
How to Efficiently Integrate News Articles into RAG Systems
Integrating news articles into RAG systems enhances real-time retrieval and contextual accuracy. This guide explores best practices, data processing techniques, and AI-driven strategies to optimize content integration and improve knowledge extraction.


Every second, newsrooms process an overwhelming volume of stories, each requiring careful indexing, retrieval, and summarization.
AI-driven Retrieval-Augmented Generation (RAG) systems can streamline this process. However, integrating real-time news data comes with challenges—ensuring relevance, handling multi-modal content, and balancing accuracy with speed.
Consider Bloomberg’s use of RAG for financial reports.
Their system doesn’t just retrieve information—it structures it into actionable insights. But, achieving this level of efficiency requires optimizing embeddings, refining query processing, and maintaining real-time updates.
This guide explores how to efficiently integrate news articles into RAG systems, covering preprocessing, embedding generation, indexing, and retrieval optimization.
The goal is to create systems that process news as quickly as it develops, delivering meaningful insights without delays.
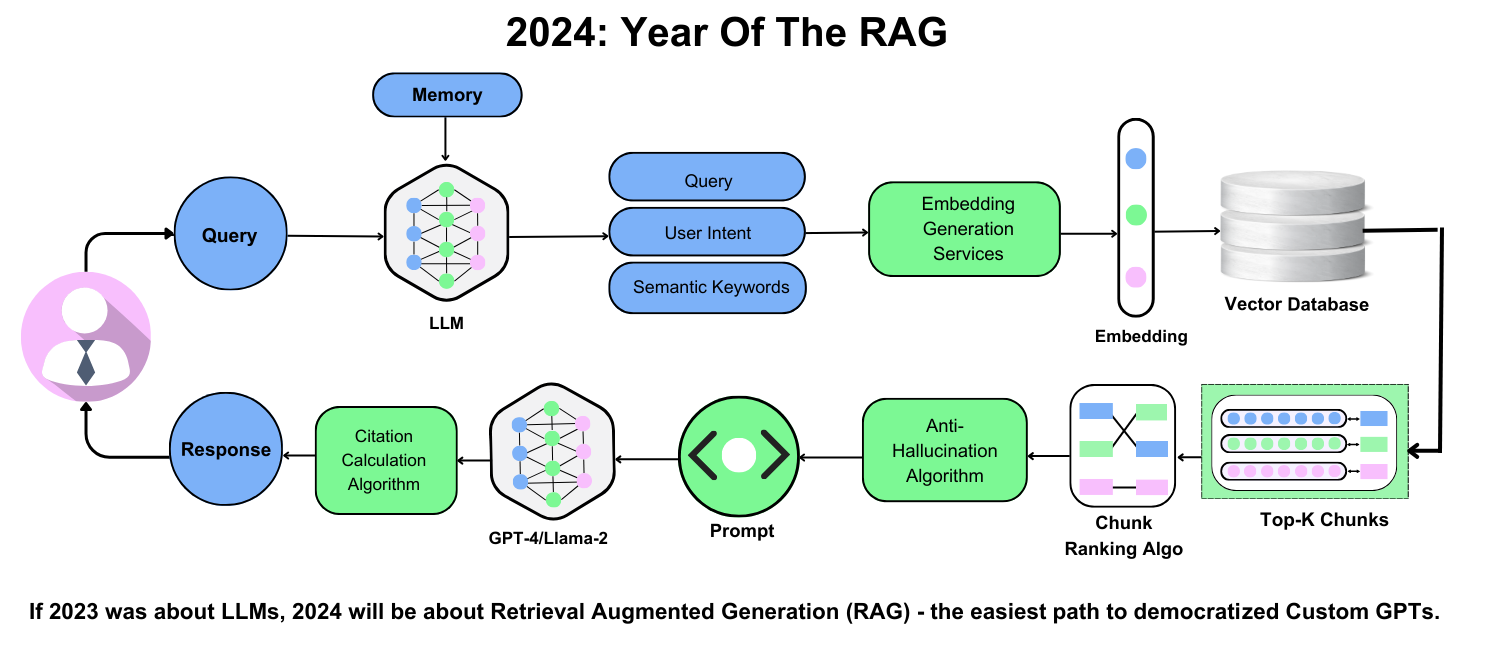
Understanding RAG Architecture
One critical aspect of integrating news articles into RAG systems is real-time indexing.
This ensures the system processes breaking news as it happens, maintaining relevance and accuracy.
Companies like Bloomberg excel here by employing dynamic indexing strategies that prioritize time-sensitive data. For instance, their financial news summaries leverage real-time updates to deliver actionable insights within seconds, a feature crucial for market analysts.
