
How to Build a RAG System Using Open-source Models
Building a RAG system with open-source models offers flexibility, privacy, and cost savings. This guide walks you through the tools, architecture, and steps needed to create a powerful retrieval-augmented generation system using open-source components.


Let’s be honest — building a RAG (Retrieval-Augmented Generation) system sounds exciting… until you try doing it with open-source models.
Suddenly, things get messy. You’re juggling vector databases, retrieval pipelines, embeddings, and half-documented tools that barely talk to each other. The promise of a fast, cost-efficient, private RAG stack? Feels a million GitHub issues away.
This guide is here to change that.
In this practical breakdown of how to build a RAG system using open-source models, we’ll walk through everything — from setting up the retrieval layer to wiring it into your LLM.
Whether you’re building a prototype or deploying at scale, we’ll help you make smart choices at each step — no vendor lock-in, no vague tutorials. If you’ve ever wanted full control over your RAG pipeline, this is where it starts.
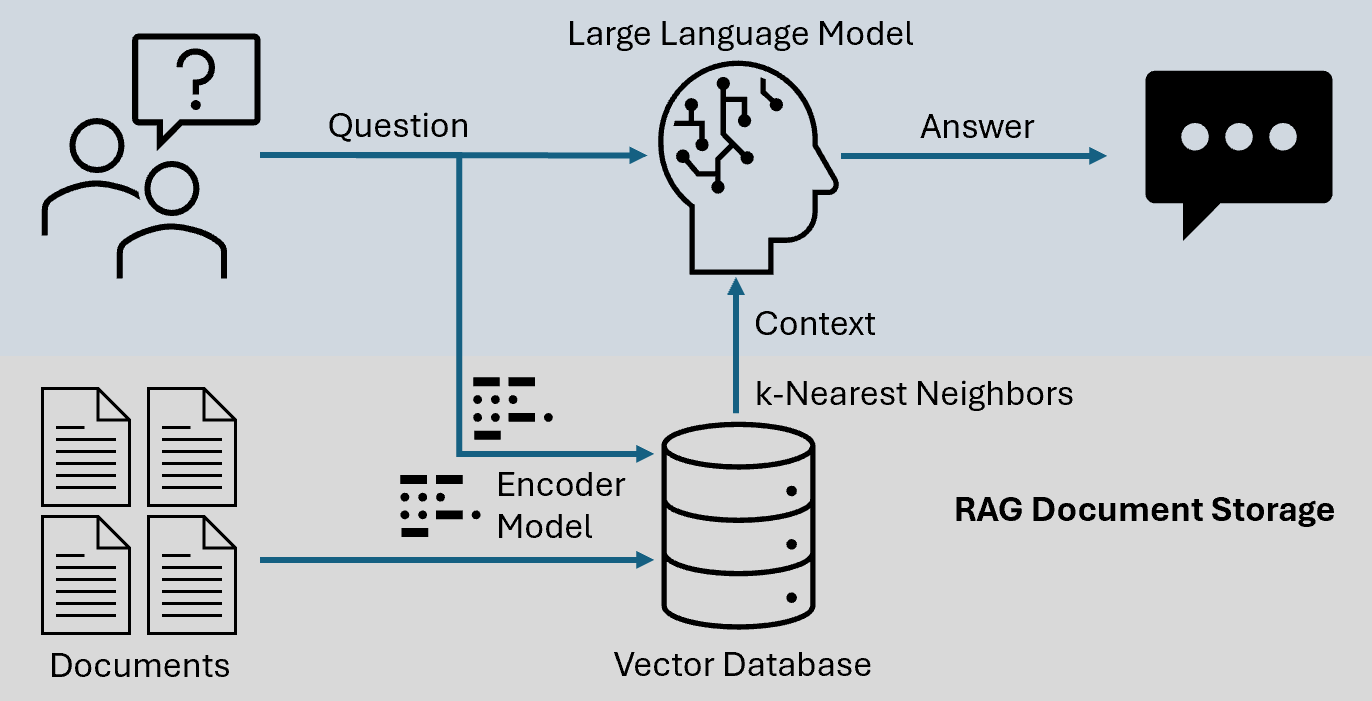
Core Concepts of RAG Systems
Essentially, RAG systems maintain semantic alignment between retrieval and generation. This alignment hinges on embedding models, which translate textual data into high-dimensional vectors.
However, the often-overlooked complexity is ensuring that these embeddings are not only accurate but also contextually compatible with the generative model’s input requirements.
