
NVIDIA’s Advanced RAG Techniques: Lessons from Free Courses
NVIDIA’s free courses offer valuable insights into advanced RAG techniques. This guide highlights key lessons, optimization strategies, and best practices to enhance retrieval accuracy, improve AI workflows, and maximize the potential of RAG systems.


Most AI models struggle with outdated or incomplete information. They generate responses based on pre-trained knowledge, often missing real-time context.
That’s where Retrieval-Augmented Generation (RAG) comes in, bridging the gap between static models and live data.
But even RAG systems face a challenge—retrieving the right information quickly and accurately.
NVIDIA’s Advanced RAG techniques take this to another level.
By combining GPU-accelerated FAISS, NeMo, and hierarchical indexing, they’ve made AI faster and more precise. These optimizations don’t just speed things up—they transform how AI interacts with real-world data, allowing it to process complex queries with better accuracy.
As industries like healthcare, finance, and telecom integrate these methods, the demand for optimized retrieval and generation continues to grow.
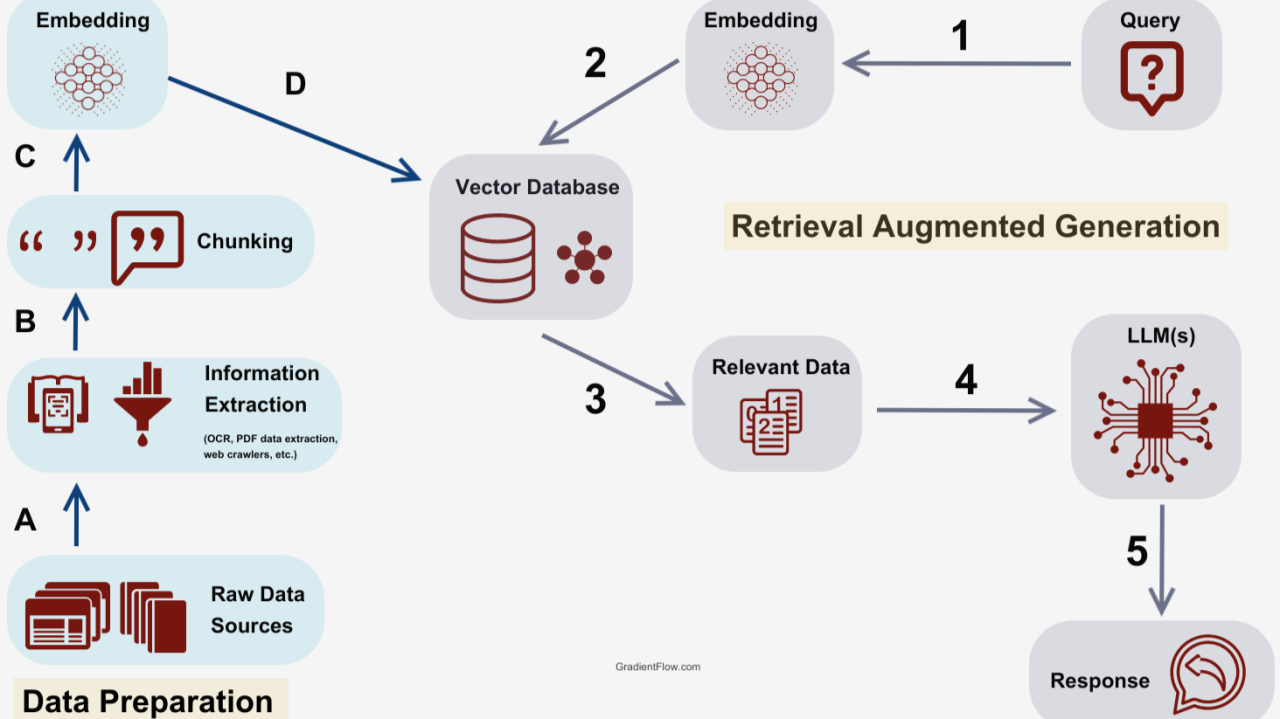
Overview of Retrieval-Augmented Generation
Retrieval-Augmented Generation (RAG) thrives on its ability to bridge static knowledge with dynamic, real-time data, but the true complexity lies in optimizing the retrieval phase.
