offering a robust framework for dynamic, real-world applications.
Performance Metrics and Evaluation
Evaluating neural rerankers in RAG systems demands precision, as the interplay between retrieval quality and response generation hinges on nuanced metrics.
Metrics like nDCG (Normalized Discounted Cumulative Gain) and Precision@K are indispensable for assessing the relevance of retrieved documents.
For instance, nDCG accounts for the ranking position of relevant documents, ensuring that top-ranked results align with user intent—a critical factor in domains like legal research or healthcare.
A common misconception is that higher retrieval precision leads to better system performance.
However, studies by Qdrant (2024) reveal that Hit Rate, a binary metric, often overestimates effectiveness in complex queries. Instead, combining Mean Reciprocal Rank (MRR) with domain-specific benchmarks provides a more holistic view of system accuracy.
Organizations like Jina AI integrate contextual embedding alignment into their evaluation pipelines to bridge theory and practice, refining metrics to reflect real-world user interactions.
This approach ensures that RAG systems remain both scalable and contextually precise.
Precision of Top-k Retrieved Documents
Achieving precision in top-k retrieval hinges on the delicate interplay between relevance scoring and contextual alignment.
The challenge is not retrieving more documents but ensuring that the most contextually relevant ones dominate the top ranks. This requires rankers to interpret subtle semantic cues, which are often overlooked in traditional retrieval systems.
One critical technique is hard negative sampling, where rerankers are trained using documents that closely resemble relevant ones but fail to meet the query’s intent.
This forces the model to refine its understanding of nuanced distinctions, particularly in domains like legal research, where overlapping terminology can obscure true relevance.
For example, a reranker fine-tuned on case law datasets can prioritize precedents that align with the query’s legal context, even when competing documents share similar language.
By fine-tuning parameters and leveraging domain-specific datasets, practitioners can transform top-k retrieval into a precision-driven process that aligns seamlessly with user intent.
Inference Optimizations: Distillation and Quantization
Distillation and quantization are often seen as complementary tools, but their effectiveness hinges on understanding their distinct roles.
Distillation excels in transferring the “essence” of a larger model into a smaller one, preserving nuanced reasoning while reducing computational overhead.
Quantization, on the other hand, focuses on compressing model parameters by reducing precision, which directly impacts memory usage and inference speed.
The interplay between these techniques becomes particularly evident in resource-constrained environments.
For instance, in IoT applications, quantization enables deployment on devices with limited computational power, while distillation ensures the model retains critical decision-making capabilities.
However, the challenge lies in balancing these optimizations without compromising accuracy. A distilled model may lose subtle contextual understanding, while aggressive quantization can introduce numerical instability.
A notable implementation is Google’s use of quantization-aware training (QAT) in TensorFlow Lite, which mitigates accuracy loss by simulating quantized operations during training.
This approach highlights the importance of aligning optimization techniques with the model’s intended use case.
Ultimately, combining these methods requires a nuanced strategy, tailored to the specific demands of the application and the constraints of the deployment environment.
FAQ
What are the main benefits of neural reranking in RAG pipelines?
Neural reranking improves RAG pipelines by refining document relevance using contextual analysis. It aligns retrieval results with query intent, filters noise, and improves the accuracy of generated responses, making RAG systems more precise and useful in complex domains.
How does neural reranking improve semantic relevance in document retrieval?
Neural reranking improves semantic relevance by scoring query-document pairs based on deep contextual alignment. It focuses on intent, not just keyword overlap, helping RAG systems return documents that match the user is needs.
What is the role of entity relationships and salience in RAG reranking?
Entity relationships connect query terms with related document concepts. Salience analysis identifies the most important parts of the document. Together, they guide rerankers to prioritize information that directly answers the query.
How does co-occurrence optimization improve accuracy in reranking?
Co-occurrence optimization detects patterns between terms in queries and documents. This helps rerankers identify deeper relationships and select more relevant content. It improves accuracy in RAG, especially for complex or vague queries.
What are best practices for fine-tuning rerankers to improve RAG performance?
Use domain-specific training data. Select high-value examples using salience. Apply co-occurrence optimization for better term matching. Update models regularly to reflect new data. Track precision metrics like nDCG and MRR to guide model tuning.
Conclusion
Neural reranking has become a key component in accelerating RAG performance. It strengthens retrieval pipelines by aligning document selection with query context, improving both precision and user trust. From semantic search to question answering, its role in modern retrieval systems continues to grow. As organizations seek faster and more accurate results, integrating neural reranking into RAG pipelines offers a reliable path forward.