Embedding compatibility is crucial because even slight mismatches can distort the retrieval process, resulting in irrelevant or incoherent outputs.
For instance, while cosine similarity is a popular metric for comparing vectors, its effectiveness can vary depending on the embedding model’s training data and dimensionality. This highlights the importance of selecting or fine-tuning embeddings that align with the domain-specific needs of the RAG system.
A practical example of this principle is seen in the legal domain, where RAG systems must retrieve case law with exacting precision.
Here, fine-tuned embeddings trained on legal texts ensure that the retrieved documents provide the necessary context for accurate and relevant generative outputs.
This approach highlights how embedding optimization directly impacts real-world applications.
Benefits of Using Open-source Models
Open-source models excel in adaptability, offering unparalleled flexibility to fine-tune Retrieval-Augmented Generation (RAG) systems for domain-specific needs.
Unlike proprietary solutions, they allow developers to modify every layer of the system, from embeddings to retrieval mechanisms, ensuring optimal alignment with unique operational requirements.
This adaptability stems from the inherent transparency of open-source frameworks.
Developers gain full access to the model’s architecture, enabling precise debugging and performance optimization.
For instance, tailoring vector embeddings to a specialized corpus—such as financial reports or medical literature—becomes straightforward, enhancing retrieval accuracy and generative coherence.
However, the true strength of open-source models lies in their collaborative ecosystem. Communities actively contribute improvements, share best practices, and refine methodologies. This collective innovation accelerates advancements while reducing the risk of vendor lock-in, a standard limitation of proprietary systems.
A notable example is Hugging Face’s Transformers library, which has enabled organizations like Bloomberg to build domain-specific RAG systems.
By using open-source tools, they achieved superior performance in financial data retrieval, demonstrating the practical advantages of transparency and customization.
Preparing Data for RAG Systems
The foundation of any high-performing RAG system lies in the meticulous preparation of its data.
This process is not merely about gathering documents but about transforming raw information into a structured, optimized format that aligns seamlessly with the system’s retrieval and generative components.
A critical first step is data cleaning and normalization. This involves removing duplicates, correcting inconsistencies, and ensuring uniform formatting.
For instance, when working with customer interaction logs, inconsistencies in timestamp formats or missing metadata can disrupt retrieval accuracy. Tools like CleanLab have proven effective in automating the detection of such anomalies, significantly reducing manual effort.
Equally important is chunking, the segmentation of unstructured data into manageable units. While smaller chunks enhance precision, they can increase processing time. Conversely, overly large chunks risk diluting semantic coherence.
Striking the right balance often requires iterative experimentation, guided by the specific requirements of your domain.
Finally, integrating metadata—such as timestamps, authorship, or source reliability—enhances contextual understanding. This additional layer of information allows the system to prioritize more relevant data, ensuring outputs are both accurate and contextually rich.
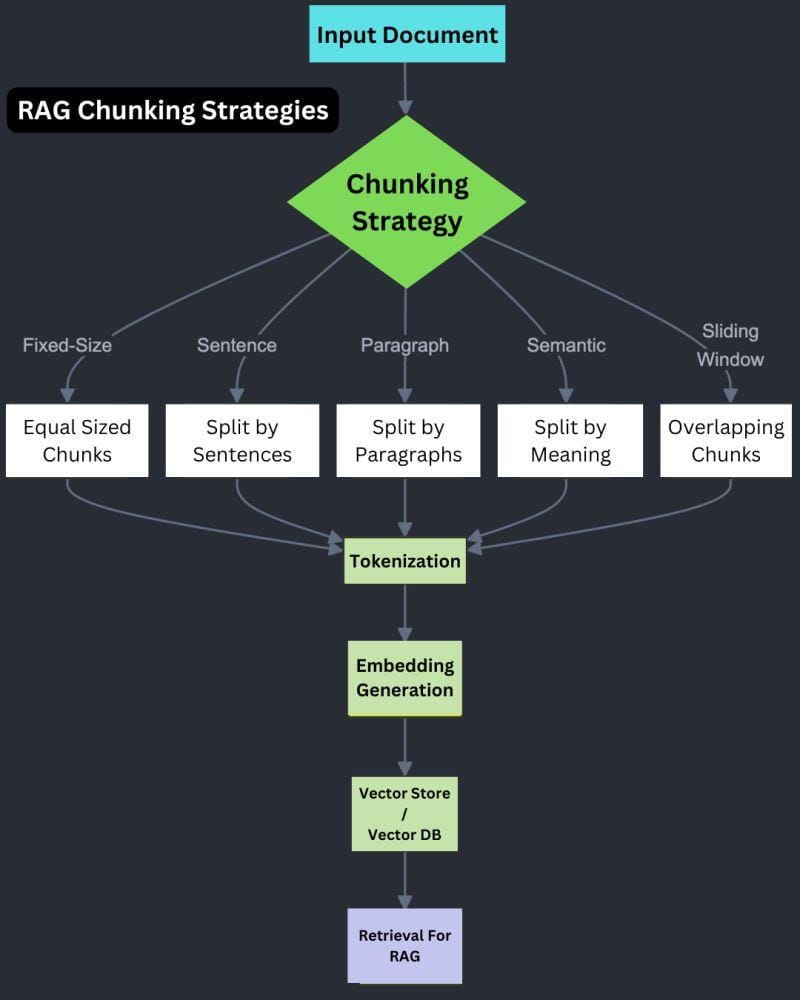
Data Collection and Chunking Techniques
Effective chunking begins with understanding the interplay between data structure and retrieval goals.