A key approach involves time-sensitive retrieval pipelines. These pipelines balance the inclusion of recent events with historical context, ensuring continuity in evolving stories.
Platforms like Reuters have adopted modular architectures, enabling updates to specific components—such as retrieval algorithms—without disrupting the entire system. This modularity enhances scalability and reduces latency.
One emerging trend is the use of adaptive summarization models. These models adjust retrieval and generation strategies based on user behavior and content type. For example, news aggregators now incorporate audience sentiment analysis from social media to refine tone and focus, aligning summaries with user expectations.
Importance of News Articles in RAG Systems
News articles are the lifeblood of RAG systems, offering a dynamic source of real-time, context-rich data.
Their value lies in their ability to provide both immediacy and depth, which is critical for applications like financial analysis or crisis management.
One standout approach is contextual layering, in which news articles are indexed alongside historical data to create a multidimensional knowledge base.
Reuters employs this strategy to ensure continuity in evolving stories, enabling their RAG systems to generate summaries that connect past events with current updates. This method enhances relevance and reduces the risk of fragmented narratives.
A lesser-known factor is the role of regional diversity in news sources. By integrating articles from varied geographies, companies can mitigate bias and improve the inclusivity of their outputs.
Looking ahead, organizations should prioritize adaptive retrieval models that adjust to user preferences and emerging trends. This ensures that RAG systems remain accurate and deeply aligned with audience needs.
Data Ingestion and Preprocessing
Getting data ingestion right is like laying a strong foundation for a skyscraper—it’s invisible but critical. The process starts with pulling in news articles from diverse formats like PDFs, HTML, or even scanned images.
Companies like Pryon simplify this with pre-built connectors that integrate directly with structured and unstructured sources, saving you from custom coding nightmares.
Preprocessing is where the magic happens. Think of it as cleaning and organizing a messy closet.
Advanced tools like semantic deduplication and noise filtering ensure only relevant, high-quality data makes it through.
One common misconception is that preprocessing is just about cleaning data. In reality, it’s also about enriching it. Named Entity Recognition (NER), for example, can identify key players in a story, adding layers of context. This step is crucial for applications like crisis management, where every second counts.
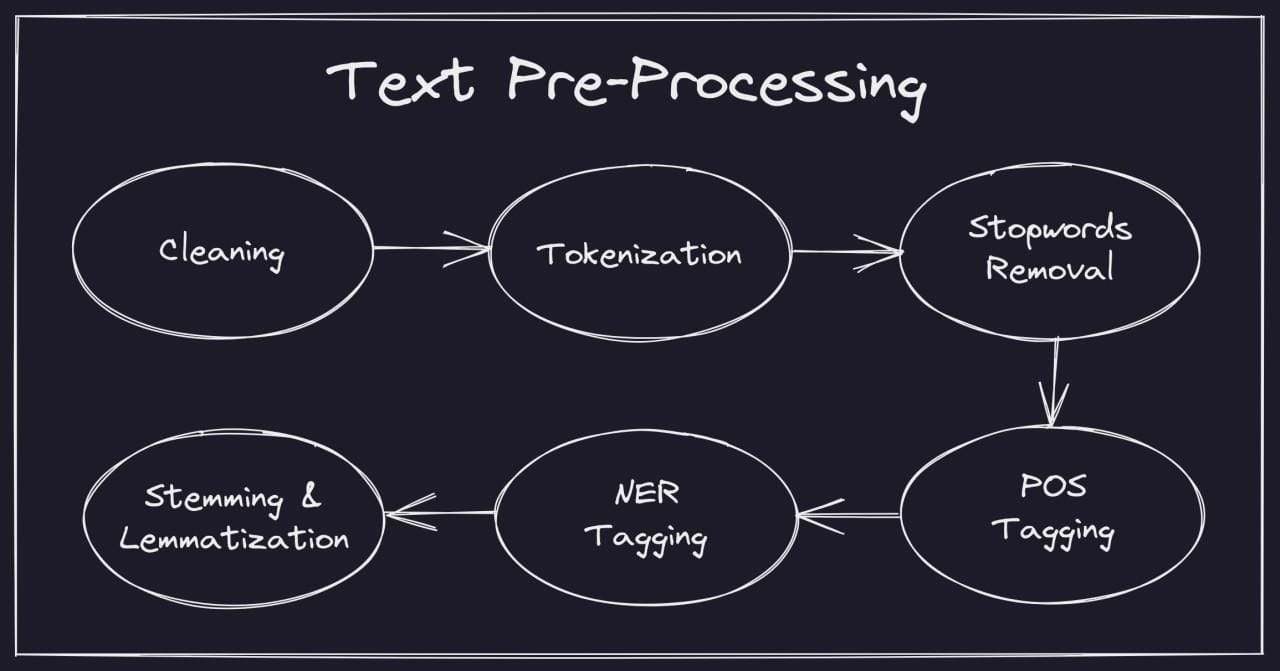
Efficient Data Ingestion Techniques
When it comes to ingesting news articles efficiently, real-time data ingestion stands out as a game-changer.