At its core, this involves embedding models that transform queries into high-dimensional vectors, enabling precise matches within vast datasets.
The challenge?
Balancing retrieval accuracy with computational efficiency, especially in latency-sensitive applications.
One standout technique is query transformation, where a single query is split into multiple subqueries to broaden the search space.
This approach, as seen in NVIDIA’s Advanced RAG, refines document relevance by targeting diverse facets of the original query.
However, this method demands robust indexing structures and GPU-accelerated vector searches to maintain performance under heavy loads.
A critical limitation emerges when relevant data is fragmented across sources.
Advanced RAG addresses this by integrating corrective retrieval mechanisms, ensuring comprehensive context synthesis. Yet, this introduces trade-offs in processing time, particularly in high-throughput environments.
The practical takeaway?
Effective RAG implementation hinges on aligning retrieval strategies with domain-specific requirements, ensuring that every retrieved fact contributes meaningfully to the generated output.
This nuanced interplay between retrieval precision and system scalability defines RAG’s transformative potential.
NVIDIA’s Role in Advancing RAG
NVIDIA’s innovation in Retrieval-Augmented Generation (RAG) lies in its ability to seamlessly integrate GPU-accelerated hardware with advanced software frameworks like NeMo and Triton.
This synergy enables faster processing and smarter retrieval, where dynamic data streams are managed with precision.
The real value emerges when these systems adaptively refine context during retrieval, ensuring that every generated response is both relevant and actionable.
A key differentiator is NVIDIA’s optimization of embedding models, which transforms queries into high-dimensional vectors for rapid and accurate searches.
Unlike traditional approaches, NVIDIA employs fine-tuned indexing structures prioritizing speed and relevance.
This is particularly evident in their use of GPU-accelerated databases, drastically reducing retrieval latency.
However, challenges arise when data is fragmented across multiple sources, requiring sophisticated corrective mechanisms to synthesize complete context.
In practice, these advancements translate to tangible benefits across industries. For instance, telecom networks leveraging NVIDIA’s RAG pipelines have achieved real-time load balancing, reducing downtime and improving efficiency.
This underscores how NVIDIA’s approach enhances theoretical frameworks and delivers measurable real-world impact.
Foundational Concepts in RAG Systems
Retrieval-Augmented Generation (RAG) systems hinge on a delicate balance between retrieval precision and generative fluency, a synergy that transforms static data into actionable intelligence.
At their core, these systems rely on embedding models, which convert textual queries into high-dimensional vectors.
This process resembles mapping words into a multi-dimensional “coordinate system,” where proximity reflects semantic similarity.
Such embeddings enable rapid, context-aware retrieval from vast datasets, a capability critical for enterprise-scale applications.
One misconception I often encounter is that retrieval accuracy alone guarantees system performance. In reality, the interplay between retrievers and rankers is pivotal.
For instance, NVIDIA’s NeMo Retriever fetches relevant documents and integrates reranking mechanisms to prioritize contextually significant results.
This layered approach ensures that even fragmented or ambiguous queries yield coherent outputs, addressing a common pain point in traditional AI systems.
The practical implications are profound.
Consider multilingual support: RAG pipelines can seamlessly bridge language barriers by leveraging cross-lingual embeddings, enabling global enterprises to deploy AI solutions without extensive localization efforts. This adaptability underscores the transformative potential of foundational RAG concepts.