One often-overlooked technique is hierarchical chunking, which organizes data into nested layers, such as sections, subsections, and paragraphs.
This method preserves the document’s logical flow while enabling granular retrieval, making it particularly effective for structured texts, such as legal contracts or academic papers.
The key to successful hierarchical chunking lies in maintaining semantic cohesion across levels.
For instance, splitting a legal document into clauses ensures that each chunk retains its contextual meaning, avoiding fragmented or incoherent retrieval.
However, this approach demands precise boundary detection, which can be challenging when dealing with ambiguous or overlapping content.
A comparative analysis reveals that while hierarchical chunking excels at preserving context, it can be computationally intensive compared to simpler methods, such as fixed-size chunking.
The trade-off is clear: higher accuracy versus increased processing time.
Contextual factors, such as the complexity of the document and the retrieval system’s latency tolerance, often dictate the choice.
To implement this technique effectively, iterative refinement is crucial. By dynamically adjusting chunk boundaries based on retrieval performance, systems can achieve a balance between granularity and efficiency.
Ensuring Data Quality and Relevance
The cornerstone of ensuring data quality in RAG systems lies in contextual metadata enrichment, a technique that transforms raw data into a structured and query-optimised format.
Metadata, such as timestamps, source reliability scores, and domain-specific tags, acts as a navigational framework, enabling the system to prioritize relevant information while filtering out noise.
This approach is efficient in dynamic fields, such as finance, where data relevance can shift within hours.
By embedding temporal markers and source credibility metrics, systems can dynamically adjust retrieval priorities, ensuring outputs remain both accurate and timely.
However, this process demands rigorous validation pipelines to prevent metadata inconsistencies from cascading into retrieval errors.
A comparative analysis reveals that while automated metadata tagging accelerates scalability, it often struggles with nuanced contexts, such as distinguishing between primary and secondary sources.
In contrast, human-in-the-loop systems excel in precision but introduce challenges related to latency and scalability. Balancing these approaches requires domain-specific calibration.
To operationalise this, organisations like Bloomberg have integrated real-time metadata validation tools, resulting in enhanced retrieval precision in high-stakes environments. This underscores the critical interplay between metadata design and system reliability.
Generating Embeddings with Open-source Models
Embedding generation is the linchpin of any Retrieval-Augmented Generation (RAG) system, transforming raw text into high-dimensional vectors that encode semantic meaning.
Open-source models like BERT and Sentence Transformers excel in this domain, offering flexibility and transparency that proprietary systems often lack.
However, the real challenge lies in tailoring these models to align with the unique demands of your dataset and application.
One critical insight is that embedding quality hinges on the interplay between dimensionality and contextual depth.
For instance, while higher-dimensional embeddings capture nuanced relationships, they can introduce noise if the training data lacks domain specificity. This is where fine-tuning becomes indispensable.
By training models on curated datasets—such as legal documents or medical records—you can significantly enhance retrieval precision without inflating computational costs.
A common misconception is that larger models consistently outperform smaller ones. In reality, compact models like nomic-embed-text can deliver faster embeddings for real-time applications, provided the retrieval tasks are less context-heavy.
This trade-off underscores the importance of aligning model selection with operational priorities, such as latency or accuracy.
Ultimately, embedding generation is not just a technical step but a strategic decision that shapes the entire RAG pipeline.