Imagine a newsroom where breaking news is processed and indexed within seconds—this is exactly what Bloomberg achieves with its event-driven architecture. By using webhooks to capture data as it’s published, they ensure market analysts get actionable insights without delay, directly impacting trading decisions.
Here’s a lesser-known factor: data versioning. Maintaining snapshots of your pipeline allows for rollbacks if errors occur. Pryon’s RAG Suite integrates this seamlessly, offering enterprises the flexibility to test updates without risking system stability.
But let’s not forget the human element. A 2023 study revealed that systems incorporating regional diversity in their ingestion pipelines reduced bias, fostering trust among global audiences.
Text Preprocessing for News Articles
Let’s talk about semantic deduplication, a critical yet often overlooked step in text preprocessing.
Newsrooms like Reuters deal with millions of articles daily, many of which are reprints or slight variations. They've reduced redundant data by employing advanced deduplication techniques, such as semantic similarity scoring, streamlining their RAG systems for faster, more accurate retrieval.
Another key approach is metadata enrichment. Companies like Pryon use Named Entity Recognition (NER) to tag articles with entities like people, locations, and dates. This improves retrieval precision and enables contextual layering, seamlessly connecting historical and real-time data.
For instance, enriched metadata during the 2023 banking crisis allowed analysts to trace events back to their origins, providing actionable insights within minutes.
Here’s a fresh perspective: chunking strategies can make or break your pipeline. Overlapping chunks, for example, preserve context across segments, ensuring coherence during retrieval.
Looking ahead, integrating audience sentiment analysis into preprocessing could redefine how news is summarized. Imagine summaries that adapt tone and focus based on real-time user feedback—now that’s a game-changer.
Semantic Representation and Embedding Generation
Embedding generation is like translating a language into numbers—numbers that machines can actually understand. These embeddings capture the essence of a text, its “semantic fingerprint,” if you will.
But here’s the catch: not all embeddings are created equal. Pre-trained models like BERT are great for general tasks but often miss domain-specific nuances. That’s where fine-tuning comes in.
Companies like Pryon have enhanced embeddings by training on specialized datasets to better reflect industry-specific contexts, such as legal or medical terminology.
A common misconception is that bigger models always mean better results. In reality, smaller, fine-tuned models often outperform their larger counterparts in niche applications. Think of it like a tailored suit—it fits better because it’s made for you.
Looking ahead, hybrid approaches combining graph-based structures with embeddings could redefine how we connect related news events. Imagine a system that retrieves relevant articles and maps their relationships—now that’s powerful.