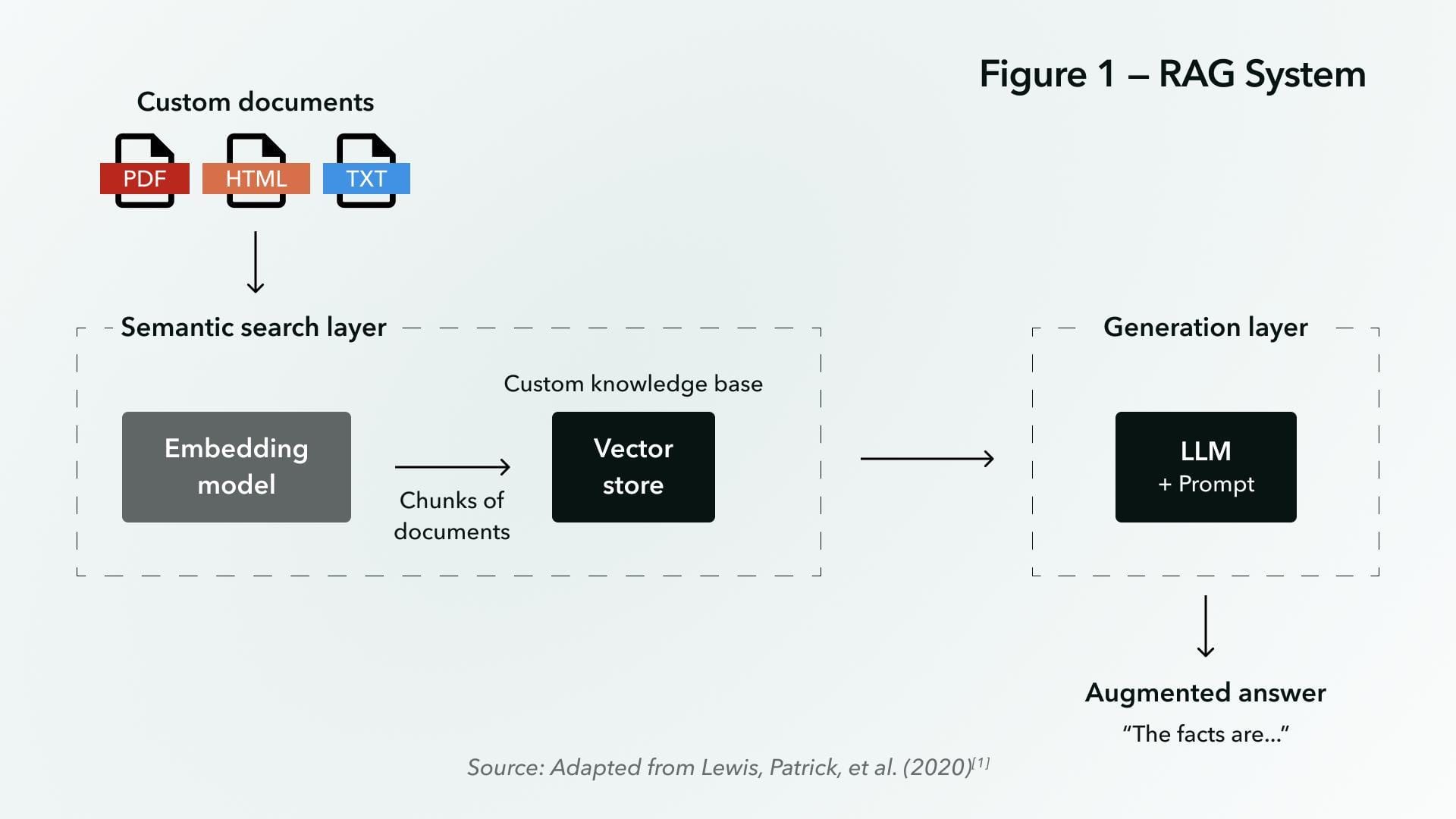
Basic RAG Architecture
The essence of RAG architecture lies in its seamless integration of retrieval and generation, but the retriever’s role often carries hidden complexities.
At its core, the retriever transforms user queries into high-dimensional embeddings, enabling precise matches within vast datasets.
This process is about speed and ensuring semantic alignment between the query and retrieved data. A poorly optimized retriever can lead to irrelevant or fragmented outputs, undermining the system’s utility.
One critical challenge arises when data is distributed across heterogeneous sources. In such cases, embedding models must account for data structure and context variations.
To bridge theory and practice, developers must prioritize retriever optimization, ensuring retrieved data integrates seamlessly with the generator.
This alignment transforms RAG from a theoretical framework into a robust, real-world solution capable of handling complex, dynamic datasets.
NVIDIA’s AI Infrastructure
NVIDIA’s AI infrastructure excels in its ability to harmonize GPU-accelerated hardware with adaptive software frameworks, creating a foundation that ensures both speed and contextual accuracy.