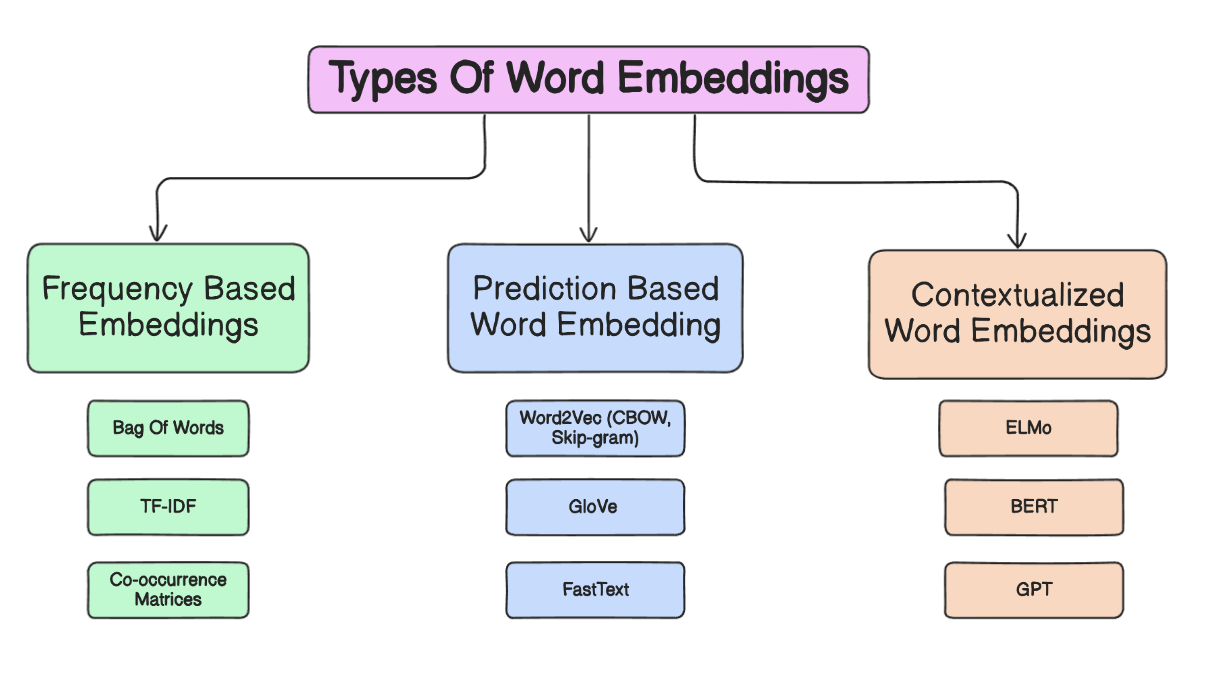
Selecting Appropriate Embedding Models
Choosing the right embedding model is less about size and more about alignment with your dataset’s unique characteristics.
A model’s effectiveness hinges on its ability to capture the semantic nuances of your domain, which often requires fine-tuning rather than relying on out-of-the-box solutions.
One critical factor is dimensionality. While high-dimensional embeddings can encode complex relationships, they often introduce noise when applied to narrowly focused datasets.
For instance, in a healthcare application, a compact model fine-tuned on medical literature may outperform a larger, general-purpose model by delivering more precise semantic matches. This highlights the importance of striking a balance between dimensionality and domain specificity.
Another overlooked aspect is tokenization schemes. Models with tokenizers optimized for your domain’s vocabulary—such as chemical formulas or legal jargon—can significantly enhance retrieval accuracy.
For example, a legal RAG system built by a mid-sized law firm leveraged a fine-tuned SBERT model, achieving superior alignment with case law terminology compared to generic embeddings.
Ultimately, embedding selection is a strategic decision. By prioritizing compatibility with your data’s structure and semantics, you can unlock the full potential of your RAG system.
Embedding Generation and Optimization
Embedding generation is an intricate process where precision dictates success. One often-overlooked aspect is the impact of dimensionality reduction techniques on the quality of embeddings.
While high-dimensional embeddings can capture complex relationships, they risk introducing redundancy and noise, especially in domain-specific applications.
Techniques such as Principal Component Analysis (PCA) or t-SNE can streamline embeddings, but their effectiveness depends on careful calibration to preserve semantic integrity.
The choice of pre-training corpus also plays a pivotal role. Models trained on general datasets may fail to capture the nuances of specialized domains.
For instance, embeddings for pharmaceutical research require exposure to chemical nomenclature and clinical terminologies.