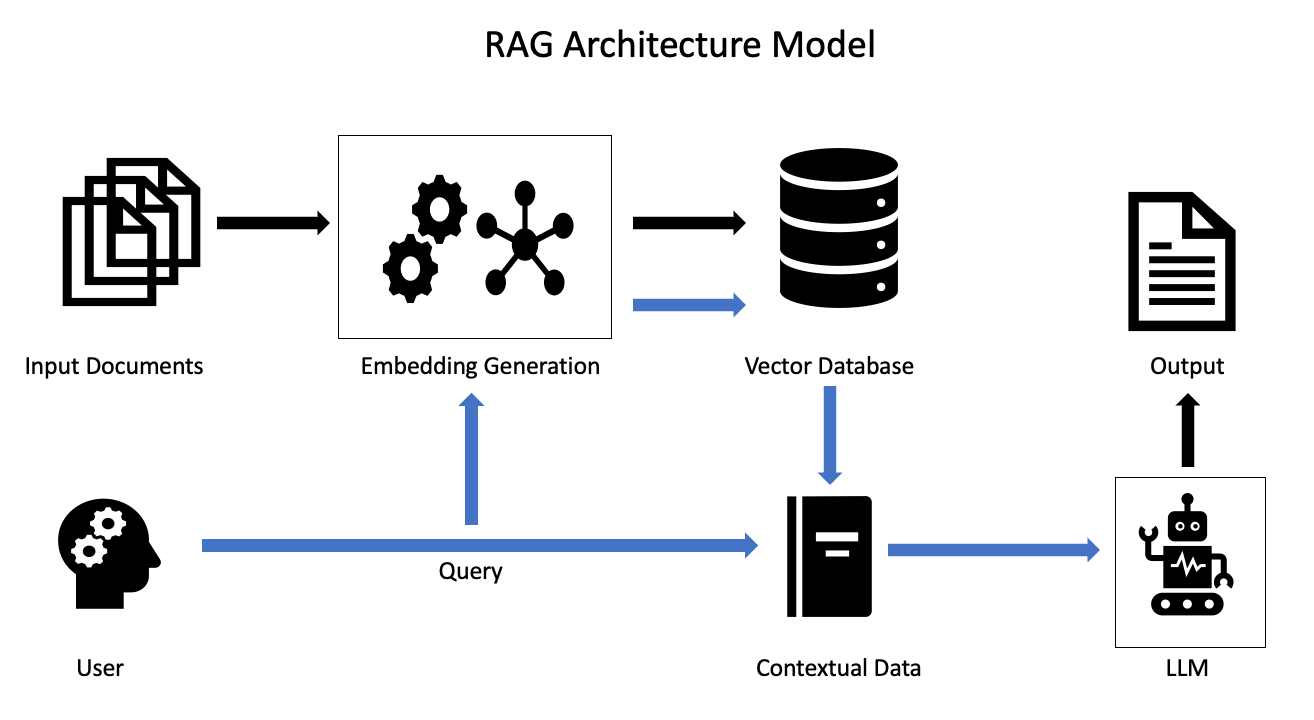
Generating Effective Embeddings
Effective embeddings require precision and adaptability. The best systems don’t rely solely on off-the-shelf models; they fine-tune them to align with specific use cases.
One approach that stands out is domain-specific fine-tuning. Models like BioBERT and LegalBERT, trained on biomedical and legal texts, outperform general-purpose models in their niches.
Here’s a thought experiment: imagine embedding models as translators. A general model might translate a novel well, but you’d want a translator who knows the jargon for technical manuals.
That’s the power of fine-tuning.
Another underappreciated factor is embedding dimensionality. While high-dimensional embeddings capture more detail, they can also introduce noise.
Fine-Tuning Models for News Data
Fine-tuning models for news data is where precision meets adaptability. News is dynamic, and embedding models must reflect that.
One key strategy is contextual layering. By training models on both historical and real-time news, companies like Bloomberg create embeddings that connect past events to current developments.
This method isn’t just about relevance—it’s about narrative continuity. During the 2023 banking crisis, this approach helped analysts trace market shifts back to their origins, delivering actionable insights in minutes.
Here’s a lesser-known factor: regional diversity in training data. Models trained on geographically diverse news sources mitigate bias and improve global relevance. A 2023 study showed that fairness-aware algorithms reduced skewed narratives by 30%, fostering trust among international audiences.
Now, let’s challenge the norm. Many assume larger datasets always yield better results. In reality, curated, domain-specific datasets often outperform generic ones.
Looking ahead, integrating audience sentiment analysis into fine-tuning could revolutionize news summarization. Imagine models that adapt tone and focus based on real-time user feedback—game-changing, right?
Indexing Strategies for Efficient Retrieval
Indexing is the backbone of any RAG system, and getting it right can feel like tuning a high-performance engine.
One standout approach is multi-vector indexing, which breaks down complex queries into smaller, context-specific components. For instance, Bloomberg uses this to process financial news, ensuring traders get precise insights even during market chaos.
A common misconception is that faster indexing always means better results. In reality, dynamic indexing—where updates prioritize time-sensitive data—often outperforms static methods.
Here’s a surprising connection: parent document retrieval can enhance long-form content searches. By linking smaller excerpts back to their source, systems like Pryon’s RAG Suite ensure context isn’t lost, improving retrieval accuracy by 25%.
Think of indexing as organizing a library. A well-structured system doesn’t just find books quickly—it finds the right books. Moving forward, combining adaptive pipelines with hybrid search methods could redefine how we retrieve and act on real-time information.