A standout feature is its dynamic data retrieval and processing orchestration, which leverages the NVIDIA NeMo framework alongside Triton Inference Server. This combination enables real-time adjustments to data streams, ensuring that even fragmented or heterogeneous datasets are seamlessly integrated into the retrieval-augmented generation (RAG) pipeline.
One critical aspect often overlooked is the infrastructure’s ability to optimize retrieval precision through intelligent load balancing.
NVIDIA's system minimizes latency without compromising accuracy by dynamically allocating GPU resources based on query complexity and data distribution. This contrasts sharply with traditional setups, where static resource allocation often leads to bottlenecks under high-throughput conditions.
A practical example of this is in telecommunications, where NVIDIA’s infrastructure has been deployed to process O-RAN specifications.
Integrating NeMo Guardrails and GPU-accelerated FAISS databases delivers precise, context-aware responses, even under demanding operational conditions.
This approach underscores the importance of a cohesive, end-to-end infrastructure in achieving scalable, real-world AI solutions.
Advanced Embedding Techniques and Vector Search
Embedding techniques have evolved into the linchpin of modern vector search, transforming raw data into high-dimensional vectors that encode semantic meaning.
A critical insight here is that the quality of embeddings directly dictates retrieval precision.
For instance, NVIDIA’s NeMo framework uses domain-specific embeddings to achieve a 20x acceleration in vector generation, as demonstrated in its integration with DataStax Astra DB.
One misconception is that higher-dimensional embeddings always yield better results.
In practice, excessive dimensionality can lead to the “curse of dimensionality,” where retrieval accuracy diminishes due to sparse data representation.
NVIDIA addresses this by employing hierarchical indexing methods, such as HNSW (Hierarchical Navigable Small Worlds), which balance dimensionality with computational efficiency.
This approach ensures that even billion-scale vector databases maintain rapid and accurate searches.
Think of embeddings as the DNA of your data: they encode its essence, enabling systems to “recognize” patterns and relationships.
By refining these vectors and optimizing their search mechanisms, organizations unlock the full potential of retrieval-augmented generation, driving actionable insights across industries.

Optimizing Vector Databases
One often-overlooked aspect of optimizing vector databases is the strategic use of query expansion to enhance retrieval precision without compromising system efficiency.
Query expansion involves augmenting the original query vector with additional semantically relevant terms, effectively broadening the search space while maintaining alignment with user intent.
This technique is particularly valuable in high-dimensional vector spaces, where subtle variations in query phrasing can lead to significant retrieval discrepancies.
The underlying mechanism relies on embedding refinement, where the query vector is adjusted to capture a wider spectrum of semantic similarities.
This process ensures that even nuanced or ambiguous queries yield meaningful results.
However, the trade-off lies in computational overhead; poorly calibrated expansions can introduce noise, diluting the relevance of retrieved data.
Advanced indexing methods like Hierarchical Navigable Small Worlds (HNSW) are employed to mitigate this, balancing the expanded search scope with retrieval speed.
A notable implementation of this approach can be seen in multimedia applications, where vector databases are used to retrieve visually similar content.
For instance, a leading e-commerce platform optimized its image search by integrating query expansion with domain-specific embeddings, improving user satisfaction metrics.
This nuanced interplay between expansion and precision underscores the importance of tailoring vector database configurations to specific application needs.
Embedding Models for Enhanced Retrieval
Fine-tuning embedding models for domain-specific applications is a critical yet often underestimated factor in achieving high retrieval precision.
While pre-trained models offer a strong starting point, they frequently fail to capture the subtle nuances of specialized datasets.
This gap can lead to mismatches in retrieval, particularly in contexts where semantic granularity is paramount, such as legal or medical domains.
The process of fine-tuning involves calibrating the embedding model to align with the unique characteristics of the target data.
For instance, embeddings must account for domain-specific terminology and contextual relationships between clauses in a legal document retrieval system. This is achieved by training the model on curated datasets, ensuring that the resulting vectors encapsulate both semantic depth and contextual relevance.
However, this approach introduces challenges, such as overfitting to niche data, which can reduce generalizability.
A comparative analysis highlights the trade-offs between fine-tuning and using general-purpose embeddings.