Fine-tuning on curated datasets ensures that embeddings align with the domain’s semantic landscape, enhancing retrieval accuracy.
Another critical factor is contextual embedding validation. Embeddings must be tested within the operational environment to ensure they meet retrieval and generative requirements.
For example, a financial RAG system might validate embeddings by assessing their performance in retrieving quarterly reports under varying query conditions.
Ultimately, embedding generation is a balancing act—one that requires harmonizing dimensionality, domain specificity, and contextual validation to achieve optimal performance.
Setting Up Vector Databases
Establishing a vector database for a RAG system is akin to designing the neural pathways of a brain—it determines how efficiently and accurately information flows.
The first step is to select a database that aligns with the scale and complexity of your data. For instance, Milvus, an open-source solution, excels in handling billions of vectors with sub-millisecond latency, making it ideal for high-demand applications.
Indexing strategies are equally critical. Techniques like Hierarchical Navigable Small World (HNSW) graphs optimise similarity searches by structuring data into layers, thereby reducing query times without compromising precision. However, improper configuration can lead to bottlenecks, especially in real-time systems.
Integration is another overlooked aspect.
Ensuring compatibility with frameworks like Hugging Face Transformers or LangChain streamlines embedding workflows, reducing operational friction. Think of this as ensuring your database speaks the same language as your models.
Ultimately, a well-configured vector database transforms raw embeddings into actionable insights, driving the system’s overall performance.

Choosing the Right Vector Database
Selecting a vector database for a RAG system requires a nuanced understanding of how indexing strategies influence both performance and scalability.
One critical yet underappreciated aspect is the choice between Hierarchical Navigable Small World (HNSW) graphs and Inverted File (IVF) indexes.
While HNSW excels in low-latency, high-precision searches, its memory-intensive nature can become a bottleneck for large-scale datasets. IVF, on the other hand, offers a more resource-efficient alternative but may sacrifice some retrieval accuracy in exchange for scalability.
The effectiveness of these indexing methods is highly context-dependent. For instance, in applications requiring real-time responses, such as conversational AI, HNSW’s speed advantage often outweighs its resource demands.
Conversely, for archival systems managing billions of vectors, IVF’s ability to handle disk-based storage with minimal memory overhead becomes indispensable.
Beyond indexing, integration with embedding models is another pivotal factor.
Databases with native support for models like Sentence Transformers or OpenAI embeddings streamline workflows, reducing engineering overhead.
Ultimately, the right choice balances indexing efficiency, model compatibility, and scalability, ensuring the database serves as a seamless backbone for the RAG architecture.
Indexing and Storing Embeddings
Indexing embeddings is not merely a technical step; it’s a strategic process that determines how effectively your system retrieves relevant data.
The choice of indexing strategy—whether Hierarchical Navigable Small World (HNSW) or Inverted File (IVF)—directly impacts both retrieval speed and accuracy.
HNSW excels in low-latency environments, utilising graph-based structures to prioritise precision, while IVF provides scalability for massive datasets by clustering vectors into partitions.
However, the trade-offs between these methods often hinge on your application’s tolerance for latency versus memory consumption.
A critical yet overlooked factor is the parameter tuning within these indexing algorithms.
For instance, HNSW’s performance can vary significantly based on the number of layers and connections per node. Misconfigurations can lead to either excessive memory usage or degraded search quality. Similarly, IVF requires careful calibration of cluster sizes to balance retrieval precision against computational overhead.
In practice, embedding storage must also preserve the semantic richness encoded in vectors.
Techniques like quantization can reduce storage costs but risk losing critical nuances. Fine-tuning these trade-offs ensures your database remains both efficient and contextually accurate.
Implementing Retrieval Logic
Retrieval logic in a RAG system is not merely about fetching data; it’s about orchestrating a precise interaction between user intent and the system’s knowledge base.
At its core, this involves designing mechanisms that ensure the retrieved information is both contextually relevant and computationally efficient. A common misconception is that retrieval quality solely depends on embedding models; however, the real differentiator often lies in how the retrieval logic is structured.
A critical aspect is query interpretation, where techniques such as query expansion and disambiguation are employed.
For instance, leveraging transformer-based models to rewrite ambiguous queries dynamically can significantly enhance retrieval accuracy. This approach ensures that even complex, multi-faceted queries are mapped to the most relevant data points.
Another overlooked factor is adaptive ranking algorithms.
By integrating user feedback loops, these algorithms continuously refine relevance scoring, aligning retrieval outputs with evolving user needs.