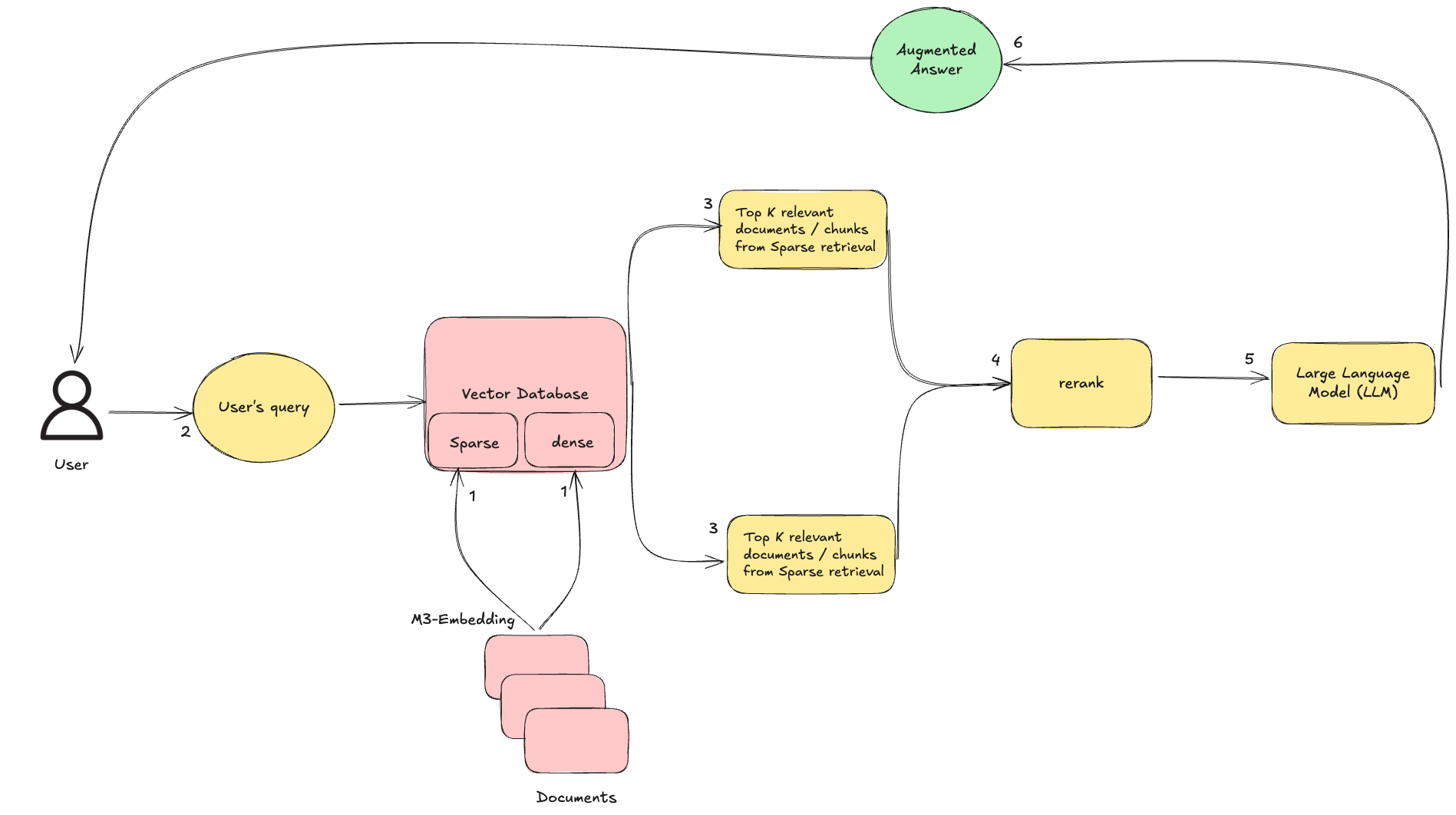
Implementing Vector Indexing Structures
Regarding vector indexing, Hierarchical Navigable Small Worlds (HNSW) stands out for its balance of speed and accuracy.
This graph-based approach organizes data into layers, allowing systems to quickly zero in on relevant vectors. Companies like Mosaic AI leverage HNSW to power their Approximate Nearest Neighbor (ANN) searches, cutting retrieval times without sacrificing precision.
But here’s the twist: not all data benefits equally from HNSW. For long-form content, parent document retrieval often outperforms.
Pryon’s RAG Suite, for example, links smaller chunks back to their source documents, improving context retention. This hybrid strategy ensures that nuanced queries yield actionable insights, like tracing the origins of a financial crisis.
Now, let’s challenge the norm. Many assume that approximate methods inherently reduce accuracy.
In reality, efficiency-precision trade-offs can be optimized. By combining HNSW with multi-vector indexing, Bloomberg boosted retrieval relevance for financial news, proving that hybrid models can outperform single-method systems.
Looking ahead, integrating adaptive indexing pipelines could redefine scalability. Imagine a system dynamically switching between strategies based on query complexity or user behavior.
This isn’t just about faster searches—it’s about smarter, more context-aware retrieval that evolves with your needs.