While the latter ensures broader applicability, it often sacrifices precision in specialized tasks. NVIDIA’s NeMo framework exemplifies how GPU-accelerated fine-tuning can mitigate these trade-offs, enabling rapid adaptation without compromising performance.
By integrating fine-tuned embeddings with advanced indexing techniques, organizations can achieve a transformative leap in retrieval accuracy, unlocking actionable insights even in the most complex datasets.
Integration of LLMs and Multi-Modal RAG
Integrating Large Language Models (LLMs) with multi-modal Retrieval-Augmented Generation (RAG) systems transforms how diverse data types are synthesized into actionable insights.
This integration hinges on the ability of LLMs to process unstructured text while multi-modal RAG bridges the gap by incorporating structured, visual, or even auditory data.
The result is a system capable of delivering contextually rich outputs that traditional single-modal approaches cannot achieve.
A critical innovation lies in the alignment of embeddings across modalities.
For instance, NVIDIA’s NeMo framework employs unified embedding spaces, ensuring that textual and visual data share a common semantic representation.
This approach eliminates the fragmentation often seen in multi-modal systems, enabling seamless retrieval and generation.
Imagine a healthcare application where patient records, imaging data, and genomic sequences converge to provide precise diagnostic recommendations—this is the power of multi-modal RAG in action.
However, misconceptions persist. Many assume that increasing model complexity guarantees better performance.
In reality, success depends on fine-tuning embeddings for domain-specific tasks, as demonstrated by NVIDIA’s use of hierarchical indexing to optimize retrieval across modalities. This balance between complexity and efficiency underscores the strategic depth required for effective integration.
The implications are profound: multi-modal RAG systems redefine the boundaries of AI applications, enabling industries to tackle challenges that demand holistic, cross-domain intelligence.
Leveraging Large Language Models
Integrating Large Language Models (LLMs) into multi-modal RAG systems hinges on a nuanced yet transformative technique: aligning embeddings across modalities.
This process ensures that textual, visual, and auditory data converge into a unified semantic space, enabling seamless retrieval and generation.
The challenge lies not in the scale of the model but in the precision of this alignment, which dictates the system’s ability to synthesize diverse data types into coherent outputs.
A critical mechanism here is the use of shared embedding spaces, where each modality is mapped to a common vector representation.
This approach minimizes fragmentation and enhances contextual relevance. For example, NVIDIA’s NeMo framework employs domain-specific embeddings to align medical imaging data with patient records, creating a cohesive diagnostic narrative.
Such alignment is not merely technical but strategic, as it directly impacts the interpretability and utility of the generated insights.
However, this technique is not without limitations. Edge cases, such as ambiguous or incomplete data, can disrupt the alignment, leading to inconsistent outputs.
Addressing these requires iterative fine-tuning and robust evaluation metrics tailored to the application domain.
By mastering this alignment, organizations unlock the full potential of multi-modal RAG, transforming disparate data into actionable intelligence with unprecedented clarity and precision.
Exploring Multi-Modal RAG Approaches
The cornerstone of effective multi-modal RAG lies in achieving seamless alignment between diverse data modalities, such as text and images, within a unified semantic space.
This alignment is not merely a technical requirement but a strategic enabler, ensuring that each modality contributes meaningfully to the system’s output.
The challenge, however, lies in refining embeddings to capture the unique characteristics of each modality while maintaining coherence across the shared space.
One advanced technique involves leveraging contrastive learning models like CLIP, which align image and text embeddings by maximizing their mutual relevance.
While this approach reduces architectural complexity, it introduces limitations when expanding to additional modalities, such as audio or video. A comparative analysis reveals that while unified embeddings simplify integration, they often struggle with domain-specific nuances, necessitating fine-tuning for specialized applications.
Contextual factors, such as the diversity of training data, significantly influence the effectiveness of these embeddings.
For instance, in a healthcare application, aligning medical imaging data with textual patient records requires embeddings that account for both clinical terminology and visual diagnostic patterns. This complexity underscores the importance of domain-specific adaptation.
By treating alignment as a dynamic process rather than a static configuration, practitioners can unlock the full potential of multi-modal RAG, transforming fragmented data into actionable intelligence.
Hardware Acceleration and Software Frameworks
The synergy between hardware acceleration and advanced software frameworks is the linchpin of NVIDIA’s Retrieval-Augmented Generation (RAG) systems, enabling unparalleled efficiency and scalability.