For example, a legal RAG system might prioritize recent case law over older precedents based on temporal metadata.
Think of retrieval logic as the conductor of an orchestra: it harmonizes embeddings, indexing, and ranking to deliver outputs that resonate with user intent.
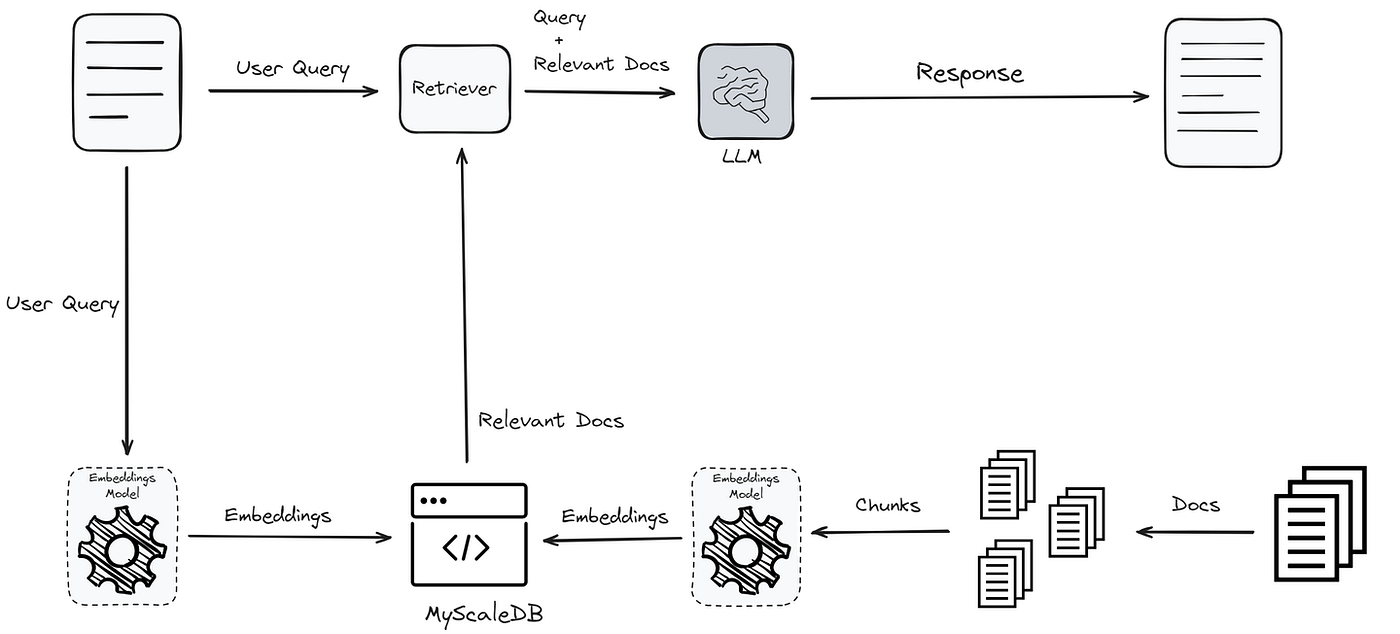
Semantic Search and Similarity Measures
Semantic search thrives on its ability to interpret meaning rather than merely matching words. A critical yet underexplored aspect is the role of contextual weighting in similarity measures.
While cosine similarity is a foundational metric, its raw output often fails to account for the nuanced importance of certain terms within a query.
For instance, in a medical RAG system, terms like “chronic” or “acute” carry disproportionate weight compared to generic descriptors, yet traditional similarity scores treat all terms equally.
To address this, advanced systems integrate contextual amplification factors, dynamically adjusting term weights based on domain-specific relevance. This approach transforms similarity scores into more meaningful rankings.
For example, a healthcare chatbot might prioritize documents discussing “chronic pain management” over those mentioning “pain relief” in passing, even if both score similarly in raw cosine metrics.
However, this refinement introduces challenges. Overweighting specific terms can lead to overfitting, where the system becomes too narrow in its retrieval scope. Balancing these factors requires iterative tuning and domain expertise.
By embedding contextual weighting into similarity measures, RAG systems can bridge the gap between mathematical precision and practical relevance, ensuring outputs resonate with user intent.
Optimizing Retrieval for Performance
Fine-tuning retrieval performance often hinges on balancing precision and efficiency, a challenge that becomes particularly nuanced when dealing with high-dimensional vector spaces.