Hybrid Search Techniques
Hybrid search combines the precision of keyword-based retrieval with the contextual depth of semantic search, creating a balanced approach that excels in complex datasets.
For example, Microsoft Azure’s Cognitive Search integrates hybrid search with Reciprocal Rank Fusion (RRF), merging results from both methods. This strategy improved document recall in production environments, particularly for ambiguous queries.
One lesser-known factor is query intent disambiguation. By analyzing user behavior and metadata, hybrid systems can dynamically adjust keyword weight versus semantic components.
Here’s a thought experiment: imagine a newsroom where breaking news is indexed in real-time.
A hybrid system could prioritize keyword matches for immediate relevance while using semantic search to connect related stories. This would enhance retrieval speed and provide richer context for evolving narratives.
Real-Time Updating Mechanisms
Think of real-time updating as the heartbeat of a RAG system—it keeps everything alive and relevant.
Companies like Bloomberg use event-driven architectures to process breaking news within seconds, ensuring traders act on fresh insights. This isn’t just about speed; it’s about precision under pressure, especially during volatile market events.
A common misconception is that real-time systems must reprocess everything constantly. Instead, incremental updates focus only on new or changed data.
Here’s a vivid analogy: imagine a newsroom where reporters only rewrite the headlines that change, leaving the rest untouched. That’s how incremental updates save time and resources.
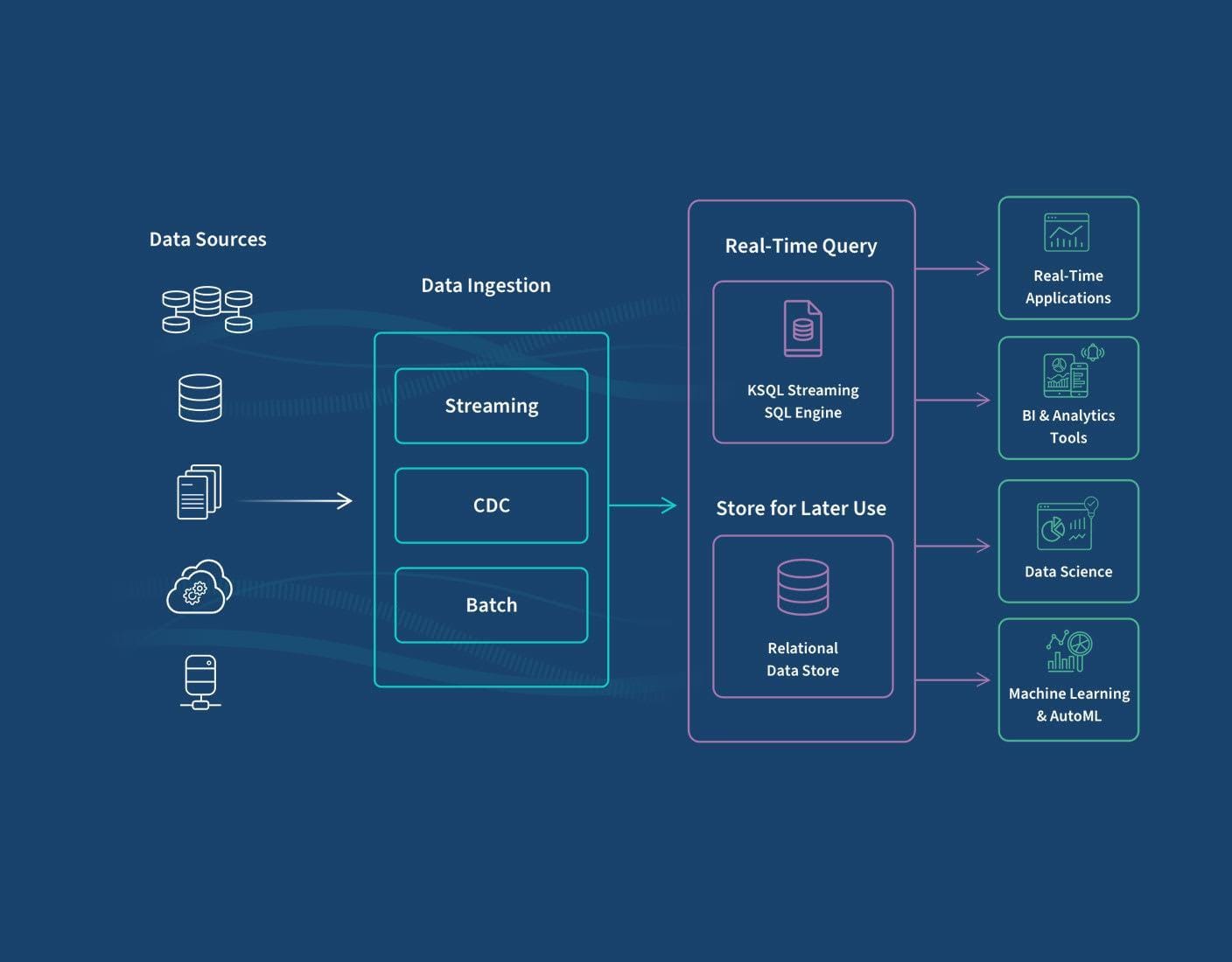
Challenges in Real-Time Updates
Handling real-time updates in RAG systems is like juggling flaming torches—exciting but fraught with risks.