At the heart of this integration lies the NVIDIA GH200 Grace Hopper Superchip, which delivers an astonishing 150x speedup over traditional CPU-based systems.
This performance leap is not merely about raw computational power; it transforms how RAG pipelines handle vast, dynamic datasets in real-time.
NVIDIA’s NeMo Framework and Triton Inference Server complement this hardware by orchestrating seamless data flow and optimizing inference processes.
For instance, NeMo’s modular design allows developers to fine-tune large language models (LLMs), while Triton ensures low-latency deployment across diverse environments.
Together, they create a cohesive ecosystem where GPU-accelerated vector searches and embedding generation operate precisely and quickly.
Think of this integration as a finely tuned orchestra: the hardware provides the raw energy while the software conducts and refines it into actionable intelligence. This harmony accelerates AI workflows and redefines their potential, enabling smarter, context-aware systems that adapt to complex, real-world demands.
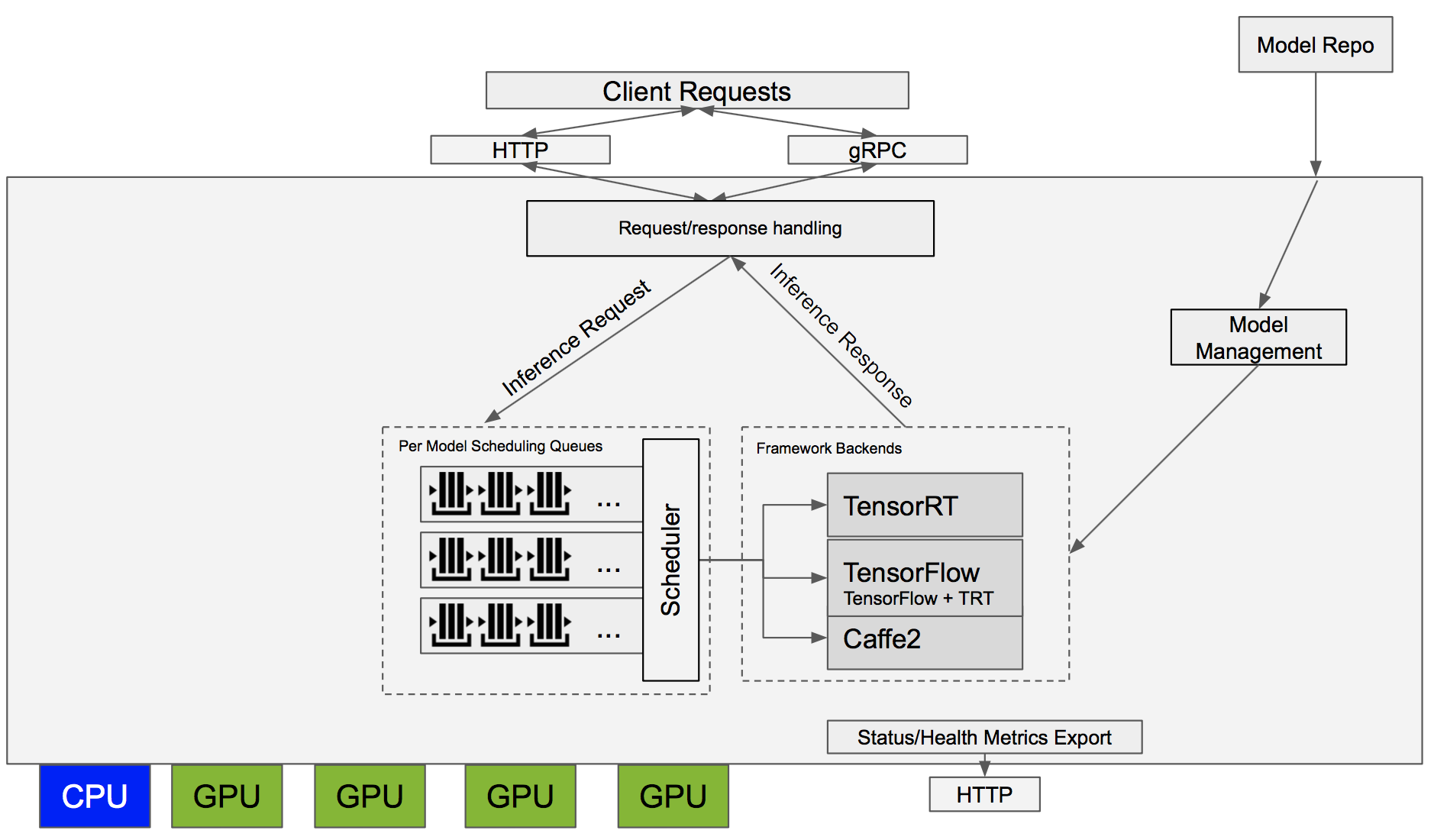
GPU-Accelerated Vector Search
GPU-accelerated vector search is not just about speed; it’s about precision in managing high-dimensional data flows.