One overlooked yet impactful technique is dynamic query re-weighting, which adjusts the importance of query terms based on their contextual relevance. This approach ensures that critical terms—those carrying the most semantic weight—are prioritised, resulting in more accurate retrieval outcomes.
The effectiveness of this method lies in its adaptability.
For instance, in a legal RAG system, terms like “jurisdiction” or “precedent” may require higher weighting than auxiliary terms.
By dynamically recalibrating these weights, the system aligns retrieval outputs more closely with user intent.
However, this process demands careful calibration to avoid overfitting, where the system becomes overly tailored to specific query patterns, reducing its generalizability.
A comparative analysis of retrieval algorithms reveals that while traditional cosine similarity offers computational simplicity, it often fails to capture the nuanced relationships between terms.
In contrast, integrating re-weighting mechanisms with advanced ranking models, such as cross-encoders, significantly enhances contextual alignment. This trade-off between computational overhead and retrieval accuracy must be carefully managed.
Ultimately, optimising retrieval is an iterative process that requires domain-specific adjustments and continuous evaluation to ensure alignment with real-world application needs.
Generating Responses with Open-source LLMs
Generating responses with open-source large language models (LLMS) requires a precise orchestration of retrieval outputs and generative capabilities.
A critical insight is that the quality of responses hinges on contextual grounding—ensuring the retrieved data aligns seamlessly with the model’s input requirements.
Misalignment here often results in outputs that feel disjointed or lack relevance, undermining user trust.
One advanced technique involves adaptive prompt engineering, where prompts dynamically adjust based on the structure and intent of the retrieved content.
For example, in a customer support application, tailoring prompts to emphasize urgency or empathy can significantly enhance user satisfaction. This approach transforms static interactions into dynamic, context-aware exchanges.
Another overlooked factor is response coherence validation.
By employing post-generation checks, such as semantic similarity scoring between the query and response, systems can filter out irrelevant outputs. This ensures that the generated text not only answers the query but does so with precision and clarity.
The interplay between retrieval precision and generative adaptability defines the success of open-source LLMs in RAG systems.
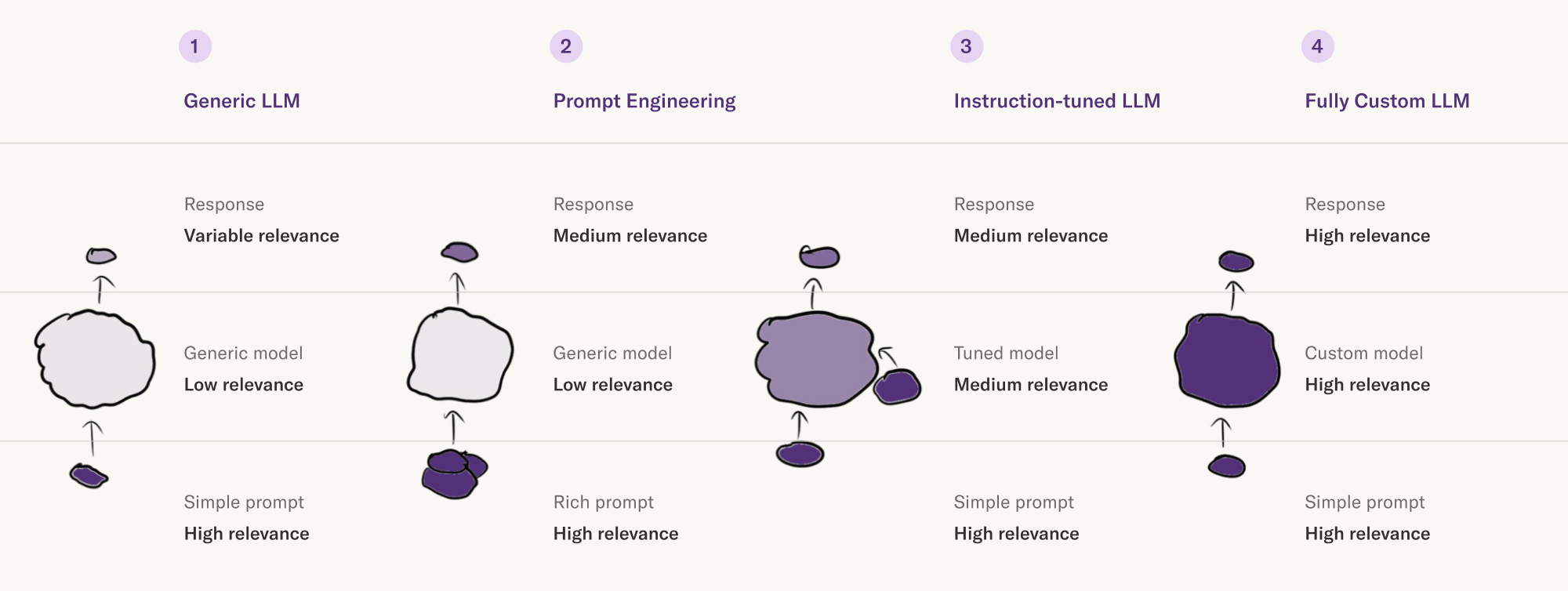
Integrating LLMs for Response Generation
The key to effective response generation lies in adaptive prompt alignment, a nuanced technique that ensures the retrieved data seamlessly integrates with the LLM’s generative process.