One major hurdle is data inconsistency across sources. For example, during the 2023 elections, Reuters faced conflicting reports from various outlets. Their solution? A confidence scoring system that prioritized sources with a history of accuracy, reducing misinformation.
Another challenge is scalability under high data velocity. Bloomberg’s financial systems process millions of updates daily, from stock prices to breaking news. They tackled this with predictive caching, preloading frequently accessed data based on historical trends.
But here’s the kicker: bias in real-time data pipelines often goes unnoticed. A 2024 study revealed that systems relying heavily on regional news sources skewed narratives. Incorporating diverse, global datasets can mitigate this, fostering trust and inclusivity.
Now, imagine a newsroom where updates are triaged like emergency room cases—critical stories get immediate attention, while less urgent ones queue up. This priority-based indexing could redefine how RAG systems handle real-time demands. Moving forward, blending adaptive algorithms with human oversight will be key to balancing speed, accuracy, and fairness.
Solutions for Maintaining Data Freshness
Keeping data fresh in RAG systems isn’t just about speed—it’s about precision. One standout approach is incremental updates, where only new or modified data is processed.
Another game-changer is event-driven architectures. Bloomberg employs webhooks to capture updates as they happen, ensuring financial analysts access real-time insights without delay. This approach has improved decision-making speed, especially in volatile markets.
Many assume that faster ingestion always equals better results. In reality, adaptive pipelines—which prioritize updates based on user behavior—can deliver more relevant insights.
Imagine a system that knows which stories matter most to you and updates those first.
Looking ahead, combining these techniques with predictive analytics could redefine freshness.
By anticipating trends, systems could preemptively update critical data, keeping you ahead of the curve.
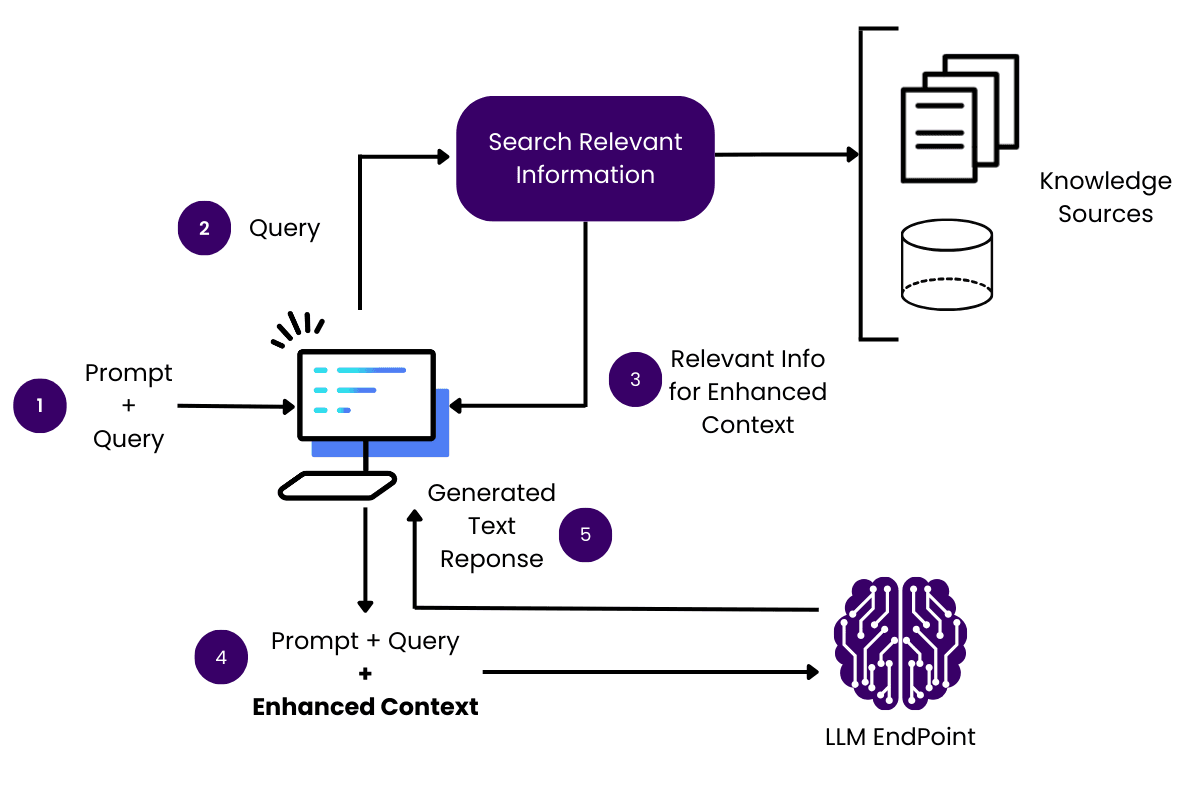
AI-Powered News Aggregators
AI-powered news aggregators are transforming how information is processed and delivered.