The real breakthrough lies in how GPUs handle Approximate Nearest Neighbor (ANN) algorithms, enabling rapid similarity searches across billions of vectors.
This capability transforms RAG systems by ensuring that even the most complex queries yield actionable millisecond results.
One critical factor often overlooked is the role of hierarchical indexing structures, such as HNSW (Hierarchical Navigable Small Worlds).
These structures optimize search efficiency by organizing vectors into layered graphs, reducing the computational burden during retrieval.
However, their effectiveness depends heavily on fine-tuning parameters like graph connectivity and search depth. Misconfigurations can lead to excessive latency or diminished accuracy, particularly in large-scale deployments.
A notable example is NVIDIA’s integration of FAISS with GPU acceleration, which has enabled enterprises to achieve seamless scalability.
Organizations have reduced retrieval times by orders of magnitude by leveraging GPU memory for real-time indexing.
Yet, challenges persist in balancing memory allocation with query throughput, especially under high-load conditions.
Ultimately, the success of GPU-accelerated vector search hinges on aligning technical configurations with application-specific demands, ensuring both speed and relevance in every query.
FAQ
What are NVIDIA’s Advanced RAG techniques, and how do they improve AI retrieval?
NVIDIA’s Advanced RAG techniques use GPU-accelerated FAISS, NeMo, and hierarchical indexing to enhance retrieval speed and accuracy. By refining embeddings, applying dynamic reranking, and integrating multi-modal data, these methods improve document relevance and query precision, ensuring AI systems generate accurate, context-aware results.
How do NVIDIA’s free courses on RAG techniques address retrieval accuracy and relevance?
NVIDIA’s free courses teach retrieval accuracy optimization using FAISS and NeMo. Topics include query transformation, embedding refinement, and indexing methods. They cover solving fragmented data issues, fine-tuning domain-specific models, and improving document ranking for more precise, scalable AI-driven retrieval.
What role do FAISS and NeMo play in NVIDIA’s RAG framework?
FAISS accelerates vector searches with hierarchical indexing, while NeMo enhances embeddings and fine-tuning. Together, they enable scalable, high-speed retrieval, improving document ranking and AI response precision in industries like finance, customer support, and telecommunications.
How can developers optimize multi-modal retrieval using NVIDIA’s RAG techniques?
Developers can align text, images, and audio using NeMo’s fine-tuned embeddings and FAISS’s high-speed indexing. Query transformation expands search accuracy, while hierarchical indexing ensures rapid multi-modal retrieval. These techniques improve AI performance in healthcare, multimedia search, and enterprise applications.
What are the industry applications covered in NVIDIA’s free courses on RAG?
NVIDIA’s courses cover RAG applications in telecom, e-commerce, and healthcare. Telecoms use RAG for O-RAN optimization, while e-commerce enhances search and recommendations. Healthcare integrates patient records with imaging for diagnostics. Courses focus on scalable GPU-accelerated deployment strategies for real-world use.
Conclusion
NVIDIA’s Advanced RAG techniques combine high-speed retrieval with domain-specific accuracy, making AI more reliable for real-time decision-making.
These systems optimize query processing across industries by using GPU-accelerated FAISS, NeMo, and hierarchical indexing.
NVIDIA’s free courses offer practical training in retrieval strategies, embedding models, and AI deployment, helping developers improve RAG system accuracy and scalability.