This alignment is not merely about formatting; it involves structuring prompts to reflect the semantic and contextual depth of the retrieved content.
Without this, even the most advanced LLMs can produce outputs that feel disconnected or irrelevant.
One critical method is dynamic prompt templating, where placeholders adapt to the structure of the retrieval output.
For instance, in a legal RAG system, prompts can dynamically emphasize jurisdictional context or case precedence, ensuring the LLM generates responses that are both precise and contextually grounded.
This approach minimizes the risk of generic or misaligned outputs, a common pitfall in static prompt designs.
However, challenges arise in balancing prompt complexity with token limits, especially in high-dimensional retrieval scenarios. Iterative testing and refinement are crucial for optimising this balance.
By integrating adaptive prompts with retrieval outputs, practitioners can achieve a synergy that transforms raw data into coherent, actionable insights, elevating the system’s overall utility.
Enhancing Response Accuracy and Relevance
Achieving precise and relevant responses in RAG systems relies on contextual prompt calibration, a technique that dynamically adjusts prompts based on the semantic structure of the retrieved data.
This approach ensures that the generative model interprets the retrieval output with maximum fidelity, reducing the risk of incoherent or irrelevant responses.
One critical mechanism is contextual embedding alignment, where the retrieved data is preprocessed to emphasise key semantic elements before being fed into the large language model (LLM).
For instance, in a healthcare application, highlighting terms like “contraindications” or “dosage” within the prompt ensures the model prioritizes these aspects in its response. This method not only enhances accuracy but also aligns the output with domain-specific expectations.
In comparison, static prompts often fail to adapt to nuanced queries, resulting in generic outputs. In contrast, dynamic calibration leverages retrieval metadata—such as timestamps or source reliability—to refine the structure of the prompt.
However, this technique requires robust validation pipelines to prevent overfitting, particularly in high-stakes environments like legal or financial systems.
By combining adaptive prompts with metadata-driven refinements, practitioners can create systems that deliver not just accurate but contextually resonant responses, setting a new standard for user engagement.
FAQ
What are the key components of a RAG system using open-source models?
A RAG system includes a retriever for fetching documents, a vector database for storing embeddings, and an open-source language model for response generation. Supporting parts include a preprocessing pipeline for chunking and metadata, and an integration layer to connect retrieval with generation.
How do embedding models and vector databases interact in a RAG pipeline?
Embedding models convert text into vectors. These vectors are stored in a database like FAISS or Milvus. When a query is entered, it’s also embedded, and the database returns vectors with similar meanings. These documents are passed to the language model for response generation.
What practices improve retrieval accuracy in open-source RAG systems?
To improve retrieval accuracy, fine-tune embedding models on domain data, use high-precision indexing like HNSW, apply query reformulation, and refresh vector databases often. Feedback loops can help adjust relevance scoring to match query intent more closely over time.
How does domain-specific fine-tuning help RAG models?
Fine-tuning models on domain-specific text improves semantic understanding. It aligns vector similarity with real context and helps the language model use the correct terminology. This increases the accuracy and reliability of both retrieval and generated responses in specialized use cases.
What strategies work best when evaluating and deploying open-source RAG systems?
Use metrics like context relevance, latency, and hallucination rate to evaluate performance. Deploy in stages with rollback options. Modular components help isolate issues. Privacy safeguards and prompt validation reduce risks during live use, especially in regulated or time-sensitive domains.
Conclusion
Building a RAG system with open-source models requires careful attention to data quality, embedding design, retrieval logic, and model alignment. By choosing tools that match your domain’s needs and fine-tuning every layer—from chunking to generation—you can create reliable, adaptable systems that respond with clarity and precision.