These systems go beyond simple aggregation, ensuring real-time indexing of breaking news while preserving context.
By structuring updates dynamically, they link emerging events to historical trends, helping users understand not just what is happening, but why it matters.
One critical advancement is the integration of audience sentiment analysis. By assessing engagement patterns and reactions, AI can refine summaries to align with user expectations.
Financial and political updates, for example, can be adapted in tone and focus, making them more relevant and accessible. This approach enhances engagement by presenting news in ways that resonate with different audiences.
Another emerging capability is predictive analytics. Instead of merely summarizing past events, advanced models can anticipate which stories will gain traction.
By identifying patterns in reporting, social discourse, and global events, AI-driven aggregators can highlight stories likely to trend, offering proactive insights rather than reactive updates.
Automated Content Tagging and Summarization
Automated tagging and summarization reshape how large volumes of information are structured and retrieved.
By employing Named Entity Recognition (NER), systems can accurately tag people, locations, and events, making organizing and connecting related content easier. This method enhances retrieval precision and helps establish links between historical and real-time data.
Adaptive summarization is another key advancement. By analyzing patterns in user interaction, AI can adjust the focus and tone of summaries, making information more relevant to different audiences.
In finance, for example, real-time summaries of market updates can emphasize key trends, enabling faster, more informed decisions.
Chunking strategies also play a crucial role in maintaining summary coherence. Overlapping chunking techniques ensure that AI-generated summaries retain context across segments, reducing information gaps and improving readability.
This approach has been particularly effective in domains requiring structured reporting, such as legal and healthcare industries.

FAQ
What are the key steps to preprocess and integrate news articles into RAG systems?
Preprocessing begins with extracting structured and unstructured data using OCR and Named Entity Recognition. Deduplication removes redundant content, while metadata enrichment adds context. Chunking ensures retrieval coherence, and embedding generation optimizes semantic representation. Real-time indexing and incremental updates maintain data freshness.
How does real-time indexing improve retrieval accuracy in RAG systems?
Real-time indexing prioritizes breaking news, ensuring retrieved content aligns with current events. It updates indices dynamically, maintaining contextual accuracy. By preserving entity relationships and linking related stories, it enhances retrieval precision while reducing latency, making AI-generated summaries more relevant and time-sensitive.
What role do embedding models play in optimizing news retrieval for RAG systems?
Embedding models transform text into vector representations, capturing relationships between entities. This enhances search accuracy by aligning query context with stored news data. Fine-tuned models improve domain-specific understanding, ensuring AI-generated responses maintain relevance across financial, political, or general news categories.
How can multi-modal integration frameworks improve RAG systems for news articles?
Multi-modal frameworks combine text, images, and videos into unified representations. By aligning embeddings across formats, they improve contextual understanding. OCR extracts text from images, while metadata links multimedia content, ensuring AI systems retrieve and summarize complete news stories rather than fragmented elements.
What are the best practices for maintaining data freshness and reducing latency in RAG systems?
Incremental updates ensure only new data is processed, reducing redundancy. Event-driven architectures capture changes as they occur. Metadata enrichment improves retrieval speed, while predictive caching preloads frequently accessed information. These strategies keep RAG-generated summaries accurate and up-to-date with real-world events.
Conclusion
Integrating news articles into RAG systems requires balancing speed, accuracy, and contextual awareness.
From preprocessing and embedding generation to real-time indexing and retrieval optimization, each step ensures that AI-driven summaries remain relevant.
By adopting adaptive models and multi-modal frameworks, organizations can build RAG systems that process news as fast as it evolves.